
Abstract
Emojis in texts provide lots of additional information in sentiment analysis. Previous implicit sentiment analysis models have primarily treated emojis as unique tokens or deleted them directly, and thus have ignored the explicit sentiment information inside emojis. Considering the different relationships between emoji descriptions and texts, we propose a pre-training Bidirectional Encoder Representations from Transformers (BERT) with emojis (BEMOJI) for Chinese and English sentiment analysis. At the pre-training stage, we pre-train BEMOJI by predicting the emoji descriptions from the corresponding texts via prompt learning. At the fine-tuning stage, we propose a fusion layer to fuse text representations and emoji descriptions into fused representations. These representations are used to predict text sentiment orientations. Experimental results show that BEMOJI gets the highest accuracy (91.41% and 93.36%), Macro-precision (91.30% and 92.85%), Macro-recall (90.66% and 93.65%) and Macro-F1-measure (90.95% and 93.15%) on the Chinese and English datasets. The performance of BEMOJI is 29.92% and 24.60% higher than emoji-based methods on average on Chinese and English datasets, respectively. Meanwhile, the performance of BEMOJI is 3.76% and 5.81% higher than transformer-based methods on average on Chinese and English datasets, respectively. The ablation study verifies that the emoji descriptions and fusion layer play a crucial role in BEMOJI. Besides, the robustness study illustrates that BEMOJI achieves comparable results with BERT on four sentiment analysis tasks without emojis, which means BEMOJI is a very robust model. Finally, the case study shows that BEMOJI can output more reasonable emojis than BERT.
Keywords
Introduction
Background and Motivation
Sentiments are subjective views, appraisals, evaluations and feelings [1]. Liu [2] first divided sentiment into explicit sentiment [3, 4] and implicit sentiment [1, 5]. For explicit sentiment analysis tasks, there is some research, such as personality traits detection [6, 7], emotion analysis [8, 9] and stress detection [10]. For implicit sentiment analysis, it studied the sentiments of language fragments, including sentences, clauses and phrases, which express the subjective sentiment with hidden explicit sentiment clues [1, 5, 11, 12, 13]. There are few works on inferring implicit sentiment from context [5, 14], on account of implementation difficulties [5]. Specifically, Liao et al. [12] divided implicit sentiments into four categories: fact-implied type, metaphorical type, rhetorical-question type and ironic type. The existing models hardly distinguished the sentiment orientations of language fragments for each category.
Meanwhile, existing implicit sentiment analysis (ISA) methods mainly focused on mining the inherent information, including contextual, semantic and syntactic information [12, 15], and introducing external knowledge such as commonsense knowledge [1] and sentiment lexicon [5] in sentences. However, they ignored the explicit sentiment clues inside the language fragments, especially emojis. Since emojis contain lots of sentiment information, a sentence with different emojis can express different sentiments. For instance, as shown in Fig. 1, the three sentences have the same text but express three different sentiment orientations because
Examples of the same text with different emojis. 
Emoji sentiment analysis methods can be divided into two categories. (1)
We will utilize and fuse the above two methods to complete the lacked information or ignored sentiment information in texts. There are two main challenges: (1)
Solutions and contributions
To overcome the above-mentioned challenges, we propose a pre-training Bidirectional Encoder Representations from Transformers (BERT) model with emojis for sentiment analysis (BEMOJI). This method utilizes the sentiment information inside emoji to complete the lacked or ignored sentiment clues and analyze implicit sentiment. It pre-trains a language representation model on texts with emojis and fine-tunes on downstream tasks by fusing emoji description representations and text representations.
The main contributions of our work are expressed as follows: (1) Prompt learning is adopted to predict the corresponding emoji descriptions of input sentences at the pre-training stage. (2) A knowledge fusion layer is adopted to combine the emoji descriptions and input sentence representations to predict the sentiment of the input texts at the fine-tuning stage. (3) A pre-training BERT model with emojis for sentiment analysis (BEMOJI) is proposed. (4) Abundant experiments verify that BEMOJI outperforms existing emoji-based methods and pre-trained language models on Chinese and English datasets.
Related work
Implicit sentiment analysis
Existing ISA methods mainly focused on mining contextual, syntactic and semantic information or injecting external knowledge. Liao et al. [12] used the multi-level semantic fusion model to capture explicit context representation, implicit opinion expression and implicit target representation from semantic dependency trees. Compared with other baseline models, their method achieved the best scores on implicit sentiment analysis and unsentimental sentence classification tasks. Zhuang et al. [15] obtained contextual, syntactic and semantic features from sentence embedding, dependency syntax tree and sentiment words of a sentence, respectively. The multi-feature neural network outperformed other RNN-based models and syntactic tree-based models. CLEAN [20] eliminated the confounding causal effects and extracted the pure causal effect between sentence and sentiment. The experimental results showed that CLEAN achieved state-of-the-art (SOTA) results on both implicit sentiment analysis and implicit aspect sentiment analysis tasks. ContextBERT [21] utilized contextual information and sentence information to analyze implicit sentiment. The experimental results showed that it achieved SOTA results on two implicit sentiment analysis tasks. Since the clues of implicit sentiment may not be obtained directly from a sentence, it is difficult to accurately identify implicit sentiment only by considering it without external knowledge.
In order to complement sentiment clues in the texts, some researchers introduce external knowledge into ISA models. Wei et al. [5] adopted BiLSTM to encode sentences for sentence representations and put them together with the words in a sentiment lexicon into the orthogonal attention layer for implicit sentiment classification. Their proposed method achieved the best scores on the implicit sentiment analysis dataset, i.e., SMP2019-ECISA, and explicit sentiment analysis datasets, including COAE and SemEval, compared to other baseline models. Zhou et al. [22] introduced an event triplet into a sentence and let the model classify event and sentiment. They constructed an event-related implicit sentiment analysis dataset, i.e., EveSA. They also used BERT to encode the event subject, event predicate, event object and sentence. Their method has two training objectives: event classification and sentiment classification. The experimental results showed that their method achieved SOTA scores on both EveSA and SemEval17 Task4 datasets. Liao et al. [1] introduced commonsense knowledge into sentences. They used TransE [23] and GAT [24] to represent commonsense knowledge and pre-trained word embedding to represent a sentence. Then they adopted BiLSTM to encode the sentence representation and knowledge representation. Third, they utilized an orthogonal attention layer to fuse a sentiment lexicon and the output of BiLSTM. At last, they used one classifier to output the predicted label. The experimental results showed that the proposed B+KG-MPOA method outperformed other implicit sentiment analysis methods. KC-ISA [25] fused context information, target sentence information and knowledge graph information to analyze implicit sentiment. The experimental results showed that KC-ISA achieved SOTA results on implicit sentiment analysis and two other sentiment classification tasks. Lin et al. [26, 64] proposed a worthwhile dynamic multiscale topological representation in representation learning. Their method significantly improved classification performance on network traffic datasets. Liu et al. [27] proposed a new cross domain sentiment aware word embedding model. Their model integrated sentiment information and domain relevance. Compared with other baseline models, their model improved the performance of comment sentiment classification.
Although these methods mentioned above could effectively utilize contextual, syntactic, semantic information and external knowledge, they treated emojis as a special token, like UNK, and ignored these explicit sentiment clues. Therefore, it is necessary to thoroughly consider contextual information, external knowledge and emojis in implicit sentiment analysis models.
Emoji sentiment analysis
The existing emoji sentiment analysis methods are divided into two categories: (1) the methods that treat emojis as unique tokens and pre-train or fine-tune their embeddings; and (2) the methods that consider the descriptions of emojis. DeepMoji [16] used a large corpus (which contains sentences and emojis) to pre-train the model by two BiLSTM layers and one attention layer. Then DeepMoji transferred the pre-trained model to the sentiment analysis task without emojis. The experimental results showed that DeepMoji could learn a lot of sentiment information from emojis and achieve SOTA results on three sentiment analysis datasets, three emotion analysis datasets and two sarcasm classification datasets. SEntiMoji [17] evaluated the performance of DeepMoji [16] in the software engineering field. The experimental results showed that SEntiMoji achieved the best results on four software engineering datasets. Based on DeepMoji [16], Li et al. [28] also considered the sentiment polarities of emojis. Their proposed EAGRU method replaced BiLSTM in DeepMoji with BiGRU. Besides, they introduced two hyperparameters as weights for the sentiment lexicon and the hidden states of DeepMoji, respectively. The experimental results showed that EAGRU achieved the best results on the Weibo dataset compared with other baseline models. Chen et al. [29, 30, 31] assigned two opposite embeddings, i.e., positive embedding and negative embedding, to each emoji and concatenated the word and emoji embeddings to create the final embedding. The experimental results showed that their methods achieved the best results on Twitter sentiment analysis datasets compared with other baseline models. Al-Halah et al. [32] used many images to train emoji embeddings. They extracted images and their corresponding emojis and let the proposed SmileyNet train the relationship between images and emojis. Then they used the pre-trained SmileyNet to fine-tune it in five different downstream tasks. The experimental results show that SmileyNet achieved many SOTA scores on the Twitter Visual Sentiment dataset [33]. Laurenceau et al. [34] studied the influence of different skin tones of emojis on sentiment analysis. EmoGraph2vec [35] adopted a graph neural network to embed emojis. Although these methods achieved remarkable results in their tasks, they still need to exploit emojis’ sentiment information.
For those methods considered emoji descriptions, Gavilanes et al. [18, 19] introduced the descriptions of emojis into a syntactic tree. They modeled the syntactic tree and emoji description. Their method utilized the sentiment information of emojis effectively. The experimental results show that their methods outperform rule-based methods on 13 language datasets. However, these methods have yet to adopt deep learning, especially pre-trained language models, to obtain better language representations. Therefore, it is crucial to fully utilize powerful pre-trained language models as the backbones and the sentiment information inside the emoji descriptions as models’ sentiment enhancement information.
Prompt learning
The pre-trained language models, such as BERT [36] and RoBERTa [37], have shown their power in many natural language processing tasks. However, they needed to introduce additional parameters and fine-tune them to satisfy downstream tasks [38]. With the help of prompt learning, these pre-trained models could predict the desired output without additional task-specific parameters or training [38]. LAMA [39] found that the SOTA models using prompt learning, without fine-tuning, could also provide relational knowledge. GLM [40] used the autoregressive generation in the pre-training stage to generate the masked spans and fine-tuned it with prompt learning for downstream tasks. The experimental results showed that GLM achieved many SOTA scores on the SuperGLUE dataset [41]. Schick and Schutze [42] manually designed many prompt templates for different downstream tasks. Their proposed PET method achieved SOTA results on four datasets with few-shot learning and zero-shot learning. Jiang et al. [43] improved BERT’s performance by manually designing and automatically searching for prompt templates. Their experiments showed that different prompt templates would get different results, and their proposed automatic searching method achieved SOTA results on seven datasets. NSP-BERT [44] solved the problem that prompt learning will map the tokens into a fixed length. It adopted next sentence prediction (NSP) as the pre-training objective of prompt learning and mapped tokens to a variable length space. The experimental results showed that NSP-BERT outperformed other manual prompt learning methods. ConnPrompt [45] adopted prompt learning to let the pre-trained language model learn the conjunctions between contexts. It achieved SOTA results compared to other pre-trained language models. Thus, prompt learning can exploit the language knowledge learned by the pre-trained language models.
Research objectives
In this section, we formally introduce pre-training and fine-tuning objectives.
Pre-training objectives
There are two pre-training objectives: (1) learning the interdependence between different tokens from the input text; (2) inferring the relationships between the input text and the emoji sentiment information. The former aims to obtain text sentiment information based on the words, while the latter aims to obtain emoji sentiment information based on the text and emojis for a given sentence with emojis. In order to achieve these two objectives, the specific methods are as follows.
For the first pre-training objective, given an input text
where
For the second pre-training objective, previous researchers [16, 17, 28] adopted the input text
where
In order to solve this problem, we expect the sentiment model to learn the relationship between the input text and the sentiment information inside the corresponding emoji. Specifically, we adopt BEMOJI to predict the emoji description
where
After pre-training, we need a well-trained sentiment analysis model to predict the sentiment polarity of the sentence with emojis. Previous researchers either adopt the well-trained language model to predict sentiment label
or they predict the sentiment label
where
In our fine-tuning objective, given the input text
To achieve the above research objectives in Section 3, we propose a pre-training BERT model with emojis for sentiment analysis (BEMOJI). At the pre-training stage, we pre-train BEMOJI by predicting the emoji descriptions from the corresponding texts via prompt learning. At the fine-tuning stage, we propose a fusion layer to fuse text representations and emoji descriptions into fused representations. These representations are used to predict text sentiment orientations.
Pre-training BEMOJI
The architecture of pre-training BEMOJI is shown in Fig. 2. We use two individual BERTs [36] as the backbone. The BERT that processes emoji descriptions is denoted as Emoji BERT (EBERT), and the BERT that handles texts is denoted as Contextual BERT (CBERT).
The BEMOJI pre-training framework.
There are two tasks when we pre-train BEMOJI: (1) learning interdependence between different tokens from input texts; and (2) inferring the relationships between texts and emoji sentiment information.
We use traditional MLM to learn the interdependence between different tokens. Specifically, 15% of the tokens in each text are selected for the following operations: (1) In 80% of the time, one selected token is replaced with [MASK]; (2) In 10% of the time, one selected token is replaced with another token in
For the input sentence
where
When we adopt CBERT to represent the input sentence, we feed the hidden state of [MASK] into a fully connected layer and map the dimension of the hidden state to
where
where
We use prompt learning to make BEMOJI learn the relationship between emoji sentiment information and texts. We first convert each text with multiple emojis to one text with one emoji. For instance, “I am going shopping [grin][wink].” will be separated into “I am going shopping [grin].” and “I am going shopping [wink].”. Then, we concatenate a [MASK] into every sentence, which stands for the emoji token, and is used to predict the emoji description. Let the input sentence be
The details of an example: “I am going shopping [grin].”
The details of an example: “I am going shopping [grin].”
Let the token sequence of an input sentence be
Let the BERT processing emoji descriptions be
where
Inspired by BYOL [46], we use the hidden state of the masked token to predict the sentence representations of emoji descriptions, which enables the model to learn the relationships between the sentence and the sentiment information of emoji descriptions. We adopt mean square error, denoted by
In order to balance these two losses, we adopt Cov-Weighting [47] to automatically obtain the weight of the loss. Specifically, CoV-Weighting utilizes the mean and standard deviation of the loss to calculate the coefficient of variation (COV) of the loss. The loss weights are then dynamically adjusted based on these statistics. This approach allows the loss weights to change adaptively during training without the need for manual adjustments or additional optimization processes. The total loss, denoted as
where
BEMOJI fine-tuning framework.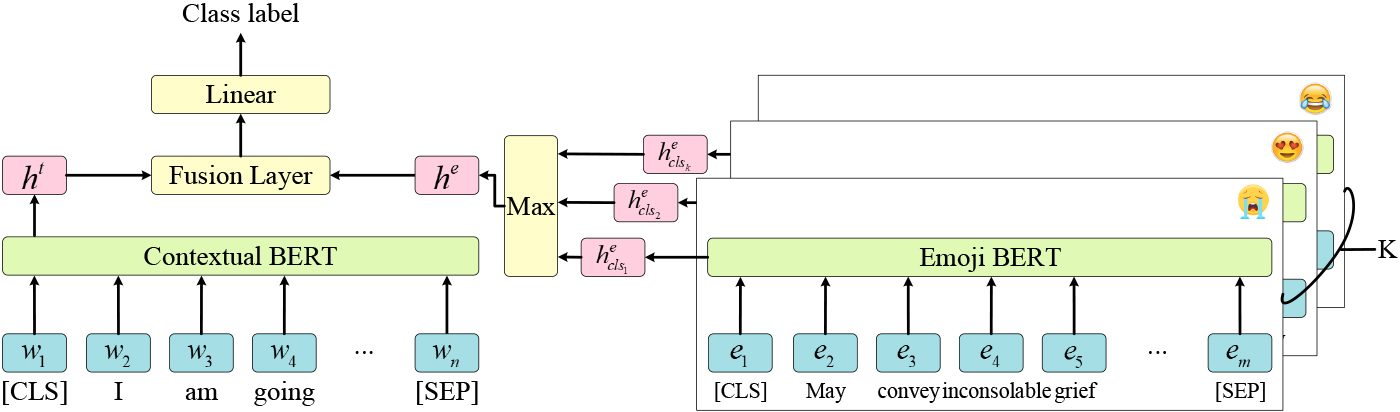
The BEMOJI fine-tuning architecture on downstream tasks is shown in Fig. 3. For each token sequence
Then we use max pooling to obtain the total emoji description representation of these
where
where
where
where
In this section, we present the pre-training and fine-tuning details of BEMOJI and show experimental results on both the Chinese and English datasets.
Datasets and implementation
In order to prove that BEMOJI is applicable in different languages, we choose Chinese and English datasets as experimental datasets.
Pre-training datasets
Since there is no suitable Chinese corpus with emojis, we obtain Chinese data with emojis from Weibo. We capture a total of 39349 posts with emojis. When we split these data into one sentence corresponding to one emoji, there are 42073 data. As for the English dataset, we use the GitHub data [17] as our pre-training dataset. We extract 5,000 data as the experimental dataset, and the remaining 1180401 data are used as pre-training data.
For the enormous cost of training BEMOJI from scratch and the small size of pre-training data, we adopt bert-base-uncased2[36] as the start point of BEMOJI on the English dataset and bert-base-chinese3[51] as the start point of BEMOJI on the Chinese dataset.
Fine-tuning datasets
We manually annotate two emoji sentiment analysis datasets for Chinese and English datasets with emojis as fine-tuning datasets. In order to satisfy the independent and identical distribution of the data, we re-crawl 11636 Weibo data which is different from the pre-training Chinese dataset. Moreover, we extract 5000 GitHub data for the English dataset, in which we label 2767 data. The details of these six datasets are shown in Table 2.
The details of fine-tuning datasets
The details of fine-tuning datasets
We select Weibo emojis that appear more than 100 times, totaling 64 emojis for the Chinese dataset. For the English dataset, there are 64 emojis [17]. Since the appearance of Weibo emojis is different from Github emojis, we convert Weibo emojis into Github emojis.4 Moreover, we obtain Chinese emoji descriptions from EMOJIALL5 and English emoji descriptions from Emojipedia.6 For descriptions, we remove texts unrelated to sentiment and remain the texts with sentiment information. Figure 4 shows three emoji descriptions of both languages.
Knowledge fusion
Since the textual representation
Implementation
We use AdamW optimizer [52] with
The settings of hyperparameters.
stands for the input sequence length, while
represents the emoji description length
The settings of hyperparameters.
Examples of three emoji descriptions in two languages.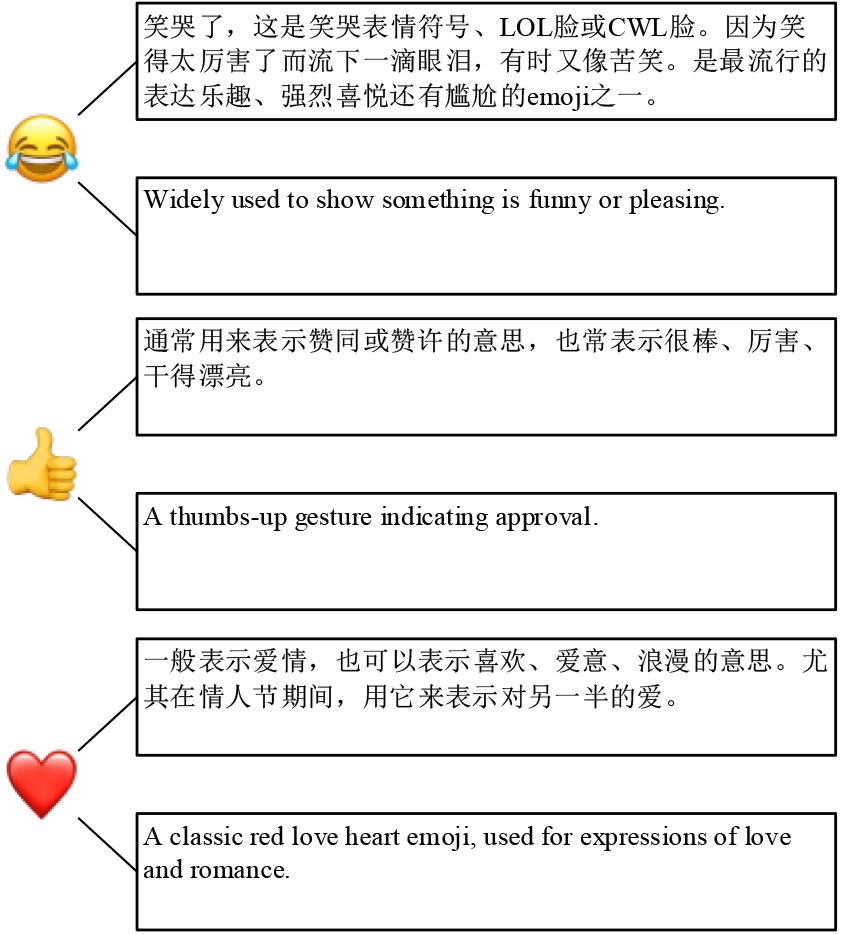
We use accuracy (Acc), macro-precision (Macro-P), macro-recall (Macro-R) and macro-F1-measure (Macro-F1) as models’ evaluation metrics. Let
where
and
As for the accuracy score, let the number of samples whose predicted labels are equal to true labels be
We choose emoji-based methods, including DeepMoji [16], WATT-BiE-LSTM [29] and MATT-BiE-LSTM [29], and other SOTA transformer-based models as our baseline methods. For DeepMoji, WATT-BiE-LSTM and MATT-BiE-LSTM, we use 300-dimensional Word2Vec as the word embedding. For other transformer-based models, we use the pre-trained parameters from Hugging Face as their start points.
DeepMoji [16]
It has two BiLSTM layers and one attention layer. It assigns each emoji a unique embedding and trains emoji embeddings with texts.
WATT-BiE-LSTM [29]
It assigns two different embeddings to each emoji and adopts an attention mechanism to get the correlation between input words and emojis. Since there may be more than one emoji in a sentence, we adopt average pooling to obtain emoji embeddings. Meanwhile, we replace LSTM with BiLSTM.
MATT-BiE-LSTM [29]
Similar to WATT-BiE-LSTM [29], it assigns two different embeddings to each emoji. First, it adopts an attention mechanism to capture the correlation between input sentences and emojis. Then it uses another attention layer to get the correlation between input words and the outputs of the previous attention layer. We also use average pooling to obtain the emoji embeddings. Furthermore, we replace LSTM with BiLSTM.
BERT [36]
It is a typical transformer-based model. It can represent a sentence. BERT will feed the last hidden state of [CLS] into a fully connected network and output the sentiment label.
RoBERTa [37]
It is a more robust BERT. RoBERTa removes the next sentence prediction task from BERT and uses dynamic MLM to mask tokens.
XLNet [53]
It is an autoregressive language model. It randomly shuffles the order of each word in a sentence and masks a certain amount of tokens at the end of the shuffled sentence. Then it predicts these masked tokens by autoregression.
DistilBERT [54]
It is a smaller and faster BERT. It uses BERT as the teacher and only trains itself on the raw data. DistilBERT can learn the same inner representation of the Chinese or English language as BERT, while it can be faster for inference on downstream tasks.
For these transformer-based models, if we choose to pre-train them, we use the pre-training dataset to pre-train them with MLM; if we choose to fine-tune them, we adopt these models to do sentiment analysis tasks on the fine-tuning dataset and fine-tune all parameters of them; and if we choose not to fine-tune them, we also adopt these models to do sentiment analysis tasks on the fine-tuning dataset and only fine-tune the classifier of these models.
Experimental results on the Chinese datasets (%). PT and FT stand for pre-training and fine-tuning, respectively. T and F stand for true and false, respectively. If FT is false, we only fine-tune the classifier. * means that we reproduce the model. The underlining data represents the best results achieved by the baseline models. Bold data indicates the best results for all models
Experimental results on the Chinese datasets (%). PT and FT stand for pre-training and fine-tuning, respectively. T and F stand for true and false, respectively. If FT is false, we only fine-tune the classifier. * means that we reproduce the model. The underlining data represents the best results achieved by the baseline models. Bold data indicates the best results for all models
On the Chinese dataset, we choose DeepMoji [16], WATT-BiE-LSTM [29], MATT-BiE-LSTM [29], BERT (base) [36], RoBERTa (base) [55], RoBERTa (large) [55], XLNet (base) [55], XLNet (mid) [55] and DistilBERT (base) [56] as our baseline methods.
Table 4 shows the experimental results on the Chinese dataset. From these results, we can observe that: (1) BEMOJI with pre-training and fine-tuning achieves the best results on the accuracy, Macro-P, Macro-R and Macro-F1 scores (91.41%, 91.30%, 90.66% and 90.95%, respectively). (2) The best results achieved by BEMOJI are 2.61%, 2.80%, 2.69% and 2.73% higher than the model with the second highest results (i.e., RoBERTa (base) with pre-training and fine-tuning) on the accuracy, Macro-P, Macro-R and Macro-F1, respectively. (3) The lowest scores achieved by BEMOJI (90.45%, 90.41%, 89.37% and 89.91%) are 1.65%, 1.91%, 1.40% and 1.69% higher than the model with the second highest results on the accuracy, Macro-P, Macro-R and Macro-F1 scores, respectively. (4) BEMOJI with pre-training and fine-tuning achieves 3.53%, 3.67%, 3.81% and 3.76% higher than BERT with pre-training and fine-tuning on the accuracy, Macro-P, Macro-R and Macro-F1 scores, respectively. (5) The performance of the emoji-based models is significantly worse than the transformer-based models. Specifically, WATT-BiE-LSTM achieves the highest accuracy, Macro-P, Macro-R and Macro-F1 scores (82.47%, 82.33%, 80.57% and 81.21% respectively) among all emoji-based models. However, the accuracy, Macro-P, Macro-R and Macro-F1 scores of WATT-BiE-LSTM are still 5.41%, 5.3%, 6.28% and 5.98% lower than BERT (base) with pre-training and fine-tuning, and 8.94%, 8.97%, 10.09% and 9.74% lower than BEMOJI with pre-training and fine-tinging, respectively. (6) Models with pre-training and fine-tuning generally perform better than these without pre-training and fine-tuning, indicating the importance of the two strategies in sentiment analysis models on THE Chinese dataset. (7) Compared to all baseline methods, the proposed BEMOJI with/without pre-training and with/without fine-tuning shows the best performance on the Chinese dataset.
In order to better show the performance difference between BEMOJI and other models, Fig. 5 shows the best results achieved by the above eight models on the Chinese dataset.
The best results on the Chinese dataset.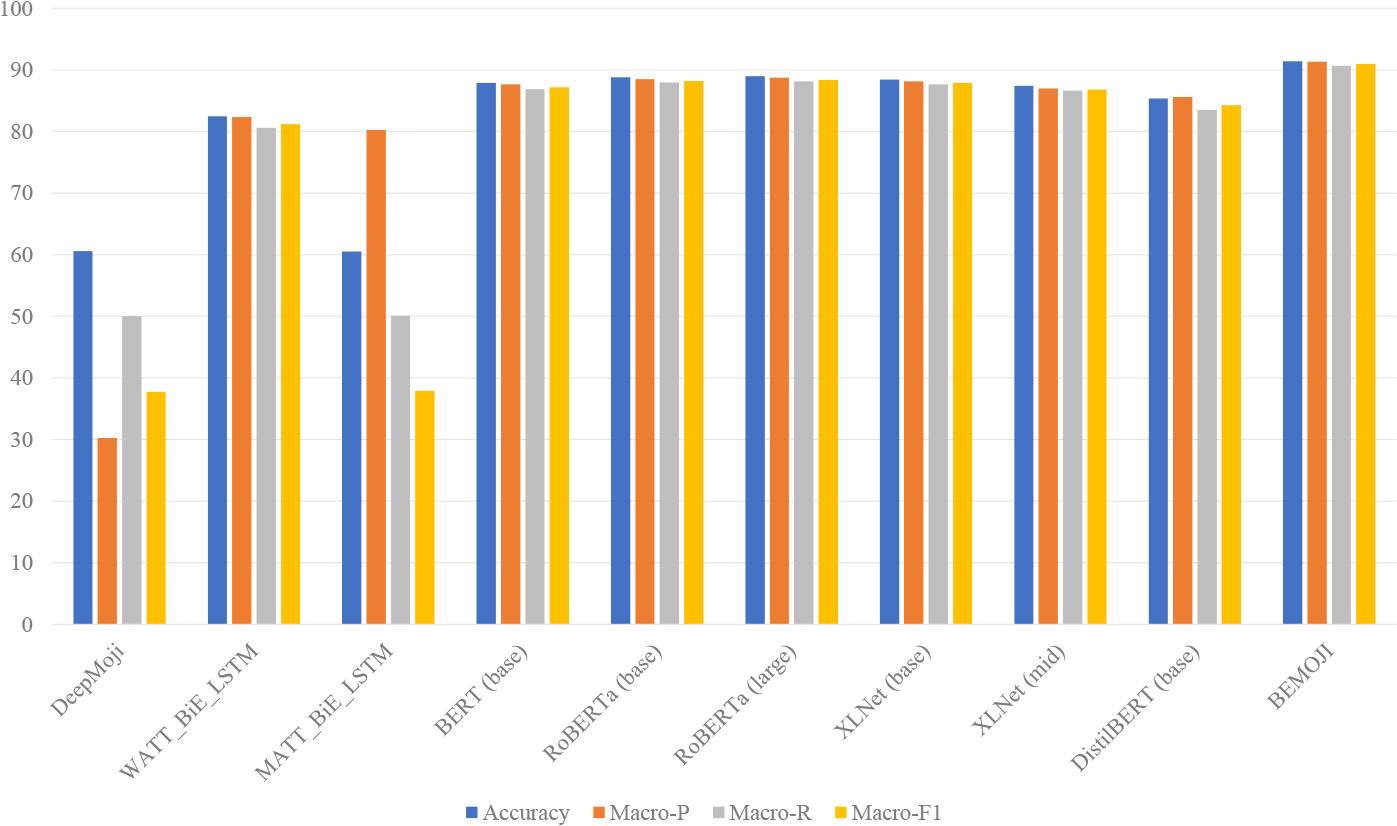
From these observations, we can conclude that: (1) BEMOJI outperforms other transformer-based models, especially BERT (base), because the backbone of BEMOJI is BERT (base), which means emoji descriptions can provide sentiment information. (2) Pre-trained language models outperform RNN-based models.
Experimental results on the English dataset (%). PT and FT stand for pre-training and fine-tuning, respectively. T and F stand for true and false, respectively. If FT is true (T), we only fine-tune the classifier. * means that we reproduce the model. The underlining data represents the best results achieved by the baseline models. Bold data indicates the best results
On the English dataset, we also choose DeepMoji [16], WATT-BiE-LSTM [29], MATT-BiE-LSTM [29], BERT (base) [36], BERT (large) [36], RoBERTa (base) [37], RoBERTa (large) [37], XLNet (base) [53], XLNet (large) [53] and DistilBERT (base) [54] as our baseline methods.
Table 5 shows the experimental results on the English dataset. From these results, we can observe that: (1) Compared to all models, DeepMoji with pre-training and fine-tuning shows relatively low performance across all metrics. (2) WATT-BiE-LSTM with fine-tuning achieves higher scores than DeepMoji with pre-training and fine-tuning. (3) MATT-BiE-LSTM with fine-tuning demonstrates lower performance than WATT-BiE-LSTM with fine-tuning. (4) For BERT (base) and BERT (large) without pre-training and with fine-tuning, the former’s performance is lower than the latter. However, for other cases that have or do not have pre-training and fine-tuning, BERT (base) outperforms BERT (large). (5) For RoBERTa (base) and RoBERTa (large) without pre-training and fine-tuning, the former outperforms the latter. However, for other cases that have or do not have pre-training and fine-tuning, RoBERTa (base) obtains lower performance than RoBERT (large). (6) XLNet (base) [53] and XLNet (large) without pre-training and fine-tuning (or without pre-training and with fine-tuning), the base version outperforms the large version. (7) DistilBERT (base) with pre-training and fine-tuning achieves the best performance compared with the model under other cases. (8) BEMOJI with pre-training and fine-tuning achieves the best results on the accuracy, Macro-R and Macro-F1 scores (93.36%, 93.65% and 93.15%, respectively), while BEMOJI with pre-training and without fine-tuning achieves the best Macro-P score (92.85%). (9) The best results achieved by BEMOJI are 3.47%, 2.84%, 4.66% and 3.74% higher than the model with the second highest results (i.e., RoBERTa (large) without pre-training and with fine-tuning) on the accuracy, Macro-P, Macro-R and Macro-F1 scores, respectively. (10) The lowest scores achieved by BEMOJI (92.58%, 92.00%, 92.84% and 92.34%) are 2.69%, 1.99%, 3.85% and 2.93% higher than the model with the second highest results on the accuracy, Macro-P, Macro-R and Macro-F1 scores, respectively. (11) BEMOJI with pre-training and fine-tuning achieves 4.91%, 4.67%, 5.75% and 5.14% higher than BERT with pre-training and fine-tuning on the accuracy, Macro-P, Macro-R and Macro-F1 scores, respectively. (12) WATT-BiE-LSTM achieves the highest accuracy (89.34%), Macro-P (89.04%), Macro-R (88.93%) and Macro-F1 (88.98%) among all emoji-based models. Meanwhile, WATT-BiE-LSTM achieves comparable results with transformer-based models, which are only 0.55%, 0.97%, 0.06% and 0.43% lower than RoBERTa (large) without pre-training and with fine-tuning on the accuracy, Macro-P, Macro-R and Macro-F1 scores, respectively. However, BEMOJI with pre-training and fine-tuning is still 4.02%, 3.75%, 4.72% and 4.17% higher than WATT-BiE-LSTM on the accuracy, Macro-P, Macro-R and Macro-F1 scores, respectively. (13) Models that utilize both pre-training and fine-tuning generally perform better than these without pre-training and fine-tuning, indicating the importance of the two strategies in sentiment analysis models on the English dataset. (14) Compared to all baselines, the proposed BEMOJI with/without pre-training and with/without fine-tuning shows the best performance on the English dataset.
In order to better show the performance difference between BEMOJI and other models, Fig. 5 shows the best results achieved by the above nine models on the English dataset.
The best results on the English dataset.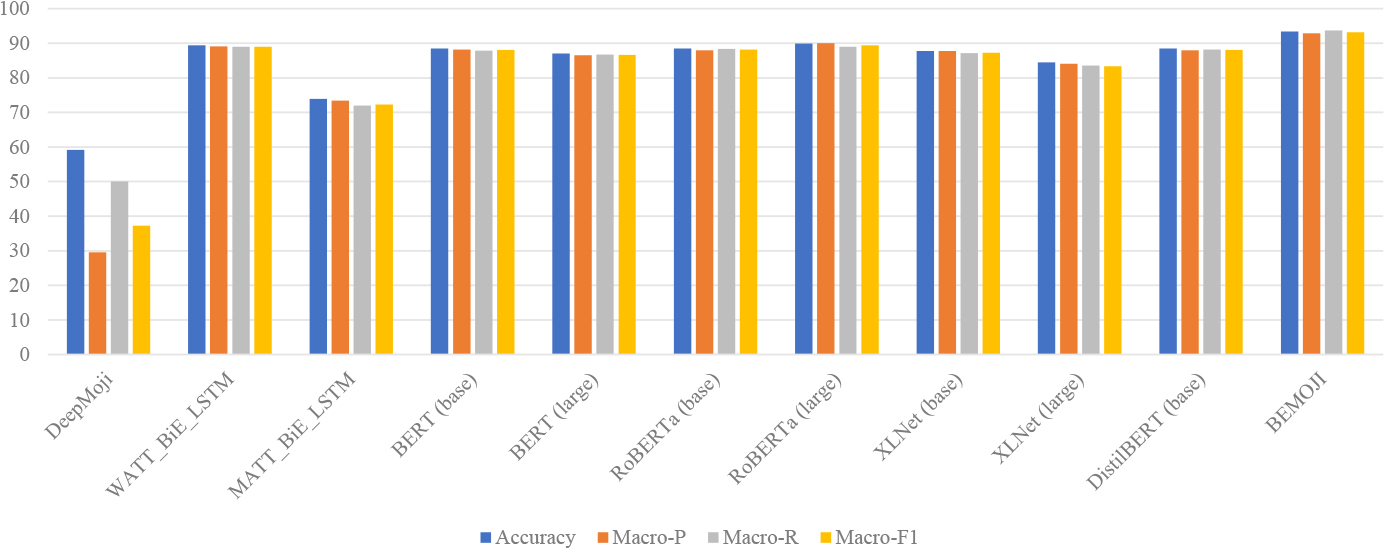
From these observations, we can conclude that: (1) The pre-training and fine-tuning strategies generally improve the performance of sentiment analysis models on the Chinese and English datasets, implying that the two strategies can make good use of text and emoji information in texts with emojis. (2) BEMOJI also outperforms other models on the English dataset, which means emoji descriptions can provide sentiment information. (3) Compared to all baseline methods, BEMOJI obtains the best performance on Chinese and English datasets.
In this subsection, we explore the effects of the emoji descriptions and the fusion layer on BEMOJI.
Table 6 shows the results of the ablation study. From these results, we can observe that: (1) The emojis in the pre-training and fine-tuning stages can make the model better perform sentiment classification when the BEMOJI model does the emoji sentiment analysis task. (2) Without emoji descriptions, the accuracy score achieved by BEMOJI drops by 3.3% (6.64%), and the Macro-F1 score drops by 3.55% (6.92%) on the Chinese dataset (on the English dataset, respectively). (3) Without the fusion layer, the accuracy score achieved by BEMOJI drops by 0.61% (1.17%), and the Macro-F1 drops by 0.68% (1.18%) on the Chinese dataset (on the English dataset, respectively). (4) BEMOJI without emoji descriptions is 0.23% higher than BERT on the accuracy score and 0.21% higher than BERT on the Macro-F1 score on the Chinese dataset, while BEMOJI without emoji descriptions is 1.73% lower than BERT on the accuracy score and 1.78% lower than BERT on the Macro-F1 score on the English dataset. And (5) BEMOJI without the fusion layer is 2.92% higher than BERT on the accuracy score and 3.08% higher than BERT on the Macro-F1 score on the Chinese dataset, while BEMOJI without the fusion layer is 3.74% higher than BERT on the accuracy score, and 3.96% higher than BERT on the Macro-F1 score on the English dataset.
From these observations, we can conclude that: (1) Emoji descriptions and the fusion layer can help BEMOJI to achieve better performance. (2) Since the backbone of BEMOJI is BERT (base), the performance of BEMOJI without emoji descriptions is similar to BERT (base), which means emoji descriptions provide a lot of sentiment information.
Ablation study on the Chinese and English datasets (%). Experimental results are output from the pre-trained and fine-tuned models
We adopt four sentiment analysis datasets without emojis (two datasets are Chinese datasets, and the other are English datasets) to illustrate the robustness of BEMOJI. We adopt the SST-2 [57], SemEval-2013 Task 2 [58], NLPCC-2014 Task 1,7 and SMP2019-ECISA8 datasets. For SemEval-2013 Task 2, we only consider positive, negative and neutral sentiments; for NLPCC-2014 Task 1, we only classify whether the text carries sentiment. The details of these four datasets are shown in Table 7.
The details of robustness study datasets
The details of robustness study datasets
We compare BEMOJI and BERT (base) on these four datasets. For BEMOJI, we only utilize the pre-trained
The robustness study results are shown in Table 8. From these results, we can observe that: (1) BERT (base) achieves a higher accuracy score on SST-2 (93.5%) and a higher Macro-F1 score on SemEval-2013 and SMP2019-ECISA (73.27% and 77.89%), while BEMOJI achieves a higher accuracy score on SemEval-2013 and NLPCC2014 (73.93% and 80.30%) and a higher Macro-F1 on NLPCC2014 (76.12%). (2) BEMOJI is 2.3% lower than BERT on the accuracy score on the SST-2; BEMOJI is 0.19% higher than BERT on the accuracy score, and 0.63% lower than BERT on the Macro-F1 score on the SemEval-2013; BEMOJI is 0.34% lower than BERT on the Macro-F1 score on the SMP2019-ECISA, and BEMOJI is 1.26% higher than BERT on the accuracy score, and 0.81% higher than BERT on the Macro-F1 score on NLPCC2014.
From these observations, BEMOJI has strong robustness and can achieve comparable results to BERT on non-emoji sentiment analysis tasks.
Robustness study on non-emoji sentiment classification tasks (%)
In this subsection, we select some Chinese and English quotes as inputs to BEMOJI and BERT in order to analyze the resulting emojis predicted by these two models. This experiment aims to evaluate the models’ ability to accurately represent the sentiments conveyed in the input texts through the resulting emojis.
The experimental results of case studies. The value inside the parentheses refers to the cosine similarity between the sentence embedding of an input text and an emoji description. And the average value refers to the average similarity between the sentence embedding of the top 5 emoji descriptions and the input sentence.
In this study, we utilize two well pre-trained models, including BEMOJI and BERT, to learn the correlation between input text
Based on these results, we can observe that: (1) BEMOJI can output more appropriate emojis than BERT. And (2) the cosine similarity between the sentence embedding of an emoji description generated by BEMOJI and an input sentence is higher than BERT. From these observations, we can conclude that the correlations between texts and emoji descriptions during the pre-training stage can enhance the ability of the sentiment analysis model to learn the association between texts and emojis.
Experimental results show that the proposed BEMOJI improves the performance of sentiment analysis by using prompt learning on both Chinese and English datasets. Tables 4 and 5 show that BEMOJI outperforms emoji- and transformer-based models on the Chinese and English datasets. Compared with transformer-based models, BEMOJI can achieve better results than other transformer-based models on the sentiment analysis of sentences with emojis. The main reason is that BEMOJI considers emoji information at the pre-training and fine-tuning stages. Meanwhile, compared with other emoji-based models, BEMOJI achieves higher results than other emoji-based models. The reason is that BEMOJI adopts a powerful pre-trained language model as its backbone. The pre-trained language models can better represent sentences than RNN-based models. In addition, DeepMoji [16], WATT-BiE-LSTM [29] and MATT-BiE-LSTM [29] only treat emojis as unique tokens, and adopt different embeddings to represent them, which ignores the sentiment information inside emojis. Furthermore, BEMOJI adopts prompt learning to force the model to learn the correlations between input sentences and corresponding emojis, which makes BEMOJI can better learn the sentiment information inside emojis.
Table 6 shows the ablation study results. From these results, we can conclude that emoji information helps BEMOJI to achieve better results. Without emojis, BEMOJI obtains comparable results with BERT (base). That is because the backbone of BEMOJI is BERT (base). Meanwhile, the proposed fusion layer is essential for BEMOJI because it fuses two different representations into the same vector space.
Table 8 shows the robustness study results. From these results, we can conclude that BEMOJI is a robust model. When we remove emoji information, BEMOJI can still finish the sentiment analysis tasks.
Figure 7 shows the case study results. From these results, we can find that pre-training BERT model with texts and emoji descriptions can well understand the associations between them.
Based on the discussion above, the proposed BEMOJI model achieves the best performance compared with the existing models.
Conclusion
This paper proposed a BEMOJI model to incorporate emoji sentiment information into language representation models. Specifically, we used prompt learning to pre-train BEMOJI to learn the relationship between emoji description and text. When we fine-tuned BEMOJI on downstream tasks, we fused emoji description and text representation so that BEMOJI could better understand text sentiment. The experimental results illustrated that BEMOJI analyzed the sentiment of texts with emojis better than other baseline methods. The ablation study illustrated that the emoji descriptions and the fusion layer could make BEMOJI perform well. BEMOJI also has strong robustness in analyzing the sentiment of texts without emojis. Case study shows that BEMOJI can produce more appropriate emoji than BERT.
However, some issues still need to be solved for future research: (1) The pre-trained language representation models are fragile [59], and a slight change will affect the emojis output by the model. A problem is how to make the model more robust and output more reasonable emojis. (2) Texts and emojis expressed by many people are sarcastic. How to identify these sarcastic texts and emojis is another study problem. (3) Abundant real-world corpora are collected to enrich pre-training data.
Date availability
The data used to support the findings of this study are available from the corresponding author upon request. All source codes are available at
Authors’ contributions
The authors claim that the research was realized in collaboration with the same responsibility. All authors read and approved the last version of the manuscript.
Footnotes
Since the number of emojis is small, we fix all the parameters of
Acknowledgments
The authors would like to appreciate the editors’ and anonymous reviewers’ helpful comments and constructive suggestions, which have improved the quality of this manuscript. This work is partially supported by the Sichuan Science and Technology Program (Nos. 2022YFG0378, 2023YFS0424, 2023YFH0058 and 2023YFQ0044), Yibin Science and Technology Program (No. 2023SF004), Engineering Research Center for ICH Digitalization and Multi-source Information Fusion (Fujian Polytechnic Normal University), Fujian Province University (No. G3-KF2022), and Innovation Fund of Postgraduate, Xihua University (Grant No. YCJJ2021025, YCJJ2021031 and YCJJ2021124).
Conflict of interest
All authors declare no conflicts of interest.