
Abstract
In this paper, the mathematical model of Vehicle Routing Problem with Time Windows (VRPTW) is established based on the directed graph, and a 3-stage multi-modal multi-objective differential evolution algorithm (3S-MMDEA) is proposed. In the first stage, in order to expand the range of individuals to be selected, a generalized opposition-based learning (GOBL) strategy is used to generate a reverse population. In the second stage, a search strategy of reachable distribution area is proposed, which divides the population with the selected individual as the center point to improve the convergence of the solution set. In the third stage, an improved individual variation strategy is proposed to legalize the mutant individuals, so that the individual after variation still falls within the range of the population, further improving the diversity of individuals to ensure the diversity of the solution set. Based on the synergy of the above three stages of strategies, the diversity of individuals is ensured, so as to improve the diversity of solution sets, and multiple equivalent optimal paths are obtained to meet the planning needs of different decision-makers. Finally, the performance of the proposed method is evaluated on the standard benchmark datasets of the problem. The experimental results show that the proposed 3S-MMDEA can improve the efficiency of logistics distribution and obtain multiple equivalent optimal paths. The method achieves good performance, superior to the most advanced VRPTW solution methods, and has great potential in practical projects.
Keywords
Introduction
With the development of online shopping, logistics distribution, as a key component of online shopping, has received more and more attention. The efficiency of distribution affects customers’ satisfaction directly. Vehicle routing problem (VRP) and its variants [1, 2] have been widely popularized because they can simulate practical applications in various fields. One of the classic variants is VRPTW. The goal of VRP is to design a set of optimal distribution routes for vehicles of a certain size, so as to provide services for customers in logistics distribution. It represents the essence of vehicle allocation and path planning under the lowest cost in logistics distribution. Therefore, it is a key problem in logistics distribution and one of the most widely studied problems in the field of combinatorial optimization. In VRPTW, each customer is associated with a time window, which limits the idle time interval for obtaining services.
Based on the constraints and problem structure of VRPTW, the improvement of one goal may lead to the deterioration of other goals. VRPTW is a combination optimization problem with multiple constraints and multi-objective decisions, and the importance of its objective function varies from field to field. For example, for the food distribution and medical industries, delay time is critical. The freight transport industry can consider the total journey as the key objective to minimize compared with other objectives, because the fuel consumption is proportional to the driving distance. Therefore, from an economic point of view, it is important to minimize the total distance traveled by all vehicles. For small industries, the minimization of the number of vehicles may be the highest priority compared to other goals. When planning the vehicle path, the traditional solution attempts to find a single optimal path without considering the diversity of the path. However, the decision-maker hopes to obtain multiple solutions (i.e. multiple equivalent optimal paths) that meet the target requirements at the same time. On the one hand, decision-makers can better understand the problems to be optimized. On the other hand, if a specific solution becomes infeasible due to changes in the environment, the decision-maker can easily change to another equivalent solution to ensure the stability of the decision, that is, at least two equivalent global Pareto optimal solutions correspond to the same point on the Pareto Front (PF) [3, 4]. Therefore, for some problems, it is important to obtain all equivalent Pareto Sets (PS). When solving VRPTW, a multi-objective optimization problem, there may be two or more global or local PSs, some of which may correspond to the same PF. If the decision-maker hopes to get multiple solutions under the constraint conditions, VRPTW can be regarded as a multi-modal multi-objective optimization problem (MMOP), that is, multi-modal multi-objective VRPTW (MMVRPTW).
Figure 1 shows a simple multi-mode multi-objective vehicle path planning scheme [5, 6], which includes cost and time objectives. In Fig. 1, the triangle and circle in the left path diagram represent different forms of transfer stations, and the dotted line in the right figure represents the PF of the problem. Route 1 and Route 4, Route 2 and Route 3 have the same time and cost respectively. Obviously, for passengers who need to complete the trip in a shorter time, there are two options: Route 2 and Route 3, and for passengers who need to complete the trip at less cost, there are also two options: Route 1 and Route 4. When the transit station of a route scheme is affected by weather and other factors, passengers can choose alternative schemes. If the final result can only provide one PS for each passenger, it can not meet the needs of different passengers. There are at least four equivalent Pareto optimal solution sets for the problem: {Route 1, Route 2} {Route 1, Route 3} {Route 4, Route 2} {Route 4, Route 3}. In this problem, a set of Pareto optimal solution sets can not well meet the needs of decision makers. Therefore, it is of great practical significance to study how to obtain more PSs at the same time, so as to provide more choices for decision makers.
MMOP in path planning.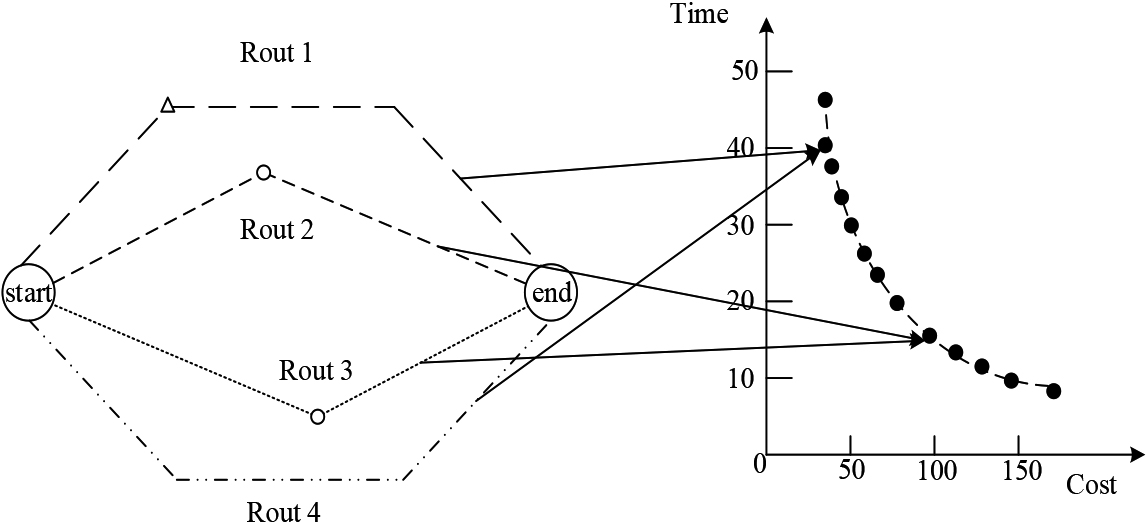
Since Solomon et al. [7] first proposed the VRPTW and gave a classical example of this kind of problem, VRPTW has become a research hotspot, which is considered as a typical variant of VRP. In recent years, researchers have proposed a large number of multi-objective optimization algorithms to solve VRPTW and its related variants. However, due to the complexity of problem modeling, the difficulty of solving, and the multi-modality of the problem, the research results are relatively few. Xu et al. [8] proposed hybrid genetic algorithm and particle swarm optimization algorithm for vehicle routing problem with time window, and used particle real number coding method to decode the path, thus reducing the computational burden. At the same time, it is combined with the crossover operator of genetic algorithm to avoid falling into local optimum. Jakub Nalepa et al. [9] solved the VRPTW by using the adaptive parameter modulus algorithm. Jose et al. [10] solved the heterogeneous vehicle routing problem with time windows (HVRPTW) using the ACS based memetic algorithm. Wang et al. [11] proposed a multi-objective multi station vehicle routing problem with time windows, and developed a two-stage multi-objective evolutionary algorithm (TS-MOEA) to solve the problem. Lu et al. [12] considered the VRP with multiple stops and multiple trips with time windows and delivery times, established a mixed integer programming model, and proposed a hybrid particle swarm optimization algorithm and a hybrid genetic algorithm to solve the model. Cueto et al. [13]combined the branch cutting algorithm with the heuristic algorithm to solve VRPTW with multiple parking lots and multiple trips. Cheng et al. [14] proposed a solution framework that combines a multi task optimization framework with multi-objective evolutionary algorithms for solving multi-objective VRPTW. Shu et al. [15] presented a two-stage multi-objective evolutionary algorithm based on classified population (TSCEA) to solve a three-objective VRPTW. In the first stage, a population is explored using the proposed algorithm and then classified according to the number of vehicles, we call this process population classification; In the second stage, Pareto solution set of tri-objective VRPTW is obtained by optimizing the classified population again. Hou et al. [16] proposed a multi-objective differential evolution algorithm for solution evaluation (differential mutation strategy based on feasible solutions) for multi-objective VRPTW. Cai et al. [17] proposed a hybrid evolutionary multitask algorithm, termed HEMT, to address MOVRPTWs under the framework of evolutionary multitasking, where multiple MOVRPTWs are optimized simultaneously by leveraging the similarity between them. Srivastava et al. [18] proposed two evolutionary approaches, viz., a steady-state grouping genetic algorithm and a discrete differential evolution algorithm, to solve a three-objective VRPTW. According to the analysis of previous studies, although some research achievements have been made on VRPTW, there are still some problems: (1) The solution objective is single. At present, the research on VRPTW mainly solves the objective from a certain angle, such as the minimum total cost, the minimum travel time, the minimum average waiting time of customers, and the minimum travel time. (2) The final solution is single. At present, the research on VRPTW optimizes multiple objectives in the form of a single objective, so only one final solution can be returned to the decision-makers.
The research on the methods of solving the optimal vehicle routing is endless. Most methods need to establish mathematical models and complete the optimization of vehicle routing by defining different types of variables, constraint functions and objective functions. Common methods mainly include precise search algorithm and heuristic search algorithm [19, 20, 21, 22, 23]. Among them, the precise search algorithm is to establish a corresponding mathematical model for a specific problem, and then use mathematical methods to solve it. It must be able to find the optimal solution of the problem, mainly focusing on branch and bound method [24], branch and cut method [25], etc. Since VRPTW is a NP hard problem, strict mathematical methods must be introduced when using accurate algorithms to solve it. Therefore, too much computing power and storage space will be consumed during calculation, which will limit the accuracy of the optimal vehicle path. This method can only be applied to small-scale VRPTW solutions. With the gradual increase of the problem scale, some scholars propose to use heuristic search algorithm to solve the vehicle routing problem. The heuristic algorithm is proposed based on the optimization algorithm, and its basic idea is to give a feasible solution of the combination optimization problem to be solved within an acceptable range. The heuristic search algorithms mainly used in VRPTW include ant colony algorithm [10], genetic algorithm [12], etc. Compared with the precise search algorithm, the heuristic search algorithm has better robustness and feasibility when dealing with large-scale VPRTW. Based on the existing research, it can be seen that precise search algorithm and intelligent heuristic search algorithm can be used to solve VRPTW and related problems. The exact algorithm can find the optimal solution of the problem, but it is highly dependent on the solution space, the number of constraints and the number of decision variables in the problem model, and cannot provide a general solution strategy for different types of variables, goals and constraints. By designing a heuristic function, the heuristic algorithm can obtain the optimal solution of the search problem in a very short time. The heuristic algorithm can further improve the accuracy of vehicle routing.
In the vehicle path planning problem, the decision-makers hope to get multiple paths with the same target value. In addition, some decision-makers can accept other paths that are slightly worse than the best solution when possible. Therefore, it is of great significance to improve the diversity of solutions obtained. In order to solve this problem, this paper first explains the importance of solving VRPTW using multi-modal multi-objective algorithm. Then, a 3-stage multi-modal multi-objective differential evolution algorithm (3S-MMDEA) is proposed to maintain the diversity of solutions in the decision space. Finally, the effectiveness of the algorithm is verified by experiments. The main contributions of this paper are as follows:
In order to improve the efficiency of logistics distribution and customer satisfaction, and meet the planning needs of different decision-makers for different vehicle routes, a multi-modal multi-objective vehicle routing problem model with time window constraints, namely MMVRPTW, is established. Aiming at MMVRPTW, a 3S-MMDEA is proposed to solve the problem. In the first stage strategy, the GOBL strategy is used to generate a reverse population, expand the search scope of subsequent individuals, and improve the diversity of individuals. In the second stage, a search strategy of reachable distribution area is proposed to divide the population to reduce the scale of logistics distribution and improve the efficiency of logistics distribution. In the third stage strategy, an improved individual variation strategy is proposed to make individuals fall within the range of the population after mutation, further improving the diversity of individuals, so as to ensure the diversity of the solution set. Based on the above strategies, the vehicle paths are optimized through forward output and feedback, and the optimization of MMVRPTW is completed cooperatively.
Relevant theories
The multi-objective optimization problem (MOP) is defined as follows [26]:
Where,
The problem has at least one local Pareto optimal solution set. The problem has at least two equivalent global Pareto optimal solutions, which correspond to the same point on PF.
The objective function values corresponding to the Pareto optimal solutions For the problem of two objectives, the Pareto optimal frontier is usually a line. For multiple targets, the Pareto optimal frontier is usually a hyper-surface. The local Pareto optimal solution refers to the solution that is not dominated by any neighborhood solution, and the global Pareto optimal solution refers to the solution that is not dominated by any solution in the feasible region.
MMOP is a special kind of MOP, which is mainly manifested in two cases: (1) each solution in the decision space has multiple equivalent solutions. (2) There are several equivalent solutions in the middle decomposition of decision space.
The goal of MMOP is not only to obtain the PF approximation with good approximation and diversity in the objective space, but also to obtain enough equivalent solutions in the decision space. In order to improve the search ability of the algorithm and ensure the diversity of decision space and objective space at the same time, researchers have proposed different solutions, mainly including methods to improve the diversity of decision space and methods to improve the search ability [30, 31, 32, 33, 34, 35].
In the process of solving MMOP, designers need to pay more attention to the performance in the decision space, that is, they hope to find the equivalent PS of multiple groups of uniform distribution corresponding to a group of PFs. Multi-modal multi-objective optimization (MMO) can provide more elegant solutions, and provide diversified decisions for decision-makers in real optimization problems. How to balance the convergence, diversity and feasibility in the search process is the key and main difficulty in solving MMOP.
Differential evolution (DE) algorithm [36] was proposed by Storn and Price in 1997. As a new intelligent algorithm, it has simple principle, fewer controlled parameters, good robustness and easy implementation. Its essence is a multi-objective (continuous variable) optimization algorithm, which is mainly used to solve the overall optimal solution in multi-dimensional space.
The basic idea of DE algorithm is [37, 38]: The difference component of two individual vectors randomly selected from the population is used as the disturbance of the third random benchmark vector to obtain the variation vector, and then the variation vector is hybridized with the benchmark vector (or target vector) to generate the trial vector. Finally, the benchmark vector competes with the test vector, and the better one is saved in the next generation group. In this way, the differential evolution algorithm improves the population quality generation by generation and guides the population to focus on the location of the optimal solution.
Similar to other population-based stochastic algorithms, the process of DE algorithm mainly includes four steps: population initialization, variation, crossover and selection. As shown in Fig. 2, initialization is a one-time process, and the other three mechanisms are repeated in the DE searching process in the D-dimensional solution space until the termination conditions are met.
Consecutive phase of DE algorithm.
(1) Initialization
Let D be the dimension of the individual, NP be the population size, and
Where,
The value of each dimension of an individual can be generated according to the following formula:
Where,
(2) Variation
From a biological point of view, variation means a change in the sequence of genes in the chromosome. In the field of evolutionary computing, variation is regarded as the change of an element. In the differential evolution algorithm, take the simplest variation operation (DE/RAND/1) as an example, the variation operation for the
Where
Obviously, the smaller the difference vector between
At present, the other four widely used variation methods [38] are as follows:
DE/rand/2:
Where,
(3) Crossover
In order to improve the diversity of evolutionary population, the discrete crossover operator is introduced. Unlike other evolutionary algorithms, which exchange genes based on multiple reference vectors from the parent, the crossover operator in differential evolution algorithm uses reference vector and variation vector to operate.
(4) Selection
The selection operation of DE is a greedy selection mechanism [38], which is to retain the best in both the target vector and its corresponding test vector, so that the fitness value of the offspring is always better than that of the parent, resulting in the population always evolving to the position of the optimal solution and gradually focusing on the position of the optimal solution or satisfactory solution.
VRP is a typical MMOP. When solving this problem, the goal is to find one solution that may be sufficient to obtain an acceptable solution. If multiple shortest paths are not determined, the decision-maker may not be able to consider solutions that may improve performance. Since the preference of decision-makers is a priori unknown, it is necessary to provide a variety of excellent solutions. Generally, in MMVRPTW, each vehicle starts from a central depot, serves customers in the distribution area, and returns to the same central depot after the service. Among them, each car has its own capacity, and each customer has its own demand and time window to obtain services. A soft time window is used here to better optimize costs. The MMVRPTW is related to many factors. The mathematical model established is very complex and has many constraints. In order to facilitate modeling, the following assumptions are made in this study:
Only consider the logistics distribution of a single logistics distribution center. Vehicles responsible for logistics distribution must start from the distribution center and return to the distribution center after completing all customer order distribution tasks. Each vehicle only completes the distribution of one line. The demand and location coordinates of each customer are known and fixed. The customer nodes are interconnected, that is, the distribution vehicles can be transferred from customer node The arc formed between customer nodes has two-way weight, representing distance and time cost. In the process of vehicle distribution, the impact of temporary vehicle failure or goods distribution error and other factors will not be considered for the time being.
Based on the above assumptions, MMVRPTW can be formulated as an optimization problem in a complete directed graph. The goal of MMVRPTW is to find a solution with multiple equivalent optimal path solutions to serve all customers, meet all constraints and minimize the following five goals. In order to serve all customer points, the following constraints need to be followed: maximum delay time constraint, that is, each customer should be served before the maximum allowable delay time, and the service request should be fully satisfied at one time. Vehicle loading constraint, that is, the total demand of customers in the route shall not exceed the vehicle capacity.
Wherein,
Wherein,
Wherein,
Wherein,
Wherein,
Three stage framework and population distribution.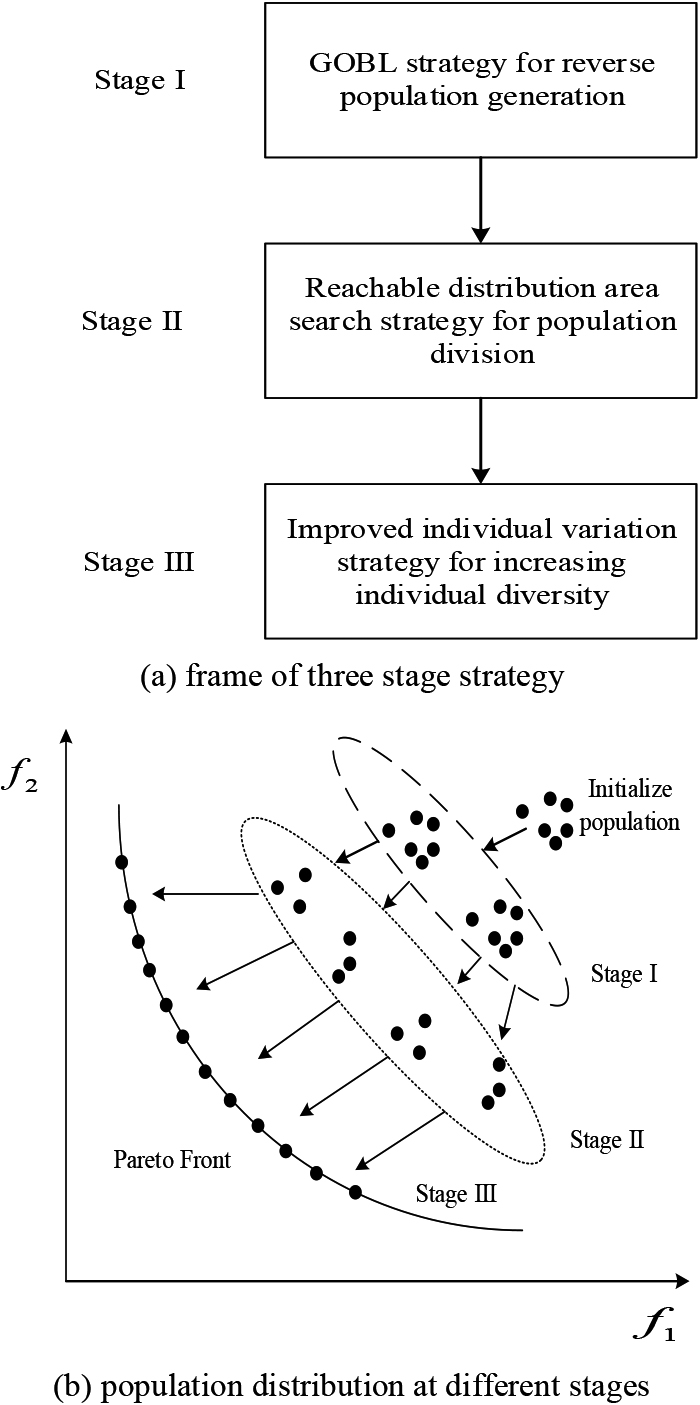
Flow chart of 3S-MMDEA.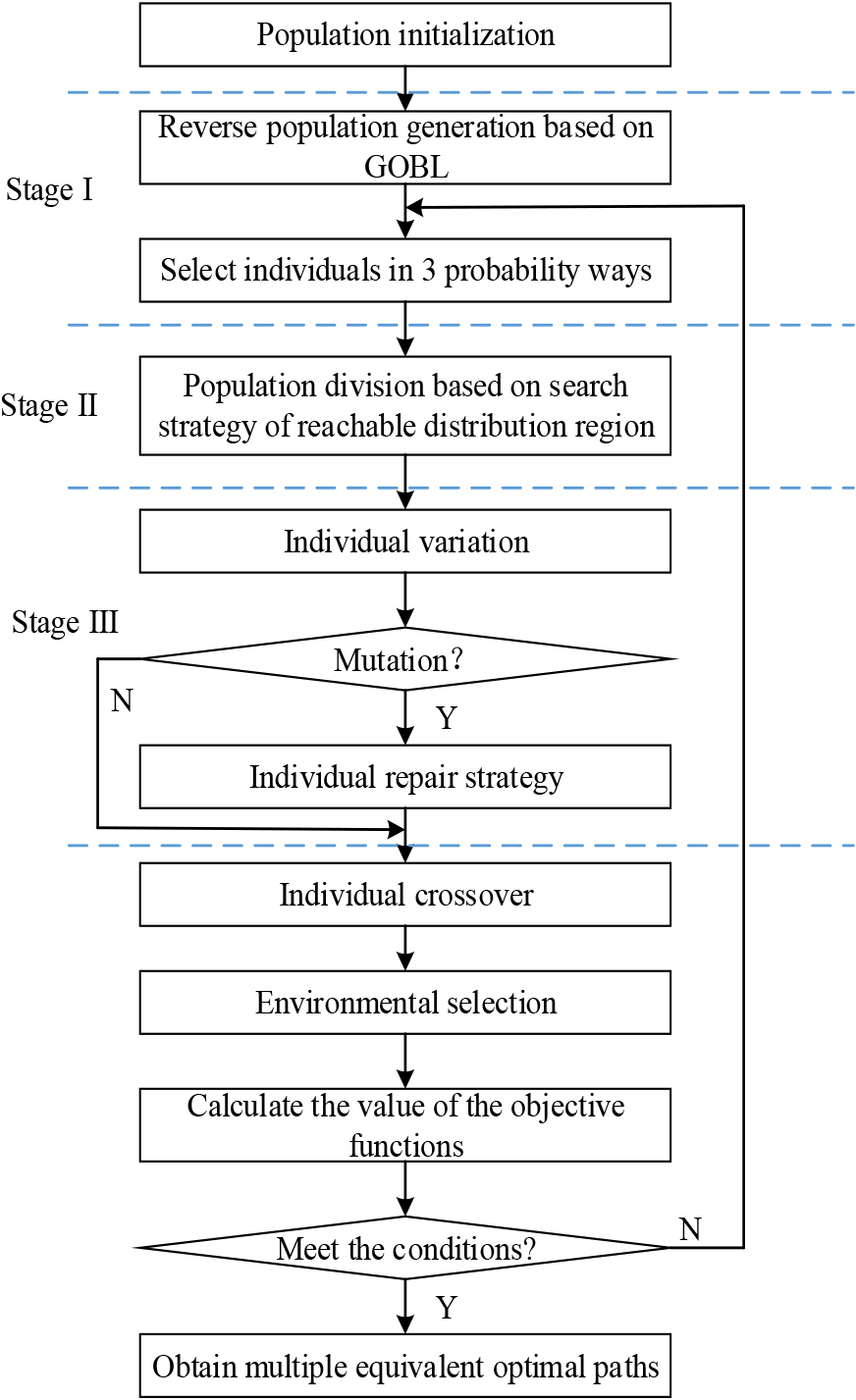
Basic framework of 3S-MMDEA
Traditional MOP solutions will be more likely to choose solutions with better convergence to form a new group. However, for problems with multiple different solutions corresponding to the same target value, convergence first will lead to premature emergence of the optimal solution, and the lack of diversity maintenance mechanism will lead to poor quality in finding all equivalent solutions.
MMDEA pursues two basic but often conflicting goals, namely convergence and diversity. This conflict has a negative impact on the optimization process of the algorithm and may be aggravated in many objective optimization. Therefore, in the process of MMDEA optimization, it is necessary to deal with the balance between convergence and diversity. In order to handle the balance well, the 3S-MMDEA shown in Fig. 3 is used to solve MMVRPTW. In 3S-MMDEA, a three-stage strategy is proposed to improve the convergence and diversity of MMDE algorithm.
3S-MMDEA consists of the following parts: population initialization, population expansion, individual selection, population division, individual variation, crossover and environmental selection. In the whole differential evolution process, in the first stage, a reverse population is generated through GOBL strategy (that is, multiple customer points are generated reversely), which increases the range of individual screening and improves the diversity of solution set. In the second stage, the reachable distribution area search strategy is used to divide the population (all customer points) with the selected individual (that is, the starting customer point) as the center point to improve the convergence of the solution set. In the third stage, through the improvement of individual variation strategy, the individual is legalized to make the individual still fall within the range of the population, further improving the diversity of the solution set. Based on the synergy of the above three stages of strategies, the diversity of individuals is ensured, so as to improve the diversity of solution sets, and multiple equivalent optimal paths are obtained to meet the planning needs of different decision-makers. The basic flow of 3S-MMDEA is shown in Fig. 4. It should be noted that the existing studies [11, 39, 40] and 3S-MMDEA use different staged methods to solve different types of problems based on different motivations.
Stage I: GOBL for population initialization
The initialization of the population is a key step in solving the problem, because it can control the quality of the final solution set, and the initialization process is an irreversible process. It is very important to conduct the operation of the non repeatable process, because the subsequent individual selection is based on the initial population, and the individual selection affects the overall quality of the initial solution obtained, thus affecting the overall process of the solution algorithm.
Generalized opposition-based learning (GOBL) [41] can effectively use the resources of the reverse solution, expand the search direction and improve the search efficiency.
Suppose
In the process of evolution, GOBL can restrict the search space of the population, accelerate the convergence speed and efficiency of the algorithm, and quickly find the optimal solution. The pseudo code in the initialization phase is as follows:
Using GOBL strategy to obtain the original population and the reverse new population, at this time, the population number becomes two, greatly expanding the range of individual selection. The individual selection needs to be conducted in two populations at the same time. The traditional DE algorithm compares the fitness of each individual of the parent vector in the population with the corresponding individual in the new population one by one, and saves the individuals with better fitness. Under this screening mechanism, there may be two individuals with better fitness or worse fitness for comparison. At this time, an individual with poor fitness will be retained, which will undoubtedly affect the evolution speed and easily fall into local optimization. In this paper, by using the generation method of difference vector and the calculation method of crowding distance in [42], the diversity of individuals is considered in both the current population and the changing population to achieve the optimal selection of individuals.
Stage II: Search strategy of reachable distribution area for population division
When using MMDE algorithm to optimize vehicle routing, customers need to be searched. That is, after individual selection, it is necessary to consider the access order of subsequent individuals to complete traversal search. Common search strategies include blind search strategy and heuristic search strategy [43]. The blind search strategy follows the specified route and does not use heuristic information related to the problem. The heuristic search strategy needs to use heuristic information related to the problem and guide the search process with these heuristic information. Combined with the research in this paper, heuristic search strategy should be adopted when searching individuals (i.e. customer points). In addition, we still need to consider the search range of individuals. On the one hand, because the experimental results are path length oriented, we need to consider the distance between different customer nodes. On the other hand, we need to consider the distribution range, that is, the maximum transportation distance of vehicle distribution. Therefore, this paper proposes a search strategy based on the reachable distribution region. The effectiveness of this method has been verified in our published paper [40].
Based on directed graph
Stage III: Improved individual variation strategy
In the variation step, it is better to have strong exploration ability because multiple solution sets need to be obtained. Therefore, DE/rand/2 [38] is adopted in this paper. The difference vector is generated into:
Wherein,
Due to the particularity of the problem, the mutated vector individual may not be feasible, that is, the individual generated by the variation does not meet the boundary conditions and directly exceeds the scope of the solution space, that is, falls outside the search space. Repairing the infeasible solution [41, 42] is a common means of evolutionary algorithm. In this paper, a new repair operator is designed to deal with the individuals crossing the boundary. The processing methods are as follows:
Firstly, the average Euclidean distance
Secondly, the individual
Then, for each dimension of the individual
If the just mutated dimension is still out of the allowed boundaries, repair according to the following formula:
Where,
The reason for using the above repair operator is that when the better NP individuals are selected from the original population and reverse new species population obtained by GOBL strategy for generation, there may be randomly generated individuals or individuals at the population boundary in the population, which may exceed the range of solution space after individual variation, resulting in fewer individuals, reducing individual diversity, and finally reducing the diversity of optimal solutions in PS. Figure 5 illustrates the legalization of mutant individuals. Where, black solid dots represent five individuals generated by difference, and hollow dots represent individuals generated by the first variation. Figure 5a illustrates that individual
Schematic diagram of variation legalization.
In order to improve the diversity of population, discrete crossover operator is introduced into DE algorithm. Different from the crossover operators in other evolutionary algorithms that exchange genes based on multiple benchmark vectors from the parent, the crossover operators in differential evolutionary algorithms use benchmark vectors and variation vectors to operate.
The selection operation of DE algorithm is a selection mechanism based on greed, which is to retain the optimal value between the target vector and its corresponding test vector, so that the fitness value of the child individual is always better than the fitness value of the parent individual, thus causing the population to always move towards the location of the optimal solution, and gradually focus on the location of the optimal solution or the location of the satisfactory solution. The commonly used selection mechanism may have the situation that the desirable number of individuals in the first level and the second level in the non dominated ranking is opposite. Therefore, this paper uses the environmental selection mechanism in [42] to screen individuals, so that the obtained PF becomes more complete with the increase of iterations.
Experimental results and analysis
Experimental settings
Parameters: In GOBL strategy,
Data-set: In this study, the data set in the same actual situation as that used by Zhou and Wang [46] and Castro Gutierrez et al. [47] is selected. This data set is composed of 45 real VRP data instances. These data are composed of 3 customers of different sizes, 5 time window configurations and 3 vehicle models of different capacities. Each instance is named “
Comparison algorithms: Since MMVRPTW is a new problem and no existing results can be directly used for comparison, we compared INSGA-II [49] (Improved NSGA-II) (equivalent to the third stage of the 3S-MMDEA) and HSA-HGBS [39] (equivalent to the second and third stages of the 3S-MMDEA). All algorithms are carried out under equal conditions. Equal conditions mean using the same starting and termination criterion, where the same starting criterion means the same primitive population, in the first stage of the three-stage algorithm, the population is initialized by using GOBL, while other comparative algorithms directly use their respective initialization methods to process the original population, equal number of starting search points, the same data set, the same hardware running the algorithms.
Evaluation indicators: A single performance indicator cannot comprehensively measure the performance of the multi-objective optimization algorithm. Therefore, we used four metrics, namely, Inverted generation distance (IGD) [50], 1/HV (HV is super capacity, hyper volume [51]), 1/PSP (PSP is Pareto Sets Proximity [34], it reflects the similarity between the obtained PSs and the true PSs.) and Number of Solution (NOS) [52]. Among them, 1/HV and 1/PSP, the most commonly used performance indicators for IGD multi-objective optimization problems, can measure performance in decision space and objective space respectively. The smaller the value of 1/HV and 1/PSP, the better the performance. They are commonly used evaluation indicators for MMOP.
In addition, the purpose of solving MMVRPTW is to find all Pareto optimal solutions that may have the same target value. Therefore, the number of different optimal solutions (NOS) is used to evaluate the results: NOS represents the number of solution sets
For IGD, 1/HV and 1/PSP, we used Wilcoxon signed rank test at 5% significance level. ‘B/S/W’ indicates that the effect of the proposed algorithm is significantly better/basically similar/significantly inferior to the current algorithm. In addition, the final ranking of all algorithms on the instance set is given using Friedman test [11]. The statistical result of the instance set is summarized as ‘B/S/W ’, which means that the effectiveness of the proposed algorithm is significantly better/basically similar/significantly inferior to the current comparison algorithm on B/S/W instances.
Experimental results and analysis
Table 1 shows the results of three algorithms on IGD, 1/HV and 1/PSP based on actual examples. Table 2 shows the performance comparison statistics results of all algorithms under the actual example. Table 3 shows the sorting results of Friedman test of the running results of the actual example. All the above results are the average of 30 times of algorithm execution. The B/S/W results in Table 2 show that for 1/HV and IGD, 3S-MMDEA is significantly better than HSA-HGBS in about half of the instances and INSGA-II in most instances. In Wilcoxon signed rank test, the R+value obtained by 3S-MMDEA is higher than the R-value in all cases. This means that 3S-MMDEA is superior to other comparison algorithms in all cases. In addition, the
Average values of IGD, 1/HV, and 1/PSP of 3S-MMDEA INSGA-II, HSA-HGBS
Average values of IGD, 1/HV, and 1/PSP of 3S-MMDEA INSGA-II, HSA-HGBS
Statistics performance comparisons on practical instances
It can be seen from Tables 1 and 2 that the difficulty of the problem increases with the increase of the number of customers and the decrease of the vehicle capacity. The reason is that the problem of having more customers and smaller vehicles will have more path planning solutions, so it will be more difficult to converge on all goals.
Average ranking of the algorithms by Friedman test on practical instances
In the real world, preference for one target (objective) may be higher than that for other targets. In the MMVRPTW with five targets considered in this paper, from a certain point of view, the target
Table 4 shows the average number of NOS obtained by all algorithms. It can be seen from Table 4 that with an increase in the number of customers (from 50 to 150 to 250), the number of solutions increases. In all instances, the 3S-MMDEA can stably obtain all different solutions. In addition, compared with the other two algorithms, the number of solution sets obtained by the three-stage strategy is obviously better.
In order to further verify the efficiency of the multi-mode multi-target algorithm proposed in this paper, we compare the method proposed in this paper with the MMOP algorithm DN-NSGAII [30], Omni optimizer algorithm [32], MO_PSO_MM [35], MMODEA_ICD [42] made comparison on “50-0-3”, “50-1-2”, “150-0-1”, “150-2-4”, “250-1-1” and “250-2-3” (randomly selected). Similarly, all algorithms are carried out under equal conditions. Equal conditions mean using the same starting and termination criterion, equal number of starting search points, the same data set, the same hardware running the algorithms. The comparison results between different MMO algorithms are shown in Table 5. It can be seen from Table 5 that 3S-MMDEA shows good effect on all evaluation indicators.
Average number of solutions obtained by 3S-MMDEA and other algorithms in 30 experiments for each problem instance
Comparison results of different multi-modal multi-objective algorithms
To better illustrate the performance of the proposed 3S-MMDEA, considering factors such as the actual logistics distribution constraints and the applicable solution scale of the compared algorithms, taking “50-1-2” as an example, which has a certain representativeness, we give the distribution of 3S-MMDEA and HSA-HGBS, MMODEA_ICD and INSGA-II in the final stage objective space. In multi-modal multi-objective optimization, the solution obtained when the objective function exceeds three is a hypersurface, which cannot be reflected in the coordinate system.
This article considers the solution of
Distribution of solution sets in the objective space obtained by different algorithms.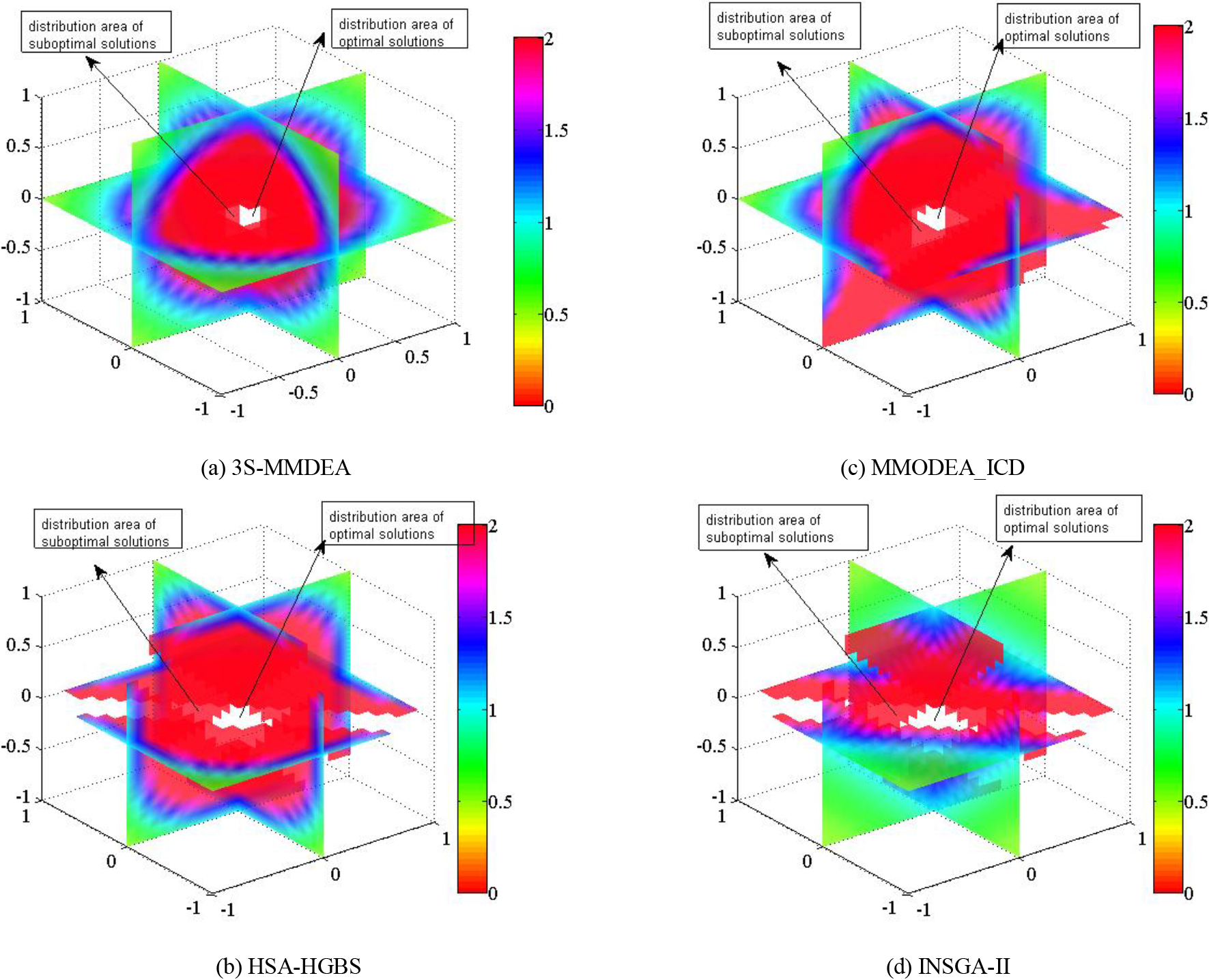
It can be seen from Fig. 6 that for the 3S-MMDEA, the optimal solution set is uniformly distributed in the objective space, showing a great diversity of solution sets, and the final solution set converges to a small region. The convergence and diversity of the other three algorithms are poor, and even some algorithms have lost some dominant solutions.
To sum up all the experiments and results, it can be seen that the 3S-MMDEA can maintain all the optimal solutions even if it has the same target value, while ensuring the diversity and convergence of the final solution set. For other MMO algorithms, it is difficult to ensure the diversity and convergence of objective space and decision space at the same time. For the traditional multi-objective optimization algorithm, although it is easy to find the Pareto front, it is difficult to find all equivalent solutions.
Vehicle routing planning is a practical problem aimed at finding the best route and realizing efficient logistics distribution. Since the preference of decision-makers is a priori unknown, it is necessary to provide multiple alternative solutions, that is, to maintain the diversity of solutions in the decision space and the convergence quality in the target space. This paper regards VRPTW as an MMOP, to solve this problem, a three-stage multi-mode multi-objective differential evolution algorithm is proposed to solve VRPTW. In the first stage, GOBL strategy is used to generate the reverse population to expand the selection range of individuals. In the second stage, a reachable distribution area division strategy is proposed to realize the population division with the selected individuals as the center point to improve the convergence of the solution set. In the third stage, the diversity of the solution set is further improved by improving the individual variation strategy to legalize the mutation individuals.
In this paper, the effectiveness of 3S-MMDEA have verified through logistics distribution of different scales in the standard data-set. By comparing with INSGA-II and HSA-HGBS, the experimental results show that the 3S-MMDEA proposed in this paper can efficiently solve VRPTW of different scales, and can obtain more equivalent optimal paths. The algorithm performs better in convergence and diversity. In addition, by comparing with DN-NSGAII, Omni-optimizer, MO_PSO_MM, MMODEA_ICD and other multi-modal multi-objective algorithms on the standard data-set, the experimental results show that 3S-MMDEA can obtain multiple equivalent optimal solutions while ensuring convergence.
Although the three-stage algorithm proposed in this paper can better optimize the vehicle routing problem with time window constraints, there are still some limitations. 3S-MMDEA is not an accurate algorithm, and in future research, we should consider the certainty of probability in optimization, and combine the characteristics of intelligent algorithm probability optimization to improve runtime and optimization efficiency. What’s more, in the subsequent research, it is still necessary to consider the local search in line with specific objectives and improve the performance of the algorithm.
Footnotes
Acknowledgments
This work is supported by the National Natural Science Foundation of China under Grant 61806006, China Postdoctoral Science Foundation under Grant No. 2019M660149, Graduate Innovation Foundation of Jiangsu Province under Grant No. KYLX16_0781, the 111 Project under Grants No. B12018, and PAPD of Jiangsu Higher Education Institutions.