
Abstract
Feature Evolvable Stream Learning (FESL) has received extensive attentions during the past few years where old features could vanish and new features could appear when learning with streaming data. Existing FESL algorithms are mainly designed for simple datasets with low-dimension features, nevertheless they are ineffective to deal with complex streams such as image sequences. Such crux lies in two facts: (1) the shallow model, which is supported to be feasible for the low-dimension streams, fails to reveal the complex nonlinear patterns of images, and (2) the linear mapping used to recover the vanished features from the new ones is inadequate to reconstruct the old features of image streams. In response, this paper explores a new online learning paradigm: Feature Evolvable Learning with Image Streams (FELIS) which attempts to make the online learners less restrictive and more applicable. In particular, we present a novel ensemble residual network (ERN), in which the prediction is weighted combination of classifiers learnt by the feature representations from several residual blocks, such that the learning is able to start with a shallow network that enjoys fast convergence, and then gradually switch to a deeper model when more data has been received to learn more complex hypotheses. Moreover, we amend the first residual block of ERN as an autoencoder, and then proposed a latent representation mapping (LRM) approach to exploit the relationship between the previous and current feature space of the image streams via minimizing the discrepancy of the latent representations from the two different feature spaces. We carried out experiments on both virtual and real scenarios over large-scale images, and the experimental results demonstrate the effectiveness of the proposed method.
Keywords
Introduction
In many practical applications, data usually comes in a streaming way, and hence, Feature Evolvable Stream Learning (FESL), which aims to tackle the streaming data problem, has abstracted considerable attentions in recent years [1, 2, 3, 4, 5]. Specifically, in an open and dynamic environment, data instances arrive at different time steps, where previous features vanish and new features appear. For instance, when we deploy surveillance cameras in the ecosystem to collect data, the parameters of the cameras will change with the replacement of the device. As a result, the features corresponding to the previous cameras would vanish while the features corresponding to new cameras would emerge. A straightforward approach for this task is to learn a new model based on the new features. Whereas, this solution suffers from the lack of new samples and the waste of vanished features.
In order to take advantage of the historical information from the previous feature space, it is urgent to bridge a gap between the previous and the new feature space. The pioneering work for this intuition is presented in [2], whose crucial observation is that the features generally do not change in an arbitrary way; instead, there are some evolving periods in which both old and new features are available. In this regard, since the service cycle of the camera is defined in advance, we can deploy the new device before the old one is completely obsolete, and consequently, there exists an overlapping stage that allows us to obtain two sets of data streams collected by the old camera and the new one. Accordingly, [2] proposes to establish the relationship between previous and current feature spaces by learning a mapping matrix based on the data from the evolving stage. By mapping the new data onto the previous feature space, the historical data or model can be exploited for learning a new model in the new feature space. Since then, a train of researches for learning feature evolvable streams have been explored [6, 7, 3].
However, the existing FESL methods can only be applied to some simple tasks where the data streams have low-dimension features. They are usually impracticable to deal with high-dimension data streams such as image sequences. This fact arises from two reasons. First, in an online learning setting, the target classifying model is usually built on shallow model (e.g., linear/kernel-based hypothesis), it fails to learn the image’s complex patterns. Second, the existing methods employ a linear function to establish the mapping between the old and new feature spaces, which may not be capable to evaluate the complex relationship between the two different feature spaces of image streams.
To fill this gap, this paper explores a new paradigm: Feature Evolvable Learning with Image Streams (FELIS), which relaxes the constraint that the data instances of low-dimension features. To achieve this, we need to address the following questions.
How to choose a proper model capacity (e.g., network depth) of the classifier to learn the complex patterns of images. The challenge is that if the model is too complex, the learning process is difficult to converge for the few arrived instances at the initial rounds. While the model is too simple, the learning capability will be limited as more instances are obtained.
How to exploit the relationship between the old and new feature spaces of the image streams. It is observed that if we apply simple linear function to evaluate the mapping as the existing methods does, the complex relationship of feature spaces is inadequate to be represented. While applying complex nonlinear function, it is unavoidable to introduce large amounts of parameters to be evaluated. These parameters are difficult to be estimated in the online learning setting and the mapping is prone to be overfitting.
In response, we design an elegant solution to the two challenges in a uniform framework. First, inspired by the thoughts of sequential decision [8], we design a novel ensemble residual network (ERN) to learn the complex patterns of image streams in an online setting. ERN is constructed by composing several classifiers that are separately attached by one residual block. The final prediction of the target model is a weighted combination of the predictions of all classifiers. With hedge backpropagation (HBP) strategy, our framework can dynamically select the model capacity and encourages the knowledge to transfer from shallow to deeper networks. Second, instead of using a parametric analyses method to evaluate the mapping between the old and new features, we proposed a novel approach, termed as latent representation mapping (LRM), to learn the relationships of the feature spaces, where the mapping is evaluated based on the alignment of image latent representations derived from an integrated autoencoder. Overall, our contributions are summarized as follows.
It is the first work to explore the FELIS problem, where the learners target at learning how-dimension streams with evolvable feature spaces. We designed an ERN framework which allows us to train deep neural networks (DNNs) of adaptive capacity meanwhile enabling knowledge sharing between shallow and deep networks. We proposed a LRM approach to learn the complex relationship between the old and current feature spaces, which is effective and parameter-free.
It is worth emphasizing that our method differs from the work proposed by [9]. In one respect, the basis blocks of network in [9] are comprised of full connection layers, which are ineffective to extract abstract representation of image streams. Our ERN architecture employs residual blocks as the basis blocks, which turn out to be feasible for image processing tasks. In another, the goal of [9] is to address the problem of learning DNN on the fly, provided that the data streams are of fixed features. While our method aims to tackle the challenge of FELIS, where the features of the streams are evolvable over times.
Related work
Online learning
Online learning is a family of scalable algorithms that learn to update models from data streams sequentially [10, 11]. Popular algorithms include Perceptron [12], Online Gradient Descent [13], Passive Aggressive [14], Online Learning with kernels [15], Online Multiple Kernel Learning [16, 17], etc. But these models are too weak to deal with the complex tasks. DNNs are state of the art methods for many complex learning tasks due to their ability to extract increasingly better features at each network layer [18, 19, 20]. However, the improved performance of additional layers in a deep network comes at the cost of added latency and energy usage in feedforward inference. [21] use a BranchyNet allows prediction results for a large portion of test samples to exit the network early via the branches in batch learning. There have been attempts at making deep learning compatible with online learning operate via a sliding window approach with a (mini) batch training stage [22, 23, 24]. These approaches optimize the loss function based on the output of the deepest layer, which is suitable only for batch settings. Similar to BranchyNet, in online settings, [9] propose Hedge Backpropagation to evaluate the performance of every output classifier at each online round using Hedge [25] and extends this Backpropagation to allow DNN capacity to vary dynamically.
Feature evolving stream learning
Online learning has been extensively studied under different settings, such as learning with experts [10] and online convex optimization [26, 27]. There are strong theoretical guarantees for online learning, and it usually uses regret or the number of mistakes to measure the performance of the learning procedure. However, most of existing online learning algorithms are limited to the case that the feature set is fixed. As the data are usually collected from dynamic environments, it is of great importance to facilitate the learning system with the capability of dealing with the environmental changes. To deal with data streams with evolving feature space, recent studies propose to exploit the relationship between previous feature space and the current one, so that historical data can be further leveraged. [1] allow the arriving instances to carry different sets of features but later instances are assumed to include monotonically more features than the earlier ones. [2] learn a linear mapping from the evolving stage to recover previous features and then ensemble two linear models learned from the recovered features and current ones. And they proposed two methods called FESL-c and FESL-s to improve the performance of learning with streaming data. [6] propose an Evolving Discrepancy Minimization algorithm and use two 5-layer MLP classifiers to apply to FDESL which both the feature space and the distribution of data evolving in the streaming scenario.
The motivations of our work
Supporting variable features and high-dimension streams are two important aspects in the field of online machine leaning. As shown in Section 2.2, the existing FESL methods aim at solving the problem of feature drifting, however, they are developed to tackle simple tasks such as classifying streams with low-dimension features. They fail to effectively online process the streams with high-dimension features due to their inferior representation capability for complex data patterns. Although some online leaning methods (e.g. BranchyNet and Hedge Backpropagation) illustrated in Section 2.1 are developed to allow DNN capacity for many complex learning tasks, nevertheless, they cannot deal with the variable features of the streams and increase latency and energy usage in the inference procedure. To fill this gap, we explore a new online learning paradigm: FELIS which attempts to make the online learners less restrictive and more applicable. However, to achieve this, it is not a trivial combination of the two family methods. The main challenge of solving FELIS lies to 1) how to choose a proper model capacity to online learn the image streams, and 2) how to effective and efficient to handle the feature drifting for the variant feature spaces.
In response, we design a uniform framework to tackle the two challenges. First, we design an ERN network to learn the complex patterns of the image streams, which gives an effective model selection approach to adapt to the optimal network depth automatically online. Second, we proposed an LRM approach to obtain the relationship of the old and new feature spaces, which is effective and parameter-free.
The FELIS problem
Problem statement
We focus on image classification tasks in the setting of FELIS. That is, on each round of the learning process, the model receives an image instance and then predicts its label before the true label is revealed. Considering the example of image collections from surveillance cameras, we denote
Illustration of how image stream comes.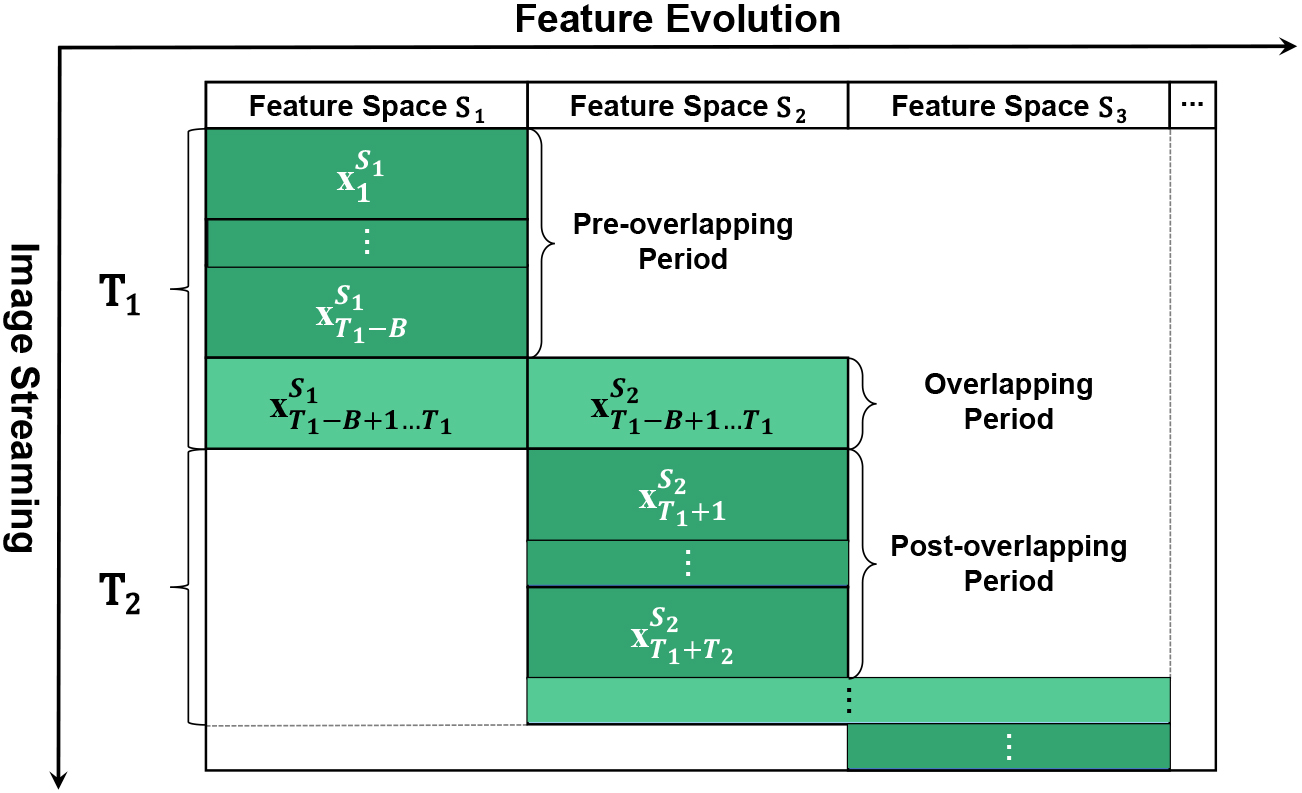
Pre-overlapping period: For Overlapping period: For Post-overlapping period: For
Note that the total rounds of pre-overlapping, overlapping and post-overlapping periods formulate one cycle and repeats continuously. The post-overlapping period in the current cycle can be recognized as the pre-overlapping period for the next cycle. Our goal is to learn of a series of model
where
From the problem statement, we observe two challenges in solving the FELIS problem, which are described as follows.
Challenge 1: Dilemma of determining the model capacity (e.g., network depth). The existing methods usually use shallow
Challenge 2: Difficulty of choosing a proper mapping. In the FELIS setting, the evolving stage
In another respect, we proposed a LRM method to effectively evaluate the relationship of the feature spaces. Instead of exploiting the feature correlations on the data naive representations, we estimate the feature relationships based on the data latent representations learned by an embedded autoencoder during the overlapping period. The proposed strategy is able to compute the mapping between different feature spaces in a parametric-free way, and hence provide an appropriate solution for the FELIS problems.
The proposed approach
Our proposal for solving the FELIS problem is composed of ensemble residual network (ERN) and latent representation mapping (LRM) strategy, where the ERN is used to learn the image patterns in an online way and LRM is applied to settle the feature evolving issue. The implementation of our method, including ERN and LRM, is outlined in Algorithm 1.
[h] : The Proposed Approach[1] Inputs: Hedge Parameter:
Update
Update
Update
Smoothing
The framework of ensemble residual network (ERN). Dark blue lines represent feedforward flow for computing residual block features. Orange lines indicate the prediction flow by the combination of outputs for each residual block. Dark green lines indicate the online updating flows with the hedge backpropagation approach. Light blue and green lines represent the flows that train an autoencoder.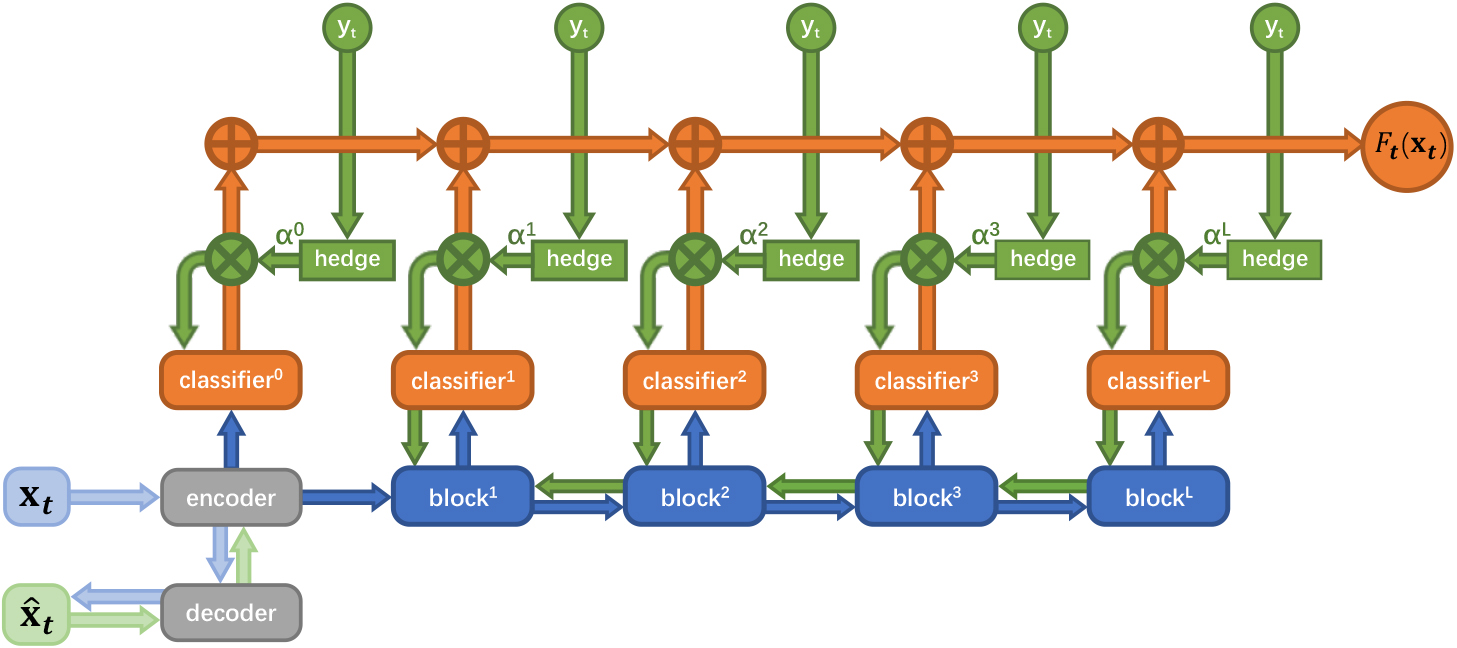
The framework of ERN is depicted in Fig. 2. First, we construct several residual blocks [19] and attach each block to a classifier. The final prediction of ERN is a weighted combination of the predictions of all classifiers. In particular, let
Different from Online Deep Learning (ODL) method that uses fully connected layer as the basic blocks to exploit data representations [9], we use residual network as the blocks in our framework, which exhibits superior capability for the image online learning problem. In addition, different from the original ResNet framework [13] wherein the final prediction is derived from
Second, we use Hedge Backpropagation (HBP) [9, 25], an efficient hedging strategy, to online update the parameter
For the update of
where
For learning the parameters
Learning the feature representation parameters
where
Note that our ERN framework can be referred to as a sequential decision procedure [8, 31], which is a form of online learning with Expert Advice. In this frame, multiplicative weight-update Littlestone-Warmuth rule [31] can be adapted to this model, yielding bounds that are slightly weaker in some cases. Specifically, the cumulative loss (or simply regret) of the learner, or of any expert, is the expected number of mistakes on the entire sequence. In our case, the regret with Hedge mechanism can be bounded by
During the rounds
Support
For the overlapping period, the discrepancy of latent representations of the instances from the old and current feature spaces are imposed to be minimized.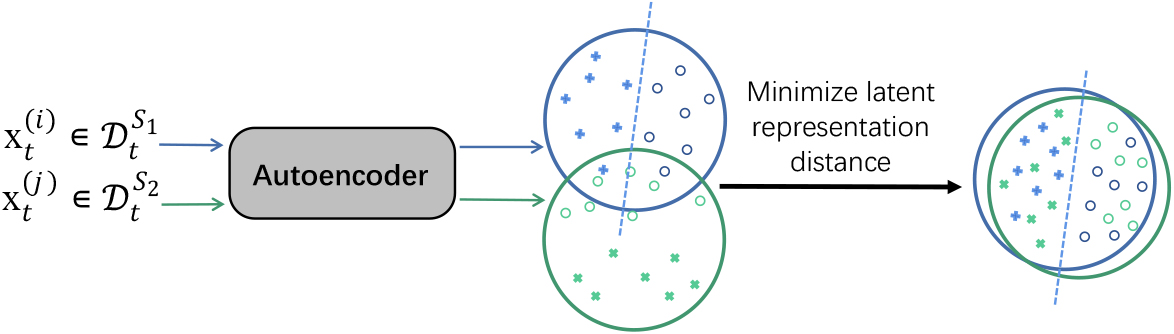
For the overlapping period, there exist two different feature spaces simultaneously, then the loss of the autoencoder is consisted of the reconstruction loss and the discrepancy of the latent representations from different feature spaces (as shown Fig. 3). Here, the discrepancy of the latent representations can be measured by Maximum Mean Discrepancy (MMD) [35, 36] metric, which formulates the loss
Overall, the loss function of the autoencoder for one cycle (comprising of pre-overlapping, overlapping and post-overlapping period) at time
where
where
Note that the mapping from the new and old feature spaces are actually established in an indirect way by the LRM strategy. As shown in Fig. 2 the autoencoder is embedded in the framework of ERN, where the encoder, rather than the decoder, is attached to the classifier for the feedforward flow. It implies that the latent representations, instead of the naive representation of the images, contribute to the learning process. Thus, when new instance arriving in the post-overlapping stage, we just need obtain its latent representation by the autoencoder that have been trained during the pre-overlapping and overlapping stages, and then feed such latent representation to the classifier to proceed the learning. Hence, it is not required to map the new features to the old ones in their naive representations in practice. In addition, when the number of features is different from the old and new spaces, the images are required to be resized to the same size by bilinear interpolation or pooling approach for matching the input format of the autorencoder.
Scenarios and datasets
To validate the effectiveness of our method for the FELIS problem, we constructed six image streams as the experimental datasets from CIFAR-10 [30] and CIFAR-100 [30], where CIFAR-10 has 6000 examples of each of 10 classes and CIFAR-100 set has 600 examples of each of 100 non-overlapping classes. Each of the six datasets contains two different feature spaces. For the old feature space, the instances are the images of CIFAR-10/CIFAR-100. For the new feature space, the instances are the images transformed from the old feature space. Overall, these datasets can be divided into virtual scenario and real scenario. For the virtual scenario, we generate new feature spaces by adding random Gaussian noise to CIFAR-10/CIFAR-100. For the real scenario, two applications including channel transforming and contrast transforming for ecosystem are considered. In the case of channel transforming, we support that the ecosystem is required to be monitored all day long, and hence optical camera that captures color images for the day time and infrared camera that captures gray images for the night are set up. We simulated this setting by converting CIFAR-10/CIFAR-100 images of three-channel into gay images of one-channel for generating new feature spaces. In the case of contrast transforming, we suppose that when we replace camera with new one for equipment replacement, the contrast of images would be changed. To simulate this setting, we convert the contrast of CIFAR-10/CIFAR-100 images to construct new feature spaces. A sketch of the six datasets are illustrated in Table 1 and the detail descriptions of the datasets are as follows.
The sketch of the datasets
The sketch of the datasets
CIFAR-10-GN: the images from CIFAR-10 are used as the data stream for the old feature space at the pre-overlapping period. The data stream for the new feature space at the post-overlapping period is generated by adding noises to images in the pre-overlapping period, where the noise is subjected to the standard normal distribution. CIFAR-100-GN: the images from CIFAR-100 are used as the data stream for the old feature space at the pre-overlapping period. The data stream for the new feature space at the post-overlapping period is generated by adding noises to images in the pre-overlapping period, where the noise is subjected to the standard normal distribution. CIFAR-10-CHC: the images from CIFAR-10 are used as the data stream for the old feature space at the pre-overlapping period. The data stream for the new feature space at the post-overlapping period is generated via converting the images in the pre-overlapping period to one-channel images with ITU-R 601-2 luma transform. This luma transform can be represented as CIFAR-100-CHC: the images from CIFAR-100 are used as the data stream for the old feature space at the pre-overlapping period. The data stream for the new feature space at the post-overlapping period are generated via converting the images in the pre-overlapping period to one channel images with ITU-R 601-2 luma transform. This luma transform can be represented as CIFAR-10-COC: the images from CIFAR-10 are used as the data stream for the old feature space at the pre-overlapping period. The data stream for the new feature space at the post-overlapping period are generated via multiplying the contrast of the images in the pre-overlapping period by 0.5 to 1.5 times. CIFAR-100-COC: the images from CIFAR-100 are used as the data stream for the old feature space at the pre-overlapping period. The data stream for the new feature space at the post-overlapping period are generated via multiplying the contrast of the images in the pre-overlapping period by 0.5 to 1.5 times.
We take seven online learning competitors along with the proposed method for experiments.
NOGD (Naive Online Gradient Descent) [13]: uses ResNet-18 [19] as classifier, where once the feature space changes, the online gradient descent algorithm will be invoked from scratch. FESL-c (FESL-combination) [2]: mentioned in Introduction section, which uses shallow classifier for online learning and linear mapping for approximating the relationship of the old and new feature spaces. This approach makes predictions for the new instances by combining the outputs of the old and new models based on exponential of the cumulative loss. FESL-s (FESL-selection) [2]: instead of combining both the old and new models for predicting new instances as FESL-c does, FESL-s utilizes the best single model to make predictions. Note that although this method selects one model for predictions, it relies on both models for updating parameters. ODL [9]: mentioned in Introduction section, where the prediction of the network is weighted combination of several 20-layer fully connected neural networks. The structure of the network in ODL is similar with the proposed ERN, except for the ensembled feature extractors. FESL-c-Variant: this is a variant of FESL-c, where the linear classifier of FESL-c is substituted with the proposed ERN. ERN ERN: compared to the proposal, this method works for invariant feature spaces, thus only ERN is applied.
NOGD, ODL and ERN target at online learning setting with non-evolving feature spaces, thus they have no mapping implementations. To enable these methods to be applicable to our setting, we yield these methods to make predictions for the new instances depending on the models trained under the pre-overlapping period. Note that NOGD, ODL, FESL-c and FESL-s are baseline methods used to make comparisons with our approach, while FESL-c-Variant, ERN
All the methods are evaluated on image classification tasks on rounds
The parameters we need to set are the number of instances in overlapping period, i.e.,
The hyperparameters of the comparing methods, where
is the learning rate,
and
is the number of rounds in
and
,
is the overlapping rounds,
is regularization factor in MMD loss
The hyperparameters of the comparing methods, where
Our experiments are carried out for answering the following research questions.
The first four and last lines in Table 3 shows the classification accuracies of the baseline methods and our proposal in FESL setting. It can be observed that our method (ERN
Figure 4 shows the trends of ACL of our method and its competitors. From the experimental results, we obtain the following observations. First, the ACLs of FESL-c and FESL-s decrease rapidly when small amount of data streams arrive in pre-overlapping stage, but with the advent of evolvable-feature instances in the post-overlapping stage, their ACLs stop declining or even going up. This is due to the fact that the target classifiers of FESL-c and FESL-s are simple linear models which have insufficient capacities to fit the new image instances with variable features. Second, although the ACLs of NOGD and ODL keep falling in all stages, their ACLs are still higher than ours at any given time. This is because in the pre-overlapping stage, the classifier’s capability of our method is superior to the ones of NOGD and ODL; while in the post-overlapping stage, NOGD and ODL have no mapping measure to handle the new instances with evolvable features.
The prediction accuracies of the proposed method and its comparing methods for different datasets
The prediction accuracies of the proposed method and its comparing methods for different datasets
The ACLs of the proposed method and its competitors for various datasets over the time from 1 to 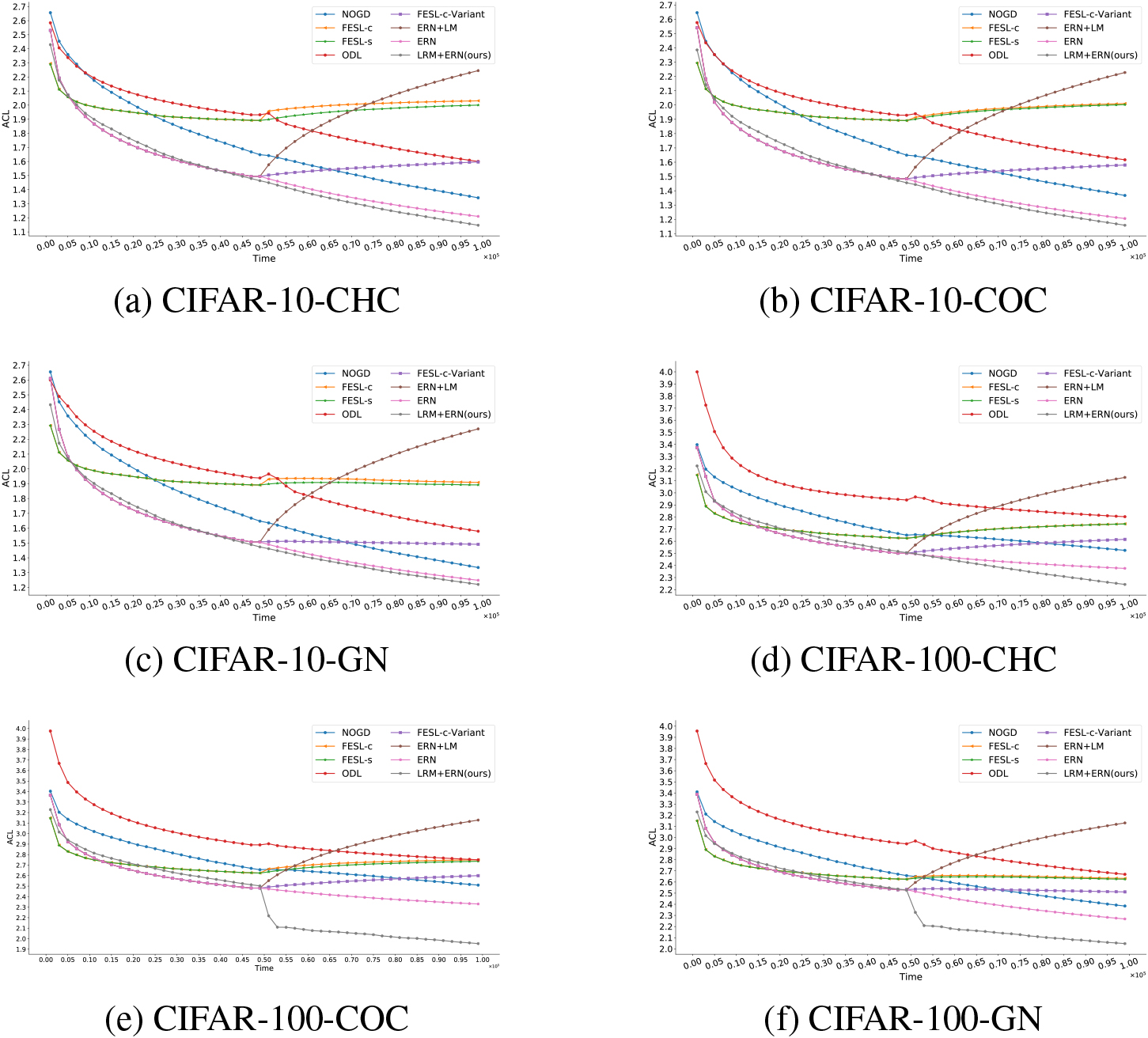
We carried out several ablation experiments for answering this question, and the experimental results are listed in Table 3. From the table, we have the following observations. (1) The classification accuracy of FESL-c-Variant is higher than that of FESL-c. The main difference between FESL-c-Variant and FESL-c is only their target models. This fact illustrates that ERN is more suitable to process FESL tasks compared to the linear-hypnotized-based models as FESL-c uses. (2) The classification accuracy of ERN is higher than that of NOGD. This is because the ensemble learning framework of ERN facilitates the knowledge to transfer from shallow to deeper networks, which is contribute to obtaining complex patterns from image streams. (3) The classification accuracy of ERN is higher than that of ODL. This demonstrates that the residual blocks that formulate the basic components for ERN have better capability than linear-connected blocks when dealing with image streams.
Figure 5 visualized the weight distributions of the attached classifiers regarding with the residual blocks. The vertical axis represents the weights, and the horizontal axis represents the index of the classifiers. Note that higher index implies deeper classifier. From this figure, we can observe that in the initial stage wherein first 1% instances arrived, shallow classifiers have high weights (Fig. 5a). This indicates that when the number of instances are small, the residual blocks in the shallow layers play a leading role. As more instances arrive (Fig. 5b), the weights of shallower classifiers are decreasing while the weights of deeper classifiers are going up. When the proportions of the arrived instances are up to 60%–80%, the weights of the deep classifier take a dominant place. This phenomenon illustrates that the ensemble learning framework of ERN encourages the knowledge to transfer from shallow to deeper networks, and thereby automatically adapting the effective depth of the network to learn an appropriate capacity network based on the image streams.
We take ERN
To validate the effectiveness of the MMD term, we have carried out an ablation experiment. The comparing method is the proposed method and the method without MMD term (termed as Without MMD). The experimental results are listed in Table 4. We can observe from the table that the prediction accuracy rates of the proposed method are higher than that obtained by the Without MMD method. This is because MMD loss can effectively align the latent representations of the old and current instances, which facilitates to establish the relationship between the old and feature spaces. Consequently, the prediction performance for the new instances is improved.
To test the effect of block implementation of our framework, we replace the origin block of Resnet with ResNeXt [37] in ERN and conduct experiments under the same setting. The result is shown in Table 4, where the variant of the proposed method is termed as With ResNeXt. From the table, we observe that our framework with ResNeXt block can further improve the online learning performance compared to that with Resnets, due to the more powerful feature representation ability of ResNeXt. This fact indicates that the blocks of our framework play a vital role for the learning performance. Designing more elaborate blocks may contribute to enhancing the prediction accuracies of the network.
The prediction accuracy rates of the variants of the proposed method
Weight distributions of the attached classifiers regarding with the residual blocks when training on CIFAR-100-COC.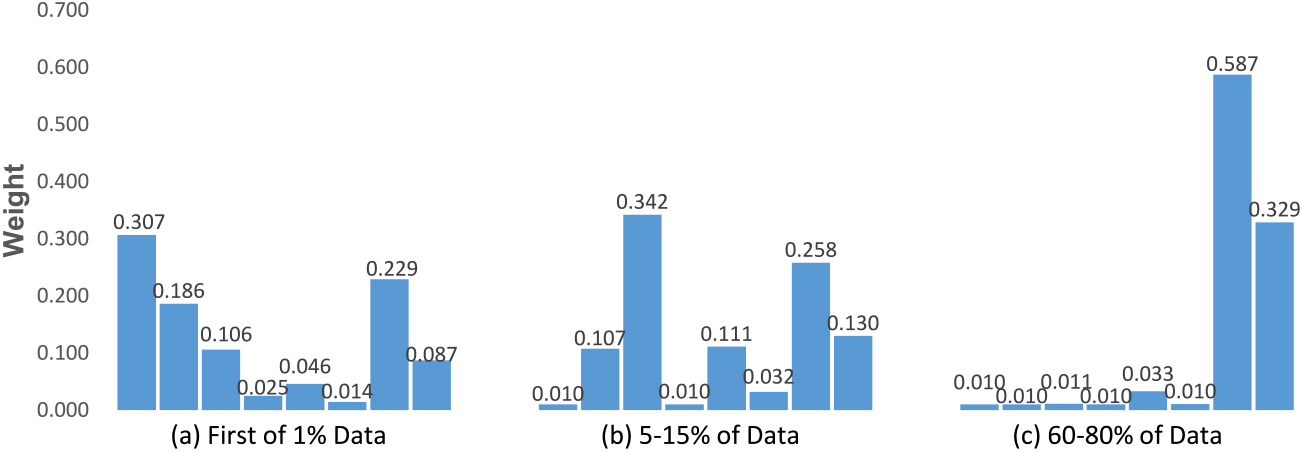
This paper explored a new online learning paradigm, termed FELIS, to tackle the challenge where the existing FESL methods are infeasible to deal with high-dimension data streams. First, we propose an ERN framework to make the learner online obtain the complex patterns of image streams. This framework is integrated with several residual blocks and make predictions by weighted combination of the outputs of the residual blocks, which encourage the knowledge to transfer from shallow to deeper networks as the number of instances increases. Second, We substitute the first residual block of ERN with an autoencoder and present a latent representation mapping (LRM) approach to solve the issue of feature evolving. LRM is able to capture the complex relationship of the old and new feature spaces in a parameter-free way, which facilitate the learner to make prediction for the new instances aligned with the previous learned model. In our future work, we will make in-depth studies of regression tasks such as image super-resolution and image inpainting for the FELIS setting.
Footnotes
Datasets can be found in
Acknowledgments
This work was supported by National Natural Science Foundation of China (No. 62072127, No. 62002076), Project 6142111180404 supported by CNKLSTISS, Science and Technology Program of Guangzhou, China (No. 202002030131, No. 201904010493), Guangdong basic and applied basic research fund joint fund Youth Fund (No. 2019A1515110213), Open Fund Project of Fujian Provincial Key Laboratory of Information Processing and Intelligent Control (Minjiang University) (No. MJUKF-IPIC202101), Natural Science Foundation of Guangdong Province (No. 2023A1515011774, No. 2020A1515010423), Scientific research project for Guangzhou University (No. RP2022003).
Declarations
The authors declared that they have no conflicts of interest to this work. We declare that we do not have any commercial or associative interest that represents a conflict of interest in connection with the work submitted.