
Abstract
As a list of remotely sensed data sources is available, the effective processing of remote sensing images is of great significance in practical applications in various fields. This paper proposes a new lightweight network to solve the problem of remote sensing image processing by using the method of deep learning. Specifically, the proposed model employs ShuffleNet V2 as the backbone network, appropriately increases part of the convolution kernels to improve the classification accuracy of the network, and uses the maximum overlapping pooling layer to enhance the detailed features of the input images. Finally, Squeeze and Excitation (SE) blocks are introduced as the attention mechanism to improve the architecture of the network. Experimental results based on several multisource data show that our proposed network model has a good classification effect on the test samples and can achieve more excellent classification performance than some existing methods, with an accuracy of 91%, and can be used for the classification of remote sensing images. Our model not only has high accuracy but also has faster training speed compared with large networks and can greatly reduce computation costs. The demo code of our proposed method will be available at
Introduction
In recent years, with the continuous development of aerial remote sensing technology and satellite remote sensing technology, more and more high-resolution remote sensing images provided by special satellite sensors have appeared. The effective processing of these remote sensing images is of great significance in many practical applications such as urban planning, land use, disaster detection, weather prediction, and environmental monitoring. In terms of resource and environmental monitoring, remote sensing image classification can help us accurately identify and count the distribution and changes of various natural resources, such as land cover, vegetation, water bodies, etc. In urban planning and management, remote sensing image classification can help us accurately identify various types of urban buildings, roads, green spaces, and other land features, providing important information support for urban planning, traffic management, environmental assessment, and emergency response. In terms of agriculture and meteorological prediction, remote sensing image classification can help us accurately identify crop planting, growth, and yield, providing scientific guidance and support for agricultural production. At the same time, remote sensing image classification can also be used for meteorological prediction, such as vegetation index, water cover, etc., providing data support for climate research and meteorological forecasting. With the continuous progress of remote sensing technology and the popularization of high-resolution remote sensing images, remote sensing image classification tasks will play an increasingly important role in providing more accurate, timely, and comprehensive information support for various industries.
It is obviously unrealistic to manually identify and classify a large number of remote sensing images, which urgently need to be processed and interpreted in an automatic and accurate manner. Improving the automation of remote sensing image processing can not only save a lot of human resources but also effectively improve the processing speed of remote sensing images on the premise of ensuring the accuracy of interpretation, thereby improving the utilization of remote sensing images.
In the early years, researchers mostly used conventional machine learning methods to process remote sensing images. Bags of visual words (BoVW) [1] divided the image into finer and finer sub-regions, extracted independent feature words according to the low-level features of the scene, and then used clustering algorithms such as K-means algorithm to combine words with similar meanings in the visual words form a word list. However, it was based on hand-extracted features, which was difficult and time-consuming. Other traditional machine learning methods such as Support Vector Machines (SVM) [2], Decision Trees [3] and Bayesian classification networks [4] were also often used, but the classification accuracy of remote sensing images was not high.
With the rise of deep learning, more and more researchers are adopting deep learning related methods to solve image processing problems. Lin et al. [5] proposed a multiple-layer feature-matching generative adversarial network (MARTA GAN), they generated remote sensing images by adding two deconvolution layers in the generator, meanwhile, in order to adapt to the complex characteristics of remote sensing data, they employed a fusion layer to combine mid-level and global features. Bazi et al. [6] presented a Vision Transformers based method for remote sensing scene classification, which uses the attention mechanism as the main building block to derive long-term contextual relationships between pixels in an image, and in order to preserve information about locations, they added embed positions to these patches. Liang et al. [7] developed a remote sensing image classification method based on overlay denoising automatic encoder. Firstly, the depth network model is established through the overlay denoising automatic encoder, in the case of noise input, each layer is trained successively by an unsupervised greedy hierarchical training algorithm to obtain a more robust expression. Niu et al. [8] used DeepLab to mine the spatial features of hyperspectral images, they fused the spatial spectral features in a weighted manner, and input the fused features into SVM for final classification.
In recent years, convolutional neural networks (CNN) have made great strides in solving image processing problems and have won the favor of many researchers. The CNN is a feedforward neural network consisting of a stack of self-learning convolutional filters that extract hierarchical contextual image features. The convolutional neural network has the characteristics of local receptive field and weight sharing, which can effectively reduce the number of training parameters, and the pooling layer can gather features from different locations, which can reduce the dimension and avoid overfitting. Compared with traditional statistical methods, convolutional neural networks do not need to make assumptions about probabilistic models, have a stronger ability to extract features, have stronger learning ability and fault tolerance, and are more suitable for solving various problems of pattern recognition.
One of the advantages of convolutional neural network over traditional image processing algorithms is that it avoids complex pre-processing of images, especially manual participation in image pre-processing. Convolutional neural networks can directly input original images to perform a series of tasks. Therefore, convolutional neural networks are widely used because they can automatically discover relevant contextual features in image classification problems. They have excellent performance in large-scale image processing and have been widely used in image classification, localization and other fields.
Luo et al. [9] designed a convolutional neural network framework suitable for hyperspectral remote sensing images, called HSI-CNN, which combines with the popular machine learning model XGBoost as a classifier, then the application of hyperspectral data in capsules neural network is proposed and realized. Xu et al. [10] proposed a two-channel convolutional neural network. The input remote sensing images enter the spectral channel and the spatial channel respectively, and use the two-dimensional convolution and one-dimensional convolution to extract the spatial and spectral information respectively, and a cascaded block is exploited to extract different levels of features. Liu et al. [11] improved the IICL-CNN model on the basis of the Inception V3 model [12], adding a new constraint to the original Softmax cross-entropy function of CNN to increase the learned from occluded samples and clear samples. The similarity between features and a central loss function is added to the objective function, which further improves the recognition ability of the learned features, thereby improving the accuracy of fuzzy samples.
Nowadays, in order to pursue higher network performance when constructing convolutional neural network, researchers usually deepen the operation of the number of layers of the network to make the convolutional neural network have better classification accuracy. However, at the same time, the volume and structure of CNN are becoming larger and more complex, and the hardware resources required for training and prediction are also gradually increasing. These disadvantages make large CNN often run only in servers with high computing power. Therefore, due to the limitations of hardware resources, computing power and storage, it is difficult for mobile embedded devices to run complex deep learning network models, so the focus of scholars has gradually changed from continuously improving the depth of the network to meet the classification accuracy. On the basis of meeting certain accuracy requirements, the network model is simplified so that it can be operated in real time, so the lightweight convolutional neural network was born. At present, lightweight networks have begun to be used in areas such as unmanned mobile terminals, edge computing of the Internet of Things, and artificial intelligence algorithm deployment.
In this paper, a new convolutional neural network based on ShuffleNet V2 model is proposed to classify remote sensing images intelligently, which is a lightweight network that can effectively reduce the memory usage of the network and has better accuracy. Our main improvements and innovations are summarized as follows,
We replace some of the convolution kernels in the ShuffleNet V2 model with larger size convolution kernels, which will not increase the computational cost but improve the classification effect. We combine the backbone network with a Squeeze-Excitation module considered as a channel attention mechanism, which can effectively improve the network performance. We remove the padding operation of the max-pooling layer to enforce the size of stride smaller than the size of the pooling kernel, making it a maximum overlapping pooling operation, which improves the detailed features and classification accuracy of the input image.
Comparative experiments on remote sensing image classification show that the improved model can significantly improve the accuracy. More importantly, our algorithm is able to meet the requirements of real-time applications.
The rest of the paper is organized as follows. Section 2 mainly introduces the basic architecture of the convolutional neural network and the principles and advantages of the reference model in this paper. Section 3 presents the CNN model proposed in this paper and describes its advantages over other networks, then introduces the network structure and training process. Section 4 mainly reports the experimental results and analysis, and conducts comparative experiments to document the efficacy of the network. Finally, Section 5 summarizes the whole paper.
Related work
The model of the convolutional neural network can be traced back to the LeNet model proposed by LeCun et al. in 1988 [13], which uses a gradient-based back propagation algorithm to supervised train the network, gradually converting the original image into a series of feature maps through alternating connected convolution layer and downsampling layer, and passing these features to a fully connected neural network to classify images based on features of the image. In 2012, the AlexNet model [14] proposed by Krizhevsky et al. came out, which establishes the status of convolutional neural networks in deep learning applications. AlexNet won the image classification championship in the training set of ImageNet, which makes the convolutional neural network become the key research object in computer vision and continues to deepen. Since then, a large number of excellent convolutional neural network models have emerged and made a big splash in the field of computer vision. Later, researchers made improvements on the AlexNet model, such as the representative ZFNet model of the 2013 ILSVRC challenge champion [15], the VGGNet model of Oxford University that is still widely used [16] and Google’s GoogLeNet model [17] and Microsoft’s ResNet model [18] for solving the degradation problem of deep networks using residual learning. The proposal of these networks has led to the gradual start of commercial applications of convolutional neural networks, almost as long as there is an image, there will be a convolutional neural network.
In this paper, we try to build a deep convolutional neural network model, which consists of convolutional layer, ReLU activation function, Batch Normalization (BN), ShuffleNet V2 module, SE module, max pooling layer, dropout layer, fully connected layer and the classifier function.
AlexNet
The convolutional layer is the core of the convolutional neural network. Convolution means moving the convolution kernel on the image by the stride size and doing dot products with the same area of the image at different positions. It can be written as,
where
The ReLU activation function layer is used to add nonlinear factors, which can enhance the learning ability of the model and tackle the problem of gradient disappearance. It can be written as,
The pooling layer can compress the input feature map. On the one hand, it makes the feature map smaller and simplifies the computational complexity of the network; on the other hand, it performs feature compression and extracts the main features. The pooling layer is often behind the convolutional layer, and pooling is used to reduce the feature vector output of the convolution layer, which can speed up the computation as well as prevent overfitting and improve the fault tolerance of the model. There are mainly maximum pooling and average pooling, which calculate the maximum and average values of data in a specified region, respectively.
The Dropout layer is the process of randomly resetting the parameters of the hidden layer to zero. It is mainly used in the fully connected layer, which can effectively prevent the problem of overfitting.
The fully connected layer is the processing of matrix-vector product. The parameter matrix vector
Softmax layer is widely used in multi-classification scenarios, it can be written as,
where
The BN layer can not only accelerate the convergence speed of the model, but more importantly, it can alleviate the problem of “gradient dispersion” in the deep network to a certain extent, thus making the training of the deep network model easier and more stable [19]. The specific standardization operation of BN is to transform the input data of each layer into a normal distribution with a mean of 0 and a variance of 1 to obtain a standardized result. It can be written as,
where
To meet the growing demand for running efficient deep neural networks on embedded devices while maintaining accuracy, Zhang et al. [20] designed the ShuffleNet V1 model, which greatly reduces the computational cost while achieving a lower top-1 error rate in the ImageNet classification task compared to the MobileNet proposed by Howard et al. [21]. After that, mobilenet V2 model [22] and mobilenet V3 model [23] were born. Ma et al. [24] proposed the “Lightweight Network Design Principle”, and used it as the basis for a series of improvements to the ShuffleNet V1 model, and finally designed the ShuffleNet V2 model. The ShuffleNet V1 module structure and the ShuffleNet V2 module structure are depicted in Fig. 1.
ShuffleNet V1 block and ShuffleNet V2 block.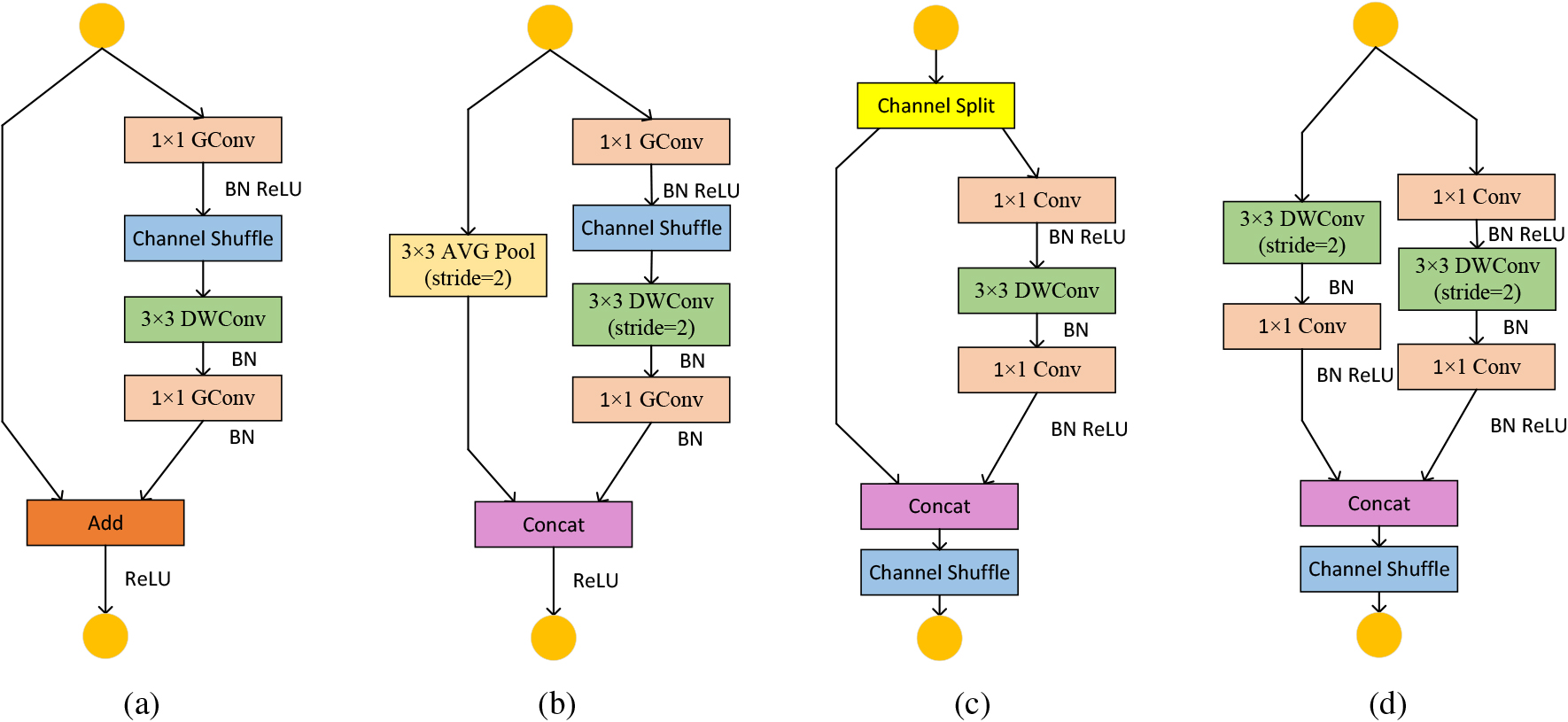
(a) and (b) in Fig. 1 are “ShuffleNet unit with pointwise group convention and channel shuffle” and “ShuffleNet unit with stride
(c) and (d) in Fig. 1 are “ShuffleNet V2 unit” and “ShuffleNet V2 unit for spatial down sampling”. When the stride is 1, ShuffleNet V2 unit is used, mainly to deepen the network layers; When the stride is 2, ShuffleNet V2 unit for spatial down sampling is used to compress the width and height of the feature layer for down sampling. Since too many groups increase the memory access cost (MAC), reduce the channel parallelism, and “add” operations with channel concatenation are undesirable, channel splitting is proposed instead of group operation. In order to meet the requirement of equal channel width and reduce the MAC, a convolution kernel of size 1
Recently, attention mechanisms have been prevalent in a range of studies including the field of natural language processing, which can reasonably allocate available processing resources to informative feature representations while suppressing less useful feature representations. In order to improve the performance of the existing state-of-the-art models at a small computational cost, Hu et al. [25] proposed the SENet model, which proceeds to optimize the channel dimension by introducing an attention mechanism with a small number of parameters so that the model can better acquire features on different channels and thus improve the accuracy. In SENet, each SEblock contains two operations: squeeze and extraction. The squeeze operation scales each pixel value in the feature map to the same scale and converts it into a one-dimensional vector. This vector is called the “receptive field” and represents the importance of each pixel in the feature map. Next, the extraction operation calculates the weight of each pixel based on the receptive field, which is used to weigh and sum the feature map to generate a new feature map. This new feature map is used in the next convolutional layer or fully connected layer. Due to the flexibility of the SE module, it can be directly applied to the existing network architecture whose structure is shown in Fig. 2.
Squeeze-and-excitation block.
An improved convolutional neural network based on ShuffleNet V2 model is designed, which can be applied to the classification of remote sensing images. Section 3.1 introduces the advantages of the model proposed in this paper compared to other networks and the main improvement methods; Section 3.2 describes the network structure of Improved ShuffleNet V2 in detail; Section 3.3 elaborates on the training details such as data preprocessing of the network.
Main improvement methods and advantages
In previous work, the research trend of most scholars was to build deeper and larger convolutional neural networks to solve visual recognition tasks, and the most powerful CNNs nowadays usually have hundreds of layers and thousands of channels, and the number of floating-point operations even reaches billions of times. Although the accuracy of large CNNs is high, they ignore practicality, and they have the disadvantages of taking up large storage space and long computation time. In recent years, the emergence of lightweight convolutional neural networks represented by ShuffleNet and MobileNet has made it possible to run on mobile platforms such as robots, drones and even smartphones. Although they occupy little storage space and have fast computation speed, the classification accuracy will be lower than that of large networks.
The convolutional neural network proposed in this paper is improved on the basis of the ShuffleNet V2 model. In order to be close to the classification accuracy of large convolutional neural networks while ensuring less memory usage, this paper employs the lightweight network ShuffleNet as the backbone network, and appropriately increases the size of the convolution kernel, especially the convolution kernel in the ShuffleNet V2 module. In this way, the model can perform more convolution operations to better extract the feature information of the input image, because large-sized convolutional kernels can capture more local features, better representing the features in the image, which can improve the accuracy and generalization ability of the model, and these additional computational costs are negligible compared to large networks. In the end, we can get a convolutional neural network model that has better classification performance compared to lightweight networks, while occupying much less memory than large networks.
We also introduce an attention mechanism module into the network, which can solve the loss problem caused by the different importance of different channels of the feature map in the process of convolution pooling. SEblock improves the model’s feature acquisition ability and classification accuracy by using squeezes and exceptions. Firstly, the squeeze operation can help the network better focus on important features, thereby improving the representation ability of features. Secondly, the extraction operation can weigh and sum the feature map based on the importance of each pixel in the feature map, thereby improving the representation ability of the feature map. The combination of these two operations enables the model to better extract and represent image features, thereby improving the accuracy of the classification model.
In the traditional convolutional neural network structure, the pooling layer generally adopts average pooling or maximum pooling, and the pooling operation mainly refers to using a fixed-size sampling window in the pooling layer to pool all the fixed-size regions in the convolutional layer and output the corresponding feature maps. In this paper, the filling operation of the maximum pooling layer in ShuffleNet V2 network is removed, so that the size of the pooling kernel is larger than the step size value, and therefore the outputs of the pooling layers overlap and cover each other to form the maximum overlapping pooling layer, thus enhancing the detail features and classification accuracy of the input image. Remote sensing images are usually affected by various types of noise interference, such as cloud cover, atmospheric light, etc. The maximum overlap pooling layer can select the most significant feature information in the image, which is not affected by noise interference and has better noise resistance. In addition, the maximum overlap pooling layer performs spatial overlap sampling on the image when extracting features, which means that the position of the feature extraction has a strong tolerance for small offsets in the surrounding area. This helps to improve the robustness of the CNN network to spatial changes and maintain the recognition of the target not affected by slight positional changes.
Improved ShuffleNet V2 architectures
Based on the ShuffleNet V2 unit, we show the overall model structure in Table 1. Taking “Improved ShuffleNet V2 1
Overall architecture of Improved ShuffleNet V2 for four different levels of complexity
Overall architecture of Improved ShuffleNet V2 for four different levels of complexity
Improved ShuffleNet V2 block.
This study uses Faceboook’s Pytorch deep learning framework. Pytorch is a very simple, efficient and fast framework, that supports multiple GPUs and distributed operations, and has the advantages of an open source code and an active community. These advantages provide favorable accuracy and scalability for the experiments in this study.
This method was applied to actual remote sensing image classification to validate the proposed method effectively, and simulation experiments were conducted. We used an Intel Core i7 Quad-Core processor with 16 GB memory. We selected the 64-bit Windows 10 operating system, Pytorch deep learning framework, and Python 3.8 as the development environment.
The main dataset we use is the NWPU-RESISC45 Dataset created by Northwestern Polytechnical University [26], which is applied to remote sensing image scene classification. The dataset contains a total of 31,500 images with a pixel size of 256
We also used the UC Merced Land-Use Dataset, which was released by the UC Merced Computer Vision Laboratory in 2010 [27]. It is a remote sensing dataset used to study land use images and is used in urban areas around the world. The public domain image of this dataset has a pixel resolution of 1 foot and an image pixel size of 256
Then we used the SIRI-WHU Dataset [28], which includes two data subsets: Google image and USGS image. The SIRI-WHU Dataset consists of 12 scene categories, mainly used for scientific research purposes. Each category contains 200 images, each with a size of 200*200 and a spatial resolution of 2 meters. The dataset was obtained from Google Earth and mainly covers urban areas in China.
Finally, we used the AID Dataset, which is a large remote sensing image dataset for aerial scene classification released by Huazhong University of Science and Technology and Wuhan University in 2017 [29]. It contains 30 categories of scene images, of which there are about 220–420 images in each category, with a total of 10000 images, of which the pixel size of each image is about 600
In the experiment, the input remote sensing dataset was randomly divided into two groups: the training set and the test set, with segmentation percentages of 80% and 20%, respectively. The test set was used for predicting and evaluating the model. In addition, to reduce computational complexity, we normalize the input data and then scale the input image to a resolution of 256
Experimental results and analysis
First, in order to verify the effectiveness of lightweight networks for remote sensing image classification, we conduct experiments on several convolutional neural networks in Section 4.1 and evaluate the results. Furthermore, in order to choose an appropriate complexity for our improved architecture, the classification accuracy of the Improved ShuffleNet V2 model under three different complexities is compared in Section 4.2. Finally, in Section 4.3, we compare the classification performance of the proposed network with several popular convolutional neural networks to demonstrate the efficacy of the experiments.
CNN-based model evaluation results
To evaluate the classification performance of the lightweight network, we selected the large-scale convolutional neural network GoogLeNet and several popular lightweight convolutional neural networks MobileNet V3, ShuffleNet V1 and ShuffleNet V2 for experiments. As shown in the results in Table 2, the number of parameters and floating-point operations (FLOPs) of GoogLeNet far exceed those of the other three lightweight networks. For classification accuracy, GoogLeNet has demonstrated superior performance on all datasets and is an excellent algorithm. However, due to its high memory usage and slow computation speed, it cannot meet the real-time and low-power requirements of some tasks. For the two ShuffleNet series models, although their classification accuracy on the three datasets is slightly lower than that of GoogLeNet, their number of parameters and computational complexity is relatively small, making them more adaptable and flexible, and finally, the performance of MobileNet V3 is slightly worse than that of ShuffleNet, which is the reason that it is not selected as the backbone network.
Results of selected models
Results of selected models
In order to further reduce the computational complexity and the number of parameters of the model, we refer to the architecture used in MobileNet and set a Width Multiplier for the model, so that the number of convolution kernels of each layer can be proportionally scaled to obtain different sizes of convolution kernels. Improved ShuffleNet V2 model. We scale the width of the network to three different complexities: 0.5
Accuracy comparison of three different complexity classifications using Improved ShuffleNet V2
Accuracy comparison of three different complexity classifications using Improved ShuffleNet V2
In order to assess the applicability of the Improved ShuffleNet V2 model to remote sensing image datasets, we compare the classification performance of three different complexities of the Improved ShuffleNet V2 with the large convolutional neural network GoogLeNet and several lightweight networks. The experimental results are recorded in Table 4. It is evident from these experiments that the classification accuracy obtained by using Improved ShuffleNet V2 1.5
Performance of selected models
Performance of selected models
For the four remote sensing image datasets we selected, through experiments, we found that if the data set is too small, the model will not have enough sample generalization to distinguish features, which will make the data over-fitting, resulting in low training error but high test error. This also explains why the classification performance of the model on the UC Merced Land-Use Dataset and SIRI-WHU Dataset is slightly worse than that of the other two slightly larger datasets.
We also tried to split the large convolution kernel in Improved ShuffleNet V2 into several small convolution kernels to increase the depth of the network, but the classification accuracy obtained in the experiment degraded, and the number of parameters and computational cost also increased. We think this is because the convolutional neural network with too many parameters and too complex network structure consumes a lot of computing resources during training, requires a lot of time overhead during network testing, and even sacrifices accuracy. Therefore, when designing the network structure, we need to strike a balance between accuracy, time and CNN architecture.
The variation of the training loss with the increase in the number of epoches is exhibited in Fig. 4a when two kinds of CNN are applied to the NWPU-RESISC45 dataset. Figure 4b shows the confusion matrix of Improved ShuffleNet V2 classification that used NWPU-RESISC45 dataset. Figure 4a shows that after 80 epoches in the NWPU-RESISC45 dataset, the training loss in the training process will stabilize. Compared with the traditional ShuffleNet V2 model, the improved ShuffleNet V2 model has lower training loss, can obtain better training effects, and fully learns the characteristics of the images.
(a) Training loss of ShuffleNet V2 model and Improved ShuffleNet V2 model iteration on the NWPU-RESISC45 dataset. (b) The confusion matrix was classified using the Improved ShuffleNet V2 on the NWPU-RESISC45 dataset.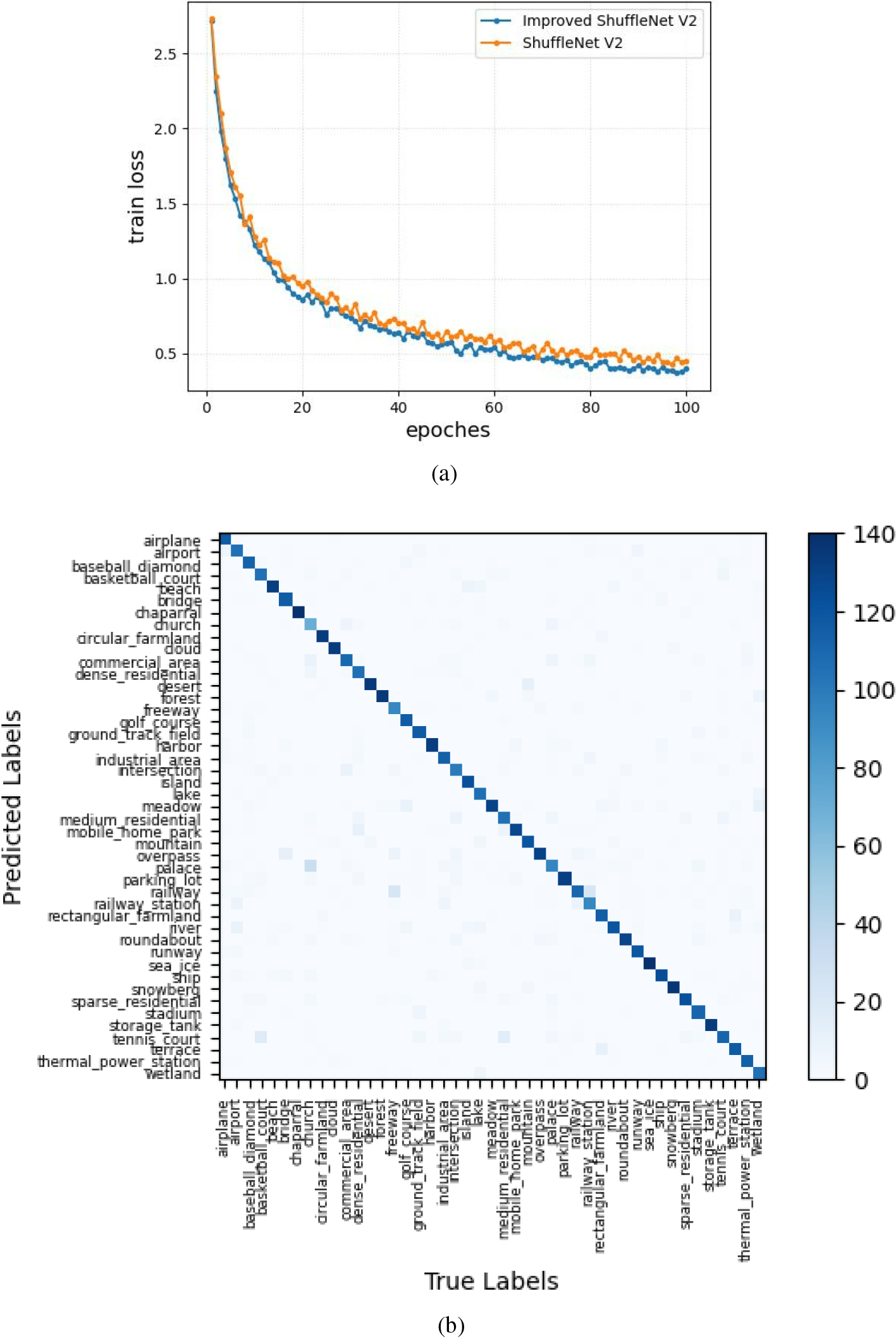
(a) Training loss of ShuffleNet V2 model and Improved ShuffleNet V2 model iteration on the AID dataset. (b) The confusion matrix was classified using the Improved ShuffleNet V2 on the AID dataset.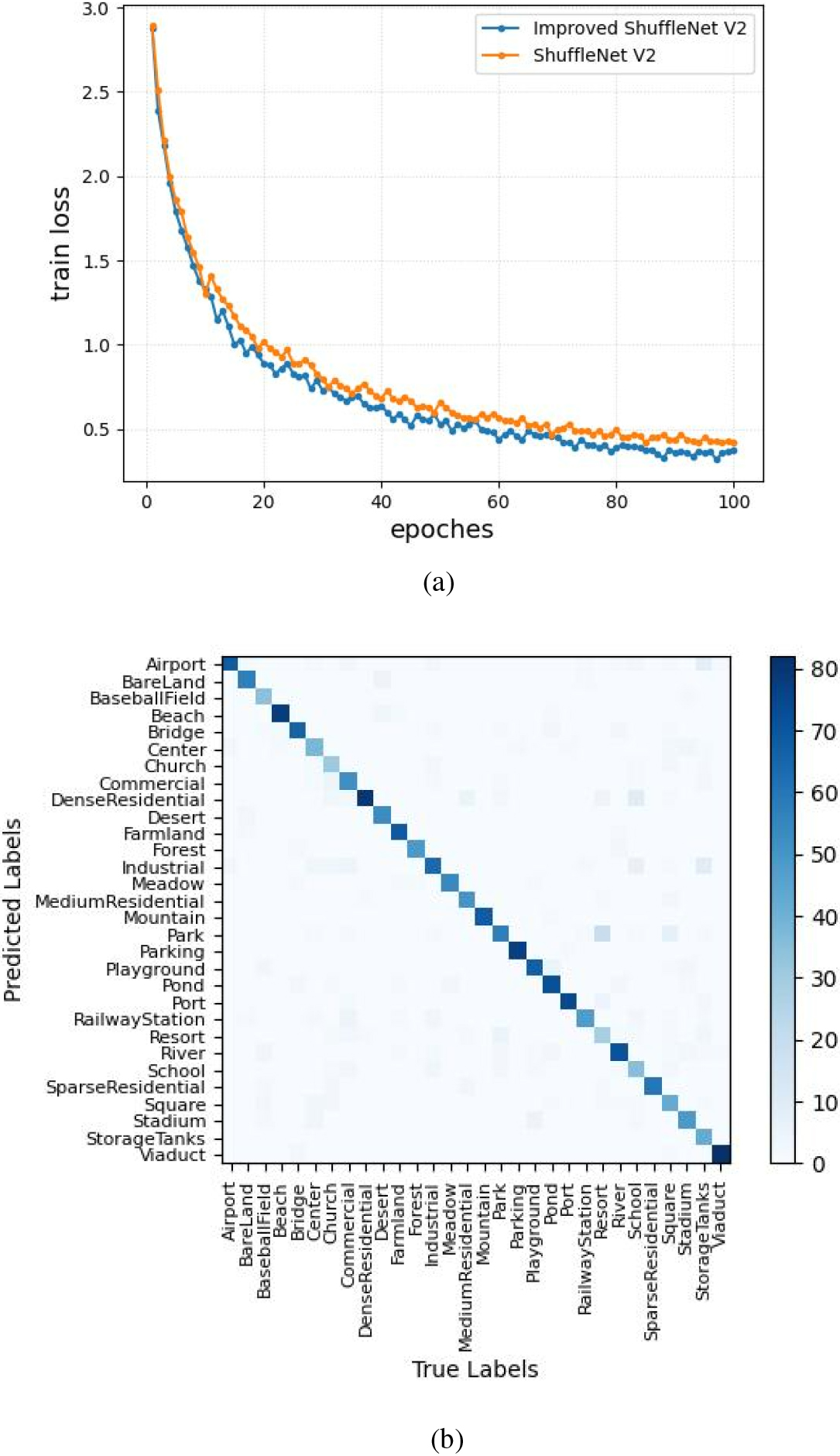
(a) Training loss of ShuffleNet V2 model and Improved ShuffleNet V2 model iteration on the UC Merced Land-Use dataset. (b) The confusion matrix was classified using the Improved ShuffleNet V2 on the UC Merced Land-Use dataset.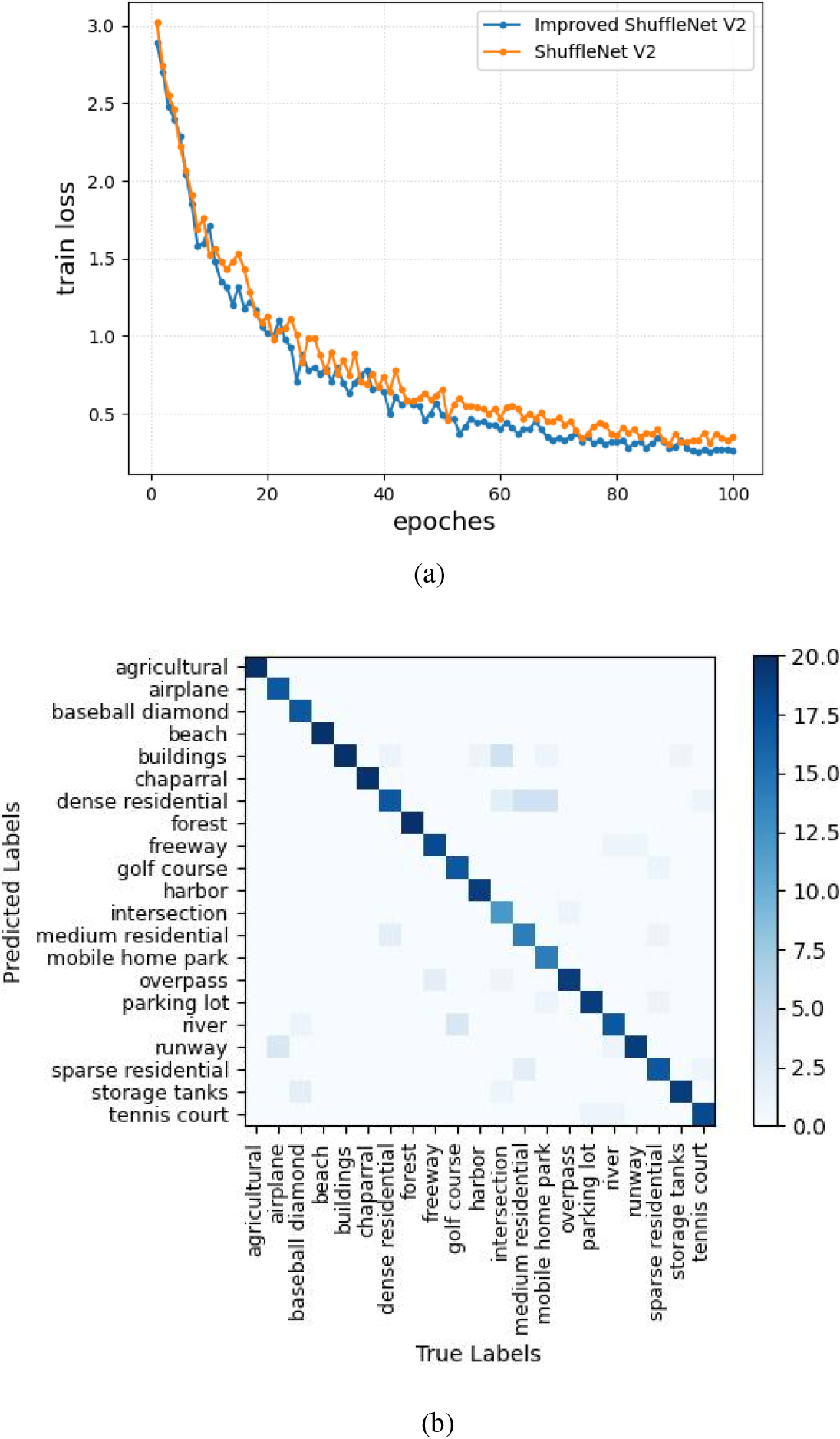
The variation of the training loss with the increase in the number of epoches is exhibited in Fig. 5a when two kinds of CNN are applied to the AID dataset. Figure 5b shows the confusion matrix of Improved ShuffleNet V2 classification that used AID dataset. Obviously, in the training process, the Improved ShuffleNet V2 model converges faster than the ShuffleNet V2 model, and the Improved ShuffleNet V2 model may converge to the final training loss of the ShuffleNet V2 model at about the 70th iteration. Figure 5b shows that we also have confusion between park and resort. However, these are natural mistakes that human experts could easily repeat, they look very similar in aerial images.
The variation of the training loss with the increase in the number of epoches is exhibited in Fig. 6a when two kinds of CNN are applied to the UC Merced Land-Use dataset. Figure 6b shows the confusion matrix of Improved ShuffleNet V2 classification that used UC Merced Land-Use dataset. Figure 6a shows that the Improved ShuffleNet V2 model is superior to the ShuffleNet V2 model in training loss, with faster convergence speed and higher accuracy.
In addition, we also explored the classification performance of different quantity training samples. Figure 7 shows the Improved ShuffleNet V2 and ShuffleNet V2 in training samples from 20% to 100% of the percentage of performance, 100% represents 80% data of the total data set as experimental training samples, and the rest as test samples, the dataset we use is NWPU-RESISC45 Dataset. As shown in Fig. 7, when the percentage is small to 20%, the proposed framework is still better than ShuffleNet V2, the performance gain is obvious and the effectiveness of the framework has been verified.
We selected Improved ShuffleNet V2 1.5
Statistical significance test result
*Indicates that the difference between the two methods is statistically significant when
Classification performance of methods with different percents of full training set.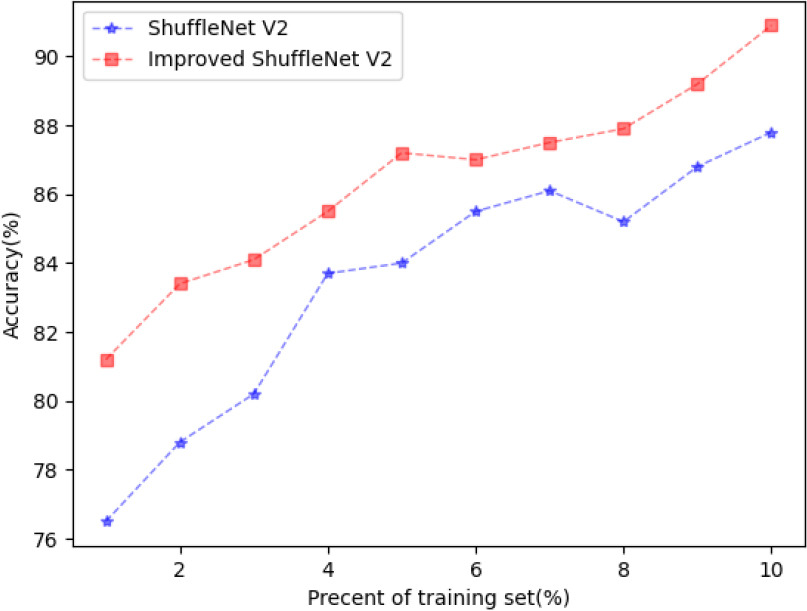
In recent years, the use of mobile devices to solve computer vision tasks has been a development trend in various fields. The traditional convolutional neural network cannot fulfill this need due to its own limitation of occupying too much memory, thus the lightweight network has become a rising star and has been widely used. This paper proposes an improved network based on the ShuffleNet V2 model. Several state-of-the-art convolutional neural network models are tested in our experiments. The experiments show that when balancing accuracy and complexity, the lightweight network ShuffleNet is more suitable for processing remote sensing imagery on mobile devices. Therefore, we employ ShuffleNet as the backbone network, and the results show that the Improved ShuffleNet V2 proposed in this paper has better image processing ability and classification accuracy. The future work of this research will involve integrating the proposed algorithm with the Internet of Things platform to make the automation process more efficient.
Footnotes
Acknowledgments
We would like to thank the anonymous reviewers for their valuable comments. The research was funded by the National Key Research and Development Program of China (2021YFE0116900), the National Natural Science Foundation of China (42175157), the General Project of Natural Science Research of Jiangsu Higher Education Institutions (22KJB520037, 23KJB520036), the ”Taihu Light” Science and Technology Project of Wuxi (K20231003, K20231010) and the Wuxi University Research Start-up Fund for Introduced Talents (2021r032).