
Abstract
Over the years, many content-based image retrieval (CBIR) methods, which use SVM-based relevant feedback, are proposed to improve the performance of image retrieval systems. However, the performance of these methods is low due to the following limitations: (1) ignore the unlabeled samples; (2) only exploit the global Euclidean structure and (3) not taking advantage of the various useful aspects of the object. In order to solve the first problem, we propose a graph-based semisupervised learning (GSEL), which can add positive samples and construct balanced sets. With the second problem, we propose a manifold learning for dimensional reduction (MAL), which exploits the geometric properties of the manifold data. With the third problem, we propose a combination of classifiers by aspect (CCA), which exploits the various useful aspects of the object. Experimental results reported in the Corel Photo Gallery (with 31,695 images), which demonstrate the accuracy of our proposed method in improving the performance of the content-based image retrieval system.
Keywords
Introduction
Over the years, much attention has been devoted to the field of image-based image retrieval [2, 51]. Measure, which measures the similarity between the query image and the images in the database [2, 36] is commonly used in traditional image retrieval systems as Euclidean distance measures. Due to the gap between low-level visual features and high-level semantic concepts, these measures become very inefficient. To reduce the gap between low-level visual features and high-level semantic concepts, the relevant feedback (RF) approach is given priority in the proposed methods [39, 47]. In RF, the interaction between the user and the image retrieval system is allowed and the purpose of the RF is to obtain positive and negative feedback samples from the user.
Over the past few years, on the basis of different assumptions about positive and negative feedback samples, many methods have been proposed [21, 51]. The One-Class SVM method only considers the density of positive feedback samples [48]. The two-class SVM examines both positive and negative feedback samples, but not considers equal importance for these two groups [27]. SVM active learning [32] is interested in patterns close to the boundary (for the user making the label) and the samples on similarity the positive side that are the furthest away from the boundary. A constrained similarity measure for image retrieval has been developed by Guo et al. [12]. Based on the defined boundary, this similarity measure uses the Euclidean distance to rank images in the margins according to the query image. In [6], the authors proposed a method that views the positive feedback samples as a group and divides manifold the negative feedback samples into several groups, then the kernel marginal convex machines were developed between a positive group and a few negative groups. The performance of this method has been significantly improved. Several other image retrieval methods that use SVM-based relevance feedback have been proposed [38]. However, their performance needs to be improved. The performance of image retrieval systems using SVM-based relevance feedback, have been proposed in the past, is not as expected due to:
Firstly, methods often ignore unlabeled samples. However, in image retrieval using relevant feedback, the user only labels a few images and does not guarantee that the labels of each response sample are correctly assigned by the user for all the times. Besides that, during the feedback process, the number of samples with negative labels is often much higher than that of positive samples. In addition, the manifold structure of the images can be explored through unlabeled samples. Therefore, the image retrieval method, which is based on the number of user-feedback samples, creates an unstable SVM classifier.
Second, the methods only explore the global Euclidean structure, while the local manifold structure of the low-level visual features is ignored. Global statistics such as variance are often difficult to estimate when the number of samples is insufficient.
Finally,methods only exploit a small number of aspects of the object.An object can consist of many different useful aspects,using a classifier that can eardly represent the various useful aspects of an object.
In image retrieval using relevant feedback, the samples provided by the user are usually very small compared to the dimension of the image feature. This makes the algorithms that can be effective in low-dimensional space becomes meaningless, we have to solve the problem called “curse of dimensionality”. In many problems such as face recognition [33, 34], image classification [26] and image annotation [9, 17], the subspace analysis approach is shown to be effective. This approach retains the specific statistical properties of high-dimensional space in the low-dimensional space. Two algorithms are widely used including principal component analysis(PCA) [30, 50] and linear discriminant analysis (LDA) [8, 28]. The PCA finds a projection on which the variance is maximized. The LDA finds a projection on which samples of the same label are grouped into a cluster, with different label samples located in different clusters. With image retrieval systems using relevant feedback, LDA gives better performance than PCA. However, when applying the LDA to the RF process, it is not feasible to collect large label samples [39]. Both PCA and LDA only consider Euclidean structures, but the low-level visual feature space can be a manifold [41, 42].
In recent years, many manifold learning algorithms have been proposed to explore the manifold structure. The method proposed by He et al. [41], named LPP, to perform locality preserving projections to find a linear approximation of the internal data manifold.
Based on LPP, the image retrieval method proposed in [41, 42] to perform comparison images in the reduced subspace by using a Euclidean metric. The image retrieval method learns a semantic manifold with the user’s preferences being included, called augmented relation embedding (ARE), proposed in [49]. Next, an image retrieval method can discover the local manifold structure through the extreme margin between the negative and positive samples in each local neighborhood, named maximum margin projection (MMP), proposed by [43]. Some methods consider the case when the data lies on or near a nonlinear submanifold in ambient space consisting of locally linear embedding (LLE) [35], Isomap [16] and Laplacian Eigenmaps [24]. The method proposed by Li et al. [17] which preserves the distinguishing information in the encoding by combining subspace learning with the maximum margin principle. These methods estimate both the geometrical and the discriminant properties of the submanifold from random points located on this unknown submanifold. However, these methods only work with data points in the training set, and it does not explicitly give the projection possible for new test points. Besides, these methods only consider geometric properties in a class, while ignoring the relationship of samples from different classes. Therefore, these methods are not effective for image retrieval.
In this paper, we propose a graph-based semisupervised and manifold learning method for image retrieval with SVM-based relevant feedback SEMAL (Graph-based Semisupervised and Manifold Learning). SEMAL based on the observation that 1) a sample that is located in a region with high positive label density, that will have a high probability of carrying a positive label and using graph partition with the Ncut criterion makes that assertion stronger; 2) A training set can have many different useful aspects, we need to have multiple classifiers to represent the different useful aspects; and 3) The global Euclidean structures do not necessarily represent the manifold of the data, we need to look at the local manifold structure of the low-level visual features. Combining these three observations with the SVM model, our proposed method improves the performance of SVM-based relevant feedback for image retrieval. In SEMAL, we chose the majority vote [4] as the similarity measure in a combination of different classifiers. The reason for this is that each different classifier has its own ability in distinguishing relevant and irrelevant images. The main contributions of this paper include:
It proposes a semi-supervised learning algorithm to add positive samples and establish a balanced training set GSEL, which take advantage of the information of the unlabeled samples in the image set.
It solves the overfitting problem of the classification model SVM through the manifold learning algorithm for dimensional reduction (MAL), which exploits the geometric properties of the data manifold. Our proposed algorithm can explore the local ma for the class manifold structure, so it is suitable for image retrieval where the nearest neighbor search is usually included.
It proposes a combination of classifiers by aspect (CCA), which exploits the statistical nature of the aspects of the class.
The rest of the paper is organized as follows. In Part 2, we present GSEL, a graph-based semisupervised learning algorithm for building the balanced training set from labeled and unlabeled samples. In part 3, we present an manifold leaning algorithm (MAL) for dimensionality reduction. Section 4 focuses on presenting a combination of classifiers by aspect and exploring the statistical properties for classification. Next, section 5 describes our proposed image retrieval algorithm (SEMAL). After that, our proposed image retrieval system diagram is presented in section 6. Analyzing our experimental results is described in section 7. Finally, we draw the conclusions in section 8.
Graph-based semisupervised learning for building a balanced training set
As mentioned in the previous section, most of SVM-based relevant techniques do not utilize the information of unlabeled samples, although they are very useful in building a strong classifier. Besides that, in the image retrieval with relevant feedback, the number of positive samples is much less than the number of negative samples, which creates an imbalance training sample set. In this section, we propose a graph-based semi-supervised learning technique to add positive samples to the training set in order to obtain a balanced sample set.
Given N points X1, X2, . . . , X N ∈ R n we construct a nearest neighbor graph G = (X, S) [37] with N nodes, one for each point. These images (nodes) are the result of the previous query. Graph G is also an undirected weighted graph. In graph G, each edge is created by two vertices x i and x j carrying a non-negative weight S ij ⩾ 0.
Assume the weighted adjacency matrix of the graph, constructed above, is the matrix S = (S
ij
) i,j=1,...N. Call kNN (X
i
) is the k nearest neighbors of point x
i
. If X
i
∈ kNN (X
j
) (or X
i
∈ kNN (X
i
)) then S
ij
= 1. Otherwise, S
ij
= 0. Since G is undirected, we require S
ij
= S
ji
. Assume that there are m points already labeled by the user (including the original query image) LX = { X1, X2, . . . , X
N
} ∈ R
n
and N - m points have not been labeled by the user UX = { XN-m+1, XN-m+2, . . . , XN-m } ∈ R
n
. To determine the temporary label of point x
i
, where the density of the positive class around that point is high, we construct graph
We define the following:
In Equation (2), the value of β is large, it implies that the two images have the same label.
On the graph
For each point x
i
∈ UX that has not been labeled, find the point with the highest degree
The reason for this is based on the observation that matrix D
label
provides a natural measure on data points. If
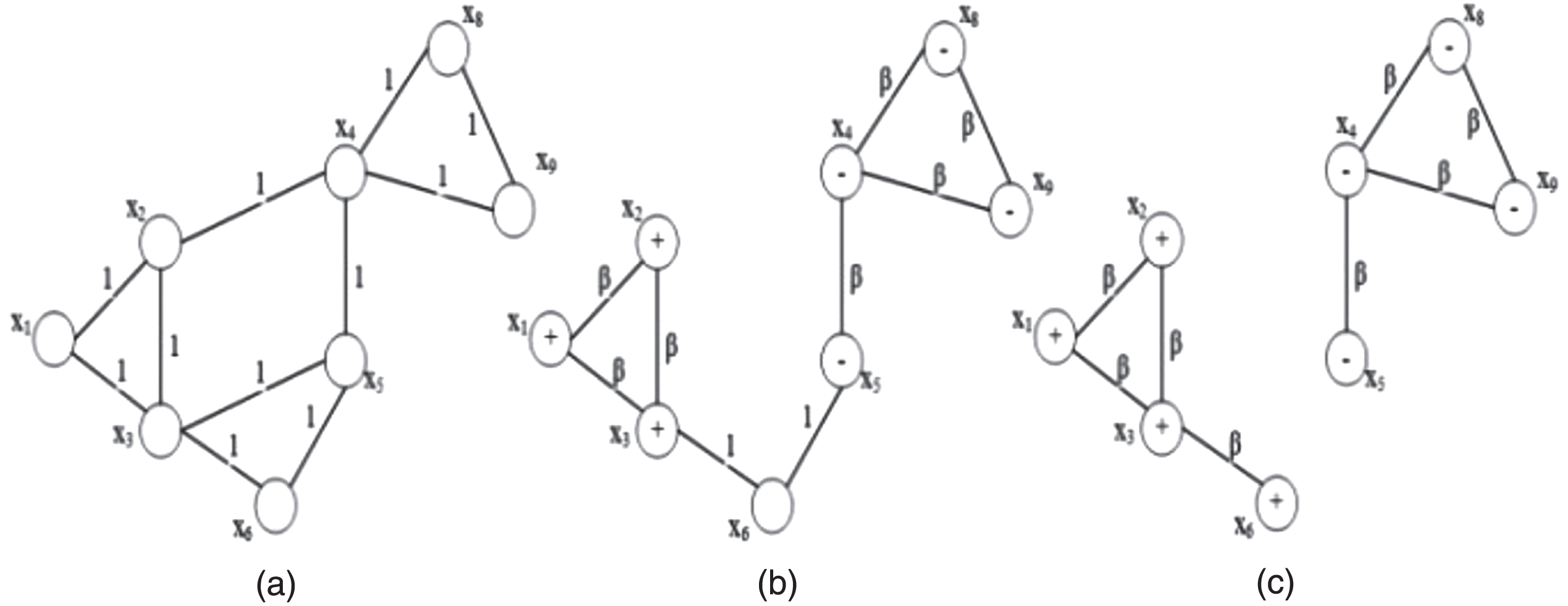
(a) Graph G. Points of the k-nearest neighbors are connected and weighted by 1, (b) On graph
The idea of identifying the last label of a point x
i
is presented as follows. First, we divide the graph
Here, the criterion used to partition the graph
On the graph
Here P ∈
To consider within-class, u’e define a vol (p) as the total weight of edges with at least one endpoint in P.
where,
The Nut criterion is defined as follows:
The problem that finds the minimum Ncut value for a graph is an NP-complete problem. Fortunately, the method proposed by Shi and Malik [18] allow us to find approximations by solving the generalized eigenvalue problem.
Generalized eigen-vector corresponding to the second smallest generalized eigen-value used to partition the graph

Graph
Figure 3 below is a graph-based semi-supervised learning algorithm for building a balanced sample set from labeled and unlabeled samples GSEL. The input of the algorithm is a set of images that are the result of a previous query, with m points labeled and N-m points unlabeled. The algorithm can determine the label of some unlabeled points and produce a result set that includes balanced sample set.

The algorithm of Graph-based semisupervised learning (GSEL).
In general, the dimension of the vectors that represent the image data is usually very high. In image retrieval using associated feedback, the number of samples provided by the user is often much smaller than the number of dimensions of the feature. SVM learning model in such high space and small sample sizes often yields poor performance. Therefore, to improve the performance of image retrieval using SVM-based relevant feedback, the number of dimensions of the feature vector must be reduced and the used dimensional reduction method should consider the local manifold structure of the low-level visual features. In this section, we present the manifold learning algorithm MAL (Manifold Learning for dimensional reduction) for reducing the dimensionality of the feature.
Let G = (X, S) be an undirected graph with a set of vertices X = {x1, x2, . . . x
N
} ∈ Rn×N. x
i
= (i = 1, . . . , N) is the point that is sampled from the basic submanifold M and they have been labeled. We construct a neighborhood graph G to model the geometric properties of the submanifold. In practice, the dimension of the feature n is very high. The goal of reducing the feature is to find a projection W which transforms the X data from the original high-dimensional space into Y = {y1, y2, . . . y
N
} ∈ RN×d in the low-dimensional space d [3, 34].
Assume S = (S
ij
) i,j=1,..N is the adjacent matrix of graph G. Because our goal is to build a graph that represents local neighborhood relations, so the Gaussian similarity function [24]
On the graph G, we construct the diagonal matrix D with its entries are row (or column) sums of S, d
i
= ∑
j
s
ji
After constructing the diagonal matrix D and the matrix S, we compute the Laplacian matrix L [10] as follows:
Suppose the map from a graph to a real line is denoted by Y = [y1 ; y2 ; . . . ; y
N
] Suppose a linear projection Y = X
T
W will give us the low-dimensional vector representations of the vertices of the graph G. In order to obtain the optimal Y, it is necessary to perform the minimum
In the objective function (11), if the vertices have the same label and neighbors i and j are mapped far apart, the objective function will perform a heavy penalty.
Therefore, the above minimum will to ensure that if the vertex i and j are “close” then y
i
and y
j
must also be close [31]. We get
At this point, the objective function will be as follows.
Here d is a constant and a constraint matrix W T XDX T W = d to avoid a trivial solution of the objective function.
The above optimization problem refers to finding the eigenvector of the generalized eigenvalue problem in combination with the smallest eigenvalues.
That is, the columns of W are eigenvectors corresponding to the smallest eigenvalues of the generalized eigenvalue problem.
Figure 4 below is the manifold learning algorithm MAL (Manifold Learning for dimensional reduction). The input of the algorithm is a set of n-dimensional images and produces a projection matrixW.

The algorithm of manifold learning for dimensional reduction (MAL).
In this section, we first focus on presenting a technique for constructing aspect classifiers of the object. We then describe a combinatorial technique for a generalized classifier that covers various useful aspects of the object.
With the belief that there is no classifier that can represent all the useful aspects of the object. Therefore, in order to represent the various useful aspects of the object, we need to have many classifiers in terms of the aspect. On the basis of aspect classifiers, we construct a generalized classifier that can represent all the various useful aspects of an object. For example, an object is a human, a classifier can be based on aspects: face, gait, and fingerprint. Given the various useful aspects of the object under consideration, these classifiers can be independently trained on a training set of aspects. Then, a generalized classifier will be determined by combining from the existing aspect classifiers. Thus, this process can represent different useful aspects of the object and lead to improved performance of the lookup system. The aspects are determined according to the specific objectives of each problem. In this paper, we chose five aspects, including color moment, color histogram, color correlation, Gabor features and wavelet features.
We expect that a generalized classifier, which is combined with many aspect classifiers with using the majority voting technique [4], yield good results based on the belief that the majority of experts are capable of making the right decision. Thus, if there are m aspect classifiers and more than half of them decide that observation x belongs to class A, then the whole determines that x ∈ A.
Figure 5 below is an algorithm for combining aspect classifiers CCA. The input of the algorithm is a training sample set and the number of aspects of the object. The algorithm results in a generalized classifier.

An algorithm of the combination of classifiers by aspect (CCA).
In this section, we propose an image retrieval algorithm for improving image retrieval system’s accuracy with relevant feedback. Our proposed algorithm is called SEMAL (Graph-based Semisupervised and Manifold learning). Figure 6 below is the SEMAL algorithm.

Algorithm of graph-based semisupervised and manifold learning for image retrieval (SEMAL).
The SEMAL algorithm is implemented as follows: Each image in S is represented as a point in a high-dimensional feature space. When a user submits initial query Q via a query-by-example, the algorithm uses the same procedure as for the database image to represent the image Q into a point in a high-dimensional feature space. Initial query RetrievalInit(Q, S, N > is performed (Step 1), where S is the database image set and N is the number of images that are retrieved for each iteration. The result of the initial query is assigned to the Resultinit(Q). On the result set Resultinit(Q) which is returned by the initialization query, the user performs the feedback on a graphical interface via the function Feedback(Result init (Q)) to get the relevant image and save it to the set R Relevant(Q,m) (Step 2.1). The process that adds positive samples and builds balanced training set is done through the function GSEL(S,Relevant(Q,m),TS) (Step 2.2). The Take_Aspect(TS) function (Step 2.3) performs the separation of the aspects of the set TS to obtain the set Aspect i . With each set of aspects i, the MAL procedure will learn a projection W to perform a dimensional reduction on the set Aspect i and we will get the set reduced A spect1 (Step 2.4). With each aspect set Aspect i (i = 1,...,k), CCA(reduced A spect1,..reduced A spect k ,C*) (Step 2.5) creates a aspect classifier C* (reduced A spect i ) and combining these classifiers, we will get a generalized classifier C*. Based on the generalized classifier C*. The Retrieval(C*,S,N) function (Step 2.6) will rank the images in the set S and take out the N images at the top to assign them to R. This process is repeated until the user satisfies thedemand.
Figure 7 shows the schema of the proposed image retrieval system, named SEMAL. The first stage, when a query image is given by the user, low-level visual features are extracted. Next, the system will calculate a similar measure for a distance function. Images are sorted by this measure and it returns a set of images at the top for the user.
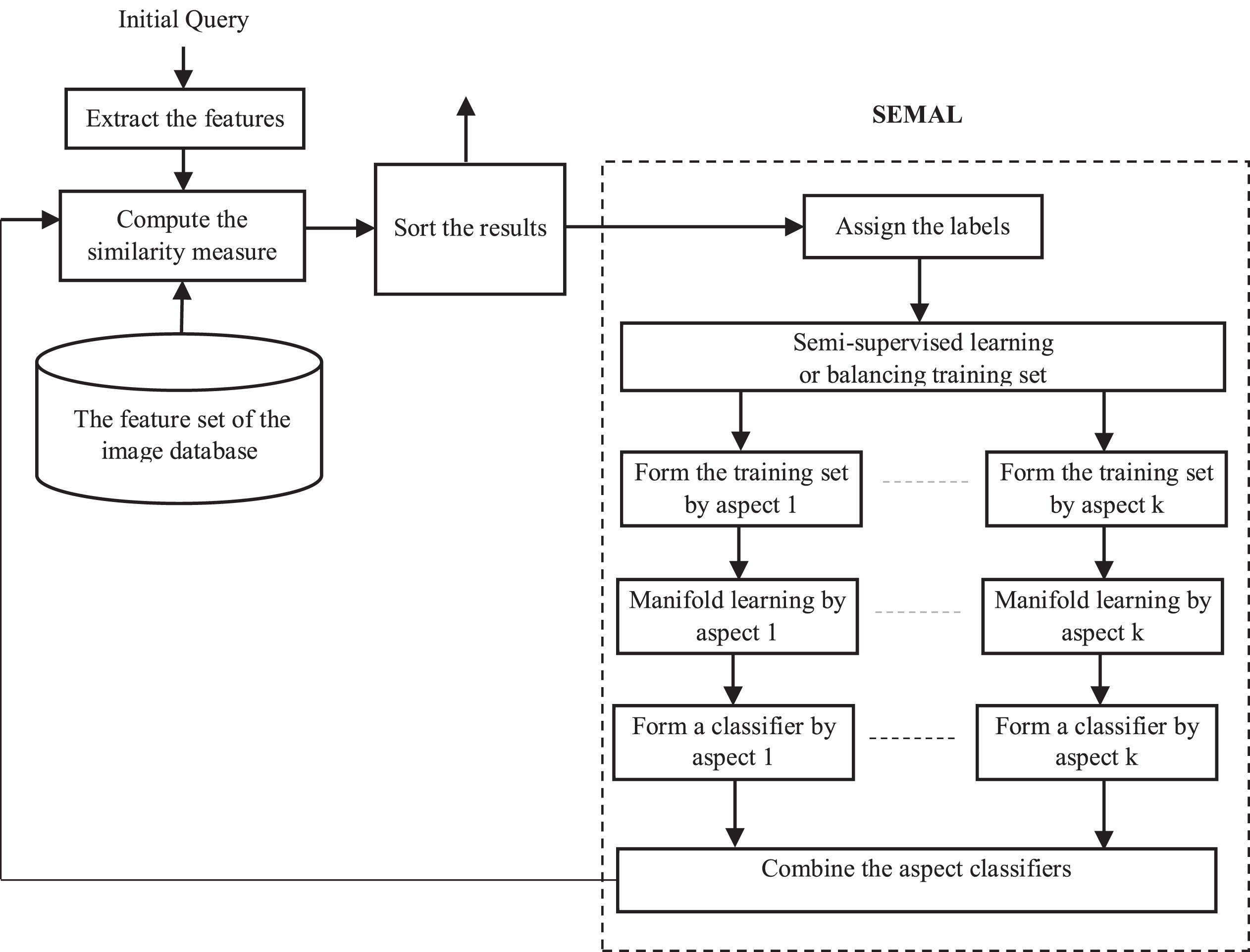
The image retrieval system flow chart (SEMAL).
The second stage, users label the images at the top as negative samples or positive samples. The system will obtain a small training set, in which the number of samples is greater than the number of positive samples. Thus, in order to create a large and balanced training set, the system implements the block “Semi-supervised learning for balancing the training set”. Based on this training set, the system generates k training sets by aspect (Here, we choose two aspects of color and texture). With each training set by aspect i (i = 1, 2, \dots k), The system reduces the number of dimensions of the training set by aspect i via the manifold learning algorithm. We get the training set by aspect, which the dimension is small. With each training set by aspect, SVM model is applied to obtain the aspect classifier. We get k aspect classifiers. The system combines k classifiers to obtain a generalized classifier. Apply the generic classifier to the image retrieval process, the similarity of the images can be updated. After that, all images are reordered based on similarity that has just been updated. If the user is not satisfied with the result, the relevance feedback process will be repeated.
This system implements the SEMAL algorithm in Fig. 6. In the system, images are represented by two main features, including color [1, 25; 45] and texture [13]. Color features are the most important feature for image retrieval because this feature is not sensitive to scaling, rotation and distortion [25]. Texture features are another important signal for image retrieval. Details of these two features are presentedbelow.
Color information: We use three features including color moment, color histogram and color correlation. First color features we extracted two moments include color mean, color Standard Deviation, in each color component (H, S, and V respectively), so the number of dimensions of the color moment is 6 dimensional. The second color feature is the HSV color histogram, which consists of 32 dimensions (8 * 2 * 2). The H component is quantized into 8 bin. Both S and V components are quantized into 2 bin. The final color feature is color correlation, it uses RGB space. The number of dimensions of this feature is 64 (4 * 4 * 4). These three types of visual color features are used to represent the color information in ourexperiments.
Texture: We extract classic global texture descriptions such as Gabor features and wavelet features. Gabor features include Mean-squared energy and meanAmplitude for 4 levels, 6 directions for the grayscale image; The number of dimensions of the wavalet feature is 40, which consists of two wavelet moments as the mean, standard deviation.
In summary, these features are combined into a feature vector of 190 values (6 + 32 + 64 + 40 + 48 = 190). After that, all the feature components are normalized into Normal distributions with zero mean and standard deviation of one to represent the images.
In this experiment, we use the Corel Photo Gallery, which contains 31,695 images [11]. Figure 8 shows some samples in this database.

Some samples in the image database.
In the Corel Photo Gallery, each folder contains 100 images and ground truth consist of 320 concepts.
The feedback process in the experiment is automatically simulated by the computer program. This means that an image in the returned image set is labeled as positive or negative depending on whether it has the same concept as the query image (in the ground truth). First, the system randomly selects 500 images from the image Set as query images. Then, with each query, 80 images are returned. Next, the computer automatically assigns positive or negative labels to each of these 80 images. In the returned image set, we chose 80 images because a system usually requires users to mark three to four screenshots of images during the current lookup. While, with some users, they want to just label a small number of feedback samples and expect to receive the best results.
In this paper, precision is used to evaluate the performance of the relevant feedback algorithm. Precision is the percentage of images in N images that are retrieved at the top. Precise curves are the average precision values of 500 queries. We use the precision curve to evaluate the precision of a given algorithm.
Figure 9 shows the accuracy values of O-SVM (Original SVM) [22], the SVM-MSMOTE method (SVM with Modified Synthetic Minority Oversampling Technique) [23] and the SVM-GSEL method (combine SVM with graph-based semisupervised learning). Experimental results show that as the number of loops increases, the performance of the original SVM method is greatly affected. The reason for this is that as the number of loops increases, the number of samples increases rapidly and thus, resulting in an imbalance of the training set. In addition, the SVM-MSMOTE method is higher than the O-SVM method but the precision is lower than the SVM-GSEL method. The reason for this is that the SVM-MSMOTE method uses artificial positive samples, which do not properly represent the context of the data space.
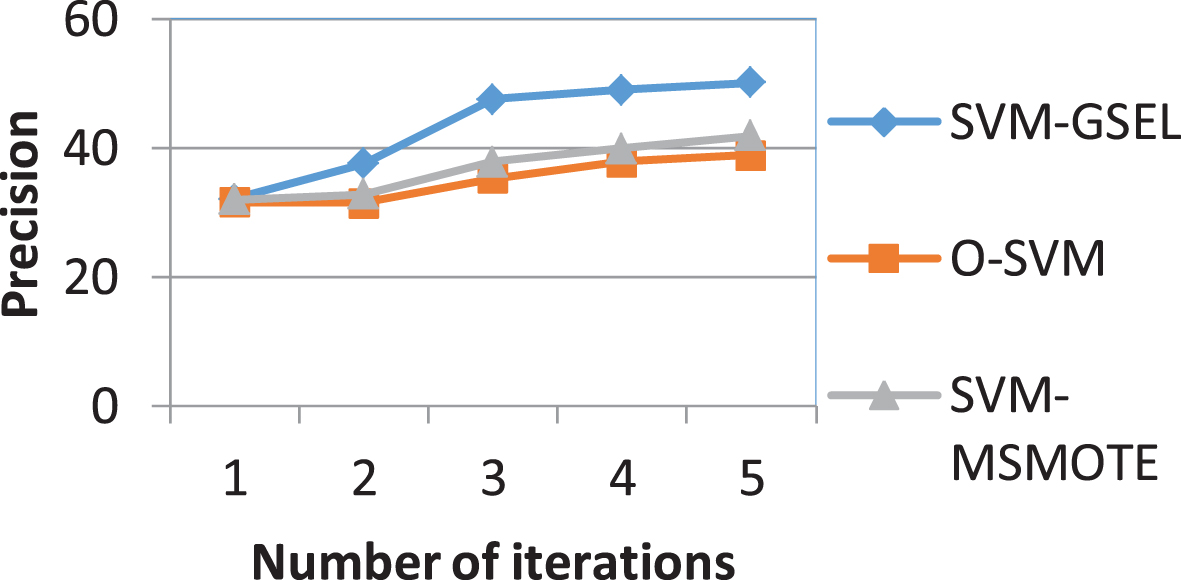
The precision of O-SVM and SVM-GSEL.
From this experiment, we can see that the SVM-GSEL algorithm outperforms the original SVM method. The precision curve of the SVM-GSEL algorithm is higher than that of the O-SVM.
Figure 10 shows the accuracy values of O-SVM (original SVM) [22] and the SVM-MAL method (combine manifold learning for dimensional reduction with SVM). The results show that as the number of loops increases, the performance of both methods increases. However, when the number of loops is small (from 1 to 2), the performance of the O-SVM method is affected. The reason for this is that when the number of loops is small, the number of samples is too small compared to the number of dimensions of the feature, the O-SVM classifier is unstable.
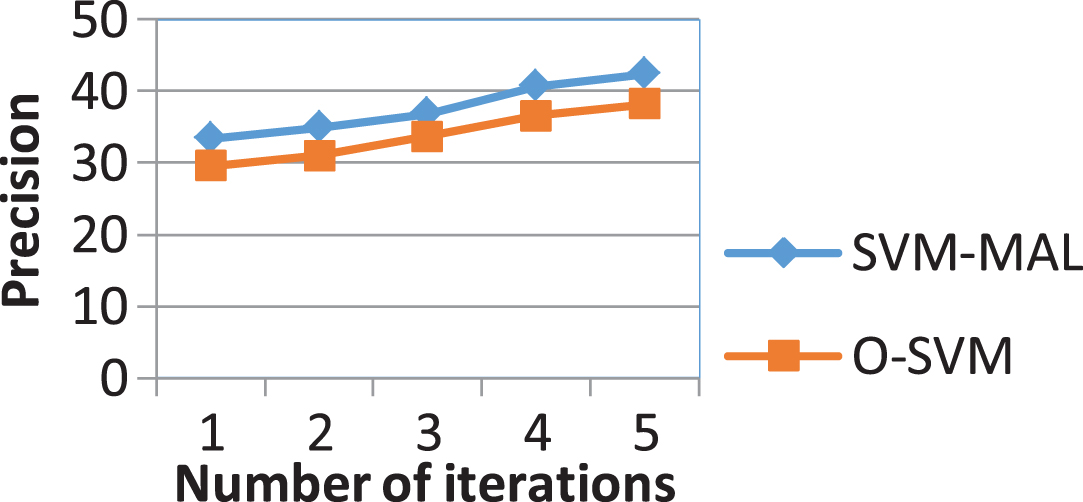
The precision of O-SVM and SVM-MAL.
From this experiment, we can see that the SVM-MAL algorithm performs better than the original SVM method. The precision curve of the SVM-MAL algorithm is higher than that of the O-SVM.
This experiment evaluates the performance of SVM-CCA (combination of classifiers by aspect with SVM) versus O-SVM (original SVM). We select the number of aspect k = 5 (including color moment, color histogram, color correlation, Gabor features and wavelet features) for SVM-CCA. Experimental results show that as the number of aspects increases, the O-SVM method is not affected, but the SVM-CCA increases rapidly in number of aspects. The reason for this is that the generalized classifier exploits the various useful aspects of the object.
The results in Fig. 11 show that the performance of the SVM-CCA algorithm is increasing rapidly.
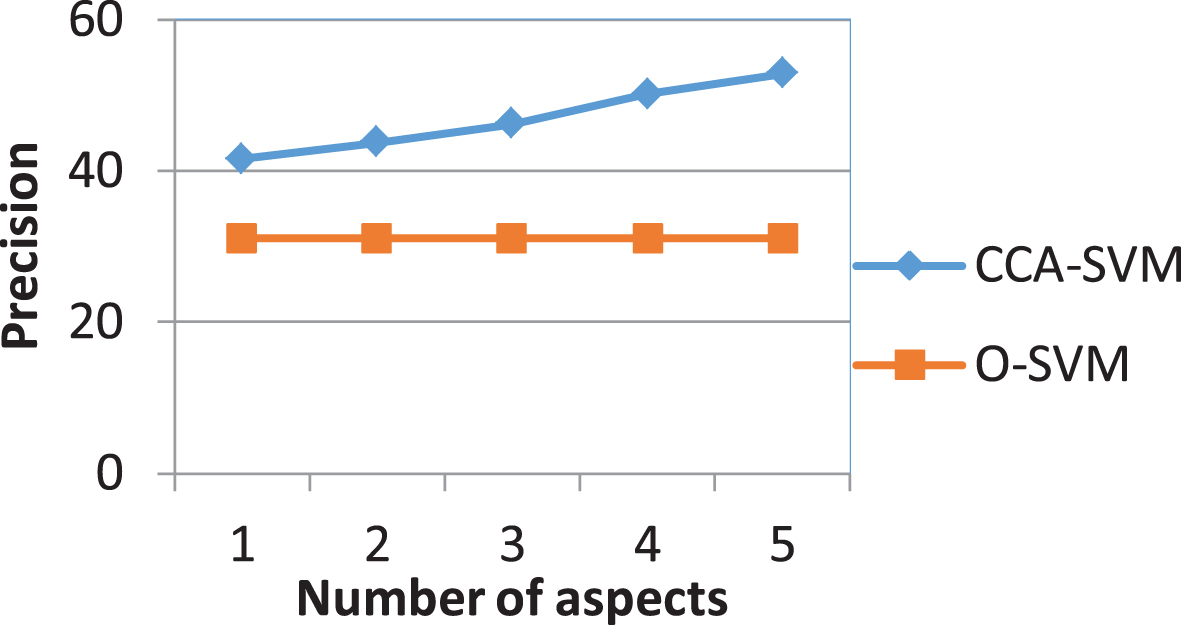
The precision of O-SVM and SVM-CCA.
Our proposed approach was compared with four other methods, including the O-SVM (the original SVM-based relevant feedback) [22], DSSA (the discriminative semantic subspace analysis) [21], DMINTIR (discriminative multi-view interactive image re-ranking) [17] and HMR (heterogeneous manifold ranking) [19]. We evaluate all algorithms on 5 loops. The precision curves are shown in Fig. 12. From this figure, we see that the SMAL method performs better than the other four, O-SVM, DSSA, DMINTIR and HMR.
In Fig. 12, we find that the performance of the DSSA method is higher than the O-SVM, because it is possible to learn a semantic subspace from similar and dissimilar pairwise constraints without using class label information. However, according to empirical results, DSSA’s performance is worse than DMINTIR, because it does not exploit the different viewing angles of the object. From Fig. 12, we see that the performance of DMINTIR is slightly lower than that of HMR because HMR exploits the locality of the data manifold. SEMAL takes advantage of semi-supervised learning for balancing the training set, manifold learning for dimensional reduction, various useful aspects of the object. Therefore, it gives the highest results.
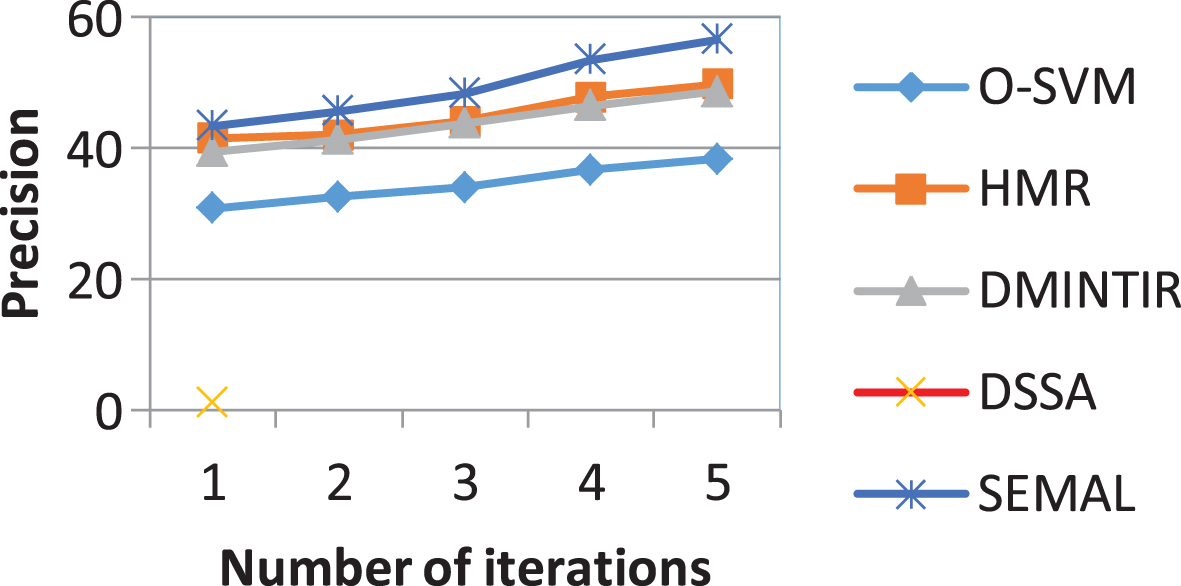
Performance of the five methods.
Content-based image retrieval, which uses SVM-based relevant feedback, has been widely used to reduce the semantic gap and improve the accuracy of the content-based retrieval system. However, this approach has three limitations as follows. First, based only on the labels provided by the user to build the training set, thus generating an unstable SVM classifier. Second, bypass the local manifold structure of visual features of the image. Finally, do not fully exploit the various useful aspects of the object. In this paper, we proposed solutions based on the argument that if a sample is located in a region with a high positive-label density and it is in the positive class of the Ncut criterion, that point will be labeled positive; A training set may have many different useful aspects, so we need more classifiers to represent those aspects and; The global Euclidean structures do not fully reflect the manifold of the data, we need to look at the local manifold structure. We have proposed the SEMAL algorithm to improve the efficiency of the image retrieval system with RF. Our proposed method can: (1) utilize the information of unlabeled samples to create good training sample set; (2) exploit the geometric properties of the data manifold for reducing the dimensionality of the feature and (3) Takes advantage of the various useful aspects of the object to enhance classification accuracy. Experiments using the Corel Photo Gallery, which includes 31,695 labeled images, demonstrate that our proposed SEMAL method outperforms better than some established CBIR RF methods in terms of accuracy.
Footnotes
Acknowledgments
This research was supported in part by a research project titled “Improve the efficiency of image retrieval via distance metric learning” and Code VAST01.07/19-20. The authors also expressed their gratitude for the reviewers, their comments have improved the quality of the paper.