
Abstract
Transformer-based networks have demonstrated their powerful performance in various vision tasks. However, these transformer-based networks are heavyweight and cannot be applied to edge computing (mobile) devices. Despite that the lightweight transformer network has emerged, several problems remain, i.e., weak feature extraction ability, feature redundancy, and lack of convolutional inductive bias. To address these three problems, we propose a lightweight visual transformer (Symmetric Former, SFormer), which contains two novel modules (Symmetric Block and Symmetric FFN). Specifically, we design Symmetric Block to expand feature capacity inside the module and enhance the long-range modeling capability of attention mechanism. To increase the compactness of the model and introduce inductive bias, we introduce convolutional cheap operations to design Symmetric FFN. We compared the SFormer with existing lightweight transformers on several vision tasks. Remarkably, on the image recognition task of ImageNet [13], SFormer gains 1.2% and 1.6% accuracy improvements compared to PVTv2-b0 and Swin Transformer, respectively. On the semantic segmentation task of ADE20K [64], SFormer delivers performance improvements of 0.2% and 0.7% compared to PVTv2-b0 and Swin Transformer, respectively. On the cityscapes dataset [11], SFormer delivers performance improvements of 2.5% and 4.2% compared to PVTv2-b0 and Swin Transformer, respectively. The code is open-source and available at:
Introduction
Transformer-based architectures, e.g., ViT (Vision Transformers) [16], Swin Transformer [35], Swin Transformer v2 [36], PVT (Pyramid Vision Transformer) [51], MobileViT [38], etc., have achieved remarkable success, demonstrating highly competitive performance compared to CNNs (Convolution Neural Networks), e.g., VGG [41], ResNet [21], ResNext [56], RepVGG [14], etc., in a variety of vision tasks. Among these Visual Transformer-based architectures, ViT [16] is the pioneer and the most popular transformer model. Typically, ViT segments the image into a string of non-overlapping patches and then uses MSA [53] (multi head self-attention) to learn representations between the patches. In performance competition, ViT-based model [35] can be achieved by increasing the model size (i.e., number of attention heads, length of tokens) to SOTA (state of the art). However, these performance gains come at the cost of reduced inference speed and increased memory footprint. Many vision applications, i.e., video surveillance, unmanned vehicles and drones, require models to run on resource-limited edge computing devices in real-time. Therefore, the ViT-based model for such applications should be lightweight and fast.
Currently, lightweight CNNs are successfully working on edge computing devices and driving many real-world vision applications. For example, [5] implemented real-time semantic segmentation and drove vehicle autopilot applications on Xilinx ZCU102, [39] implemented real-time object detection and drove autonomous motion planning application for UAV (Unmanned Aerial Vehicle) on Intel Movidius Myriad X VPU. However, ViT-based networks still struggle on edge devices due to a large number of parameters and FLOPs (floating point of operations) [28]. In contrast to lightweight CNNs, the ViT-based models are heavyweight (i.e., ViT-B/16 [16] vs. MobileNetv2 [40]: 86 million vs. 3.4 million parameters) and harder to optimize [55]. In terms of the number of patches, MSA has a secondary computational complexity. With the same parameter size, the ViT-based models tend to have higher FLOPs and consume more memory than CNNs (i.e., PVTv2-B0 vs. MobileNetv2. 0.7 vs. 0.3 GFLOPs).
Moreover, Token length (feature capacity) will limit the feature extraction ability of the model, transformer performance decreases dramatically as token embedding decreases [52, 35, 15], i.e., the token length of PVTv2-B0 is half of that of PVTv2-B1 and the Top1 accuracy decreases by 8.2%. When the size of the model is reduced to be suitable for mobile devices, Transformer model shows a performance disadvantage compared to the convolutional model (i.e., PVTv2-B0 [52] vs. MobileNetv2. 3.7 vs. 3.5 million parameters, 70.5% vs 72.0% Top-1 accuracy). Besides, MLP used by Transformer FFN is likely to generate a large number of similar redundant features due to the simple space structure and the similar initial values [20]. And, since ViT lacks the inductive bias inherent in convolution, the ViT-based models are converged slowly and sensitive to the choice of hyperparameters [55].
In this paper, we introduce convolution in ViT and combine the advantages of attention mechanisms (input adaptive weighting and global processing [58]) and convolution (inductive bias) to construct a lightweight, compact and general ViT backbone. To achieve this goal, we propose the Symmetric Former (SFormer), the structure is shown in. Specifically, SFormer mainly consists of two novel Attention modules (Symmetric Block) and FFN (Feed-Forward Network) modules (Symmetric FFN) to pursue performance and compactness. These two modules model correlations between tokens and features within tokens, respectively. SFormer follows a standard four-level structure, which has similar parameter sizes to existing lightweight networks, such as MobileNetV2 and PVTv2-B0. The contributions of this paper are three-fold:
We summarize and analyze three shortcomings of existing lightweight ViTs, i.e., weak feature extraction ability, feature redundancy, and lack of convolutional induction bias. We propose a novel lightweight and compact FFN module (symmetric FFN) and an enhanced attention module (symmetric Block) to solve these problems. Symmetric block introduces the idea of inverted residual block [40], which expands the channel capacity inside the module and enhances the long-range modeling capability of the attention mechanism. And, Symmetric FFN employs cheap operations of convolution, which introduces convolutional inductive bias and reduces the redundant features. We propose a novel ViT backbone network, Symmetric Former (SFormer), by combining Symmetric Block and Symmetric FFN. Experiments on various vision tasks demonstrate the superiority of SFormer over PVTv2-b0 and Swin Transformer. Notably, for image recognition on the ImageNet [13] dataset, SFormer achieves a 1.2% and 1.6% improvement in accuracy compared to PVTv2-b0 and Swin Transformer, respectively. On the semantic segmentation task of ADE20K [64], SFormer delivers performance improvements of 0.2% and 0.7% compared to PVTv2-b0 and Swin Transformer, respectively. On the cityscapes dataset [11], SFormer delivers performance improvements of 2.5% and 4.2% compared to PVTv2-b0 and Swin Transformer, respectively.
Light vision transformer
Transformer has been very successful in both NLP and computer vision. ViT was the first vision transformer to successfully apply the NLP transformer [6] architecture to image recognition tasks with excellent performance. Then, many scholars designed enhanced ViT models [17, 50] and achieved comparable performance to convolutional neural networks. With the development of ViT, scholars have achieved SOTA on several important vision tasks based on the ViT model, i.e., [44] proposed a novel Transformer object detection framework TSP-RCNN that achieved SOTA on COCO dataset; [43] proposed Segmenter, a novel Transformer semantic detection framework, which achieved SOTA on ADE20K and Pascal Context scene understanding datasets; [4] proposed a novel Transformer video understanding framework, ViViT, which achieved SOTA on multiple video classification datasets, i.e., Kinetics 400 and 600, Epic Kitchens, Something-Something v2 and Moments in Time. Since the computation of the MSA grows quadratically with the number of tokens, many works have constructed light and efficient vision transformers by building MSAs with near-linear computational complexity. For example, [51] proposed a linear spatially reduced attention (SRA), which achieves linear computational complexity by compressing the tokens; [24] introduced depth-separable convolution in the attention mechanism to suppress the spatial communication of the attention mechanism and reduce the computational complexity; [47] designed Quadtree Attention, which limits the self-attentive receptive field of different regions based on the intensity of attention; [26] improved information exchange by introducing token shuffle operation between cross-window attention mechanisms; Meanwhile, [35] designed window-based MSA, which restricts the receptive field of self-attentive mechanisms; [27, 9, 49, 6, 61] approximated the full attention matrix by linearizing the SoftMax attention, which can be accelerated by first computing the product of keys and values; [31] employed learned inducing points with fixed size to compute attention with input tokens and reduce the computation to linear complexity. In contrast, this paper takes the existing attention mechanism and proposes two more compact and powerful modules.
Convolution and vision-transformer
Recent work [52] shows the advantages of combining convolution and Transformer. We introduce them into three categories. The first one is the fusion of convolution and self-attention mechanisms. [58] proposed Convolutional Self-Attention (CSA) and designed a new ViT backbone network; [12] introduced two ways to combine convolution and attention mechanisms and replaced the self-attention mechanisms in ViT; [57] proposed a new self-attention mechanism that introduces convolution for local enhancement, called Locally Enhanced Self-Attention (LESA); [38] designed the Transformers as Convolutions Module and combined it with MobileNet to design a lightweight ViT backbone network. The second one is to introduce CNN in MSA module or FFN module. [10] introduced CNN into position embedding to enhance the generalization capability of the model; [33, 52] inserted the convolution operation into the FFN module to enhance the local feature representation capability of the model; [54] introduced CNN into MSA module as the input projection of self-attention mechanism. The third one is inserting CNNs in ViT architecture. [19] inserted several convolutional layers in front of ViT, which introduces the convolutional inductive bias of the model; [38] inserted several Inverted Blocks before ViT to introduce convolutional inductive bias and construct a low-latency and lightweight Transformer backbone; [7] added a CNN branch next to ViT and designed an interaction bridge. Our proposed SFormer combines CNN with Transformer in-depth and designs lightweight convolutional modules to replace the redundant structure in ViT.
Cheap Operations in CNN
Constrained by GPU computing resources, [30] proposed group convolution, which reduces computation by limiting the channel exchanges of convolutional layers. However, the performance of convolutional neural networks is severely degraded due to the limitation of group convolution on channel communication. To solve this problem, [62] proposed the channel shuffle operation and applied it between two layers of group convolution to improve the channel information exchange. Subsequently, [25] decomposed the traditional 3
Method
The architecture of our proposed symmetric former is shown in. To be specific, Symmetric Former consists of four Stages, of which “Stage1” consists of a Patch Partition module and two Symmetric Former Blocks. Each Symmetric Former Block contains a Symmetric Block and a Symmetric FFN, described in Sections 3.1 and 3.3, respectively. “Stage2”, “Stage3” and “Stage4” are composed of a Patch Merge module and several Symmetric Former Blocks. “Stage1” first employs Patch Partition to divide the input image into
Symmetric block
Inspired by Inverted Residual Block and MobileViT, we propose Symmetric Block, as shown in. Symmetric Block effectively improves the context modeling capability of MSAs in lightweight ViT networks by increasing the length of the token embedding and expanding the channel capacity within module. Symmetric Block contains two branches and a Fusion module, i.e., Global Representation branch and Local Representation branch. Specifically, the input of the Global Representation branch is considered as short tokens. And the tokens are normalized by Layer Normalization and projected as three long tokens by three MLP layers. The outputs of Layer Normalization and three MLP layers can be denoted as
Symmetric Former (SFormer). 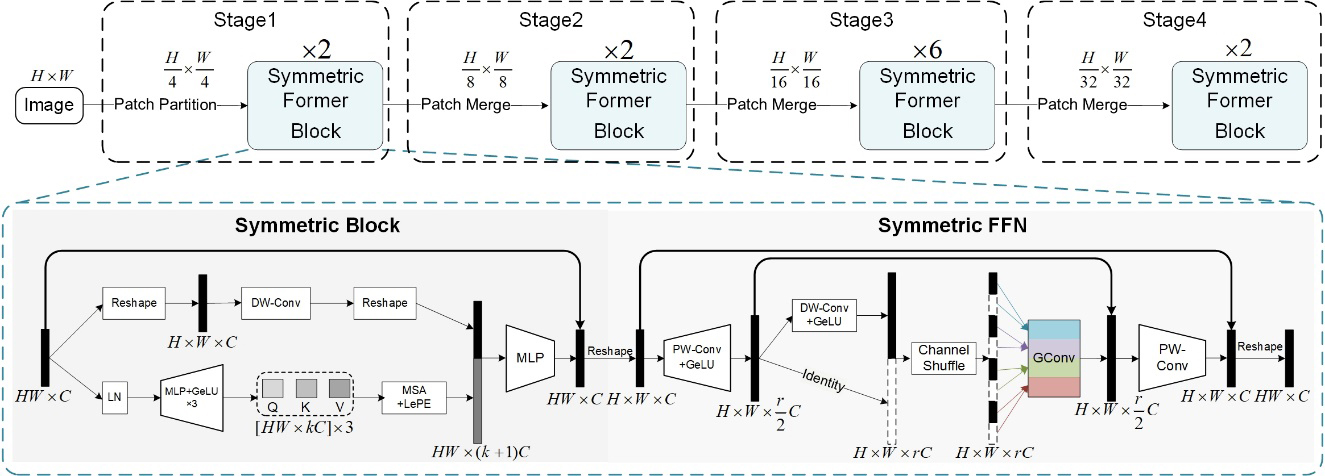
where MSA is the window-based self-attention mechanism [35], Seq2Img and Img2Seq are Reshape operations (Seq2Img takes the input from
To further represent the local spatial information of the tokens, the local representation branch employs depth-separable convolution and applies to the input. Then, MLP fuses global representation branch with local representation branch and projects them as short tokens. Finally, the input and output are connected by a residual structure. The outputs of the depth-separable convolution and Symmetric Block are represented by Eqs (3) and (4), respectively.
where
Symmetric Block. 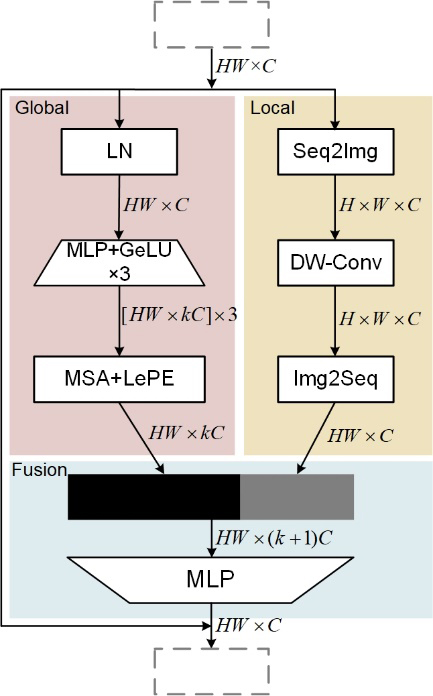
The origin FFN (shown in Fig. 3a) is proposed by ViT, which models the channel by two pointwise convolutions (MLP) and connects the input to the output using residuals. Specifically, the first convolution expands the channel capacity
To address this problem, [20] proposed the Ghost Module, whose structure is shown in Fig. 3b. Ghost Module reduces the channel expansion multiplicity by half and reduces redundant features by generating more eigenfeatures through depth-separable convolution. Ghost Module can effectively enhance the compactness and local spatial modeling capability of the model. However, [59] argues that the second pointwise convolution is responsible for expressivity and should not be oversimplified. But Ghost Module compresses the second pointwise convolution by half. The ideal improvement module is to be lightweight and compact while maintaining performance.
Symmetric FFN
Inspired by [20, 59], we propose Symmetric FFN, a lightweight and compact FFN module. The structure of Symmetric FFN is shown in Fig. 3c. We can see that the output channels of the hidden layer of Symmetric FFN are symmetrical, which are
Symmetric FFN consists of two parts, Channel Expansion and Modeling. Channel Expansion first widens the channel capacity by pointwise convolution to
Modeling contains a group convolution and a pointwise convolution. Specifically, to further reduce the number of parameters and the computational complexity of the model, the channels of the input feature map is reduced by a 3
Structure of FFN, Ghost Module and Symmetric FFN. c is the channel of current feature map and 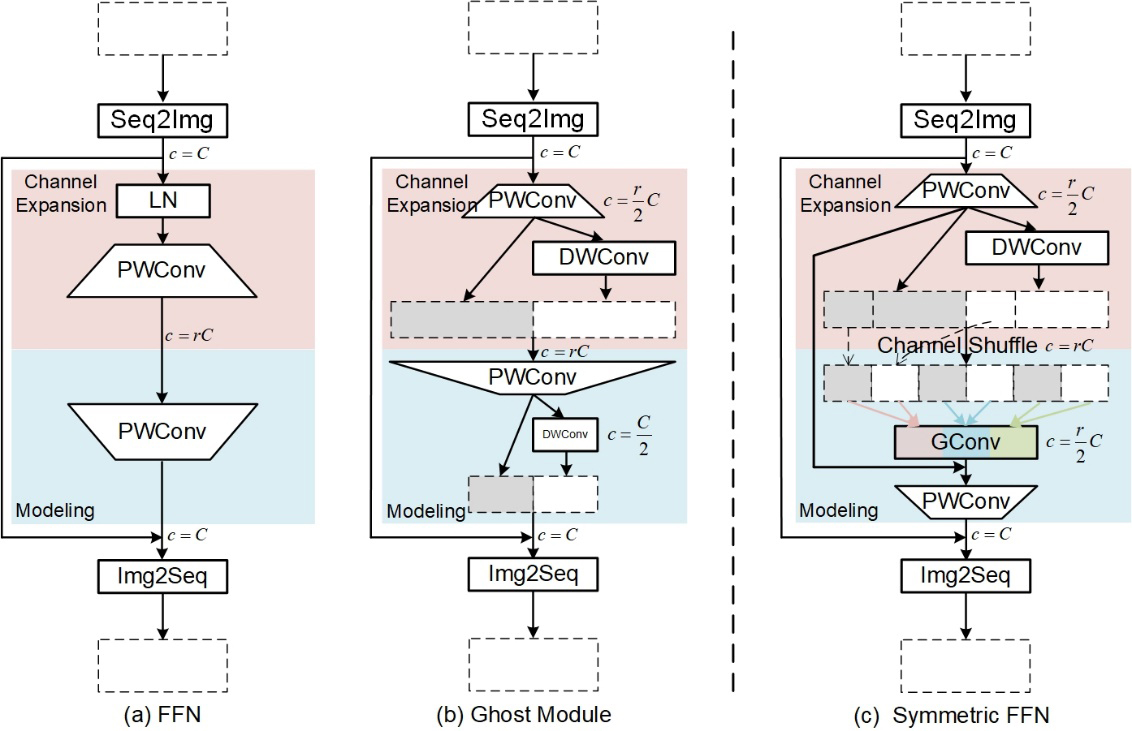
Notably, the output Channel Expansion is rearranged by a Channel-Shuffle [62] module in order to maintain the consistency of the group convolutional input channels. We define the output of Channel-Shuffle module as
We can find (as shown by the two dashed lines in Fig. 3c) that the two channels of each group of the group convolution come from
where
where
The experiments include three types of vision tasks: image classification, object detection and semantic segmentation. To evaluate the performance of SFormer, we compare SFormer with existing lightweight models.
Evaluation metrics
We evaluate the model size using #Param and FLOPs. The #Param refers to the number of parameters of the entire model (including the backbone and output layers). The FLOPs refers to the number of floating point operations of the entire model (excluding the loss function). Three vision tasks, image classification, object detection and semantic segmentation, were evaluated using top1, AP (Average Precision) and mIoU (Mean Intersection over Union) as metrics. Top1 is the number of samples with correct predictions (the category with the highest probability of the output matching the label) divided by the number of all samples. And AP is divided into six parts, i.e., AP
Image classification
Settings
The image classification experiments were performed on the ImageNet-1K dataset [21]. It contains 1,000 categories, 1.28 million training images and 50,000 validation images. All models were trained on the training set for a fair comparison. These models were then tested in the validation set and Top1 accuracy was used as an evaluation metric. We followed the data augmentation approach of Swin Transformer, which includes applying random clipping, random horizontal flipping [46], label smoothing regularization [45], blending and random erasing [63]. During training, we used the AdamW optimizer [37] with a momentum of 0.9, a small batch size of 512 and a weight decay of 5
Results
Shows the image classification performance. In the ViT model with the number of parameters less than 4M, SFormer has the same number of parameters as Swin and QuadTree-A-b0, but the highest Top1 accuracy for image classification (1.6% more accurate than Swin, 1.2% more accurate than QuadTree-A-b0, 0.1% more accurate than QuadTree-B-b0 and PVTv2-B0 by 1.6%). It is worth noting that SFormer has the same advantage over the CNN’s model. SFormer has 0.1M less parameters than MobileNetv2, but gains 0.2% improvement in Top1. To validate our improvements on the attention module, we further compare SFormer-FFN with other Transformer models with a similar number of parameters. As shown in the bottom part of, SFormer-FFN has the lowest number of parameters and computation but the highest Top1 accuracy compared to other models.
Object detection
Settings
In this paper, object detection experiments are performed on COCO dataset and Pascal VOC dataset, respectively. For COCO dataset, all models were trained on COCO train 2017 (118k images) and evaluated on COCO val 2017 (5k images). In the training phase, we randomly adjusted the short side of the input image in the range of [480, 800] and the long side of image is fixed at 1333. During the test phase, the resolution of the input image was fixed at 800
Image classification performance on the ImageNet validation set, “#P” refers to millions of parameters, “#G” refers to GFLOPs (Giga Floating Point Operations), which was calculated with an input scale of 224
224 and “Swin” refers to the Swin Transformer configured using Table 1. SFormer-FFN refers to the SFormer using the FFN Module
Image classification performance on the ImageNet validation set, “#P” refers to millions of parameters, “#G” refers to GFLOPs (Giga Floating Point Operations), which was calculated with an input scale of 224
Configurations of SFormer and compressed Swin Transformer [47]. “#C” is the embedding length of Patch Embedding, “#Blocks” is the number of blocks for each “stage”, “#heads” is the heads number of MSA for each “stage”, r is the expand ratio of FFN and Symmetric FFN
To analyze the existence of statistically significant differences in the essential performance metrics obtained by the different models, statistical analyses were performed in this paper. We performed one-way analysis of variance (ANOVA) and Tukey post-hoc tests. Since the COCO dataset and Pascal VOC dataset have been divided into training set, validation set and test set, we trained and validated the model five times, and used the results of those five experiments for statistical analysis. For COCO dataset, we used the AP
Results
We mainly compared our method with PVTv2, Swin Transformer on RetinaNet [8] and Mask RCNN [22] detection framework. Table 2 shows the results of COCO Val 2017 object detection. The overall trend is that Swin has the weakest performance and PVT has the strongest performance. Specifically, SFormer achieves higher performance in both RetinaNet and Mask RCNN detection frameworks compared to Swin Transformer which uses the same attention mechanism, but with the same number of parameters. This result demonstrates that our two improved modules effectively enhance the modeling and representation capabilities of the model. Compared to PVTv2-B0, the number of parameters is reduced by 0.3, but still maintains a competitive performance.
Results of COCO dataset. Each metrics are the mean of 5 experiments. “#G” refers to GFLOPs (Giga Floating Point Operations), which was calculated with an input scale of 800
We argue that the window-based self-attention mechanism used by SFormer limits the information exchange between sliding windows, which affects the fine granularity of detection of objects across sliding windows and large objects. Due to the restricted information exchange between sliding windows, the model struggles to precisely predict object boundaries outside the sliding window. In Table 3, We can see that the AP
ANOVA results for the COCO dataset is shown in Table 4. For AP50 metric in the COCO dataset, statistically significant differences are seen between the models (
ANOVA results of COCO dataset. “
The results of Pascal VOC dataset are shown in Table 2. In general, the performance of these three models is consistent with their performance in COCO. SFormer and Swin have the lowest number of parameters, FLOPs of Swin are somewhat lower. PVTv2-B0 has the largest number of parameters and the highest FLOPs. SFormer outperform Swin by 2.5% and 2.6% on the RetinaNet and Mask RCNN frameworks, respectively. And, the performance of SFormer is lower than that of PVTv2-B0.
Table 6 presents the results of ANOVA for Pascal VOC dataset. Same with ANOVA results for COCO dataset, the intra-group variance between the models is much smaller than the inter-group variance, and the difference statistically significant (
Results of Pascal VOC dataset. “#G” was calculated with an input scale of 600
ANOVA results of Pascal VOC dataset
Settings
We chose ADE20K and cityscapes dataset to measure the performance of semantic segmentation. We used the Semantic FPN [29] framework and the mmsegmentation [1] codebase. All models were trained under this framework for fair comparison. In the training phase, encoder was initialized with the weights pre-trained on ImageNet and the other newly added layers are initialized with Xavier [18]. We optimized our model with AdamW with an initial learning rate of 1
Results
The results of ADE20K dataset are shown in Table 7. We can observe the advantage of SFormer in terms of semantic segmentation compared to the other two models. Among them, SFormer has an mIoU improvement of 0.7% compared to Swin transformer which uses the same attention mechanism. We attribute this improvement to the introduction of convolution in the FFN module and the enhancement of the attention module. Unlike the object detection task, SFormer provides a 0.2% improvement in mIoU over PVTv2-B0 on this task. We argue that sliding windows have different effects on the semantic segmentation task and the object detection task. Semantic segmentation aims to predict the semantics of each pixel, while object detection aims to predict the boundaries of each object. On the object detection task, the model cannot predict the boundaries and center of the cross-window objects based on features within the window. For the semantic segmentation task, the semantics (class) of each pixel within the sliding window is still predictable even if the feature information is limited by the sliding window.
Results of ADE20K semantic segmentation. “#G” was calculated with an input scale of 512
512
Results of ADE20K semantic segmentation. “#G” was calculated with an input scale of 512
The results of ANOVA for ADE20K dataset are presented in Table 8. Overall, although the differences in performance between the models are quite small, statistically significant differences are reflected because the models are stable (SD
ANOVA results of ADE20K semantic segmentation. “
The results of cityscapes dataset are shown in Table 2. In general, the performance trends are consistent among the three models compared to the ADE20K dataset, but the performance gap increases. SFormer has the lowest number of parameters and the strongest performance. PVTv2-B0 has the highest number of parameters and the highest FLOPs, but the performance is weaker than SFormer. While Swin has the weakest performance.
Results of cityscapes semantic segmentation. “#G” was calculated with an input scale of 512
Table 10 lists ANOVA results for the cityscapes dataset. Compared to ADE20K dataset, the stability of three models in the cityscapes dataset is significantly lower and SD increases dramatically. It can be seen that the SD of the three models Swin, SFormer and PVTv2-B0 increases by 0.638, 0.157 and 1.036, respectively. And, ANOVA analysis shows that the differences between the models also increased, exhibiting statistically significant differences. Tukey HSD test also reveals the same results, the mean difference between the models are all larger than 1.5 and the
ANOVA results of cityscapes semantic segmentation
Despite SFormer achieves the best performance on the classification task and semantic segmentation task compared to models of the same size. However, SFormer performs worse than PVTv2 for the object detection task. from Table 3, we can see that SFormer is stronger than PVTv2 for small objects, but weaker than PVTv2 for medium and large objects. We believe that the main reason for this problem is that the window-based self-attention mechanism used by SFormer limits the information exchange between sliding windows, which affects the fine granularity of object detection across sliding windows and large objects. Due to the restricted information exchange between sliding windows, it is difficult for the model to precisely predict object boundaries outside the sliding windows.
To address the problem, we believe that there are some approaches that may solve the problem: (1) Replacing some of the attention mechanisms. For instance, alternating between window-based attention mechanisms and spatial reduction attention mechanisms; (2) Adjusting the number of attention mechanism modules of each stage. Window-based attention mechanisms start sliding windows and interacting spatial information at the second attention mechanism of each Block. Consequently, adjusting the number of attention mechanism modules of each Stage and optimizing the model structure can achieve optimization of the model performance; (3) Adopting spatial convolution to model the input and output of the attention mechanism. Introducing more convolutional induction bias, and achieving spatial information exchange through local spatial modeling.
Conclusion
We investigate three shortcomings of the lightweight Transformer, i.e., weak feature extraction ability, feature redundancy and lack of convolutional inductive bias. And two improvement modules are designed: Symmetric Block and Symmetric FFN. Symmetric Block mainly enhances the modeling ability of the model, while Symmetric FFN mainly increases the compactness of the model and introduces inductive bias. Extensive experiments on different tasks, i.e., image classification and semantic segmentation, demonstrate that the proposed SFormer is stronger than PVTv2 and Swin Transformer with comparable number of parameters. Since SFormer performs weaker than PVTv2 in object detection task, we perform further analysis and propose reasons for this phenomenon. We summarize this in Discussion, and suggest possible solutions for the future. Hopefully, the proposed SFormer model will be applied and performed on the edge computing devices, speeding up the computation of the transformer model to perform vision tasks in the future.
Footnotes
Acknowledgments
This research was funded by the National Natural Science Foundation of China (NSFC) (grant no. U21A6003), the Program of Promoting the Development of University-Diligence Talents (grant no. 5112111145).