
Abstract
Learning the similarity between fashion items is essential for many fashion-related tasks. Most methods based on global or local image similarity cannot meet the fine-grained retrieval requirements related to attributes. We are the first to clearly distinguish the concepts of attribute name and their values and divide fashion retrieval tasks that combine images and text into: attribute-guided retrieval and attribute-manipulated retrieval. We propose a hierarchical attribute-aware embedding network (HAEN) that takes images and attributes as input, learns multiple attribute-specific embedding spaces, and measures fine-grained similarity in the corresponding spaces. It can accurately map different attributes to the corresponding areas of the image, thereby facilitating the feature fusion of two different modalities of text and image, including enhancement and replacement. Then on this basis, we propose three attribute-manipulated similarity learning methods, HAEN_Avg, HAEN_Rec, and HAEN_Cmb. With comprehensive validation on two real-world fashion datasets, we demonstrate that our methods can effectively leverage semantic knowledge to improve image retrieval performance, including attribute-guided and attribute-manipulated retrieval tasks.
Introduction
Fashion image retrieval [1, 2, 3, 4] refers to retrieving images that meet the user’s search intent. Traditional image retrieval systems only allow users to use text or image queries to express their search intent. It is difficult for users to describe their search intention through a single textual query in actual scenarios. Meanwhile, it is also difficult for users to find ideal images to express their intention accurately. In some cases, users want to search for fashion items with similar designs instead of roughly the same or similar items. There is also a situation where users want to query images similar to a given image but have other characteristics. Figure 1 shows these two different requirements of users for image retrieval tasks. The first two are based on a given image and an attribute and query other similar images with the same attribute value, such as neckline design in (a-1) and sleeve design in (a-2). The latter two are based on a given image and an attribute value and query similar images with the new attribute values, such as red/flowers in (b-1) and mini blue in (b-2). These detailed requirements need to combine the text description of the image and the image itself in the search.
Four examples of composing text and image for image retrieval. The query conditions are listed on the left, and the results that meet user requirements are on the right.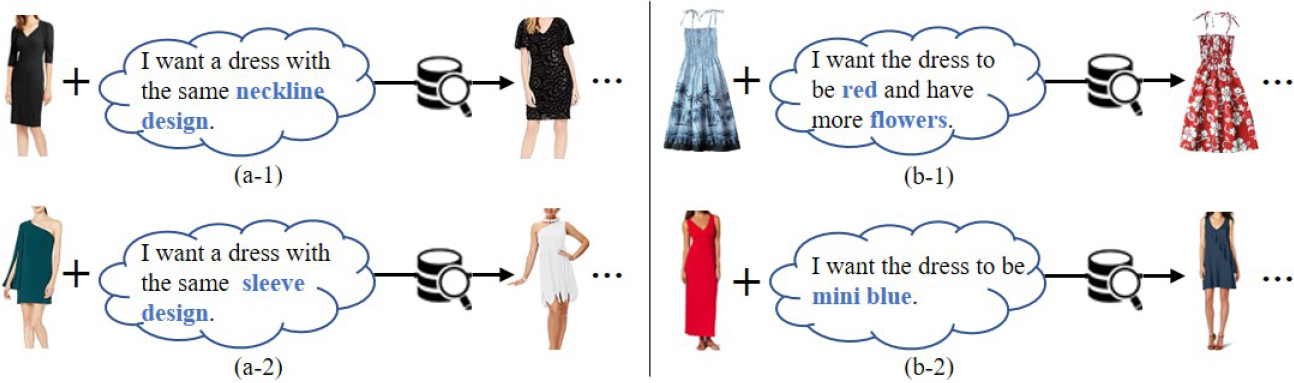
With the development of deep learning, deep neural networks have been widely used in clothing retrieval tasks and achieved remarkable results. Most of the methods that have been proposed are to learn a joint embedding space so that the item similarity can be measured by calculating their distance in the space [2]. However, such coarse-grained methods are usually affected by occlusion, cropping, or different views between the original and the target images [3].
Composing text and image for image retrieval (CTI-IR) or conditional image retrieval is a new yet challenging task [4, 5, 6]. The input query is not the conventional image or text but a composition, i.e., a reference image and its corresponding modification or enhancement text. The text gives additional conditions which describe the semantic modification or enhancement from the query image to the target gallery images. The main challenge comes from the semantic fusion of image and text, i.e., the feature mapping and fusion of two types of different modal data [7].
Therefore, this paper will focus on understanding the semantics between text and images and design a multi-modal similarity learning network for two types of retrieval tasks. The main contributions of this paper are summarized as follows:
To our best knowledge, we are the first to clearly distinguish the concepts of attribute name and their values, which will facilitate future related research. We use attributes and attribute labels to represent them in this paper. Meanwhile, we also categorize fashion retrieval by combining text and image into two categories: attribute-guided and attribute-manipulated fashion retrieval. We propose a hierarchical attribute-aware embedding network (HAEN) for semantic mapping between images and attributes. Given an attribute, HAEN can accurately map it to the corresponding areas of the image, thereby facilitating the feature fusion of two different modalities of text and image, including enhancement and replacement. We also propose three similarity learning methods based on HAEN for attribute-manipulated image retrieval tasks, HAEN_Avg, HAEN_Rec, and HAEN_Cmb. HAEN_Cmb is a fusion of the first two approaches, taking full advantage of their strengths to obtain better results than the baseline. We are the first to propose a network to unify the two tasks, i.e., attribute-guided and attribute-manipulated retrieval tasks. Extensive experiments conducted on two real-world datasets validate the superiority of our network.
The remainder of this paper is organized as follows. Section 2 briefly reviews the related work. Section 3 details the proposed network HAEN and its three variants. The experimental results and analysis are presented in Section 4, followed by the conclusion and future work in Section 5.
Fashion retrieval
Content-based image retrieval methods have attracted wide attention due to their convenience and accuracy [8, 9]. Most of the current research works on fashion retrieval follow global similarity computation and matching, e.g., they use CNN (convolutional neural network) or other deep learning networks to aggregate local features into a single global representation and then perform similarity calculations [10, 11]. To obtain local features of images and pay attention to the fine-grained similarity, Veit et al. [12] proposed to use a set of masks to select the embedding dimensions related to specific attributes and calculated the similarity based on the mask embedding vector. Kuang et al. [3] proposed a graph reasoning network to build a similarity pyramid, which represents the similarity by considering both global and local features. However, retrieval that only relies on images will be affected by certain factors such as occlusion and cropping. Attribute labels play an important role in fine-grained retrieval [13]. Ma et al. [14] proposed a fashion similarity learning network and used both image and the attributes to specify user’s query intent to perform attribute-guided fine-grained retrieval. This idea also attracted the attention of other researchers [5, 15]. How to perform feature fusion between text attributes and images, and map images to different attribute-related embedding spaces is significant for accurate retrieval, and it is still worthy of further research. Therefore, this paper will use multi-modal data (text
Composing text and image for image retrieval
Although CNN and related deep learning networks are widely used to learn the visual features of images, they cannot efficiently compose visual representations and natural-language semantics. Combined image and text for image retrieval incorporates user feedback into the image retrieval task to guide or modify the image retrieval results according to user expectations. Vo et al. [7] introduced a residual gating operation to fuse image and text embeddings, while Chen et al. [16] concatenated the text embedding at multiple layers of the image CNN to extract the composite representations. To find a more fine-grained semantic relationship between text and image, Jandial et al. [5] introduced a pyramid gated fusion mechanism that uses CNNs-based hierarchical visual representations across different abstractions to generate fine-grained Visio-linguistic embeddings and leverages their coarse hierarchy structure to learn the final compositional representation. Wen et al. [4] designed two composition modules: fine-grained local-wise and global-wise composition modules, and used a mutual enhancement module to promote them to share knowledge. Despite the outstanding progress of these studies, they do not consider the effect of attribute relationships on the effectiveness of identifying fine-grained differences in images. In this paper, we will study fine-grained semantic associations between attributes and images for the task of image retrieval for text-conditioned image retrieval tasks.
Attention mechanism in multi-modal similarity learning
In the field of text
Methodology
Problem formulation
Examples of attributes and their corresponding attribute labels
Examples of attributes and their corresponding attribute labels
where
The aggregation function usually refers to the average pooling or max-pooling operator. The similarity function is often realized by the Cosine similarity or Euclidean distance. However, the aggregation function might aggregate noisy features such as clutter background, other objects, or unique regions, which can only be observed in the query or the gallery when existing occlusions, cropping, or different views. Therefore, local similarity, only considering the characteristics of a particular aspect or a few aspects, is also considered. The local similarity is defined as
where
where
where
The proposed HAEN consists of five key modules: (a) feature extraction, (b) hierarchical attribute embedding (HAE), (c) attention, (d) mask, and (e) embedding branch.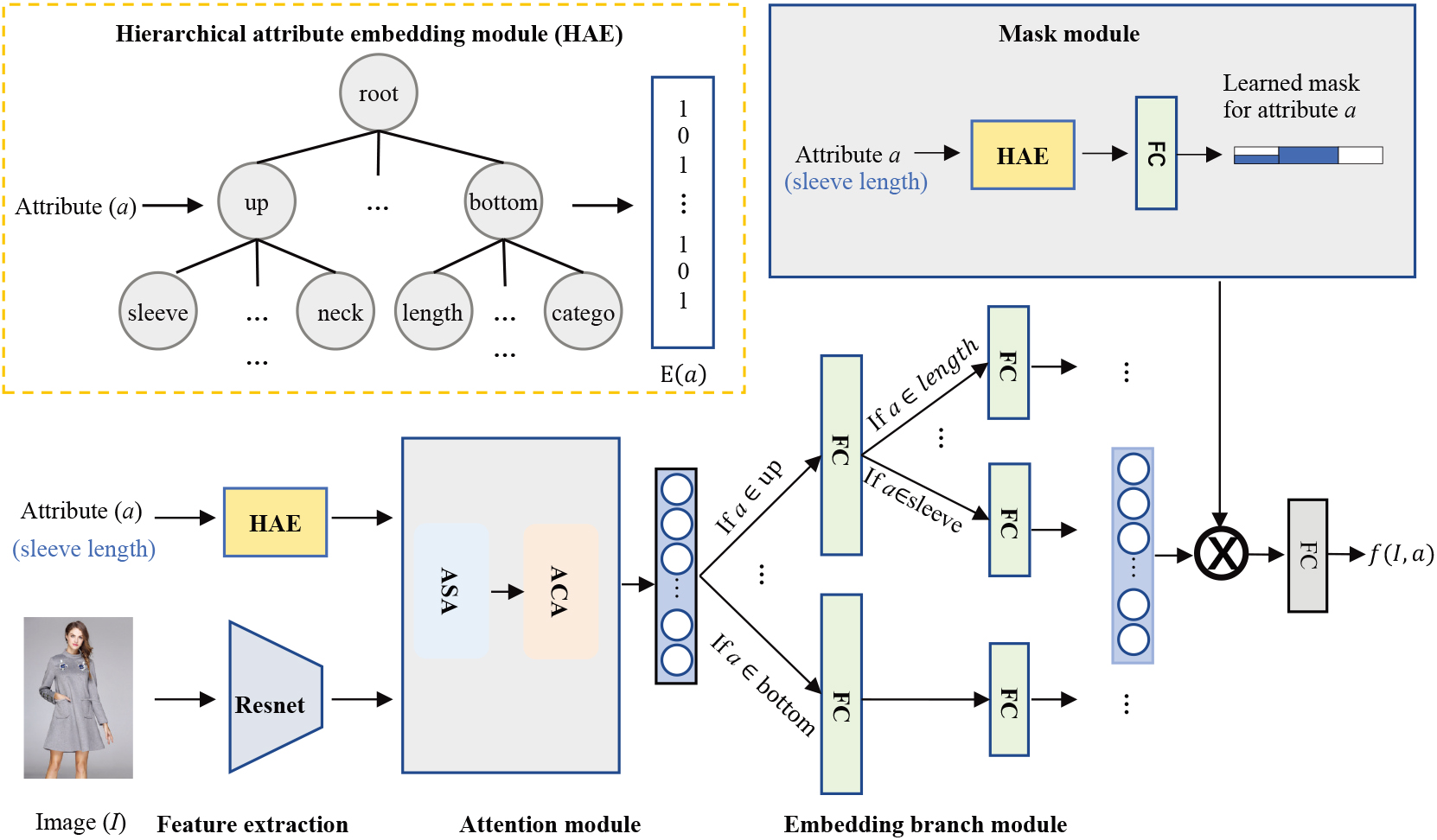
Figure 2 is an overview of our proposed hierarchical attribute-aware embedding network, which contains five modules: feature extraction module, HAE module, attention module, mask module, and embedding branch module. First, we adopt a CNN model such as Resnet pre-trained on ImageNet [19] as the backbone network for feature extraction. To retain the spatial information of the image, we remove the last fully connected (FC) layer of the pre-trained CNN model. The image feature is represented as
The categories and attributes of fashion products provide clues to identify similarities in fashion products. As shown in Fig. 2, tops are associated with attributes such as “sleeve length” and “neckline”, while pants do not have these attributes. When we represent the attributes with one-hot vectors, the distance between sleeve length and neckline and that between sleeve length and pant length are the same, which is not consistent with the perception of human experts. We need to learn the relationship between these attributes, which will significantly increase the amount of information of the original input, which will help the model learn the relationship among attributes.
Based on the knowledge of fashion experts, we represent fashion attributes with a hierarchical structure. These attributes come from two fashion datasets, FashionAI and DARN. These attributes form an attribute tree, where each leaf node denotes an attribute value, aand the parent node denotes attribute names or categories. Among them, some parent nodes contain multiple child nodes, and sibling nodes will share the characteristics of the parent node, e.g., “sleeve” and “neck” are sibling nodes, and their parent node is “up”. We introduce an operator “
where
Some recent studies employ attention mechanisms to locate salient meaningful regions and identify potential associations between image regions and outputs. Considering that attribute-guided features are related to specific regions and styles of images, inspired by [14], we use two attention modules, ASA and ACA, to capture attribute-related features.
where
where
where
where
On the other hand, We encode the vector of attributes with a separate attribute embedding. An embedding layer is used to embed attribute
where
where
Two consecutive FC layers are employed on the channel attention output
where
To disentangle similarity feature
where
Finally, we further employ an FC layer over
where
We use the triplet ranking loss to learn the similarity vector, which is proven effective in embedding learning tasks [20, 21]. Assume that
where
where
In the field of fashion, for attribute-manipulated retrieval tasks, the popular method is feature substitution [1], i.e., the feature corresponding to the modified label in the image is replaced with the feature value of the new label. The feature value of each label is calculated in advance. For example, it uses the feature value of the “3/4 sleeves” label to replace the feature corresponding to the “sleeveless” label of the input image.
Since HAEN can help extract the characteristics of each attribute corresponding to a given image, we propose the method HAEN_Avg to implement the attribute-manipulated fashion retrieval. The specific steps are as follows.
Step 1. Extract the feature value of each label in the image gallery. For any image in the gallery, we feed the image features and each attribute value into the HAEN model to obtain the attribute-guided image features
Step 2. Calculate the mean vector of each label. Then we get the mean feature values of all labels.
Step 3. Replace the input image feature with the mean image features correlated to the input label. Suppose there is an input
Step 4. Similarity computation. For the input
The HAEN_Avg method is simple and easy to understand [1], but it ignores the information of other attributes. Moreover, it replaces individuals with global average characteristics, which may result in the loss of individual variability. So we propose HAEN_Rec, a feature substitution method based on reconstruction. The core of this method is the reconstruction module, whose object is to to generate new features based on the target label. Figure 3 shows the overview of the proposed HAEN_Rec.
The proposed HAEN_Rec consists of two parts: (a) HAEN and (b) reconstruction module.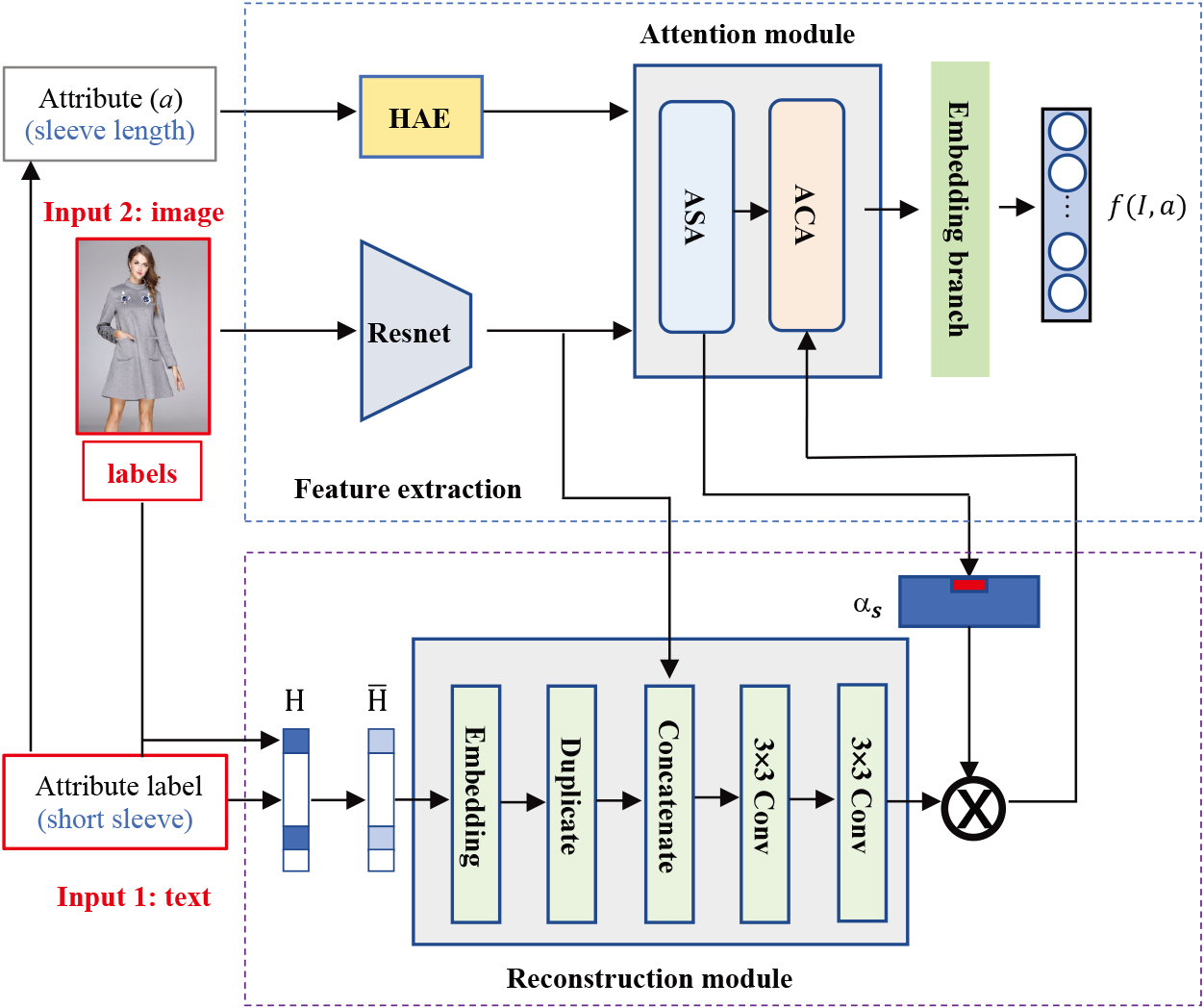
Each attribute
After preprocessing, the image is represented as
where
To fuse the image with the manipulation label, we still need to pay attention to the spatial regions and channels related to the modified attribute in the image features. We also use ASA module and ACA module to get the attention weights
HAEN_Rec is based on HAEN, so we first train the HAEN model and then train the reconstruction module after fixing the HAEN parameters. We also use the triplet ranking loss as the loss function. First, we construct a set of triples
where
Given an image
Step 1. Input
Step 2. Feed the attribute manipulation indicator of
Step 3. Replace the original feature and get
Step 4. Calculate the similarity between
The effect of the HAEN_Rec method depends on the clarity of the original query image. In actual scenes, many clothing images are occluded or distorted. At this time, the valuable information contained in the reconstructed attribute features obtained by this method may not be as much as HAEN_Avg. So, we propose a combination method, HAEN_Cmb, which uses an attention-based adaptive feature fusion module to integrate the processing results of the two methods, and adaptively adjust the weights to obtain the target feature vector that meets the needs more.
The adaptive fusion module.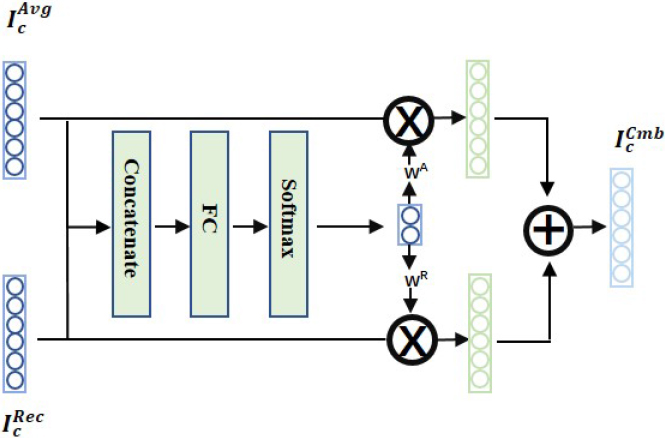
Figure 4 shows the structure of the adaptive fusion module. The input includes two parts: image feature
Step 1. Feed the concatenated vector of
where
Step 2. Assuming that the weights corresponding to HAEN_Avg and HAEN_Rec are
where
In this section, we perform extensive experiments on two benchmark datasets to evaluate our proposed HAEN and HAEN-based methods. We aim to answer the following research questions:
RQ1: Can our proposed HAEN perform better than other competitive models on attribute-guided fashion retrieval tasks?
RQ2: Can our proposed models based on HAEN perform better than other competitive models on attribute-manipulated fashion retrieval tasks?
RQ3: Are the key components in HAEN (i.e., HAE method, mask technique, and embedding branch) helpful for improving retrieval results?
RQ4: What is the visual effect of the attention mechanism in the model?
Experimental settings
FashionAI [22] is a large-scale, high-quality fashion dataset. There are 8 attributes with 245 attribute values covering 6 categories of women’s clothing. Each attribute (e.g., sleeve length) is associated with a list of multiple attribute values (e.g., sleeveless, cup sleeve, and short sleeve). In our experiment, we split the dataset into three subsets for training/validation/testing at a ratio of 8:1:1 and train the model by constructing triplets from the training set. Concretely, for the triplet with respect to the sleeve length attribute, we randomly sampled two images with the same attribute value sleeveless as a similar pair and an image with a different sleeve length value as a dissimilar one.
DARN [2] is a fashion dataset collected for cross-domain image retrieval tasks. The dataset contains 253,983 images, and each image is annotated with 9 fashion attributes, and the total number of attribute values is 179. After delete the broken URLs, 200,580 images are obtained for our experiments. We sampled the triplets in a similar way to the FashionAI dataset.
For attribute-manipulated retrieval, we use top-k recall rate as the evaluation metric. It is defined as
where
For two different tasks, we use different baselines. We use four different models for experimental comparisons of attribute-guided retrieval tasks. To make a fair comparison, we use Resnet50 pre-trained on ImageNet as the image feature extraction network for all models.
Standard Triplet Network (STN) [12]: It is a simple similarity learning model by adding an FC layer as the embedding layer after the Resnet feature extraction network. The network parameters are updated through the backpropagation according to the triplet loss. Through the training of all triplets, STN aims to learn the similarity measure space of all attributes. Conditional Similarity Networks (CSN) [12]: As an extended model of STN, CSN uses a learned mask to select relevant dimensions of the embedding space to model the specific attribute similarity. Attribute-Specific Embedding Network (ASEN) [14]: This model has achieved the best performance in the field. It learns attribute-guided embedding space for fine-grained fashion similarity prediction. HAEN: Proposed in this paper, HAEN leverages the hierarchical attribute embedding of a specific attribute as a condition. Two attention modules are applied to extract the features related to the attribute firstly. Then, it integrates the feature information through the embedding branch module and selects the dimension related to the attribute through the mask module. w/o HAE: It is a variant of HAEN. It feed the one-hot vector into the attention module and HAE into the mask module to get the output features of the final FC layer.
MAP of specific attribute-based retrieval on FashionAI
To demonstrate that using specific attribute spaces to measure fashion similarity is better than using a general space, Table 2 shows the retrieval results of different models on each attribute on the FashionAI dataset, and we get the following observations.
STN performs the worst, and its MAP value is only 38.52. The MAP value of CSN is 54.47, which is an increase of 41.41% compared to STN. ASEN performs better. Compared with STN and CSN, its MAP value has increased by 58.41% and 12.02%, respectively. The main reason is that the model uses the attention mechanism to extract more relevant features to the specific attribute. Compared with ASEN, HAEN proposed in this paper has a 5.11% improvement in MAP.
We also conduct experiments on the DARN dataset. Table 3 shows the retrieval results of different models on each attribute. The observations we get are similar to Table 2.
AMNet is a classic model for attribute manipulation retrieval tasks and has been used as a benchmark in many studies. We compare the proposed methods with AMNET in the following experiment.
We set
MAP of specific attribute-based retrieval on DARN
MAP of specific attribute-based retrieval on DARN
Top-k recall rate of attribute-manipulated retrieval on FashionAI.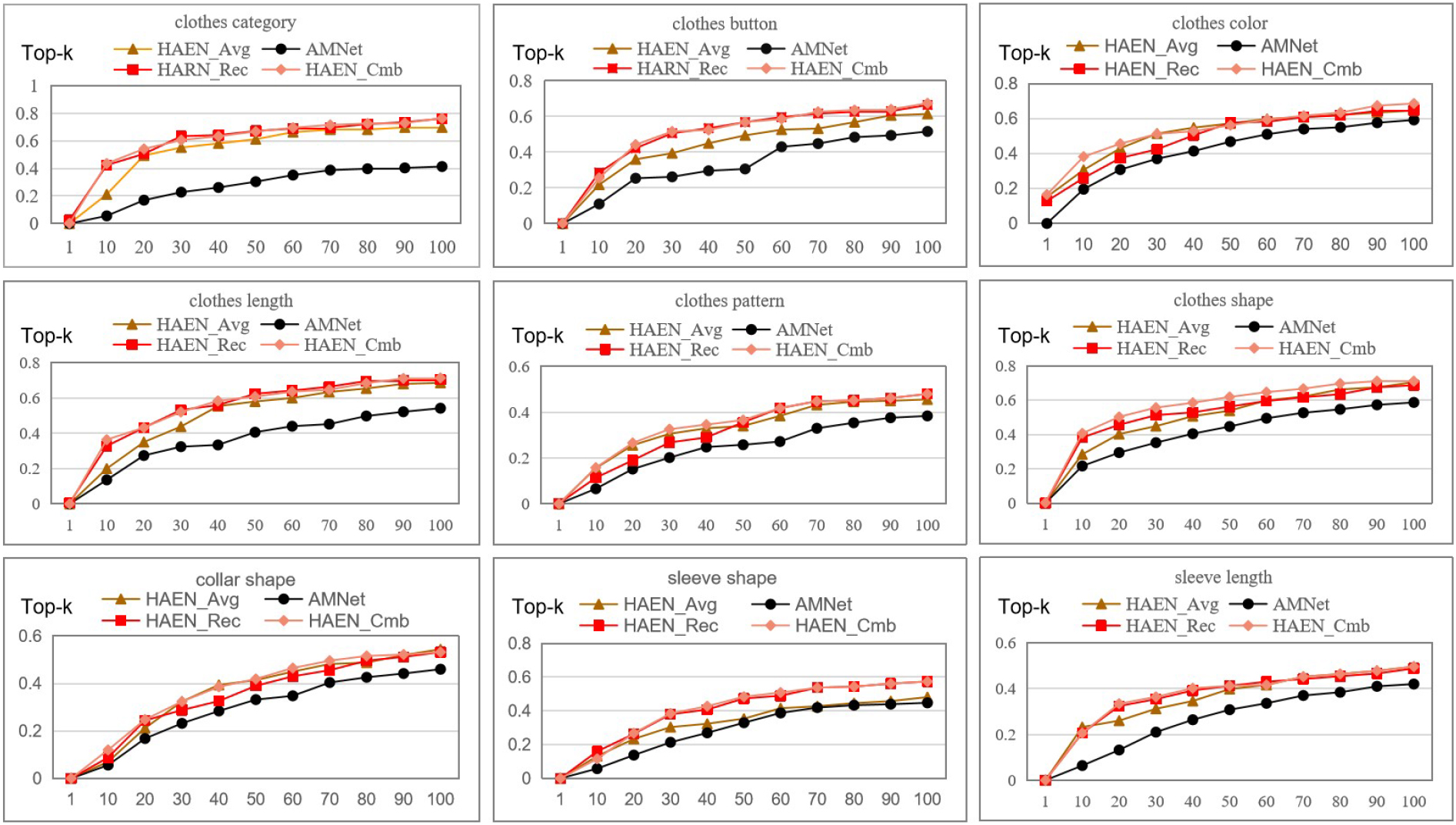
As For six attributes such as clothes_category, clothes_button, clothes_length, clothes_shape, sleeve_shape, and sleeve_length, HAEN_Rec performs better than HAEN_Avg, which proves the effectiveness of the reconstruction module. However, HAEN_Rec does not perform as well as HAEN_Avg for the two attributes of clothes_color and clothes_pattern. The fact is that there is no clear correlation between these attributes and the regional characteristics of an image. In this case, the average embedding feature can be used for similarity calculation, while the reconstructed embedding feature will have a negative effect and is not suitable for similarity calculation. The HAEN_Cmb method combines the structures of HAEN_Avg and HAEN_Cmb and allows them to complement each other through an adaptive feature attention module. It can be seen from the figure that for all attributes, no matter how k changes, HAEN_Cmb performs best, and its top-k curve is smoother, which proves the effectiveness of the proposed adaptive feature attention module.
The impact of HAE method
Parameter statistics of different models
Parameter statistics of different models
The relationship between fashion attributes, especially the hierarchy relationship, is a kind of effective information that can be used. We use a hierarchical attribute coding method to embed information into the model so that the attention module can learn the hierarchy structure between attributes. It can be seen from Tables 2 and 3 that HAEN (using the HAE method) can help improve retrieval precision and prediction accuracy compared to HAEN w/o HAE. Table 4 shows that the number of training parameters of HAEN is less than that of ASEN. These results prove the effectiveness of hierarchical relationships among attributes for fashion retrieval.
Therefore, when representing item features, we first share the same FC layer to integrate feature information according to the hierarchical relationship between attributes and then use an embedded layer. When some attributes share specific characteristics, their embedding space should be shared in some dimensions. Thus, we use a mask operation similar to [12] to select specific dimensions for sub-nodes to measure their similarity. Figure 6 shows an instance of the mask technique. It can be observed that in the mask graph, compared with two child nodes under different parent nodes, such as “neck_design” and “lapel_design”, “pant_length” and “skirt_length”, have more overlapping in some dimensions.
The impact of embedding branch module
To see the effectiveness of the EB module, we add it to the ASEN model. The new model is called ASEN
MAP of specific attribute-based retrieval
MAP of specific attribute-based retrieval
Visualization of the mask operations on certain attributes.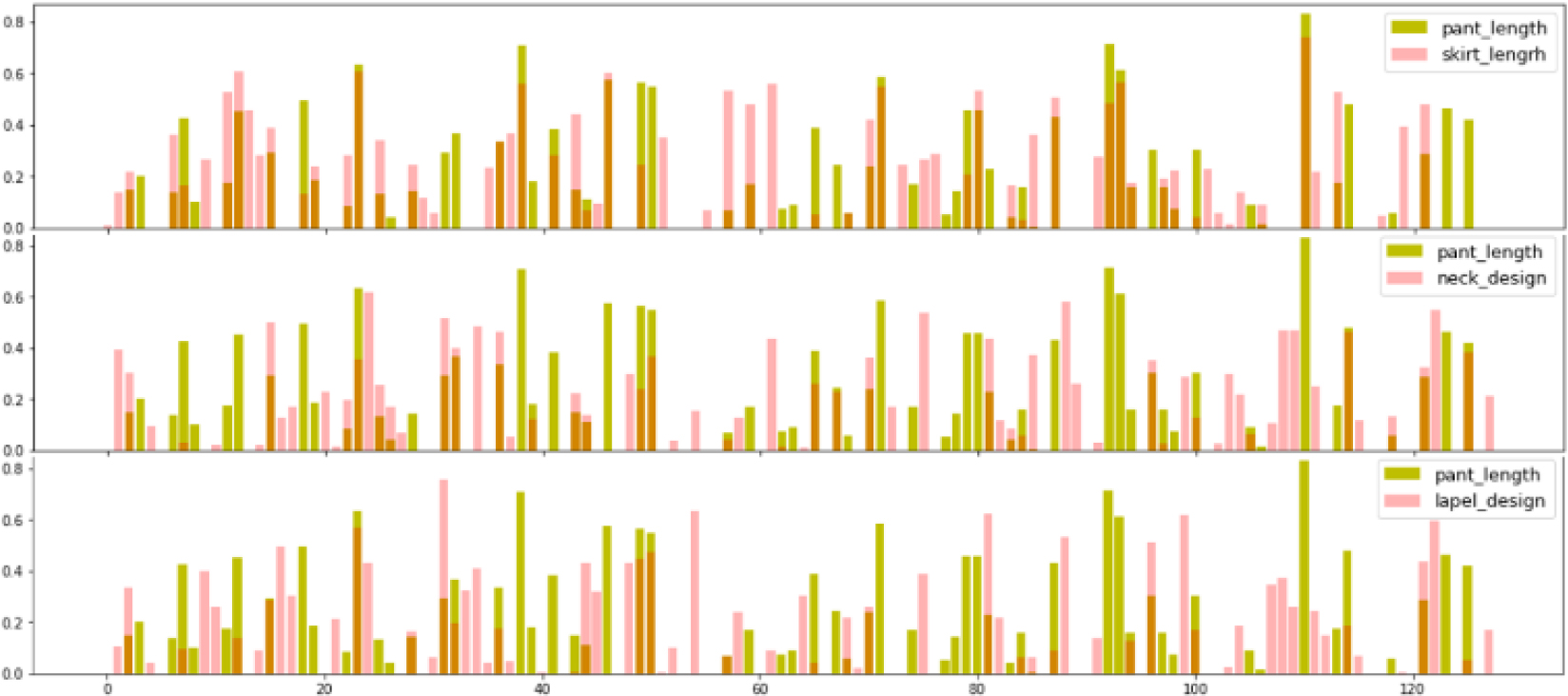
Two instances of attribute-guided fashion retrieval on FashionAI. The area in the red bounding box corresponds to the given attribute. The blue bounding boxes indicate that the images have the same label as the given image in terms of the given attribute. The green ones mean the images do not include the same label.
Two instances of attribute-manipulated fashion retrieval on FashionAI. The blue bounding box indicates that the image attributes are consistent with the query conditions, and the green indicates that the image attributes do not meet the query conditions.
Heatmaps of different attributes on different models.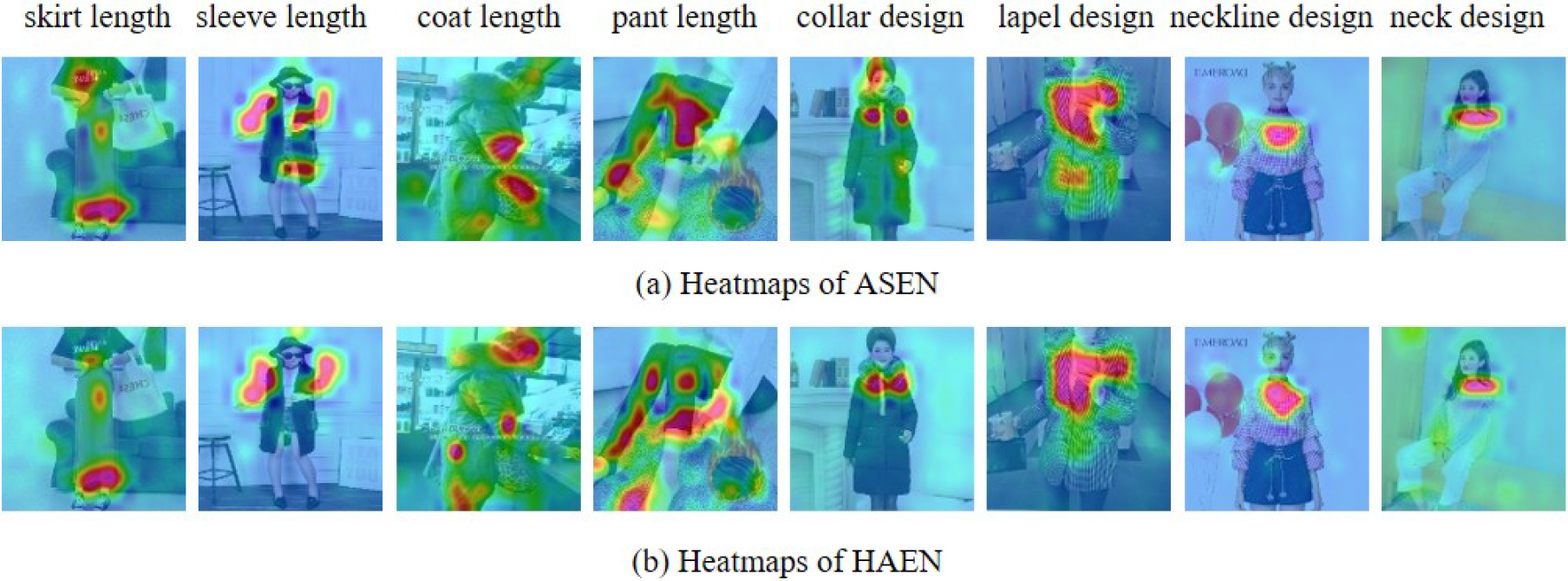
From Table 5, we can see that ASEN+EB performs best. It proves the effectiveness of the EB module. However, ASEN
Image retrieval visualization
To further demonstrate the effectiveness of the proposed method, the following will take a look at the effect of the proposed methods through application examples on two different tasks. Figure 7 shows two instances of attribute-guided fashion retrieval on the FashionAI dataset with given attributes by using HAEN. These results demonstrate that our HAEN is good at capturing the attribute-specific fine-grained similarity among fashion items. Figure 8 shows two instances of attribute-manipulated fashion retrieval on the FashionAI dataset.
Attention visualization
To verify the ability of the attention modules in HAEN to locate areas based on attributes, we visualize the attribute-guided attention function on fashion images. Figure 9 shows the comparison between HAEN and ASEN. The following two points can be seen.
The attention module in HAEN can more accurately identify the area related to a certain attribute in the fashion image. For example, in Fig. 9, for the attribute skirt length, ASEN mistakenly positions the focus in the middle of the coat, while HAEN accurately identifies the beginning and end of the skirt. For the attribute collar design, ASEN focuses on the human head, with only two scattered areas related to the attribute, while HAEN locates the continuous area related to the attribute. For some images with complex scenes, both ASEN and HAEN do not perform well when paying attention to specific attributes such as coat length and pant length. However, HAEN can find the beginning and end positions of the coat when paying attention to the coat length attribute, while ASEN incorrectly locates the attribute on the sleeves of the clothes.
Aiming at the problem of using text and image information for a query in the fashion field, we propose for the first time in this paper to distinguish two tasks: attribute-guided image retrieval and attribute-modified image retrieval. We propose a similarity learning network HAEN based on the attention mechanism, which can learn the semantic relationship between text attributes and images. The extensive experiments show that compared with the state-of-the-art methods, HAEN performs better in attribute-specific similarity learning by using the hierarchical relationship between attributes and obtains competitive results in attribute-guided retrieval tasks. Based on HAEN, HAEN_Avg, HAEN_Rec, and HAEN_Cmb methods are proposed for attribute-manipulated retrieval tasks. HAEN_Cmb is a fusion of the first two methods, absorbing their advantages and obtaining much better results than the baseline. Since HAEN training requires images to be labelled, accurate image annotation is critical to improving retrieval performance. Therefore, we will study the multi-label classification and automatic labelling of fashion images in our future work.