
Abstract
Process discovery techniques analyze process logs to extract models that characterize the behavior of business processes. In real-life logs, however, noises exist and adversely affect the extraction and thus decrease the understandability of discovered models. In this paper, we propose a novel double granularity filtering method, executed on both the event and trace levels, to detect noises by analyzing the directly-following and parallel relations between events. Based on the probability of an event occurring in a sequence, the infrequent behaviors and redundant events in the logs can be filtered out. In addition, the missing events in parallel blocks are detected to further improve the performance of filtering. Experiments on synthetic logs and five real-life datasets demonstrate that our method significantly outperforms other state-of-the-art methods.
Introduction
Process mining [1] is a technique that dedicates to extracting process-related knowledge from event logs and providing profound insight for stakeholders. Process discovery, as one of the most challenging process mining tasks, captures the behavioral characteristics of processes from event logs and builds process models that reflect the actual process execution from a control-flow perspective [2]. In other words, process is discovered by analyzing process logs to extract sequential patterns that characterize the behavior of business processes. Such sequential patterns could be the building blocks of process models. High-precision process models not only visually demonstrate the actual flow of service execution but also help stakeholders acquire deeper insights into real business and support their decision-making such as detecting process deviation and take proactive actions in advance [3]. One of the greatest challenges that process discovery faces is to diagnose noises existed in event logs, which cause unnecessary structures in discovered models and further impede their precision and understandability [4]. It is generally believed that cleaning event logs to address quality issues prior to conducting a process discovery analysis is necessary [5].
False logs refer to unexpected and incorrect data that are generated during system operations, and system malfunction is considered as the main cause of false logs, which usually misses events (i.e., some events are not recorded in logs) [6] or adds redundant events (i.e., some events are repeatedly recorded in logs) [7] to event logs. Infrequent behaviors are behaviors that are not expected to occur but actually happen with very low frequency in real execution, the existence of which also seriously impacts the extraction of process models [8]. The above-mentioned incorrect or infrequent data in real-life logs (collectively called noises in this paper) [9] not only increase the complexity of discovered process models, but also reduce their precision [10]. Thus, in many cases, approximations to the process model can be discovered by applying a fraction of the event data [11].
In general, business process activities are performed in accordance with a well-designed process model (i.e., Reference Model), and the execution of these activities are recorded in logs for process discovering. However, noises that are unexpectedly generated in logs during real executions greatly impede the discovering. As shown in Fig. 1, the reference model contains only sequential and exclusive structure, which means the recorded logs should contain only two types of traces (i.e., trace
Example of negative effects of noise.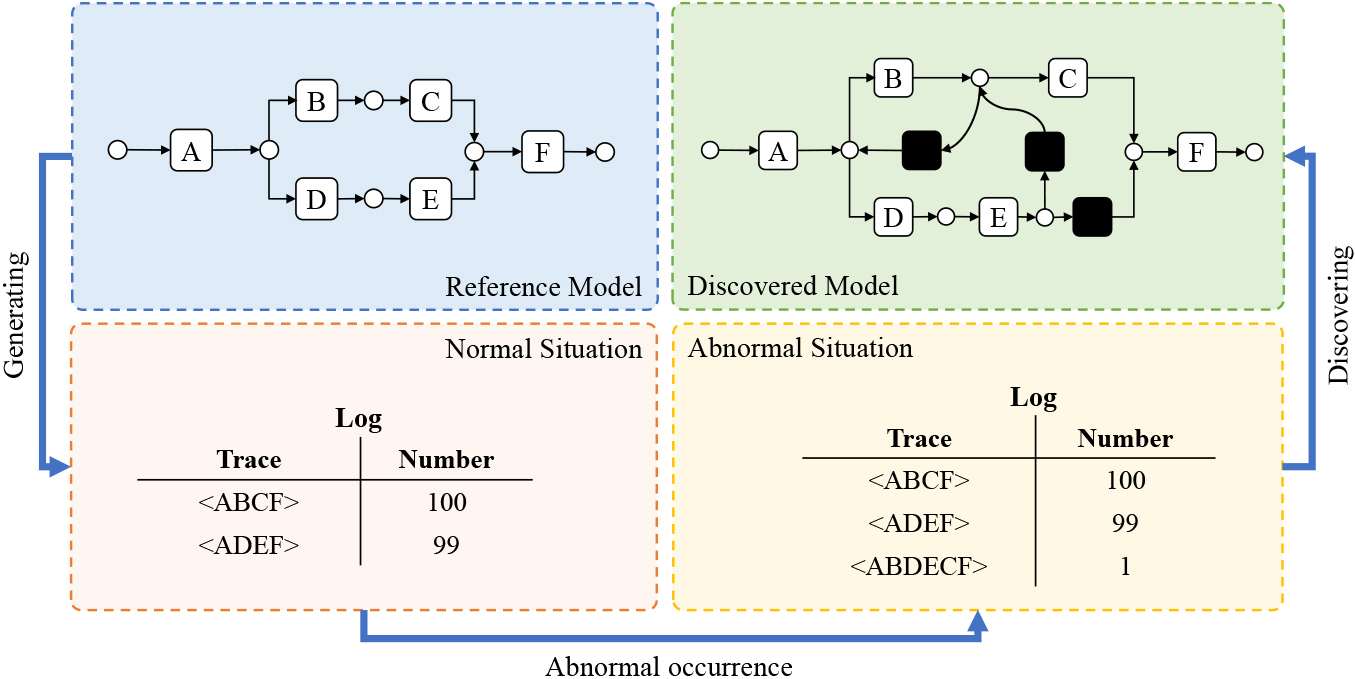
To improve the results of process discovering, a range of methods have been proposed to filter noises in event logs. However, some of them cannot detect all types of noise, such as missing events, while others affect the quality of discovered models for small logs by removing entire traces rather than specific incorrect events from logs [6, 5, 9]. To address these problems, in this paper, we propose a novel method of filtering out noises in event logs, called Double Granularity Filtering (DGF), to ease process discovery based on the concept of dependency. Here, dependency refers to the relationship between events in recorded logs, indicating the probability of one event occurring after another. The higher the dependency value between two events, the stronger their relationship would be. In our opinion, closely related events are more likely to be normal, while loosely related events are more likely to be infrequent behaviors. More specifically, in our method, we couple local dependency and global dependency as mixed dependency to conduct fine-grained filtering of abnormal events based on statistical probability. Here, we use local dependency to denote the frequency of two sequentially occurring events among all paired ones beginning with the first event or ending with the second one, while global dependency is defined to denote the frequency of two sequentially occurring events in the whole log. In addition, considering that fine-grained filtering is not detectable for some specific scenarios such as event lost, we add a coarse-grained filtering to the method for removing traces through a double-tier penalty mechanism to achieve double granularity filtering. Comparison experiments on synthetic and real-life datasets with two other filtering methods verify the precision and superiority of our method.
The major contributions of our paper are as follows: 1) We propose a novel double granularity filtering method, which considers both the events and traces, to detect noises more precisely. 2) We introduce the definitions of Local and Global Dependency to reflect the relation of two events precisely. 3) We define a concept of parallel block to detect missing events that are supposed to exist in the parallel structure. 4) We conduct extensive experiments to verify the effectiveness of our method on synthetic logs and five real-life datasets by comparing it with other state-of-the-art filtering methods.
The rest of this paper is structured as follows: After discussing the related work of log noises filtering in Section 2, we introduce preliminaries and details of our method in Section 3. Section 4 evaluates our method on multiple datasets against existing methods. Finally, we conclude the paper and discuss future works in Section 5.
Given the growing availability of event logs, an equally growing interest is drawn on automated process discovery [12]. However, noises in event logs always decrease the understandability of discovered models. To address this problem, during the past years, various techniques have been put forward to remove the impact of noises for better process model discovery during the past decade. Due to the fact that the implementation of noise filtering is mainly distributed in two different stages of process mining, the related researches on noise detection are accordingly divided into two categories.
The first category deals with noises during the mining process. Most early process discovery techniques (e.g., the
The second category is to pre-process logs and remove noises before the mining process. According to the granularity of noise processing, this category of methods is further divided into two types: fine-grained filtering (i.e. removing specific abnormal events from log) and coarse-grained filtering (i.e. removing entire traces of anomalies from logs). Conforti et al. [9] proposed the method of constructing an automaton to filter events in logs. The core idea is to build an Anomaly-Free Automaton by removing infrequent events in the logs. Then the original logs are filtered by replaying on the previously constructed Anomaly-Free Automaton according to alignment-based technique. Similar to this method, Zelst et al. [21] proposed a method that is suitable for noise filtering in online environments. This method first constructs a probabilistic automaton using the historical event stream, and then filters the incoming event stream and automatically adjusts the probabilistic automaton to adapt the new online environment. Tax et al. [22] proposed Activity Filter (AF) for filtering out events based on information theory and Bayesian statistics. However, this technique may erroneously filter some correct events due to the different ways the same task can be performed. In addition, the PROM framework [23] provides a lot of plugins for log preprocessing. In particular, the Filter Log using Prefix-Closed Language (PCL) plugin implements filtering of abnormal events through its defined language rules, so that the trace can be expressed via a PCL. Meanwhile, the Filter Log using Simple Heuristics (SLF) plugin filters the noisy events based on the frequency of the events occur or their positions in traces. Moreover, Ghionna et al. [24] proposed a method to distinguish abnormal traces and normal traces. It first uses clustering algorithms to obtain the main behavior patterns in the logs, and then filters traces that contain infrequent behavior patterns. Budalakoti et al. [25] used unsupervised clustering to cluster the sequences of events in logs, and then filters out the traces that deviate from the centers of the clusters. Florez-Larrahondo et al. [26] used Hidden Markov models (HMMs) to filter abnormal data. Sani et al. [6] proposed a filtering method (Matrix Filter (MF)) that fully considers the relationship between current activity and prefix activity sequence, and removes traces containing events whose conditional probabilities between sequences of activities are below a set threshold. Nguyen et al. focused on detecting anomalous values and reconstructing missing values at the level of attributes in event logs [27]. They proposed methods based on autoencoders, which can reconstruct their own input and are particularly suitable to learn a model of the complex relationships among attribute values in an event log. Likewise, through auto-encoding the event-level and state-level features, Ni et al. [28] represented process instances in a comprehensive and compact form so as to predict the remaining execution time of business process instances. Besides, Vidgof et al. [29] put forward an interactive log-delta analysis technology that enables analysts to interactively establish the range for log filtering and further explore manual differentiation between typical and atypical behaviors. BINet, a neural network architecture proposed byNolle et al. [30], is another work worthy of attention, which can be used to detect anomalies in event logs not only at a case level but also at event attribute level.
Inspired by previous studies, we propose a novel double granularity filtering method to detect noises while pre-processing business logs. Here, we first couple local dependencies and global dependencies as mixed dependencies to perform fine-grained filtering of noisy events based on statistical probability. Secondly, we employ a penalty mechanism to punish the traces after removing the noisy events. Afterwards, we define a concept of parallel block to detect missing events that are supposed to exist in the parallel structure, and combine it with the penalty strategy to determine the abnormality of traces to complete the second part of coarse-grained filtering. Finally, we test and compare the performance of our method with other filtering methods on both synthetic and real-life datasets.
Approach
In this section, we introduce our noise filtering method, i.e., DGF, from three aspects. Firstly, we demonstrate the basic definitions of concepts used in this paper. Secondly, we introduce how our method works to finely filter noises based on mixed dependency. Finally, we explain the strategies used in the coarse-grained filtering stage.
Preliminaries
In information systems, the executed activities are usually recorded in logs to help the relevant personnel to understand and analyze the practical process [31]. Table 1 provides an example event log of credit application process in a bank, where each row represents an event. Here, CaseId indicates which process execution instance the event belongs to, Activity gives the name of the activity executed by the event, StartingTime (CompletionTime) denotes the starting time (completion time) of the event, and finally Resource shows the execution resource of the event.
Example of real-life logs
Example of real-life logs
For example, as indicated from first row of Table 1, we have
For example, as indicated from Fig. 1, we have
For example, as indicated from Fig. 1, we have
By analyzing event logs, the relationships between events can be calculated and analyzed. Based on the stability assumption of system operation, either the probability of noise occurrence or the proportion of noises in logs is small. Therefore, we can analyze logs from the perspective of probability and statistics to identify noises. In this paper, we focus on two kinds of relations between events, i.e., directly following relation and parallel relation. Figure 2 shows an example of the two relationships.
Example of directly following relation and parallel relation.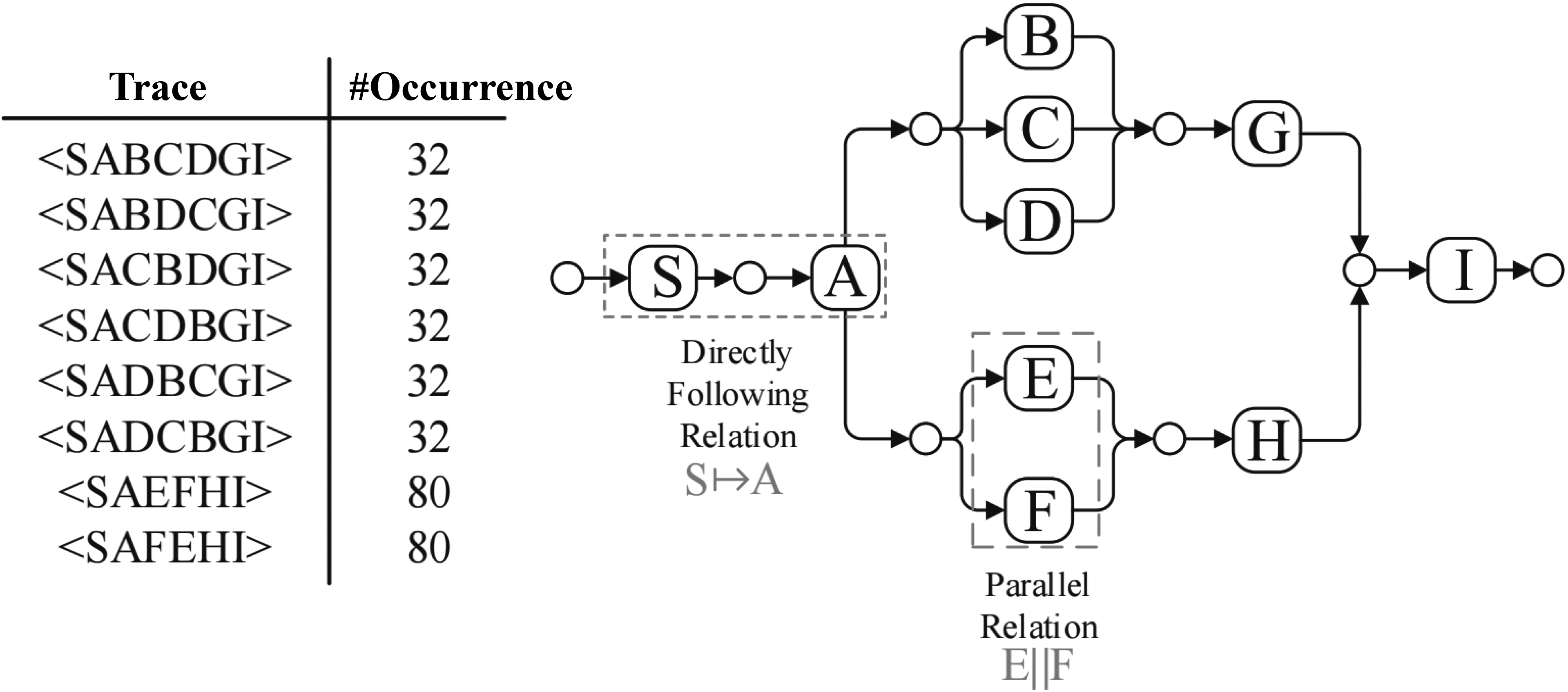
In order to describe the association strength between two events, we use
For example, given log
If
For example, as indicated from Fig. 1, since
For example, given log
For example, in Fig. 2, the Parallel Block Set of the log
For example, in log
This subsection introduces how to comprehensively consider the local and global dependencies of events to complete the Fine-grained filtering of noises, which refers to filtering noises at the event level. We assume that abnormal events occur less frequently than normal events as generally accepted [9]. Therefore, by analyzing the execution context of an event, we determine whether it is a noise or not.
As Eq. (4) indicates, Local Dependency is normalized to [0, 1), and tends to 1 (0) as the
In addition to Local Dependency, we also determine noises by the overall correlation, i.e., whether the frequency of current behavior (co-occurring events) is significantly lower than the frequency of other behaviors. A noise global factor
Finally, a trade-off factor
A higher
Given
The construction process of mixed dependency matrix.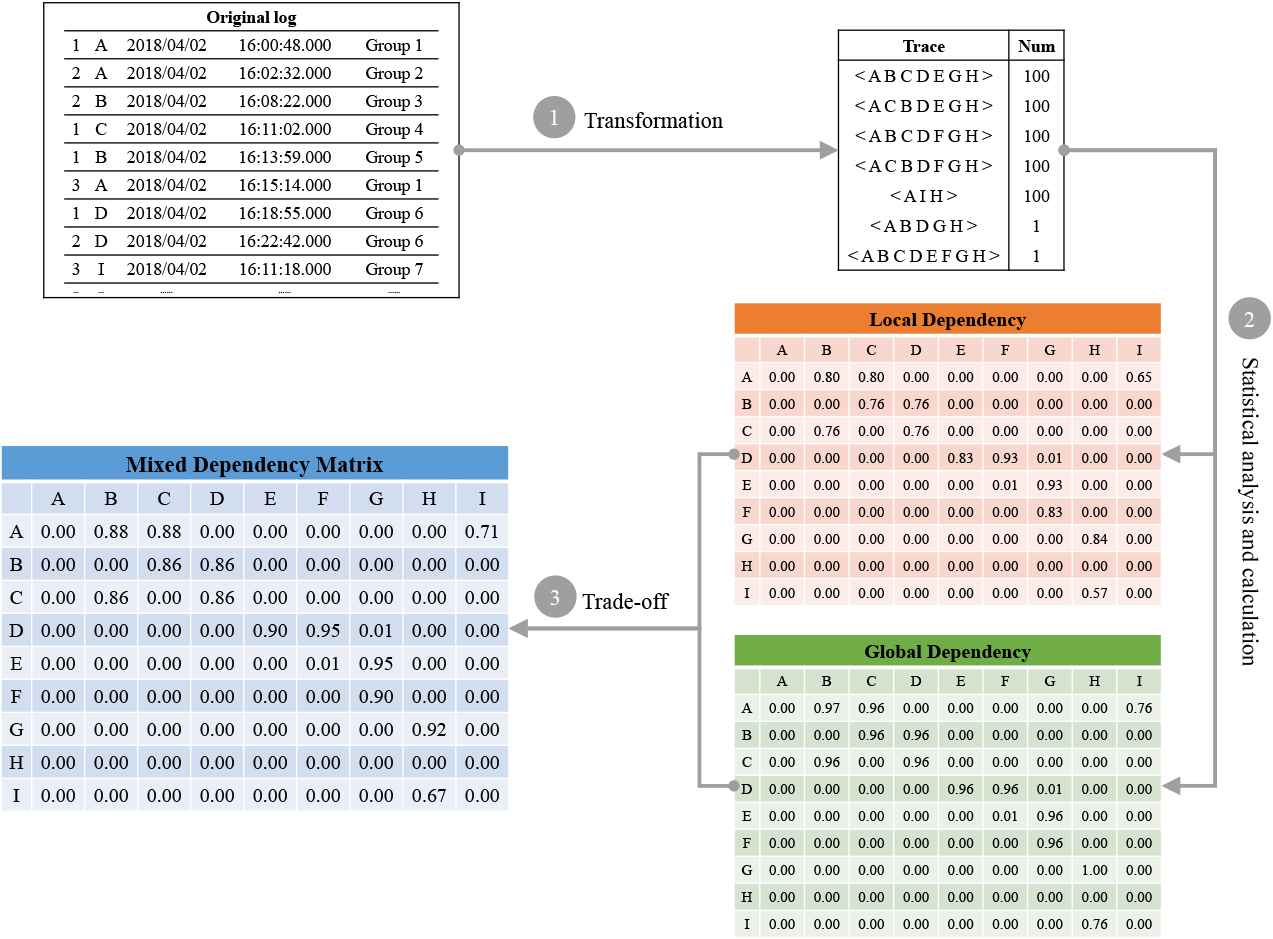
In addition to the Fine-grained filtering, we further use Coarse-grained filtering to detect abnormal traces and filtering these anomalies at a trace level. For each trace
However, during our research, we notice that the above penalty mechanism still fails to detect the lost of events in parallel structures. To solve this problem, we employ the parallel block we proposed above to implement the penalty for parallel structures to check for missing parallel events.
For trace
For example, in log
Further, if the missing degree of the trace is bigger than 0, which means that there are events missing from the parallel blocks, we use the following formula to punish the current trace.
If the abandon factor of
[htbp]
[1] initial event log
Algorithm 1 detailly describes the filtering process of our Double Granularity Filtering method (DGF), which is divided into the following two steps:
Constructing mixed dependency matrix (Lines 1–2) Firstly, according to the definitions proposed above, statistical analysis is performed on all events in the initial log Double granularity filtering (Lines 3–30) For each trace
As for the first part, the fine-grained filtering is performed together with the first part of coarse-grained filtering (Lines 7–18). Specifically we traverse two adjacent events in
As for the second part of double granularity filtering, the coarse-grained filtering on
Examples of noise filtering.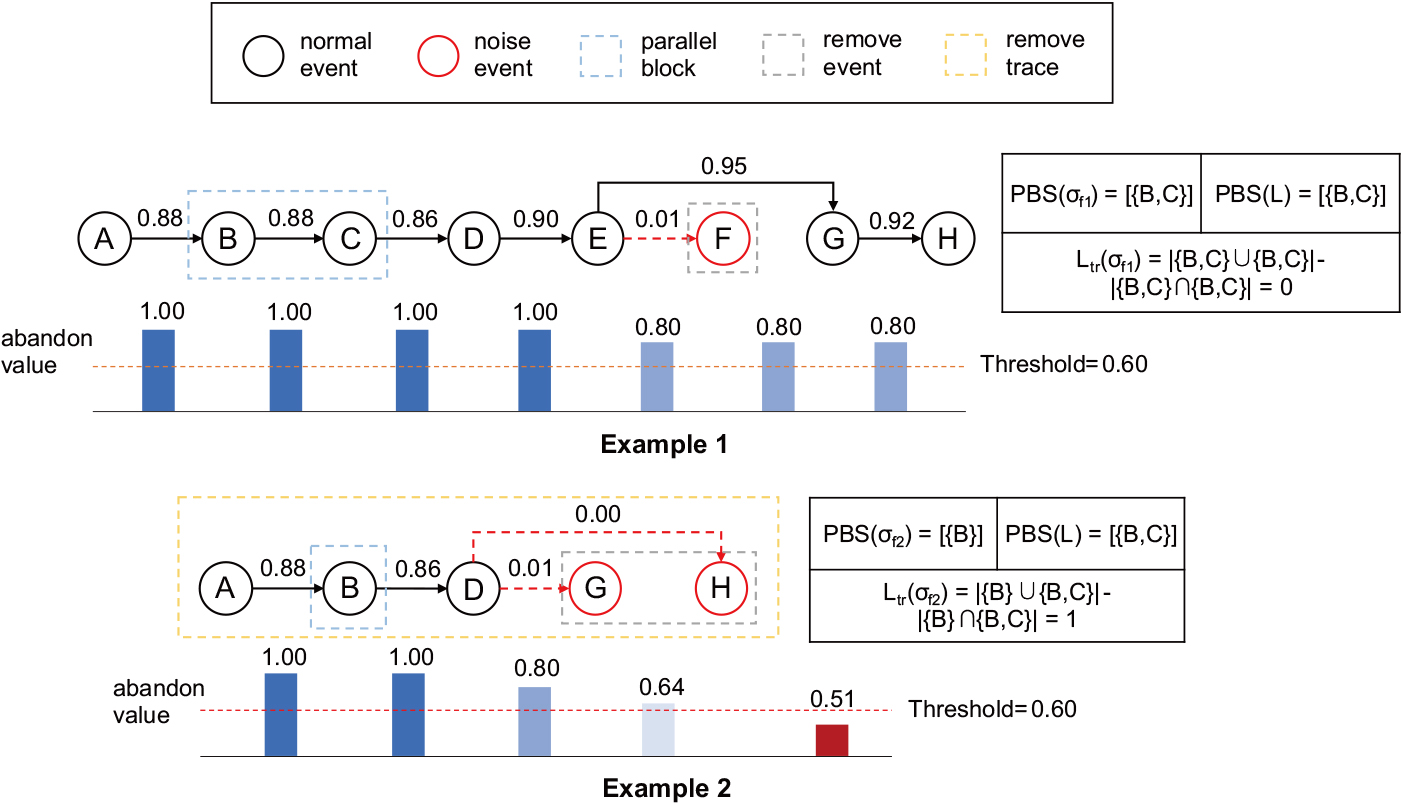
In order to better understand the method of this paper, we introduce our method in detail through an example. We select the log shown in Fig. 3 as the initial log with trace
Firstly, extract start event Secondly, take out the succeeding event Similarly, take out the succeeding event Take out the next event Take out the next event Take out the next event Take out the next event Take out the next event Obtain the parallel block set of the original log and
In the second example of Fig. 4, similar to the above process, for the trace
In order to verify the effectiveness of the log noise filtering method proposed in this paper, we conduct extensive experiments on the ProM platform based on both synthetic and real-life datasets. The source code can be downloaded from
Datasets
As for datasets, we use CPNtools [32] to synthesize logs with different noise ratios. In addition, we also use five real-life business process logs obtained from 4TU Centre for Research Data (
Synthetic log Since the simulation log data is synthesized by CPNtools and is noise-free, we generate log sets with different noise ratios by injecting noises into them. As we know, during the execution of the real system, event redundancy, event missing, event sequence exchanges and other types of errors occur in the log. In this paper, we mainly consider the first two types of noises. Based on Pareto Principle [33], the noise ratio in the generated log in this paper ranges from 5% to 25% with a increasing step of 5%. In each log, the noise consists of an equal number of missing events and redundant events, with a total of 5 logs, 20000 events per log on average. Hospital Billing (HB) This log is collected from the ERP system of a local hospital. Each case records a series of medical procedure that are billed together. It contains 10000 process execution instance records, each with an average of 16 events. Road Traffic Fine Management Process (RTF) This dataset is obtained from a local police station in Italy and it recordes 150,370 examples of local road traffic fine repayment processes, with an average of 4 events per instance. Sepsis Cases (SC) Similar to HB, this dataset also comes from the local hospital’s ERP system. The difference is that this dataset is generated from the diagnostic module. There are 1050 cases with an average of 14 events in this log. BPI Challenge 2020 (BPIC2020) This dataset contains the events of two years related to Requests for Payment of 6,886 cases and 36,796 events. The dataset is used for Business Process Intelligence Challenge 2020. Help Desk (HD) This event log concerns the ticketing management process of the Help desk of an Italian software company, which covers 4580 cases and 21348 events.
Metrics and baselines
Three indicators are selected to measure the quality of the discovered process models: fitness, precision and F-score.
Fitness: Fitness is used to measure how many behaviors in the event log can be reproduced in the discovered models. The range of values for fitness is [0, 1], and the higher the fitness of the discovered models, the stronger their ability to represent the log behavior. Precision: Precision measures how many behaviors in a model can be supported by event logs. When the precision value is 1.0, it means that only behaviors recorded in the log are allowed in the process model. F-score: F-score combines the fitness and precision to consider the quality of the discovered model, as Eq. (10) shows,
To demonstrate the effectiveness of our proposed DGF method, we compare it with the following methods:
Inductive Miner (IM [18]/IMi [17]): Inductive Miner is a discovery algorithm based on a divide-and-conquer approach. An extension of IM, which called Inductive Miner-infrequent (IMi), is able to filter infrequent behaviors while ensuring soundness. Matrix Filter (MF [6]): MF employs the conditional probability of an activity occurring after sequence of activities to detect abnormal behaviors. Activity Filter (AF [22]): AF filters out events based on information theory and Bayesian statistics. Filter Log using Simple Heuristics (SLF [23]): SLF, a plugin of ProM, removes traces and activities based on frequency of events.
Performance of filtering methods on synthetic logs with different noise ratios.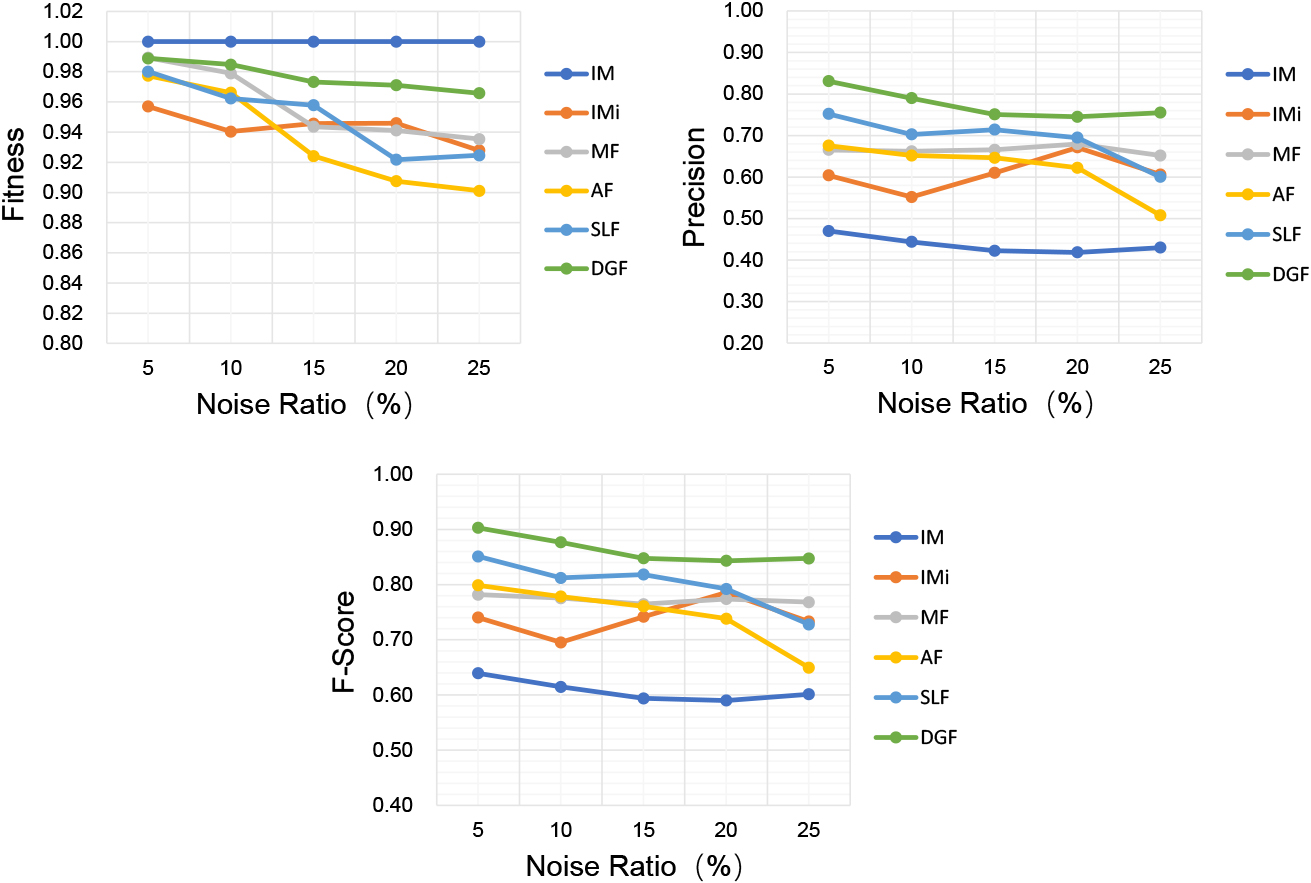
In the first experiment, we use the synthetic logs with different proportions of noises to investigate the effect of different noise ratios on the performance of six methods, i.e., IM [18], IMi [17], MF [6], AF [22], SLF [23] and our newly proposed DGF. The experiment uses IM as the benchmark mining method. In other words, we incorporate these noise filters into IM for a fair comparison. Meanwhile, we use the IMi variant with a default noise threshold of 0.2. As for our method DGF, we use
Due to the fact that IM does not have a built-in noise filtering mechanism, its discovered models are complex and cover all behaviors including false behaviors and infrequent behaviors, which explains why its fitness value is close to 1.0 but its precision is the lowest. Compared to IM, IMi has a certain noise tolerance, but its precision is also relatively low since its noise mechanism mainly aims at filtering low-frequency behaviors rather than all types of noises. As a contrast, the DGF method manages to guarantee the highest precision and pretty high fitness of the discovered model simultaneously, and its F-score is much higher than the other methods.
Comparison of model indicators for five real-life logs.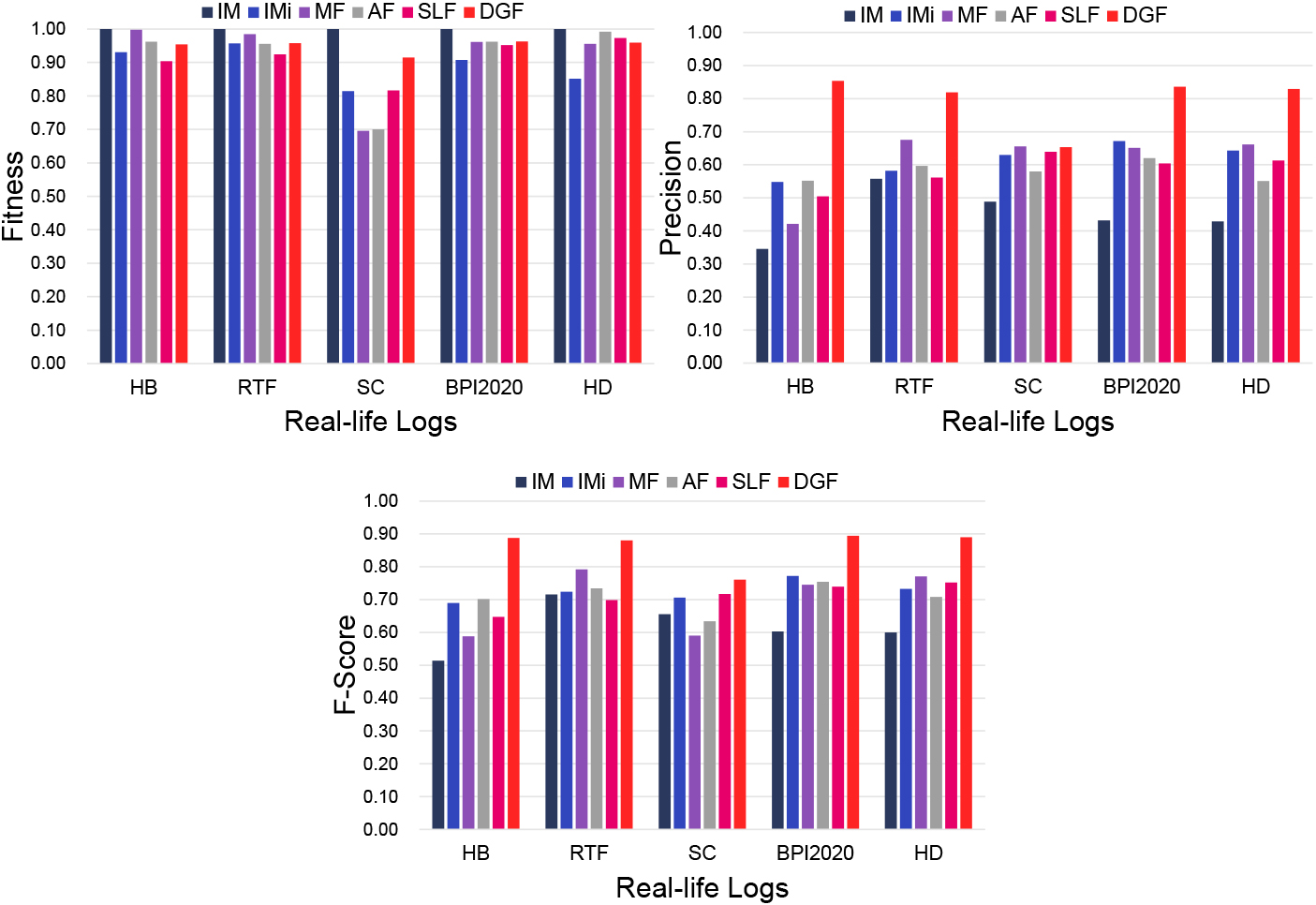
To further demonstrate the effectiveness of our proposed method, we perform a second experiment on five real-life datasets. Here, we set the noise thresholds for IMi to 0.1 and 0.2 and take the average as the final results. The IM method is again used as a benchmark. We apply DGF with five noise global factors ranging from 0.10 to 0.30 with a trade-off factor of 0.5. Figure 6 shows the average results.
The influence of the trade-off factor on the model.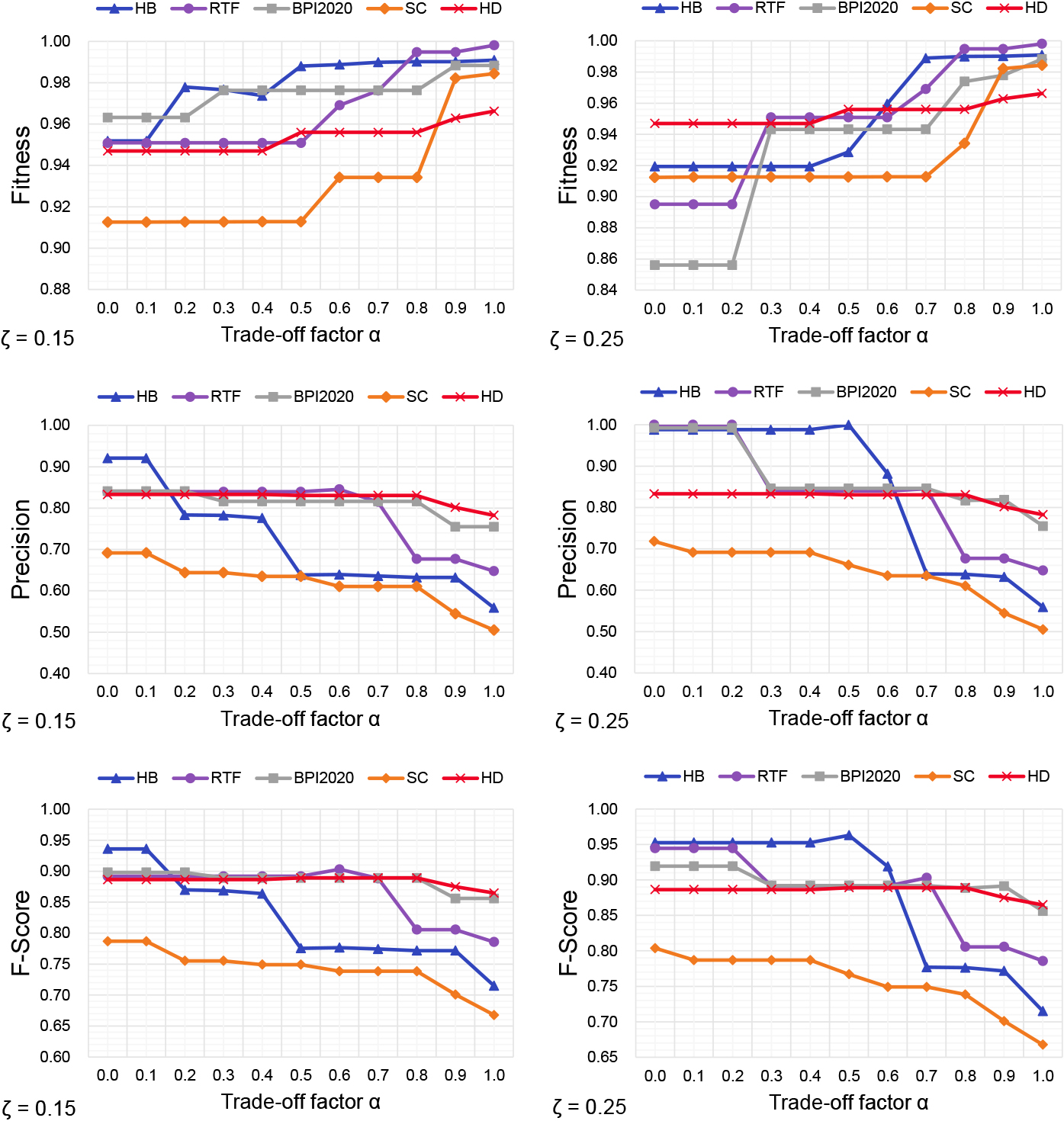
As for these five datasets, DGF outperforms all other methods in terms of F-score. Although the precision of DGF is slightly lower than that of the MF method on the SC dataset, it has excellent performance on the other four datasets. In particular, the precisions of DGF on the HB, RTF, BPI2020 and HD datasets are all higher than 0.80. The main reason is that the process structure corresponding to these datasets is relatively simple. In addition, DGF takes the missing events in parallel structure into consideration, which also leads to a higher precision than other methods. Since the abnormal behaviors recorded in these logs are filtered and hence cannot be replayed in DGF, there is a certain decline in the fitness of its discovered models. However, DGF manages to ensure that the final F-score of models achieves the highest among all methods. In terms of fitness, the models discovered by IM remain the highest and the reason is the same as we discussed above that they contain all behaviors recorded in the log. Besides, we also notice that as a comprehensive combination of the fitness and precision of the model, the variation of F-score index is basically consistent with precision.
In the last experiment, we try to explore the influence of the setting of the trade-off factor
In sum, the results in Figs 5 and 6 show that our method achieves better performances in both synthetic and real-life datasets than the compared methods. However, it takes a slight decrease of the fitness of the discovered models as a cost to achieve higher precision. The result in Fig. 7 shows that although the variation trend of precision and fitness is different for each dataset when
In this paper, a novel double granularity noise filtering method based on dependency correlation and parallel relation is proposed to solve the negative impact of log noises on discovering high-quality process models. Unlike traditional filtering methods that only conduct fine-grained or coarse-grained filtering to remove noises, our method couples these two granularities to remove noisy events and traces simultaneously. In addition, in order to prove the effectiveness of our method, we carry out comparison experiments in ProM based on one synthetic and five real-life datasets. The results verify our proposed DGF improves the precision and F-score of the process models significantly.
In future, we will try to use heuristic algorithms to further improve filtering efficiency. In addition, we will employ the deep learning technology to recommend a correction scheme for noisy traces under different circumstances. Last but not least, to add our proposed DGF method in ProM as a plugin is also on the list of future work.