
Abstract
The classification of the smart contract can effectively reduce the search space and improve retrieval efficiency. The existing classification methods are based on natural language processing technologies. Because the processing of source code by these technologies lacks extraction and processing in the software engineering field, there is still a lot of room for improvement in their methods of feature extraction. Therefore, this paper proposes a multi-feature fusion method for smart contract classification (MFF-SC) based on the code processing technology. From the source code perspective, source code processing method and attention mechanism are used to extract local code features. Structure-based traversal method are used to extract global code features from abstract syntax tree. Local and global code features introduce attention mechanism to generate code semantic features. From the perspective of account transaction, the feature of account transaction is extracted by using TransR. Next, the code semantic features and account transaction features generate smart contract semantic features by an attention mechanism. Finally, the smart contract semantic features are fed into a stacked denoising autoencoder and a softmax classifier for classification. Experimental results on a real dataset show that MFF-SC achieves an accuracy rate of 83.9%, compared with other baselines and variants.
Keywords
Introduction
With the development and application of blockchain technology, the number of smart contracts deployed on the blockchain platform has grown exponentially [1]. Since the official release of the smart contract white paper, it marks that smart contracts will be widely used in the fields of digital identity, asset record, financial trade, mortgage, data sharing and IoT supply chain in the next few years. There are currently over 200 smart contract applications on the Ethereum platform, with an average of nearly 100,000 smart contracts released each month [2]. The huge number of smart contracts makes it difficult for users to manually filter the services they need. How to manage and organize massive smart contracts so that users can select the services they need in the contracts is an important problem that needs to be solved.
Unlike traditional text, smart contract text mainly consists of source code, annotations, account information, and account transaction information. Smart contract text classification has certain specificity. The traditional text of natural language processing is usually weakly structured. The source code is structured text, and the code is clear and structured [3]. Therefore, how to use the rich and clear structural information in the source code to extract code semantic features is a problem that needs to be studied. All information about smart contract accounts is stored on the Ethereum blockchain [4]. The behavior information of smart contracts can be obtained through transactions related to smart contracts. For example, a smart contract for a lottery can automatically judge based on the lottery number and the number purchased by the lottery user when the lottery is drawn. If a user wins, the smart contract automatically transfers the prize money from the lottery company’s digital currency wallet to the winner’s digital currency wallet. Therefore, the transaction information of smart contracts contains the internal logic of smart contracts, and there is heterogeneity in relationships between accounts. How to fully utilize the heterogeneity of relationships between account transactions to extract account transaction features is also a problem that needs to be studied. Therefore, it is necessary to automatically generate efficient classification methods for smart contracts. Challenges in achieving efficient classification of smart contracts often include:
How to extract the semantic information of the smart contract source code: Early researchers, such as Huang et al. [5] and Wu et al. [6], used common source code as the input to the smart contract classification model, which made the processing of source code single and also ignored the structural information of the source code. Therefore, in recent research work, such as Tian et al. [7] added source code comments to the input of the classification model to improve the accuracy of the model. In the research of source code structure, Hu et al. [11] parsed the source code into the abstract syntax tree (AST), and traversed the AST through the structure-based traversal (SBT) method to obtain the SBT sequence as input to learn the semantic information of the source code. However, smart contract source code can be represented in multiple ways, each focusing on a different aspect of semantic information. Therefore, using a single processing method to represent the semantic information of the code is not comprehensive. To represent the semantic information of the code more comprehensively, on the one hand, this paper takes the comments, function names, and parameter of the source code as input, focusing on extracting the local semantic information of the source code. On the other hand, the SBT sequence is globally parsed from the AST using the SBT method and used as input, focusing on extracting the global semantic information of the source code. How to extract the account transaction information of the smart contract: A smart contract corresponds to an account that includes related contract addresses and transactions, balances, etc. Existing research works, such as Huang et al. [5], Wu et al. [6] and Tian et al. [7] used account information as the input of the smart contract classification model, which ignored the heterogeneity of the relationship between accounts. Therefore, in this paper, account transaction information is taken as part of the input, and because of the heterogeneity of the relationship between accounts, the TransR [12] is utilized to find the semantic representation of potential smart contract accounts from the structured heterogeneous network.
To address the above challenges, this paper proposes a multi-feature fusion method for smart contract classification (MFF-SC). The main contributions of this paper are summarized as follows:
We propose a source code processing method called SCP. It extracts comments, function names, and parameter in the source code to form features related to the field of the smart contract as local code features of the source code. The source code is parsed into AST and the SBT method is applied to parses out the global code features of the source code from the AST. TransR is adopted to extract the account transaction features of the smart contract. Moreover, stacking denoising autoencoder (SDAE) is used to pre-train and classify the semantic features of smart contracts. Web crawler is utilized to collect a smart contract dataset from the State of the Dapps website.1
The remainder of this paper is organized as follows. Section 2 introduces the smart contract classification model. Section 3 discusses the data preparation and reporting experiments. Section 4 presents related work, and Section 5 concludes the work of this paper.
The framework of MFF-SC is shown in Fig. 1. MFF-SC mainly consists of smart contract feature extraction module, source code feature representation module, account transaction feature representation module, feature fusion module and smart contract classification module. The process of MFF-SC is divided into four phases:
Step 1: We collect data on Ethereum-based smart contracts from the State of the DAPPS website crawler. The data set includes smart contract source code and account transaction information. Step 2: The source code processing (SCP) method is used to extract the comments, function names and parameter of the source code, and perform data cleaning to form three local texts. The word embedding is performed on the local text to generate three local vectors, and the attention mechanism is introduced into the three local vectors for weighted combination to generate local code features. At the same time, the source code is converted into abstract syntax tree (AST), and the structure-based traversal (SBT) method is used to convert the AST into the SBT sequence. And the SBT sequence is input into the word embedding layer to extract global code features. The local and global code features are weighted and combined into code semantic features using the attention mechanism. Step 3: The account transaction information is represented as triple text, and then the triple text is input into TransR to extract account transaction features. Step 4: Code semantic features and account transaction features are weighted and combined using the attention mechanism to generate smart contract semantic features. Then, the smart contract semantic features are input into stacking denoising autoencoder (SDAE) for pre-training. The pre-trained data is input into the softmax classifier for classification, while the labeled data is input into the softmax classifier for supervised fine-tuning. Finally, the probability of each class label is output, the highest probability of which is the class of the smart contract.
MFF-SC framework.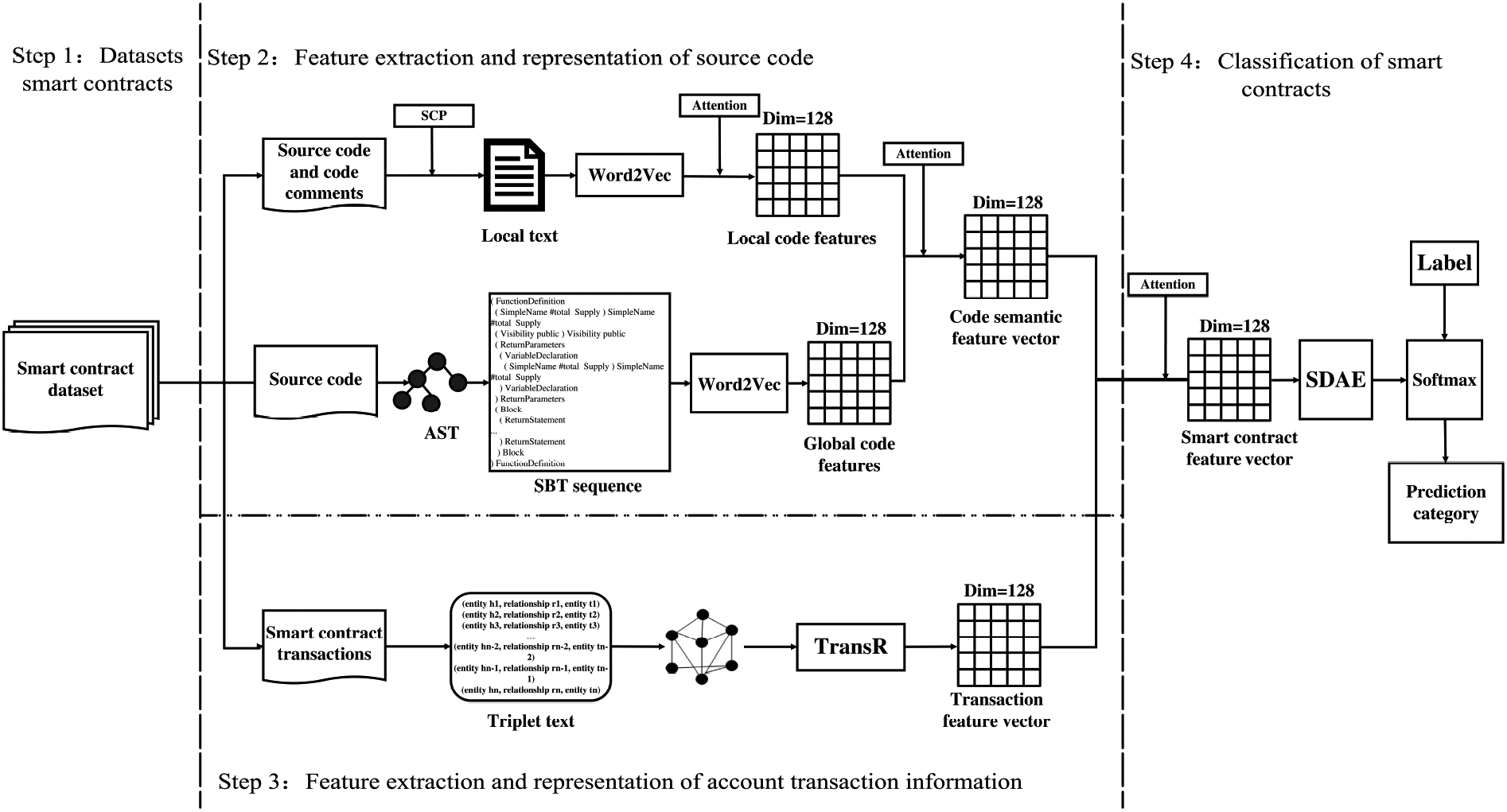
The feature extraction of smart contracts is mainly carried out from the source code and account transaction information. The code features of smart contracts are extracted from the source code, and the account transaction features are obtained from the account information.
For smart contract source code, early researchers, such as Huang et al. [5], Wu et al. [6] and Tian et al. [7], used common source code as the input of the model. Their processing of source code lacked the extraction and processing of software engineering, and also ignored the structural information of source code. Therefore, in the feature extraction of source code, we propose the SCP method to extract relevant information in the field of smart contracts as the local code features of the source code. At the same time, inspired by the literature [11], the SBT method is applied to convert the AST parsed from the source code into an SBT sequences to extract the global code features of the source code. By comprehensively considering the local and global features of the source code, the accuracy of smart contract classification is improved to a certain extent. The detailed feature representation method is elaborated in Section 2.1.1.
For smart contract account transaction information, early researchers, such as Huang et al. [5], Wu et al. [6] and Tian et al. [7], considered that extracting the features of account information as input can improve the classification effect. However, the above research works ignored the heterogeneity of the relationship between accounts.
Therefore, in the feature extraction of account transaction information, we represent account transaction information in the form of triples. The detailed feature extraction method is elaborated in Section 2.1.2. In the feature representation of account transaction information, TransR is used to find the semantic representation of potential smart contract accounts from a structured heterogeneous network.
Source code feature extraction
In source code feature extraction, MFF-SC focuses on extracting local code features and global code features of source code.
On the one hand, in order to obtain relevant features in the field of smart contracts, this paper uses the SCP method to extract source code comments, function names and parameter to form three local texts. Then, the three local texts are respectively input into the Word2vec model of the word embedding layer and converted into three local vector representations. Finally, an attention mechanism is introduced to perform a weighted combination of the three local vectors to generate local code features. The process of local code feature extraction is shown in Fig. 2.
Local code feature extraction.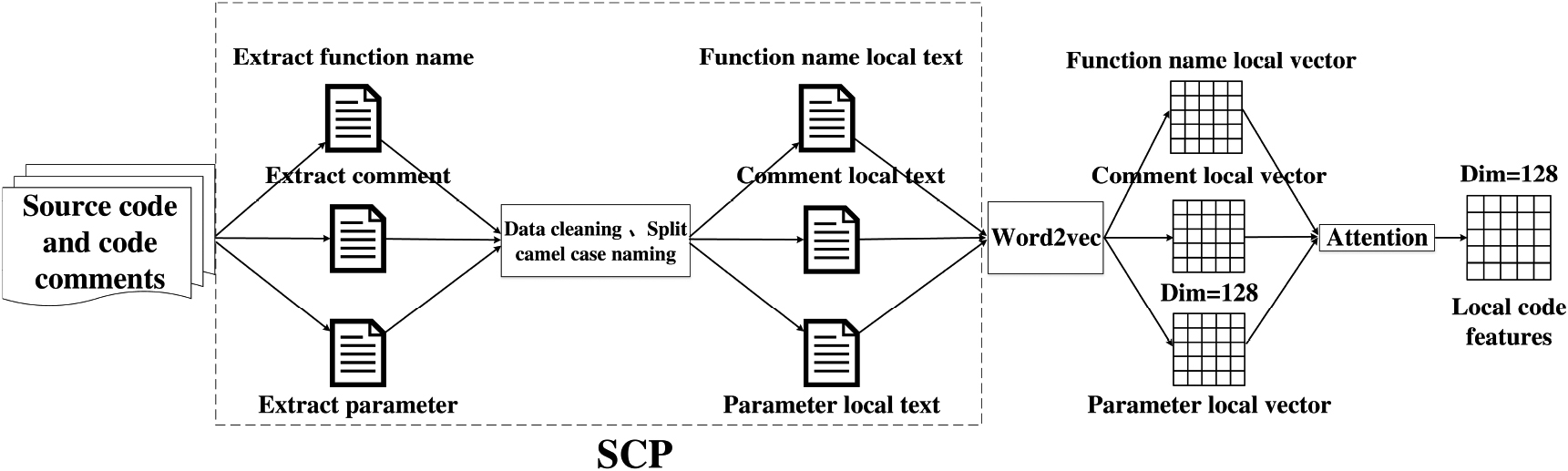
The detailed process of the SCP method is as follows:
First, extract comments, function names, and parameter from source code with custom rules. Specifically, the comment that start with “/*” and end with “*/”, or start with “//” and end with a newline “ Then, data cleaning is performed on the extracted comments, function names and parameter. Next, split camelcase-named variables into multiple words. Finally, the sentence is segmented to obtain three kinds of local texts.
Smart contract source code snippet.
Take the smart contract source code snippet in Fig. 3 as an example. “Submitted for verification at Etherscan.io on 2017-09-28” that starts with “/*” and ends with “*/” is used as a comment. The “totalSupply” after “function” and before “(” is regarded as the function name, and “uint256 totalSupply” between “(” and “)” on the same line as function is extracted as parameter. Data cleaning is performed on the extracted function name, parameter, and comment (that is to remove stop words, delete punctuation marks, and convert case). Split the camelCase-named variables into multiple words. For example, the variable named “totalSupply” is divided into “total” and “Supply”. The english tokenizer NTLK is called to split the sentences. Finally, from the source code of a smart contract, three local texts of comments, the function names, and the parameter are obtained.
On the other hand, considering the structural information of the smart contract code, the smart contract source code is converted into AST using ANTLR [13] grammar rules. In order to preserve the structural information of the source code, the SBT method proposed by Hu et al. [11] is then adopted to generate SBT sequences through traversing the AST globally. The SBT sequence is sent to the word embedding layer to obtain the global code feature vector.
The detailed process of the SBT method is as follows:
Starting from the root node, the SBT method uses a pair of brackets to represent the tree structure, and put the root node itself after the right bracket. The SBT method traverses the subtree of the root node and puts all the root nodes of the subtree in brackets. The SBT method recursively traverses each subtree until all nodes are traversed to get the final sequence.
Examples of AST and SBT.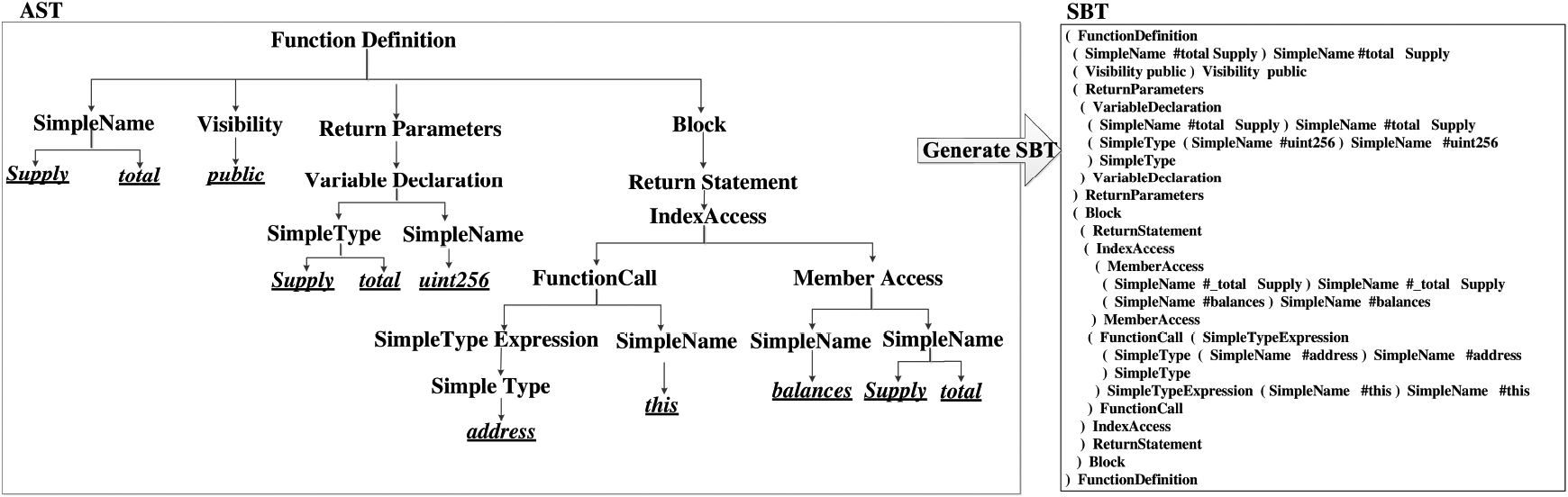
As shown in Fig. 3, the source code snippet defines a function named “totalSupply”, which is parsed into an AST using the parsing tool solidity-parser-antlr2
In the feature extraction of account transaction information, MFF-SC focuses on extracting entities and relationships from the transaction data to generate triple text. Specifically, it extracts the sender’s contract account address, receiver’s contract account address, and transaction relationship from the account transaction data. It uses the addresses of sender’s and receiver’s account as entities and set the transaction relationship as “transfer in” and “turn out”, forming the triple text. The account transaction features are obtained by taking the triple text formed as the input of TransR model. The detailed feature representation method is presented in Section 2.3. Figure 5 shows the process of feature extraction and representation of smart contract account transactions.
Account transaction feature extraction and representation.
For the local text and SBT sequence after source code feature extraction, word embedding processing is performed respectively. Firstly, three kinds of local texts extracted by the source code processing (SCP) method, including comments, function names, and parameter, are input into the word embedding layer to be converted into three kinds of local feature vectors respectively. Secondly, the preprocessed SBT sequence is sent to the word embedding layer to obtain the global code feature vector.
Word embedding usually requires converting words into vectors of low-dimensional distributions and mapping words to corresponding real-valued vectors to capture morphological, syntactic and semantic information of words. To better represent the textual content, this paper adopted the Skip-Gram model [14] in Word2vec [15] to train the data and learn the context between words. The training data consists of a corpus of cleaned source code comments, function names, parameter, and SBT sequences combined into a smart contract corpus. The feature dimension is also set to 128 dimensions and the minimum number of occurrences of words is 10. The value of the parameter workers is set to 2 for parallel modeling and the context window size is 5.
In this model,
where,
Therefore, the input of a smart contract source code mainly consists of three kinds of local texts, namely comments, function names and parameter, and SBT sequence texts, which are respectively input into word2vec model to obtain three kinds of local feature vectors and global code feature vectors.
For the triple text extracted from account transaction data, this paper mainly applies TransR to it to generate account transaction features of smart contracts. TransR can separate entity space and relation space, which can better construct entity and relationship representations [12]. First, entities and relations are embedded in the entity space
Specifically, a smart contract corresponds to an account, and there is a transaction relationship between accounts. The transaction relationship between accounts is represented as a triple
Example of structured embedding TransR.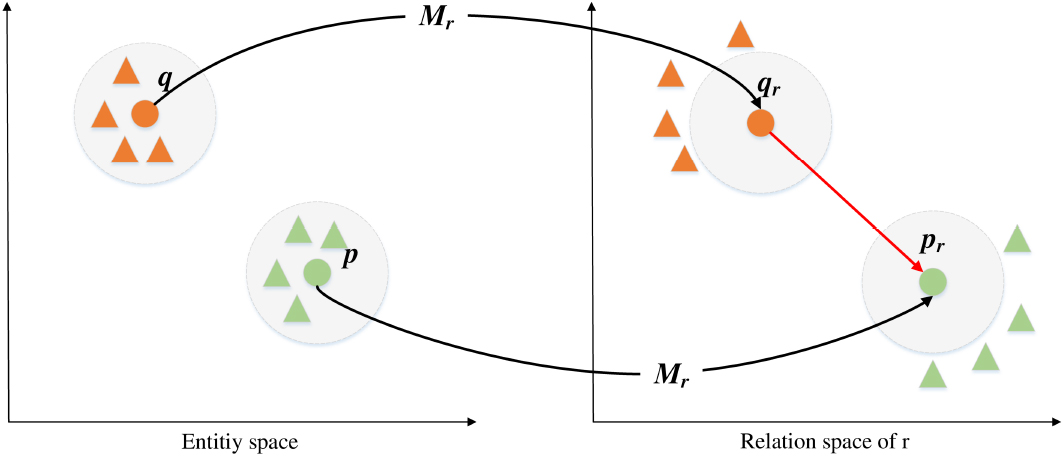
The entity vector definition of the trading account in the smart contract is shown in Eq. (2):
The formula for calculating the score function of a triplet is shown in Eq. (3):
The objective loss function is shown in Eq. (4):
In this way, after the entity in the entity space is transferred to the relation space, the head entity and the relationship are closer to the tail entity. Each head entity and tail entity becomes a vector representation of the relation space. Therefore, the transaction relationships between smart contract accounts are converted into account transaction features by the TransR model.
For the three local feature vectors, the global code feature vector and the account transaction features, an attention mechanism is introduced for weighting combination, and then features that are important for smart contract classification are extracted.
Specifically, the three local feature vectors are first combined into a local code feature using attention weighting. Then the local code features and the global code feature vector are fused into with weights to get code semantic features by introducing attention mechanism. Finally the code semantic features and the account transaction features are used to generate smart contract semantic features using attention mechanism.
Local features fusion
For the three local feature vectors formed by the word embedding layer, the weighted combination of attention mechanism is introduced to form local code features.
A smart contract source code
where,
Local code features and global code features generated by the word embedding layer are weighted and combined via introducing an attention mechanism to form smart contract code semantic features.
After obtaining the local code feature representation
where,
The code semantic features and the account transaction features obtained via the TransR layer are weighted and combined through introducing an attention mechanism to form the smart contract semantic features.
After obtaining the smart contract code semantic feature
where,
In order to make the features learned by deep autoencoders more robust and resistant to original data pollution, Vincent et al. [16] proposed a denoising autoencoder (DAE). The DAE consists of an encoder, a hidden layer, and a decoder. The DAE structure diagram is shown in Fig. 7. Firstly, the input vector is randomly denoised to generate a denoised vector. Then, the noise vector is added for encoding calculation to form a hidden layer vector. The hidden layer vector is decoded to obtain the reconstructed output layer vector. Finally, the encoder is trained by minimizing reconstruction errors.
The DAE structure diagram.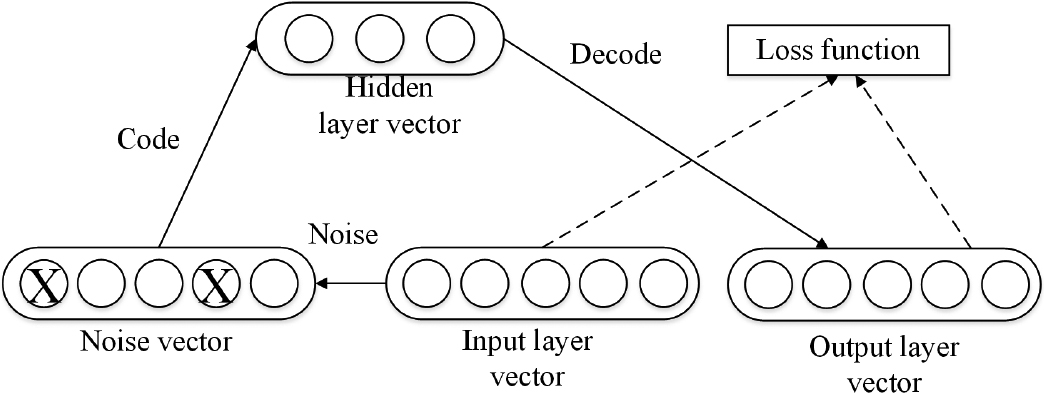
Stacking denoising autoencoder (SDAE) [17] is a combination of multiple denoising autoencoders. Each autoencoder learns and extracts different abstract features of the data. These abstract features can serve as inputs for the next autoencoder, allowing for the extraction of higher-level feature representations layer by layer. This hierarchical feature extraction method can better handle complex nonlinear data structures and improve the performance and generalization ability of the model.
This paper applies SDAE to denoise the semantic features of smart contracts and extract feature representations. The combination of SDAE and Sotfmax can better complete the classification and recognition of input data. Therefore, we chose to use SDAE
Basic structure of SDAE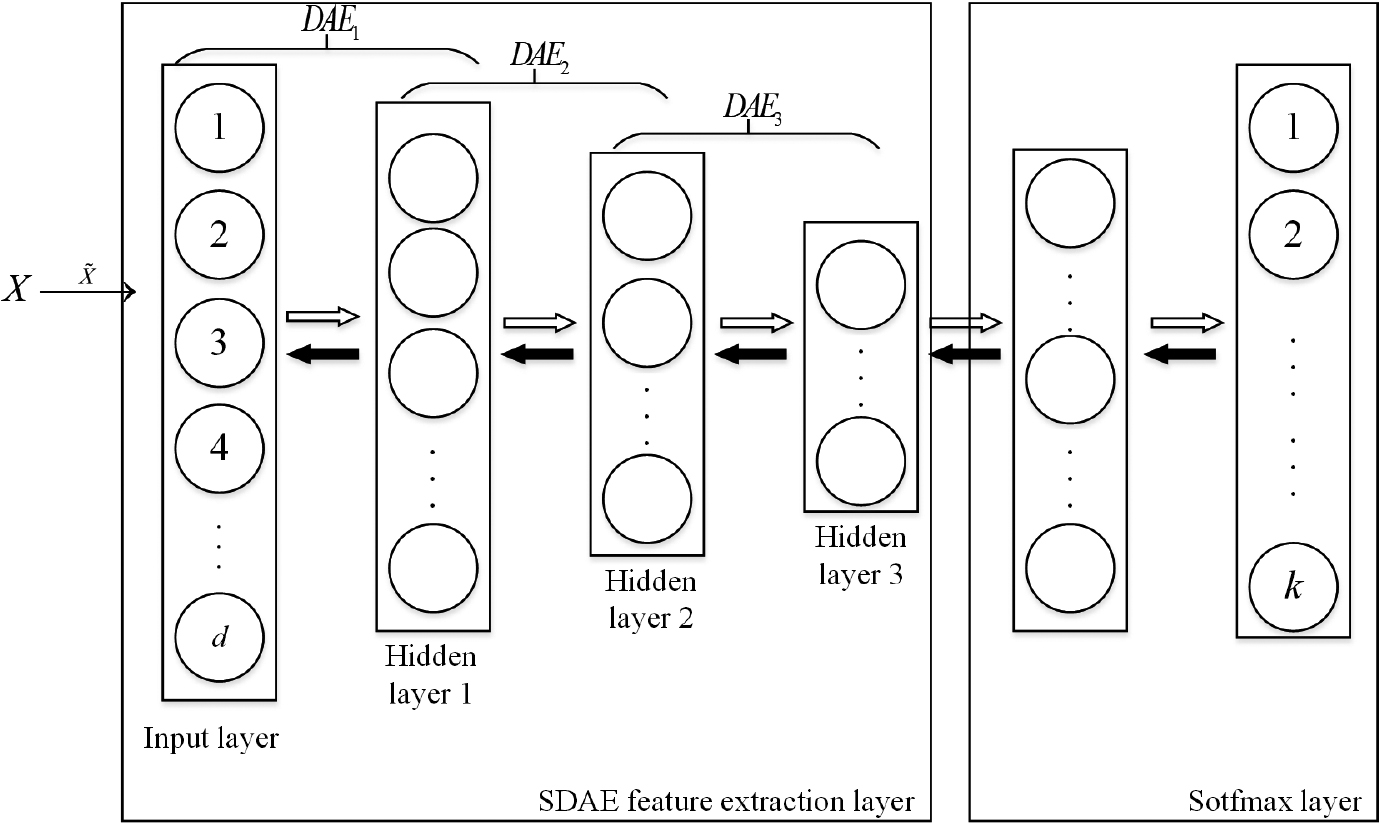
The training of SDAE
In this experiment, the cross entropy loss function is shown in Eq. (17):
where,
Algorithm 2.6 gives the pseudocode of the smart contract classification algorithm. Initializing model parameters:
[htbp] : Smart Contract Classification Algorithm
SDAE pre-train: i in range n_layers
Supervised fine-tuning: item in range train_batches
Experiments
Experiments setup
Dataset
We collected a smart contract dataset from the State of the Dapps website using a web crawler. This dataset includes 2,294 smart contract source code and 6,524,556 account transaction records. According to the classification of smart contracts by Huang et al. [5], these smart contracts are manually divided into six categories, including: tools, entertainment, finance, management, internet of things and others. To obtain better experimental results, 80% of the smart contract dataset is selected as the model training set and 20% as the test set after repeated tests. The statistical information of the smart contract dataset is shown in Table 1.
Smart contract dataset statistics
Smart contract dataset statistics
Similar to the metrics commonly adopted in classification problems, this paper uses three metrics, Precision, Recall, and F1-score, to evaluate the performance of the model [18]. The calculation of indicators is shown in Eqs (19)–(21):
where, out_tp indicates the number of smart contracts that are predicted to be positive and actually positive. out_fp presents the number that are expected positive and actually negative. out_fn shows the number that are forseen to be negative and actually positive.
This section will introduce the parameter settings of each model used in the MFF-SC method. The parameters of the model need to be determined through comparative experiments. The impact of main parameters on model performance is detailed in Section 3.2
(1)
Word2vec main parameter settings
Word2vec main parameter settings
(2)
Description and settings of TransR hyperparameter
(3)
Description and settings of SDAE hyperparameter
The impact of size on classification performance in Word2vec
The parameter size in the Word2vec model determines the number of neurons in the hidden layer, which is the dimension of the output word vector. If the size is too small, it is easy to lose some important information; If the size is too large, more training data and computing resources are required. In order to find the appropriate size value, a smart contract corpus was used to test the classification performance of the Word2vec model under different word vector dimensions, as shown in Fig. 9.
The effect of size value on contract classification.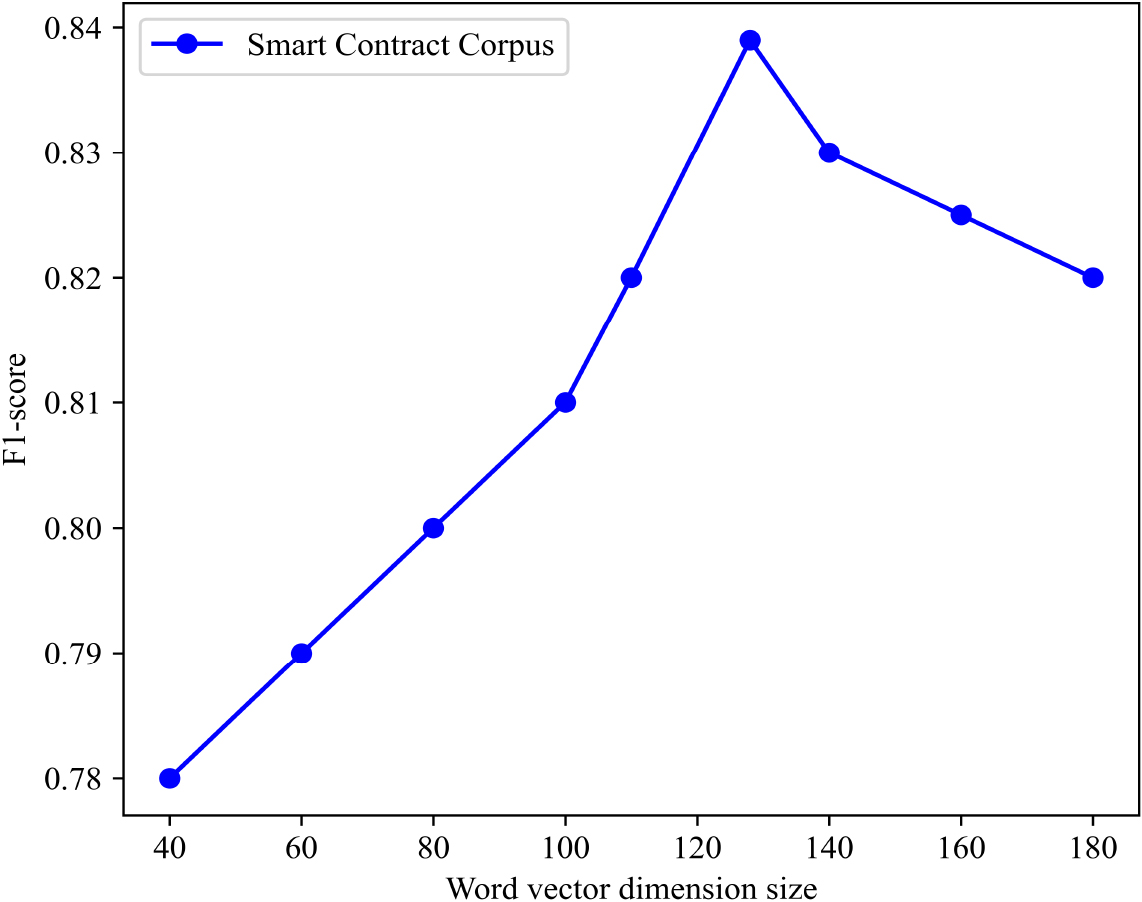
From Fig. 9, it can be seen that the F1 value of MFF-SC is also constantly changing when different values are selected for the word vector dimension size. The F1 value of MFF-SC is highest when the size reaches 128. As the size continues to increase, the value of F1 begins to decrease and the effect of MFF-SC gradually deteriorates. Therefore, we believe that a size value of 128 is the best choice for word embedding in the Word2vec model.
When training the Word2vec model, we specify the min_count value to filter out words with lower frequencies to reduce noise and improve training efficiency. If the min_count value is set too small, low-frequency words will be filtered out, which may lead to inaccurate vector representation. Therefore, by selecting an appropriate min_count parameter value through experiments, we can effectively improve the accuracy of smart contract classification while ensuring that data is not lost. When the corpus is a smart contract corpus and the output word vector dimension is 128 dimensions, this paper tests the impact of different min_count values on classification performance and word vector coverage, as shown in Fig. 10.
Analyzing Fig. 10, it can be seen that when different values are selected for min_count, the F1 value of MFF-SC is also constantly changing. As the min_count value increases, the F1 value of MFF-SC gradually increases. When the min_count value is 3, the F1 value is the highest and the word coverage rate increases rapidly. As the min_count value continues to increase, the word coverage rate gradually increases while the F1 value rapidly decreases. Therefore, we believe that a min_count value of 3 is optimal for word embedding in the Word2vec model.
Hyperparameter analysis of TransR model
There are too many types of hyperparameter in the TransR model. If we manually adjust the parameters for hyperparameter combination, it will take a lot of time. Therefore, we specify the hyperparameter range and use grid search to determine the best parameters of the model. Table 5 shows the setting of the super parameter value range of TransR.
Hyperparameter range settings
Hyperparameter range settings
The effect of min_count value on classification and coverage.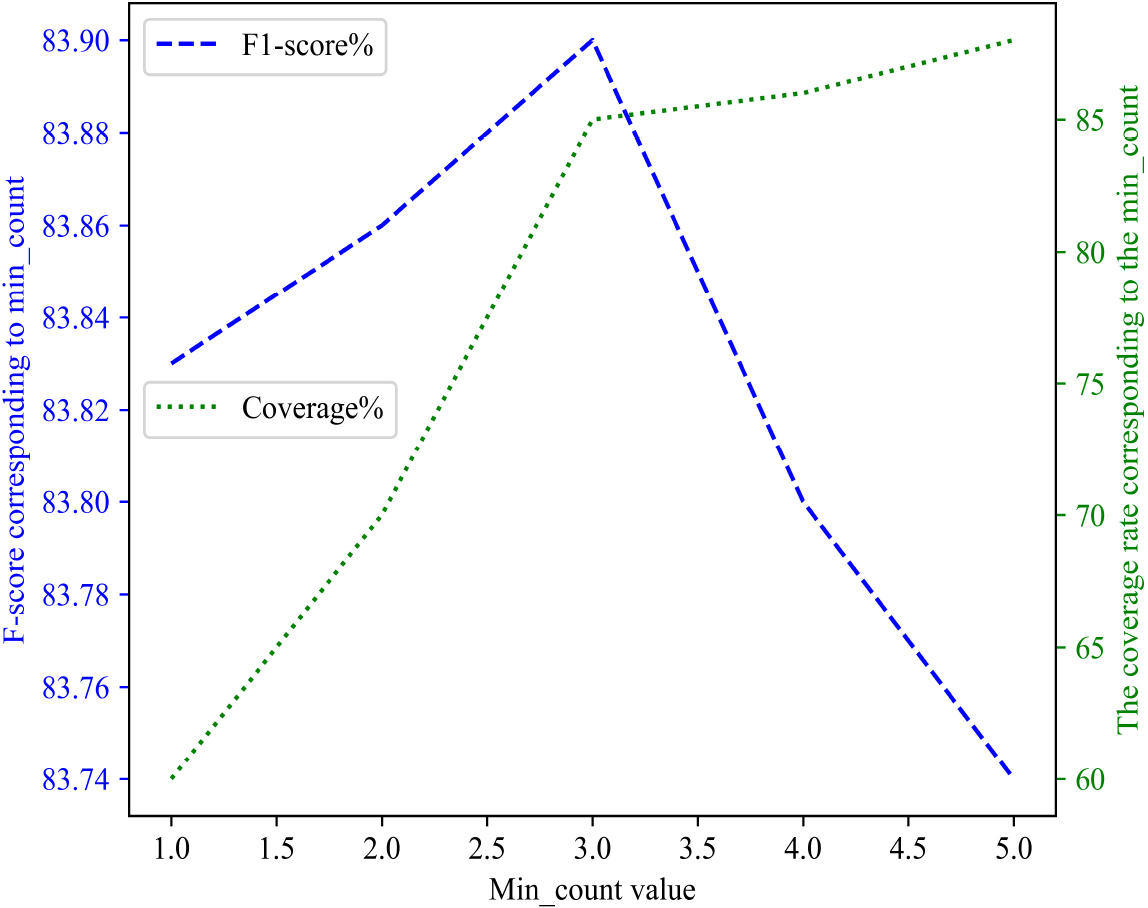
The grid search method is used to train each group of hyperparameter. We select the hyperparameter with the smallest error in the validation set to determine the best parameters of the model. The optimal configuration obtained from the training results is
As shown in Fig. 11, as the number of iterations of the model increases, the loss of the model gradually decreases. The loss of TransR training tends to flatten out when epoch is 400 and the loss value reaches its lowest.
Experimental comparison of SDAE in different layers
Experimental comparison of SDAE in different layers
TransR model training loss.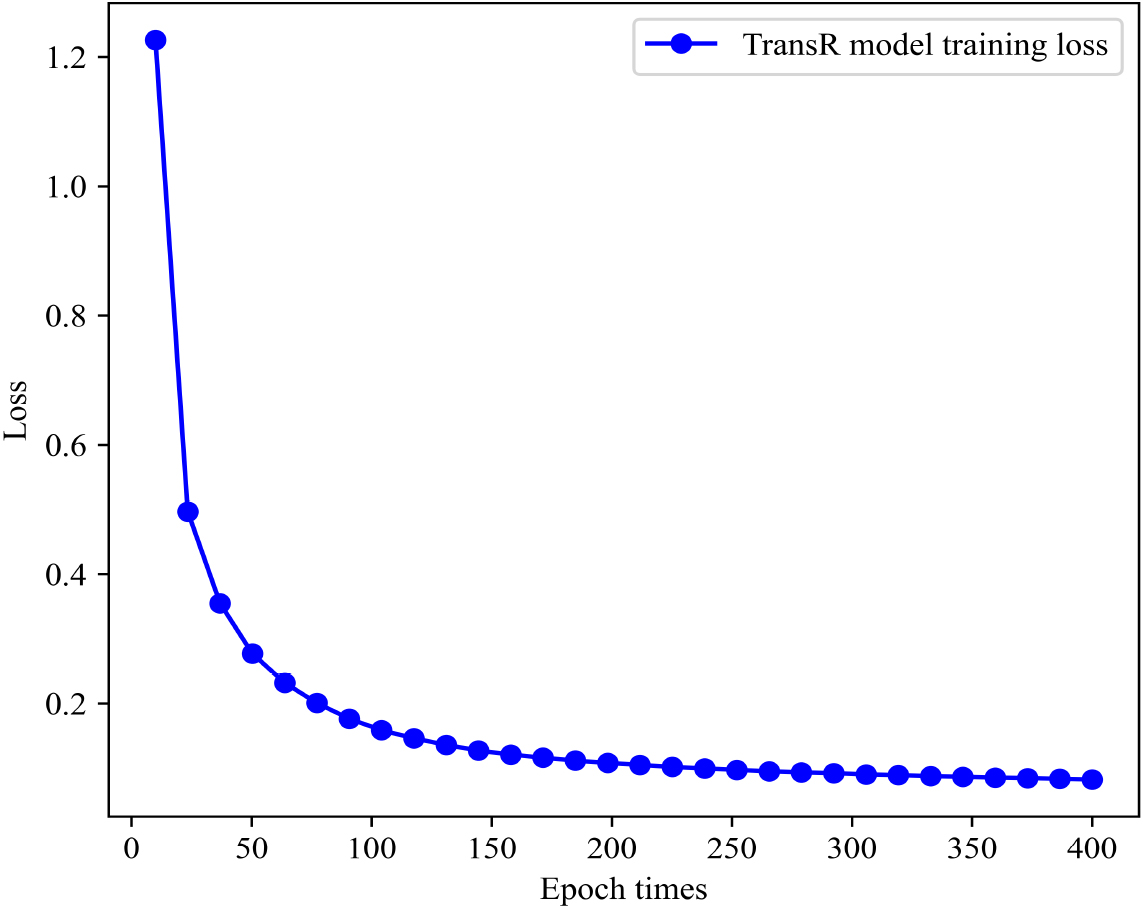
SDAE training results with different hidden layers.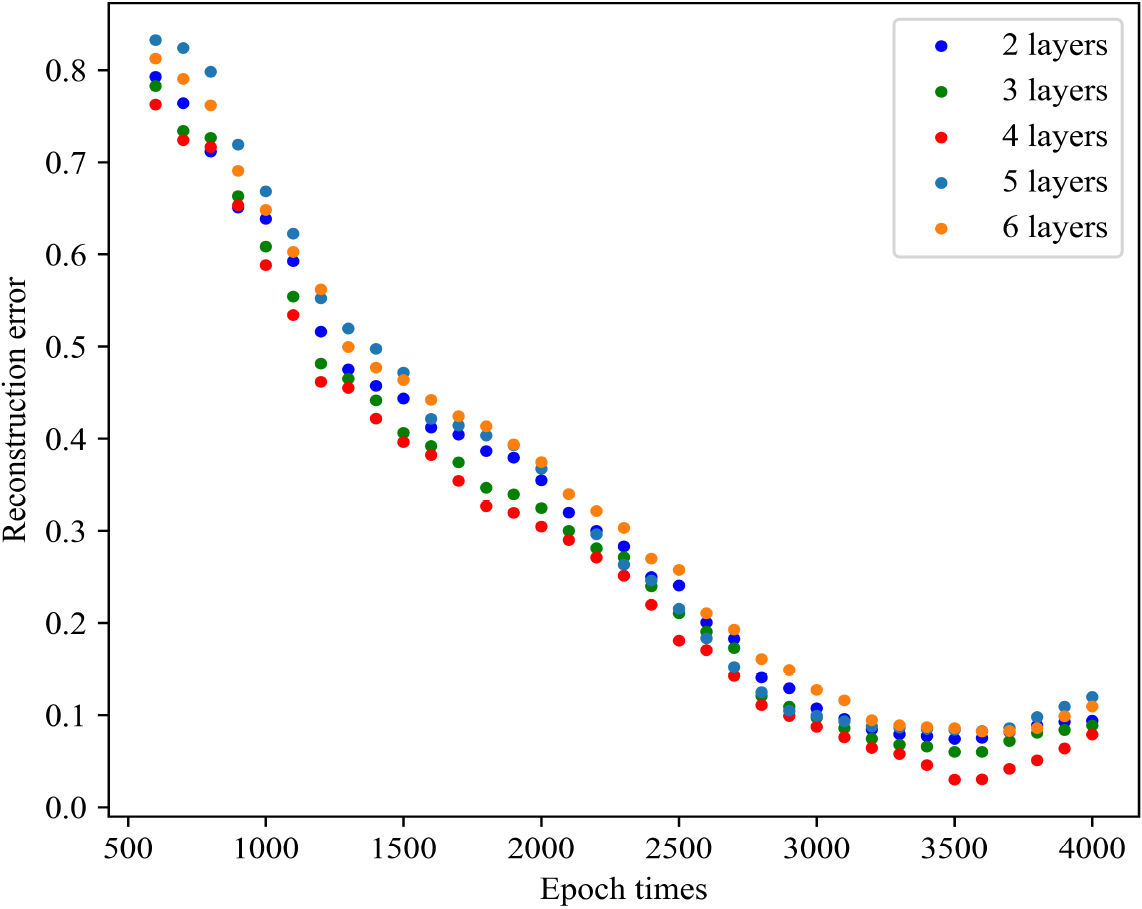
The SDAE network structure is determined by the number of layers and nodes. According to the research of Li et al. [19], in order to achieve good feature extraction performance of the encoder, the number of nodes in the first layer of the encoder’s hidden layer can be greater than twice the number of nodes in the input layer. As the number of nodes increases, the network learning ability will be enhanced. However, having too many nodes can easily lead to poor generalization ability of the network. Therefore, we chose the network structure of SDAE through experimental comparison. Due to the word embedding vector output dimension of the word2vec model being 128, we set the number of nodes in the input layer to 128 and the number of nodes in the first hidden layer to 256. We selected five different hidden layer structures of SDAE for experimental comparison. Table 6 shows five different hidden layer structures and their experimental results.
From Table 6, it can be seen that different hidden layer nodes and layers produce different classification results. The F1 values of layer 4 in the table are higher than those of layer 2 and layer 3. This indicates that the more nodes in the hidden layer, the stronger the learning ability of the network. However, as the number of layers and nodes increases, the F1 values of layers 5 and 6 decrease. This indicates that having too many nodes leads to a decrease in the generalization ability of the network. Therefore, through experimental comparison, we chose SDAE with 4 hidden layers. In addition, Fig. 12 shows the relationship between the number of iterations and the reconstruction error during the model training process. From Fig. 12, it can be seen that the more Epoch times, the lower the reconstruction error value. The error value is the lowest when Epoch reaches 3500 times. It can also be seen that the error is the smallest when the number of hidden layers in SDAE is 4. In addition, through comparative experiments, the accuracy of smart contract classification is optimal when the learning rate is set to 0.01 and the noise ratio is set to 0.2.
In order to verify the effectiveness of MFF-SC method in smart contract classification tasks and demonstrate its superiority in smart contract classification, we conducted comparative experiments with existing smart contract classification methods W2V-LSTM [5], HANN-SCA [6], and GLDA-ATBi-LSTM [7]. The comparative methods are explained as follows:
In MFF-SC, stack denoising autoencoder (SDAE) is used to extract the semantic representation of smart contracts, and heterogeneous network embedding method TransR is used to extract account transaction features. In order to verify whether the two feature extraction methods are superior to other feature extraction methods, Bi-LSTM and Bi-LSTM
To verify whether the global code feature representation generated by incorporating the AST
In order to increase the accuracy and reliability of the experimental results, we will conduct ten experiments on the comparison method, and take the average of them as the final classification result. The comparative experimental results are shown in Table 7.
The performance comparison of different methods
The performance comparison of different methods
According to Table 7, by comparing the MFF-SC method with the existing smart contract classification methods W2V-LSTM, HANN-SC, and GLDA-ATBi-LSTM, it was found that the MFF-SC method performed the best, with F1 values increased by 3.5%, 2.7%, and 1.3%, respectively. The possible reason is that although other smart contract classification methods also model features from both source code and account information, they lack processing methods in the field of software engineering for source code operations; Meanwhile, other classification methods have not taken into account the heterogeneity between account transactions. The MFF-SC method can effectively solve the above problems. Therefore, the above experiments have also proven that the source code processing method used by MFF-SC can effectively extract features related to the field of smart contracts. MFF-SC uses abstract syntax trees and structure based traversal methods to focus on the structural information of the smart contract source code; TransR can be used to represent the heterogeneity between accounts, which can better construct representations of entities and relationships. Therefore, the above experiments indicate that the MFF-SC method proposed in this paper is superior to existing smart contract classification methods.
In order to verify whether SDAE and TransR feature extraction methods are superior to other feature extraction methods, this paper selects Bi-LSTM and Bi-LSTM
To verify whether the global code feature representation generated by incorporating the AST
In order to further verify the performance of MFF-SC, this paper conducts experiments and analyses on it from the following aspects.
Performance verification on different corpus
The different corpora used during the training of the Word2Vec model will have different impacts on the classification results. Due to the fact that the smart contract corpus in this paper is generated by cleaning and organizing the smart contract dataset, the data volume of the corpus is relatively small. To verify the performance of the smart contract corpus, we selected two relatively large and commonly used text8 and Wikipedia corpora for experimental comparison. Figure 13 shows the F1 performance of MFF-SC using different corpora to train the word2vec model.
The performance of MFF-SC using different corpora.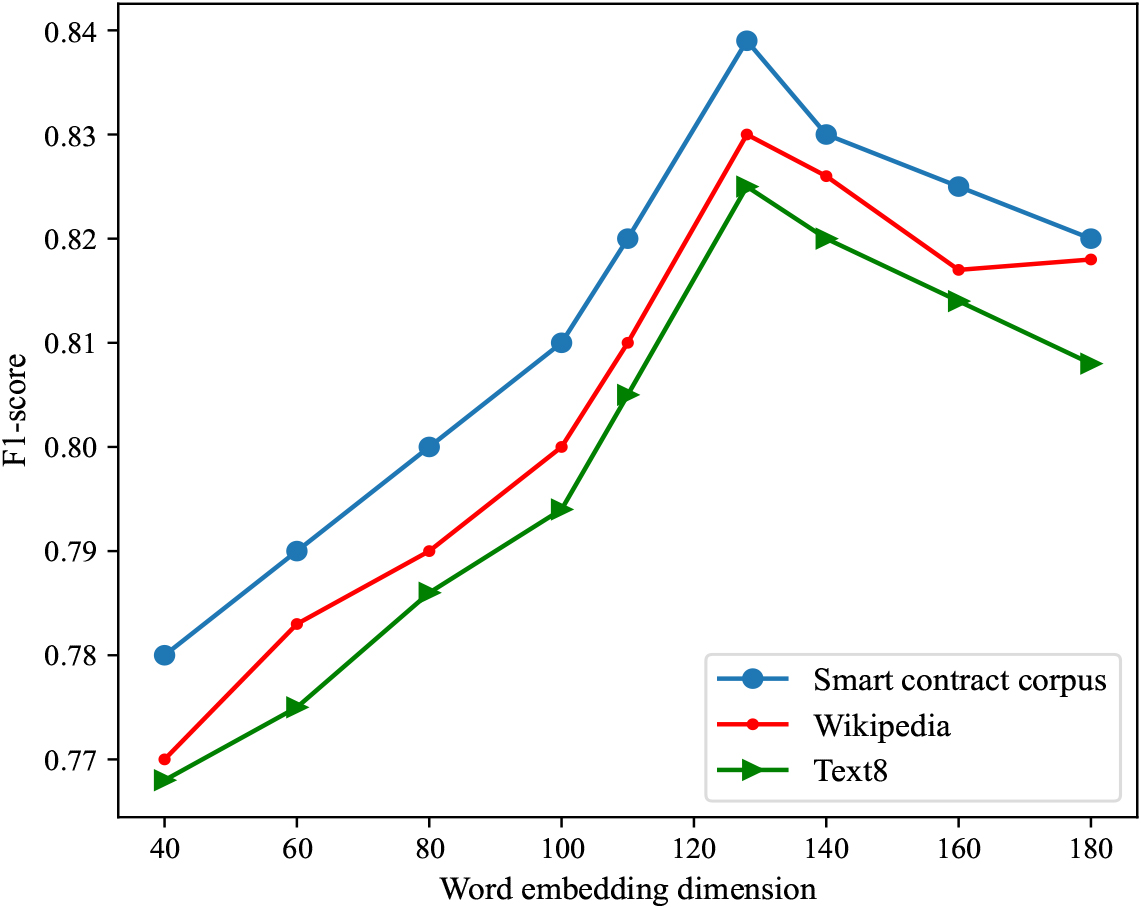
According to the experimental results, the F1 value of the smart contract corpus is much higher than that of text8 and Wikipedia. One possible explanation is that some important words extracted from smart contracts appear less frequently in text8 and Wikipedia corpora, resulting in the removal of these important words during word embedding training. Therefore, in order to maintain the optimal classification performance of the model, we use smart corpus for training the Word2vec model. In addition, the F1 value of the smart corpus is the highest when the word vector dimension is 128.
In the smart contract feature extraction layer, the source code processing (SCP) method is used to extract the local code information related to the domain, and the abstract syntax tree (AST) and structure-based traversal (SBT) method are applied to generate the global code information. At the same time, the characteristics of account transaction are obtained by TransR. To verify the effectiveness of the smart contract feature extraction layer, we compare MFF-SC with the other three methods. Figure 14 shows the F1 performance of MFF-SC using different feature extraction methods.
Method 1: It takes the source code as the input of Word2vec model for word embedding. At the same time, TransR is utilized to generate account transaction features. Method 2: It performs word embedding training on account transaction information. Both SCP and AST methods are used to generate code features. Method 3: It cleans the source code and account transaction information and take it as the input into of Word2vec model for word embedding.
The performance of MFF-SC using different feature extraction methods.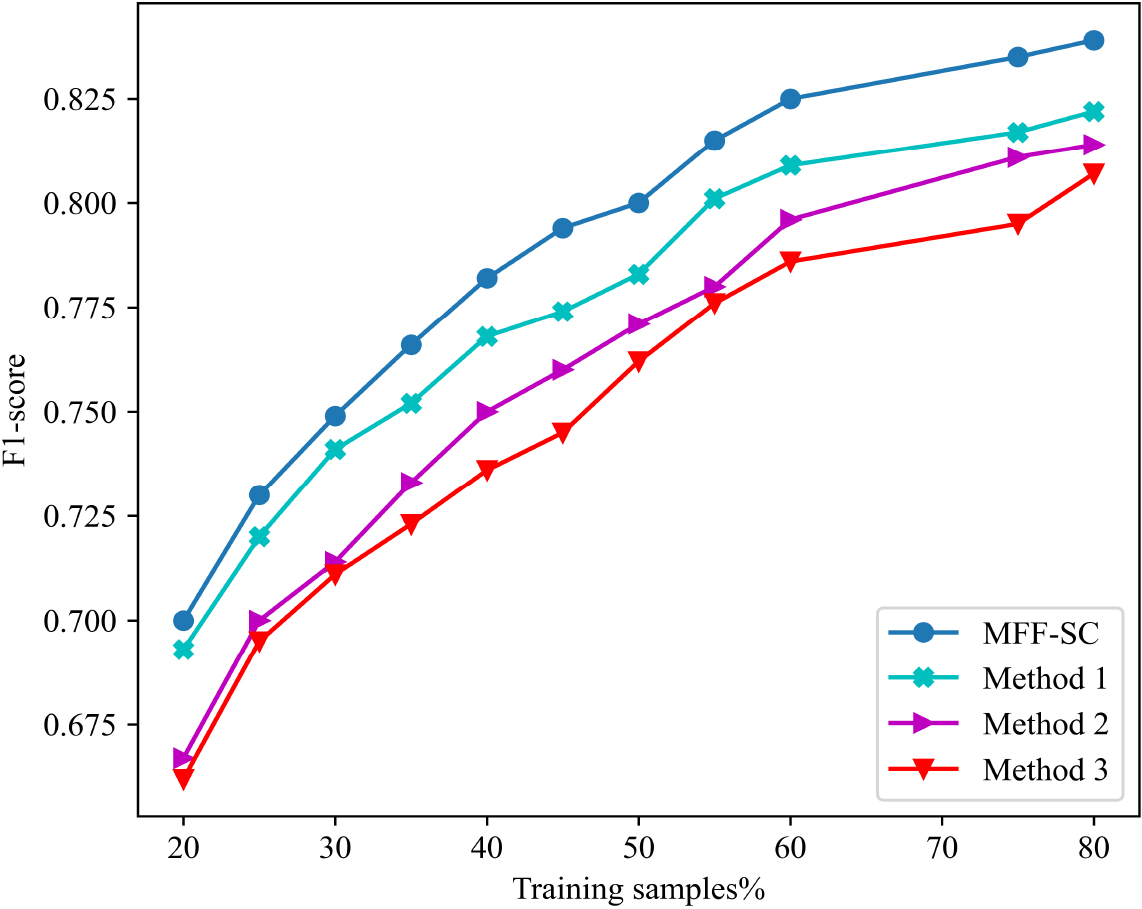
As shown in Fig. 14, it is obvious that the feature extraction method of MFF-SC has a higher F1 than the other three methods for smart contract classification. This is because using the SCP and AST to extract code features from both local and global aspects of the source code can represent the code semantic information more comprehensively. Meanwhile, considering the transactions associated with smart contract accounts, using the TransR model can make the interrelated accounts closer to each other in the relationship space. Therefore, using the feature extraction method proposed in this paper, MFF-SC obtains more information about smart contracts to effectively improve the accuracy of classification.
In this paper, the weighted combination of attention mechanism is applied when combining three local feature vectors, local and global code features, and code semantic features and account transaction features. To verify the effectiveness of the attention mechanism, we compare MFF-SC with the other four variants. The first is that no attention mechanism is added when combining local code features. Second, no attention mechanism is added when combining local and global code features. Third, the attention mechanism is not added when combining code features and account transaction features. Fourth, the attention mechanism is not added at each place. Figure 15 shows the F1 performance of MFF-SC using the above methods.
The performance of MFF-SC using different attention mechanism.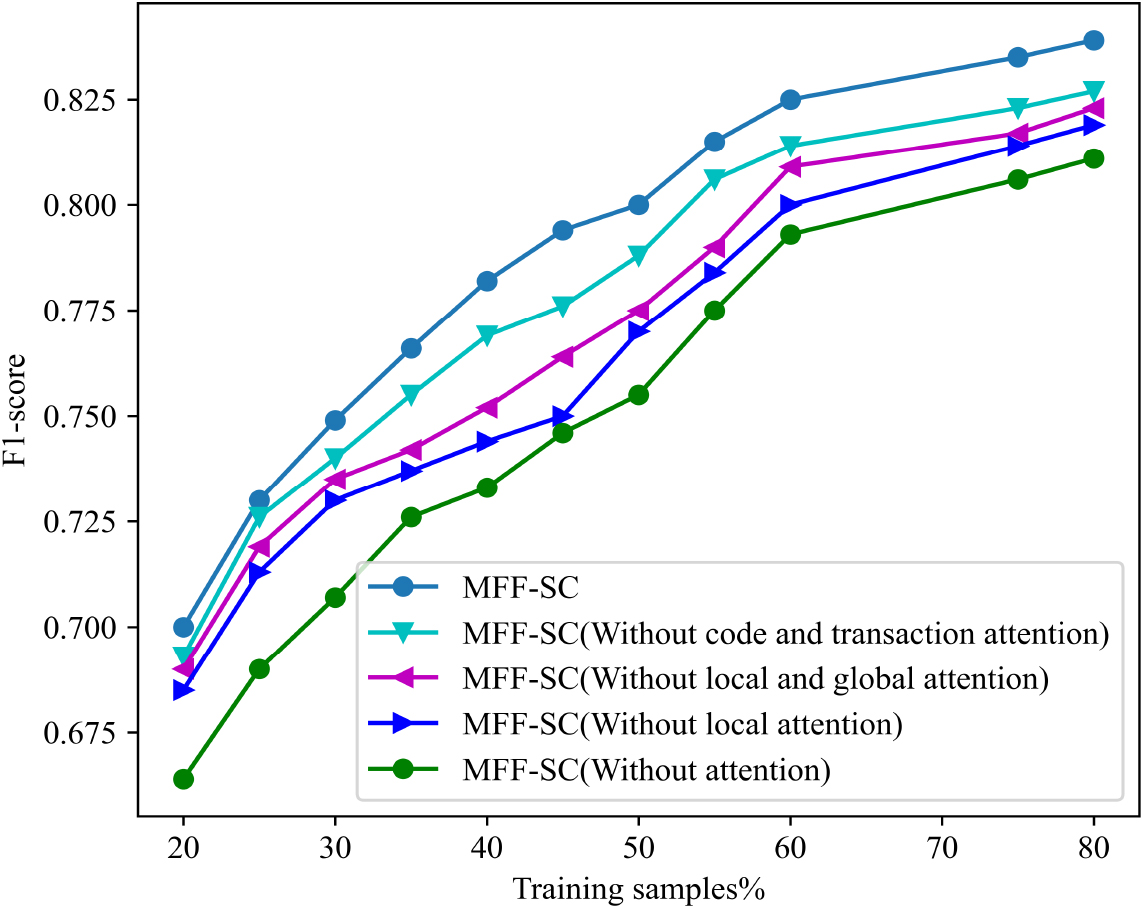
As shown in Fig. 15, it can be seen that MFF-SC has better classification results with the addition of the attention mechanism in all three places compared to the other four processing methods. Because adding attention mechanism to the neural network model will make the model focus on the key features when learning the semantic information of smart contracts, thus effectively improving the classification accuracy of the model.
In order to determine the impact of the components in MFF-SC and the various features generated by them on the final contract classification effect, this section set up ablation experiments. W/O represents “delete” in MFF-SC, with the specific settings as follows:
The experimental results obtained by training the above six methods under the same conditions are shown in Table 8.
Results of ablation experiment
Results of ablation experiment
According to Table 8, the F1 value of the MFF-SC method on the smart contract dataset is higher than that of the W/O LCF. This indicates that MFF-SC can extract important features related to the field of smart contracts using the SCP method, effectively improving the effectiveness of contract classification. The F1 value of W/O LCF is the lowest among the seven methods, indicating that local code features have the greatest impact on MFF-SC.
In addition to W/O LCF, the experimental results showed that the F1 values of W/O GCF and W/O ATC were also relatively low. This indicates that MFF-SC can effectively improve classification performance by extracting global code features and account transaction features using AST
The experimental results indicate that each feature and component of MFF-SC plays a varying role in the classification results of smart contracts. Although some parts may not have the greatest impact on MFF-SC, such as W/O CEF, W/O Attention, W/O SDAE, if any part is reduced, the F1 value of MFF-SC will decrease. This proves that each feature in MFF-SC has a positive improvement effect on classification results.
The widespread application of smart contracts has led to a sharp increase in the number of smart contracts. It is difficult for users to retrieve the most appropriate contract from tens of thousands of smart contracts; At the same time, the increase in the number of smart contracts has made the problem of information overload increasingly serious. To address the above issues, a smart contract classification system has been proposed. This system is a classification and retrieval platform based on blockchain technology. The system aims to automate the classification and management of smart contracts to improve their availability and security. The smart contract classification system based on MFF-SC designed in this papers is further optimized on the basis of the smart contract classification system. The system uses the MFF-SC model to improve classification accuracy and efficiency, effectively achieving contract detection, retrieval, and storage management.
The specific application of a smart contract classification system based on MFF-SC: The main participants of the system include ordinary users and administrators. Users can retrieve existing smart contracts on the system through categories during login. In addition, users can upload their smart contracts for category detection. The system returns classification results based on the contract data uploaded by the user. After the detection is completed, the user can also upload the contract for other users to retrieve and view. The system administrator can perform basic information management on users as well as basic data management on uploaded smart contracts. At the same time, system administrators can use the platform’s smart contract data to achieve visual training of MFF-SC.
The functional modules of the MFF-SC-based smart contract classification system include: login registration module, user management module, smart contract detection and upload module, smart contract retrieval module, contract data management module, and model training management module. The main functional modules are shown as follows:
(1) Smart contract detection and upload module
After successfully logging in to the system, ordinary users can click on “Sc detection&upload” in the left menu bar to perform contract detection. The smart contract name for the contract to be detected will be automatically generated on the detection page. After entering the smart contract subject, account information, and transaction information, users can click the “Detection” button to perform contract detection. Account information is not required. The functional display is shown in Fig. 16.
Smart contract detection interface.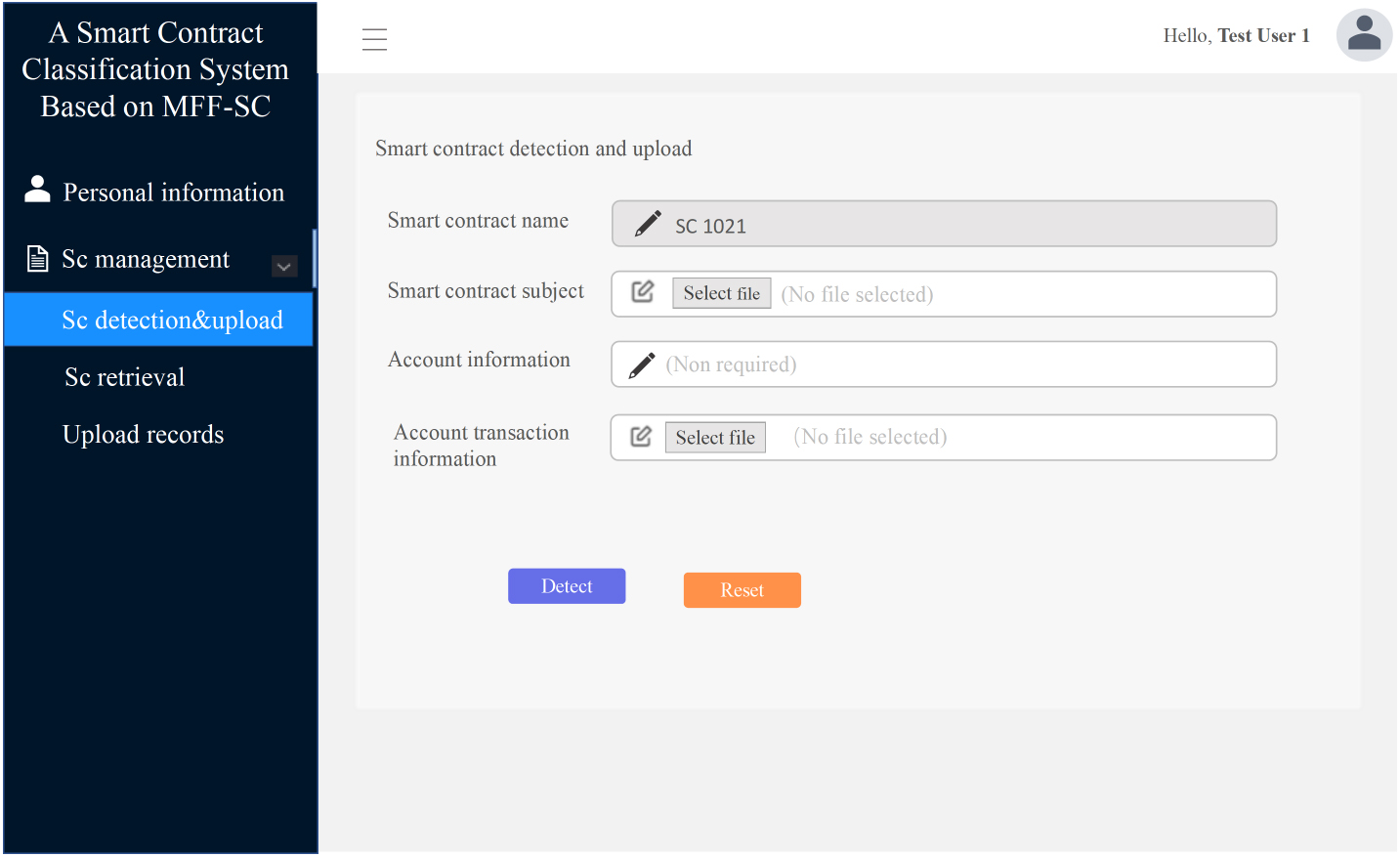
Smart contract upload interface.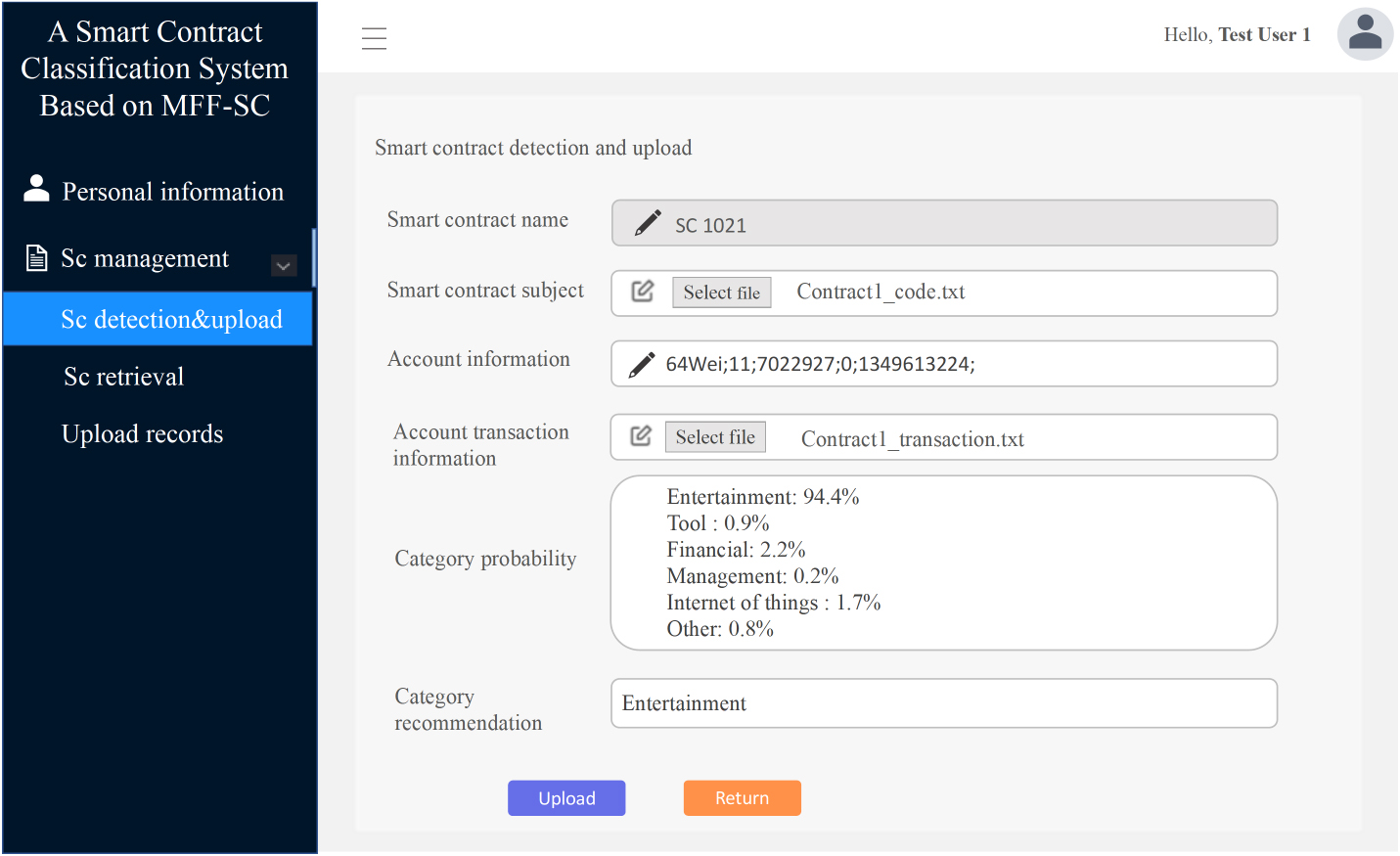
Smart contract retrieval interface.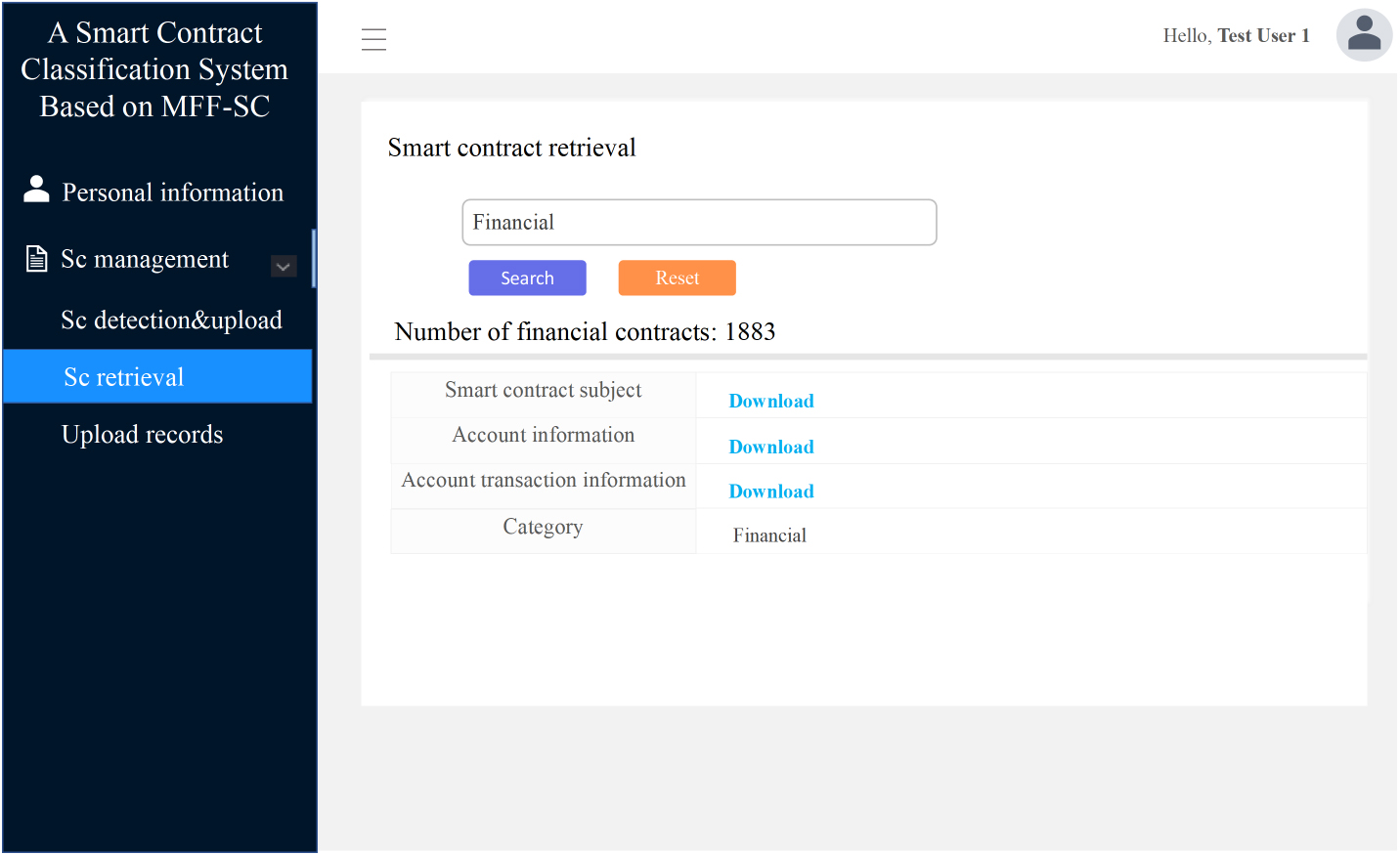
Model training management interface.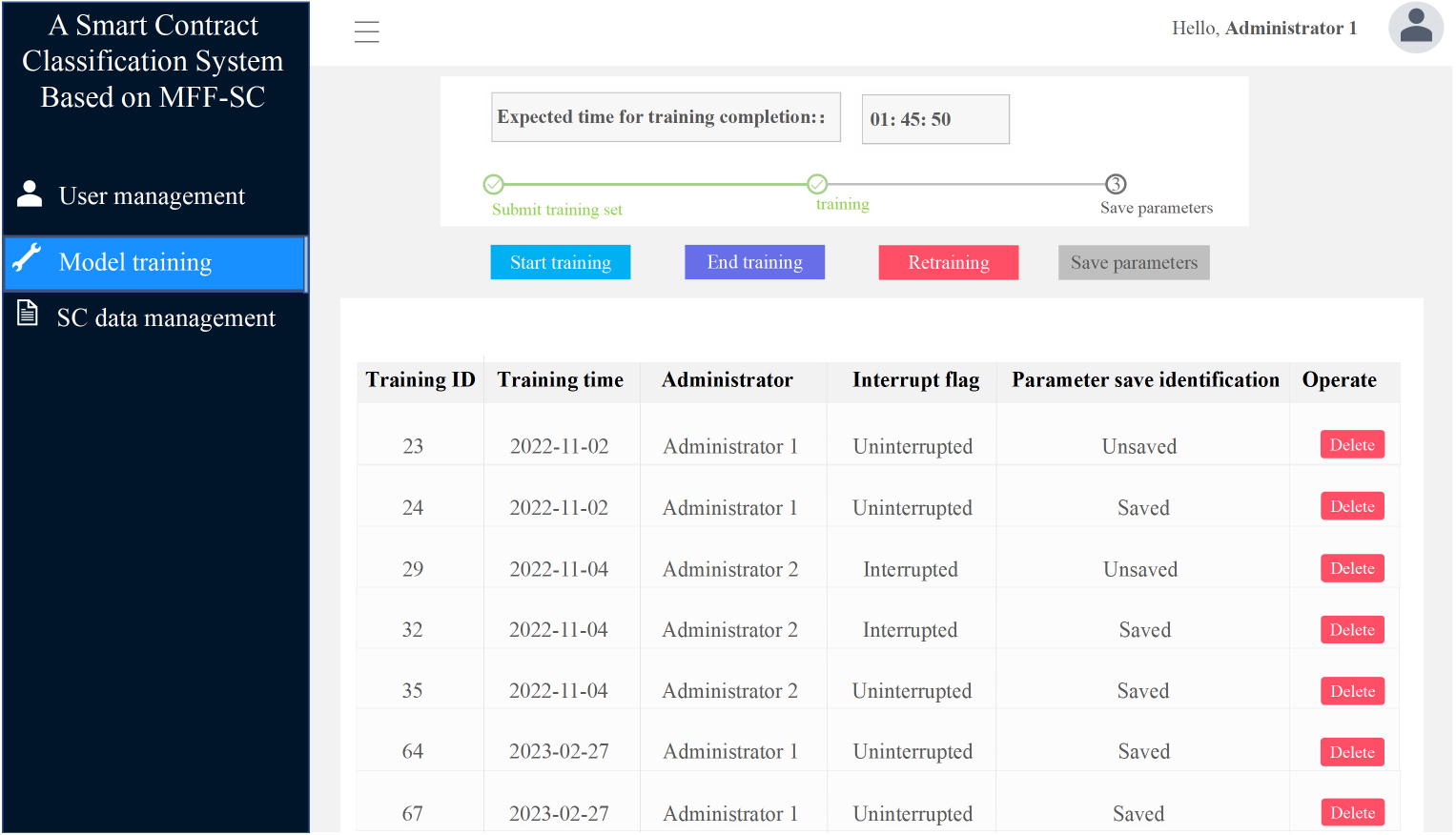
After uploading smart contract data, users can click the “Detect” button for detection. The system will perform category detection based on the content filled in by the user and the uploaded contract subject information. After the system detection is completed, it will generate category probability and category recommendation. Users can click the “Upload” button to upload the smart contract to the database. The functional display is shown in Fig. 17.
(2) Smart contract retrieval module
After logging in to the system, ordinary users can click on “Sc retrieval” in the left menu bar to retrieve the required contract. Users can enter the contract category on the search page, and the system can search and return the appropriate contract for users to download. The functional display is shown in Fig. 18.
(3) Model training management module
After logging in to the system, the administrator clicks on “Model training” to enter the visual model training interface. At the top of the model training interface, administrators can perform operations such as starting, ending, retraining, and saving training parameters. At the same time, administrators can view the training progress of the model in real-time. Due to the large amount of data operations required during the model training process and the limitations of network bandwidth and server resources, the model training is conducted offline. The functional display is shown in Fig. 19.
Current research on smart contract classification focuses on natural language processing solutions which are based on contract source code. For example, Huang et al. [5] proposed a smart contract classification method based on the word embedding model. It is worth noting that they combined source code and account transaction information of smart contract for the first time. They applied a LSTM network to generate the code semantic vector of the source code. Then, they obtained the results of classification via feeding the code semantic vector and account feature vector into a feed-forward neural network. Wu et al. [6] proposed an automatic classification model of smart contracts based on a hierarchical attention mechanism and Bi-LSTM network. They extracted the feature information of smart contracts from source code and account information by utilizing the Bi-LSTM network. They introduced attention mechanisms from the word level and the sentence level, which aimed to focus on capturing the important words and sentences. Tian et al. [7] proposed a smart contract classification approach based on the Bi-LSTM model and Gaussian LDA. The SCC-BiLSTM they proposed can take a variety of information as the inputs, including source code, comments, tags, account, and other content information. They utilized Bi-LSTM to capture grammar rules and context information in source code, and adopted the Gaussian LDA model and attention mechanism to improve the performance of the classifier. Jiang et al. [8] proposed a smart contract classification approach based on DApps categorization. In the proposed approach, three types of features are extracted from the general information data, contract code data and contract invocation data of DApps. The fused multi-feature vectors of code features, time features and value features are applied to the DApp classification model. Shi et al. [9] proposed a classification model based on features from contract bytecode instead of source code to solve these problems. They also use feature selection and ensemble learning to optimize the model.
Our research work mainly focuses on natural language processing technology based on contract source code. The processing of the source code of the above research is relatively simple and also ignores the structural information hidden. Meanwhile, the processing of account transaction information ignores the heterogeneity of the relationship between accounts. To effectively extract the source code semantic information and account transaction information of smart contracts, this paper discusses related work from the following four aspects.
To sum up, in addition to utilizing the SBT to extract global code features from AST, we also propose a SCP method to extract relevant information in the field of smart contracts as local code features. Extract account transaction features by utilizing TransR. Moreover, an attention mechanism is applied to fuse multiple features into smart contract semantic features, and the SDAE classifier is used for training and classification. Experiments demonstrate that the proposed method outperforms other baselines and variants.
In this paper, we propose a multi-feature fusion method MFF-SC based on the code processing technology for the task of smart contract classification. Specifically, information related to the field of smart contracts can be extracted using the SCP method. The AST of the source code is traversed globally by the SBT method, which can fully preserve the structural information of the source code. The attention mechanism is able to focus on important features. By considering the heterogeneity of relationships between smart contract accounts, TransR is adopted to better construct entity and relationship representations. In addition, SDAE is used to further learn the features and data structure of the dataset, thereby effectively improving the classification effect. To verify the effectiveness of the proposed MFF-SC, we conduct experiments on a real-world dataset, and compare it with several baselines and variants. The experimental results demonstrate that our method outperforms other baselines and variants by at least 3.5%. In future work, we will mine the features of AST to represent the deeper semantics of source code. Other neural models will also be explored to improve the performance of smart contract classification.
Footnotes
Acknowledgments
This work was supported in part by the grant of National Natural Science Foundation for Young Scholars (Grant No. 61702305).