
Abstract
Transformer-based networks have revolutionized visual tasks with their continuous innovation, leading to significant progress. However, the widespread adoption of Vision Transformers (ViT) is limited due to their high computational and parameter requirements, making them less feasible for resource-constrained mobile and edge computing devices. Moreover, existing lightweight ViTs exhibit limitations in capturing different granular features, extracting local features efficiently, and incorporating the inductive bias inherent in convolutional neural networks. These limitations somewhat impact the overall performance. To address these limitations, we propose an efficient ViT called Dual-Granularity Former (DGFormer). DGFormer mitigates these limitations by introducing two innovative modules: Dual-Granularity Attention (DG Attention) and Efficient Feed-Forward Network (Efficient FFN). In our experiments, on the image recognition task of ImageNet, DGFormer surpasses lightweight models such as PVTv2-B0 and Swin Transformer by 2.3% in terms of Top1 accuracy. On the object detection task of COCO, under RetinaNet detection framework, DGFormer outperforms PVTv2-B0 and Swin Transformer with increase of 0.5% and 2.4% in average precision (AP), respectively. Similarly, under Mask R-CNN detection framework, DGFormer exhibits improvement of 0.4% and 1.8% in AP compared to PVTv2-B0 and Swin Transformer, respectively. On the semantic segmentation task on the ADE20K, DGFormer achieves a substantial improvement of 2.0% and 2.5% in mean Intersection over Union (mIoU) over PVTv2-B0 and Swin Transformer, respectively. The code is open-source and available at:
Introduction
Transformer-based networks have achieved remarkable success in various computer vision tasks and gained significant attention. Models like Swin Transformer [1], PVT (Pyramid Vision Transformer) [2], MobileViT [3] have demonstrated superior performance compared to convolutional neural networks (CNNs) such as ResNet [4], VGG [5], MobileNet [6] and DenseNet [7]. ViT [8], as a pioneering model, segments input images into equal-sized image patches, treating them as tokens for self-attention computation within the Transformer model. This approach allows ViT to extract global features from the input images. Furthermore, ViT partially overcome some of the limitations faced by CNNs in processing large-scale images, offering performance on par with CNNs across a range of tasks. Additionally, several improved Transformer-based models, such as DeiT [9], T2T-ViT [10], and CaiT [11], have emerged, building upon the base of ViT with additional modules to heighten performance. However, these models often carry the burden of higher computational and parameter requirements, thereby slowing inference speed, increasing memory consumption, and diminishing efficiency. These factors make them unsuitable for deployment on resource-limited edge computing devices.
On the other hand, continuous innovation in lightweight CNN models has achieved significant breakthroughs on edge computing devices and has driven the development of visual applications. For instance, [12] proposed the lightweight DSUNet, which provides an efficient solution for lane detection and path prediction tasks in autonomous driving through end-to-end learning. [13] implemented a lightweight real-time road surface state recognition algorithm on the low-power embedded device NVIDIA Jetson AGX Xavier, which has advanced the field of intelligent transportation. In addition, [62, 63] had also made significant contributions to intelligent transportation systems. [60] proposed a lightweight printed circuit board (PCB) defects detection model (light-PDD), addressing the issues of redundant parameters and slow inference speed in existing methods. [61] proposed a new outlier detection method using the fuzzy C-means (FCM) algorithm, significantly contributing to defect detection in industrial applications. [56] proposed a novel method called Consistency-Dependence Guided Knowledge Distillation (CDKD), which aims to make CNN models more lightweight while maintaining fast inference speed and high detection accuracy for object detection in remote sensing (RS) images. [59] proposed a tensor decomposition and knowledge distillation-based network (TDKD-Net) for low-altitude aerial (LAA) object detection, utilizing tensor decomposition and knowledge distillation methods to reduce redundant parameters while maintaining performance. These methods provide valuable insights for deploying models on resource-constrained edge computing devices. However, these achievements seem somewhat out of reach for applications based on Transformer models. Due to their large parameter and computational requirements, Transformer-based models are challenging to deploy on resource-constrained edge computing devices. Therefore, it is necessary to propose Transformer models that are more lightweight but still deliver outstanding performance.
In this paper, we introduce convolutional operations into the structure of ViT to leverage the advantages of attention mechanisms [8] in global modeling and the efficient modeling of local features by convolutions. This combination results in a lightweight and versatile backbone network that efficiently captures features at different granularities. We name this network Dual-Granularity Transformer (DGFormer), and its structure is illustrated in Fig. 1. Specifically, DGFormer consists of two novel modules: Dual-Granularity Attention (DG Attention) and Efficient Feed-Forward Network (Efficient FFN). The DG Attention is responsible for efficiently extracting two different granularities of feature information and modeling global features, while Efficient FFN is designed to efficiently extract local feature information. Both modules possess the inductive bias [14] capability. DGFormer adopts a standard four-stage design [15], and its parameter size is similar to existing lightweight networks such as MobileNetV2 [16] and PVTv2-B0 [17]. The main contributions of this paper can be summarized in three aspects:
We propose Dual-Granularity Transformer (DGFormer), which is a lightweight Transformer-based model that incorporates convolutional operations to efficiently model features across different granularities. This design enables DGFormer to achieve competitive performance while maintaining an extremely low parameter count and FLOPs (floating-point operations). We propose two lightweight and efficient modules (DG Attention and Efficient FFN) to address the limitations of the lightweight Transformer-based models. The DG Attention module effectively extracts global feature information and models diverse granularities of features, the Efficient FFN module efficiently captures local feature information by leveraging the inductive bias of convolutions [14]. These modules effectively alleviate these limitations and significantly enhance the performance of lightweight Transformer-based models. We evaluate DGFormer on multiple vision tasks and compare it with popular lightweight models. Remarkably, DGFormer outperforms these models across all tasks, even with fewer parameters and FLOPs. In ImageNet image classification [18], DGFormer surpasses PVTv2-B0 and Swin Transformer by 2.3% in Top1 accuracy. In object detection on COCO [19, 20], with RetinaNet detector, DGFormer surpasses PVTv2-B0 and Swin Transformer by 0.5% and 2.4% in AP. With Mask R-CNN detector, DGFormer surpasses PVTv2-B0 and Swin Transformer by 0.4% and 1.8% in AP. In semantic segmentation on ADE20K [21], DGFormer surpasses PVTv2-B0 and Swin Transformer by 2.0% and 2.5% in mIoU. These results highlight the powerful performance of DGFormer across various vision tasks.
Related work
Light-weight vision-transformer
As the creator of the Transformer, Vision Transformer (ViT) has achieved tremendous success in both natural language processing (NLP) [22] and computer vision fields. However, the multi-head self-attention mechanism (MSA) [8] in ViT requires processing a large number of image patches, leading to high model parameters and computational complexity. Therefore, several approaches have been proposed to lightweight the MSA. One such approach is the Spatial Reduction Attention (SRA) mechanism introduced in PVT [2], which compresses the spatial scales of keys (
However, these existing methods have achieved lightweight ViT models to some extent and addressed redundancy, but they have not consistently demonstrated strong performance across the mentioned three visual tasks (Object detection, Classification, Semantic segmentation). For example, SFormer [57] is a lightweight ViT model and performs well in image classification and semantic segmentation tasks but shows some weaknesses in object detection. Similarly, LVT [26] performs well across the three visual tasks, it does not reach the desired level of lightweightness and still exhibits higher FLOPs and computational complexity. In contrast, our proposed DGFormer not only achieves lightweightness with lower parameter count and FLOPs, but also incorporates convolutional inductive bias and multi-granularity feature information. By maintaining lightweight design principles, DGFormer demonstrates strong performance across all the mentioned three visual tasks, outperforming the existing methods.
Convolution with vision-transformer
Due to the lack of the inherent inductive bias of convolutional neural networks (CNNs) [14], ViT models may slightly underperform lightweight CNNs in certain cases. Some researchers have found that incorporating convolutions into ViT can improve model stability and performance. These approaches can be categorized into three types. The first type involves adding convolutional stems to ViT models to introduce the inductive bias. For example, works like CMT [27, 28] add convolutional stems to ViT models to enhance their performance. Similarly, [58] proposed the Deconv-Transformer (DecT) network, where they introduced convolutional operations at the beginning of the ViT model and achieved exceptional performance. The second type involves integrating CNNs into the multi-head self-attention mechanism [8]. Works like CVPT [29] and CoaT [30] fuse convolutional and self-attention position encodings, while ConViT [31] introduces the Gated Position Self-Attention (GPSA) to incorporate soft convolutional inductive bias. CvT [32] modifies the multi-head attention in Transformers and replaces linear projection with depth-wise separable convolutions to further enhance model expressiveness. The third type involves adding CNN structures within the multi-head self-attention mechanism. Approaches such as CoAtNet [33] and LocalViT [34] enhance feature extraction capabilities by adding convolutions within the MSA. These methods often stack convolutional layers and self-attention layers alternately to introduce the inductive bias, thereby enhancing model performance. By incorporating convolutional elements into ViT models, these approaches aim to leverage the strengths of both Transformers and CNNs, resulting in improved stability and performance.
While these methods introduce convolutions into ViT models to leverage the strengths of both Transformers and CNNs, they often result in large model parameter sizes and computational complexity due to the lack of lightweight design principles. Additionally, these approaches typically focus on incorporating a single type of convolutional element. For example, CMT [27] adds convolutional stems to ViT structures to introduce the inductive bias. Similarly, CvT [32] replaces linear projection in the MSA with convolutions to incorporate the desired inductive bias. Although these approaches improve model performance to some extent, they fail to consider the significance of model parameter sizes and FLOPs. In contrast, our proposed DGFormer maintains a lightweight design while introducing convolutions in different parts of the model to incorporate the desired inductive bias. For instance, DGFormer adds a convolutional stem at the beginning of the backbone network and integrates convolutional structures within the MSA and feed-forward network (FFN) components. This novel approach achieves competitive performance while ensuring lightweightness, offering a unique and effective solution.
Method
Overall architecture
DGFormer is a powerful hierarchical model that leverages the strengths of both CNN and Transformer architectures. By synergistically combining CNN’s local perception capabilities with Transformer’s global context modeling and long-range dependency modeling abilities, DGFormer achieves a comprehensive and efficient representation for various visual tasks. Its structure, as shown in Fig. 1, consists of four stages. “Stage 1” comprises a convolutional stem and two Dual-Granularity Former Blocks. “Stage 2”, “Stage 3”, and “Stage 4” consist of a Patch Embed module and two Dual-Granularity Former Blocks. Each stage includes an Absolute Position Embedding (APE) [35] and a Relative Position Embedding (PEG) [36] to encode the spatial structure of the image. Each Dual-Granularity Former Block consists of a Dual-Granularity Attention module and an Efficient Feed-Forward Network (FFN) module. The specific details are described in Sections 3.2 and 3.3. The convolutional stem consists of stacked convolution modules, which efficiently extract local features and reduce the image size. The Patch Embed module downsamples the feature map and divides it into fixed-size image blocks, which are then inputted into the Dual-Granularity Former Block as a sequence. By utilizing the convolutional stem and Patch Embed modules, DGFormer can generate feature maps of four different sizes
Dual-Granularity Former (DGFormer). 
The Dual-Granularity Former Block, as shown in Fig. 2, consists of two LayerNorm (Layer Normalization) [8] layers, a DG Attention module, and an Efficient FFN module. Specifically, the input feature sequence is passed through two branches of the residual structure [40]. One branch undergoes Layer Normalization to expedite model convergence and then extracts dual-granularity features using the DG Attention module. The other branch is connected to the DG Attention module’s output through a shortcut, the equation is represented by the following formula:
where
The output
where
Dual-Granularity Former Block. 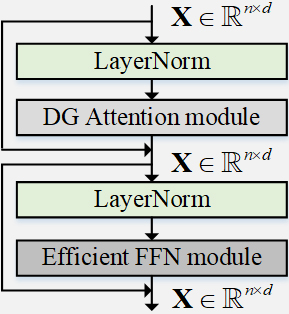
As a crucial component of the Transformer, the multi-head self-attention mechanism directly influences the performance of the model. Some studies (such as MViT [41], MViTv2 [42] and CrossVit [43]) have shown that integrating multi-scale feature information with the Transformer model can effectively improve its performance. However, the inclusion of multi-scale network structures increases the model’s parameter count and complexity, making it cumbersome and unsuitable for designing lightweight models. We believe that the increased complexity associated with multi-scale feature information primarily stems from the computation of multiple feature maps in the multi-head self-attention mechanism. To address this and achieve multi-granularity feature modeling in lightweight Transformer models, we propose the Dual-Granularity Attention module, as illustrated in Fig. 3. In the Dual-Granularity Attention module, we integrate the spatially downsampled dual-granularity feature information into the keys (
Dual-Granularity Attention (DG Attention) module.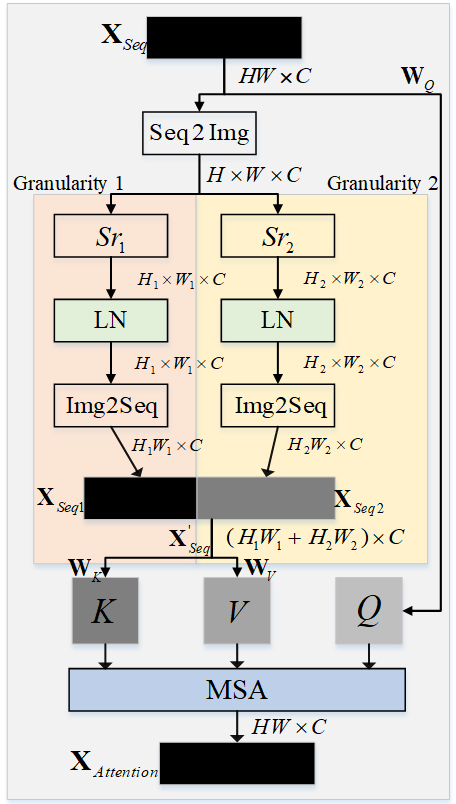
As shown in Fig. 3, Dual-Granularity Attention module primarily consists of two branches: Granularity 1 and Granularity 2, designed to efficiently model features at different granularities. Building upon PVT’s inspiration, we downsample
where
where
where
where
where
where
While the multi-head self-attention mechanism captures the correlations among all positions in the generated feature sequence, its utilization in the original Feed-Forward Network (FFN) is not fully optimized. Additionally, although the FFN can learn complex linear relationships between different positions and effectively extract local features, we believe that its feature representation capacity can be further improved. To address these limitations, we introduce the SE (Squeeze-and-Excitation) attention mechanism [44] and propose a lightweight and efficient version of the FFN called Efficient Feed-Forward Network (Efficient FFN). By incorporating the SE attention mechanism, the Efficient FFN enables the FFN to focus more on important channels within the input features, thereby enhancing the feature representation capacity and further improving the model’s performance. This improvement is particularly effective for tasks that require modeling global features, as the SE attention significantly improves the model’s performance and achieve better results.
Structure of efficient feed-forward network (efficient FFN).
As shown in Fig. 4, the Efficient FFN module primarily consists of two components: an efficient feature extraction part and a channel attention weighting part. The efficient feature extraction part begins by applying Layer Normalization (LN) [8] operations to the input feature sequence denoted as
Then, efficient feature extraction is performed using the Efficient Convolutions module (EConvs). Specifically, EConvs is composed of stacked PointWise Convolution (PWConv), DepthWise Convolution (DWConv), and PWConv layers. The first PWConv expands the channel dimension of the feature map to a higher dimension (
The channel attention weighting part applies SE (Squeeze-and-Excitation) attention operations to the input feature map, resulting in a weighted feature map denoted as
This operation assigns weights to the channels of the feature map based on their importance. Next,
This structure helps Efficient FFN to effectively integrate global and local features when handling complex sequence models, providing significant advantages in tasks that require modeling global information. Furthermore, it introduces the inductive bias inherent in convolutional operations, further enhancing the model’s ability to extract local features. Consequently, this mitigates to some extent the limitations faced by Transformer-based models, which lack this inductive bias.
In this section, we explore the effectiveness of DGFormer by conducting experiments on three different vision tasks: image classification, object detection, and semantic segmentation. Our objective is to evaluate the performance of DGFormer by comparing it with existing lightweight models in these tasks.
Evaluation metrics
We evaluate the model’s size by considering the number of parameters (#Param) and the number of floating point operations (FLOPs) performed by the model (including both the backbone and output layers). Image classification, object detection, and semantic segmentation, are evaluated using Top1, AP (Average Precision), and mIoU (Mean Intersection over Union). Top1 measures the accuracy of the model by calculating the ratio of correctly predicted samples (the category with the highest probability matches the label) to the total number of samples. AP is divided into six parts: AP50:5:95, AP50, AP75, APS, APM and APL. AP50 and AP75 represent the IoU (Intersection over Union) thresholds between the predicted objects and the labels, set at 0.5 and 0.75, respectively, and then AP is calculated based on a range of correct and incorrect samples. AP50:5:95 is expressed as the IoU thresholds between the predicted objects and the labels ranging from 0.5 to 0.95 with a stride of 0.05 and AP is subsequently calculated separately and taken as the mean value. APS, APM and APL represent the AP calculated specifically for small, medium, and large objects, respectively. mIoU is measured in pixels and is calculated as the intersection between predicted and labeled regions divided by the union of the two.
Image classification
Settings
The image classification experiments were performed on the ImageNet-1K dataset [18], which consists of 1,000 categories, 1.28 million training images and 50,000 validation images. For fair comparison, all models were trained on the training set, and the Top1 accuracy on the validation set was reported. Data processing techniques were employed to enhance the training process. Specifically, we followed the data augmentation approach of PVT, which included random cropping, random horizontal flipping [45], label-smoothing regularization [46], mixup [47], CutMix [48], and random erasing [49]. For optimization, we employed the AdamW optimizer [50] with a momentum of 0.9, a mini-batch size of 256, and a weight decay of 5
Results
In Table 1, the performance of the DGFormer model on classification datasets is presented. Among ViT models with less than 6M parameters, DGFormer has the fewest parameters (3.4M), which is the same as Swin [1] and QuadTree-A-b0 [51]. However, DGFormer achieves the highest Top1 accuracy (72.8%) for image classification, surpassing Swin and PVTv2-B0 by 2.3%, QuadTree-A-b0 by 1.9%, QuadTree-B-b0 [51] by 0.8%, T2T-ViT-7 [10] by 1.1%, DeiT-Tiny/16 [9] by 0.6%. Note that DGFormer also exhibits similar advantages compared to CNN models. DGFormer has 0.1M fewer parameters than MobileNetv2, but achieves a 0.9% improvement in Top1 accuracy. Overall, DGFormer demonstrates impressive performance in image classification tasks among lightweight models.
To validate the performance of the DG Attention module, we compared the DGFormer-FFN model with other Transformer models that use the same FFN module. Compared to PVTv2-B0, the results shown in Table 1 indicate that DGFormer-FFN achieves a 1.8% improvement in Top1 accuracy while reducing 0.1 GFLOPs and 0.3M parameters. Compared to models like Swin, QuadTree-A-b0, and QuadTree-B-b0, it also demonstrates relatively higher Top1 accuracy with fewer or similar parameters and GFLOPs. This suggests that the DG Attention module has better computational efficiency while maintaining competitive performance compared to other Attention modules.
To validate the performance of the Efficient FFN module, we further conducted a comparison between DGFormer-FFN and DGFormer (using the Efficient FFN module). The results, presented in Table 1, demonstrate that DGFormer achieves a higher Top1 accuracy by 0.5% with a 0.1 GFLOPs reduction. This indicates that the Efficient FFN module possesses computational efficiency while maintaining competitive performance compared to the original FFN module.
Image classification performance on the ImageNet validation set, “#Param” refers to number of parameters, “GFLOPs” refers to Giga Floating Point Operations, which is calculated with an input scale of 224
224 and “Swin” refers to the Swin Transformer [57], DGFormer-FFN refers to the DGFormer using the FFN Module
Image classification performance on the ImageNet validation set, “#Param” refers to number of parameters, “GFLOPs” refers to Giga Floating Point Operations, which is calculated with an input scale of 224
Obeject detection performance on COCO val2017. Each metrics are the mean of 5 experiments. “#Param” refers to number of parameters, “GFLOPs” refers to Giga Floating Point Operations, which is calculated with an input scale of 800
Settings
Object detection experiments were performed on the challenging COCO benchmark [19]. All models were trained on COCO train2017 (118k images) and evaluated on COCO val2017 (5k images). The efficiency of the DGFormer backbone was assessed in combination with two standard detectors (RetinaNet [37] and Mask R-CNN [38]), and compared against PVTv2-B0 and Swin Transformer. Before training, data processing techniques were applied to initialize the backbone. We employed weights pre-trained on ImageNet to initialize the backbone, while the newly added layers were initialized using Xavier [52]. Our models were trained using an AdamW optimizer [50] with an initial learning rate of 1
Results
As shown in Table 2, the results obtained from RetinaNet and Mask R-CNN for object detection consistently demonstrate that Swin Transformer performs the weakest, while DGFormer achieves the highest performance. Specifically, under RetinaNet detection framework, DGFormer stands out with its lowest number of parameters (12.6 vs. 12.7 and 13.0) and lowest GFLOPs (167.2 vs. 168.6 and 186.1), yet it outperforms PVTv2-B0 by 0.5% (37.6 vs. 37.1) in terms of average precision (AP50:5:95) and surpasses Swin Transformer by 2.4% (37.6 vs. 35.2). Additionally, DGFormer achieves highest scores in term of APS, APM and APL, indicating its efficiency in capturing objects of all scales. Similarly, under Mask R-CNN detection framework, DGFormer exhibits comparable performance. It stands out with the lowest number of parameters (23.1 vs. 23.2 and 23.5) and second lowest GFLOPs (183.1 vs. 171.5 and 188.7), but it outperforms PVTv2-B0 by 0.4% (38.6 vs. 38.2) in terms of AP50:5:95 and surpasses Swin Transformer by 1.8% (38.6 vs. 36.8). Once again, DGFormer also achieves the highest score in term of APS, APM and APL. These experimental results demonstrate the powerful of our model.
Semantic segmentation performance of different backbones on the ADE20K validation set. “#Param” refers to number of parameters, “GFLOPs” refers to Giga Floating Point Operations, which is calculated with an input scale of 512
512 and “Swin” refers to the Swin Transformer [57]
Semantic segmentation performance of different backbones on the ADE20K validation set. “#Param” refers to number of parameters, “GFLOPs” refers to Giga Floating Point Operations, which is calculated with an input scale of 512
Settings
We chose the ADE20K dataset [21], a challenging scene parsing dataset, to analyze the performance of our models in semantic segmentation. ADE20K consists of 150 fine-grained semantic categories, with 20,210, 2,000, and 3,352 images allocated for training, validation, and testing, respectively. Our experiments were conducted using the Semantic FPN framework [39] and the mmsegmentation [54] codebase, ensuring fair comparison within this framework. Before training, data processing techniques were applied to initialize the DGFormer backbone. We initialized the backbone with weights pre-trained on ImageNet [18], while the newly added layers were initialized using Xavier [52]. Our model was optimized using the AdamW optimizer [50] with an initial learning rate of 1
Results
As shown in Table 3, when Semantic FPN is used for semantic segmentation, DGFormer demonstrates significant results compared to the other two models. PVTv2-B0 has the highest number of parameters and GFLOPs, yet its performance is weaker than DGFormer. Swin Transformer, on the other hand, exhibits the weakest performance. Specifically, DGFormer stands out with the second lowest number of parameters (7.2 vs. 6.8 and 7.6) and lowest GFLOPs (23.5 vs. 24.0 and 25.0), but it outperforms PVTv2-B0 by 2.0% (39.2 vs. 37.2) in terms of mIoU and surpasses Swin Transformer by 2.5% (39.2 vs. 36.7). We believe that the remarkable performance of DGFormer on ADE20K can be attributed to its Dual-Granularity Attention mechanism. This mechanism efficiently models different fine-grained feature information, enabling DGFormer to excel in semantic segmentation tasks that require a high level of detail in feature representation.
Conclusion
Through our research on lightweight Transformer models, we identified three primary limitations: insufficient capability to extract features at different granularities, weak capacity for local feature extraction, and the lack of inherent inductive biases specific to convolutional operations. To mitigate these limitations, we introduce DGFormer, a lightweight powerful Transformer backbone for three vision tasks (image classification, object detection, semantic segmentation). DGFormer is equipped with two new modules: Dual-Granularity Attention (DG Attention) module and Efficient Feed-Forward Network (Efficient FFN) module. The DG Attention module is designed to boost the global modeling capacity of the model, enabling it to extract features at different granularities. In contrast, the Efficient FFN module focuses on the efficient extraction of local features. Notably, both these modules incorporate inductive biases, addressing a major limitation of existing lightweight Transformer models. Our extensive experimental evaluation, conducted across three visual tasks, indicates that DGFormer outperforms established models such as PVTv2 and Swin Transformer. This superior performance is achieved with fewer parameters and reduced FLOPs, demonstrating the model’s efficiency. In future research directions, we will focus on improving the performance of DGFormer to make it more practical and efficient in real-world applications. We believe that DGFormer has particular value in the context of edge computing devices, where its capabilities can be effectively leveraged. Furthermore, we hope that our work will become a benchmark for future research in the field of lightweight vision transformers. We also hope that our research outcomes will provide a valuable reference for research in the field of lightweight vision transformers, and promote further development in this field.
Footnotes
Acknowledgments
This research was funded by the National Natural Science Foundation of China (NSFC) (grant no. U21A6003), the Program of Promoting the Development of University-Diligence Talents (grant no. 5112111145).
Conflict of interest
All authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.