
Abstract
Person re-identification relies on discriminative features. However, most researches focus on extracting features from the high-layer of network while ignoring the middle-layer features, some important details are overlooked frequently. To address this issue, we propose a Multi-Scale and Multi-Patch Feature Fusion Network(MSPF). We employ modified OSFA to extract, align, and fuse the feature maps in the middle-layer of network, which can compensate for the lack of detailed information in the high-level network features. To obtain richer detailed global features of pedestrian, we construct a multi-patch feature fusion module(MPF). We concatenate the global features extracted from modified OSFA and MPF to obtain global features with richer detailed representations. Cross-entropy loss, triplet loss and center loss are combined to constrain our model. We evaluate the performance of our model on Market-1501, CUHK03_labeled and DukeMTMC. The results prove that our method is superior to the state-of-the-art approaches.
Introduction
Person re-identification aims to distinguish identities from person images captured by diverse cameras. Given a full-body image of one person we care about(Query), then we need find the closest image or images from database(Gallery) to that person. Person re-identification is a extremely challenging task. When a single person is captured by diverse cameras, observable human body parts, the illumination conditions, background clutter, and occlusion can be extremely different. Even within the same camera, the above-mentioned conditions may vary due to human movement and other factors. Therefore, it becomes difficult to obtain relevant features.
Early researches focus on discriminative feature representation [1–3] or distance metrics [4, 5] or their combination in a deep learning framework [6, 7]. However, these methods tend to lose some detailed features with high time complexity. With the increasing computational power of computers, the outstanding performance of convolutional neural networks(CNN) in person Re-ID has been extensively recorded [8–13]. Some studies regarded pedestrian re-identification as a multi-classification problem and only utilized global-scale features [11–13]. However, these methods can not solve pedestrian occlusion problem well, and background clutter in pedestrian images can make it difficult to extract the global-scale features. To solve the above problem, in recent years, researchers proposed to fuse global-scale and local-scale features to extract more discerning feature representations [14–16]. Extracting local-scale features from multiple parts of pedestrian image and then fusing the local-scale features with the global-scale features are robust to factors like occlusion and background clutter, and can produce better results. But simply fusing local and global features still does not bring terrific results.
For the past few years, multi-scale feature combination(fusing local features extracted from diverse convolutional layers) for person re-identification has received much attention. For example, Wang [19] fused features cross different scales to emphasize ID related factors and ignore irrelevant factors. Rao et al. [18] proposed a multi-scale graph relation network to learn structural relations so as to capture more discriminative skeleton graph features. Huang et al. [19] proposed a multi-scale feature combination network. It combines structural feature information with global comprehensive feature information of person image through a convolution neural network, which can effectively retain distinguishing detail information. Combining the multi-scale features with the global-scale features can extract enough discriminative features of person. Though it performs well in person Re-ID and has higher identification accuracy than that of other single-scale methods, it increases the complexity of network. Therefore, it is necessary to find a lightweight network for the multi-scale feature person re-identification task.
A lightweight network with small number of parameters is less prone to overfitting and can reduce complexity of model. Fortunately, a number of lightweight networks have been proposed for various recognition tasks [20–22]. F et al. [21] evaluated and compared some lightweight networks like ResNet-50 and GoogleNet which proved themselves in object recognition tasks. Jha et al. [22] proposed a novel Lightweight Attribute Localizing Model (LWALM) for pedestrian attribute recognition. It demonstrated a significant reduction in parameters and computational complexity with less than 2% accuracy drop. Based on the research of lightweight network, combining the multi-scale feature learning, [12] designed a novel deep re-ID CNN termed omni-scale network (OSNet). This is achieved by designing a residual block composed of multiple convolutional streams and each detecting features at a certain scale. OSNet is lightweight since its building blocks involve factorized convolutions. In particular, OSNet exploits the multi-layer information of network, so it can learn discriminative pedestrian representations under the optimization of multiple losses, which is thus that many works employ it as the basic backbone network [23–25]. Especially, Li et al. [30] proposed an Omni-Scale Feature Aggregation method (OSFA) with OSNet as backbone. OSFA can exploit the multi-layer discriminative pedestrian features, learn discriminative pedestrian representations, and reduce model complexity of network.
Based on the above situations, in this paper, we consider employing OSNet as the basic CNN backbone network. Furthermore, we construct a multi-patch feature fusion module(MPF). Feature aggregation over multi-patch can extract rich detailed global features of pedestrian and has been widely used in image classification task [26, 31]. The contribution of this work is summarized as follows:
We employ Omni-Scale Feature Aggregation Network(OSFA) [30] to exploit the multi-layer discriminative pedestrian features and learn discriminative pedestrian features based on global and local representation learning. Different from OSFA, we put Spatial Attention Module behind Channel Attention Module since Woo et al. [36] confirmed that there can be better performance when Spatial Attention Module is behind Channel Attention Module. We construct a multi-patch feature fusion module(MPF) by using OSNet as baseline to extract discriminative pedestrian global features. Then we concatenate the global features extracted from modified OSFA and MPF to obtain richer detailed global features. We evaluate our method on three benchmark person Re-ID datasets: Market-1501, CUHK03_labeled and DukeMTMC, compare the performance with some advanced Re-ID models, and confirm that our method outperforms the other methods in person Re-identification task.
Related work
Based on the above researches, combining multi-scale, multi-patch, and lightweight network, we propose a Multi-Scale and Multi-Patch Feature Fusion Network(MSPF) for person re-identification task. MSPF includes two parts: modified OSFA and multi-patch feature fusion module(MPF). Modified OSFA is used to extract rich local and global features. MPF is used to extract richer discriminative global features of pedestrian. Detailed descriptions are given in section 3.
Our proposed network architecture
In this section, we describe the proposed Multi-Scale and Multi-Patch Feature Fusion Network(MSPF) in detail.
Network architecture overview
Our network architecture consists of modified OSFA and multi-patch feature fusion module(MPF), which can be described as follows:
Modified OSFA is illustrated in Fig. 1. OSFA [30] can extract global features and local features simultaneously by using OSNet as the baseline. Compared with traditional baselines, OSNet is lightweight and has lower computational costs. OSFA consists of two parts: baseline and Smooth Aggregation Module(SAM). The baseline can learn the abstract and concrete information in the underlying features by employing an attention mechanism to the middle of network. The attention module is composed of Position Attention Module and Channel Attention Module, which can decrease the influence of background clutter. Channel Attention Module is behind Position Attention Module in OSFA. Different from OSFA, we employ Spatial Attention Module and Channel Attention Module in the second block from the baseline, and put Spatial Attention Module behind Channel Attention Module. CBAM [36] has confirmed that there can be better performance when Spatial Attention Module is behind Channel Attention Module. Inputting an image into the baseline, after Global Max Pooling, we can obtain a 512-dimensional global feature vector f G . Smooth Aggregation Module(SAM) can extract the multi-scale feature maps from different layers and fuse them to obtain the local features f L . Cross-entropy loss, triplet loss and center loss are employed to constrain the model, which is helpful for our network learning robust pedestrian image information.
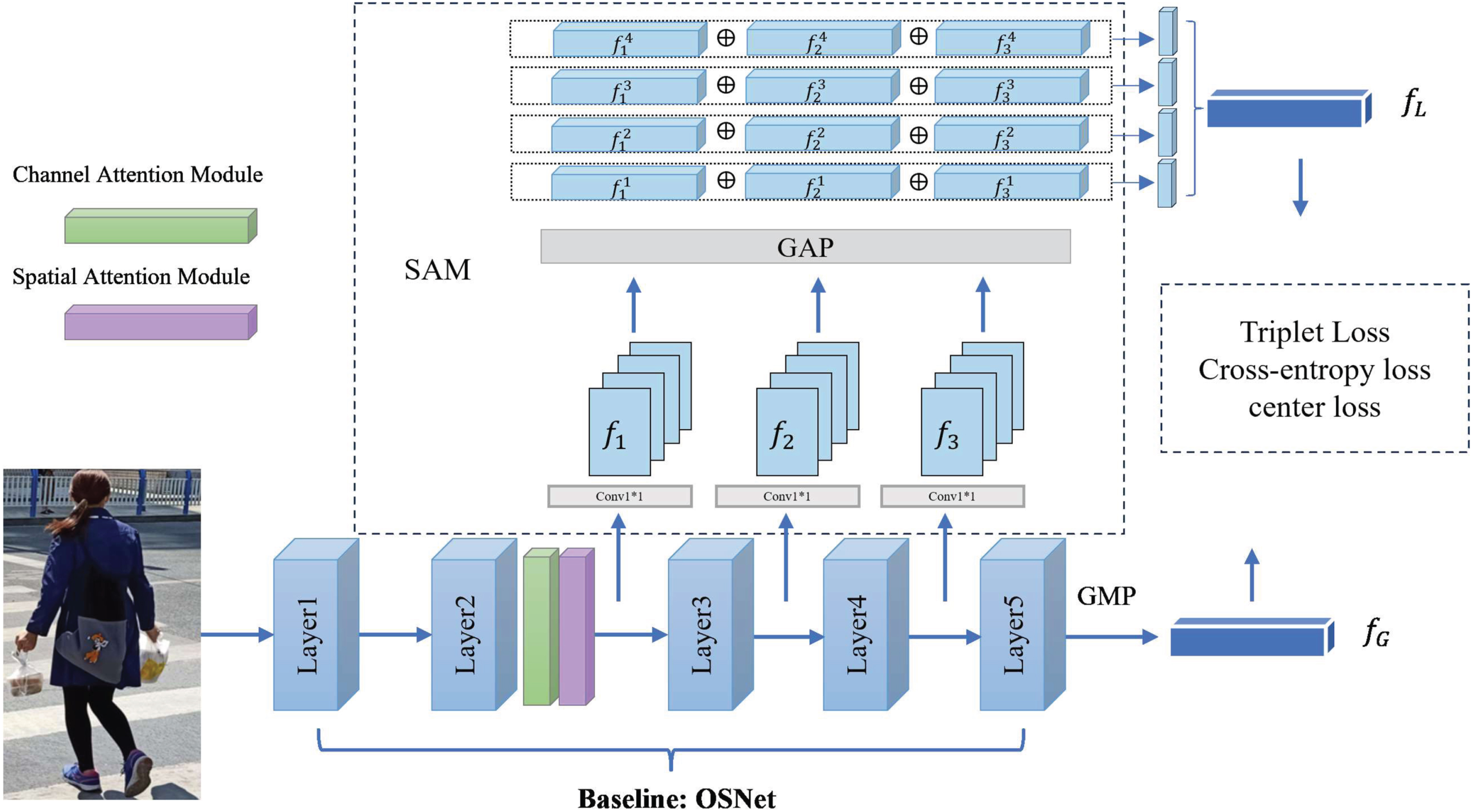
The framework of modified OSFA. It consists of two parts: Omni-Scale Network(OSNet) and Smooth Aggregation Module(SAM). OSNet is used as the CNN backbone to extract the high-level global feature f G . Smooth Aggregation Module (SAM) is used to fuse multi-scale features to obtain local feature f L . Cross-entropy loss, triplet loss and center loss are employed to constrain the model.
Multi-patch feature fusion module(MPF) is illustrated in Fig. 2. MPF contains two levels: the initial pedestrian image is divided into 4 patches as input at the 2-level(P2), and divided into 2 patches as input at the 1-level(P1). The 1-th level is of half patch size of the 2-th level. Each level of MPF consists of OSNet and Global Max Pooling. The output from lower level (corresponding to finer grid) is added to the output from upper level (one level above) so that the output from the top level contains all the information extracted from the finer level, which helps us to obtain the global feature
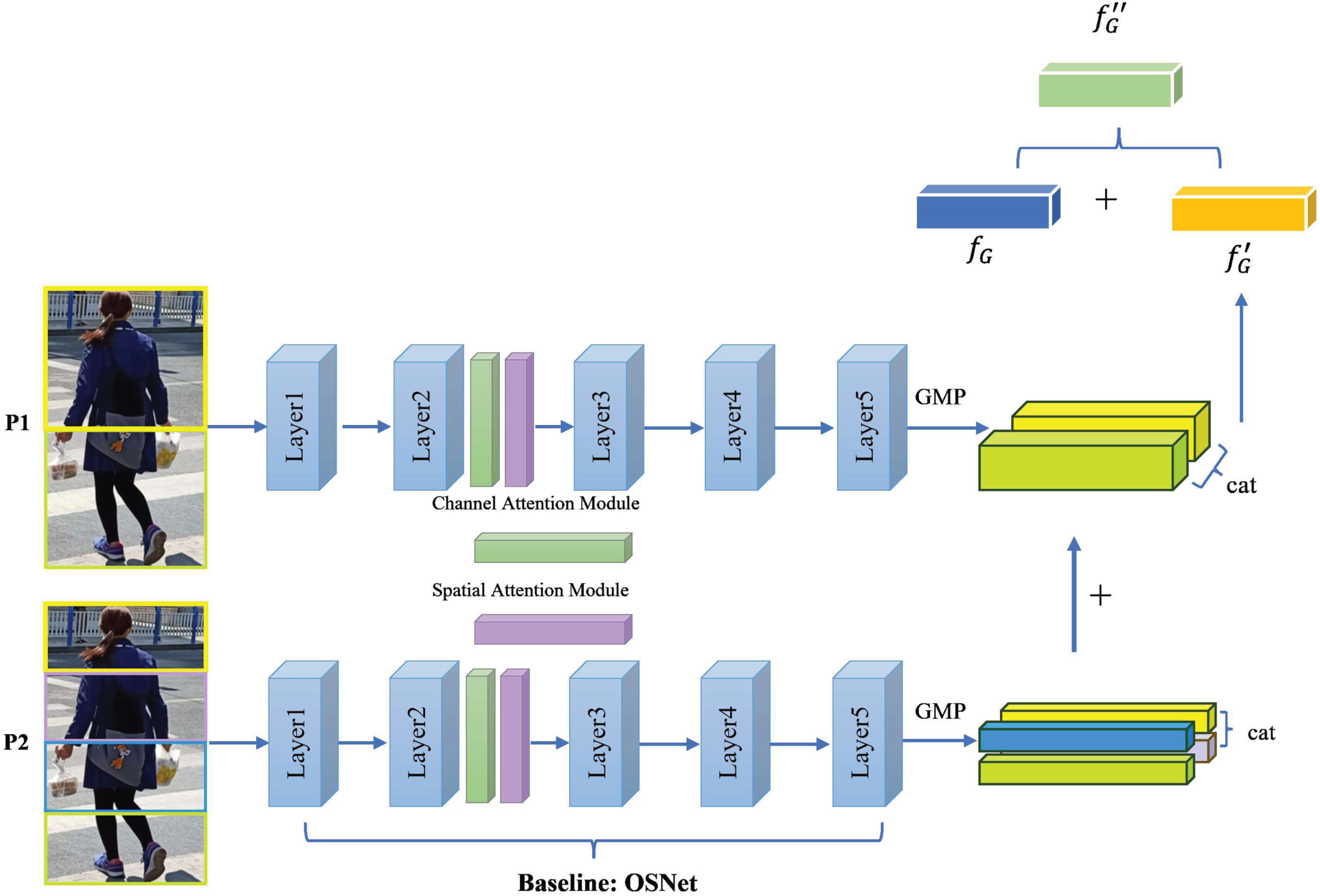
The framework of multi-patch feature fusion module(MPF). It contains two levels. Images with multi-patches are sent to the two baseline to obtain global feature
Like most person re-identification tasks, we also use metric loss and classification loss as constraints in this paper. In order to represent the difference between inter-class and intra-class better, we employ multiple loss functions to strengthen the feedback to the network. The total loss can be expressed as the weighted sum of the following three losses:
In the meanwhile, to enhance this inter-class discrimination, we employ cross-entropy loss with label-smoothing regularization:
Besides, we add the center loss to the above loss:
Implementation details
Our model is based on the pre-trained OSFA and built on the PyTorch framework. The size of training image is reset to 256 × 128. Then, we feed a batch size of 64 data randomly selected into the network to avoid overfitting. During testing, the test images are also resized to 256 × 128. Our model is trained for 200 epochs. The values of α1, α2 and the learning rate are set to 1, 0.0007, 3.5e - 5, respectively. In SAM, the number of horizontal parts is set to 4. All experiments are executed with a hardware environment as 11th Gen Intel(R) Core(TM) i7-11800H @ 2.30GHz and NVIDIA GeForce RTX 3060.
Datasets and settings
In this paper, we use three popular person Re-ID datasets to evaluate the performance of our proposed MSPF model. The three datasets statistics are provided in Table 1.
Summary of three popular person Re-ID datasets
Summary of three popular person Re-ID datasets
We compare the performance of our model MSPF with that of other recent methods. Our model achieves state-of-the-art results on Market-1501, CUHK03, and DukeMTMC both in terms of Rank-1 and mAP. The comparison results on Market-1501 are shown in Table 2. We can see that our model is 1.2% and 0.9% ahead of OSFA on Rank-1 and mAP, respectively, and has better performance than other methods on Rank-1 and mAP.
Performance comparison on Market-1501 dataset
Performance comparison on Market-1501 dataset
Since OSFA [30] shows that the performance on CUHK03_detected dataset is unsatisfied, we do the experiment only on CUHK03_labeled dataset. The comparison results on CUHK03_labeled are shown in Table 3. The accuracy of Rank-1 and mAP are 2.8% and 1.2% higher than that of OSFA.
Performance comparison on CUHK03_labeled dataset
The comparison results on DukeMTMC dataset are shown in Table 4. We can see that our model outstrips OSFA on Rank-1/mAP by 0.5% /0.6% and has better performance than other methods on Rank-1 and mAP. Experiment results show that: Our model has high performance in pedestrian re-identification task.
Performance comparison on DukeMTMC dataset
As shown in Fig. 2, MPF includes two levels. To determine the effectiveness of multi-patch, we conduct experiments on Market-1501 and DukeMTMC. Then we compare four variations of MPF: MPF with 2-4-8 patches, regular MPF with 2-4 patches, MPF with only 2 patches and model without patches. The result is shown in Table 5. We can see that MPF with 2-4 patches can achieve the best result. Therefore, we can confirm that our proposed MPF is helpful for obtaining richer detailed global features of pedestrian.
Effectiveness of multi-patch on mAP and Rank-1
Effectiveness of multi-patch on mAP and Rank-1
In modified OSFA framework, we insert a attention module composed of CAM and SAM into the baseline to extract global features. To determine the effectiveness of attention module, we conduct experiments on Market-1501 and DukeMTMC datasets and compare five variations of MSPF(the same MPF module with 2-4 patches): MSPF without attention module, MSPF with SAM or CAM, MSPF with CAM behind SAM and regular MSPF. The mAP and Rank-1 results are shown in Table 6. After adding SAM or CAM to the network, the accuracy of Rank-1 and mAP on Market-1501 dataset are improved by approximately 1% and 3%. When simultaneously utilizing SAM and CAM, the network can enhance the learning ability of samples in terms of pixels and channels. Therefore, we confirm that attention module is meaningful for obtaining richer detailed global features.
Effectiveness of attention module on mAP and Rank-1(× means not using the attention, ✓ means using the attention)
Effectiveness of attention module on mAP and Rank-1(× means not using the attention, ✓ means using the attention)
To confirm the utility of our model, we use self-constructed dataset for testing. The dataset includes 300 pictures of 30 pedestrians captured by the same camera. Each person has about 10 images. All images are hand-cropped with size 256 × 128. The testing set includes 30 images in query set(each pedestrian is provided with one query image.) and 270 images in gallery set. Three example query images are shown in Fig. 3. Each sub-figure contains, from left to right, a query image, two true matches, and three false matches (distractor). In the three sets of images, the three false matches are similar to the query image due to the influence of illumination and image resolution. Since we construct our model based on OSNet [12] and OSFA [30], we compare the performance of our model with that of OSNet and OSFA on the dataset. The testing result is shown in Table 7. We can see that both our model and OSFA have good performance with Rank-1 100%, and our model has 3.5% and 0.2% higher performance than OSNet and OSFA on mAP, respectively. Therefore, we demonstrate the utility of our model in the real world.
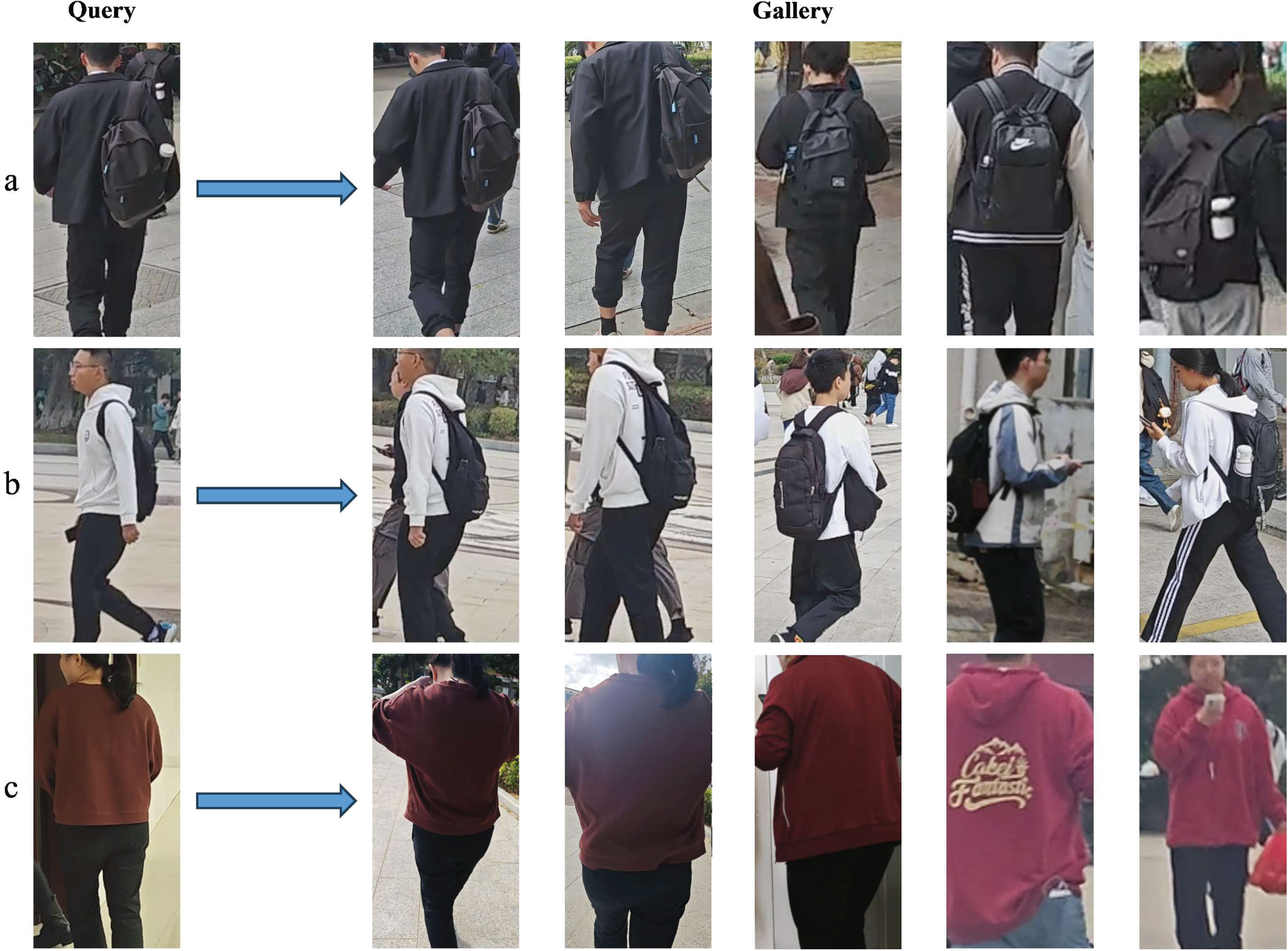
Three example query images. Each sub-figure contains, from left to right, a query image, two true matches, and three false matches (distractor).
Performance comparison on self-constructed dataset
In this paper, we propose an novel Multi-Scale and Multi-Patch Feature Fusion Network(MSPF) for pedestrian re-identification task. To enhance the feature extraction capability of the network, we first employ modified OSFA to extract global and local features. Smooth Aggregation Module(SAM) of OSFA can extract rich detailed information of the shallow network to obtain local features. Then we construct a multi-patch feature fusion module(MPF) to extract richer global features of pedestrian. Under the constraint of multiple losses, our model can learn robust feature representations. Finally, we compare the performance of our model with that of other methods on Market-1501, CUHK03_labeled, and DukeMTMC. Experiment results show that our model is superior to the state-of-the-art methods in person re-identification task. In addition, we do experiments on self-constructed dataset. Experiment results confirm the utility of our model in the real world.
Acknowledgements
The work is partially supported by School-level Scientific Research Found Projects at Minnan University of Science and Technology(Grant No.23KJX017).