
Abstract
This paper proposes a data clustering algorithm that is inspired by the prominent convergence property of the Projection onto Convex Sets (POCS) method, termed the POCS-based clustering algorithm. For disjoint convex sets, the form of simultaneous projections of the POCS method can result in a minimum mean square error solution. Relying on this important property, the proposed POCS-based clustering algorithm treats each data point as a convex set and simultaneously projects the cluster prototypes onto respective member data points, the projections are convexly combined via adaptive weight values in order to minimize a predefined objective function for data clustering purposes. The performance of the proposed POCS-based clustering algorithm has been verified through a large scale of experiments and data sets. The experimental results have shown that the proposed POCS-based algorithm is competitive in terms of both effectiveness and efficiency against some of the prevailing clustering approaches such as the K-Means/K-Means
Introduction
Cluster analysis or clustering is a kind of unsupervised learning task that aims to categorize similar data points while separating them from dissimilar ones without any prior knowledge. There exist numerous types of clustering approaches, each method is best suited to a particular distribution of data, thus it is very difficult to introduce a thorough list of all the clustering algorithms because of the variation of information, the research fields, and the rapid development of modern technology [1]. Though there exists a great number of approaches to clustering, there are three most popularly used categories including partitional, density-based, and hierarchical methods [2]. Among them, the simplest form of clustering is partitional clustering [3, 4, 5, 6, 7, 8] which considers the clustering error (sum of the distances from all cluster centers to their corresponding data members) as the main criterion to be optimized.
One of the most popular partitional methods is the K-Means algorithm [9] which has been widely applied to numerous general applications due to its simplicity and efficiency [10]. The K-Means clustering algorithm alternates between assigning cluster membership for each data point to the nearest cluster center and updating the center of each cluster. The objective of the algorithm is to find a set of prototypes that minimize the clustering error and the algorithm converges when there is no further change in the assignment of instances to clusters [9]. The convergence quality of the K-Means clustering algorithm heavily depends on the initial prototypes. Besides, this algorithm is not guaranteed to find the optimum and is known to be sensitive to noise and outliers [11]. In order to overcome the drawbacks of the naïve K-Means, Arthur and Vassilvitskii introduced the K-Means
Another well-known clustering method in the partitional category is the Fuzzy C-Means (FCM) algorithm. In the FCM algorithm, a data point can belong to multiple subgroups, and the certainty degree for that data point belonging to a certain cluster is represented by a membership function. The performance of the FCM algorithm is also highly dependent on the initialization of prototypes and the initial membership value [13]. In addition, the drawbacks of the FCM algorithm include extended computational time and incapability in handling noisy data and outliers [14]. In order to overcome the FCM algorithm’s shortcomings, the Gradient-based Fuzzy C-Means (GBFCM) algorithm was introduced by Park and Dagher [15] in which the minimization process of the objective function is proceeded by solving two equations alternatingly in an iterative fashion.
On the other extreme, Projection onto Convex Sets (POCS) is a powerful method of finding the common point of convex sets in several convex programming problems which was introduced in the mid-1960s [16, 17]. The main goal of the POCS approach is to find a vector that resides in the intersection of convex sets. It has been shown that successive projections between two or more convex sets with non-empty intersections converge to a point that exists in the intersection of the sets [16]. If the sets are disjoint, the sequential projections converge to greedy limit cycles which are dependent on the order of the projections [18]. This implies that the projections keep “greedily” moving towards the sets and can be stuck in a cycle that involves projection points bouncing between the boundaries of the sets without ever converging to a specific location. POCS has been applied to solve various problems including communication systems [19], super-resolution [20], embedding analysis [21], and tomography [22]. POCS can also be applied to point-matching problems to determine the correspondence between two sets of points extracted from different images. Lian et al. [23] proposed a clustering successive POCS (SPOCS) algorithm for a fast point-matching problem. The algorithm utilizes SPOCS for enforcing a two-way constraint. The concept of clustering is used to decrease the computational load of the SPOCS technique. The algorithm can reduce computational complexity with an insignificant decline in precision.
In this paper, we present a novel clustering algorithm using the convergence property of POCS. The proposed POCS-based clustering algorithm considers each data point as a convex set and all the data points in a data set as disjoint convex sets, then performs projections from the cluster prototypes onto each of their respective constituent instances in order to update the membership of data and compute a new set of prototypes. At the beginning, a careful seeding method is applied to initialize cluster prototypes, and each data point is then assigned to its nearest cluster. The process of simultaneously projecting the cluster prototypes onto corresponding member data points is repeated until the convergence criterion is satisfied and the final clusters are found. Part of this research was presented in [24] where the basic idea and the preliminary experiments were introduced.
The remainder of this paper is structured as follows. In Section 2, a brief review of the POCS concepts and notations is presented. The POCS-based clustering algorithm is proposed in Section 3. Section 4 provides extensive experiments and assessments on a wide range of applications and datasets in order to verify the validity of the proposed POCS-based clustering algorithm. Section 5 concludes this paper.
Preliminaries
The theory of convex set and function has a rich history and has been a focus of research as it has been one of the most powerful tools in the theory of optimization [25, 26, 27]. This work proposes to use the concepts of convex set and POCS theory for data analysis and clustering problems.
Convex set
A convex set is a collection of vectors (data) having the following property: given a non-empty set
and thus
The concept of projection of a point onto a plane deals with minimization problems, which is to find a point on the plane that is closest to the center of the projection. Given a vector
such that the distance between
If
Alternating projections between two (or more) convex sets with non-empty intersections converge to a point that falls within the intersection of the convex sets [16]. This prominent property of alternating POCS can be applied to solve many tasks which can be described under the convex optimization problems. Given
where
Alternating POCS: (a) The successive projections converge to a point that belongs to the intersection of the sets for intersecting convex sets, while (b) they converge to greedy limit cycles that depend on the order of projections for disjoint convex sets.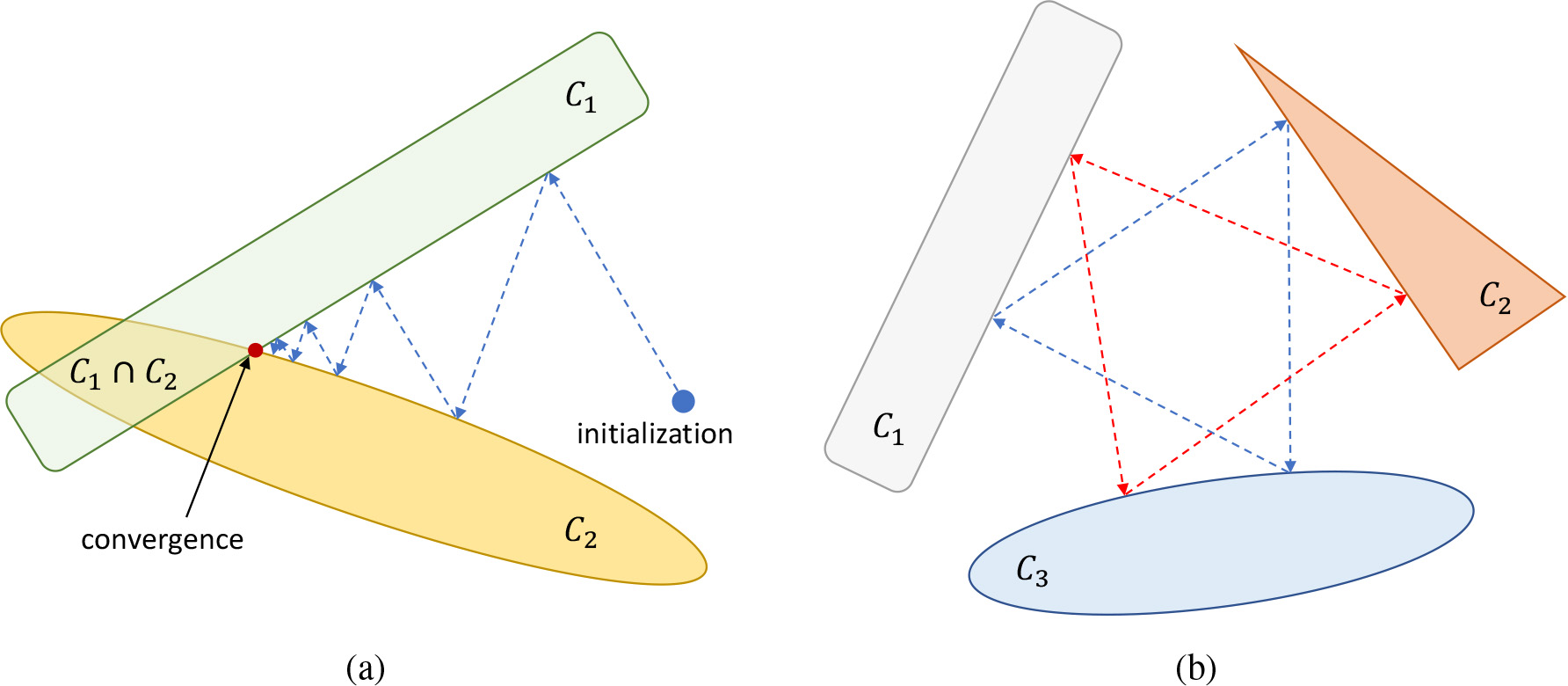
Note that the intersection is also convex. A graphical illustration of the alternating projections onto intersecting convex sets is given in Fig. 1a.
On the other hand, when the convex sets are disjoint, the sequential projections do not converge to a single point. Instead, they converge to greedy limit cycles which are dependent on the order of the projections. Especially, in the case of only two non-intersecting convex sets, the projections converge to a greedy limit cycle between two points (one for each set) that are closest in the distance sense [29]. Figure 1b depicts an illustration of alternating projections on three disjoint convex sets.
The parallel mode of POCS sometimes is referred to as simultaneous weighted projections [18]. Given an initial point and
All the projections in each iteration are convexly combined to find a minimum mean square error solution which can be applied to solve many minimization problems. The updated data point after one iteration of parallel projections can be expressed as:
where
Parallel POCS: (a) The simultaneous projections converge to a point that belongs to the intersection of the sets for intersecting convex sets, whereas (b) they converge to a minimum mean square error solution for disjoint convex sets.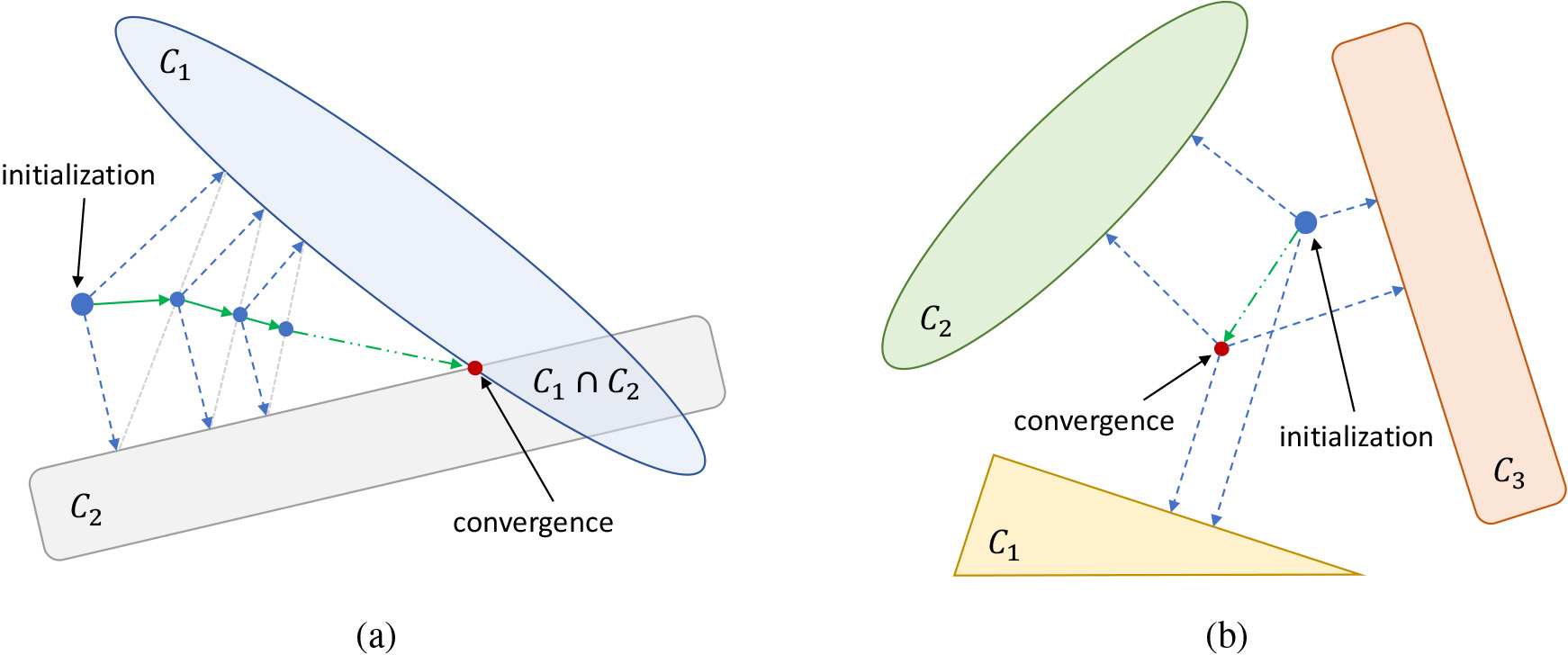
If the sets are disjoint convex sets, the parallel projections after some iterations will converge to a minimum mean square error solution which is written as:
with a constraint as in Eq. (6). A graphical interpretation of the convergence process of the parallel POCS method is illustrated in Fig. 2b.
As discussed in Section 2, the iterative projections (for both alternating and parallel forms) of a random data point onto closed and intersecting convex sets converge to a point that resides on the intersection of the sets. For disjoint convex sets, the alternating POCS converges to greedy limit cycles which are dependent on the order of projections. Alternatively, the parallel mode of projection converges to a point that minimizes the weighted sum of the distances from the point to the sets. The parallel form of POCS performs the projections simultaneously, this property can improve the computational efficiency when compared with that of the alternating version. Relying on the prominent properties of the parallel form of POCS, in this section, we devise the POCS-based clustering algorithm.
Following the definition of the convex set presented in Section 2.1, an empty set
Proof..
For any
Cluster prototype initialization is a vastly important procedure that directly affects clustering performance. Beginning with arbitrary prototypes which are typically chosen uniformly at random from the data points has been widely applied due to its positive effects on empirical speed and simplicity. However, this prototype initialization method comes at the price of unstable clustering accuracy [9]. In order to handle the issues of the random seeding technique, a careful seeding procedure can be adopted to improve accuracy while assuring execution speed [12]. To this end, we adopt a careful prototype initialization procedure which is described as follows: the first prototype is chosen as the data point which is closest to the center of the whole dataset, then each of the next prototypes is chosen successively among the rest of data points based on a weighted probability, called D2 weighting [12], that is proportional to the squared distances from the data points to their respective nearest prototypes that have been chosen earlier.
Consequently, we can devise the POCS-based clustering algorithm as follows: Given a set of data points and a parameter
and:
where
can be satisfied as described in Eq. (6).
Algorithm 1 shows the pseudocode of the proposed POCS-based clustering algorithm which includes three main steps. In the first step, the algorithm initializes cluster prototypes by applying a careful prototype initializing method. In the second step, each data point is assigned to the nearest prototype. In the last step, for each cluster, the algorithm performs simultaneous projections and computes new cluster prototypes using the following equation:
where
The clustering problem we are dealing with is to solve the optimization problem for the objective function given by Eq. (9). That is, starting from a set of initial prototypes:
the algorithm converges to a set of optimized prototypes which minimizes the weighted sum of the distances from the prototypes to their corresponding member points:
In order to provide a comprehensive evaluation, we have compared the performance of the proposed POCS-based algorithm against those of other prevailing methods including the K-Means, K-Means
Evaluation on synthetic 2-D data sets
Details of the 2-D synthetic datasets
Details of the 2-D synthetic datasets
Assessments of clustering results on 2-D space allow observers to easily evaluate visual clustering solutions produced by different clustering algorithms. To this end, experiments to examine the performances of the proposed POCS-based clustering algorithm on six synthetic 2-D data sets including A1, A2, Aggregation, R15, S1, and S2 were conducted [30]. The specifications of these data sets are summarized in Table 1.
Figures 3–8 illustrate typical clustering results produced by different methods in 2-D plots. The found cluster centroids are marked out in red color and located in the vicinity of the center of each data group.
Visual clustering results of various clustering methods on A1 dataset (red points denote cluster centroids): (a) FCM, (b) K-Means, (c) K-Means
Visual clustering results of various clustering methods on A2 dataset (red points denote cluster centroids): (a) FCM, (b) K-Means, (c) K-Means
Visual clustering results of various clustering methods on Aggregation dataset (red points denote cluster centroids): (a) FCM, (b) K-Means, (c) K-Means
Visual clustering results of various clustering methods on R15 dataset (red points denote cluster centroids): (a) FCM, (b) K-Means, (c) K-Means
Visual clustering results of various clustering methods on S1 dataset (red points denote cluster centroids): (a) FCM, (b) K-Means, (c) K-Means
Visual clustering results of various clustering methods on S2 dataset (red points denote cluster centroids): (a) FCM, (b) K-Means, (c) K-Means
Figures 3 and 4 show the representative visual clustering results of the algorithms under consideration on the A1 and A2 datasets. Both A1 and A2 datasets contain 2-D data points that form 20 and 35 clusters, respectively. The numbers of data points for the A1 and A2 datasets are 3,000 and 5,250, respectively. As shown in Figs 3 and 4, the cluster memberships and prototypes vary for different algorithms. Despite the mild overlapping among the clusters, all the algorithms under consideration were able to identify most of the clusters. Different from the A1 and A2 datasets, the Aggregation dataset shown in Fig. 5 has 7 clusters with a total of 788 instances distributed in different densities. As the outcomes shown in Fig. 5, the FCM, K-Means
Execution time of different algorithms on various datasets (sec.)
In addition, execution time and clustering error were adopted as comparison metrics to quantitatively assess the performance of each algorithm. On every dataset, each algorithm was executed 10 times and the mean values of convergence speed and clustering error are presented. Table 2 summarizes the measurements of the average convergence time of different algorithms on various synthetic 2-D data sets. Based on the results shown in Table 2, the convergence speed of the POCS-based algorithm can be competitively compared with those of the K-Means/K-Means
where
Typical convergence processes of various clustering methods on the 2-D synthetic datasets: (a) A1, (b) A2, (c) Aggregation, (d) R15, (e) S1, and (f) S2.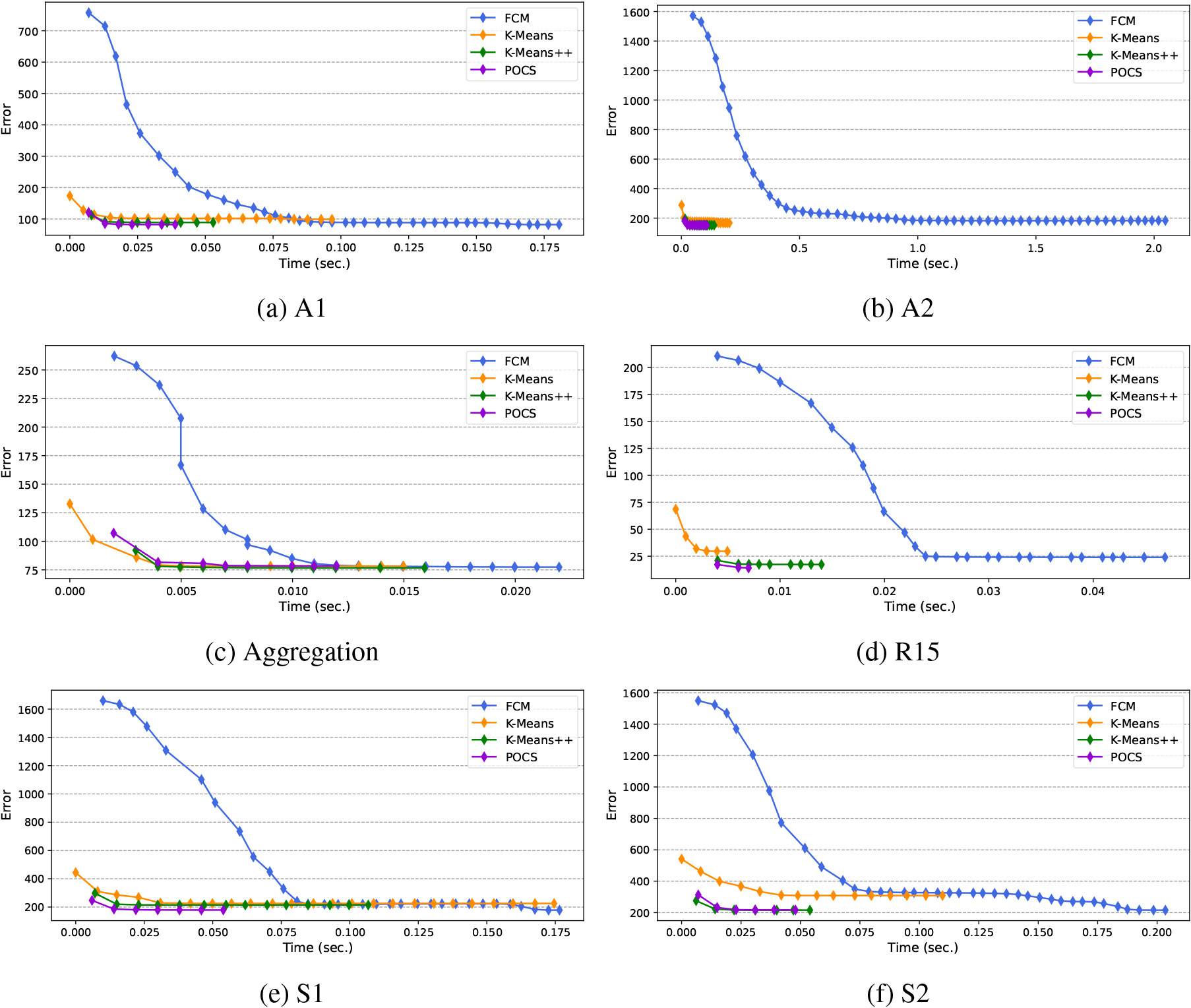
Comparison of various clustering methods in terms of clustering error on the synthetic 2-D datasets.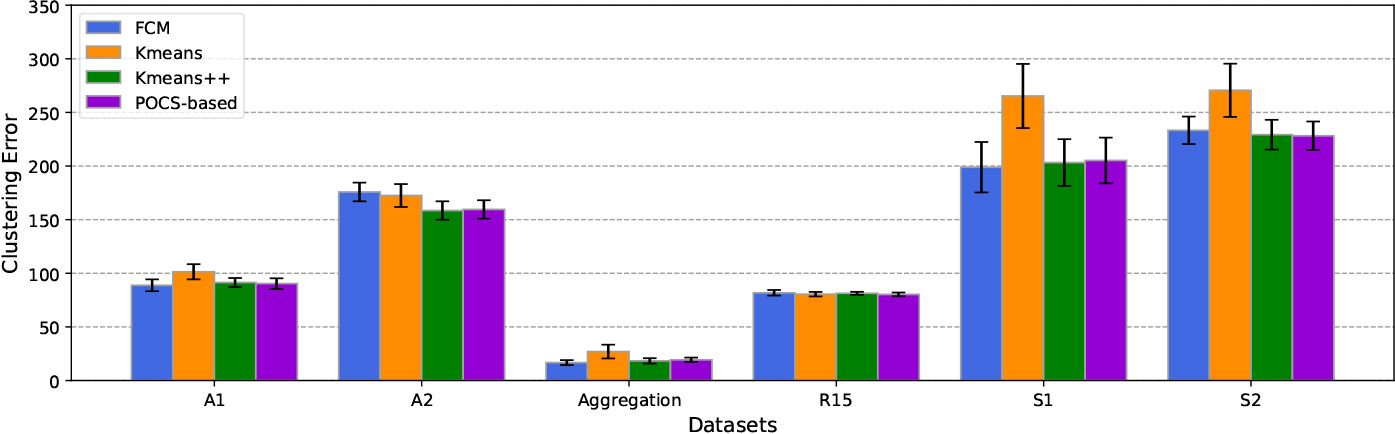
Details of the UCI benchmark datasets
Details of the UCI benchmark datasets
In this section, experiments on 11 benchmark data sets with up to 1,024 attributes have been conducted so as to investigate the performance of the proposed POCS-based clustering algorithm on clustering tasks with high-dimensional data. The data sets were selected from the UCI dataset repository, including Iris, Breast-cancer-Wisconsin (BCW), Seeds, Ionosphere (Ionos), Sonar, Wine, Glass, Ecoli, Parkinson’s Disease (PD), QSAR Androgen Receptor (QSAR), and King-Rook vs. King-Pawn (Chess) [31]. A pre-defined number of clusters is also given for each data set. The specifications of the selected benchmark data sets are presented in Table 3. The performances of the algorithms under consideration were compared based on various standard metrics including Accuracy, Precision, Recall, and
where TP, TN, FP, FN represent true positive, true negative, false positive, and false negative, respectively. Despite the fact that clustering is an unsupervised learning task, the classes can be retrieved when the label information of input data is given. To this end, we determine the class of a cluster by adopting the confusion matrix method [32]. Each algorithm was executed 10 times on each data set and the measurement values were averaged to present the final results.
Comparisons of various methods in terms of accuracy, precision, recall, and F1 Score on high-dimensional datasets.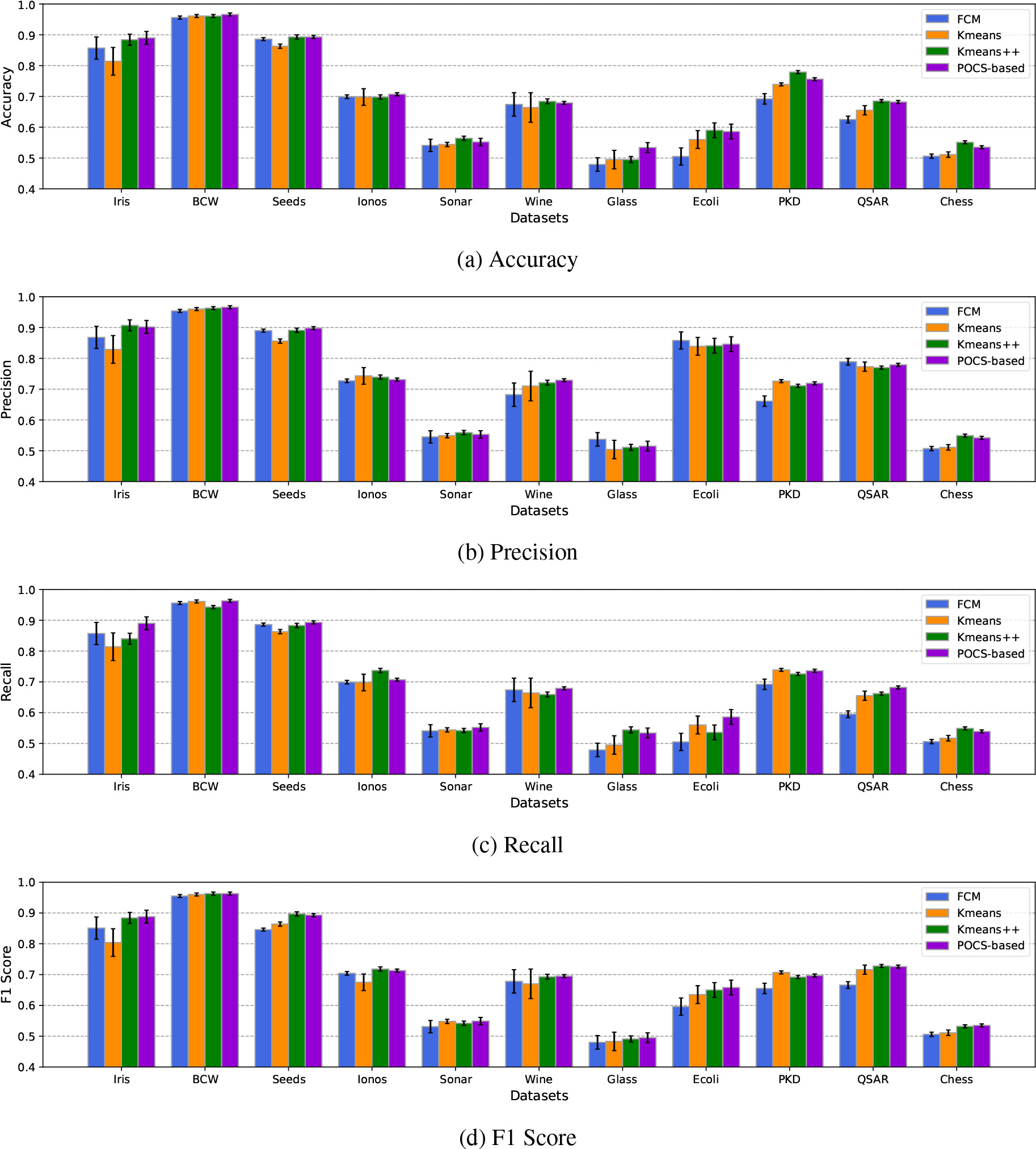
The comparisons in terms of Accuracy, Precision, Recall, and
In general, the proposed POCS-based algorithm has shown promising performance when compared with the other classical clustering algorithms in high-dimensional data clustering problems.
In this section, we investigate the applicability of the proposed POCS-based clustering algorithm to face clustering by performing clustering as a downstream task. Five subsets of face image data with different numbers of clusters and densities (instances per cluster) were prepared based on two widely used data sets for face clustering tasks, Five Celebrity Faces (FCF) [33] and Labeled Faces in the Wild (LFW) [34]. The FCF dataset contains images of five celebrities (Ben Afflek, Elton John, Jerry Seinfeld, Madonna, and Mindy Kaling) that are divided into training and validation sets. However, since this is a small data set, we merged the training and validation sets to obtain a single data set of 118 images. On the other hand, the LFW dataset is a test set for face verification [35] with 13,233 images of 5,749 identifications which were detected and centered by the Viola–Jones face detector [36]. Since there is a significant imbalance in the face cluster densities with a lot of subjects having less than 10 instances, we created four image subsets from the LFW dataset such that the cluster densities in each subset are relatively equivalent and distributed in various ranges (11–20, 21–30, 31–40, and 41–50). The details of the prepared data subsets in this experiment are summarized in Table 5.
Average execution time (sec.) of different algorithms on various UCI benchmark datasets
Average execution time (sec.) of different algorithms on various UCI benchmark datasets
Details of the face data subsets
The face clustering system in this experiment has three main steps. In the first step, MultiTask Cascaded Convolutional Neural Network (MTCNN) [37] is adopted with default settings to extract the face region in a given input image. MTCNN is a robust and accurate face detector that has been applied to numerous face recognition studies [38, 39, 40]. In the second step, FaceNet [35] is utilized for face embedding extraction. The input and output shapes of FaceNet are 160
Comparisons of various clustering algorithms in terms of accuracy (%) and execution time (sec.) in face clustering task
The pipeline of the face clustering system in this experiment.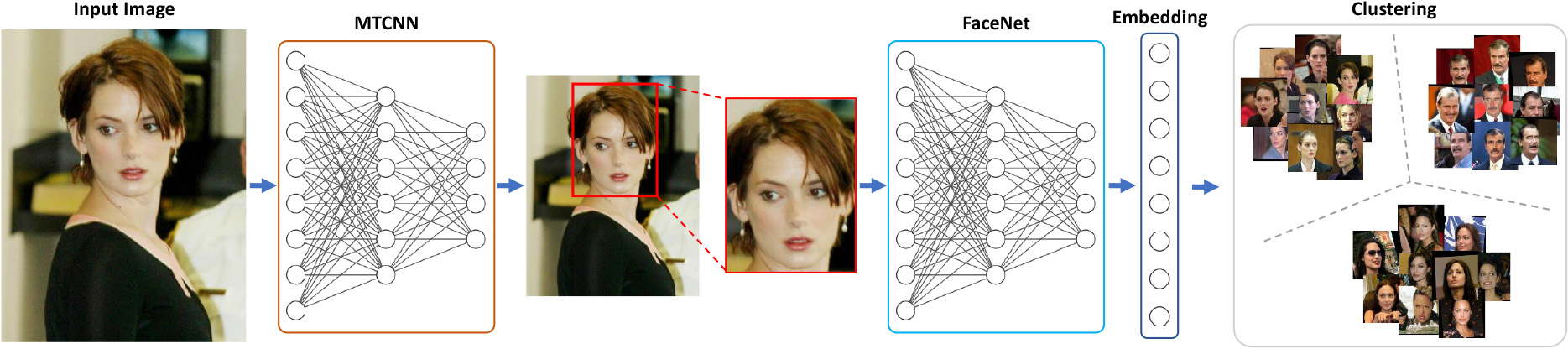
Table 6 summarizes the performances of the FCM, K-Means, K-Means
Details of the big data sets
Details of the big data sets
The performance of the POCS-based clustering algorithm on big data is examined in this section. To this end, four realistic data sets including 3D Road Network [43], Poker Hand [41], MetroPT-3 [42], and Electric Power Consumption [44] were utilized to conduct experiments. The descriptions of these data sets are summarized in Table 7.
In this examination, we only compare the POCS-based algorithm against the K-Means and K-Means
Comparisons in terms of clustering error (bar charts) and convergence time (line graphs) with different numbers of clusters on big data sets: (a,b) 3D Road Network, (c,d) Poker Hand, (e,f) MetroPT-3, and (g,h) Electric Power Consumption.
The comparisons in terms of clustering error and execution time are given in Fig. 13. As shown in Fig. 13, in terms of clustering error, all the algorithms under examination generally provide competitive performances, and the error is lower when the number of clusters becomes higher. The K-Means
Consequently, the proposed POCS-based clustering algorithm generally yields a competitive performance when compared with those of other clustering algorithms on various types of data sets and applications under our investigations. These results imply that the POCS-based clustering algorithm has potential in a wide range of clustering tasks.
Due to the strong dependency on the POCS optimization method, the proposed clustering approach inherits significant characteristics of the POCS algorithm including a possibility of unexpected convergence. The POCS methods have generally demonstrated robustness in finding local minimum solutions based on predefined objective functions with low complexity [46]. However, there is a specific scenario in which the minimum mean square error solutions of POCS can potentially produce undesirable outcomes [18]. This scenario occurs when a dataset includes outliers. In such case, the proposed algorithm assigns higher weight values to outliers according to the importance constraint described in Eq. (10) and results in outliers’ greater influence when compared to other data points. Note that this only happens when the number of data points in the data set is relatively small. Consequently, the algorithm converges to a position midway between the cluster and the outliers. However, we cannot judge whether this convergence is considered desirable or not because we may not know whether the outlier data are valid or noisy data in advance. Note that this problem is common in unsupervised learning algorithms. However, when the number of data points is sufficient and the outlier rate is under control, the proposed POCS-based algorithm can show competitive performances across various types of data and tasks which have been demonstrated through extensive experiments in the paper.
Conclusions
A new clustering method, called Projection Onto Convex Set (POCS)-based clustering algorithm, is proposed in this paper. The proposed POCS-based clustering algorithm treats each data point in a given data set as a convex set and applies the convergence property of the parallel POCS method in order to optimize the cluster prototypes. Based on extensive experiments on various synthetic and real-world datasets, the proposed POCS-based algorithm has shown superior performance when compared with the Fuzzy C-Means (FCM) clustering algorithm in most cases and is competitive with the K-Means/K-Means