
Abstract
There are many attempts to implement deep neural network (DNN) distributed training frameworks. In these attempts, Apache Spark was used to develop the frameworks. Each framework has its advantages and disadvantages and needs further improvements. In the process of using Apache Spark to implement distributed training systems, we ran into some obstacles that significantly affect the performance of the systems and programming thinking. This is the reason why we developed our own distributed training framework, called Distributed Deep Learning Framework (DDLF), which is completely independent of Apache Spark. Our proposed framework can overcome the obstacles and is highly scalable. DDLF helps to develop applications that train DNN in a distributed environment (referred to as distributed training) in a simple, natural, and flexible way. In this paper, we will analyze the obstacles when implementing a distributed training system on Apache Spark and present solutions to overcome them in DDLF. We also present the features of DDLF and how to implement a distributed DNN training application on this framework. In addition, we conduct experiments by training a Convolutional Neural Network (CNN) model with datasets MNIST and CIFAR-10 in Apache Spark cluster and DDLF cluster to demonstrate the flexibility and effectiveness of DDLF.
Keywords
Introduction
It takes a lot of time to train a DNN. The larger the training dataset, the better the model, but the longer the training time will be [1, 2]. Usually, the training process takes days or even weeks until convergence [3, 4]. We need to speed up this process by building a distributed training system that takes advantage of cluster computing capacity. Apache Spark is the most prominent and popular big data processing framework today. So many DNN training frameworks have been combined with Apache Spark to take advantage of its distributed computing feature. However, in the process of developing DNN training applications based on Apache Spark we encountered some obstacles [5, 6, 7]. Apache Spark’s map/reduce structure is very useful when dealing with big data, but it has proved unsuitable for DNN training. The forced combination of Apache Spark for DNN training reduces the overall performance of the system. As a result, we developed the DDLF distributed processing framework, which is completely independent of Apache Spark, to overcome the obstacles of training DNN on Apache Spark.
Our contributions can be summarized as:
Proposing a new framework named DDLF for distributed DNN training. Describing the features of DDLF and how to implement a distributed DNN training application on DDLF. Analyzing the obstacles when implementing a distributed training system on Apache Spark and presenting solutions to overcome them in DDLF. Comparing the performance of DDLF and Apache Spark in distributed DNN training.
The rest of our paper is organized as follows: Section 2 is related works, Section 3 provides the basic concepts, Section 4 presents the methodology, Section 5 is about experiments, and the last section is the conclusions and future works.
Many research and development activities on distributed DNN training frameworks have been done as a result of the remarkable progress of deep learning (DL). Li et al. proposed a parameter server framework for distributed learning and several approaches were proposed to reduce the communication cost between nodes, such as only exchanging non-zero parameter values, local caching of index list, and randomly ignoring transmitted messages [8, 9]. Abadi et al. presented TensorFlow, a centralized framework for DNN training that integrates model and data parallelism [10]. Both works support asynchronous communication to improve efficiency but they do not control the stability of gradient updates.
Harlap et al. also proposed a distributed pipelined system for DNN training [11]. This work focuses on pipelining with a parallel model, partitioning DNN layers on different machines, and dividing the execution of machines by injecting consecutive mini-batches into the first one. This approach reduces communication load because only the operations and gradients of a subset of classes are communicated between machines. However, complex mechanisms (such as profiling, partitioning algorithms, and replicated stages) are needed to balance workloads between different machines, otherwise, computational resources will be wasted.
The next generation of machine learning (ML) applications will continuously interact with the environment and learn from these interactions. These applications place new and demanding system requirements, both in terms of performance and flexibility. Moritz et al. proposed Ray – a distributed system to solve them [12]. Ray implements a unified interface that can represent both task-parallel and actor-based computations, supported by a single dynamic execution engine. To meet performance requirements, Ray uses a distributed scheduler and a distributed fault-tolerant storage system to manage the control state of the system. In their experiments, they demonstrated scaling beyond 1.8 million tasks per second and better performance than existing dedicated systems for some challenging reinforcement learning applications.
With the growth in data size and model size, the data parallelism method cannot work on models whose parameter size cannot fit into the device memory of a single GPU. To further improve industrial-grade huge model training, Wang et al. introduced Whale, a unified distributed training framework [13]. It provides comprehensive parallel strategies including data parallelism, model parallelism, pipelines, hybrid strategies, and automatic parallel strategies. Whale is TensorFlow compatible and training tasks can be easily distributed by adding a few lines of code without changing the user model code. According to the authors, Whale is the first work that can support different hybrid distributed strategies in a framework. In their experiment on the BERT (Bidirectional Encoder Representations from Transformers) large model, Whale pipeline strategy is 2.32x faster than Horovod data parallelism on 64 GPUs. In large-scale image classification tasks (100,000 classes), Whale hybrid strategy, which consists of operator sharding and data parallelism, is 14.8x faster than Horovod data parallelism on 64 GPUs.
Preliminaries
Computer cluster
A computer cluster is a group of computers connected to a network and they act like a single entity [14, 15]. There are many computer cluster architectures, Fig. 1 is a typical computer cluster. Each computer of a cluster is called a node. Where:
Master node: is the computer that runs the main program, sends requests to the worker nodes to execute in parallel and collects the results. Worker node: is the computer involved in processing the requests of the master node.
A computer cluster.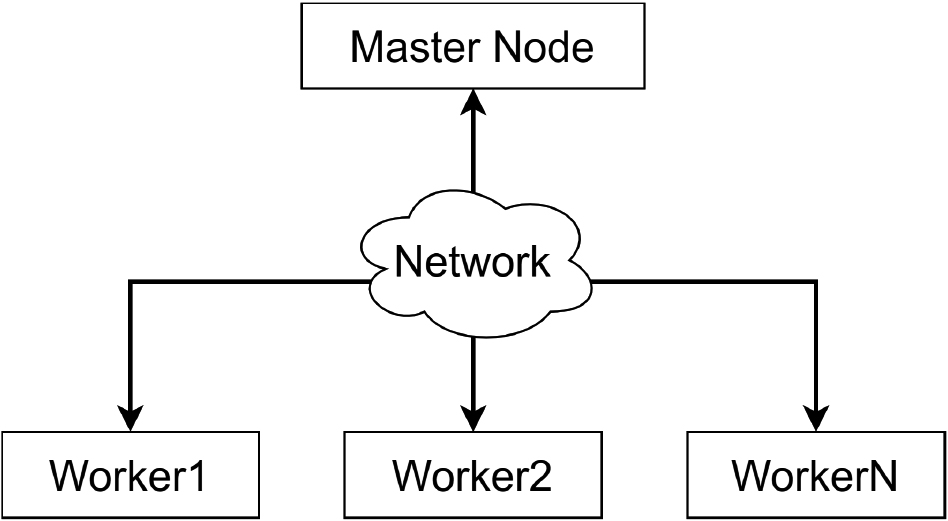
A computer cluster provides a distributed processing solution to solve complex problems by dividing a complex problem into many small parts, each of which is handled by a worker node. A computer cluster has many advantages such as cost-effectiveness, processing speed, high availability, scalability, and flexibility.
There are many distributed processing frameworks such as Hadoop, Apache Spark, Apache Storm, Samza, Flink [16, 17]. Where, Apache Spark is the most powerful and widely used distributed processing framework for big data because of the following features: 1) The processing speed is said to be lightning-fast; 2) Easy to use and flexible; 3) Providing support for complex analytics; 4) Real-time stream processing.
To deploy a distributed processing system on the Apache Spark framework, a Spark cluster must be built. The Spark cluster is a computer cluster where each computer is installed with Apache Spark software to control the operation in the cluster. Because Apache Spark does not have its file management system, the Spark cluster is often combined with a distributed file system such as Hadoop’s HDFS (Hadoop Distributed File System) [18] or Amazon’s S3 [19].
DNN training
There are two ways to train DNN: local training and distributed training. If the training dataset is small (fits into the memory of a single computer) and the DNN is simple, we should use local training. On the contrary, we should choose distributed training. However, distributed training is more complex and incurs additional communication costs between machines in the processing cluster.
The accuracy of a DL model can increase with the number of training samples, the number of model parameters, or both. However, training large networks is complex and time-consuming when trained on a single machine, even with multithreading support. This requires training the DL models on many connected computers in a distributed manner.
Training DNN in a local environment
Currently, there are many frameworks for implementing DL. The five best ones are TensorFlow, Keras, PyTorch, Apache MXNet, and Microsoft Cognitive Toolkit [20]. Among them, Keras is the simplest and easiest to use. Keras’s salient features include 1) The API is easy to understand and consistent; 2) Keras can combine with many DL frameworks such as TensorFlow, Theano, and CNTK; 3) Keras supports parallel and distributed training on multiple GPUs. Besides, TensorFlow is the best and most preferred framework today. Highlights of Tensorflow include: 1) Powerful multi-GPU support; 2) Visualize calculation graphs; 3) Great documentation and community support. However, Tensorflow is seen as a complex, difficult-to-use framework. Therefore, Keras was chosen as Tensorflow 2’s high-level API for ease of access and efficiency when solving DL problems. From the above analysis, we choose Keras as the framework to train DNN in the local environment in this study.
Training DNN in a distributed environment
The accuracy of a DL model can be increased with the number of training samples, the number of model parameters, or both. However, training large models is complex and time-consuming when training in a local environment with a single computer. To speed up the DNN training, we train a DNN model in a distributed environment. There are two main ways of distributed training: model parallelism and data parallelism [21, 22, 23].
Two distributed DNN training methods.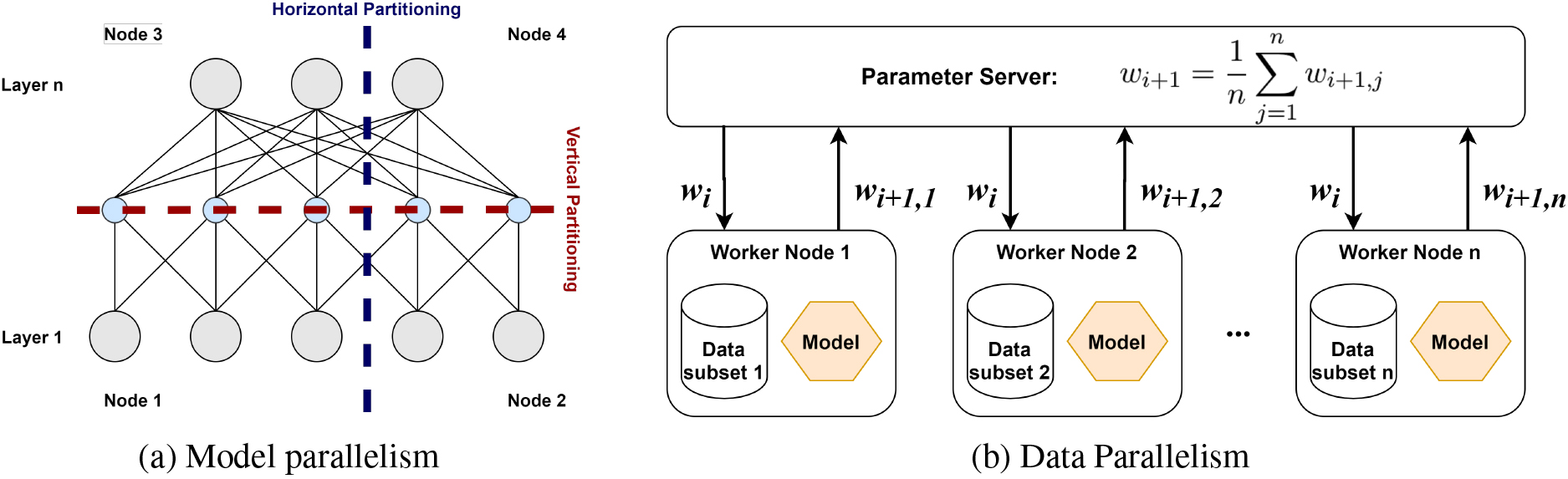
In model parallelism, as in Fig. 2a, the model is divided into different parts that can run concurrently on different machines, and each part will run on the same dataset. The worker nodes only need to synchronize the shared weights, usually once per propagation step forward or backward. Since this method is quite complicated, we should only use it when the large model does not fit in a single machine. Because of the complexity of this method and the limited scope of the paper, we only focus on the data parallelism method.
Data parallelism, as in Fig. 2b, is the most frequent method, as well as the simplest to build and use in most situations. In this approach, the training dataset is divided into partitions and distributed among worker nodes. The model is created at the master node, then sent to the worker nodes, and independently trained using previously distributed data partitions. After training the model for a controlled period, the model weights are sent to the master node by the worker nodes and the averaged values are used to update the weights of the model on the master node.
Data parallelism includes two main types: 1) Synchronous training (Fig. 3a): all worker nodes synchronize with each other during training; 2) Asynchronous training (Fig. 3b): each worker node trains at its own pace.
Synchronous and asynchronous distributed DNN training.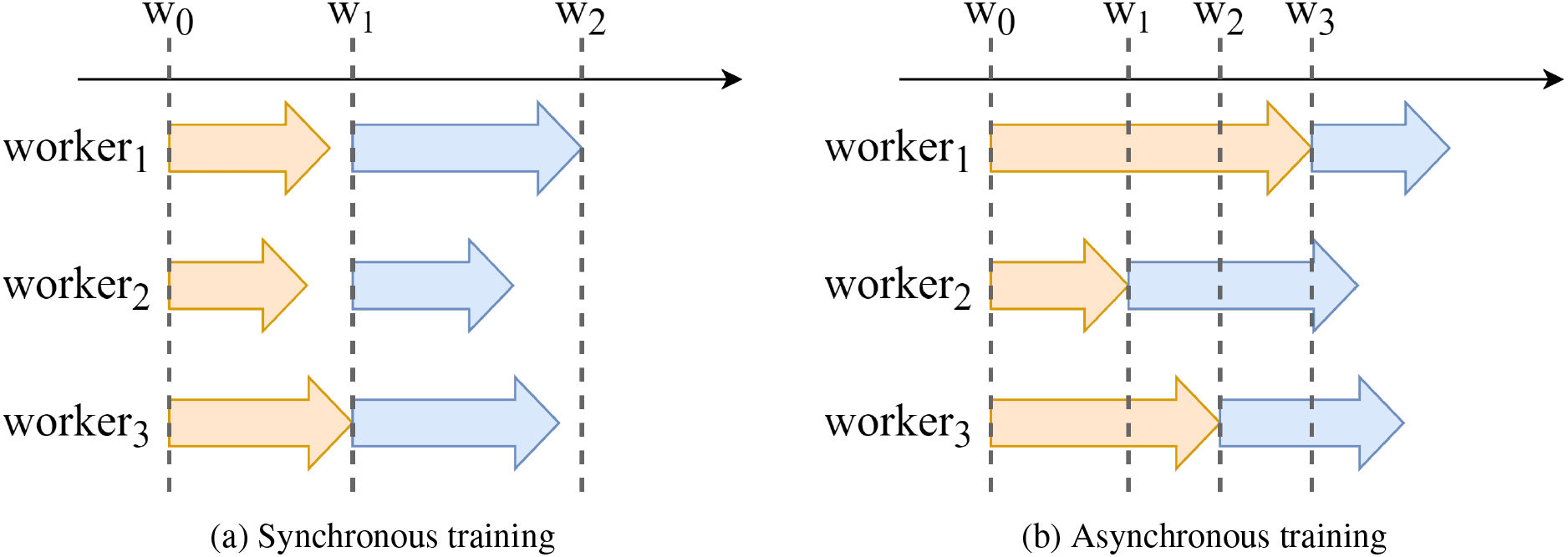
Implementation of a distributed DNN training system on Apache Spark
Apache Spark is a specialized distributed processing framework for processing and analyzing big data very efficiently. Apache Spark has become the most commonly used big data processing framework today. However, when deploying a distributed DNN training application on Apache Spark, we encountered difficulties that adversely affected the entire system. Algorithm 1 shows the synchronous DNN training on Apache Spark.
In the above implementation, there are three major problems, which adversely affect the performance of the entire system: 1) In each iteration, shuffling the data, partitioning the data, and sending new partitions to the worker nodes is time-consuming; 2) Programming thinking is dependent on the structure map/reduce, programmers are not free to develop ideas; 3) The function worker_train() is sent from the master node to the worker nodes multiple times, while the contents of this function do not change, increasing the traffic on the network unnecessarily. Through deploying distributed DNN training application on Apache Spark, we encountered the following difficulties:
Apache Spark’s map/reduce structure is very effective in big data processing, but it is not suitable for the distributed DNN training because the programming is confined to the map/reduce structure, which binds programming thinking, resulting in the less flexible and ineffective implementation of DNN training applications. Because it depends on the map/reduce structure, the function worker_train(data_iterator) accepts only one parameter, data_iterator (which is a data partition). The programmer cannot pass other information to the worker_train() function as needed. Using an alternative is too troublesome. This makes it difficult to deploy applications. The mechanism for sharing data between a master node and worker nodes is very limited through broadcast and accumulated variables. While broadcast variables are read-only variables, and accumulated variables are addition-only variables. Users cannot actively add/remove variables or methods to worker nodes. Apache Spark does not support asynchronous communication between a master node and worker nodes. Therefore, to implement an asynchronous DNN training application, application developers must either manually add asynchronous communication to Apache Spark or use a framework that supports asynchronous communication.
To avoid the above difficulties when developing a distributed DNN training application on Apache Spark, we consider 2 solutions: 1) Using an existing framework; 2) Building a new framework. Currently, many frameworks support distributed DNN training such as Distributed TensorFlow, Elephas, Horovod, TensorFlowOnSpark, BigDL, PyTorch, Ray [21, 2]. Using an existing framework helps to develop applications quickly, but the downside is to accept its internal shortcomings, and difficult to improve, leading to less flexibility. We choose to build a new framework named DDLF because of the following reasons:
Mastering the technology: The framework is developed by us, so we understand the techniques applied, understand its inner workings, and master the key techniques. Deepening the research content: When developing the framework, we have to conduct a lot of research, and surveys to deepen the content under research. Flexibility: We are not tied to any programming structure, such as map/reduce, which frees up programming thinking and helps to develop ideas freely and comfortably. Scalability: With the support of the techniques used in our framework, we can improve and extend our framework more easily. Overcoming the limitations encountered: Through our experience using existing frameworks, we can provide solutions to problems encountered.
The architecture of DDLF.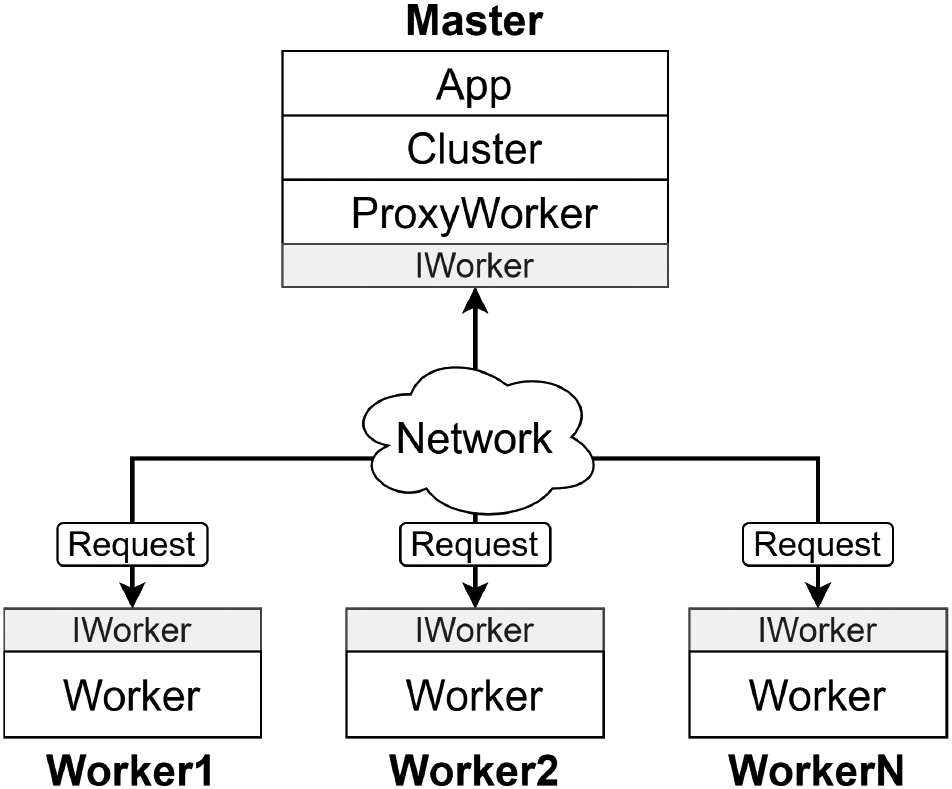
The architecture of DDLF is a computer cluster consisting of a master node and many worker nodes as in Fig. 4. The master node will control the worker nodes to handle tasks in a distributed fashion. The IWorker interface specifies the functionality of the worker nodes. The worker nodes are implemented using the Worker class. The master node consists of three main classes: 1) ProxyWorker: represents a worker node; 2) Cluster: represents the cluster; 3) App: represents a distributed application. The Request class represents a Remote Procedure Call (RPC) request which is sent from the master node to the worker nodes.
Deploying a distributed DNN training application on DDLF
To deploy a distributed DNN training application on DDLF, we perform the steps as in Algorithm 2.
For the convenience of deploying a distributed application, we have created the IApp interface to specify the required functions. When developing an application, the application developer only needs to create the App class (you can name it differently) that implements the IApp interface and override some of the necessary methods. Example 1 demonstrates a synchronous distributed DNN training application on DDLF.
In the App class, the load_dataset() and create_model() methods are required to be implemented according to specific requirements. The methods train(), train_sync(), and train_async(), if the default implementation is accepted, we don’t need to override them; otherwise, we can override them appropriately. Example 2 details the implementation of the load_dataset() method to load the MNIST dataset.
Example 3 details the implementation of the create_model() method to create a CNN model for classification on the MNIST dataset.
Features of DDLF
DDLF has the following advantages:
Simplicity: The design intent was to keep DDLF as simple as possible. Simple to install and use makes it easy to approach and quickly deploy the application, saving time and effort, and eventually, attaining economic efficiency. To install DDLF on the cluster just run a simple script. To deploy a distributed DNN training application, just extend the IApp interface to reuse existing utility methods, without complicated programming. Efficient multitasking: DDLF uses the asyncio package of Python 3.7 Multi-platform: DDLF can be installed on different operating systems, as long as the operating system supports Python 3.7 Flexibility: DDLF allows the master node to control worker nodes without any restrictions. This facilitates free programming thinking, programming is not dependent or constrained by any programming structure. Scalability: DDLF allows the master node to dynamically add variables and methods to worker nodes to serve diverse practical needs. Additional variables and methods persist on worker nodes until performing a request to delete or shut down the cluster. This allows the reusing of variables and methods, minimizing the need to transfer data or programs from the master node to the worker nodes, resulting in shorter processing times. This feature also helps programmers to dynamically and easily organize data and programs at worker nodes, so that distributed programming will be more natural, unrestricted, and increase performance. In addition, DDLF also allows adding worker nodes easily by making small changes in the configuration file. Efficiency: Experimentally, DDLF proves to be effective because it helps to quickly train DNN and create a quality model.
DDLF also has the following disadvantages:
Multi-language not supported: Currently, DDLF only supports Python language. The utility functions are not yet rich: The provision of many utility functions helps to quickly develop the application. However, in this release, there are a few utility functions, and we need to add more. Optimizing communication costs: During the training of a distributed DNN, the communication between the master node and the worker nodes occurs frequently and often requires the transmission of large amounts of data such as gradients, and data. Therefore, a good framework must have measures to optimize communication costs. However, in this release, DDLF has not implemented communication cost optimization measures. Training methods are not diversified: Currently, DDLF only supports training methods such as synchronous and asynchronous data parallelization.
As mentioned above, when implementing distributed DNN training systems on Apache Spark, we encountered some obstacles. Here are our solutions to overcome them.
Dynamic organization of data and functions at worker nodes
On DDLF, users can add/remove variables or methods to worker nodes without any constraints. This makes it easy for users to develop and deploy distributed applications. Meanwhile, Apache Spark allows to do this in a limited way via the map/reduce structure and shared variables.
A. The map/reduce structure
To solve problems when using the map/reduce structure, we allow the master node to send code freely to the worker nodes for execution. Code content can be a code segment or a method. In addition, we also allow the master node to dynamically add methods to worker nodes. These methods will persist on worker nodes until the master node requests to delete them or shut down the cluster. In the future, we will allow these additional methods to persist on worker nodes even after shutting down the cluster. This solution offers the following benefits:
The code, which is sent to worker nodes, does not depend on any programming structure (like map/reduce). Methods can have any number of parameters and arbitrary parameter data types. This frees up programming thinking and facilitates the development of ideas. For methods that are used repeatedly, we don’t need to send them to the worker nodes before each use as in the map/reduce structure but just send them to the worker nodes once, then use them again and again. This reduces the amount of traffic on the network.
B. Shared variables
In Apache Spark, the mechanism for sharing data between the master node and worker nodes is very limited via broadcast and accumulated variables. Broadcast variables are read-only variables, and accumulated variables are add-only variables. Furthermore, these variables have the same content across all worker nodes and they will be lost at the end of a Spark session.
To make the method of sharing data more convenient, on DDLF, we allow the master node to dynamically add variables to the worker nodes and manipulate them freely. The contents of these variables can be the same or different across worker nodes. Like additional methods, these variables will persist across worker nodes until the master node requests to delete them or shut down the cluster. In addition, the master node can also request worker nodes to access the local or shared file system to load or store data at the worker nodes. This solution has the following benefits:
Convenient in organizing data at worker nodes, facilitating the development of ideas and implementation of algorithms. Since dynamically added variables can persist until shutting down the cluster, the master node only needs to send data to worker nodes once and then reuse it many times, even across different applications. This reduces communication costs between the master node and the worker nodes.
To improve problems related to data shuffling, data partitioning, and sending data to worker nodes; we propose the following solution:
Worker nodes will preload all training data if it is not already in the cache. At each iteration, the master node simply shuffles the index of the training dataset, partitions the index set, and sends the index partitions to the worker nodes. Worker nodes will take their training data partition based on the previously loaded training dataset and the received index partition.
This solution has the following advantages:
It minimizes the size of the data sent from the master node to the worker nodes because the size of an index, which is an integer, is very small compared to the size of a training data sample, especially image data. This results in a maximum reduction in data sending time, which greatly improves the performance of the distributed DNN training system. The datasets can be cached in the worker nodes’ memory or local file system for reuse in different DNN training applications. It avoids creating a bottleneck at the master node because the master node does not have to distribute large volumes of training data to all worker nodes.
The above solution well solves the case that the entire training dataset can be stored in one worker node. However, when the size of the training dataset is too large, it exceeds the storage and processing capacity of a worker node; we need to improve the above solution like Fig. 5. First, we store the training dataset in a distributed file system accessible to all worker nodes (such as HDFS, S3), and partition it into
Loading datasets into DDLF.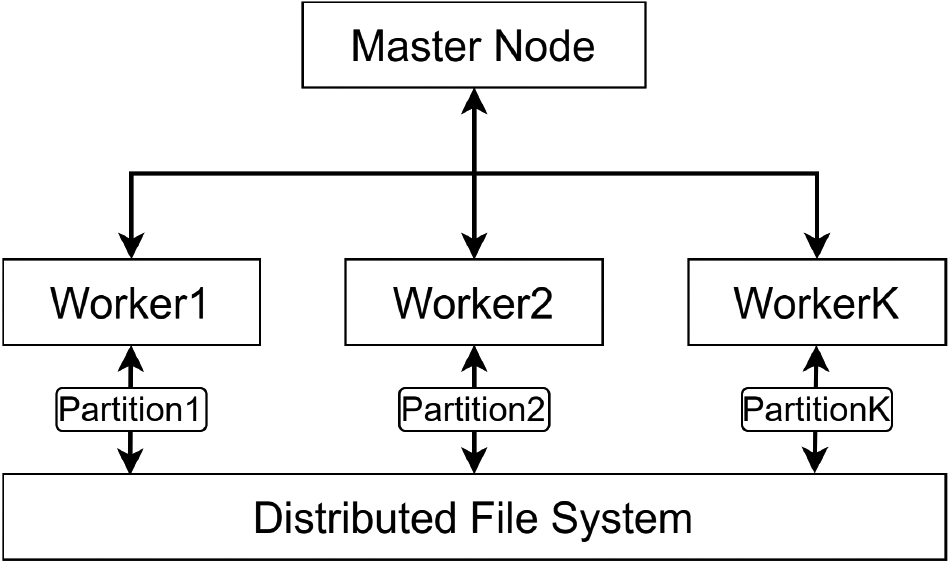
The above solutions are easily implemented on DDLF because of its flexibility (such as allowing dynamically adding variables and methods to worker nodes, allowing access to the local file system of worker nodes). However, on Apache Spark, it is very difficult for us to implement these solutions because Apache Spark does not allow the master node to access the worker nodes’ memory and local file system flexibly.
Apache Spark does not support asynchronous communication between the master node and the worker nodes. Therefore, to implement an asynchronous DNN training application, developers must either manually add asynchronous communication to Apache Spark or use a framework that supports asynchronous communication.
On DDLF, the master node is free to control worker nodes’ operations without any restrictions. So, when needed, the master node can very natively communicate with worker nodes synchronously or asynchronously.
Experiments
Datasets
In this research, we use two datasets MNIST and CIFAR-10. They are well-known datasets, often used to train image processing, computer vision, and machine learning systems. The MNIST dataset (
Experimental system configuration
We have built a cluster of nine computers. In which, one computer is the master node and eight computers are the worker nodes. The detailed configuration of the cluster is listed in Table 1.
Computer cluster configuration
Computer cluster configuration
We conducted experiments in two environments: a Spark cluster and a DDLF cluster. The Spark cluster is a computer cluster where each computer is installed with the Apache Spark distributed processing framework. Similarly, the DDLF Cluster is a computer cluster where each computer is installed with the DDLF distributed DNN training framework.
To compare the efficiency between Apache Spark and DDLF in distributed DNN training, we conducted three kinds of experiments on two datasets MNIST and CIFAR-10: 1) Using Keras in combination with Apache Spark for synchronous training; 2) Use Keras in combination with DDLF for synchronous training; 3) Use Keras in combination with DDLF for asynchronous training. Each type of experiment consists of ten different experiments based on the number of epochs varying from 10 to 100, with a step of 10. The CNN model is used for training as shown in Example 4.4. We did not test the case of using Keras in combination with Apache Spark for asynchronous training because Apache Spark does not support asynchronous communication between the master node and the worker nodes as mentioned in Section 4.1.
Table 2 shows the details of the experimental results on MNIST. Figure 6 shows charts illustrating the experimental results. The chart in Fig. 6a shows that DDLF is more efficient than Apache Spark because of its faster training time. On the other hand, since asynchronous training takes full advantage of the worker nodes, it is more efficient than synchronous training. The chart in Fig. 6b shows that the accuracy of the model in all three cases is not significantly different.
Comparison of the CNN model training time and accuracy in Apache Spark cluster and DDLF cluster on MNIST
Comparison of the CNN model training time and accuracy in Apache Spark cluster and DDLF cluster on MNIST
Comparison of the CNN model training time and accuracy in Apache Spark cluster and DDLF cluster on MNIST.
Table 3 shows the details of the experimental results on CIFAR-10. Figure 7 shows charts illustrating the experimental results. Similar to MNIST, experimental results on CIFAR-10 also show that DDLF is more efficient than Apache Spark. The accuracy of the model in all three cases is also almost the same. On the other hand, because CIFAR-10 (containing color images) is more complex than MNIST (containing only black and white images), the training time on CIFAR-10 is much longer than on MNIST.
Comparison of the CNN model training time and accuracy in Apache Spark cluster and DDLF cluster on CIFAR-10
Summary of the comparison of training time on two datasets
Comparison of the CNN model training time and accuracy in Apache Spark cluster and DDLF cluster on CIFAR-10.
By observing the experimental results on both data sets, we can summarize as follows: 1) The performance of DDLF compared to Spark becomes more apparent as the number of epochs is increased or the training dataset is larger. 2) The asynchronous training method always has better performance than the synchronous training method. 3) The accuracy of the model in all three ways of training is almost the same. That is the result of the solutions that we have applied to DDLF. Table 4 summarizes the experimental results on two datasets MNIST and CIFAR-10. On average, synchronous DDLF is 12.80% faster than Apache Spark, asynchronous DDLF is 20.78% faster than Apache Spark, and asynchronous DDLF is 9.15% faster than synchronous DDLF.
In the big data era, small training datasets are increasingly rare. Training DNN in a distributed environment is the goal to aim because of its practical benefits. Apache Spark is considered one of the most prominent big data processing frameworks today. Therefore, many DNN training frameworks have combined with Apache Spark to take advantage of its distributed computing feature. However, the design purpose of Apache Spark is to handle big data, not to train DNN. The forced use of Apache Spark to distributed DNN training faces several challenges, resulting in a reduction in overall system performance. So, we developed the DDLF distributed processing framework, which is completely independent of Apache Spark, overcoming the obstacles we encountered when using Apache Spark to train DNN. Although the original goal of DDLF design was to specialize in training distributed DNN, DDLF can also be used to deploy any type of distributed application. Advantages of the DDLF framework: 1) Simple, easy to deploy distributed application; 2) Make programming natural, and comfortable; 3) Flexible and extensible; 4) High performance. Besides, DDLF also has the following disadvantages: 1) Currently, only Python programming language is supported and requires version from 3.7 onwards due to the inside technique using package asyncio; 2) The utility functions are not many because they are newly developed; 3) The communication cost between the master node and the worker nodes is not optimized.
We will continue to research and improve DDLF as follows: 1) Integrate some important components written in C/C
In addition, we will study using DDLF to train and fine-tune our BERT model and implement a DNN training system using model parallelism.
Footnotes
Acknowledgments
This research is funded by Vietnam National University Ho Chi Minh City (VNU-HCMC) under grant number DS2023-26-01.
Conflict of interest
We have no conflict of interest for this paper.