
Abstract
Prescriptive Performance Analysis (PPA) has shown to be more useful than traditional descriptive and diagnostic analyses for making sense of Big Data (BD) frameworks’ performance. In practice, when processing large (RDF) graphs on top of relational BD systems, several design decisions emerge and cannot be decided automatically, e.g., the choice of the schema, the partitioning technique, and the storage formats. PPA, and in particular ranking functions, helps enable actionable insights on performance data, leading practitioners to an easier choice of the best way to deploy BD frameworks, especially for graph processing. However, the amount of experimental work required to implement PPA is still huge. In this paper, we present PAPAYA,1?> a library for implementing PPA that allows (1) preparing RDF graphs data for a processing pipeline over relational BD systems, (2) enables automatic ranking of the performance in a user-defined solution space of experimental dimensions; (3) allows user-defined flexible extensions in terms of systems to test and ranking methods. We showcase PAPAYA on a set of experiments based on the SparkSQL framework. PAPAYA simplifies the performance analytics of BD systems for processing large (RDF) graphs. We provide PAPAYA as a public open-source library under an MIT license that will be a catalyst for designing new research prescriptive analytical techniques for BD applications.
Introduction
The increasing adoption of Knowledge Graphs (KGs) in industry and academia requires scalable systems for taming linked data at large volumes and velocity [15,29,30]. In absence of a scalable native graph system for querying large (RDF) graphs [25], most approaches fall back to using relational Big Data (BD) frameworks (e.g., Apache Spark or Impala) for handling large graph query workloads [27,28]. Despite its flexibility, the relational model requires several additional design decisions when used for processing graphs, which cannot be decided automatically, e.g., the choice of the schema, the partitioning techniques, and the storage formats.
In [21,24], we highlight the severity of the problem by showing the lack of performance replicability of BD systems for querying large (RDF) graphs. In particular, we showed that changing even just one experimental parameter, e.g., partitioning technique or storage encoding, invalidates existing optimizations in the relational representation of RDF data. We observe that issues do not lay in how the investigations were conducted but rather in the maturity of the analysis, which is limited to descriptive or at most diagnostic observations of the system behaviour. Such discussions leave much work for practitioners to transform performance observations into actionable insights [19].
Later in [19], we have introduced the concept of Bench-Ranking as a means for enabling Prescriptive Performance Analysis (PPA) for processing larger RDF graphs. The PPA is an alternative to descriptive/diagnostic analyses that aims to answer the question What should we do? [14]. In practice, Bench-Ranking enables informed decision-making without neglecting the effectiveness of the performance analyses [19]. In particular, we showed how it could prescribe the best-performing combination of schema, partitioning technique, and storage format for querying large (RDF) graphs on top of SparkSQL framework [18,19].
Our direct experience with big RDF graphs processing confirms what a well-known truth in data engineering and science project, i.e., most time-consuming phases is the data preparation [26], which accounts for 80% of the work.2 In our work, we also show that the performance analytics can be extremely overwhelming, with the maze of performance metrics rapidly increasing with the number of system knobs. Although the Bench-Ranking methodology [19] simplifies performance analyses, a cohesive system that helps automate the intermediate steps is currently missing. In particular, the existing bench-ranking implementation was designed to show the feasibility of the approach as it does not follow any specific software engineering best practices. Thus, the adoption of our Bench-Ranking methodology may face the following challenges:
To address these problems, we extend the work in [19] by designing and implementing an open-source library called PAPAYA (Python-based Approach for Performance Advanced Yield Analytics). The main intention of this tool was to reduce our efforts while preparing the pipeline of processing large RDF KGs on Big relational engines (specifically the data preparation phase) and whilst applying the Bench-Ranking methodology for providing prescriptive analyses on the performance results. Yet, we still believe we designed PAPAYA in a way that makes it useful and handy for practitioners to process large KGs.
The PAPAYA library stems from the following objectives: (O.0) reducing the engineering work required for graph processing preparations and data loading. (O.1) reproducing existing experiments (according to user needs and convenience) for relational processing of SPARQL queries using SparkSQL. This will reduce massive efforts for building analytical pipelines from scratch for relational BD systems subject to the experiments. Moreover, PAPAYA also aims at (O.2) automating the Bench-Ranking methods for enabling post-hoc prescriptive performance analyses described in [19]. In practice, PAPAYA facilitates navigating the complex solution space via packaging the functionality of different ranking functions as well as Multi-Optimization (MO) techniques into interactive programmatic library interfaces. Last but not least, (O.3) checking the replicability of the relational BD systems’ performance for querying large (RDF) graphs within a complex experimental solution space.
The focus of this paper is to show the internals and functionality of PAPAYA as a means for providing PPA for BD relational systems that query large (RDF) graphs. For completeness, we aim to describe PAPAYA prescriptions with the WatDiv benchmark [5] experiments.3 In [19], we applied Bench-Ranking to the

PAPAYA dynamicity.
Several tools and recommendation frameworks exist to reduce the effort required to design and execute reproducible experiments, share their results, and build pipelines for various applications [16]. For instance, the RSPLab provides a test-drive for stream reasoning engines that can be deployed on the cloud. It enables the design of experiments via a programmatic interface that allows deploying the environment, running experiments, measuring the performance, and visualizing the results. In their work outlined in [3], the authors tackled the problem of quantifying the continuous behavior of a query engine and presented two novel experimental metrics (dief@t and dief@k) that capture the performance efficiency during an elapsed period rather than a constant time. These metrics evaluate the query engine performance based on the query processing logs at various times (t) and various results (k). On another side, gMark [7] presents a flexible, domain-agnostic, extensible graph dataset generator driven by schemas. Additionally, it furnishes query workloads tailored to anticipated selectivity. Similarly, authors in [6] provide a data loader that facilitates generating RDF graphs in different logical relational schemas and physical partitioning options. However, this tool stops the work of data generation and data loading. This tool leaves the work of deciding the best experimental solutions for the data/knowledge engineers.
The mentioned efforts aim at providing the environment that enables the practitioners to develop their experimental pipelines. Nonetheless, none of these efforts provide prescriptive performance analyses in the context of BD problems. Conversely, PAPAYA aims to cover this timely research gap in an easy and extensible approach, facilitating the building of an experimental solution space for processing large RDF KGs, hence automating PPA where possible.
Background
This section presents the necessary background to understand the paper’s content. We assume that the reader is familiar with the RDF data model and the SPARQL query language.
RDF relational processing experimental dimensions
Several design decisions emerge when utilizing relational BD systems for querying large (RDF) graphs, such as the relational schema, partitioning techniques, and storage formats. These experimental dimensions directly impact the performance of BD systems while querying large graphs. Intuitively, these dimensions entail different choice options (we call them dimensions’ parameters).
First, the
BD platforms are designed to scale horizontally; thus, data partitioning is another crucial dimension for querying large graphs. However, choosing the right
Serializing RDF data also offers many options such as RDF/XML, Turtle, JSON-LD, to name a few. On the same note, BD platforms offer many options for reading/writing to various file formats and storage backends. Therefore, we need to consider the variety of
Bench-ranking in a nutshell
This section summarizes the concept of Bench-Ranking as a means for Prescriptive Performance Analysis. Bench-Ranking is based on three fundamental notions, i.e., Configuration, Ranking Function, and Ranking Set, defined below.
A configuration c is a combination of experimental dimensions. The configuration space
In [19], we consider a three-dimensional configuration space, i.e., including relational schemas, partitioning techniques and storage formats. Figure 2 shows the experimental space and highlights the example of the (a.ii.3) configuration, which is akin to the Single Triples (ST) schema, Subject-based Partitioning (SBP) technique, and stored in the HDFS (ORC) storage file format. This naming convention guides configurations reading in the rest of the paper results (figures and tables).

The configuration space
A ranking set
A ranking set is defined by a ranking function
A valid example of a ranking score can be the time required for query executions by each of the selected configurations (see Table 1). The ranking function abstracts this notion (Definition 3). In [19], we consider a generalized version of the ranking function presented in [4], which calculates the rank scores for the configurations as follows:

Configuration rankings by query execution time, e.g., (a.i.1) configuration is at 41th rank in

In Equation (1), R is the rank score of the ranked dimension (i.e., relational schema, partitioning technique, storage format, or any other experimental dimensions). Such that, d represents the total number of parameters (options) under that dimension (for instance five in case of schemas, see Fig. 2),
Example of rank scores [19]


Despite its generalization, Equation (1) is insufficient for ranking the configurations in a configuration set defined
Finally, our Bench-Ranking frameworks include two evaluation metrics to assess the effectiveness of the proposed ranking criteria. In particular, we consider a ranking criterion is good if it does not suggest low-performing configurations and if it minimizes the number of contradictions within an experimental setting. When it comes to PPA, practitioners are not interested in a configuration that is the fastest at answering any specific query in a workload as long as it is never the slowest at any of the queries. To this extent, we identified two evaluation metrics [19], i.e.,
We calculate the conformance according to Equation (2) by positioning an element in a ranking set w.r.t the initial rank score. For instance, let’s consider a ranking criterion 
For coherence, we employ Kendall’s index5 according to Equation (3), which counts the number of pairwise (dis)agreements between two ranking sets, Kendall’s distance between two ranking sets 
We assume that ranking sets have the same number of elements. For instance, the K index between
In this section, we present the requirement analysis for PAPAYA library and describe its architecture (Fig. 3). We elicit PAPAYA’s requirements based on the implementation challenges we discussed in the introduction and on the existing research efforts on benchmarking BD systems for processing and querying large RDF graphs [9,19,22,27,28]. Before delving into the requirements, it is also important to list the assumptions under which PAPAYA is designed. We derive the following assumptions from our work on the Bench-Ranking framework [19].

Papaya architecture and workflow.
Given our assumptions, we can outline the requirements as follows:
This section presents the PAPAYA’s main components and shows how they fulfill the requirements. Table 3 summarizes the requirements for challenges mappings alongside the PAPAYA solutions. PAPAYA allows its users to build an entire pipeline for querying big RDF datasets and analyzing the performance results. In particular, it facilitates building the experimental setting considering the configuration space (described in Definition 1) specified by users. This entails preparing and loading the graph data in a user-defined relational configuration space, then performing experiments (executing a query workload on top of a relational BD framework), and finally analyzing and providing prescriptions of the performance.
Summary of challenges and requirements mapping along with PAPAYA solutions

Summary of challenges and requirements mapping along with PAPAYA solutions
To achieve that, PAPAYA includes three core modules depicted in Fig. 3, i.e., the Data Preparator, the Executor, and the Ranker. Moreover, PAPAYA relies on few core abstractions depicted in Fig. 4, i.e., Configuration, Experiment, Result, and Rank. While detailing each module’s functionalities, we introduce PAPAYA workflow, which also appears in Fig. 3, starting with the input is a configuration file that points to the input N-Triple file with the RDF graph (Fig. 3 step (A)).

PAPAYA internal abstractions.
The first actor in the pipeline is the Data Preparator (DP), which prepares RDF graphs for relational processing. It takes as input a configuration file that includes experimental options of interest. The configuration file is represented by the Configuration abstraction (see Fig. 4), which enables extensibility (
The DP interface is generic, and the generated datasets are agnostic to the underlying relational system. The DP prepares RDF graph data for processing with different relational BD systems, especially SQL-on-Hadoop systems, e.g., SparkSQL, Hive, and Impala. Seeking scalability, the current DP implementation relies on SparkSQL, which allows implementation of RDF relational schema generation using the SQL transformations. Notably, Apache Hive or Apache Impala could be potential candidates for alternative implementation executors. However, SparkSQL also supports different partitioning techniques and multiple storage formats, making it ideal for our experiments [19].
Figure 5 shows a sample of schema generation in PAPAYA DP component. First, the DP transforms the input RDF graph (N-Triples file(s)) into an ST table schema (i.e., Fig. 5 Step (1)), and then other schemas are generated using parameterized SQL queries.7 For instance, the VP and WPT schemas are generated using SQL queries given the ST table as a parameter (i.e., Fig. 5 Step (2), and (3), respectively). While, the ExtVP schema generation relies on VP tables to exist first (i.e., Step (4) in Fig. 5).

RDF relational schema transformations in PAPAYA data preparator.
The
The results logs are then loaded by the
The Rank call allows defining additional ranking criteria (
PAPAYA allows its users to interact with the experimental environment (
Finally, to evaluate the raking criteria, we introduced in Section 3.2 the notions of coherence and conformance (
In this section, we explain how to use PAPAYA in practice, showcasing its functionalities with a focus on performance data analysis, flexibility, and visualizations. In particular, we design our experiments in terms of (i) a set of SPARQL queries that we manually translated into SQL accordingly with the different relational schemas, (ii) RDF datasets of different sizes automatically prepared using our Spark-based DataPreparator, and (iii) a configuration based on three dimensions as in [19], i.e., schema, partitioning techniques, and storage formats.
In Bench-Ranking experiments [19], we used the
Listing 1 shows a full example of PAPAYA pipeline, starting by deciding the configurations (in terms of three dimensions and their options, e.g., list of schemas, partitioning techniques, storage formats to prepare, load, and benchmark) (Listing 1 lines 4–8). Then, an experiment is set up for running, defining the dataset size (e.g., “100M” triples), a list of queries to execute or exclude from the workload, and the configurations (Listing 1 line 10). An executor is defined for running the experiment along with the number of times experiments will be run (Listing 1 line 11). The results (runtime logs) are kept in log files in a specified path (e.g., HDFS or a local disk). The Bench-Ranking phase starts when we have the results in logs (Listing 1 line 13).10 For instance, we call the SDRank (Listing 1 line 15) for calculating rank scores for the “schema” dimension, alongside specifying the number of queries (“q”), and number of options under this dimension (“d” in Equation (1)). The MD-Ranking(i.e., Pareto fronts) is applier in two ways. The first one is called

Experiment design example in PAPAYA
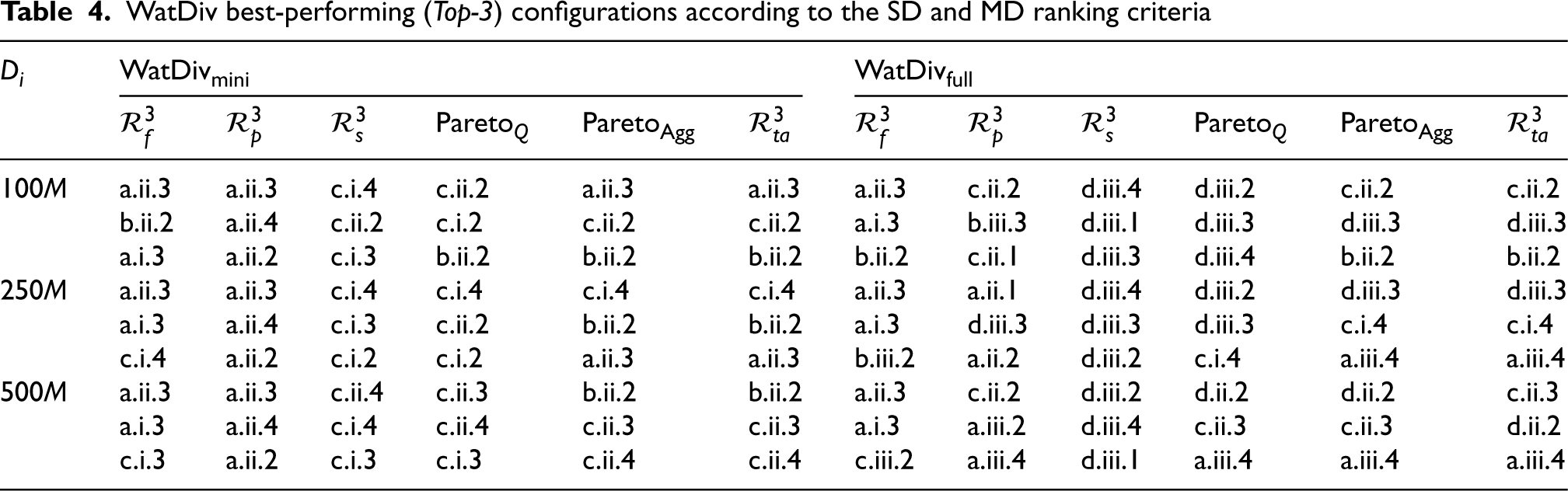
Table 4 shows the top-3 ranked configuration according to the various ranking criteria, i.e., Single-Dimension and Multi-Dimensional (Pareto) for the WatDiv datasets (i.e., 100M, 250M, 500M triples). In addition, Table 5 provides the ranking evaluation metrics (calculated according to Equations (2) and (3)).
WatDiv best-performing (Top-3) configurations according to the SD and MD ranking criteria
Ranking coherence (Kendall distance, the lower the better) & conformance across WatDiv datasets (D1=100M, D2=250M, D3=500M)

To fulfill

Examples on SD rank scores over different dimensions (100M), the higher the better.
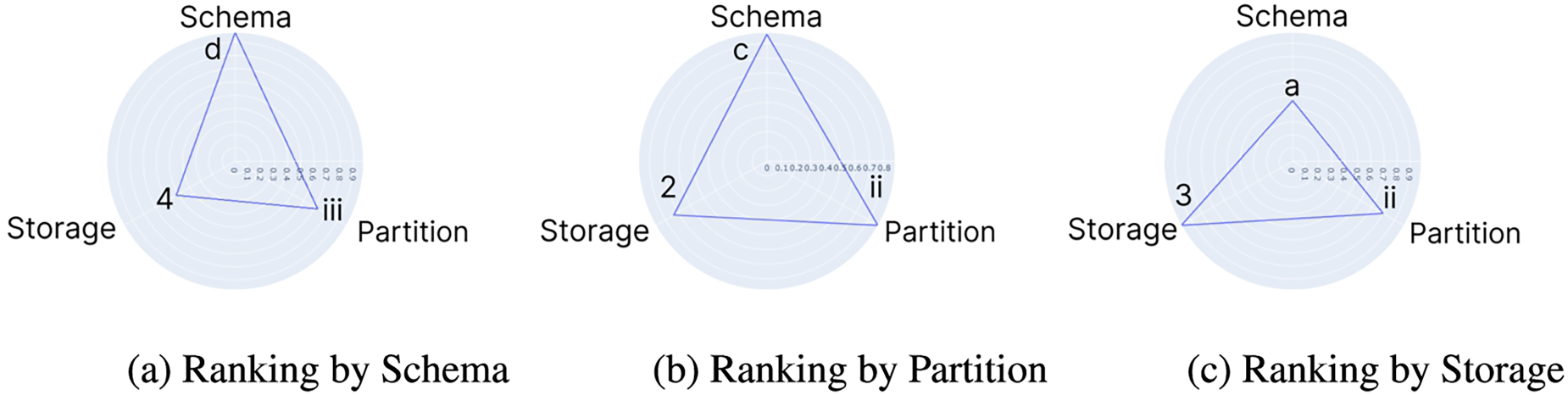
Dimensions trade-offs using single-dimensional ranking (

Pareto fronts, and queries best-worst configuration examples.
PAPAYA visualizations allow explaining the conformance and coherence results using simple plots. For instance, Fig. 9 (a) shows the coherence of the top-5 ranked configurations of the Rs criterion in the 100M dataset while scaling to the larger datasets, i.e., 250M and 500M. PAPAYA explains the conformance of the Bench-Ranking criteria by visualizing the conformance of the top-3 ranked configurations (or any arbitrary number of configurations) with the actual query rankings (Table 1). The green color represents the level of conformance, and the red depicts a configuration that is performing worse than the h worst rankings. Thus, this may explain why

Heatmap shows the coherence of the
Practitioners can also use PAPAYA visualizations for fine-grained ranking details. For instance, showing the best and worst configurations for each query (as shown in Fig. 8 (b) for example of three queries of the WatDiv workload). Such detailed visualizations could help the user rationalize the final prescriptions of PAPAYA.

YAML configuration file for various experiments in PAPAYA
To show an example of the extensibility of PAPAYA, we implement the Bench-Ranking criteria over a subset of the configurations and subset of the WatDiv benchmark tasks (i.e., queries); we call it
The right side of Table 4 shows the top-ranked three configurations according to the specified configurations. Intuitively, results differ according to the available ranked configuration space. For instance, with the inclusion of the ExtVP schema (i.e., ‘d’), it dominates instead of the PT schema (i.e., ‘c’) in
With such flexibility, PAPAYA also provides several dynamic views on the ranking criteria. For example, Table 6 shows the SD ranking of the schema dimension by changing the configuration space. Particularly, it shows how the global ranking of each relational schema (or any other specified dimension) could change by including/excluding configurations of the other dimensions. The table shows that the order of the global schema ranks changes by including all configurations (“Full Conf. Space”) than including/excluding the predicate partitioning or CSV format, i.e., “PBP/!PBP”, “CSV/!CSV”, respectively. For instance, the PT schema global ranking is interestingly oscillating with those changes in the available configurations.
Schemas global ranking across various configurations


Best-performing configurations,

Criteria evaluation (conform.ance, and coher.ence),

In Fig. 10, the triangle sides represent the SD-ranking dimensions’ rank scores. Thus, this criterion aims to maximize this triangle’s area (i.e., the blue triangle). The closer to the ideal (outer red triangle), the better it scores. In other words, the bigger the area of this triangle covers, the better the performance of the three ranking dimensions altogether. The red triangle represents the case with the maximum/ideal rank score, i.e., 
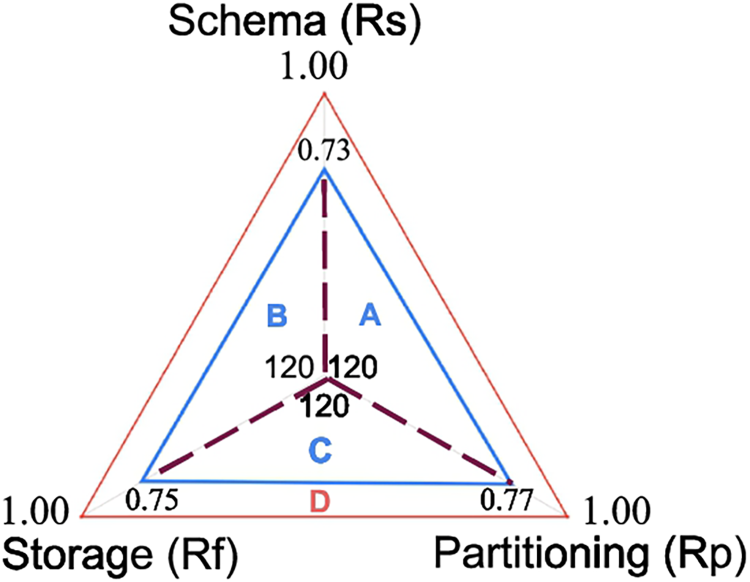
Triangle area criterion.
The formula (Cf. Equation (4)) computes the actual triangle area. Simply, it sums up the triangle area of the three triangles A, B, and C by two of its sides which are the rank scores of each dimension, i.e.,

Plugin the triangle-area as new ranking criterion
It is worth mentioning that the idea behind
PAPAYA also activates the functionality of checking the BD system’s performance replicability when introducing different experimental dimensions. In particular, it enables checking the system’s performance with one specific dimension while changing the parameters of the other dimensions. For example, Figs 11 (a) and (b) respectively show the impact of the partitioning and storage on the performance of the schema dimension. The Figures show how the performance of the system with a configuration can significantly change with changing other dimensions.

Schema replicability across changing partitioning or storage formats.
PAPAYA can also check the performance replicability by comparing two configurations as discussed in [21]. For instance, PAPAYA can compare the schema optimizations (i.e., WPT, and ExtVP) w.r.t their baseline ones (i.e., PT, and VP) while introducing different partitioning techniques and various HDFS storage formats that are different from the baseline configurations [27,28].
Table 9 shows the effect of introducing partitioning techniques (right of the table) and different file formats (left of the table) different from the baseline configurations (i.e., Vanilla HDFS partitioning and Parquet as storage format). The trade-offs effect is evident in the replicability results. Indeed, WPT outperforms PT schema only with
The replicability of schema advancements (i.e., WPT, ExtVP) VS. baselines (i.e., PT, VP), WatDiv 500M dataset


Table 10 provides a concise overview of the objectives, delineating the challenges encountered during their pursuit, and outlines the set of requirements necessary for accomplishing these objectives.
Summary of objectives, challenges, and requirements

This paper presents PAPAYA, an extensible library that reduces the efforts needed to analyze the performance of BD systems used for processing large (RDF) graphs. PAPAYA implements the performance analytics methods adopted in [23,27,28] including an novel approach for prescriptive performance analytics we presented in [19].
Inspired by Gartner’s analysis methodology [11], Fig. 12 reflects the amount of human intervention required to make a decision with the descriptive and diagnostic analyses of the performance results. Descriptive and diagnostic analytics are limited, and cannot guide practitioners directly to the best-performing configurations in a complex solution space. This is shown in this paper with the lack of performance replicability (shown Section 5.3). Indeed, the performance of the BD system is affected by changing the configurations, e.g., oscillating schema performance with changing partitioning, and storage options (Fig. 11). On the other side, PAPAYA aims to reduce the amount of work required to interpret performance data. It adopts the Bench-ranking methodology with which practitioners can easily decide the best-performing configurations given an experimental solution space with an arbitrary number of dimensions. Although descriptive discussions are limited, PAPAYA still provides several descriptive analytics and visualizations on the performance to explain the final decisions given by PAPAYA. PAPAYA also aims to reduce the engineering work required for building an analytical pipeline for processing large RDF graphs. In particular, PAPAYA prepares, generates, and loads data ready for big relational RDF graph analytics.

Performance analysis methodology, and how PAPAYA reduces human intervention in BD analytics.
PAPAYA is developed considering the ease of use and the flexibility aspects allowing extending the library with an additional arbitrary number of experimental dimensions to the solution space. Moreover, PAPAYA provides abstractions on the level of ranking criteria, meaning that the user can use his/her ranking functions for ranking the solution space. Seeking availability, we provide PAPAYA as an open-source library under MIT license and published at a persistent URI. PAPAYA’s GitHub repository includes tutorials and documentation on how to use the library.
As a maintenance plan, PAPAYA’s roadmap includes:
Covering the phase of query evaluation into PAPAYA pipeline. In particular, we plan to provide native support of SPARQL by incorporating native triple stores for query evaluation. Incorporating SPARQL into SQL translation for a given schema, i.e., query translation is a schema-dependent task. This can be approached using advancements of R2RML mapping tools (e.g., OnTop) [8]. Wrapping other SQL-on-Hadoop executors to PAPAYA; thus, the performance of the engines could also be compared as well as enabling benchmarking of other KG data models (e.g., property graphs [17]) in PAPAYA. Using orchestration tools (such as Apache Airflow) to monitor the PAPAYA pipelines. Integrating PAPAYA with tools like gmark [7], which generates graphs and workloads, and ESPRESSO [20], which enables search and query functionalities over personal online datastores as well as personal KGs.
Footnotes
Acknowledgements
We acknowledge support from the European Social Fund via IT Academy programme and the European Regional Development Funds via the Mobilitas Plus programme (grant MOBTT75).
2
Cleaning Big Data: Most Time-Consuming, Least Enjoyable Data Science Task, Survey Says
3
Due to space limits, we diagnose the WatDiv prescriptions results and evaluation metrics in Section 5 on the library GitHub page, mentioned below.
4
Pareto frontier aims at finding a set of optimal solutions if no objective can be improved without sacrificing at least one other objective.
5
Kendall is a standard measure to compare the outcomes of ranking functions.
7
schema SQL-based transformations are kept in the DP module on PAPAYA’s GitHub repository due to space limits.
8
Nonetheless, seeking conciseness, we keep
9
Benchmarks’ query workload (in SQL) and experiments runtimes:
10
It is worth noting that the performance analyses, e.g., Bench-Ranking, could start directly if the performance data (logs) are already present.
11
12
Due to space limits, we keep other Pareto figures on the PAPAYA GitHub page.
13
Notably, the Rp and Rta criteria cannot be calculated when excluding the partitioning dimension.