
Abstract
The fundamental aim of feature selection is to reduce the dimensionality of data by removing irrelevant and redundant features. As finding out the best subset of features from all possible subsets is computationally expensive, especially for high dimensional data sets, meta-heuristic algorithms are often used as a promising method for addressing the task. In this paper, a variant of recent meta-heuristic approach Owl Search Optimization algorithm (OSA) has been proposed for solving the feature selection problem within a wrapper-based framework. Several strategies are incorporated with an aim to strengthen BOSA (binary version of OSA) in searching the global best solution. The meta-parameter of BOSA is initialized dynamically and then adjusted using a self-adaptive mechanism during the search process. Besides, elitism and mutation operations are combined with BOSA to control the exploitation and exploration better. This improved BOSA is named in this paper as Modified Binary Owl Search Algorithm (MBOSA). Decision Tree (DT) classifier is used for wrapper based fitness function, and the final classification performance of the selected feature subset is evaluated by Support Vector Machine (SVM) classifier. Simulation experiments are conducted on twenty well-known benchmark datasets from UCI for the evaluation of the proposed algorithm, and the results are reported based on classification accuracy, the number of selected features, and execution time. In addition, BOSA along with three common meta-heuristic algorithms Binary Bat Algorithm (BBA), Binary Particle Swarm Optimization (BPSO), and Binary Genetic Algorithm (BGA) are used for comparison. Simulation results show that the proposed approach outperforms similar methods by reducing the number of features significantly while maintaining a comparable level of classification accuracy.
Keywords
Introduction
Classification (supervised) is one of the important areas of machine learning in which new observation is predicted based on the learning from training data. It is frequently noticed that datasets contain numerous features, which are not equally important for classification performance. Some redundant and irrelevant features make the classification model more complex, incur more computational burden and affect the classification performance [1]. The problem can be solved effectively with feature selection approach by selecting the most informative or discriminatory features for classification.
Feature subset selection algorithms can be divided into two basic approaches based on feature ranking and subset selection [2]. In ranking approach, features are ordered according to a feature evaluation metric, and high ranking features are selected depending on a predefined number of features or a threshold value of the evaluation metric. Subset selection uses a search strategy that aims to find out the optimal feature subset from all possible subsets. Based on evaluation metrics, feature selection approaches are categorized into wrappers, filters and embedded approach [3]. Wrapper approach uses classification accuracy as a measurement technique for evaluation of subsets. On the contrary, filter approaches use intrinsic characteristics of datasets as the evaluation metric. Wrapper approach is computationally more expensive than filter techniques, but it produces better classification accuracy. In the embedded approach, feature selection is performed during the model building process.
Feature subset selection can be considered as an optimization problem where the most informative subset with m features are to be selected from a total n features (m < n). Exhaustive search method can find out the optimum feature subset, but it is not plausible for relatively large datasets. This is because the time complexity of feature subset selection is O (2 n ), which is computationally demanding. To overcome the problem, several greedy strategies such as sequential forward search (SFS), and sequential backward search (SBS) are popularly used. However, they are comparatively slower and sub-optimal for high dimensional data sets as a limited area of search space is explored in these algorithms [4]. Another search approach, different from the above, is meta-heuristic search. These stochastic approaches are effective in solving global optimization problems within a reasonable time constraint. Although an optimum solution is not guaranteed, they produce better sub-optimal solution. In feature subset selection, these methods have been used effectively. Some of these methods are Genetic Algorithm (GA) [5], Tabu search [6], Simulated Annealing (SA) [7], and Particle Swarm Optimization (PSO) [8]. Recently, Owl Search Algorithm (OSA) has been proposed to solve continuous optimization problems with satisfactory performance [9]. To date, OSA and its variants have been effectively employed to solve global optimization problems for several application areas. To trace the maximum power point (MPP) for photovoltaic (PV) systems in electric energy production, OSA is combined with Perturb and Observe (P&O) methods, and it is found that P&O-OSA combined approach achieves faster convergence rate in producing maximum power [10]. To solve the optimized method for the telecommunication supply system, an improved version based on OSA was proposed and their reported results were better than PSO and Emperor Penguins Optimizer (EPO) based approach [11]. A type of OSA, named developed OSA (DOSA), was used to optimize cooling, heating, and power (CCHP) systems and fast convergence for the cost function is achieved by the proposed DOSA compared with GA [12]. Besides, chaotic OSA was employed for optimizing the quality of the negotiation process problem and achieved average fitness value better than PSO [13]. It is observed that OSA shows potentiality in solving global optimization problems. Besides, this algorithm is straight forward, and unlike many popular meta-heuristic techniques such as GA and PSO, it has only one parameter for tuning. Although OSA has been used to solve continuous optimization problems, the capability of this algorithm to solve the feature selection problem has not been attempted before. These motivate us to employ OSA algorithm for feature selection problem.
In authors’ previous work, a binary variant of Owl Search Algorithm, named BOSA, has been proposed, which was shown to have good potential for feature selection [14]. However, during feature selection using BOSA, we observed that there are some issues need to be addressed to improve its performance. First, solution quality is highly sensitive to parameter β, and therefore static initialization of β and adjusting its value linearly during the search process does not provide quality feature subsets for many datasets. Besides, the convergence speed of BOSA is comparatively slower and its premature convergence, especially for high dimensional datasets, is likely to result in less number of feature reduction. Considering these issues, the aim of this study is to improve the BOSA algorithm further for feature subset selection in a wrapper based framework. Therefore, in this paper, a new feature subset selection algorithm based on metaheuristic search strategy named as Modified Binary Owl Search Algorithm (MBOSA) has been proposed. In order to achieve a proper balance between exploration and exploitation in search, three strategies are incorporated: a self-adaptive strategy for parameter tuning, elitism mechanism, and mutation operation. Decision Tree (DT) classifier is used for wrapper based fitness function while the final classification performance of the selected feature subset is evaluated by Support Vector Machine (SVM) classifier. To obtain empirical evidence for the performance, the algorithm is employed on several public benchmark datasets and compared with similar state-of-the-art algorithms.
The structure of the paper is organized as follows: Section 2 presents the related works on feature subset selection. Section 3 describes the details of Owl Search Algorithm. The proposed approach of feature selection is presented in section 4. Section 5 reports the information of the datasets, parameter values used for the algorithms and experimental setups. Section 6 presents the experimental results and discussion. Finally, the conclusion is presented in section 7.
Related works
In recent years, various meta-heuristic approaches have been proposed and applied to solve the feature subset selection problem. Among them, population-based algorithms, which consider a set of candidate solutions during the search, are frequently used in feature selection. This is due to their reasonable computational cost and efficient performance in dealing with complex real-world problems.
Early research on population-based feature selection focused on genetic algorithms (GA) and particle swarm optimization (PSO). A filter-based feature selection method was introduced where fuzzy operations are combined with GA [15]. Another implementation of GA approach was multi-objective GA for feature selection of microarray gene expression data [16]. Guha et al. proposed an approach where GA was hybridized with great deluge algorithm to perform feature selection [17]. Meanwhile, a binary GA with granular information was proposed for selecting significant features in [18]. Shukla et al., however, proposed hybrid framework combining the benefits of both filter and wrapper approaches for selecting essential features. In their approach, conditional mutual information maximization (CMIM) selects the prominent features which are then improved by GA [19]. To obtain an optimal feature subset, particle swarm optimization (PSO) has also been extensively used by numerous researchers. A binary variant of PSO or BPSO was proposed for binary optimization problem [20] as well as feature selection problem. An extension of BPSO for feature selection was Hamming distance-based BPSO algorithm for high dimensional feature selection [21]. Furthermore, Chakraborty introduced a BPSO with fuzzy fitness function for appropriate feature selection [22]. Multi-objective concept was also embedded with PSO for feature selection problem [23]. Lu et al. proposed an improved feature selection using particle swarm optimization for text classification [24]. Also, a combination of genetic algorithm and particle swarm optimization was reported in [25].
Another commonly used meta-heuristic for feature selection problem is Ant Colony Optimization (ACO). In [26], authors used ACO for text feature classification. A similar type of wrapper based approach where ACO was hybridized with artificial neural network (ANN) is reported in [27]. A multivariate filter-based feature selection that uses ACO for unsupervised learning was reported in [28]. A harmony search (HS) based feature selection has shown potential for feature selection problem. A recent example of HS for feature selection for imbalanced data problem is presented in [29]. To improve the harmony search-based feature selection for high dimensional medical data, adaptive strategies are suggested in [30]. The apparent merit of this approach is its limited computational overhead. A similar reported relevant approach is feature selection using self-adjusting harmony search [31]. A variation of Artificial Bee Colony (ABC) where similarity search approach was integrated with binary ABC (BABC) algorithm was reported to find out optimum feature subset [32]. Another ABC-based approach is a multi-objective Artificial Bee Colony (MOABC) that employs fuzzy mutual information as a new filter fitness evaluator for efficient feature selection [33]. Cuckoo Search Algorithm (CSA) was also proposed. Combining rough set-based fitness function with CSA for selecting relevant features is reported in [34]. In [35], it was also observed that a gravitational search optimization with wrapper approach can be an effective feature selection strategy [36].
Some contemporary studies in the feature selection problem focused on recent population-based metaheuristics. Rodrigues et al. [37] proposed binary Bat Algorithm (BBA) and Optimum-Path Forest for feature selection. Another approach was a hybridization of BBA with enhanced particle swarm optimization to address the feature selection problem [38]. Mafarja et al. presented a feature selection strategy based on hybridization of Binary Grasshopper Optimization Algorithm (BGOA) with incremental hill climbing search [39]. To improve wrapper feature selection method, in [40], authors combined Binary Salp Swarm Algorithm (BSSA) with Random Weight Network (RWN) classifier and suggested three objectives. Another recent strategy of finding optimal feature subset is Chaotic Salp Swarm Algorithm (CSSA), in which SSA was hybridized with ten different chaotic maps [41]. Chaotic theory was also embedded with other metaheuristic algorithms for feature selection, such as Chaotic Crow Search Algorithm (CCSA) [42], Chaotic Dragonfly Algorithm (CDA) [43], and Chaotic Multi Versed Optimization (CMVO) [44]. In another recent work, Grey Wolf Optimization (GWO) was integrated with Particle Swarm Optimization(PSO) to explore the feature search space [45]. Another similar type of work is combining GWO and Whale Optimization Algorithm (WOA) [46]. Two other recently proposed feature selection approaches based on meta-heuristic algorithms are Binary Teaching-Learning Based Optimization (BTLBO) [47], binary variant of Butterfly Optimization (BBO) [48].
It is observed that several population-based metaheuristics are proposed for solving feature selection problem. According to No Free Lunch theorem [49], a single optimization algorithm cannot work well for all optimization problems. Therefore, new meta-heuristics have the potential to perform well in feature subset selection problem.
Owl search algorithm (OSA)
Owl Search Algorithm (OSA) is a nature-inspired algorithm proposed for global optimization problem in [9]. The inspiration comes from the auditory behavior of owls during hunting their prey. Owls can determine the location of their prey using a unique auditory system whereby the sounds reach one ear before the other. The brain of an owl generates an auditory map of the prey’s sound, which induces the owl to fly towards the prey in dark [9]. This nature-inspired strategy has been employed for solving global optimization problems where a group of owls works to find prey or optimum solution. In the d dimensional space, each owl is represented by a randomly generated position. At each iteration, this position is updated based on the influence of the prey’s movement. Let us suppose that the number of owls is denoted as n. The initial position vector of the i
th
owl is defined as follows:
The fitness function f (.), associated with the optimization problem, evaluates each search agent O
i
. This fitness value of O
i
is directly related to the intensity information received through ear and it is represented as
Finally, the new position of the owl O
i
is updated by the following equations:
In this section, the detail description of the proposed Modified Owl Search Algorithm (MOSA) for feature selection problem is presented. Although the original Owl Search Algorithm(OSA) is effective in continuous optimization problems, it can not be applied directly to the feature selection problem. Therefore, the binary representation of Owl Search Algorithm (BOSA) is proposed earlier by the authors and is presented in brief in the following subsection. The methods of self-adaptive strategy, elitism, and mutation, which are the key steps of improvement of BOSA, are proposed in this work and are described in this section. Finally, the characteristics of the fitness function and the overall procedure of feature selection are presented.
Binary representation of OSA
Binary encoding is used for feature selection problem because it is straight forward to implement. Assuming that
As the positions of the owls are represented in a binary space, Hamming distance is used as a distance measure between the prey and the owl. The original equation of Euclidean distance in (4) is, therefore, replaced as follows.
For updating the owls’ position in binary space, the original updating equation of OSA in Equation 6 is modified into following equation.
Finally, the current position of i
th
owl at (t + 1) iteration in j
th
dimension is updated according to the following equation based on the probability value of Equation 10.
There is a controlling parameter β, which influences the performance of BOSA a lot. This parameter has to be initialized with a relatively large value at the beginning and is gradually decreased as the search progresses. In this proposed approach, the initial value of β is defined dynamically using the following equation.
In each iteration, the parameter β is exponentially decreased using the following mathematical model.
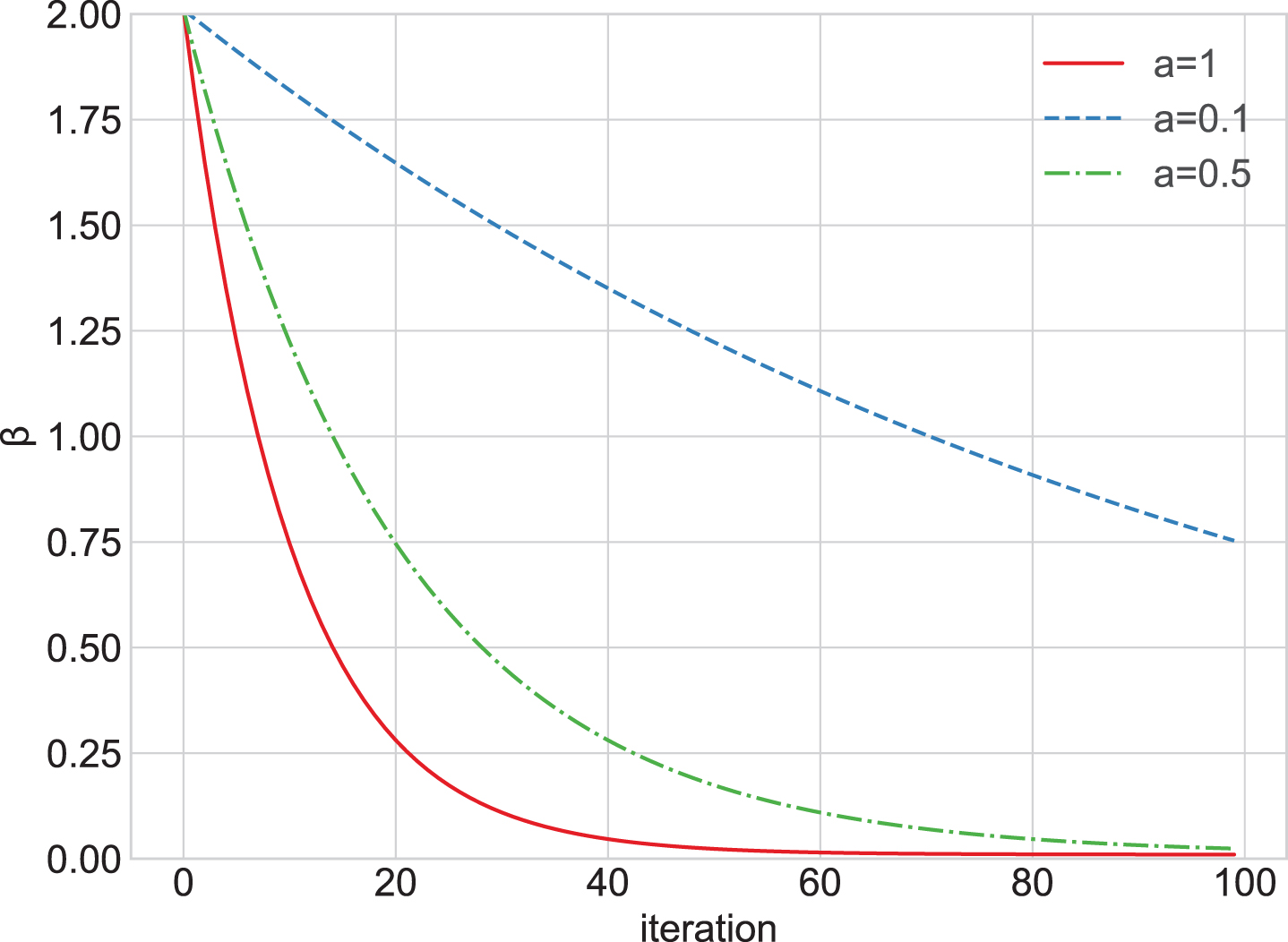
Shape of β during iteration with 3 different a values.
Elitism is a strategy where the best individual is selected for the next generation. Elitism strategy is incorporated in owl search optimization algorithm in order to speed up the convergence of search. In this strategy, the current fitness value of each owl is compared with its immediate earlier fitness value. Between them, the owl with the best fitness value is considered as the candidate owl for the next generation. Mathematically elitism strategy can be represented as follows:
As it is mentioned in the previous subsection that elitism provides exploitation, it may happen that the solutions are trapped into local optimum, and then diversification is needed to move the search landscape into a promising area of solution space. Mutation strategy is incorporated here to perform this task. Usually, mutation operator is used in an evolutionary algorithm for modification of a single chromosome. In this proposed method, mutation operation is performed when the minimum or maximum fitness value of the owl population do not change for two consecutive iterations. Here uniform bit-flip mutation is used in which position values of each owl is a bit flip independently with a mutation probability, mp r [50]. This value is set to mp r = 1/d, where d is the dimension of the owl. Overall, mutation operation is performed using the following equation.
The goodness of a feature subset is measured by a fitness function. In another way, binary position of an owl is measured at a particular iteration t with this fitness function. In this proposed approach, wrapper-based strategy has been used where classification accuracy is employed for evaluation. In addition, measures like the number of selected feature is also counted for the evaluation. These two criteria are combined together to form a single objective and used as an evaluation function. Classification accuracy is calculated by Decision Tree (DT) with Gini Index as splitting measure [51]. Optimization of the fitness function is a maximization problem where better fitness value corresponds to higher classification accuracy with a lower number of features. The fitness function is given as follows. It is noted that the maximum value of the objective function is 1.
In this wrapper approach, classifier accuracy A (O
i
) is measured using following equation:
In this subsection, the entire process of MBOSA for feature subset selection is described. The procedure is illustrated in Fig. 2 and Algorithm 1. This algorithm takes the training data with full features as input value and returns the best feature subset as an output. At first, the owl populations are randomly initialized, and mean fitness value is calculated. The parameter β is then defined based on this fitness value. Besides, other parameters such as a, the global best solution, the position of prey, the number of owls, and the number of iterations are also set.
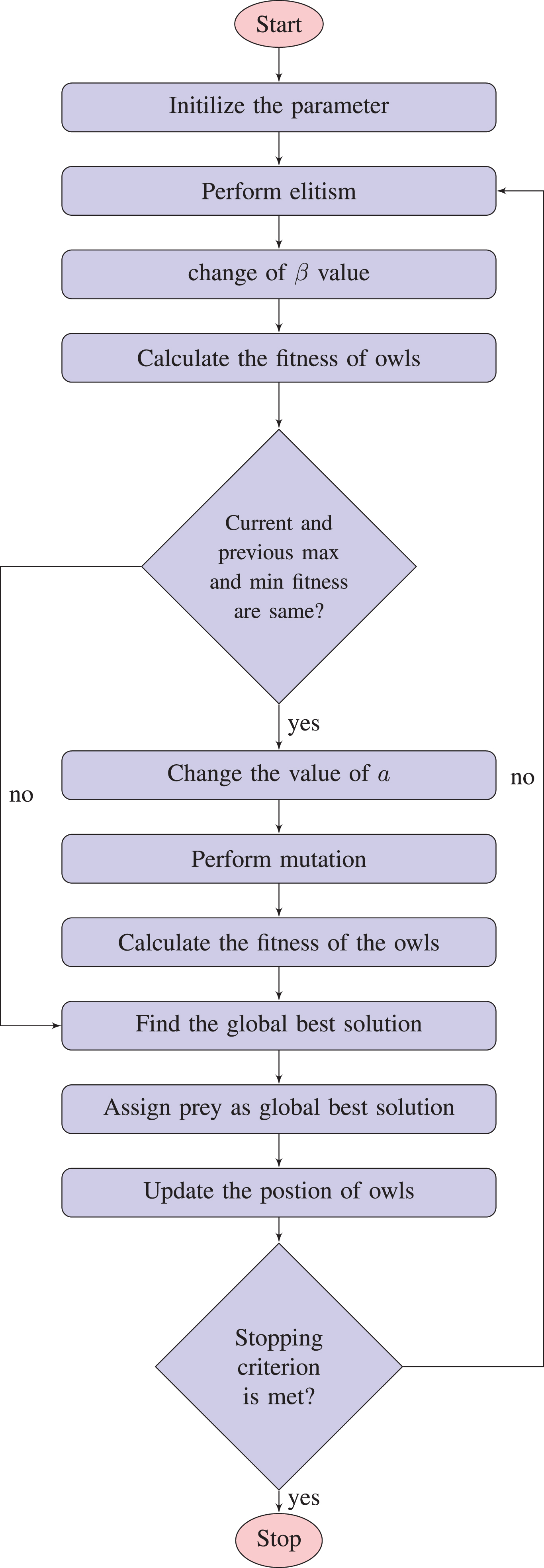
Structure of MBOSA.

After the successful initialization of all parameters, several steps are performed repeatedly until stopping criterion (no. of iteration) is met. Elitism strategy is performed in each iteration so that the better owl population can evolve in the next iteration. After the incorporation of elitism strategy, fitness values are calculated, and maximum as well as minimum fitness values are measured. β value is usually decreased exponentially based on Equation 13. When both maximum and minimum fitness value of owl populations for consecutive iterations are the same, β is adjusted by self-adaptive way, and mutation strategy is performed to diversify the owls in another area of search space. The process of self-adaptive mechanism is accomplished by the changes of parameter a of Equation 14 in such a way that it can control the β value.
Once the mutation is performed, minimum and maximum fitness values are again measured. The best current owl is set as the global best if the fitness value of the best owl is greater than the global best. The global best solution is then assigned to the prey’s position. The next step is the updating of the position vector of each owl. Here the important part is mapping the continuous values to binary ones using sigmoid function or s-type of transfer functions. After the final iteration, the algorithm returns the best owl (global best) as the best (optimal) feature subset.
In this section, the description of the datasets used, design of the simulation experiments, and the settings of parameters for simulation experiments are presented.
Dataset description
In order to evaluate the performance of the proposed MBOSA, twenty benchmark datasets from the UCI repository are employed [54]. Table 1 shows the datasets used in this experiment. These datasets include a different number of features, instances, and classes. Several of the datasets have more than 500 features. Since some datasets contain missing values, a prepossessing step is performed. For numeric features, missing value is replaced with the median value of the feature. On the other hand, a missing value in the categorical feature is replaced with the most frequent value.
Datasets
Datasets
In order to evaluate the proposed MBOSA approach in comparison with other similar approaches, four different state-of-the-art algorithms, which are Binary Particle Swarm Optimization (BPSO) [23], Binary Genetic Algorithm (BGA) [17], Binary Bat Algorithm (BBA) [55] and Binary Owl Search Algorithm (BOSA) [14] are selected for feature subset selection. In [14], authors proposed BOSA with different transfer functions for building BOSA model. In order to avoid bias by the transfer function, the same transfer function in Equation 10 is used here for BBA, BPSO, BOSA, and MBOSA. The parameters related to individual algorithms are shown in Table 2. These parameters are set according to reported works on feature selection and based on trial and error on small simulations. It is noted that all the algorithms used the same fitness function defined in Equation 17. For each algorithm, population size is set to 20, and stopping criteria for each run is set to 100 iterations. Populations are initialized randomly in each algorithm.
Parameter settings of algorithms
Parameter settings of algorithms
The evaluation of the selected feature subsets by different algorithms is done by classification experiments using Support Vector Machine (SVM) with Linear Kernel [56]. SVM is used in this research because it is one of the widely used learning algorithms that can classify both linear and non-linear data well. 10-fold cross-validation strategy is used to evaluate the classification accuracy of each selected feature subset. After feature subset selection, training sample with selected feature subsets is used for building the SVM model. On the other hand, test samples with selected feature subsets is used for testing the model to calculate classification accuracy.
All algorithms are developed in python 3.7 and executed on an Intel Core i5-9500 machine containing 3.00 GHz CPU, 8 GB RAM, and Windows 10 OS. Finally, the experiment is repeated twenty times to get statistically meaningful results. For each of the algorithms, several evaluation measures that are mean classification accuracy, mean number of selected features, mean computational time, and their standard deviation are calculated. Wilcoxon signed-rank test [57] is used to check the significant difference between MBOSA and each of the other algorithms. To further assess the statistical significance of the results of algorithms, Friedman test [58] and Nemenyi post-hoc test [59] are carried out.
Simulation results and discussion
Table 3 shows the average classification accuracy (Avg.) and standard deviation (std.) of BBA, BPSO, BGA, BOSA and MBOSA on twenty datasets. The best result is highlighted in bold text. According to the accuracy of the classification results, MBOSA has the best performance where it achieves the best results for half of the datasets. A relatively low standard deviation of accuracy results of MBOSA indicates its less variation of classification accuracy in different run. The second best algorithm after MBOSA is BGA that produces best results for six datasets. Compared to MBOSA, BBA obtains best classification accuracy on five datasets (Cnae, Libras-move, Ionosphere, Lung-cancer, Parkinson). When MBOSA is considered for comparison with BOSA, for three datasets (Breast-w, Cnae, Vehicle) BOSA produces better average classification accuracy than MBOSA. Furthermore, MBOSA attains better classification accuracy compared to BPSO on all datasets except for Hepatitis.
Average classification accuracy and standard deviation (std.) of different methods
Average classification accuracy and standard deviation (std.) of different methods
Table 4 shows the average number of selected features (cardinality of the final feature subset) and standard deviation values for BBA, BPSO, BGA, BOSA, and MBOSA on twenty datasets. The best result is highlighted in bold text. It is noticed that MBOSA selects fewer features compared to other algorithms for almost all cases (18 out of 20). MBOSA outperforms BGA and BOSA in terms of feature reduction for all datasets, whereas BBA has the minimum number of features compared to MBOSA only for two cases (MiceProtein and Pendigits datasets). Compared with MBOSA, BPSO can provide better reduction on only Pendigits dataset. It is found that BGA is not as successful as MBOSA regarding reducing feature size. For large datasets such as Cnae, Colon, Waveform, and Micro-mass, MBOSA outperforms other methods notably in terms of feature reduction.
Average number of selected features and standard deviation (std.) of different methods
Fig. 3 presents the comparison of the proposed MBOSA with other approaches regarding average feature selection ratio. Feature selection ratio is defined as the ratio of the number of selected features and the total number of features and is expressed in percentage. MBOSA select less than 60% feature for 18 datasets and for some datasets it can even achieve less than 40% feature. It is also observed that MBOSA is the most effective in feature reduction as minimum feature selection ratio values are obtained by MBOSA for almost all datasets.
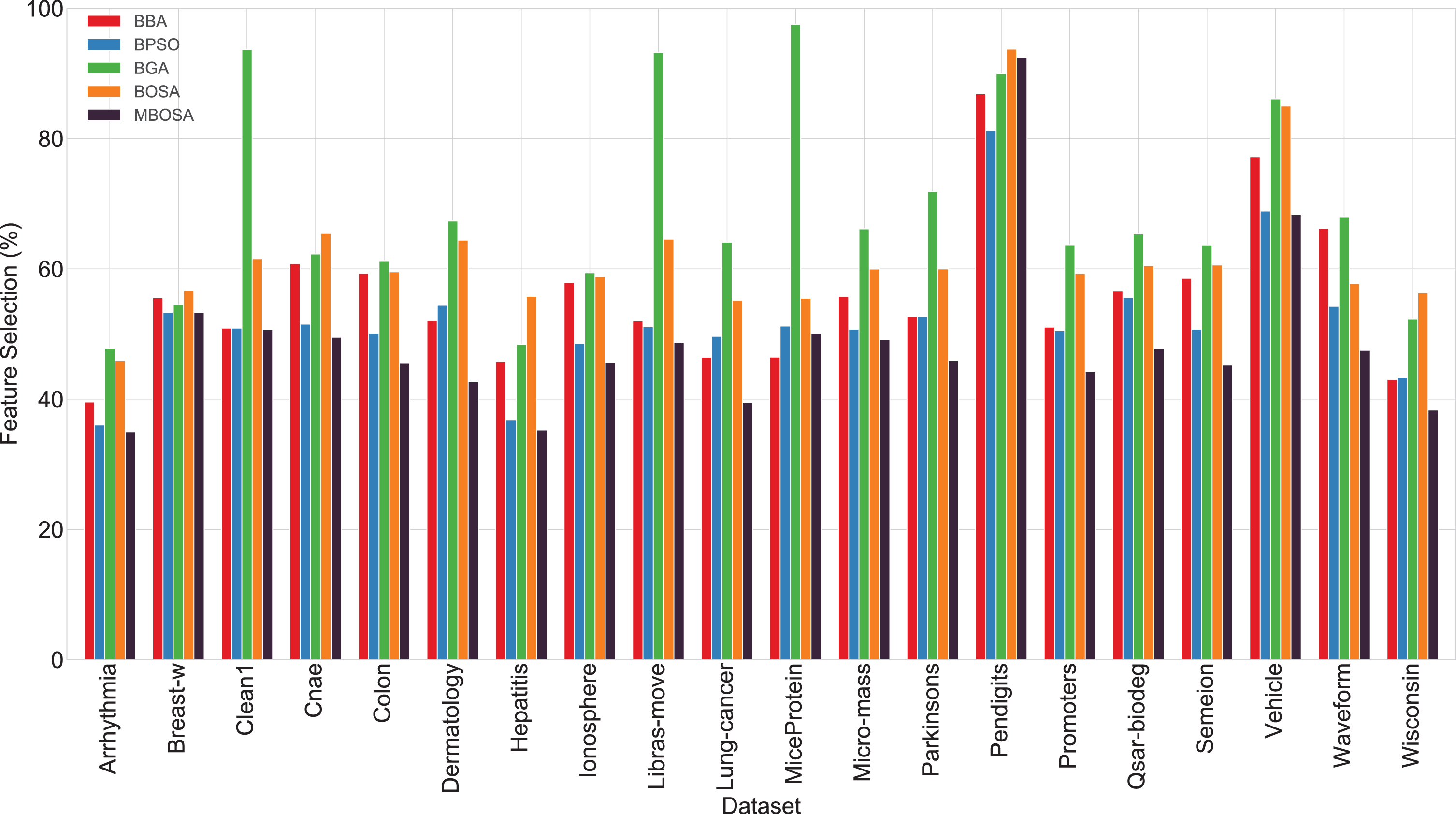
Average selection ratio of feature obtained with BBA, BPSO, BGA, BOSA, and MBOSA.
Fig. 4 displays the average computational time for all the feature selection techniques employed in this research. In general, datasets containing a large number of features or instances take a longer time irrespective of approaches. MBOSA takes less CPU time than BOSA for the majority of the datasets (15 datasets out of 20). Rest of the five datasets where MBOSA takes more computational time than BOSA selects a smaller number of features. When compared with all other approaches, the proposed approach takes lesser time for 60% datasets. A notable characteristic is that in term of CPU time, MBOSA performs better than other algorithms for datasets with large number of instances (Cnae, Semeion, mice-protein, Waveform, Pendigits). MBOSA is also faster than BGA for 13 out of 20 datasets. However, it is noticed that MBOSA may not exhibit the best CPU time for some high dimensional datasets.
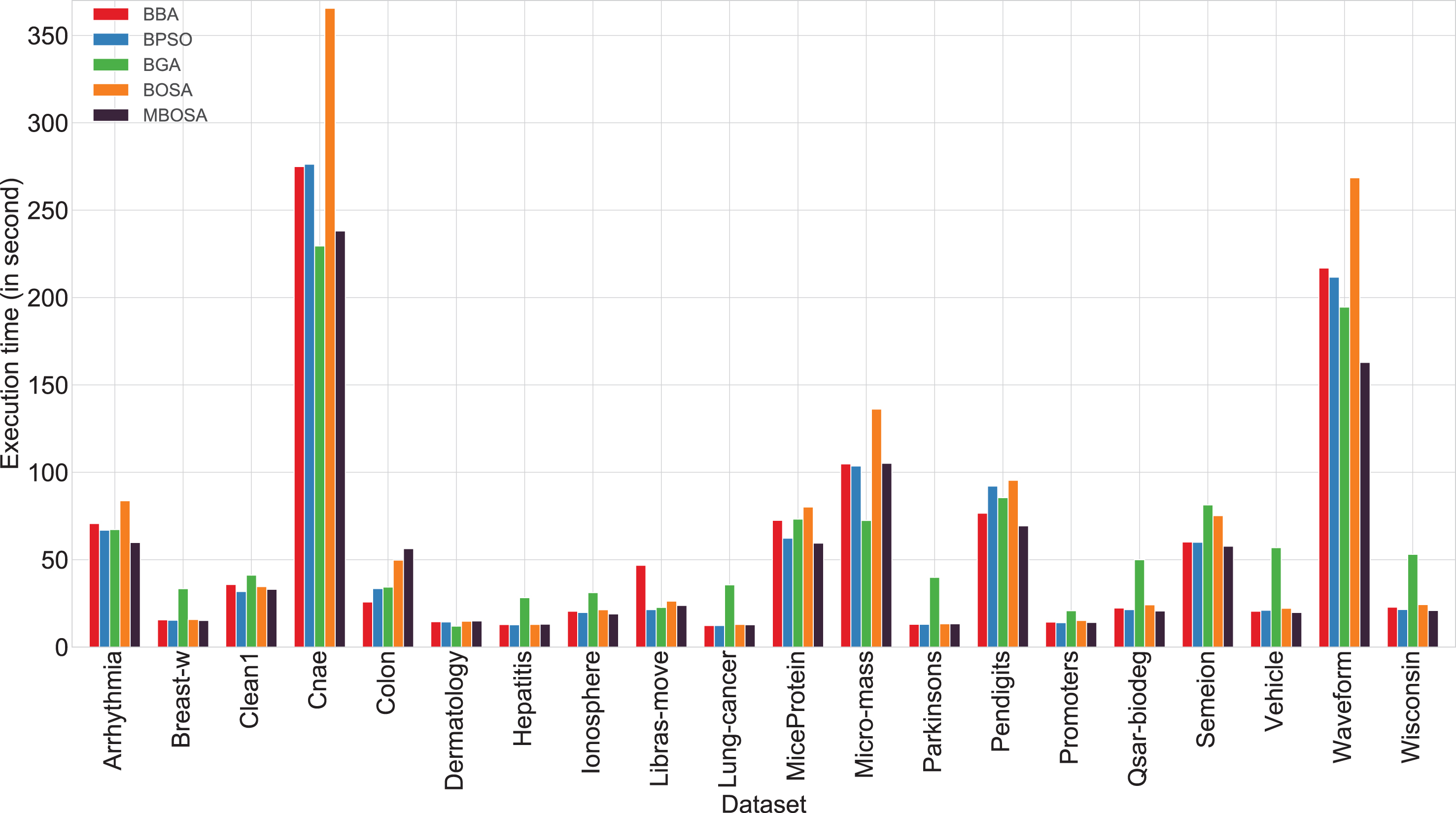
Average computational time obtained with BBA, BPSO, BGA, BOSA, and MBOSA.
Fig. 5 presents the overall classification accuracy of each method by averaging the accuracy values over all datasets. From this bar chart, it can be remarked that MBOSA performs better in terms of accuracy. On the other hand, Fig. 6 shows the mean feature selection ratio of the algorithms according to the average of the feature selection ratio over the datasets. Results show that MBOSA performs better than others with respect to feature reduction and classification accuracy.
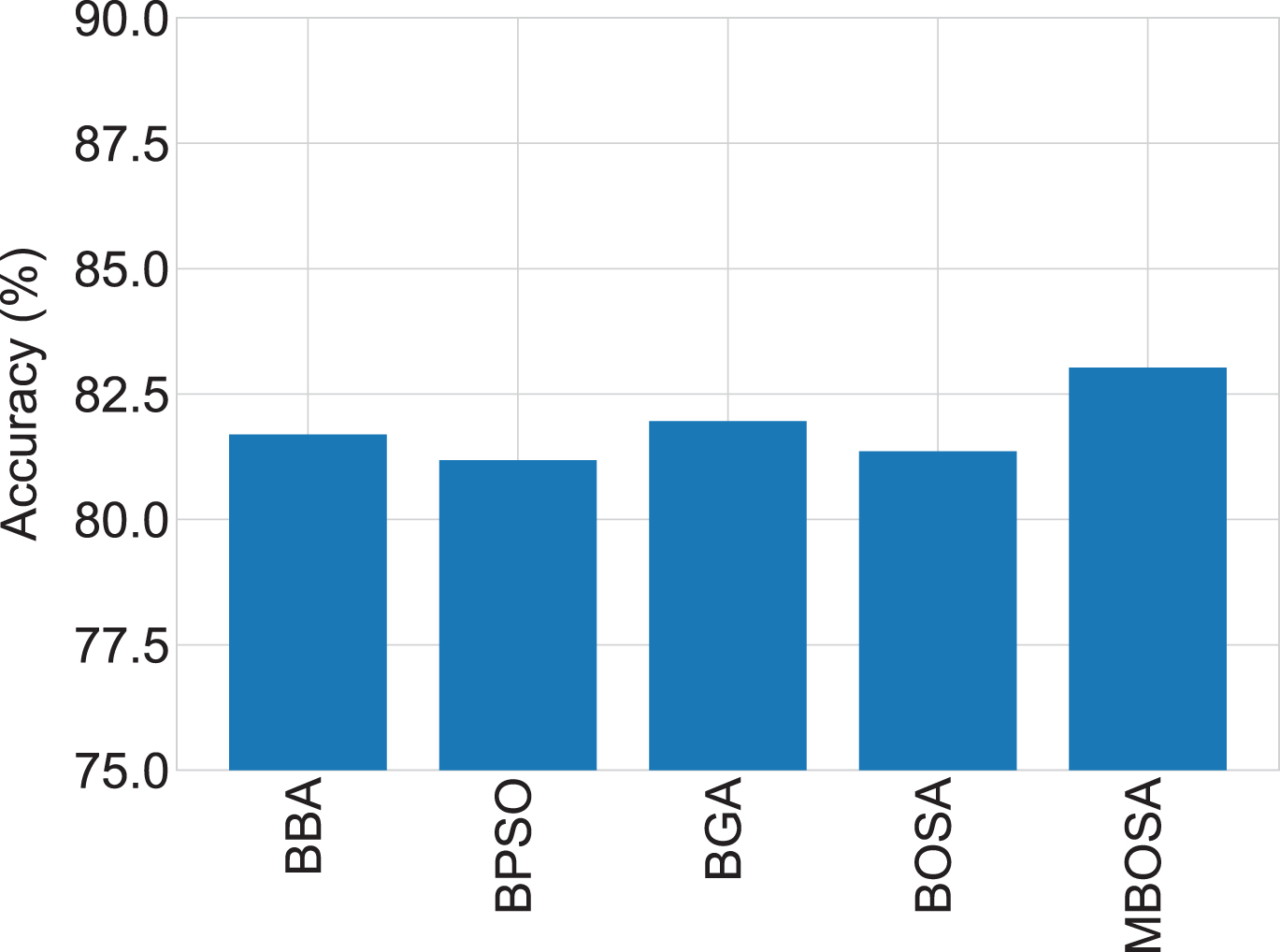
Overall comparison of methods in respect of average classification accuracy.
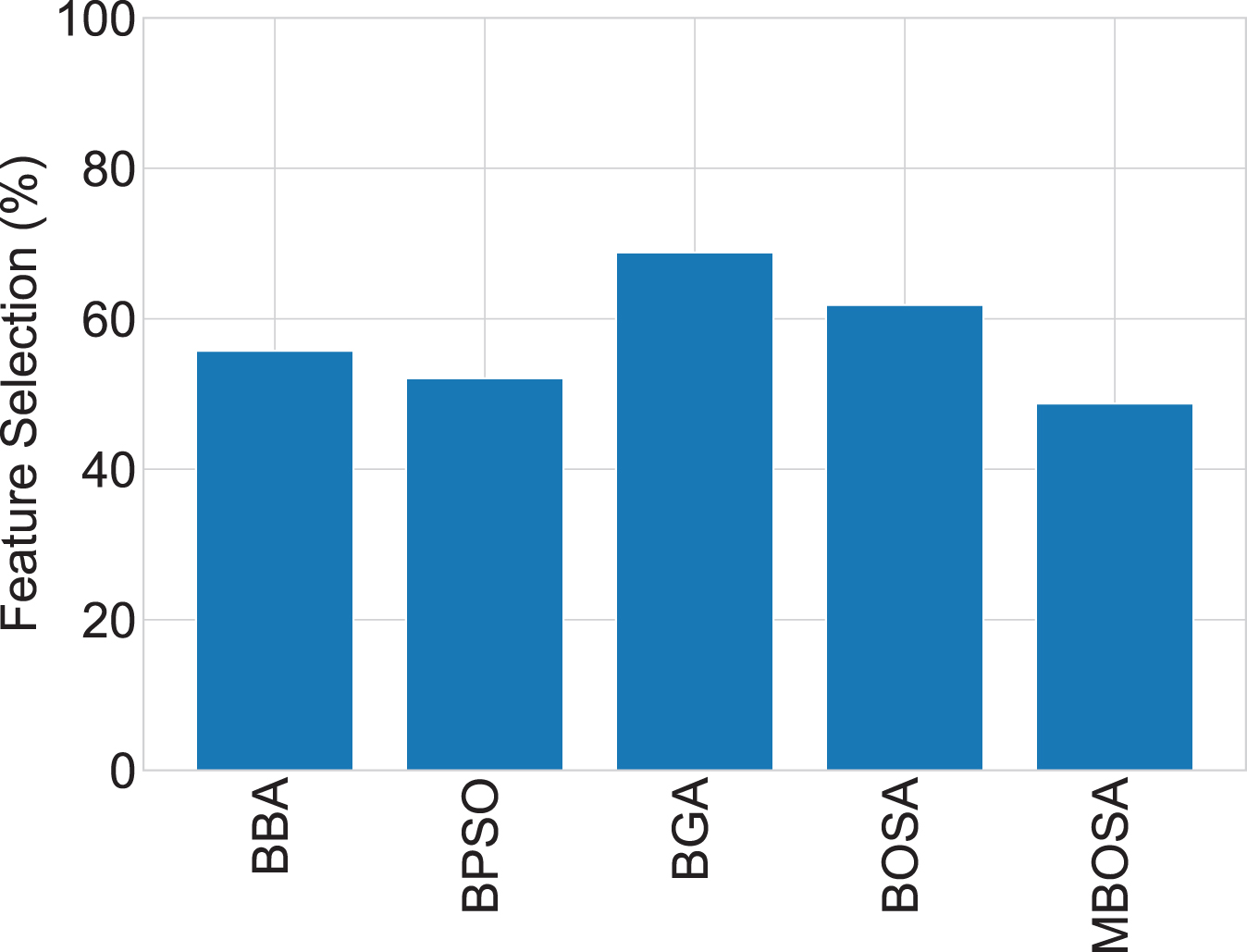
Overall comparison of methods in respect of average feature selection ration.
To determine whether the difference between the proposed MBOSA and each of the four approaches is statistically significant, a two-sided Wilcoxon signed-rank test with a confidence level of 0.05 has been performed. The null hypothesis is that there is no significant difference between the two approaches, whereas the alternative hypothesis states two approaches are different. When p-values are lower than the confidence level of 0.05, the null hypothesis is rejected, and the alternative one is accepted. Table 5 shows the p-values of Wilcoxon signed-rank test when MBOSA is compared against other approaches in terms of classification accuracy and the number of selected features. Non-significant values are highlighted with bold. Besides, during the comparison between two approaches, a number of cases where the proposed approach wins (W), draws (D), or loses (L) over other are also reported in the table.
p values of Wilcoxon signed-rank test results computed between MBOSA and other approaches for classification and number of feature selection.(p > =0.05 are bold).
Results indicate that MBOSA shows significantly better classification accuracy than BOSA and BPSO for the majority of the datasets (wins over 11 datasets). The difference between MBOSA and BBA is significant in 9 out of 20 datasets. However, compared to BGA, MBOSA shows significantly better classification accuracy only in 6 out of 20 datasets and significantly inferior in 1 dataset. On the other hand, results are not significant for 13 datasets.
According to the p values of Table 5 regarding the number of selected features, it is noticed that the most meaningful difference exists between MBOSA and BGA because significant results have been obtained for almost all the datasets, with BGA being significant for two cases. Similarly, a significant difference is also found between MBOSA and BOSA for 17 out of 20 datasets. MBOSA also wins over BBA for 50% of the datasets in terms of the number of selected features. Compared to BPSO, MBOSA wins over nine datasets. MBOSA reduces the number of features significantly than BGA, while it produces competitive classification accuracy. It can be concluded that the proposed approach has a good ability to reduce the number of features as well as to maintain reasonable classification accuracy.
To evaluate whether the differences among the algorithms regarding classification accuracy and the number of selected features of the datasets are significant, we use Friedman test and Nemenyi post-hoc procedure at a confidence level of α = 0.05. Friedman test result shows that statistically significant differences exist among the algorithms in terms of classification accuracy and feature selection results (i.e. p < 0.05 for both cases). Table 6 shows average Friedman mean ranks of the approaches and MBOSA obtains the best mean ranks among the approaches in both accuracy and feature selection. Pair-wise comparison of algorithms with Nemenyi test is shown in Fig. 7. A significant difference between the two algorithms exists when the distance between their average ranks is more than critical distance (CD). Algorithms without significantly different are connected to each other with a straight line. From Fig. 7a, it is observed that there is a significant difference between MBOSA and each of BBA, BOSA, and BPSO regarding accuracy measure. On the other hand, in Fig. 7b, a significant difference between MBOSA and each of BBA, BOSA, and GA are seen when the number of selected features are considered.
Friedman mean ranks for data sets.
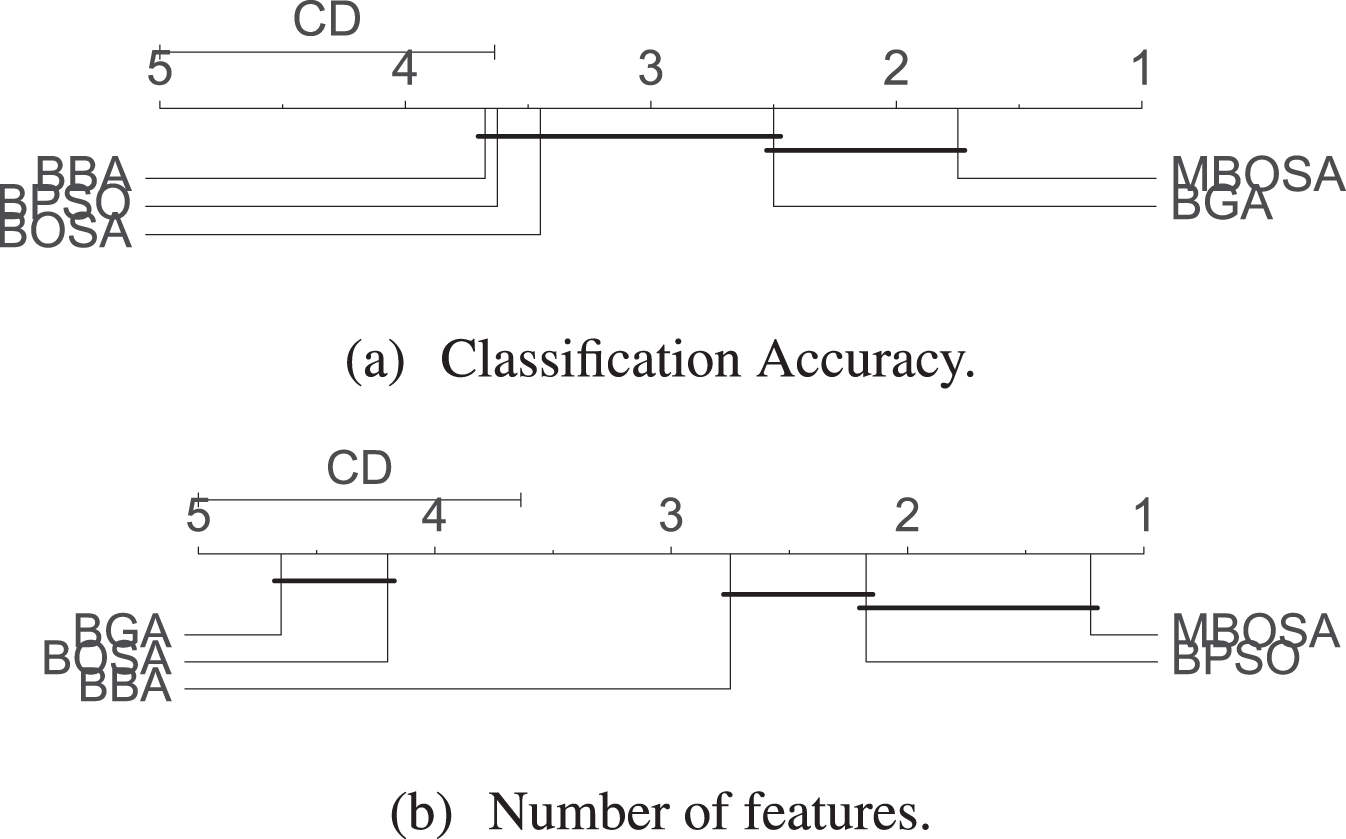
Nemenyi’s post-hoc test.
Based on the above empirical study on benchmark datasets, it is found that for high dimensional data, MBOSA results in a lower number of features with relatively better computational accuracy, though in some cases, it takes a longer time. BGA produces better classification accuracy with less computational time in high dimensional datasets, but it can not reduce the number of features greatly. MBOSA performs better than BOSA in all of the three metrics of accuracy, feature reduction, and CPU time. On the other hand, the nearest competitor of MBOSA is BPSO and BBA based upon these metrics.
Overall, with a few exceptions, the proposed feature selection approach is superior to other approaches in the reduction of the number of features and improvement of classification accuracy. This is due to mutation, adaptive, and elitism strategies of MBOSA, which result in several benefits. Elitism promotes better candidate solutions to the next generation in order to improve the convergence of the search. If the premature convergence problem is detected during the search, the mutation strategy is incorporated for diversifying the solution away from the local optimum. Along with the mutation strategy, the parameter β is self-adaptively adjusted, and this adaptive behavior also assists in avoiding early convergence. Another merit is that parameter β is initialized dynamically before the iteration begins, unlike the difficult parameter adjusting in many meta-heuristic approaches. Therefore, the proposed approach has the ability to find out the near-optimal solution by balancing exploration and exploitation.
Conclusions
In this work, an improved version of Binary Owl Search Algorithm, named MBOSA, has been developed for feature subset selection problem in pattern classification. To avoid premature convergence and improve the search direction toward global best solution(s), three main strategies which include self-adaptive parameter tuning, mutation, and elitism are incorporated with BOSA. The proposed approach is evaluated over 20 benchmark datasets from UCI, and the performances are compared with other popular metaheuristic algorithms, namely BBA, BPSO, BGA, and BOSA. Three evaluation criteria including classification accuracy, fitness value, number of selected features are considered for comparison among the methods. For all the algorithms, DT classifier served as a part of fitness function during feature subset selection, and SVM is used for the final classification accuracy.
The experimental results show that, compared to other approaches, MBOSA can produce the best classification accuracy for 50% of the datasets, with most of the cases containing small standard deviations. It is also apparent that MBOSA can select the fewest number of features in most of the datasets (18 out of 20). Also, the feature selection ratio of our proposed method is less than 60% in most of the datasets. Although six cases MBOSA has significantly better classification accuracy than BGA, it achieves significantly better feature reduction over BGA in almost all cases. During feature selection, MBOSA also performs significantly better than BOSA for most of the cases. While comparing the number of selected features and classification accuracy, MBOSA shows significantly better performance than BBA, BPSO, BGA around at least 50% of datasets. In the case of CPU time, MBOSA also outperforms the other methods for the majority of the datasets, especially datasets having large number of instances. In general, the proposed approach can reduce the number of features while providing decent classification accuracy, and thus it can be considered worthy of being a powerful feature subset selection tool.
In future, MBOSA can be combined with other wrapper-based approaches including, Naive bays classification (NB), K-nearest neighbor classifier (KNN), and SVM for further extension. Also, the proposed approach can be used in solving more large scale datasets of real-world applications, such as text mining, feature selection in genomic microarray data.