
Abstract
At the core of Deep Learning-based Deformable Medical Image Registration (DMIR) lies a strong foundation. Essentially, this network compares features in two images to identify their mutual correspondence, which is necessary for precise image registration. In this paper, we use three novel techniques to increase the registration process and enhance the alignment accuracy between medical images. First, we propose cross attention over multi-layers of pairs of images, allowing us to take out the correspondences between them at different levels and improve registration accuracy. Second, we introduce a skip connection with residual blocks between the encoder and decoder, helping information flow and enhancing overall performance. Third, we propose the utilization of cascade attention with residual block skip connections, which enhances information flow and empowers feature representation. Experimental results on the OASIS data set and the LPBA40 data set show the effectiveness and superiority of our proposed mechanism. These novelties contribute to the enhancement of 3D DMIR-based on unsupervised learning with potential implications in clinical practice and research.
Keywords
Introduction
Deformable Medical Image Registration (DMIR) serves as a key tool in medical image processing and analysis. Its primary objective involves aligning reference images by establishing voxel displacement connections. This facilitates the matching and alignment of comparable anatomical structures across images. However, achieving precise registration presents a considerable challenge.
In the domain of medical image registration, traditional methods have long been employed to align and fuse different medical images for diagnostic and treatment purposes. These methods encompass a range of techniques such as intensity-based methods, feature-based methods, and landmark-based methods. Intensity-based methods seek to optimize similarity measures between pixel intensities, often using optimization techniques like gradient descent [1]. Feature-based methods leverage identifiable points, edges, or corners in the images to establish correspondences and facilitate alignment [2]. Landmark-based methods involve selecting distinctive anatomical landmarks to guide the registration process [3]. These traditional approaches have provided valuable insights and laid the foundation for the development of more advanced registration techniques.
Learning-based techniques use machine learning, deep learning, and artificial intelligence to make the process more accurate. Deep learning models, such as generative adversarial networks (GANs) and convolutional neural networks (CNNs), have demonstrated unparalleled capabilities in extracting relevant features and learning complex spatial transformations [4, 5, 6, 7].
Deformable medical image registration employing deep learning techniques is a topic of active research. Approaches for training networks can generally be categorized into two main groups: supervised and unsupervised learning techniques. Supervised learning techniques necessitate training the registration model using image pairs with known displacement and deformation fields. However, obtaining these fields typically involves prior registration through conventional methods. Consequently, the supervised learning models struggle to surpass the accuracy of traditional methods [8]. To address the limitations imposed by the requirement for labeled data in supervised learning, many researchers have turned their attention to unsupervised learning approaches for image registration.
Jaderberg et al. [9] introduced a spatial transformer network (STN) that supports the backpropagation of neural networks and transforms the image directly by using a deformation field. STN has played an important role in medical image registration. Balakrishnan et al. [10] combined U shaped network [11] and STN and developed a new network called voxelmorph and used unsupervised learning manner to register MRI brain atlas. Single image registration is enough to align those areas of an image that are less deformed, while multi-registrations are required for alignment of those areas of an image that are more deformed. Creating 3D models is crucial in the fields of computer-aided design (CAD), computer-aided engineering (CAE), and computer-aided manufacturing (CAM). HRLT3D, a hierarchical reinforcement learning approach was used for the reconstruction of 3D shapes [12]. DeepCSR, an innovative 3D deep learning framework for MRI-based cortical surface reconstruction, outperforms FreeSurfer and FastSurfer in accuracy, precision, and speed. Its continuous approach and hypercolumn features demonstrate efficient high-resolution reconstruction, promising advancements in medical studies and healthcare applications [13].
ViT-V-Net was introduced for registration of 3D medical image registration [14]. In ViT-V-Net, the vision transformer was employed as the final down sampling step of the encoder, alongside a CNN for non-final down sampling. The unsupervised learning methods with comparable to traditional algorithms have been presented [15]. They all calculate the similarity between fixed volume and warped moving volume, while the gradients can backpropagate through the differentiable warping operation. Most of the proposed networks show a lake of efficiency during dealing with complex deformation, especially with large displacement. For DMIR, transformers take the same attention mechanism [16] as single image tasks which focus on the relevance in the one image but ignore correspondences between image pairs. For fine registration, capturing correspondence between moving and fixed can pose challenges for transformers to give better registration of medical images. X-Morpher used cross attention to transformer structure, which just captures the corresponding between the same level of convoluted layers of fixed and moving images due to which the aligning accuracy of fixed and warped moving images is decreased. The efficiency of skip connection used in UNet [17, 18] is not optimal and their empowerment falls short of expectations. Further improvements are necessary to increase the effectiveness of skip connections in medical image registration. In the recursive cascade network introduced by Zhao et al. [19] the idea of using a sequence of networks to improve image registration has been shown to work well. However, in this setup, each part of the network needs both the original image and the image being registered. There is no proper relationship between the processed steps. This means that some parts of the image that are already aligned well are being processed again, which doesn’t really help and can slow things down. VTN [20] used cascade, but they suffered from the problems of training and complexity. In order to handle the prescribed challenges we used the following components:
In order to capture the correspondences between moving and fixed images, both in encoder and decoder, we introduce cross attention at different levels, which enhances the aligning capability of fixed and moving images. So by considering correspondences at multi-layers, we enhance registration accuracy. By concatenating the usefulness of skip connections and residual blocks, our method aims to increase the empowerment of skip connections in medical image registration tasks. This integration makes possible, the efficient flow of information across various layers of the encoder and decoder, helping better alignment and enhance accuracy in 3D DMIR. To handle the challenges related to training and complexity in cascade-based techniques, we present a novel approach. By introducing residual block skip connections with the cascade architecture, our method increases the efficiency and performance of the 3D medical image registration process.
In this section, we are going to discuss a short overview of the existing literature and research tools in the field of medical image registration.
Deformable registration process
In conventional volume registration, one of the volumes, either the moving (source) or the fixed (target), is adjusted to align with the other. Significant differences in brain anatomy due to natural variations among individuals and variations in their health conditions lead to substantial variability among subjects. Deformable registration plays an important role in enabling the comparison of these anatomical structures across different scans. This proves to be exceptionally useful for studying variations within different populations and for tracking how brain anatomy changes over time, particularly in individuals with medical conditions. The process of deformable registration typically involves two key steps: initially, an affine transformation is used to achieve a broad alignment, and then a more complex deformable transformation is applied to allow for greater flexibility. Our main emphasis lies in the latter phase, specifically in establishing a comprehensive and nonlinear correspondence for every voxel point.
The majority of deformable registration algorithms in use today employ an iterative approach that involves fine-tuning a transformation by minimizing an associated energy function [21, 22].
Consider two images, one fixed (

1) Mean Squared Error (MSE)
Mean Squared Error (MSE) is a commonly used metric in DMIR, calculating the average squared distances between corresponding pixel intensities in the aligned images, in order to increase the registration accuracy. It is calculated as:

2) Cross-correlation
Cross-correlation is used to measure similarity in DMIR, which calculates the rank of similarity between fixed and moving volumes by relating links between interrelating pixel intensities. It is formulated as:
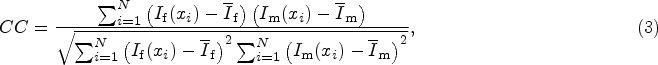
3) Mutual Information
It determines the amount of information shared between the pair images by calculating the mutual relationship of their intensity distributions. By increasing the mutual information, DMIR techniques can find the accurate alignment between the images, due to which the accuracy of registration is increased.
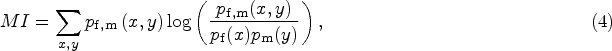
The smooth transformation is achieved by using regularizers that calculate consistency or directly applying on the displacement vector field [26, 27, 28, 29].
Traditional methods for image registration involve optimizing the deformation field separately for each pair of images. This approach can be comparatively complex, during dealing with a huge number of volumes, such as in population-wide analyses.
Essentially, instead of individually optimizing deformation fields for each pair, we perform a global optimization of the shared parameters. This idea is similar to something called “amortization,” a method used in different areas [30, 31]. After the calculation of the overall function, we demonstrate the deformation field based on displacement-based vector field, for the specific pair of images.
The adoption of learning-based models, particularly convolutional neural networks (CNNs), across diverse domains like image segmentation, classification, and reconstruction has paved the way for increased interest in CNN-based registration methods. This heightened attention is primarily driven by the remarkable performance achieved by CNNs in these areas. The classification of these methods into two categories, namely supervised learning and unsupervised learning, is contingent on the training approach employed.
1) Supervised learning techniques
In these methodologies, it is essential to have access to ground-truth deformation vector fields. These fields are usually generated using established classical registration techniques [32, 33, 34]. In a study by Yang et al. [32] they introduced a novel approach involving an encoder-decoder network. This network was designed for predicting deformation fields on a patch-wise basis. However, the effectiveness of these methods in image registration relies heavily on the accuracy of the provided ground-truth data. These techniques often demand carefully constructed ground truth deformation fields and involve complex pre-processing steps. In real-world scenarios, obtaining such high-quality ground truth data and executing these complex pre-processing tasks can be quite challenging.
2) Unsupervised learning techniques
Researchers have introduced unsupervised learning methods to reduce the shortcomings of supervised learning techniques. These approaches aim to improve image registration by minimizing the loss between the transformed image and a predefined reference image. Kreb et al. [35] introduced an innovative unsupervised learning model that employs a low-dimensional stochastic representation of deformation. This approach minimizes the KL divergence between two image distributions. Balakrishnan et al. [15] introduced a 3D medical image registration method that operates in a pairwise fashion. They incorporated a Convolutional Neural Network (CNN) featuring a spatial transform layer (STL). The parameters of this layer are trained using the normalized cross-correlation function. In the context of large-volume image registration, Vos et al. [36] introduced a comprehensive framework for both affine and non-rigid image registration. Lei et al. [37] proposed an innovative multi-scale unsupervised learning technique known as MS-DIRNet. This approach incorporates both global and local registration networks.
However, these approaches have limitations in ensuring consistency, which can lead to a folding problem due to the mapping loss of integrity. In order to solve this problem diffeomorphic integration layers were introduced [38]. It is tantrum to note that applying the constraint during the inference phase can add extra complexity.
Cross-attention (CA) is a commonly employed version of self-attention (SA), often utilized for both inter- and intra-modal tasks within the field of computer vision [39, 40]. Its applicability to image registration has also been explored [41, 42]. What sets CA apart from SA is the manner in which it calculates matrix representations. In XMorpher [43] the CA is used between the same features layers of moving and fixed volumes.
Cascade approaches find application across diverse domains within computer vision. For instance, in the context of pose estimation, cascaded pose regression iteratively enhances pose predictions acquired from supervised training data [44]. Additionally, they play a role in expediting object detection through cascaded classifiers [45]. Cascade architectures have proven advantageous in the field of deep learning as well. One notable example is the deep deformation network, which employs a cascading approach across two stages to forecast deformations for landmark localization [46]. These cascade principles extend their benefits to a spectrum of applications, such as object detection [47], 3D image reconstruction for MRIs [48], liver segmentation [49], and mitosis detection [50].
In the field of medical image registration and deep learning, many researchers are using Residual Networks(ResNets). These ResNets are getting a lot of attention because they are good at understanding detailed image features and they are also good at learning complicated patterns. Residual networks (ResNets), first introduced by He et al. [51], have transformed deep learning. They solve the problem of gradients vanishing during training by using skip connections.
We build upon these concepts and expand CA, cascade, and ResNets to perform 3D volume registration, and enhance registration accuracy.
Methodology
Our model is based on deep learning networks. This model is used for extracting and matching features from fixed and moving images, and increase the registration capability of the input image pairs. Our model plays a key role in aligning 3D DMIR. In this section, we present the foundational framework of our model. We leverage cross-attention mechanisms across multiple layers in both the encoder and decoder components. This approach is instrumental in achieving precise alignment between the fixed and moving images. The residual block used in the skip connection helps the flow of information between the encoder and decoder. Cascade operates iteratively, continually refining its representations and the inclusion of residual skip connections seamlessly facilitates the flow of information between these iterations. This harmonious interplay between cascade and residual skip connections not only enhances the training process but also contributes to the model’s overall effectiveness. The complete flowchart of our proposed approach is shown in Figure 1.
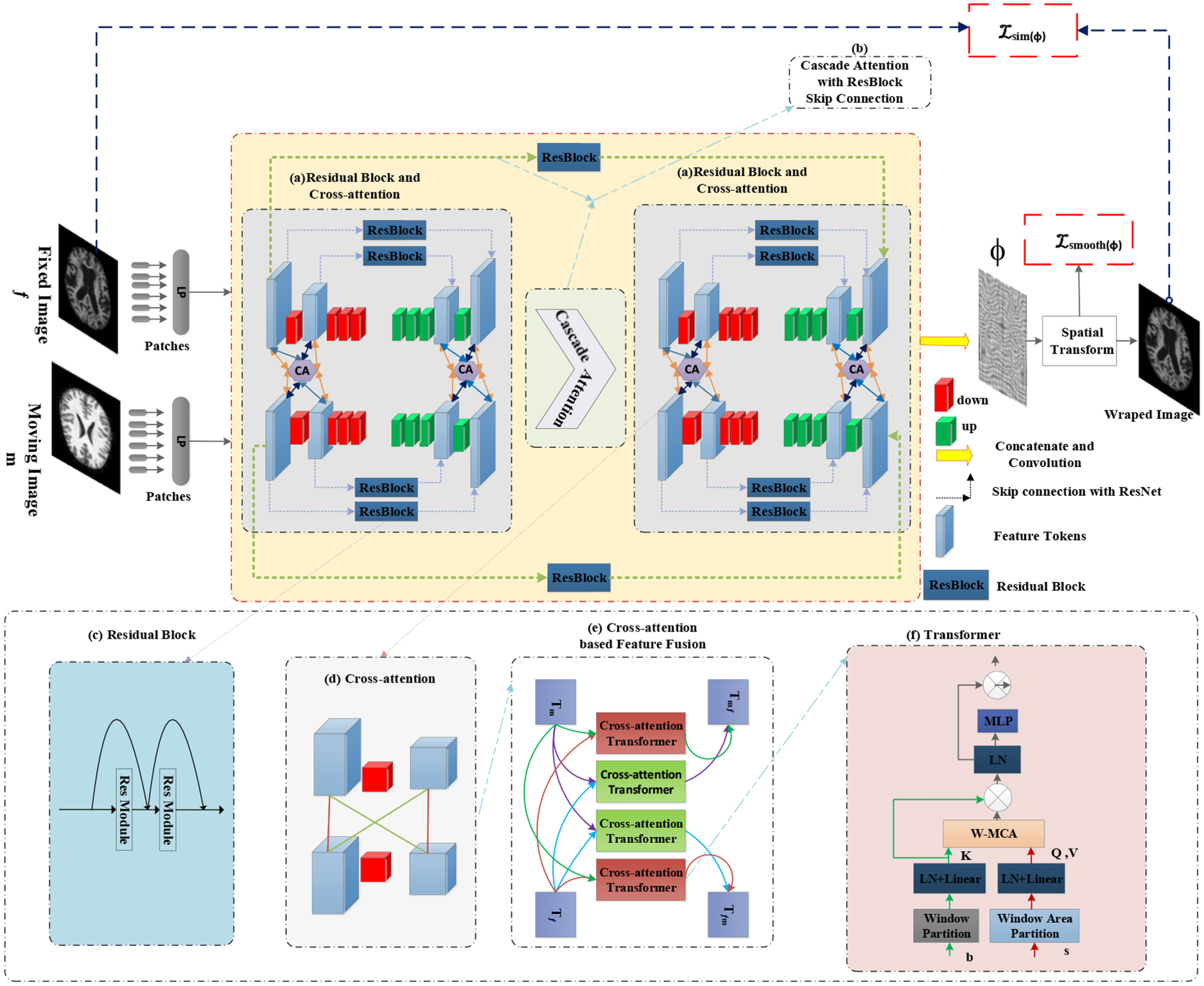
Overall architecture of our model which consists of: (a) Residual block used in skip connection for uniform flow of information between encoder and decoder and cross-attention is used over different layers of fixed and moving images. (b) Cascade attention with residual skip connection, which help in passing information through series of stages. (c) Residual block, which helps in proper flow of information between layers of encoder and decoder. (d) Cross attention between different layers. (e) The feature fusion module comprises four computation cross-attention blocks that share parameters to facilitate mutual correspondences. (f) Working structure of cross attention transformer.
The foundation of cross attention mechanism is based on the XMorpher technique. We use cross attention between the similar layers and as well as different layers of the fixed and moving images and that is why we call it cross attention over multi layers as shown in Figure 1d. We employ the max-pooling technique to effectively handle the varying sizes of features layers in both the fixed and moving images during applying the cross attention between them. It helps in better understanding and shares of information between fixed and moving images and thus accuracy of aligning of the images is improved. This cross attention consists of:
1) Cross-attention assisted feature integration block
As depicted in Figure 1e, the corresponding features
2) Cross-attention transformer for mutual attention
By using the attention mechanism, the cross-attention transformer block calculates new feature tokens from input feature b to feature s as shown in Figure 1f. In this mechanism, base windows set
Local window diversity and enhancement of image alignment
1) Window division (WD) and window area division (WAD)
In WD and WAD, we split the input feature tokens, represented as ‘
2) Multi-scale window fusion (MWF)
The main function of MWF is to connect query with the pairs of key and value as shown in Figure 2II. From base windows query is derived, while from searching windows the keys and values both are derived. The output is determined by summing up the values, each weighted by how much it aligns with query. In order to cover different representation angles MWF uses multi head attention. The formula for calculating cross attention is given as:
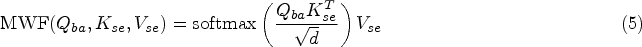
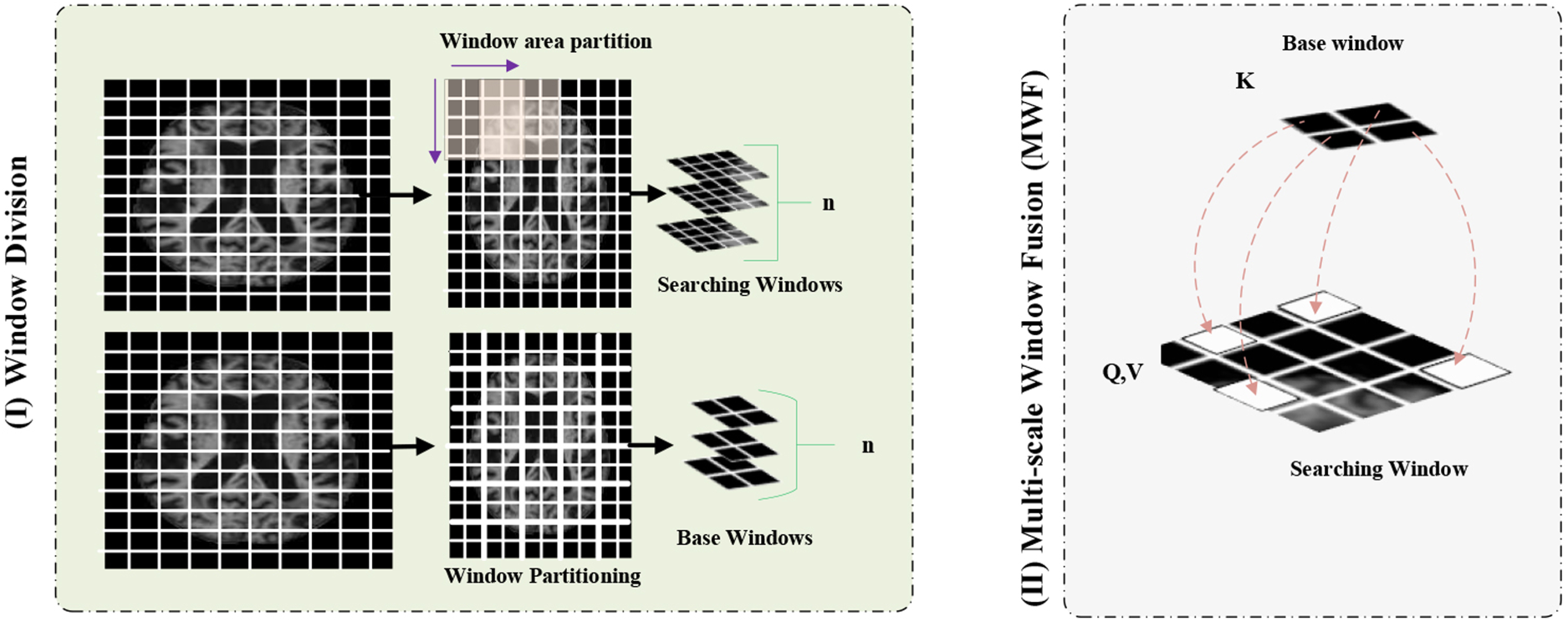
(I) A specific approach to create a basis and searching windows using window partitions. (II) Using W-MCA, cross-attention between the base and search windows is calculated.
We have included the U-shaped architecture [11], which is a popular design for medical image registration tasks because it can capture both global and local information, in our suggested model. The encoder and decoder are the two primary parts of this architecture. Whether the input images are the fixed or moving image for our registration task, the encoder is in charge of extracting complex information from them. However, after receiving these characteristics, the decoder reconstructs the images using the information that was extracted, allowing for precise alignment.
We use skip connections into our architecture to strengthen the connectivity between appropriate levels of the encoder and decoder using ResNet as shown in Figure 1a. ResNet is well known for its capacity to solve the disappearing gradient issue. It is made up of residual blocks that help gradients spread during training. With a kernel size of 3
Cascade-base attention with residual skip connection (CARSC)
Our methodology for enhancing medical image registration integrates two key components: cascade attention and residual skip connection. Cascade attention, as illustrated in Figure 1b, plays a crucial role in refining the representation of the images, thereby enhancing the accuracy of the registration process. It achieves this by selectively focusing on relevant features and suppressing irrelevant ones, thereby improving the overall alignment. On the other hand, the residual skip connection facilitates the smooth flow of information and gradient propagation during the training phase. By incorporating skip connections, our model ensures that information from earlier layers is preserved and efficiently transmitted to subsequent layers, enabling better convergence during optimization. In order to achieve a balance between registration accuracy and computational efficiency, our model also employs the technique of executing the registration program twice in order minimize the computing burden. This method guarantees that the registration procedure stays effective without sacrificing the caliber of the output.
Unsupervised loss function
An unsupervised loss function

We investigated the influence of the regularization parameter
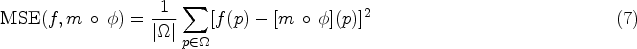
The other part of the equation is the cross-correlation between
Let
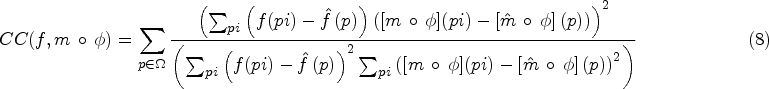
A higher cross-correlation (CC) value indicates a more accurate alignment, resulting in the following loss function:

To ensure that the displacement field

To estimate the spatial gradients, we utilize differences between adjacent voxels. In particular, for the gradient components
Data and preprocessing
To check the performance of our proposed method, based on the atlas, we evaluate it on brain MR scans from two datasets: 450 T1-weighted brain MR scans from the OASIS dataset [52] and 40 brain MR scans from the LPBA40 dataset [53]. The OASIS dataset consists of brain MR scans from subjects spanning an age range of 18 to 96 years, consisting of 100 individuals with Alzheimer’s disease in the mild to moderate stages. Atlas-based registration is used on a huge scale in multidisciplinary image analysis to create an empowered correspondence between the atlas and moving images. In the OASIS dataset, our evaluation is based on the segmentation of 28 subcortical structures representing anatomical features as shown in Table 1. For the LPBA40 dataset, we utilize the segmentation of 56 anatomical structures, meticulously hand-drawn by experts, as the foundation for our evaluation. To enhance registration accuracy and computational efficiency, all data images are uniformly resized to dimensions of 160
The OASIS dataset’s 28 anatomical structures for testing.
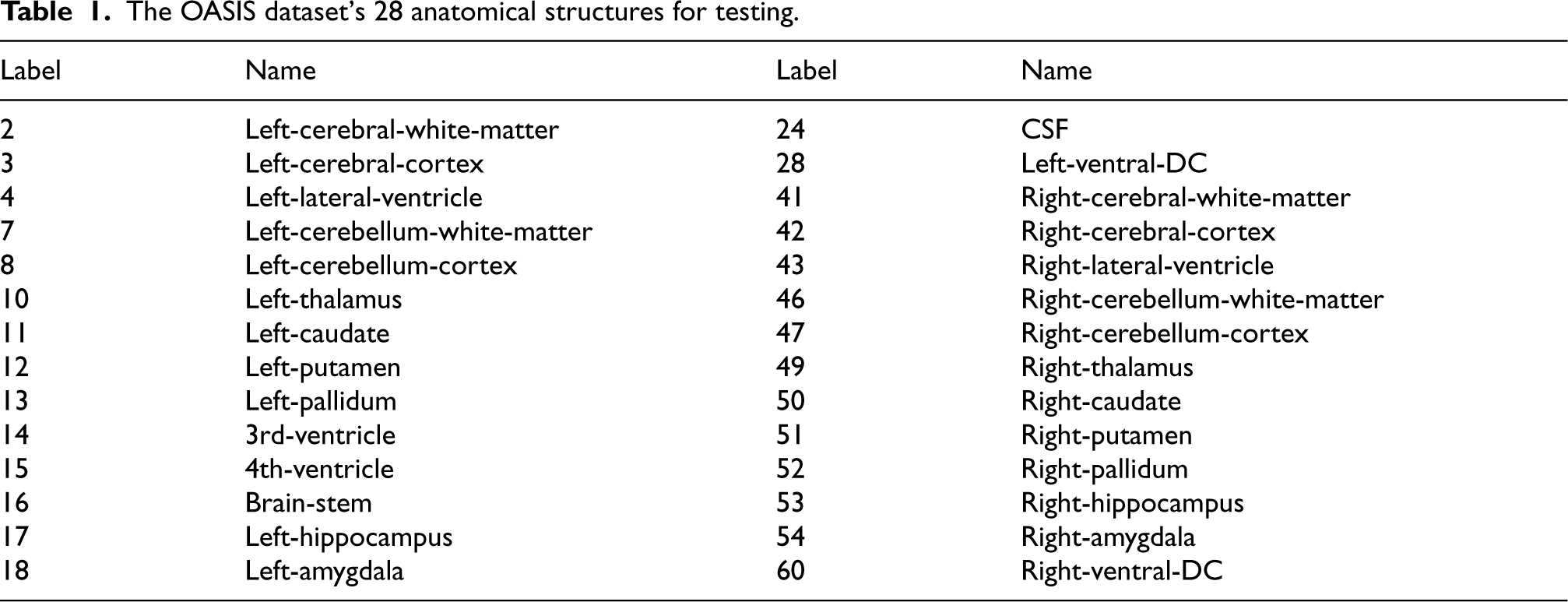
The OASIS dataset’s 28 anatomical structures for testing.
We evaluate our contributions by comparing them to two traditional approaches, called SyN [25], Elastix [54]. Additionally, we also assess our approach in comparison to learning-based algorithms, called VoxelMorph [15], ViT-V-Net [14], TransMorph [55], XMorpher [43], and TransMatch [56]. For the learning-based algorithms, we followed the hyperparameter settings provided by the authors to train our model from scratch on the dataset we used. In contrast, we adjusted the parameters for the traditional approach to achieve a balance between registration time and effectiveness.
Test
In our evaluation, we assess the similarity between segmented images from distorted moving and fixed images by calculating their Dice scores. Additionally, we gauge the significance of the registration performance concerning differential isometry characteristics by measuring the percentage of voxels with non-positive Jacobian determinants in the displacement field. Furthermore, we employ topology change (TC) as an additional evaluation metric, analyzing the differences in the segmented images before and after spatial transformation to examine the properties of differential isometry. Additionally, we conduct testing to calculate the average registration time for each image pair.
Implementation
We used pytorch 1.10.0 and trained with CUDA support (cu111) for the implementation of our proposed method. We used Adam Optimizer. The learning rate was set to
Evaluation matrices
We check the performance of the registration techniques with two evaluation matrices, i.e, Dice score (Dice) and Jacobian (
(1) Dice
Dice score which is also called Dice Similarity Coefficient, is a calculation of similarity between the pairs of fixed images and worked moving images. Mathematically it can be written as:

Where
(2)
Jacobian matrix shows the spatial transformation field between fixed and moving images. Mathematically Jacobian matrix can be defined as:

Where
(3) Topology change (TC)
It shows the change in the relationships and arrangement between different structures in fixed and moving images during their alignment with each other.
(4) Time-complexity (T)
It shows the empowerment of the algorithm during the aligning of fixed and moving images, and calculates how computational effort increases with image complexity.
Registration performance comparison
A thorough assessment of registration performance is shown in Table 3, which compares two traditional registration methods with five modern learning-based registration strategies. The traditional approaches show the lowest Jacobian score (% of
Anatomical regions in LPBA40 for cross-dataset validation.
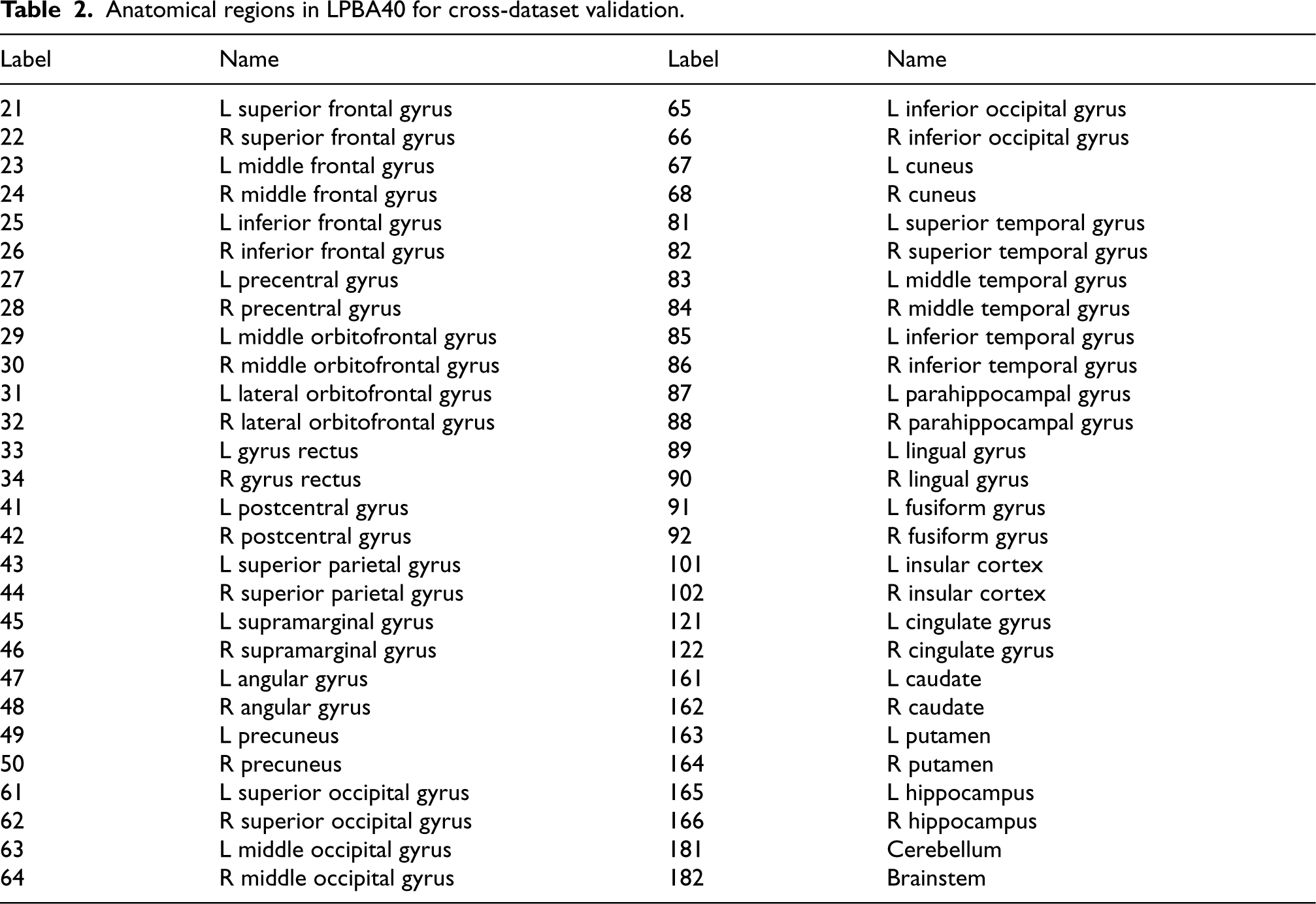
Anatomical regions in LPBA40 for cross-dataset validation.
Quantitative evaluation of proposed framework against other methods on the OASIS and LPBA40 datasets.
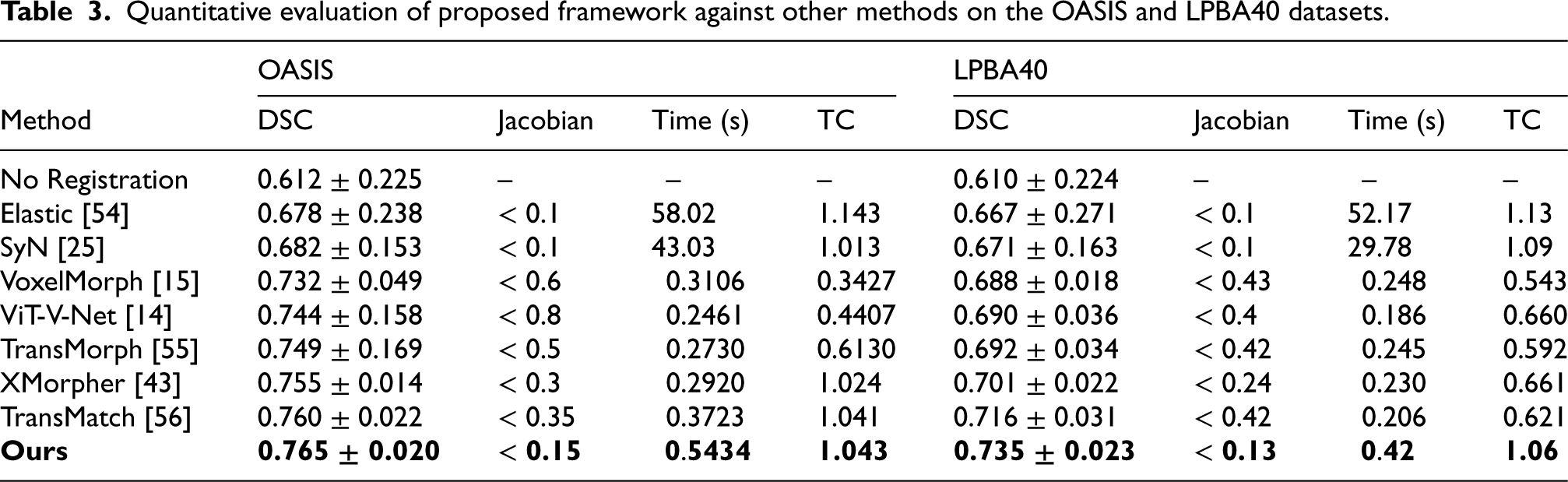
The cross-data-set verification findings for six machine learning-based techniques and two conventional algorithms using our method on the LPBA40 dataset are also presented in Table 3. As Table 2 shows, LPBA40 is more complex than OASIS and requires registration for a larger number of regions, which resulted in a performance decrease for all registration strategies. However, our methodology continues to be the most effective registration technique even when managing the most challenging data collecting. These findings highlight our methodology’s benefits in numerous registration settings and confirm its stability and adaptability.
Visual analysis
In this segment, we provide visual comparisons of our proposed framework alongside seven other state-of-the-art deformable medical image registration techniques.
Figure 3 offers a visual representation of the registration outcomes for a specific image pair. It shows the moving and fixed images, the results obtained by each registration method, and the generated registration field. After comparison with other approaches, our technique shows superior alignment.
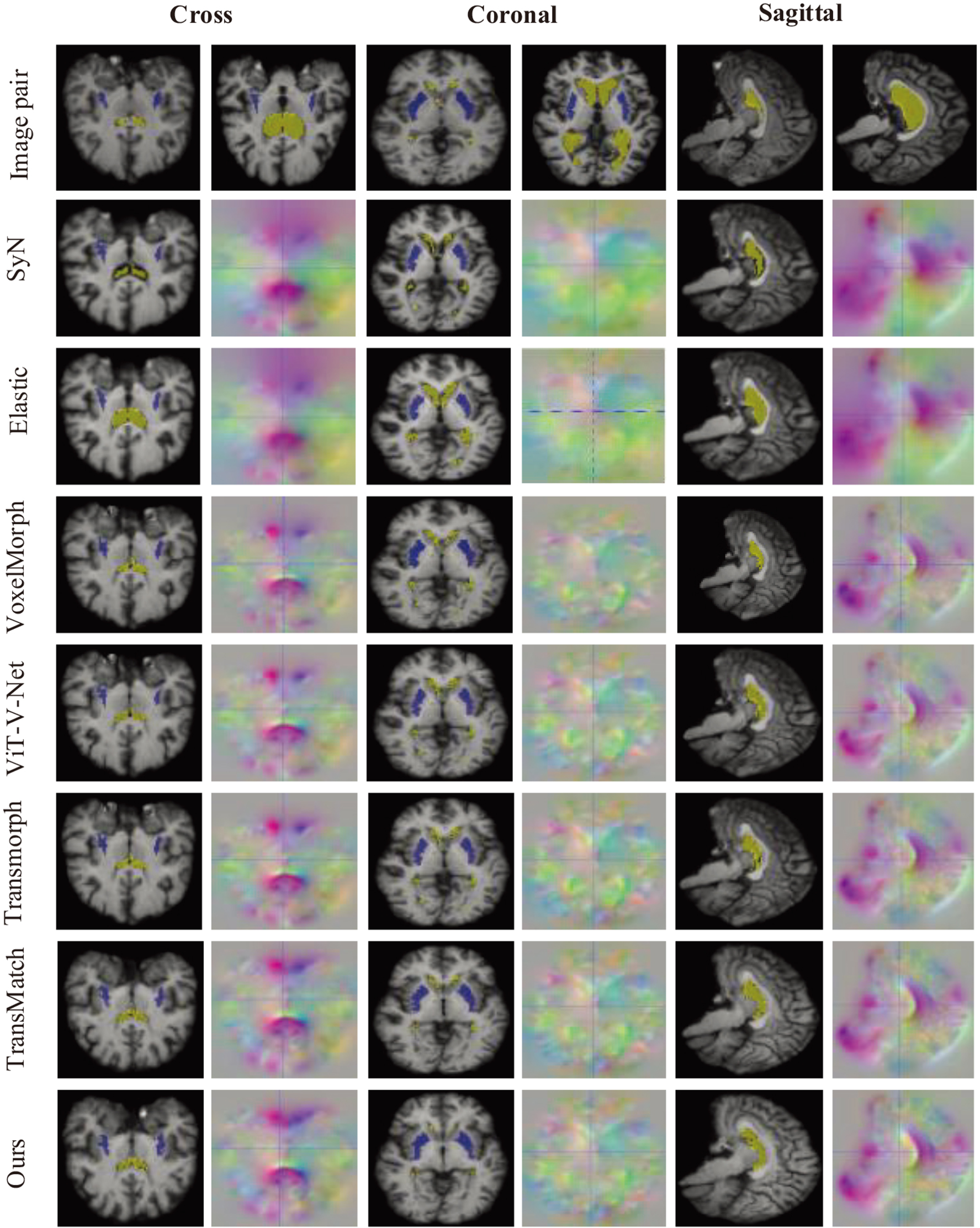
Qualitative outcomes regarding the registration precision achieved by our approach in comparison to the baseline methods.
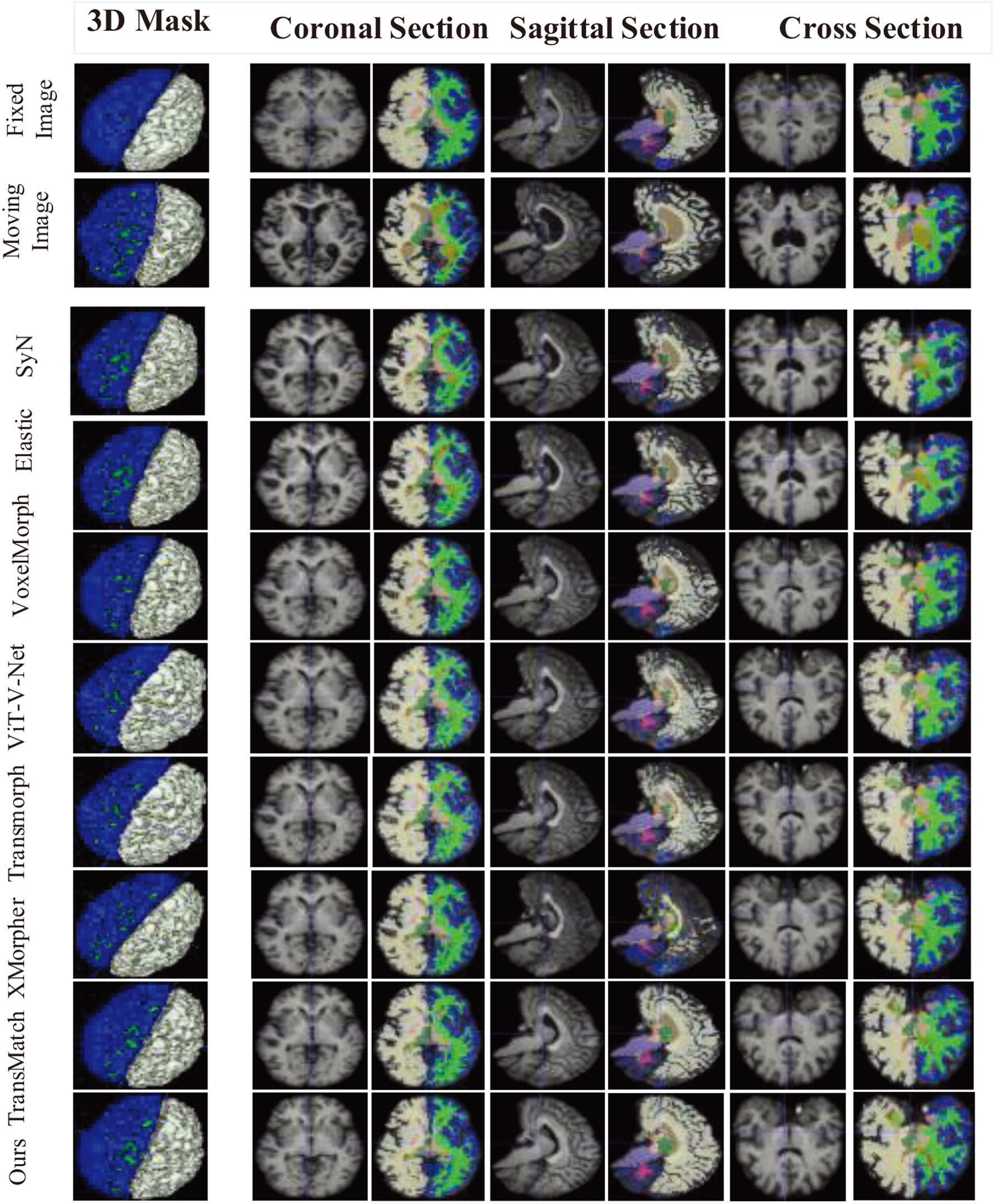
Visualization of registration outcomes: A random pair of registration images from the OASIS test set was chosen for experimentation with six different registration algorithms. The registered images and corresponding masks were visualized in three dimensions and three specialized medical sections. The results from our model indicate that the registered image closely resembles the fixed image in the primary registration area.
In Figure 4, after employing our model for registration, the three-dimensional contour of the mask exhibits a remarkable alignment with the fixed mask. Furthermore, when we examine two-dimensional slices from various perspectives, such as coronal, cross-sectional, and sagittal views, it becomes apparent that the post-registration with our model closely resembles with the fixed image.
We conducted ablation experiments and recorded Dice Similarity Coefficient (DSC), Jacobian Co-efficient (% of
We found that, when looking at single-component effects, RBSC had the greatest effect on DSC score, up to 0.6%. With a maximum impact of 0.5%, the CAML had the second-biggest effect on DSC. The increased voxel folding capacity was exhibited by CARSC. CARSC resulted in a 1.6% rise in the Jacobian co-efficient.
We carefully eliminated two components at the same time to see how the double components affected our model. The impact on the DSC value for RBSC with CARSC was 1.7%, but the impact for CARSC with CAML and RBSC with CAML was 1.3% and 1.0%, respectively. Thus, the combination of RBSC and CARSC had the greatest effect on DSC score. The highest influence on the Jacobian co-efficient, which might reach 4.0%, was observed when RBSC plus CARSC was used. CARSC with CAML had the second-greatest effect on the Jacobian co-efficient, with a recorded influence of up to 3%.
Considering time and memory factors, we discovered that CARSC had the greatest increasing influence on our model. The smallest impact was reported with CAML.
Ablation experiment results of our model.
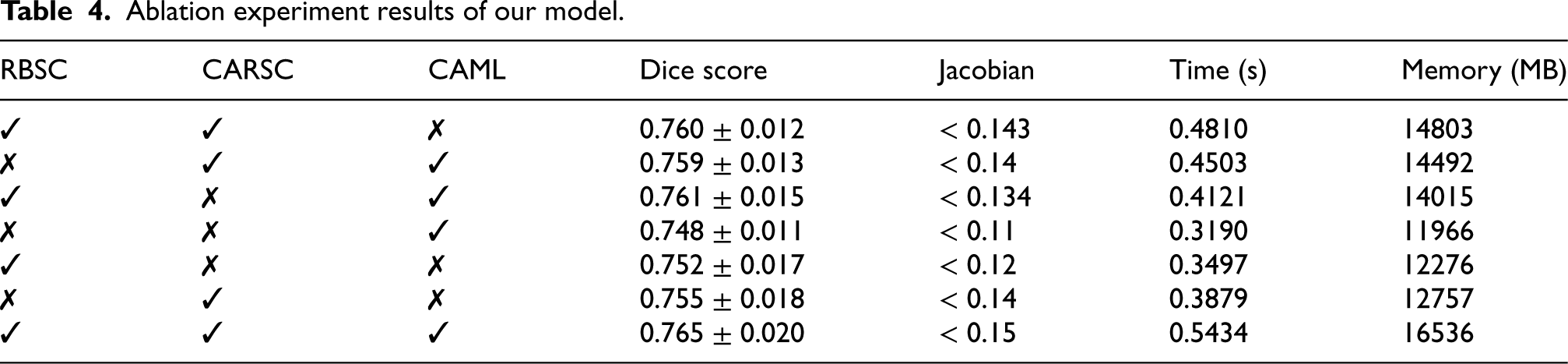
Ablation experiment results of our model.
This paper consists of an unsupervised deep learning-based algorithm for the registration of 3D medical images. We massively tested and verified our model using the publicly accessible OASIS dataset. After training our model on the OASIS dataset, we tested it on another publicly accessible LBPA40 dataset, in order to verify our model performance across variant datasets, improving the the assessment of its robustness and applicability. The output from our experiments gives compelling evidence to reinforce the effectiveness of our model. Our novel approach not only increases the accuracy of 3D medical image registration but also enhances the reliability of the registration process. The novelty mentioned in this paper consists of cross-attention over multilayers, residual network in skip connection, and cascade-base attention with residual skip connection. In future research, there is potential to expand and refine our framework for other 3D applications such as 3D polygon mesh [57] and monocular 3D object detection [58]. In later investigation, if better ways of training emerge, then there is potential to complement or replace the existing contribution described in this paper. This perspective mechanism could further increase the performance of image registration, thereby enhancing the accuracy and quality of the registration process.
Footnotes
Acknowledgments
Funding for this research has been provided by the Fundamental Research Foundation of Shenzhen underGrant JCYJ2023080810570512.