
Abstract
Nowadays, the idea of active learning is gradually adopted to assist domain adaptation. However, due to the existence of domain shift, the traditional active learning methods originating from semi-supervised scenarios can not be directly applied to domain adaptation. To solve the problem, active domain adaptation is proposed as a new domain adaptation paradigm, which aims to improve the performance of the model by annotating a small amount of target domain samples. In this regard, we propose an active domain adaptation method named Boosting Active Domain Adaptation with Exploration of Samples (BADA), dividing Active DA into two related issues: sample selection and sample utilization. We design the instability selection criterion based on predictive consistency and the diversity selection criterion. For the remaining unlabeled samples, we design a self-training framework, which screens out reliable samples and unreliable samples through the sample screening mechanism similar to selection criteria. And we adopt respective loss functions for reliable samples and unreliable samples. Experiments show that BADA remarkably outperforms previous active learning methods and Active DA methods on several domain adaptation datasets.
Introduction
Deep neural networks have achieved impressive performance in various scenarios such as image classification [1, 2] and semantic segmentation [3, 4] by training a large amount of supervised data. However, these networks, which depend on the utilization of the supervised data in the single domain, can not be well generalized to the unsupervised domain with different data distributions [5]. To solve the problem, unsupervised domain adaptation (UDA) [6, 7] aims to transfer the knowledge of the supervised source domain to the unsupervised target domain. Nonetheless, there is still a wide gap between the results of UDA methods and that of fully supervised learning [8]. In reality, it is feasible to label a small number of target domain samples. Therefore, the paradigm of labeling samples to improve the performance of domain adaptation defined as Active Domain Adaptation (Active DA) has attracted the attention of researchers [9].
Active learning focuses on how to select the most informative samples to improve the performance of the model [10, 11]. Most active learning algorithms design sample selection criteria from the perspectives of the uncertainty and diversity of unlabeled samples. The uncertainty of the sample usually depends on the classification results of the model [12, 13], and the diversity of the sample is regarded as its representativeness [11, 14]. Although existing sample selection criteria show superior performance in active learning tasks, directly applying these criteria to domain adaptation is infeasible. Due to domain shift, traditional uncertainty and diversity estimation on the target domain may be miscalibrated, which leads to sub-optimal sample selection [15].
Comparison between Active DA methods pipeline and our proposed pipeline. The recent some Active DA methods achieve initial domain alignment through domain adversarial learning, followed by sample selection, and finally combine with source domain samples for supervised training. Our proposed method first selects informative samples without pre-alignment, and then screens out appropriate samples for self-training. 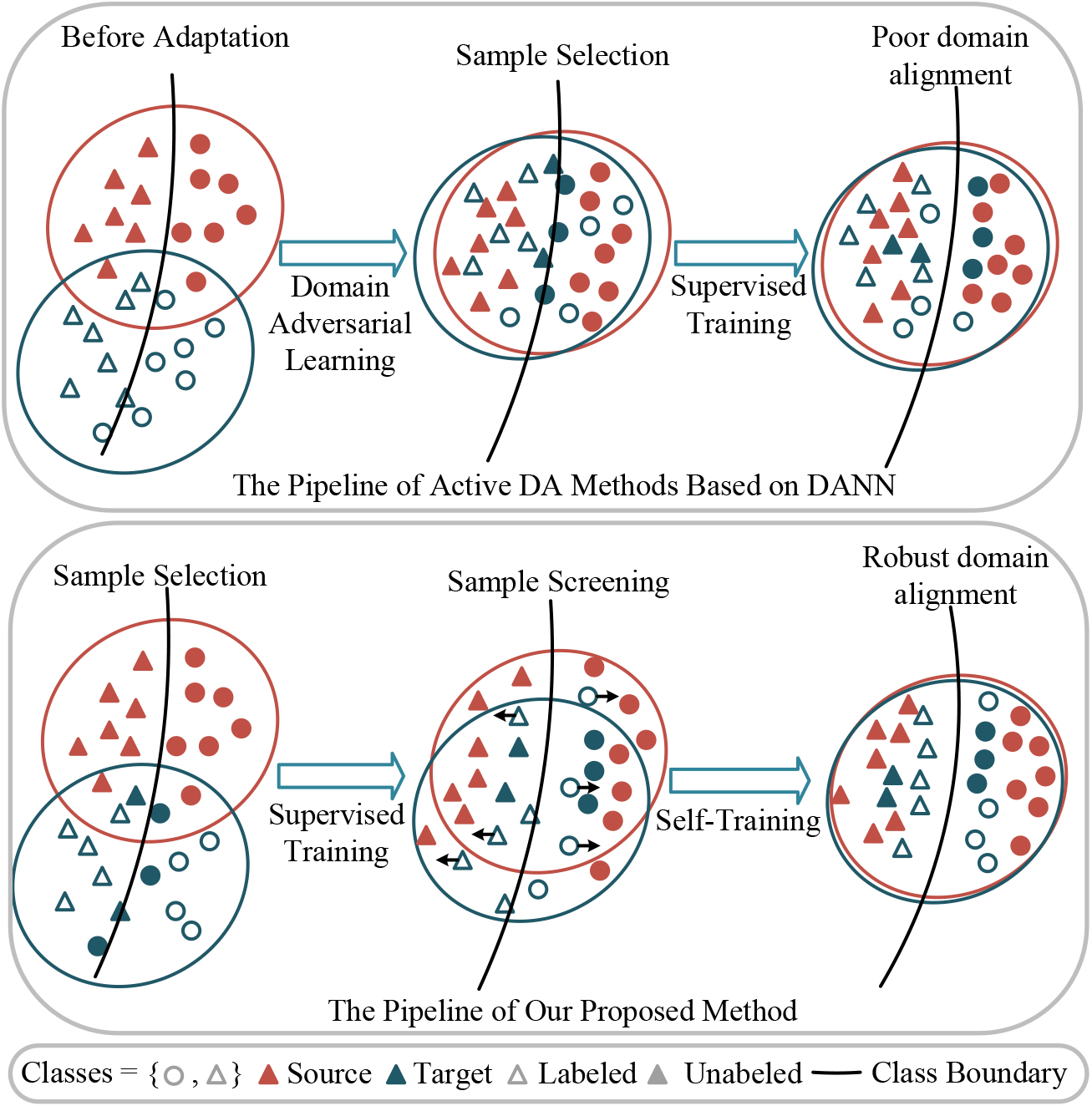
In order to overcome the negative effects of domain shift in Active DA, recent work in Active DA has sought an appropriate pipeline that can fit domain adaptation and sample selection. AADA [16], the state-of-the-art Active DA method, proposed the pipeline of Active DA. As shown in Fig. 1, its pipeline was to align the source domain and target domain through domain adversarial learning [17], and then designed complex sample selection criteria for unlabeled samples based on the output of the domain discriminator and the entropy. The pipelines of subsequent Active DA methods, such as TQS [18] and S3VAADA [19], are similar in that the target domain is originally well aligned with the source domain through DANN [20] before sample selection. The difference is that they design different sample selection strategies. On the whole, these Active DA methods select samples to label from the uncertainty and diversity of samples, which inherits the perspective of sample selection in traditional active learning. And these methods follow the same pipeline, that is, sample selection is performed on the basis of domain adversarial training.
Although the existing methods have achieved good results, we believe that there are two problems to be solved. First, most of Active DA methods rely on domain adversarial learning, which inspires us to design effective sample selection strategies that can overcome domain shift without relying on adversarial learning. The other is that the information on available unlabeled samples is not fully utilized, and it is hoped to make full use of the information on remaining unlabeled samples. In fact, there are Active DA methods that try to combine semi-supervised domain adaptation methods to explore the value. However, due to the difference between the experimental settings of semi-supervised DA and Active DA, the expected results may not be achieved. In general, the existing Active DA methods do not significantly exploit the value of the remaining samples after sample selection, and making full use of these unlabeled samples can further boost the performance.
In order to solve the above problems, we propose a new method named Boosting Active Domain Adaptation with Exploration of Samples (BADA). Its pipeline is shown in Fig. 1. In sample selection, to avoid sub-optimal selection caused by using an uncalibrated model under domain shift, we design consistency-based instability criteria based on the consistency learning paradigm. Specifically, the instability of the sample is estimated based on the predictive consistency between the sample and its label-preserved transformed versions, and the sample with high inconsistency is preferential to be labeled. The insight behind this is that consistency checks based on data augmentation which is considered as a way of perturbation injection can effectively detect initial errors of the model [21]. Secondly, to overcome the redundancy of selected samples, we further consider the diversity of the sample. To be specific, we estimate the local density of the sample by calculating the distance between the sample and its neighbors in the feature space and then evaluate the diversity of the sample with entropy as uncertainty weight. Finally, for the remaining samples, we design a self-training framework. Based on the predictive consistency checks, we screen out the samples with high stability among reliable samples and assign pseudo-labels to these samples for self-training. In addition, for the remaining unreliable samples, we further develop negative learning loss to enhance the performance of the model.
In general, the contributions of this work are as follows: firstly, we have designed simple and effective sample selection criteria, which can select the most valuable samples that are worth labeling. Our proposed sample selection criteria take the instability and the diversity of the sample into account. Secondly, we design the self-training framework to boost performance. By screening out reliable samples and unreliable samples, our proposed framework can further explore and utilize the value of samples. Finally, through conducting extensive experiments on mainstream datasets, we show that BADA can achieve excellent performance.
The rest of this article is organized as follows. We first retrospect the related work in Section 2, and then describe our proposed method in detail in Section 3. Next, the results of our experiments are presented and discussed in Section 4. Finally, we summarize our article in Section 5.
Domain adaptation
Domain adaptation aims to transfer the knowledge of the source domain to the target domain. A typical line of approaches [22] mine domain invariant features based on adversarial learning to achieve domain alignment between the source domain and the target domain, and another typical line of approaches improve feature alignment based on the clustering hypothesis [23] through the minimization of conditional entropy [24, 25]. However, there is still a large gap between the performance of these methods and the full supervision.
There exist some researches that assign pseudo-labels to samples with high confidence for self-training [26, 27]. These methods also show that partially pseudo-labeling the target domain samples can effectively improve the performance. In practice, it is feasible to give ground-truth labels to some samples. Inspired by active learning, we can select the most valuable samples for labeling on the target domain.
Active learning
Active learning aims to improve model performance by selecting the samples with the most information. They can be categorized into two mainstream sampling criteria: uncertainty sampling and diversity sampling. Uncertainity sampling methods identify the most ambiguous samples under the current model. The reason behind this is that by labeling the samples whose classification results are ambiguous, the model can learn more useful knowledge in the next round of training. These methods usually evaluate the uncertainty of the samples by relying on the confidence, the entropy [28, 29] or classification margin [30, 31]. Some methods measure the predictive consistency of the samples under ensemble models [32, 33] as the basis of uncertainty. Diversity sampling methods usually pre-cluster the unlabeled samples in the feature space in advance and annotate the most representative samples [34, 35]. There also exist approaches to combine the two, selecting samples with both uncertainty and diversity. BADGE [36] explored the diversity and uncertainty of samples in gradient embedding space, running KMeans
However, these traditional active learning algorithms were all designed in the single-domain, without overcoming domain shift. For this reason, we propose BADA, which labels the samples according to the instability and diversity of the samples.
Active domain adaptation
With the development of deep learning in domain adaptation, AADA [16] started with pre-alignment via DANN [20], and selected samples by measuring the entropy of samples and the domain similarity based on the domain discriminator. TQS [18], after pre-alignment, designed rather complex selection criteria that combined predictive consistency, margin, and domainness of under ensemble classifiers to select worthy samples. S3VAADA [19] designed a score function based on the sensitivity of samples to their adversarial perturbation, the diversity and representativeness to construct the annotated sample candidate pool after virtual adversarial domain adaptation. CLUE [37], similar to BADGE, selected samples by entropy-weighted clustering algorithm and also combined with MME [38]. SDM-AG [39] proposed selection criterion by calculating the distance between the sample and different categorical clusters.
The above some Active DA methods adopted similar pipeline. Our proposed method first selects samples from the instability and the diversity without pre-alignment, and then screens out reliable samples and unreliable samples for self-training.
Method
In this section, we describe BADA in detail. Firstly, we propose simple and effective sample selection criteria to select samples. Then, we explore the value of the remaining unlabeled samples.
In Active DA setting, we have a fully labeled source domain defined as
As shown in Fig. 2, we divide Active DA into two phases: (1) fully supervised training and (2) self-training. In the first phase, appropriate samples are selected through the designed sample selection criteria, and these labeled samples are trained along with the source domain supervised samples; In the second phase, we explore the value contained in unlabeled samples for self-training.
The architecture of BADA, which contains two phases. The first phase is the fully supervised training of source domain samples and labeled target domain samples. Select the samples to be labeled through sample selection criteria, and then combine the source domain samples for fully supervised learning. For the remaining unlabeled samples in the target domain, samples can be split into reliable samples and unreliable samples based on sample screening mechanism. We adopt respective loss functions for different samples. 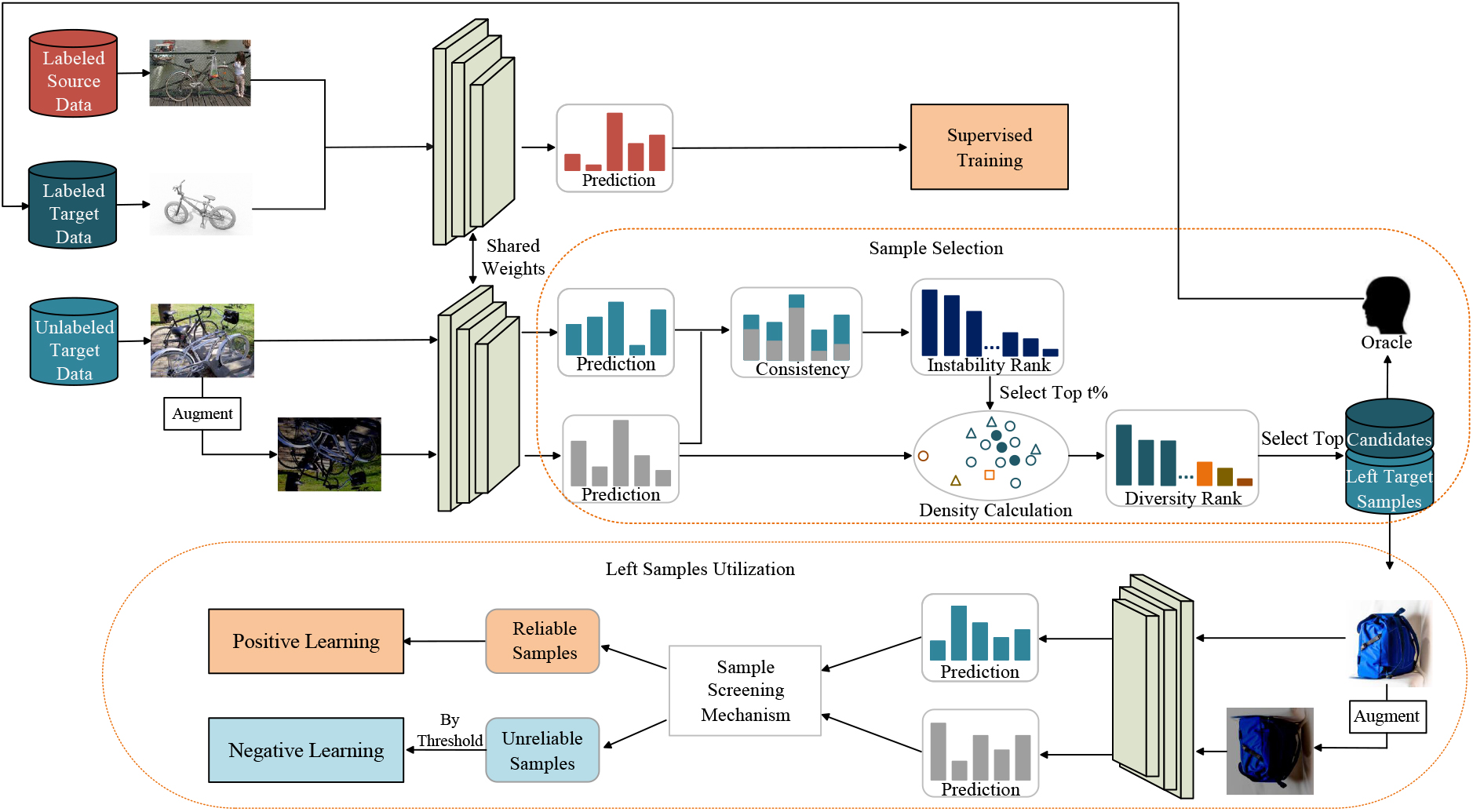
Traditional active learning methods use top-1 softmax confidence to measure the uncertainty of the sample under the model, and then label samples with high uncertainty. However, when in domain adaptation, the evaluation results of the sample by traditional selection criteria could be unreliable due to domain shift. Therefore, most of the current mainstream active domain adaptation methods usually achieve domain alignment through adversarial training before sample selection.
On the contrary, our proposed sample selection criteria do not need to align the source domain with the target domain initially. In order to avoid the error calibration problem of traditional active learning methods in the case of domain shift, we do not consider the uncertainty estimation of samples, but rather consider the instability of samples themselves. The stability of the sample refers specifically to the degree of consistency of the classification results of the sample and its label-preserving transformed versions. The insight is that firstly data augmentations can be seen as a way to inject perturbation to samples [40], and samples with high stability are less affected by perturbation; Secondly, for given classifier, the performance on highly stable samples is still robust despite the existence of noise.
We suggest using the predictive inconsistency as a more stable sample selection criterion, namely Consistency-based Instability Criterion. Specifically, given the sample
We use standard deviation to calculate the inconsistency of predictions. With Eq. (1), we can calculate the instability score for all unlabeled samples. We select the samples with the top
By performing CIC, we can initially construct a candidate pool of samples with high instability or out of distribution. However, if only rely on CIC for selecting samples, it will cause redundancy in sample selection, resulting in a pool of samples with similar properties. In addition to samples with high instability, there are still many informative samples that have not been selected. To overcome redundancy as much as possible and further select samples that are worth labeling, we need to select the most diverse samples among candidate pool.
The diversity of the sample usually refers to its representativeness in unlabeled samples. The distance between the sample with high diversity and its adjacent samples in the feature space can be compact, and the local density of the sample can be large. In this paper, we measure the diversity based on the local density of the sample in the feature space. Specifically, given an unlabeled sample
where
In addition, entropy can not only reflect the uncertainty and information of the sample, but also measure the domainness of the sample [37]. The domainness of the sample represents how private the sample is to the target domain. Since the model is initially trained by the source domain samples, the sample easily classified by the model is biased to the source domain and less private to the target domain. We use the entropy of the sample and its augmentations as the weighting factor, so that the criterion can not only estimate the diversity, but also capture the uncertainty and domainness. The score of Uncertainty-based Diversity Criterion is calculated by the following formula:
where
In the process of sample selection, we first obtain the instability score of each sample through CIC, According to CIC, the samples with the top
The final selected target domain samples and source domain samples participate in supervised training. The objective function is defined as:
Through sample selection, we determine the samples that are ultimately worth labeling. For the remaining large amount of unlabeled samples, there are few Active DA methods to explore the value thoroughly. Due to the difference between the experimental setup of semi-supervised DA and that of Active DA, the effect of directly applying semi-supervised DA methods, such as MME [38], may not be as good as expected. To this end, we propose a self-training framework for the remaining samples. We divide the remaining samples into reliable samples and unreliable samples through the sample screening mechanism, and based on this, we design respective loss functions.
Reliable Samples
Usually, DA methods based on self-training manually set the confidence threshold to screen out reliable samples. The reliable samples can be defined as:
where
This method is simple and effective, but it can not overcome the error caused by domain shift. Therefore, we need to further screen out more reliable samples and its pseudo-labels. Due to the superiority of CIC on estimating the instability of the sample, we adopt the similar way to evaluate the instability of
So combined with the instability of pseudo-labels, the sample screening mechanism of reliable samples can be defined as:
where
The objective function for reliable samples is defined as:
By optimizing Eq. (9), the probability of the pseudo-label
Unreliable Samples
For left samples that are not belong to
where
where
: BADA Algorithm[1] Labeld source domain
To be clear, the selection and training processes based on above description is summarized as Algorithm 3.3. And the overall objective function is defined as:
We begin by describing our experimental setup: datasets, implementation details and baselines. Next, we present our results and compare them with other state-of-art methods. Finally, we perform ablation experiments, examine the rationality of our methods, analyse parameters sensitivity and perform feature visualization.
Datasets
Implementation details
We perform all the experiments based on PyTorch. On Office31, OfficeHome and VisDA, we adopt ResNet-50 [43] pre-trained on the ImageNet [44] as our backbone network. All the networks are optimized by applying a mini-batch Stochastic Gradient Descent optimizer (SGD) [45], where the momentum is set to 0.9 and the weight decay is set to 5e-3. In sample selection, we conduct five rounds of sample sampling, each round selecting 1% target domain samples, so the labeling budget
Baselines
We compare BADA with several active learning methods and state-of-art Active DA methods. For active learning methods, we compare BADA with RANDOM, UCN [28], QBC [47], Cluster [48], BADGE [36]. And for Active DA methods, we compare BADA with ADMA [14], AADA [16], TQS [18], S3VAADA [19], CLUE [37] and SDM-AG [39]. Among these methods, AADA, TQS and S3VAADA are based on domain adversarial learning. BADA-Selection is a special case of BADA, where only sample selection is performed and the self-training framework is not performed.
Results on Office31 with 5% target domain samples as the labeling budget. We highlight the best result
Results on Office31 with 5% target domain samples as the labeling budget. We highlight the best result
Results on OfficeHome and VisDA with 5% target domain samples as the labeling budget. We highlight the best result
The results of experiments on Office31, OfficeHome and VisDA are shown in Tables 1 and 2. We can see that our method achieves better performance than compared methods on three datasets. In addition, although traditional active learning methods do not take domain shift into account, they achieve better performance than ResNet-50, which proves that Active DA has broad prospects.
On Office31, BADA-Selection obtains comparable mean accuracy with current state-of-art Active DA methods. The performance of BADA can be better than all compared methods, improving 0.8% than the second best. On OfficeHome, we can observe that BADA-Selection can outperform state-of-art active learning methods and Active DA methods based on DANN, such as AADA, TQS and S3VAADA. When combined with self-training, the mean accuracy can be further improved from 71.3% to 74.1%. Obviously, we can see that on tasks A
(a) Comparsion results of varying the percent of selected samples on VisDA. (b) Mean accuracy of BADA and its components varying the percent of selected samples on OfficeHome.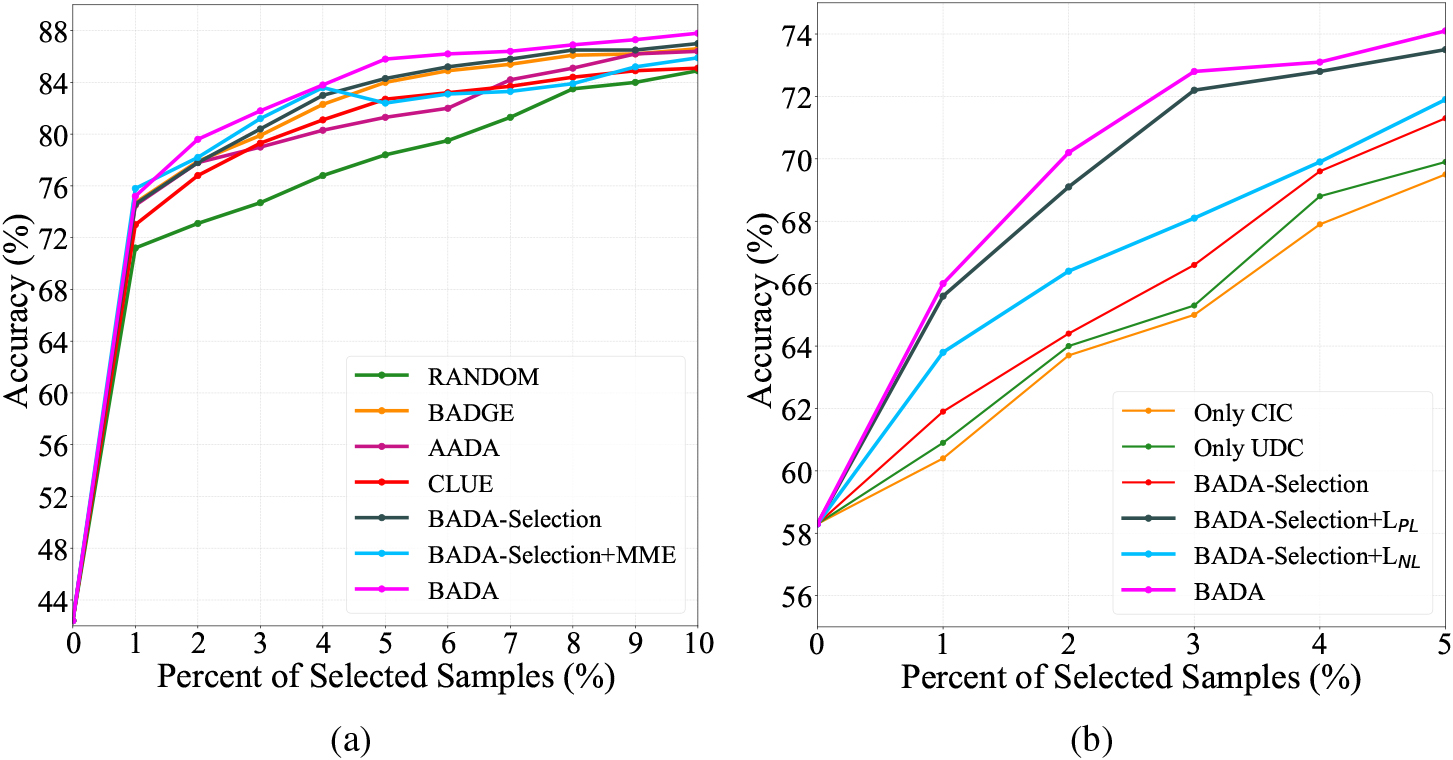
Varying budget
To demonstrate the superiority of our method, we perform experiments with different methods under different labeling budgets. Four other methods are compared with BADA-Selection and BADA. In addition, we combine BADA-Selection with MME to further study the effect of MME on BADA-Selection as increasing the labeling budget. The results on VisDA are shown in Fig. 3a. We can observe that as the labeling budget goes from 1% to 10%, the accuracy of BADA-Selection increases steadily and BADA can achieve better performance than the compared methods consistently. We can also observe that under 1% labeling budget, combing BADA-Selection with MME outperforms BADA-Selection and BADA. However, when the labeling budget reaches to 5% and then continues to increase, the effect of MME on BADA-Selection tends to be saturated and is not as good as BADA-Selection. We conjecture the reason is that in the experimental setting of MME, there exists a small amount of labeled samples per class, but the labeling budget of Active DA far exceeds that of MME. This phenomenon also indicates that directly combining Active DA with MME may not be as good as expected.
Ablation results on OfficeHome with 5% target domain samples as the labeling budget
Ablation results on OfficeHome with 5% target domain samples as the labeling budget
To quantify the effect of each component of our proposed method, we conduct ablation experiments on all 12 tasks of OfficeHome in this subsection. The results under 5% labeling budget can be found in Table 3 and the mean accuracy with the increasing labeling budget on OfficeHome is shown in Fig. 3b. For sample selection criteria, we study the effect of each criterion. When performing UDC or CIC alone, we directly select samples according to respective scores, not setting the parameter
Sensitivity of parameters
Considering that different values of parameters have different influence on the performance of the model, the values of parameters
Sensitivity analysis of 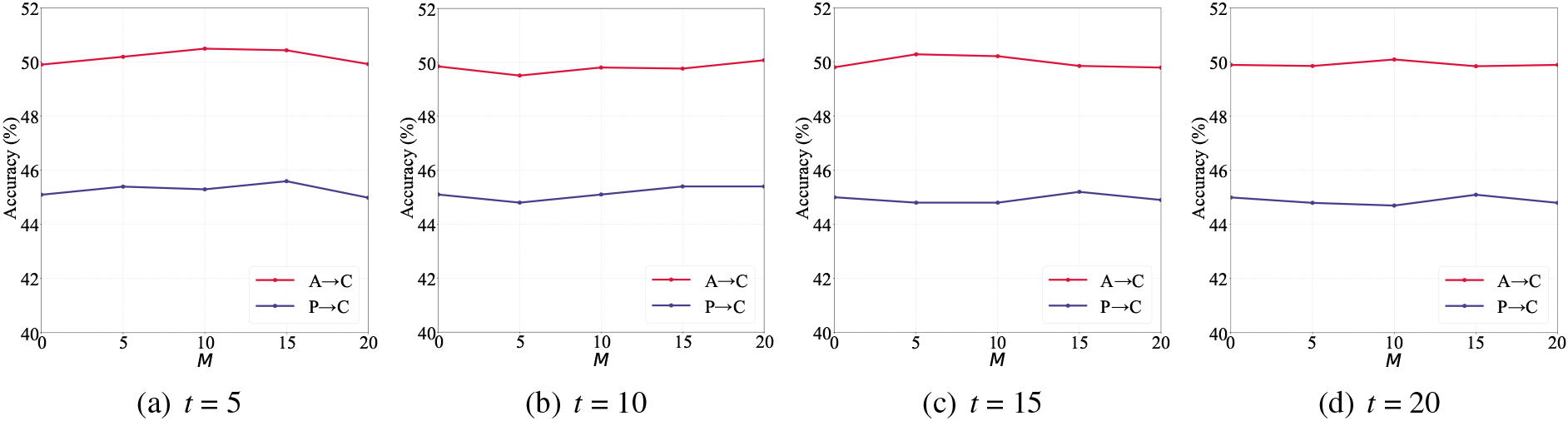
Results of different values of 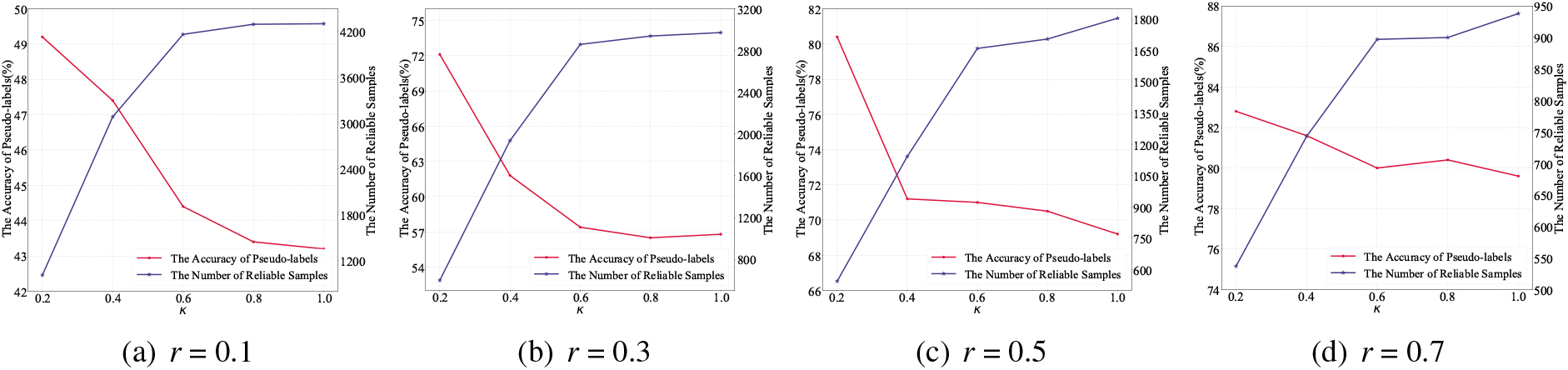
(a) Results on the task A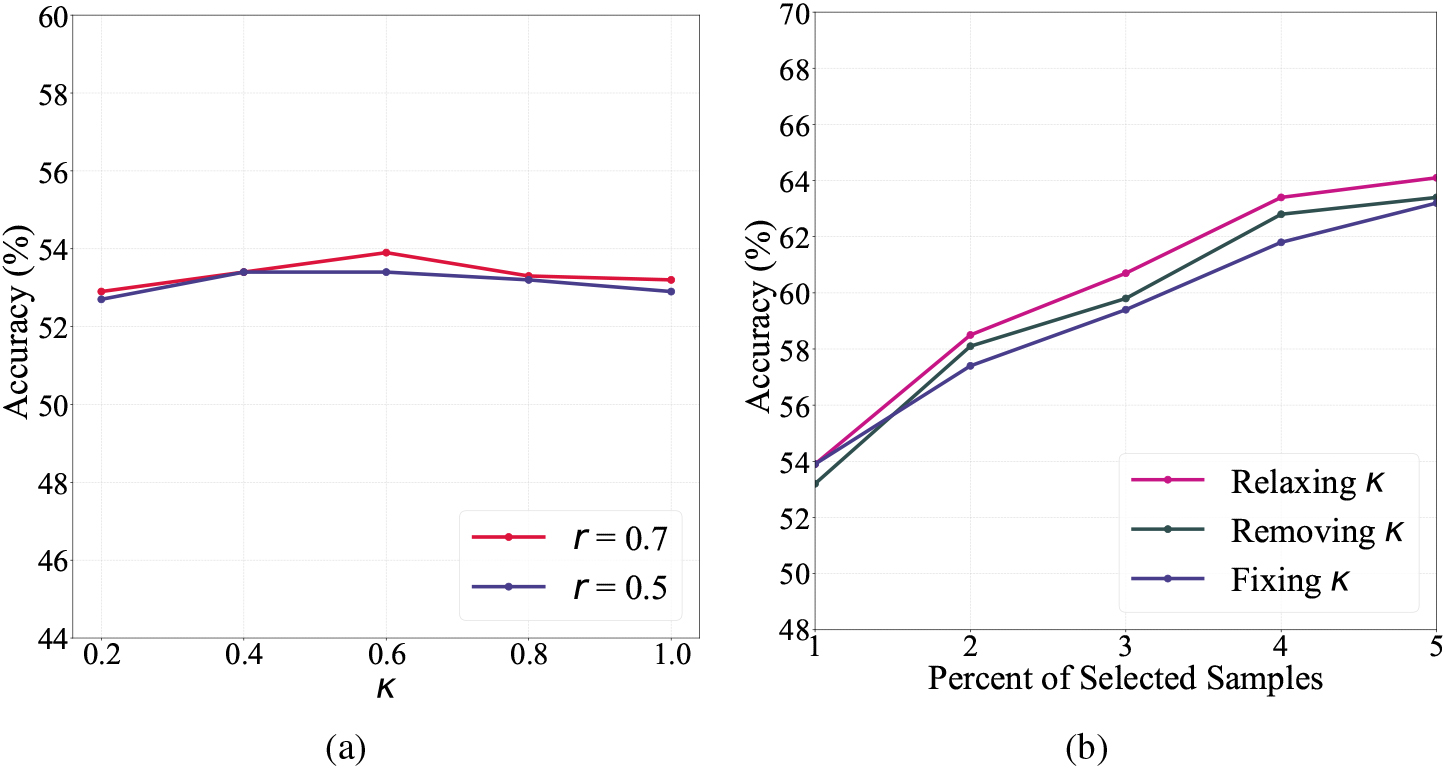
In this subsection, we study the effects of the sample screening mechanism in detail. The key to the mechanism is the values of
Visualization of the feature distribution on the task A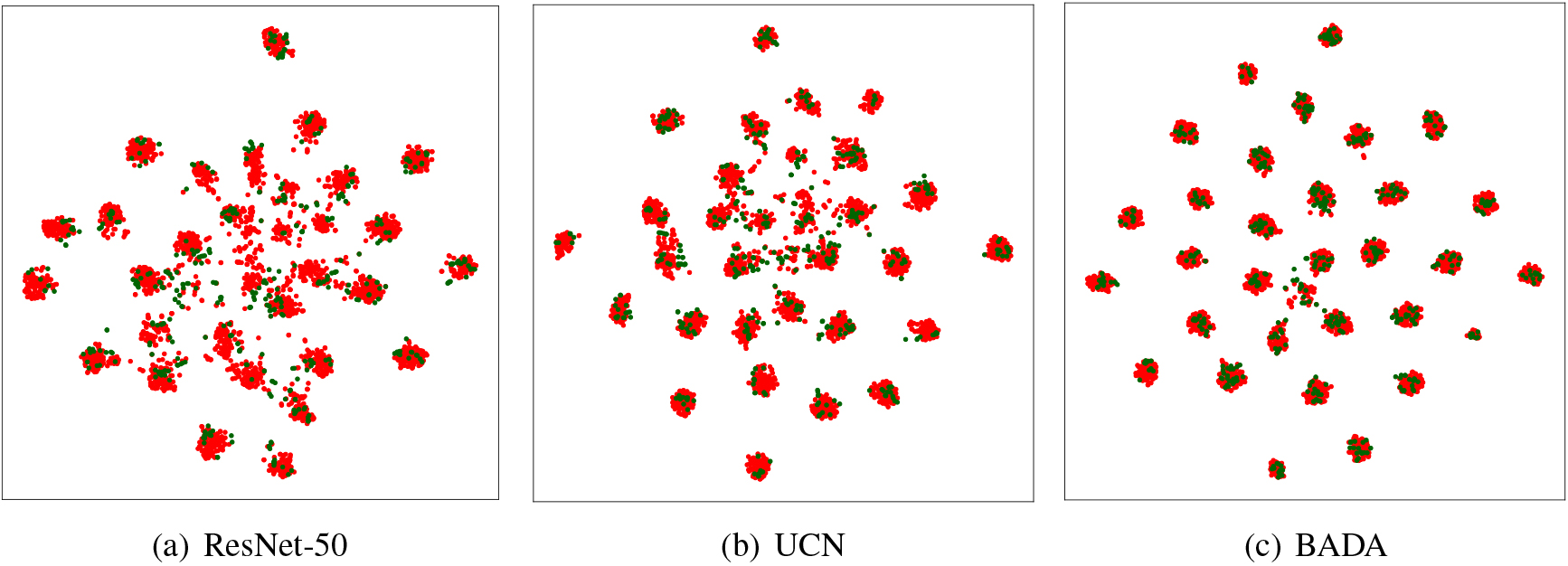
In this subsection, we further use feature visualization to show experimental effects intuitively. Specifically, we perform T-SNE for ResNet-50, UCN and BADA on the task A
Conclusion
In this paper, we introduced a new method named Boosting Active Domain Adaptation with Exploration of Samples (BADA) to solve the problems of Active DA. We proposed comprehensive sample selection criteria considering the instability and the diversity of the sample. Firstly, candidate samples were determined based on CIC, and then the most diverse samples were selected through UDC to overcome the redundancy in sample selection. And we further designed a self-training framework to explore the value of unlabeled samples after sample selection. We adopted the sample screening mechanism to distinguish reliable samples and unreliable samples, and took respective loss functions. Through lots of experiments, we showed that BADA could outperform other state-of-art methods. In the future, we will explore how to extend the proposed method to source free domain adaptation and open-set domain adaptation.
Footnotes
Acknowledgments
This work was supported by the National Natural Science Foundation of China under Grant 62176128, the Open Projects Program of State Key Laboratory for Novel Software Technology of Nanjing University under Grant KFKT2022B06, the Fundamental Research Funds for the Central Universities No. NJ2022028, the Project Funded by the Priority Academic Program Development of Jiangsu Higher Education Institutions (PAPD) fund, as well as the Qing Lan Project.