
Abstract
Due to the multiple types of objects and the uncertainty of their geometric structures and scales in indoor scenes, the position and pose estimation of point clouds of indoor objects by mobile robots has the problems of domain gap, high learning cost, and high computing cost. In this paper, a lightweight 6D pose estimation method is proposed, which decomposes the pose estimation into a viewpoint and the in-plane rotation around the optical axis of the viewpoint, and the improved PointNet
Introduction
For the intelligent mobile robot in an indoor scene, there are many functional requirements, such as grasping [1], obstacle avoidance [2], and virtual reality [3], which are based on the estimation of object pose. However, with the development of mobile robots and 5G technology, robots will transfer data to a central cloud server for data processing. However, this architecture of robot-cloud collaboration will bring some drawbacks. on the one hand, the transmission of a large amount of raw data will bring a huge network pressure, the actual operation will bring non-negligible delay [4]. On the other hand, there are resource constraints on point cloud processing locally, including memory capacity, computing power, and so on, so lightweight neural networks are more suitable for edge computing such as mobile robots.
In order to make the mobile robot recognize the rigid body posture of the indoor scene object, the robot needs to estimate the information from the input data of the point cloud, which includes the relative rotation and relative displacement relative to the camera or a viewpoint. In the 3D space, the two properties usually contain six degrees of freedom and are therefore called 6D pose estimation [5]. In pose estimation, the estimated point cloud is the target domain, while the training point cloud is the source domain. The domain gap is the distance between these domains. Due to the difference in geometry structure and size of indoor objects, the domain gap becomes a problem that can not be ignored in the pose estimation of mobile robots.
In order to solve the above problems, a generalized and lightweight method for pose estimation by point cloud is proposed. The main innovation of this paper is as follows:
An unsupervised learning method is proposed to reduce the problem of domain gap, which is caused by the robot landing on the pose estimation of an indoor object, the pose estimation does not directly use point cloud as input to the network, but decomposed into a viewpoint and in-plane rotation around the optical axis of the viewpoint. In order to reduce the computing cost of mobile robots, a lightweight end-to-end framework is proposed, including a backbone based on improved PointNet In order to reduce the learning cost of the point cloud model of unknown objects, the construction-query codebook method is used to provide the viewpoint prediction basis for the object pose estimation, simultaneously reducing redundant calculations during inference.
Scholars have conducted extensive research on 6D pose estimation of indoor objects. In general, 6D pose estimation typically includes the following types of methods: template matching, feature matching, and Hough voting.
The method of feature matching is to find the features between the input data and the complete 3D point cloud of the existing object, and then recover the 6D position and pose of the object by using the correspondence relation. If the input data is a 2D image, the key point must be found between the image and the point cloud. While the input is a point cloud, the feature must be extracted from the target point cloud, and the model is optimized by reducing the distance of the feature to decrease the loss. It is also suitable to use fused multidimensional information to estimate the pose of severely occluded objects, Chen proposed a hybrid representation method [6], which integrated multidimensional features such as geometric information, key points, and edge vectors to reduce inaccurate representation of raw data, and better performance and accuracy are demonstrated than the methods with single dimensional information. Similarly, Ivan Shugurovt proposed a method that combines a two-dimensional object detector with a dense correspondence estimation network to generate predictions based on views generated by various imaging modalities, postures are refined based on predicted and rendered correspondence [7]. The method of feature matching approach usually has a better solution to the problem of occlusion, Huang proposed a network to learn the corresponding 2D-3D relationship based on the input of RGB info and the camera frustum and performed robust matching of 3D-3D through algorithms, which attenuated the effect of occlusion [8]. These methods are suitable for objects with rich textures or geometric details, but also easily affected by lighting and texture.
For the object with weak texture, the method of template matching is more suitable for pose estimation. This method selects the most similar template from the template with complete 6d pose marking, the pose of the template is regarded as the target posture. Aoki used PointNet as a learnable imaging function and optimized Lucas Kanade algorithm to adapt PointNet, for improving the generalization and efficiency in estimated [9]. Different from traditional methods that use images as pose estimation information, Gao proposed a new idea, in which a point cloud is used as the input of depth information, and a separate network is used to learn the regression of rotation and translation, the network based on axis-angle and was optimized by reducing geodesic loss [10]. Later, in order to deal with the problem of domain gaps, he proposed an automatic encoder that learns the pose information of point clouds as a code, and regression of rotation and translation are inferd through that code [11]. For reducing the impact of occlusion, Hua proposed a pose estimator based on RGBD information, this method adds weights to differentiable outliers to improve the confidence of regression results [12], this type of method performs poorly when facing severe occlusion, especially when the geometric structure of the point cloud is missing, it is hard to obtain stable output results.
The method based on Hough voting is to learn a mapping function to map each point or region of the input data into a voting space, obtain candidate poses from the voting results by the clustering algorithm, and finally select an optimal pose by other methods. Wang proposed a method for pixel-level dense fusion of heterogeneous RGB and depth data, and the pose is estimated from the feature, which achieved high precision [13]. In another way, He designed a network, generating key points for voting by these two modes of information separately, and calculating the posture by the least squares fitting algorithm [14]. In order to fully utilize these two types of information, He conducted sparse fusion on the two streams, while improving the performance and accuracy of pose estimation [15]. This type of method performs well in multi-mode but still suffers from severe occlusion in single-ode.
These methods achieve high accuracy in 6D pose estimation but do not demonstrate the ability of domain adaptation. The networks of these methods mostly need to be optimized for a single model in the training dataset, which will result in a significant decrease in accuracy when facing objects that have not been optimized. This is unsuitable for the indoor environment’s complex and ever-changing objects. When mobile robots require estimating more pose of the objects, they need to be retrained, which undoubtedly brings expensive learning costs, including time and computational costs.
In reverse engineering, the Point Cloud is a collection of point data on the surface of an object obtained by measuring instruments. Due to its disorder, discreteness, and non-structure, the feature extraction of the point cloud is a challenge. PointNet pioneered the deep learning of the point cloud, which utilized MLP to ascending dimension the feature and a Max pooling layer to extract global information of the point cloud [16], followed by PointNet
To address the problem of domain gap, Cai proposed OVE6D [21] this method designed a viewpoint encoder that completes pose estimation of unseen objects using synthetic data via depth maps. Inspired by OVE6D, this paper proposes a method of pose estimation that is suitable for indoor scenes constructed by point cloud, the pose of an object is decomposed into a virtual viewpoint relative to the model and rotation in the plane around the optical axis of the viewpoint. Different from the previous methods, This method does not directly focus on the pose regression of objects directly but takes the above-mentioned decomposition task as the target, and adapts to different objects’ pose estimation in an unsupervised learning way.
Method
The method in this paper belongs to the types of template matching. For the pose estimation of the point clouds of indoor objects, a pre-split mask must be provided, and the model infers the rigid transformation from the standard model to the target model, and this can be represented by a rotation matrix R and a displacement vector t.
The method consists of three stages: During the training, the ShapeNet V2 dataset is used to train the model and calculate a mapping relationship between a random viewpoint and the object’s complete point cloud, which is represented as a mask of the object’s point cloud, the paper calls it the map of the viewpoint. Before the inference, the point cloud of the training dataset is standardized first and then generates a uniform spherical of viewpoints, the maps of each viewpoint are calculated and coded, and stored as a codebook file. In the inference stage, the map of viewpoint calculated from the target object relative to the virtual camera is encoded, and the encoding is compared with the codebook to deduce the candidate viewpoints and the rotation matrixes in the plane of the optical axis around the viewpoints. Finally, the best matching template is calculated from the information.
The inference process of pose estimation.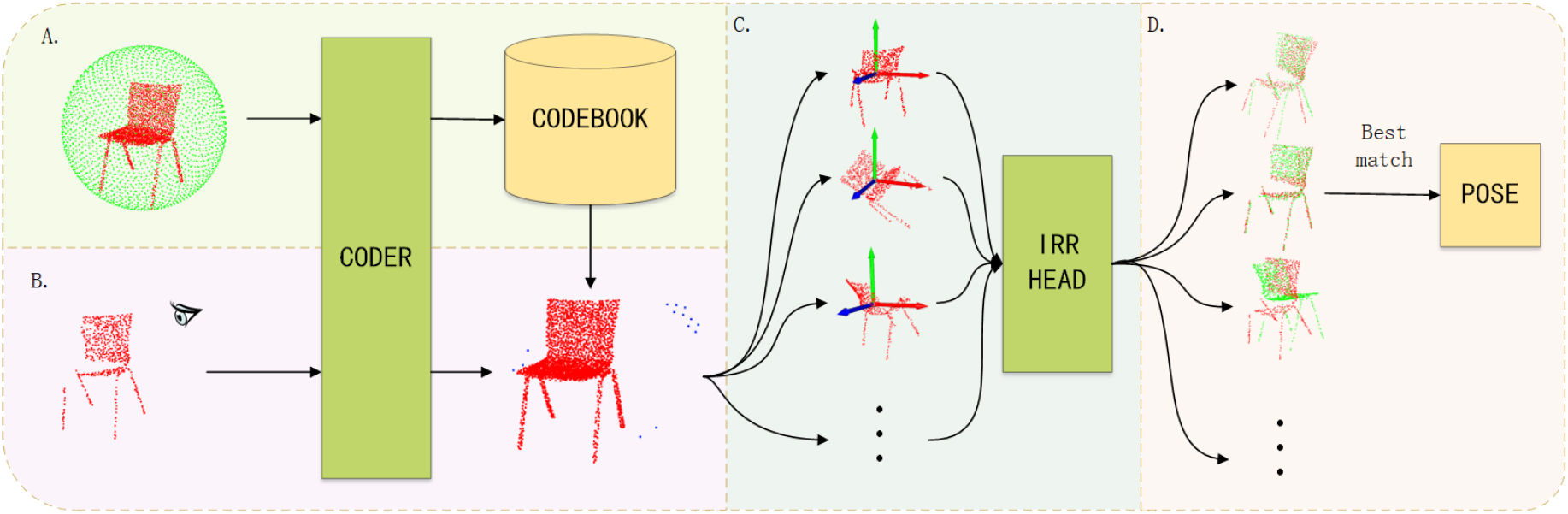
As shown in Fig. 1, the inference process for pose estimation consists of four steps, step A, encodes the point cloud of a standard object and generates 2,100 uniform views on a sphere through a Fibonacci grid, the map of each viewpoint is calculated, and encoded by the encoder, and the information including encoding code, Standard Model, scaling factor and so on are saved as a codebook file. Step B indicates that in inference, the point cloud visible to the observation viewpoint is encoded by the encoder, and the cosine similarity function is used to compare the cosine similarity between the modified code and the codebook, and several candidate viewpoints are calculated, the candidate viewpoints are shown in the diagram as blue points. In Step C, the map of the candidate viewpoint and the map of the observation viewpoint are almost the same as each other except for a rotation around the optical axis of the observation viewpoint, predicted the rotations and computed to get the map of the candidate viewpoints. Step D generates the kd-trees from the map of candidate viewpoints, and matches the 32 points of interest extracted from the backbone in step B with the kd-tree. The viewpoint with the least distance loss is the target viewpoint, the pose can be calculated from the viewpoint and the rotation matrix of the optical axis around the viewpoint.
After pre-processing the ShapeNetV2 training data set, the surface point cloud of the indoor objects is obtained. The pose estimation method needs to extract features from the point cloud and carry out unsupervised learning. The network model consists of a backbone network and two lightweight heads, the functions of viewpoint selection and point cloud rotation are accomplished respectively.
The structure of network.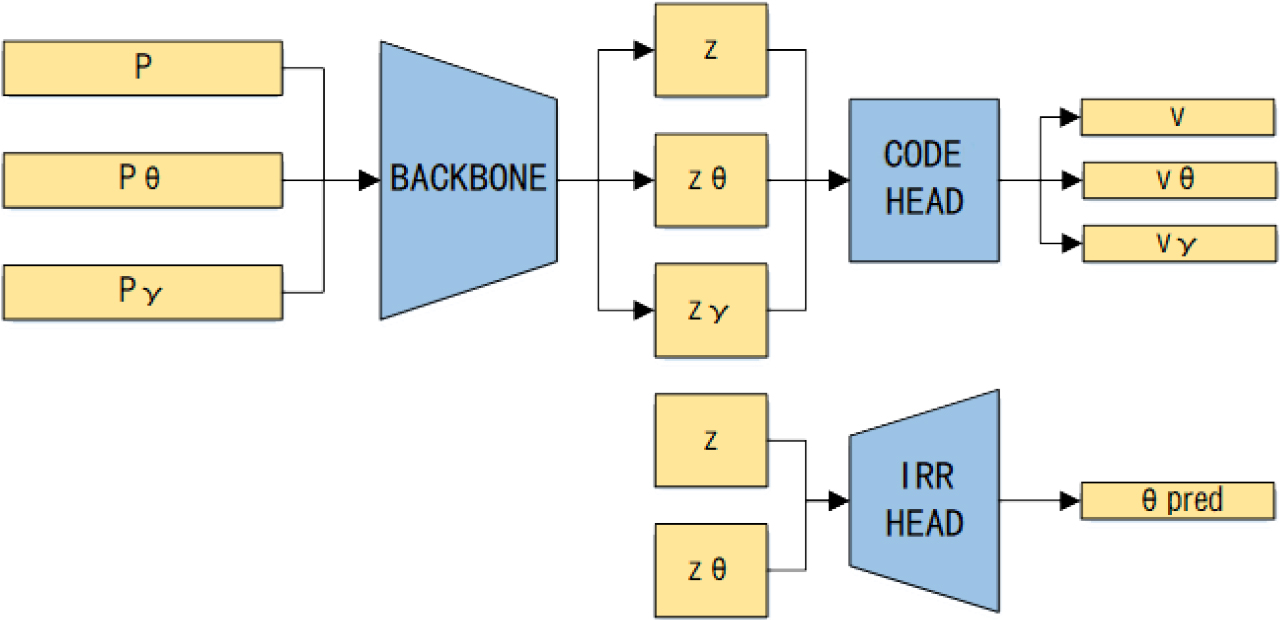
The Fig. 2 shows the structure of the whole network, the triplet map of three viewpoints {
For extracting features, as shown in part A of Fig. 3, a network structure based on PointNet
Models of the network.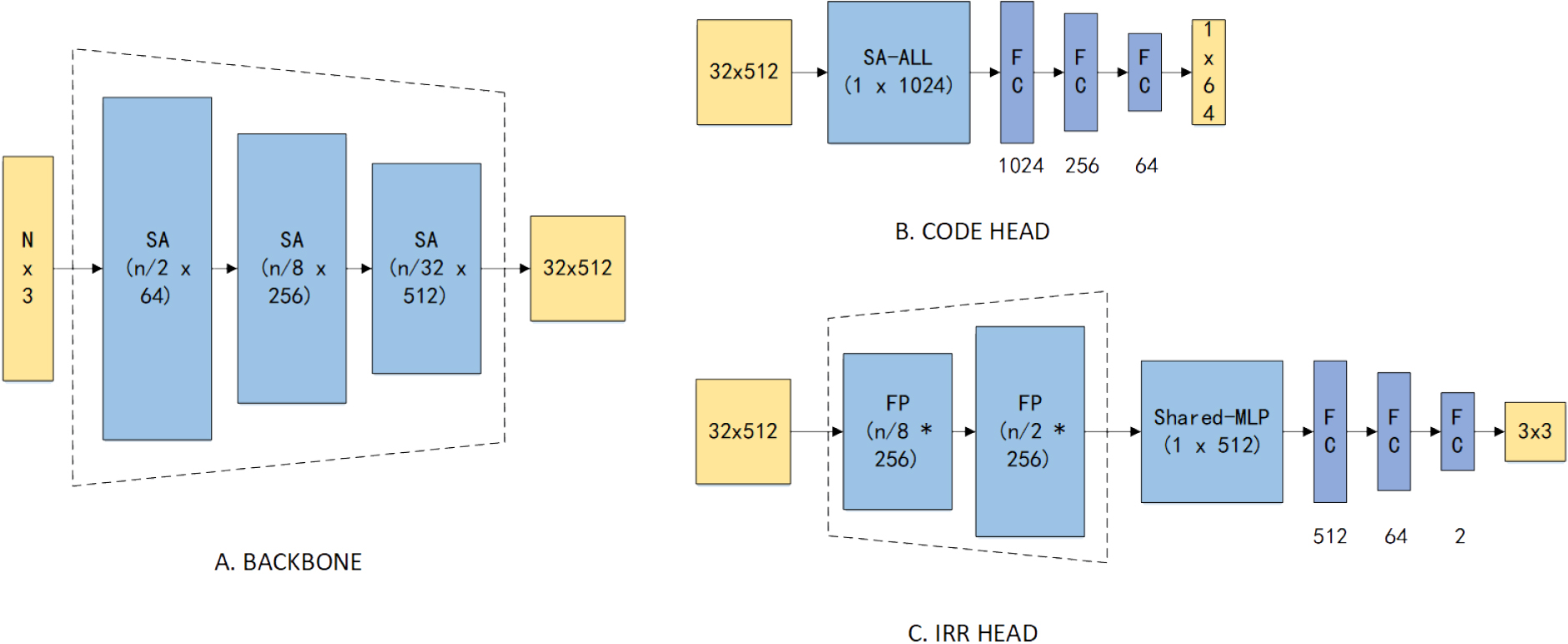
In the training stage, for completing the unsupervised learning of the follow-up Code Head and IRR Head, it is necessary to generate different maps of viewpoints for the point cloud of an object. For this purpose, a number of random viewpoints are generated, and the corresponding triplet maps {
The objective of the Code Head is to be insensitive to the in-plane rotation of a viewpoint and sensitive to the selection of viewpoints, coding needs to extract lower-dimensional features that are suitable to store according to the global features of the map. As shown in part B of Fig. 3, the encoder is designed as an SA-ALL layer and three FC layers, The SA-ALL module is for extracting global features from the backbone. After coding, the triplet code {
In order to achieve the goal that the head is sensitive to different viewpoints and insensitive to the rotation of maps from the same viewpoint, the optimization of the coding head is described as
In Eq. (1), the margin is the sort remainder, which represents the degree of gap between the codes of views that rotate around the optical axis plane of a viewpoint and the codes of the maps from different viewpoints. Due to the preset viewpoints in the codebook being discrete points, a margin is needed to control the ability of the generalization in the map selection. The paper set the margin to 0.1.
The aggregated features extracted through the backbone network have basically described the global structure of the maps, in order to obtain the rotation angle
The goal of the IRR head is to deduce a theta matrix, making the map best coincide with the target map by rotating the theta angle around the optical axis of the viewpoint, the degree of these two point clouds overlap can also be described by cosine distance, then the loss is defined as follows:
Among them,
The model is trained on the ShapeNetV2 data set [23], and two experiments are designed to verify the validity of the method in solving the problem of domain gap and the accuracy in pose estimation. First, estimate the pose of indoor objects from ModelNet40 dataset [24] with random translation and rotation. Second, compared the effectiveness of pose estimation with other methods on public datasets YCB-Video [25] and Line-MOD [26].
Training dataset preprocessing
Due to the fact that the point cloud data of indoor objects contains data that comes from the surface of an object, and the models provided by the ShapeNetV2 dataset are composed of composite mesh models, in order to meet the requirements of input for training, it is necessary to perform surface point cloud sampling on the composite model through reverse engineering.
[t] Algorithm of surface Point Cloud samplingPointcloud of an object P: Nx3 Pointcloud after mask
sample_number
threshold
z_axis
z_viewpoint
masks
i in sample_number v
R
vecs
mask
point p in
Add
kdtree
vec
ps
max_i, max_z
Add max_i in mask
Remove ps from p Except max_z – ps.z
i
Firstly, the PCL Library of C
Introduction to validation datasets
The YCB-Video dataset consists of 21 objects selected from the YCB dataset, including the real scene and the rendered scene. In the real scene, each scene was made up of 3–9 objects and shot with the RGBD camera. 92 Videos were made, containing a total of 133,827 frames. The scene was rendered using BlenderProc4BOP, and the composite image and pose annotation were automatically generated, including 21 images of objects in different backgrounds, lighting, and viewing angles, with a total of 80000 images.
The LineMOD dataset contains 15 non-textured or low-textured household items, with each object containing a test image set. Each image set displays instances of objects with a large amount of debris and slight occlusion.
Verification standard
The common metrological standards for 6D pose estimation of point cloud are ADD and ADD-s, which are used to evaluate the matching degree of point clouds of symmetric and asymmetric objects respectively. The formulas are as follows:
Where
The experimental environment is ACER B36H4-AM2 (DCH), with i5-9500 as CPU and NVIDIA RTX 2080 super as GPU, and the OS is Ubuntu18.04. The model is trained on high-performance cloud servers through the preprocessed training dataset, including 45,645 point clouds of the objects. Before validation, the codebook needs to be generated, the codebook of each object is calculated for about 400 seconds and occupies space of about 9.3 Mb.
First, 100 models are selected from the ModelNet40 dataset, and the rotation of [0–2
Visualization of ModelNet40.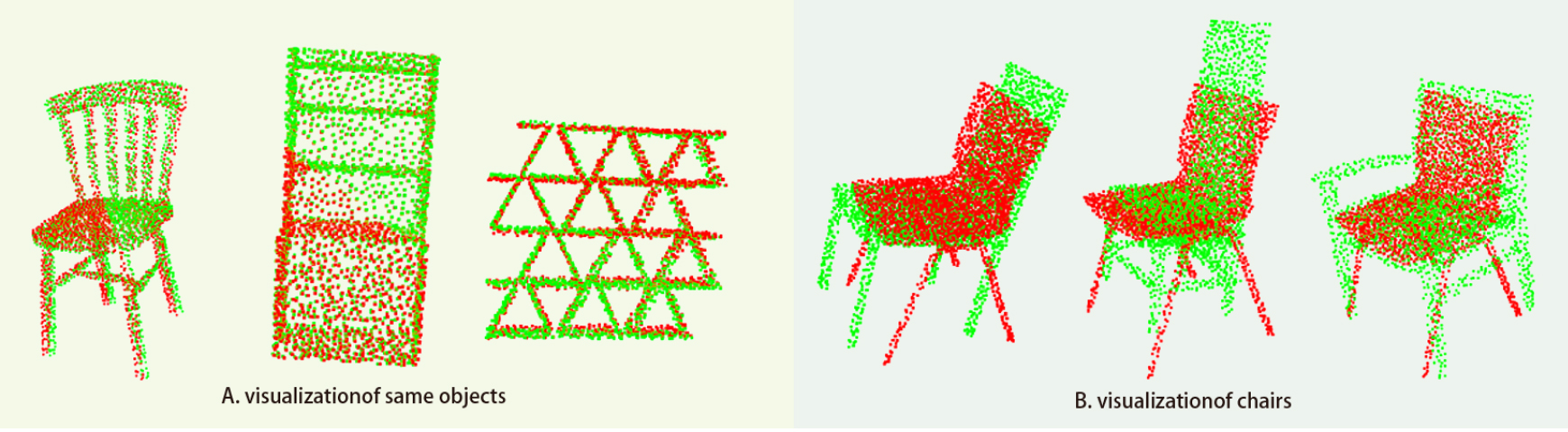
As shown in Fig. 4, with the target point cloud in red and the predicted point cloud in green, Group A represents the pose estimates of objects selected in the ModelNet40 dataset without optimization by the ICP algorithm, the indices of ADD and ADD-s are 81.1% and 99.9% respectively, which indicates that this method has low prediction accuracy for symmetric objects and high prediction accuracy for asymmetric objects. Group B shows strong generalization for the same type of object without optimization using the ICP algorithm, with an ADD-S score of 86.4%.
To demonstrate the encoder’s sensitivity to viewpoint selection, an aircraft model is encoded and a random viewpoint is generated, then visualize the recommended candidate viewpoints for the aircraft model by the Code Head.
Visualization of viewpoint selection.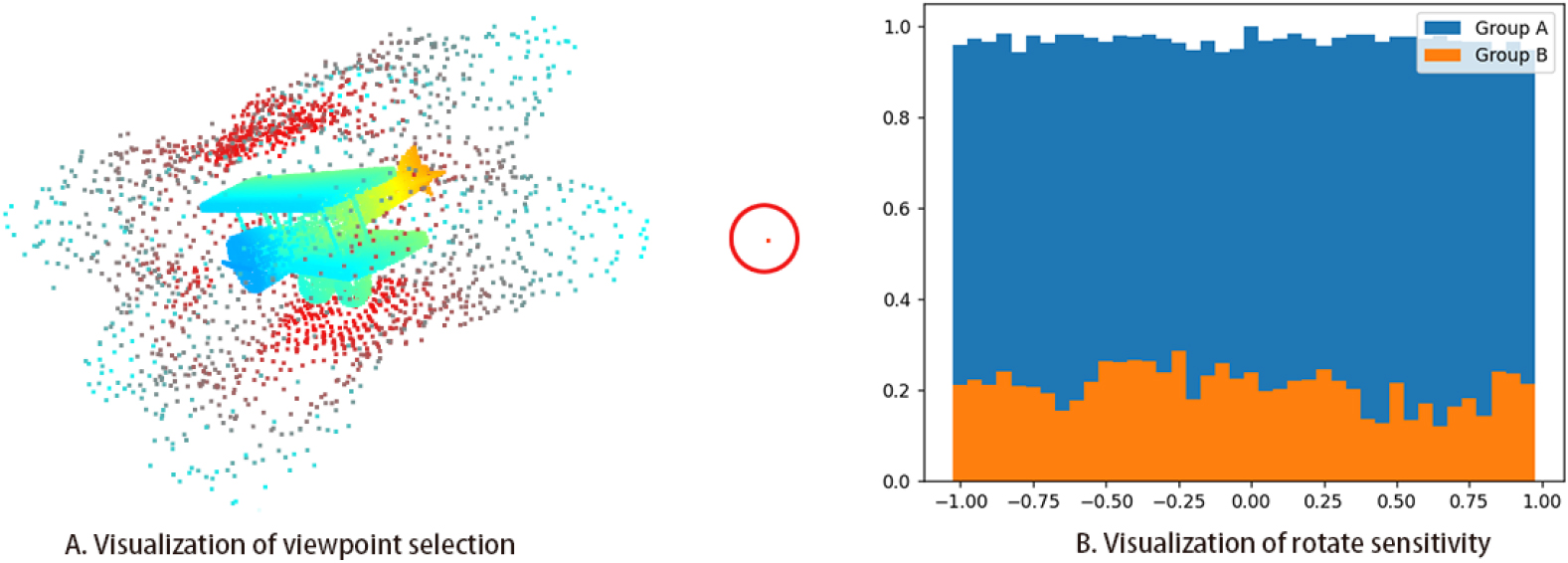
The visualization results are shown in part A of Fig. 5. The red circle marked is the virtual viewpoint. The higher the probability, the farther the point is from the center, the color shows more blue, and vice versa, the closer the point is to the center, demonstrates more red. The results show that the encoder can display the probability distribution of the viewpoint correctly. At the same time, there is also a high probability distribution in the symmetric part, indicating that the encoder has low robustness to object symmetry.
At the same time, the maps of the two viewpoints were rotated with a step size of 0.5 times [
As shown in part B of Fig. 5, group A is the cosine similarity of maps that rotated around the optical axis of the same viewpoint, and group B is the cosine similarity of the maps of other viewpoints and the map in group A. The figure shows that the coding of the maps from the same viewpoint does not show a large gap but in different viewpoints.
In another experiment, the paper validated the trained model on untrained pose estimation datasets, including YCB-Video and LineMOD, which included both synthetic and real data, the pose estimation is challenging due to low texture, severe occlusion, and incomplete point cloud. Partial visualization results are shown in Fig. 6.
ADD-S of YCB-video dataset
Table 1 shows the ADD-S metrics for real data and composite data in the YCB-Video data set. The key frame data of the validation set in the real scene, and the composite data selects a partial training set as the validation set, the method with * is the result of the evaluation after the use of ICP algorithm modification. The experimental results show that, at the threshold of 0.1 times diameter, even without the optimization of the ICP algorithm, the prediction accuracy of the proposed method is slightly lower than the current advanced methods.
ADD-S of LineMOD dataset
Lightweight of models comparison
Visualization of pose estimates on YCB-Video data set.
Table 2 shows the ADD-S metrics for the LineMOD dataset, using a composite model to validate the real-scene training set as a validation set. Since the Point Cloud in the LINEMOD dataset is more severely fragmented, the method of this paper is slightly inferior to the mainstream method after being optimized by the ICP algorithm at the threshold of 0.1 times diameter. in particular, CloudAAE and FFB6D are validated on this dataset using models that have not been trained on these objects, the resulting ADD-S metric is 0.
In order to verify how the light weight of the model, the number of parameters, the time spent in finishing a pose estimation, and the cost of computing resources are compared in the above experimental platform.
Table 3 shows the result of the comparison of the methods including DenseFusion, PVN3D, FFB6D, and the methods in this paper. First, the parameter quantity of the model was compared using the method provided by Pytorch, and the parameter quantity of the model in this paper is much lower than other methods. The second is time spent in pose estimating, only calculating the time from point cloud input to completion of pose estimation. The methods used in the paper are faster than other methods. Finally, for the consumption of computing resources, GPU memory was detected, because the memory consumption of the method depends on the number of recommended viewpoints, the usage of graphics memory is only slightly lower than other methods with 16 recommended viewpoints.
The experimental results show that the model can accurately estimate the 6d position and pose of the object point cloud for the unseen model, the accuracy on average is slightly lower than other models trained for objects, but the model is more lightweight, and the input only requires no texture point cloud, which is suitable for landing in the mobile robots.
The article proposes a lightweight pose estimation method for indoor point cloud objects. A viewpoint encoder can be used to accurately estimate the 6D pose of known or approximate object point cloud targets by building a codebook from untextured point cloud data. The entire process is low-cost in both the computing unit and hardware storage unit, and it demonstrates strong generalization ability. Only a codebook needs to be constructed when learning the ability to estimate the pose of a new object, which takes much less time than model training. It allows for more flexible deployment of target pose estimation systems in mobile robot applications. At present, there are still some deficiencies in the framework. When constructing a codebook, due to the sequence in calculating the map of a viewpoint, the algorithm can only run on the CPU, resulting in a longer construction time for the codebook. In addition, before inference, it is necessary to first obtain the segmented point cloud, or a mask for the object, it relies on other tasks such as target detection and even semantic segmentation.
Footnotes
Acknowledgments
This work was supported by the National Key Research and Development Project of China Grant Number 2022YFC3601400.