
Abstract
Image retrieval with relevant feedback on large and high-dimensional image databases is a challenging task. In this paper, we propose an image retrieval method, called BCFIR (Binary Codes for Fast Image Retrieval). BCFIR utilizes sparse discriminant analysis to select the most important original feature set, and solve the small class problem in the relevance feedback. Besides, to increase the retrieval performance on large-scale image databases, in addition to BCFIR mapping real-valued features to short binary codes, it also applies a bagging learning strategy to improve the ability general capabilities of autoencoders. In addition, our proposed method also takes advantage of both labeled and unlabeled samples to improve the retrieval precision. The experimental results on three databases demonstrate that the proposed method obtains competitive precision compared with other state-of-the-art image retrieval methods.
Introduction
Content-based image retrieval (CBIR) with relevant feedback has been an active area of research over the past decade [6, 16, 37, 45, 46, 48]. Measuring the similarity between two images by Euclidean distance in multi-dimensional space is often ineffective because there exists a semantic gap between the low-level visual features and the high-level semantic concepts of the image. To reduce this semantic gap, the approach is to include classifier machine learning in the retrieval process. In the returned results, this mechanism allows the user to assign positive labels to images that are semantically similar to the query image and also allows the user to assign negative labels to images that are not semantically similar to the query image. These feedback samples are used as the training set for the classifier machine learning technique. Because the number of feedback samples obtained is very small compared to the dimensionality of the feature space of the image data, it is difficult to obtain a good classification learning model. In this situation, people often find ways to reduce the image data dimensionality, which obtains a lower dimensional projection space [22, 24, 29, 39]. In this low-dimensional projection space, machine learning techniques are applied to learn high-level semantic concepts.
Dimensional reduction is one of the most effective techniques for classification machine learning problems on multidimensional data [52, 55]. It is proposed to solve the problem of the “curse of dimensionality” [8], which means that machine learning models cannot perform effectively when dealing with high-dimensional data. Recently, many classification machine learning models have been proposed such as multiple-instance learning [53] and subspace learning. The most well-known projection space learning methods include principal component analysis (PCA) [25] and Linear discriminant analysis (LDA) [13, 40]. PCA learns a projection that can preserve the information of the data, while LDA finds an optimal discriminant projection space such that the ratio of between-class scatters to within-class scatter is maximized. However, if image retrieval relies solely on these approaches, we will encounter two problems: Firstly, the number of dimensions in the projection space is too small, the classification performance on this space will be degraded. Second, we must use an exact nearest neighbor search strategy, which is time consuming and unsuitable for large-scale datasets.
Approximate Nearest Neighbor (ANN) search [2, 23], which attempts to find the nearest neighbor, has been actively studied. It has been successfully applied to many machine learning and data mining problems such as image retrieval [36, 64, 77] and classification (Kulis and et al., 2012; Grauman, 2012). However, efficient ANN search remains challenging in contexts where the data set size is large and the data has high dimensions.
Recently, deep learning has been effectively applied to areas such as computer vision, machine learning, and many other related fields [53, 67]. Deep learning-based hashing methods [33, 63] are also proposed for ANN search. These methods show that deep networks can help learn hash codes more efficiently. Usually, these methods are supervised, which requires a large number of pairwise relations [33] or triplet relations [7]. Then, pairwise or triple loss functions are used to map similar points to similar hash codes in Hamming space and guide the hash function learning process. However, because manual labeling of data is often time-consuming, labor-intensive and costly. Therefore, the main dependence on the availability of many annotated data may hinder the practical application of these methods. To better exploit the available unlabelled data, unsupervised deep hashing methods are proposed. Recent unsupervised deep hashing methods use deep autoencoders to learn hash codes [26, 44]. These methods first map the inputs to hash codes and then attempt to reconstruct the original inputs from the hashes learned at the pixel level. However, since natural images often contain many small variations in position, color, and shape, pixel-level reconstruction can degrade the hash codes learned by focusing on these small changes. Other recent deep hashing methods learn hash codes by maximizing their representation capacity [35] or enforcing similarity between rotated images and their respective original images [34, 35]. However, neither of these methods can capture and preserve semantic similarity between different instances, so it may lose the opportunity to learn more precise hash codes.
The image retrieval problem with relevance feedback has some problems as follows: (1) the number of layers is too small, i.e. only two layers, so the number of projection directions must be small because the number of dimensions is closely related to the number of layers, (2) the performance of the retrieval algorithm is low on large-scale datasets, and (3) the number of user’s feedbacks is often too small compared to the dimension of the feature space [30]. Motivated by the above observations, we propose a new semi-supervised image retrieval method, called Binary Codes for Fast Image Retrieval (BCFIR). BCFIR has the following characteristics.
Take advantage of sparse discriminant analysis to determine the most important original feature set and avoid having to solve the NP-Hard optimization problem on discrete space, but still solve the small-class size problem in the retrieval with relevance feedback. Increase retrieval performance on large-scale datasets: First, map real-valued features to short binary codes for fast and suitable retrieval of large-scale datasets. Then, enhance the generalizability of deep autoencoders through a bagging learning strategy. Leverage both labeled and unlabeled samples to solve the small sample size problem in a retrieval problem with relevance feedback.
The remainder of this paper is organized as follows. In Section 2, a number of related works are presented. Section 3 will introduce our proposed method BCFIR. The experimental results on three data sets are described in Section 4. Finally, conclusions are made in Section 5.
In this section, we first introduce some norms used in this paper. Then we briefly review the related works.
Given a matrix
For a vector
Some related works:
From the perspective of information reconstruction and preservation, the PCA approach is widely used as a data preprocessing tool for data analysis [14, 62]. Locality preserving projection [18], neighborhood preserving embedding [19], and sparsity preserving projections [43] are the most common feature extraction methods, which learn projections from different geometric structures of the original data. These methods get some good results in feature extraction, but feature vectors extracted from these methods do not have discriminative information so they are not suitable for classification [42].
LDA learns a discriminant projection to improve classification precision. Many improved methods of LDA have been proposed to improve the classification precision. Some of the improvement methods include uncorrelated LDA [66], two-dimensional linear discriminant analysis [61], and orthogonal LDA [65], which solve the small sample size problem of naive LDA. For data of non-Gaussian distribution, LDA does not handle well, so some suggested improved LDA methods include: manifold partition discriminant analysis [76], discriminative locality alignment [70], and Marginal Fisher analysis [60]. However, the LDA and LDA improvement methods mentioned above, which compute the scatter matrixes by the
Image data, in the image retrieval problem with relevance feedback, has many redundant and irrelevant features. These features reduce the performance of the classification model [28]. To eliminate redundant and irrelevant features, and select important features, the sparse constraint is used in projection space learning methods. Some typical methods of sparse constraint include sparse uncorrelated linear discriminant analysis [72], sparse linear discriminant analysis [42], and sparse discriminant analysis [5]. These methods extract features through learning a sparse discriminant projection space. The techniques for selecting features by sparse attributes through the
Autoencoders are developed to learn efficient features for content representation of images (Feng et al., 2015). It exploits a neural network to learn the representations of a given sample in such a way that the reconstruction error is minimized. Feature learning with unsupervised learning algorithms to reconstruct input patterns based on predefined rules. Autoencoder [47] can learn representative features to reconstruct input samples with minimal reconstruction error. Autoencoders are utilized to combine audio and lyrics for music mood classification [59]. Autoencoders and their variants have also been applied to multimodal representation learning [1, 4]. The authors in (Feng et al., 2015) proposed an autoencoder network to learn the hidden representation between textual and visual content, minimizing the correlation error between the hidden representations of the two methods. The authors in [17, 38] took advantage of a denoising autoencoder to learn representative features in an unsupervised manner and applied it to training dominant detection models from raw image data.
The proposed image retrieval method
In this section, we first present the proposed image retrieval model. Feature selection and performance improvement techniques are presented shortly afterwards. At last, an efficient master algorithm was designed to solve the image retrieval problem with relevant feedback.
Model of the proposed method
This section presents the proposed image retrieval model with a detailed analysis.
Model of the proposed image retrieval approach.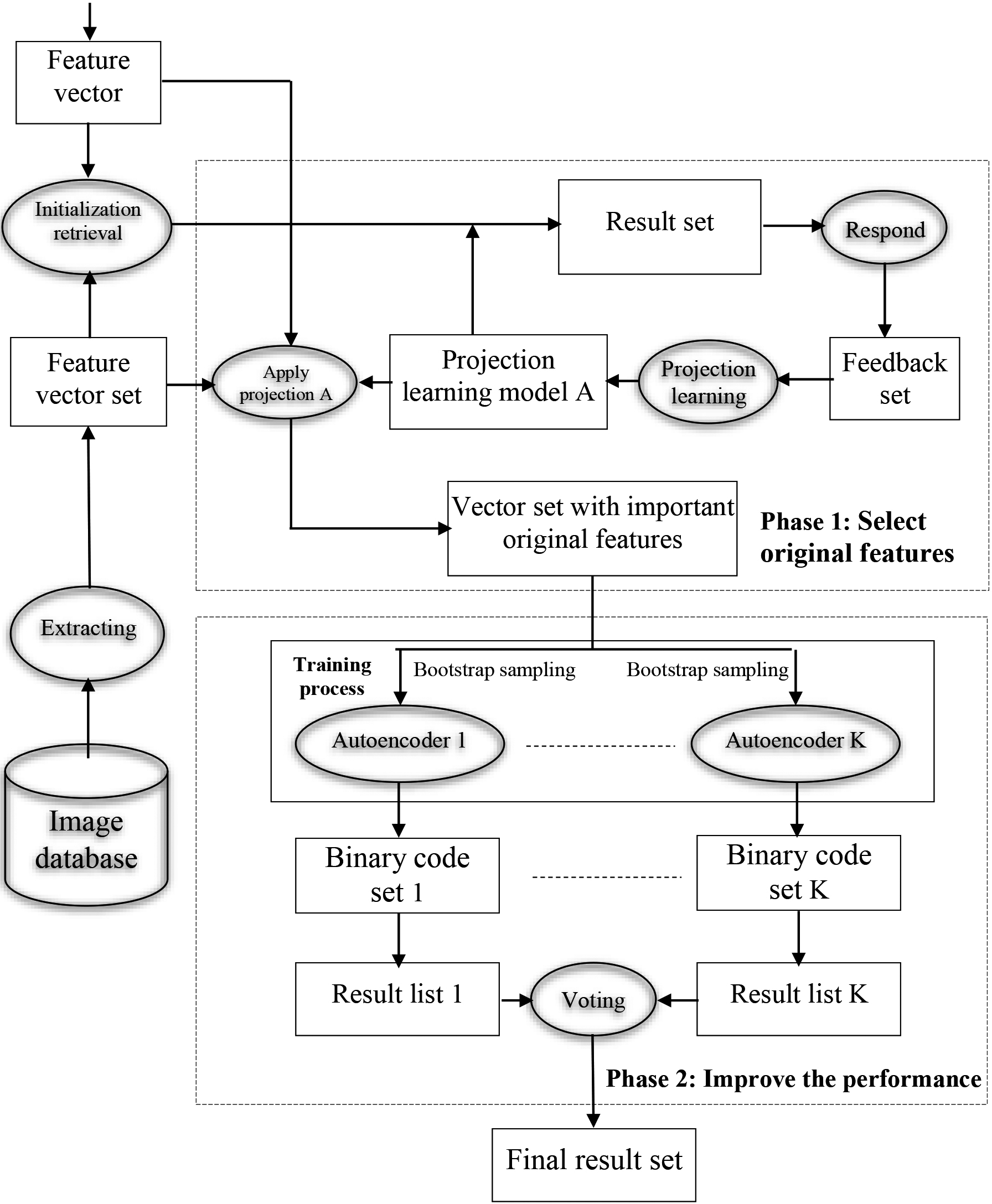
From the perspective of data flow, our proposed image retrieval method is described as shown in Fig. 1. The retrieval process begins by extracting the features of the query image. The features of the database images are pre-extracted according to some defined feature extraction procedure. Using these feature vectors together with a predefined image similarity measure (at the initial retrieval, the similarity measure is the Euclidean distance), the similarity between the query image and the database images is evaluated. Then, a set of images that are neighboring to the query image (At the initial retrieval, the set of neighboring images consists of images whose euclidean distance to the query image is below a given threshold) is selected and this set is sorted in descending order of similarity to obtain the result set. Our model is divided into two main phases corresponding to two dashed rectangles surrounded: Phase 1: Choose original features and Phase 2: Improve the performance.
With stage (1), the user responds on the retrieval result set to get the feedback set. This feedback set is also a training set, where the samples that are similar to the query image are considered positive, and the remaining samples (samples that are not similar to the query image) are negative. Based on this training set, the projection learning algorithm is performed to obtain the projection learning model A. This process continues until the user stops responding. Using projection learning model A on the feature vector set of the database image set, we obtain a set of vectors with important original features (this is also the output of Phase 1). It should also be noted here that, Phase 1 of our proposed model only returns the important features on the original feature space, but not the important features in the projection space (the meaning here is to avoid small-class size problem).
In the training process of Phase 2, we randomly select a subset of L feature vectors from the set of vectors that are the output of Phase 1 (note here that the samples in this subset are unlabeled). This subset will be used to train K deep autoencoders. During the training of deep autoencoders, we bootstrap the training set to train the corresponding K deep autoencoders.
After training K deep autoencoders, the candidates belonging to the database image set are passed through K deep autoencoders to obtain K sets of binary codes and then K result lists. An average voting mechanism is implemented to determine the similarity of each candidate. Next, we sort the candidates in descending order of similarity to get the final result set.
In the next section, we will focus on presenting the two main components of the model, which are “Select original features” and “Improve the performance”.
The goal of this section is to reduce the data dimension but still solve the small-class size problem. In this section, we first introduce the
A feature can be relevant, irrelevant, and redundant. The irrelevant and redundant features, which are taken into consideration during the classification process, can reduce the classification performance. The dimensionality of image data is often very high and often includes many redundant and irrelevant features [11]. Therefore, eliminating redundant and irrelevant features will simultaneously reduce the time and improve the precision for classification. This also improves the precision and reduces the retrieval time because the classification process is an important component of the image retrieval system.
We should note here that feature selection on the original feature space is an NP-Hard optimization problem on discrete spaces. To avoid facing the NP-Hard optimization problem, we reduce the optimization problem on the discrete space to the optimization problem on the continuous feature space, that is, we follow the transform-based dimensionality reduction approach [69].
Let
A feature selection method can be obtained by minimizing the
Feature extraction by imposing
First, we compute the matrix
Next, we solve the following optimization problem.
Here
The feature extraction method according to the LDA approach has a limitation that is sensitive to the number of selected dimensions, that is, when the number of dimensions
To overcome the above very small-class size problem, we propose a projection learning model for selecting the important feature set on the original space, specifically as follows. We first learn a projection matrix
Assume that we have the following data matrix
Suppose that after calculation, we have
The projection learning algorithm for selecting the set of vectors with important features is summarized in Algorithm 1.
Computational complexity
In Algorithm 1, Step 2 has the highest computational cost. In this step, the computational cost is to solve the Eq. (4). The computational cost (Wen et al., 2018) to find the solution of Eq. (4) is
In Section 2.2, we have obtained a set of vectors with important features. Although redundant and irrelevant features have been removed, the cost of image retrieval is still very high, which is not suitable for searching in a large-scale dataset. The reason for this is that because the remaining features have real values, it must use a traditional linear search (or exhaustive search) strategy. The following sections demonstrate how to achieve the goal of improving image retrieval speed and precision on large-scale datasets.
Speed up image retrieval process
Autoencoder can adaptively learn the structure of data and efficiently represent the data. The output of the autoencoders is converted to low-dimensional binary codes, which are well suited for large-scale datasets and data diversity. In addition, autoencoder overcomes poor generalization and expensive design costs.
We convert feature vectors to low-dimensional binary codes. The autoencoder consists of an adaptive multilayer encoding network, which maps high-dimensional data to low-dimensional code, and a similar decoder network, which recovers data from the code. The autoencoder network architecture includes hidden layers for encoders, decoders, and a bottleneck layer. We assume the final output of the bottleneck layer
The entire autoencoder network is trained with gradient descent through minimizing the error between the original data and its reconstructed data. Note here that all unlabeled samples (image database feature vectors) are utilized. That is also why our proposed method is called semi-supervised. As in [26], the entire training process of an autoencoder includes pretraining and fine-tuning. As shown in Fig. 2, during pretraining, we create the encoder network by learning a stack of restricted boltzmann machines (RBM) with standard contrastive divergence specified in [20]. Each RBM has only one hidden layer and it is trained using the hidden activations of the previous RBM as input. By stacking RBMs, we can obtain better initialization weights for gradient descent. We then unroll the encoder network to generate an autoEncoder, which is initialized with the weights from the stacked RBMs and fine-tuned by reconstruction errors via backpropagation. We train the autoencoders on a subset of size L (in our experimental case we choose L
Proposed deep autoencoder model.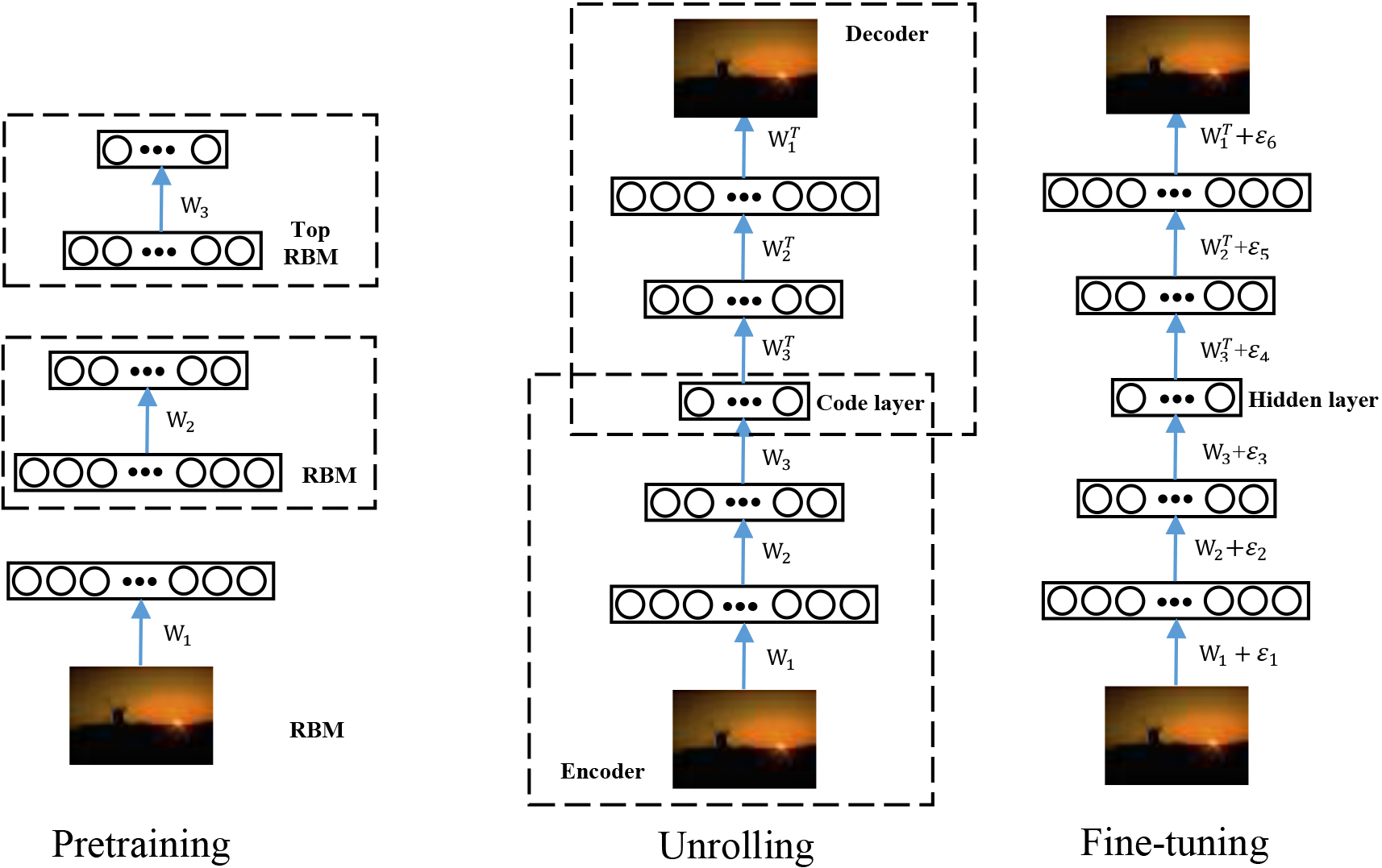
Improve precision of image retrieval
As tested in [68], neural networks are unstable models, and shuffling the training set can cause significant changes in the built model, especially when the distribution of samples is uneven. Bagging is an effective associative learning strategy for improving unstable predictive models. In our method, many new training sets are generated through bootstrap cloning of the original training set and each of them is used to train a corresponding autoEncoder. By reselecting the training set, bagging increases the differences in the integration of different autoencoders. This enhances the generalizability of autoencoders. So we can get multiple descriptions for each object with these autoencoders. We can compute multiple similarity for each pair of objects and obtain a lookup result set by ranking the average measure values. Training many autoencoders will take a long time, but our method uses bagging, which can compute in parallel, so efficiency is still guaranteed.
The K deep autoencoders training algorithm is summarized in Algorithm 2.
This section presents the overall algorithm for image retrieval. This overall algorithm calls Algorithm 1 to generate a set of vectors with important features, i.e. each feature vector includes important features on the original feature space of the image database. On this set, the overall algorithm randomly selects a subset including L candidates to train K deep autoencoders by calling Algorithm 2.
To improve precision, in addition to using bagging autoencoder strategy in algorithm 2, here we will use coarse-to-fine retrieval strategy. In this strategy, we first find a set of candidate images based on a quick comparison of binary compact codes over the Hamming distance. Then, on the list of candidate images, we filter out the images based on comparing the real value vectors (output of Phase 1) by Euclidean distance.
The proposed image retrieval algorithm is summarized in Algorithm 3.
Experimental results
In this section, we present experiments to evaluate the performance of our proposed image retrieval method. The first experiment reports the comparisons of our proposed method with typical image retrieval methods. This is to show that the proposed method has higher overall precision than the other methods. The second experiment tests the average execution time of the proposed method. The third experiment is to consider the efficiency when removing redundant and irrelevant features. The last experiment is to demonstrate the effectiveness of the method in solving the very small-class size problem in image retrieval with relevant feedback. The final experiment on the large-scale datasets is to demonstrate the precision and speed of the proposed method.
In the original feature space, the Euclidean Distance, which is between the query image and the database image, is used in calculating the precision of the Baseline method and the initial retrieval stage.
Image database
Corel Image Database
The Corel photo gallery is an image database that has been widely used to evaluate the performance of CBIR systems [48, 71]. Therefore, we use this dataset to perform an empirical evaluation of our proposed method. Based on the ground truth, the images that are not suitable for image retrieval in the Corel photo gallery are removed, we get a Corel image database of 10,800 images with 80 semantic concepts. In this image database, each semantic concept consists of 100 or more images, and the size of each image is 120
Some representative images of 5 semantic concepts in Corel.
Images in an image database are represented by a set of low-level features in 190-dimensional space. Thus, each image is represented by a feature vector consisting of 190 components. Of these 190 components, there are 102 components for color features and 88 components for texture features. With 102 components for color features, it includes 6 components for the color moment, 32 components for color histogram, and 64 components for color correlation. In addition, the 88 components for the texture feature are composed of 48 Gabor components and 40 Wavelet components.
SIMPLIcity Image Database
The SIMPLIcity database consists of 1000 images, which are divided into 10 semantic concepts. The size of each image in this set is 256
Some representative images of five semantic concepts in SIMPLIcity.
The CIFAR-10 dataset
The CIFAR-10 database consists of 60000 images, which are divided into 10 semantic concepts with 6000 images for each semantic concept. The size of each image in this set is 32x32. Figure 5 includes some of the images in this image database.
Some representative images of 5 semantic concepts in CIFAR-10.
In this section, we use the precision and precision-scope curves [21] to evaluate the effectiveness of the image retrieval methods. Where, the scope is the top
Experiment on the overall performance of the proposed method
In this section, to show the precision of the proposed method, we divide the methods used for comparison with our method into two groups: the first comparison group are methods that do not use deep learning; The second group of comparisons are methods that use hashing or that use deep learning. The reason for this grouping is to compare with our proposed method which covers only phase 1 with SVM (called BCFIRPhase1) and our proposed method which includes enough two phases (ie, BCFIR).
The first comparison group includes Baseline, BDA, DSSA, DLRPIR methods. Baseline is an image retrieval method that only uses Euclidean distance to measure the similarity between the query image and the database image. It retrieves the images that are neighboring to the query image based on the Euclidean distance and does not use any learning mechanism in the retrieval process. This method is used to show the effectiveness of relevance feedback in image retrieval. We compare the proposed method with methods BDA [75] and DSSA [73] because they are very popular traditional relevance feedback image retrieval methods. DSSA uses relevant feedback to learn a discriminant projection matrix, which projects data from the original space to the projection space. BDA is an image retrieval scheme with relevance feedback based on discriminant analysis, it reduces the influence of sample imbalance. We also choose DLRPIR for the comparison because it can mitigate the small-class size problem. DLRPIR is an image retrieval method, which uses the same similarity measure and feedback mechanism as our proposed method. What is different from our method is that DLRPIR uses a Discriminative Low-Rank Projection method, called DLRP [29], to project the original data into a projection space. It then performs classification on this projection space to classify the images. The reason we use the DLRPIR method for comparison is because it can mitigate the small-class size problem.
The methods belonging to the second group of comparisons are NSCM (new similarity calculation method) [50], and LSH [2]. We chose the NSCM method for our comparison because it is a method that has state of the art performance. We chose LSH because it is one of the most popular data-independent hashing methods. LSH embeds similar images into similar binary codes with high probabilities.
In the experiment, we set the values of the parameters for the methods of the first group as follows. With DSSA, the number of dimensions of the projection space is 8 because this is its optimal dimension [22]. In DLRP, we set the value of both parameters
4.2.1.1 Results on Corel
Precision test of the proposed method with the first comparison group
After initial retrieval, we get an initial retrieval result set of 100 images. On this set of 100 images, the user response to obtain a feedback set, which consists of positive and negative samples. Next, we apply BDA, DSSA, DLRPIR and BCFIRPhase1 methods to rerank the images in the image database. After ranking the images, we get four sets of search results of the four methods respectively. Figure 6 shows the average precision, at the top 100 images for the first iteration, of the five methods. Here, we give precision for the first loop because in image retrieval with relevance feedback, the first loop is the most important. It is also important to note here that average precision is the average precision of all queries, each of which corresponds to an image in the image database. Taking each of the entire database image set as a query image and then calculating the average precision of all queries will more accurately reflect the performance of the method because it includes very bad queries (returns only a few relevant images).
The results in Fig. 6 show us that the Baseline method gives the lowest precision. The reason for this is that the Baseline method does not have a learning mechanism to reduce the semantic gap between the high-level semantic concept and the low-level visual feature, it only calculates the Euclidean distance between the query image and the database image on 190-dimensional feature space. Regardless of the Baseline method, the precision of the BDA method is the lowest of the four methods. The reason for this is that the projection space of BDA is low discriminant and is greatly affected by the small-class size problem. The precision of the DSSA method is superior to that of BDA because it can find a projection space that is more discriminative than that of BDA. The DLRPIR method gives a higher precision than that of BDA and DSSA because its projection space is less prone to loss of discriminability when the dimensionality is very low, i.e. it reduces the effect of the small-class size problem. The precision of our proposed method is the highest among the four methods because it effectively solves the problem of small-class size, and solves the problem of small sample size.
Table 1 shows the average precision, at the top 100 images for the first iteration, of each of the 20 semantic concepts. It should also be noted here that the precision of a semantic concept here is the average precision of all queries, where each query corresponds to an image in that semantic concept. From Table 1, we see that, in only 3 out of 20 semantic concepts, the precision of our proposed method is lower than the other three methods, while there are up to 17 semantic concepts (the highlights in Table 1), the precision of our method is higher than other methods.
Average precision of 20 semantic concepts of the five methods
Average precision of 20 semantic concepts of the five methods
Average precision of the 5 methods in the top 100.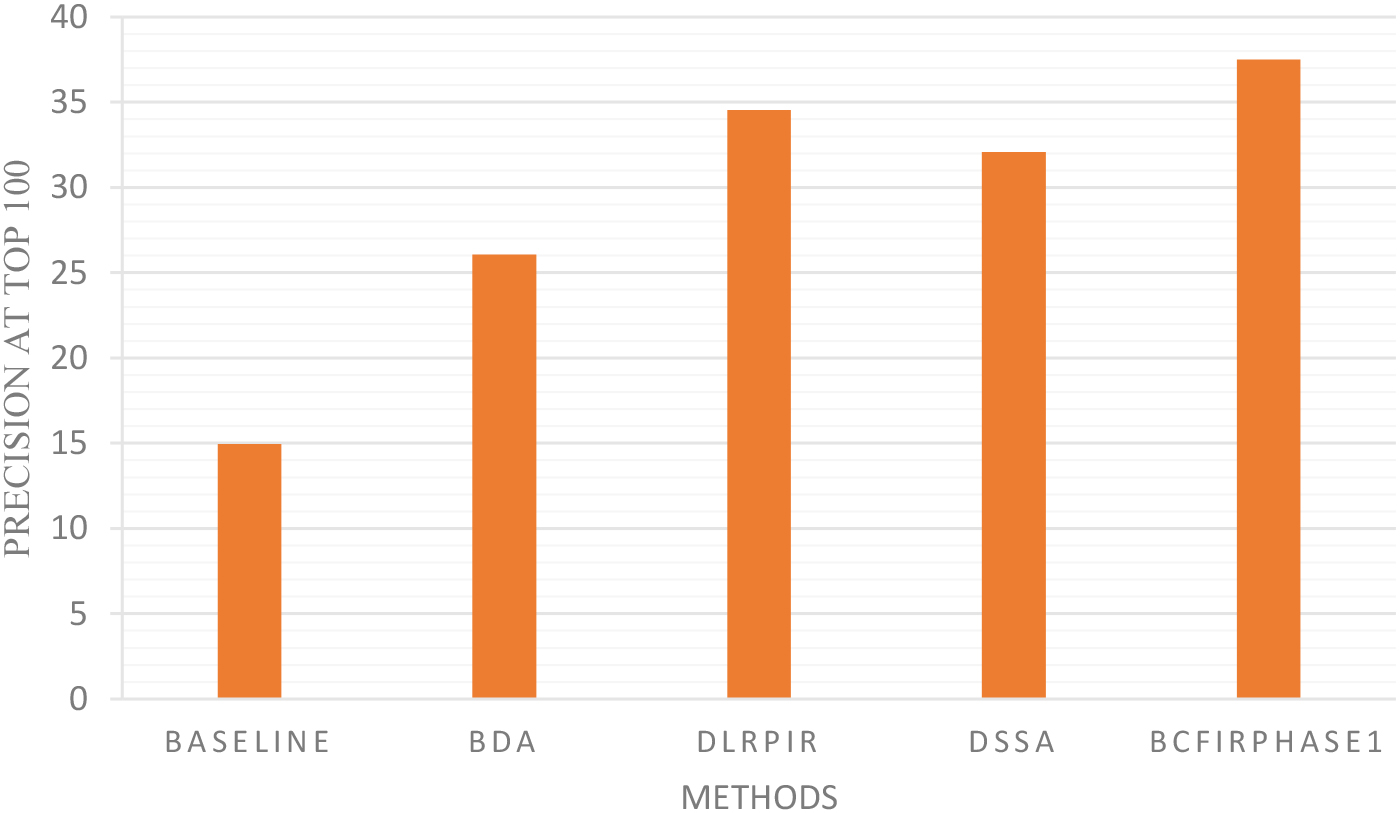
Figure 7 shows the precision-scope curves for the first response iteration. The methods are tested on scopes 20, 40, 60, 80, and 100. According to the scopes, the precision of our method is higher than that of the other four methods. As shown in Fig. 7, the precision of DLRPIR is higher than that of DSSA but its that is lower than our method.
Query processing time test with the first comparison group
This experiment aims to test the query execution time of the proposed method compared to the remaining methods. As shown in Table 2, the average query time for all four methods is fast, which is less than 0.05 s for the first feedback iteration. The average query time of our method is slower than that of the DSSA method and is comparable to that of DLRPIR. The average query time of DSSA is faster than that of our method because DSSA can be obtained the mapping matrix by using the Eigenvalue decomposition. Our method and DLRPIR use the same algorithm to find the projection matrix, so the average query time of our method is equivalent to that of DLRPIR. Average query time in Table 2 made on the computer, configured as 3.1 GHz Dual-Core Intel Core i5 Catalina machine with 8 GB 2133 MHz LPDDR3 memory.
Average time for executing a query
Average precision-scope curves of the different methods.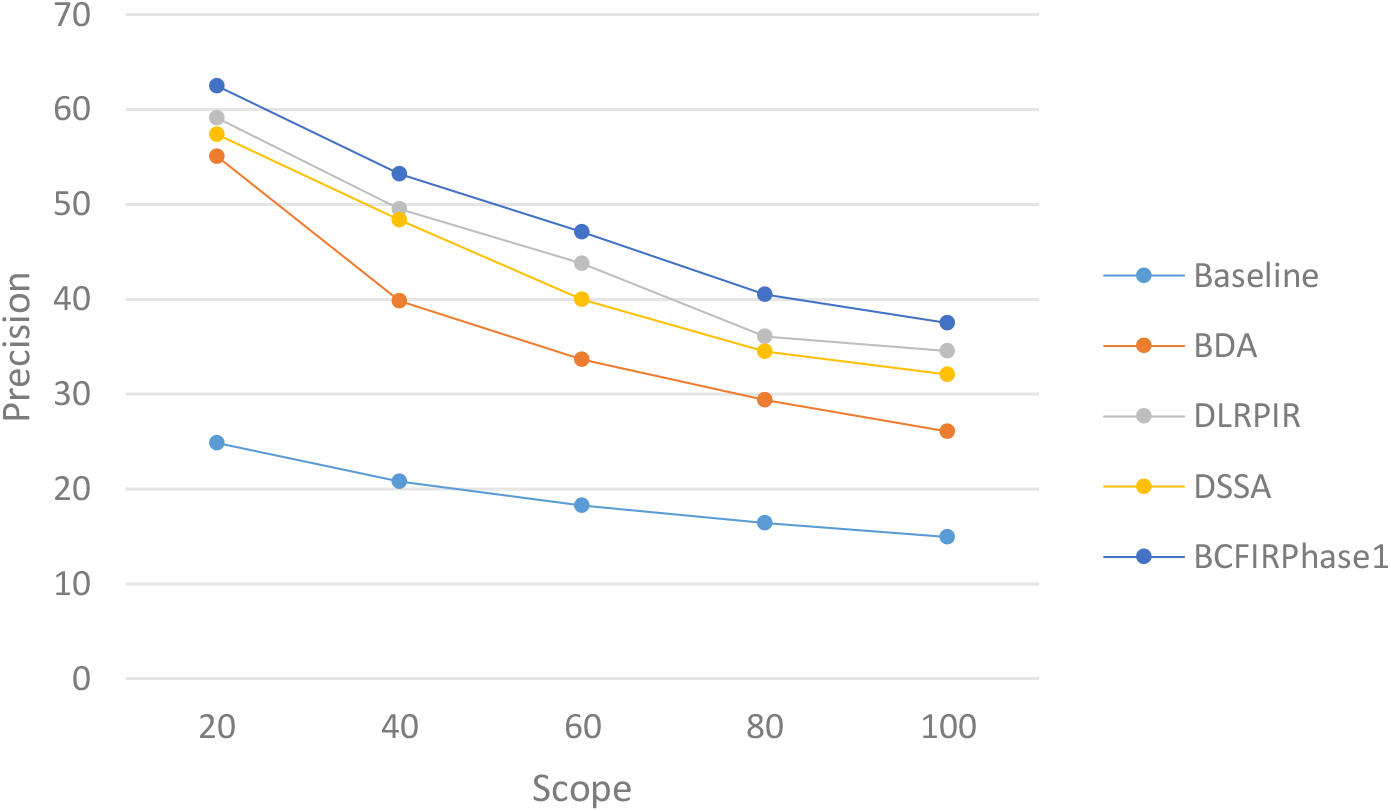
4.2.1.2 Results on the set of SIMPLIcity
This section shows the precision of the proposed method compared with the methods of the first comparison group on the set of SIMPLIcity.
The average precision-scope curves of the BDA, DLRPIR, DSSA, and proposed methods are shown in Fig. 8. Methods are tested on scopes 20, 40, 60, 80, and 100 for the first iteration. According to the results in this figure, the average precision-scope curve of the proposed method is better than the rest.
Thus, on two benchmark data sets, the performance of our method is higher than that of BDA, DLRPIR, and DSSA. This information helps us to confirm that the proposed method is very effective.
Average precision-scope curves of the different methods.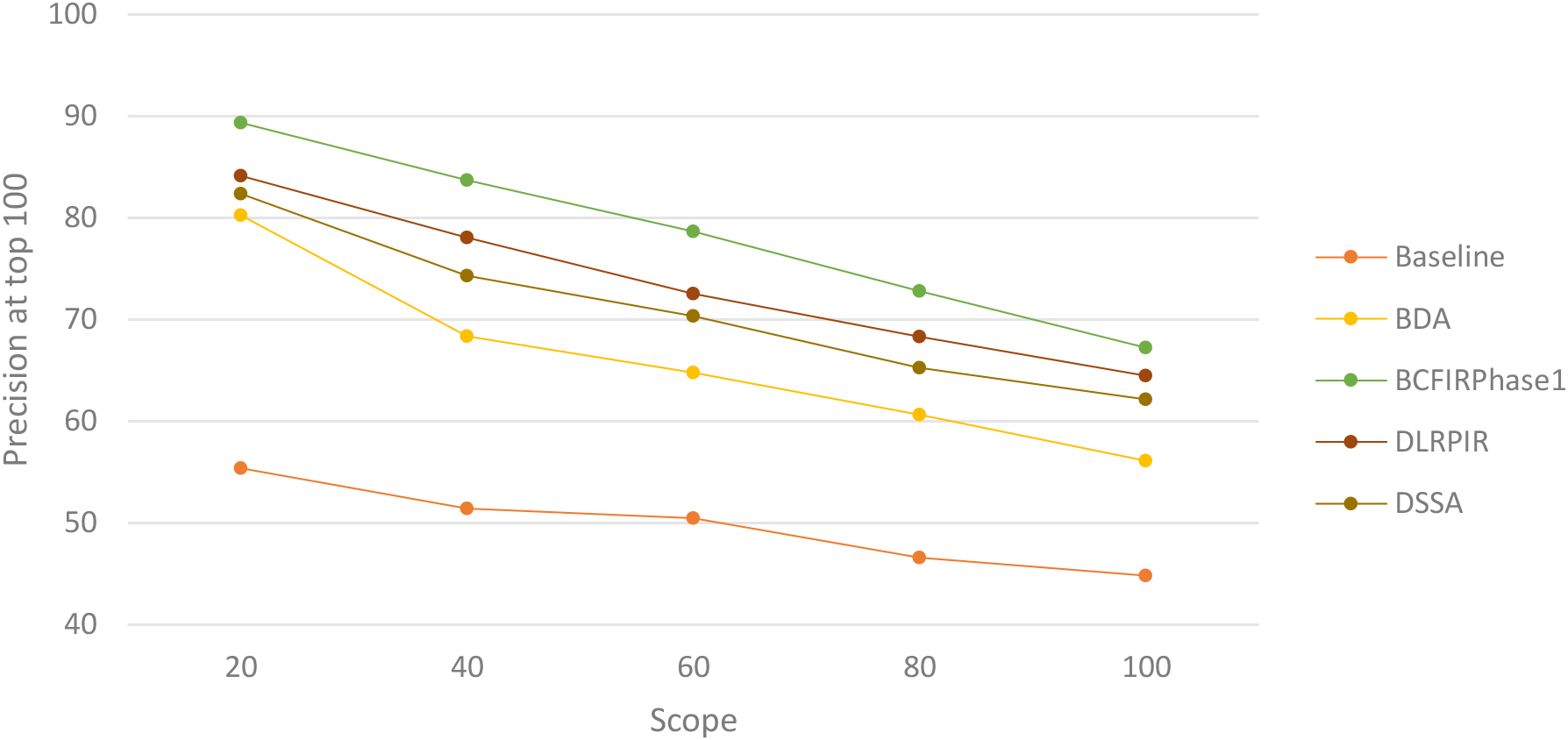
Effectiveness when removing redundant and irrelevant features.
Because the effectiveness of our proposed method relies on removing redundant and irrelevant features, so we show this experimentally in this section. To show that eliminating redundant and irrelevant features is effective for image retrieval with relevance feedback using classification learning, we conduct the test under the following scenario. We build an image retrieval method with relevant feedback using SVM, called SVMRF. The SVMRF method uses the received feedback set to train an SVM model and then uses this SVM model to rank the images to obtain the result set. When applying SVMRF on the original feature space, which consists of 190 dimensions, it is called SVMRF_190. Also SVMRF but applies it an important feature set (the result of Algorithm 1), which consists of 135 dimensions, it is called SVMRF_135. The precision of SVMRF_190 and SVMRF_135 is shown in Fig. 9. It should also be noted here that precision is calculated on the top 100 returned images and for the first iteration. As shown in the figure, although SVMRF_135 has eliminated 55 dimensions, the precision of SVMRF_135 is still higher than that of SVMRF_190. Thus, we can see that the 55 dimensions of the feature space are redundant and irrelevant.
Precision of SVMRF_190 and SVMRF_135.
Results for query image.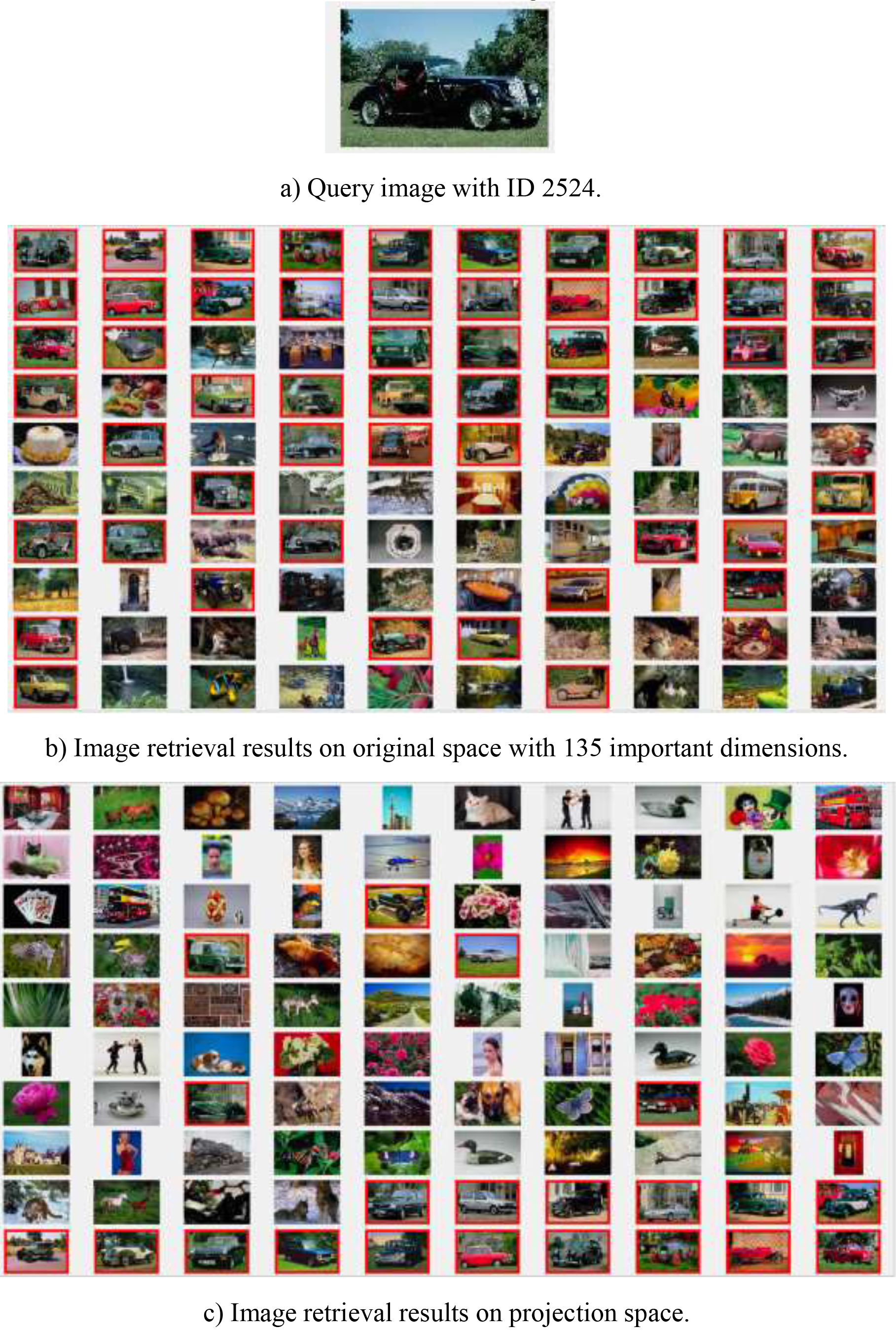
Effectiveness when dealing with small-class size problems.
An important contribution of our proposed method is that it is not affected by the small-class size problem. To illustrate this problem visually, we randomly select an image in the Corel database as the query image, it has ID 2524 and belongs to the concept of “obj_car”. We perform this image retrieval process on the original space with 135 important dimensions and also perform this on the projection space. Figure 10 shows the result with ID 1386, Fig. 10a is the query image ID 2524, Fig. 10b shows the result on the original space, and Fig. 10c shows the result on the projection space. As shown in Fig. 10b, out of 100 returned images, we get 52 relevant images, which rank very high. Figure 10c shows us that, out of the 100 returned images, we get only 21 relevant images, which have low rankings.
Next, we conduct experiments to show the advantages of the proposed method. In the test scenario, our proposed method SDAIR is performed on both the projection space and on the important feature set for comparison purposes. BCFIRPhase1 is applied on projection space for dimensions that include 19, 57, 95, and 135. On projection space, the methods BCFIRPhase1_P19, BCFIRPhase1_P57, BCFIRPhase1_P95, and BCFIRPhase1_P135, which have dimensions of 19, 57, 95, and 135, respectively. It should also be noted here that BCFIRPhase1 is a retrieval method on the original space with the removal of 55 redundant dimensions as shown in Fig. 6. The precision of the methods is shown as shown in Fig. 11. Figure 11 shows us that, although the number of dimensions of BCFIRPhase1_P135 and BCFIRPhase1_135 are the same, the precision of BCFIRPhase1_P135 is lower than that of BCFIRPhase1_135 by approximately 10%. The reason that the precision of BCFIRPhase1_135 is so much higher than that of BCFIRPhase1_P135 is because the BCFIRPhase1_135 method is not affected by the small-class size problem. As this figure shows, the precision of BCFIRPhase1_P19, BCFIRPhase1_P57, BCFIRPhase1_P95 are equivalent to each other and also equivalent to BCFIRPhase1_P135. The reason for this is because performing the retrieval on the projection space is severely affected by the small-class size. Thus, we can confirm that our proposed method is not affected by small-class size.
Precision of BCFIRPhase1_135 on original space and BCFIRPhase1 on projection space.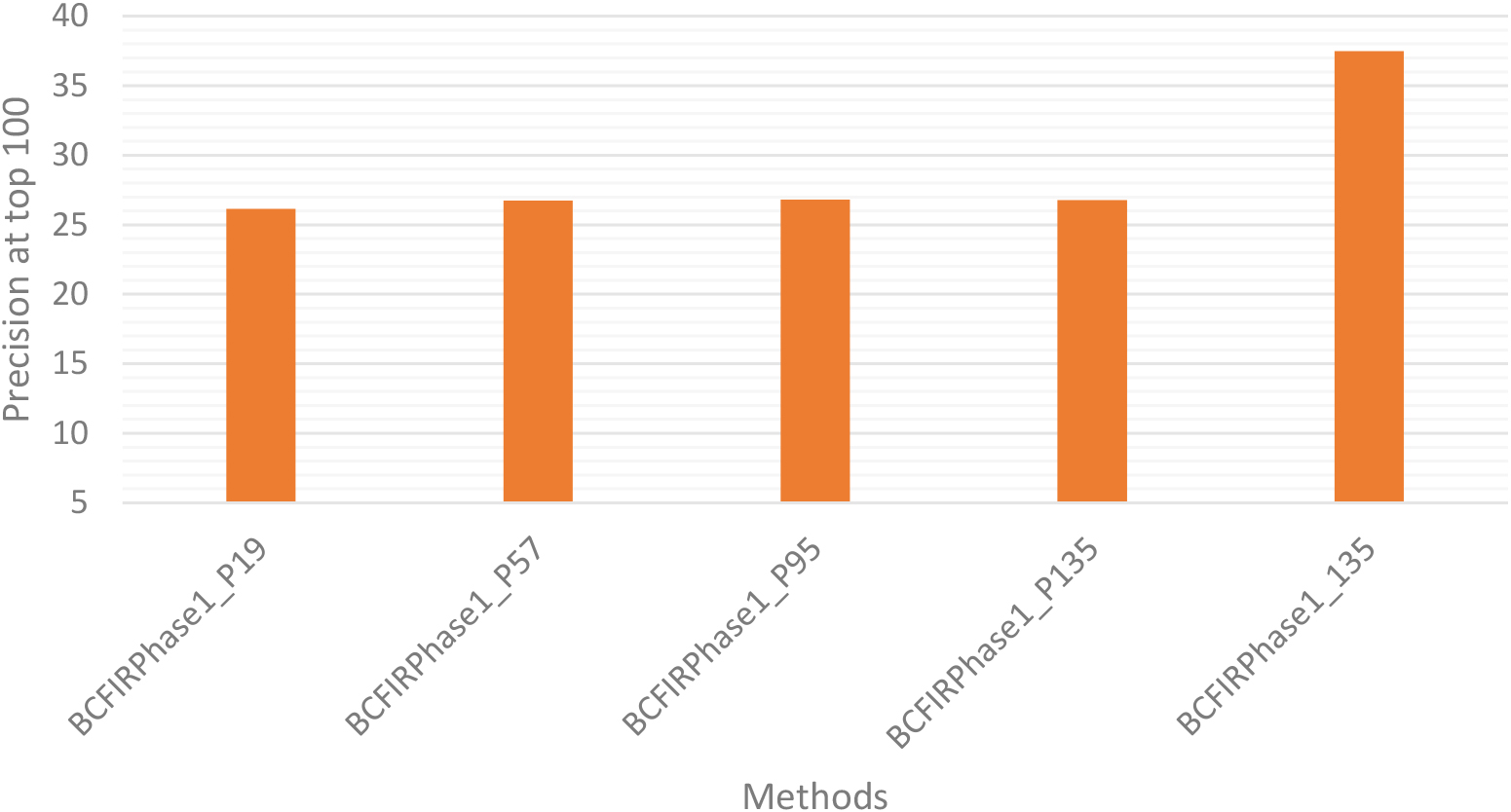
4.2.2.1 Results on the CIFAR-10
Our goal in this section is to compare the BCFIR’s performance with the state of the art method, which uses deep learning (of the second comparison group) on large image set. When comparing on 32-bit and 48-bit lengths, our proposed method is named BCFIR32b and BCFIR48b. When BCFIR32b and BCFIR48b are applied to four autoencoders (
In this experimental part, we randomly select 1000 images in the image set as query images. We also take the top 100 images as the returned list of images. Note here that, in our method, we choose the number of images in the candidate list as 300. Thus, the top 100 resulting images are selected from 300 candidate images.
Precision of different methods
From Table 3 we can see, our method BCFIR32b_4a and BCFIR48b_4a have higher precision than that of LSH which is about 8% and 10% respectively. This shows the precision of the proposed method. On a code length of 32 bits, our proposed method BCFIR32b_4a has slightly less precision than that of NSCM32b. The reason for this may be because the length of the code is too low while phase 1 of the proposed method has removed some dimensions of the feature vector on the original space. With a code length of 48 bits, our proposed method has slightly higher precision than that of NSCM48b. However, when the length of the code is 128, the precision of our method is higher than that of NSCM. The reason for the effectiveness of our method compared to the NSCM method is because our method solves the following problems: (1) small-class size problem; (2) it can efficiently learn binary codes; (3) use bootstrap cloning strategy with effective bagging; (4) take advantage of unlabeled samples in the retrieval process; and (5) use an efficient coarse-to-fine retrieval strategy. With the first response, the average time to perform 01 query image on original space with 95 dimensions for BCFIRPhase1_95 is 12 s while our proposed method BCFIR128b_4a is only 2.58 s.
In the problem of image retrieval with relevance feedback, we have to reduce the data dimensionality and still have to solve the small-class size problem which is a difficult task. In this paper, we solve this problem by selecting important original features and performing classification based on them. In order not to have to solve the NP-Hard problem in feature selection, instead of solving the combinatorial optimization problem, we reduce it to an optimization problem on the continuous feature space (according to the transform-based dimensionality reduction approach).
In addition, although recent works on image retrieval with relevance feedback have shown many improvements in performance, they yield low performance for large-scale datasets. Our proposed method BCFIR gives good performance on large-scale datasets. In addition to mapping real-valued features to short binary codes and using Hamming distance measure to speed up image retrieval, our proposed method also learns a good parameter transfer model, and apply a bagging learning strategy to improve the generalizability of deep autoencoders.
In addition, in the image retrieval problem with relevance feedback, the number of user feedback samples is usually small. This limits the performance of pure supervised learning methods. Our proposed method BCFIR takes advantage of both labeled and unlabeled samples. In particular, labeled samples need only be used for the selection of important original features in Phase 1, while Phase 2 uses unlabeled samples to train deep autoencoders.
Experimental results on CIFAE-10, Corel, and SIMPLIcity show that the proposed method generates state of the art image retrieval performance on standard benchmarks. These experimental results are in agreement with our proposal and analysis.
Footnotes
Acknowledgments
This research is funded by “Research on content-based image retrieval using relevance feedback with sparse representation classification” of Institute of Information Technology (IOIT), Vietnam Academy of Science and Technology (VAST) under grant number code CS21.04. This research was also supported by the research support program Offer for senior researchers in 2022 under grant no. NVCC02.01/22-22.