
Abstract
In recent years, sequential recommendation has received widespread attention for its role in enhancing user experience and driving personalized content recommendations. However, it also encounters challenges, including the limitations of modeling information and the variability of user preferences. A novel time-aware Long-Short Term Transformer (TLSTSRec) for sequential recommendation is introduced in this paper to address these challenges. TLSTSRec has two major innovative features. (1) Accurate modeling of users is achieved by fully leveraging temporal information. Time information is modeled by creating a trainable timestamp matrix from both the perspectives of time duration and time spectrum. (2) A novel time-aware Transformer model is proposed. To address the inherent variability of user preferences over time, the model combines long-term and short-term temporal information and adjusts the personalized trade-offs between long-term and short-term sequences using adaptive fusion layers. Subsequently, newly designed encoders and decoders are employed to model timestamps and interaction items. Finally, extensive experiments substantiate the effectiveness of TLSTSRec relative to various state-of-the-art sequential recommendation models based on MC/RNN/GNN/SA across a spectrum of widely used metrics. Furthermore, experiments are conducted to validate the rationality of the TLSTSRec structure.
Introduction
Sequential recommendation has become a focal point of research in the field of recommendation systems, introducing novel methodologies to meet users’ dynamic needs. Traditional recommendation methods, such as content-based recommendation [1] and collaborative filtering [2], although capable of providing valuable suggestions to users to some extent, are often static and struggle to capture users’ changing behaviors and preferences. In contrast, sequential recommendation models possess unique advantages, dynamically modeling user-item interactions and capturing sequential patterns [3,4]. This implies that these models can more accurately comprehend users’ interests and needs, thereby delivering more personalized and precise recommendations. Consequently, sequential recommendation models have received extensive research attention in recent years and have been effectively implemented in a number of fields., including film and music recommendations, e-commerce, tourism, and other applications [5,6].
The perpetually dynamic nature of user preferences presents a substantial challenge for user modeling, particularly in large-scale recommendation systems. On a daily basis, millions of new interaction data are integrated into the existing candidate pool [7]. Due to the periodic emergence of new trends and popular topics, users’ attention undergoes continuous fluctuations. Hence, it is imperative for recommendation systems to accord sufficient emphasis to short-term preferences. Simultaneously, users’ interests exhibit stability and long-term characteristics, requiring sequential recommendation models to proficiently apprehend the dynamic characteristics of short-term preferences and the enduring constancy of long-term preferences.

An example of a user-item interaction sequence for a user.
Recent studies have revealed a common drawback in most existing self-attention (SA)-based sequential recommendation models. They inadequately utilize the time information associated with user-item interactions (timestamps) [8,9,10]. This observation has prompted our contemplation on enhancing sequential recommendation models. The majority of prevailing SA-based sequential recommendation models predominantly depends on incorporating positional embeddings to delineate the sequence of elements. While position embeddings serve their purpose, they do not fully consider the temporal dimension. This paper addresses the problem by innovatively capturing both long-term and short-term preferences, along with timestamp information. From the perspective of temporal length, a novel computation of time weights distinguishes time since the last interaction, allocating information with varying time spans to different attention layers, and finally consolidating them. This approach is justified by the time sensitivity in recommending the next interaction, where recent user behavior (short-term) typically holds more significance than actions or records from a long time ago (long-term) [11,12]. From the viewpoint of the time spectrum, a newly designed window function facilitates smoother weight calculations for time information, minimizing attention to time information outside the window, and thereby enhancing precision. Figure 1 illustrates two distinct interaction patterns for users – Andy and Mary. For Andy, his next project relies on the local features of his historical project sequence, dependent on his short-term interactions. In contrast, Mary’s next project is more influenced by her global interaction interests, necessitating the incorporation of both long-term and short-term information, as well as temporal information, for SA-based models to better capture user behavior patterns.
In this paper, a novel Time-Aware Long and Short-Term Transformer for Sequential Recommendation (TLSTSRec) is proposed. The model introduces a redesigned treatment of time information, a unique feature among self-attentive Sequential Recommendation. In recent studies, TAT4SRec [13] and TiSASRec [14] have utilized time information in SA-based sequential recommendation models. However, TiSASRec does not fully exploit the inherent continuity dependencies in timestamp information, and TAT4Rec lacks a clear distinction between long-term and short-term information, resulting in limited capturing capabilities for time information of different spans.
Our main contributions are as follows:
A novel time-aware Transformer model is proposed, which combines long-term persistent preferences with short-term immediate interests. It adjusts the personalized trade-offs between long-term and short-term sequences through adaptive fusion layers. This configuration enhances the model’s ability to comprehensively and effectively capture information. For timestamp information, a trainable timestamp matrix is utilized to model temporal information by incorporating both time duration and spectrum. This innovative multidimensional temporal information modeling approach allows for more effective adaptation to the continuously evolving patterns of user behavior over time. We conducted extensive experiments, and the results demonstrate that our model outperforms other state-of-the-art models in prediction accuracy. Furthermore, in Section 4.6, the effectiveness of our model is further validated through the visualization of the distribution of time embedding vectors.
Sequential recommendation
Traditional recommendation systems methods, such as collaborative filtering and content-based recommendation [15,16], have been widely researched and applied primarily to address the issue of information overload. These methods typically employ a static modeling approach to capture users’ general preferences for items and make recommendations based on them. However, this static modeling approach may not be entirely applicable in many real-world scenarios. Specifically, in the real world, user interests and the popularity of items often undergo constant changes [11]. For example, over time, users may develop an interest in new movies, books, or music, while old preferences may gradually fade. Similarly, certain items may suddenly become very popular due to events or marketing activities. More importantly, interactions between users and items often exhibit sequential dependencies, meaning a user’s current choices may be influenced by their past behavior. Therefore, to more accurately capture this dynamism and sequential dependency, it is imperative for recommendation systems to introduce sequence dependency for more precise recommendations.
In the literature, early works primarily utilized Markov chain models [17] to propose personalized recommendations for the next step based on previous user actions. However, these methods only capture adjacent positions and struggle with handling long-term dependencies. Subsequently, neural network-based models rapidly advanced. Recurrent Neural Networks (RNNs), through sequential dependency relationships and memory mechanisms, enhanced recommendation performance across various tasks [18,19]. However, RNNs also face challenges in capturing long-term dependencies. Simultaneously, The utilization of Convolutional Neural Networks (CNNs) aimed to capture local features within sequences, with a particular emphasis on the influence of recent user behavior [20]. Due to issues like gradient vanishing or exploding, GRU4Rec
Attention mechanism
Attention mechanisms are widely popular in various tasks such as image/video captioning [26], machine translation [27], and recommendation [28]. Specifically, models based on self-attention (SA), like Transformer [25], have achieved remarkable performance in the NLP and CV domains. The key to the SA mechanism is its ability to effectively capture long-distance dependencies between different parts of the sequence [29], which is crucial for sequential recommendation. Multi-head attention, an integral part of the SA mechanism, allows the model to simultaneously focus on different parts of the input sequence, thereby better capturing its internal structure. Recent research has proposed improved models, such as SASRec [9], which is a groundbreaking model based on self-attention (SA) that leverages the encoder component of the Transformer. Its enhanced version, FDSA [10], independently models both items and features. Models like BERT4SessRec [30] apply the SA mechanism to model user-item interaction sequences. These models leverage the advantages of the SA mechanism to more effectively handle long-term dependencies, thereby enhancing the performance of recommendation systems. Additionally, SA models are computationally efficient and easily parallelizable.
While most existing SA-based models have demonstrated commendable performance, they tend to overlook timestamp information. Only TiSASRec [14] and TAT4SRec [13] incorporate timestamp information, with TiSASRec treating time intervals as relative positional embeddings, outperforming SASRec. However, TiSASRec overlooks the temporal sequence and dependencies of timestamps. On the other hand, TAT4Rec does not distinguish between long- and short-term information, leading to limitations in capturing time information with varying spans. In this paper, we address these limitations by modeling time information from two perspectives: time length and time spectrum, achieved through the creation of a trainable timestamp matrix. Our approach involves using a long-term layer in the long-term feature attention layer to capture users’ enduring preferences and incorporating a short-term layer to emphasize users’ immediate interests. This enhancement aims to improve the overall ability of the model to capture information effectively.
Windows function
The window function, alternatively known as a windowing or weighting function, is a mathematical tool extensively employed in information processing and spectrum analysis. In the context of time series processing, its application involves the weighting or smoothing of the time series to alleviate the impact of noise, abrupt changes, and irregularities. This process facilitates a more comprehensive understanding of the periodicity, trends, and features inherent in the sequence. The schematic diagram is shown in Fig. 2.
The utilized window function comprises two components, each serving distinct purposes. The Eq. (1) represents the rectangular pulse function, which carries additional significance in processing temporal information within a specific range. Thus, this function proves useful for local feature extraction and analysis within a designated time window. On the other hand, Eq. (2) mirrors the Hamming window function. In time series data with irregular timestamps, this function serves as a time-smoothing mechanism, effectively reducing irregular noise in temporal information. Furthermore, it assigns weights to time information, contributing to a more precise capture of temporal details.
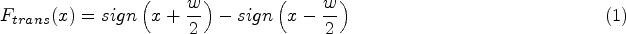
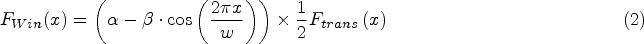
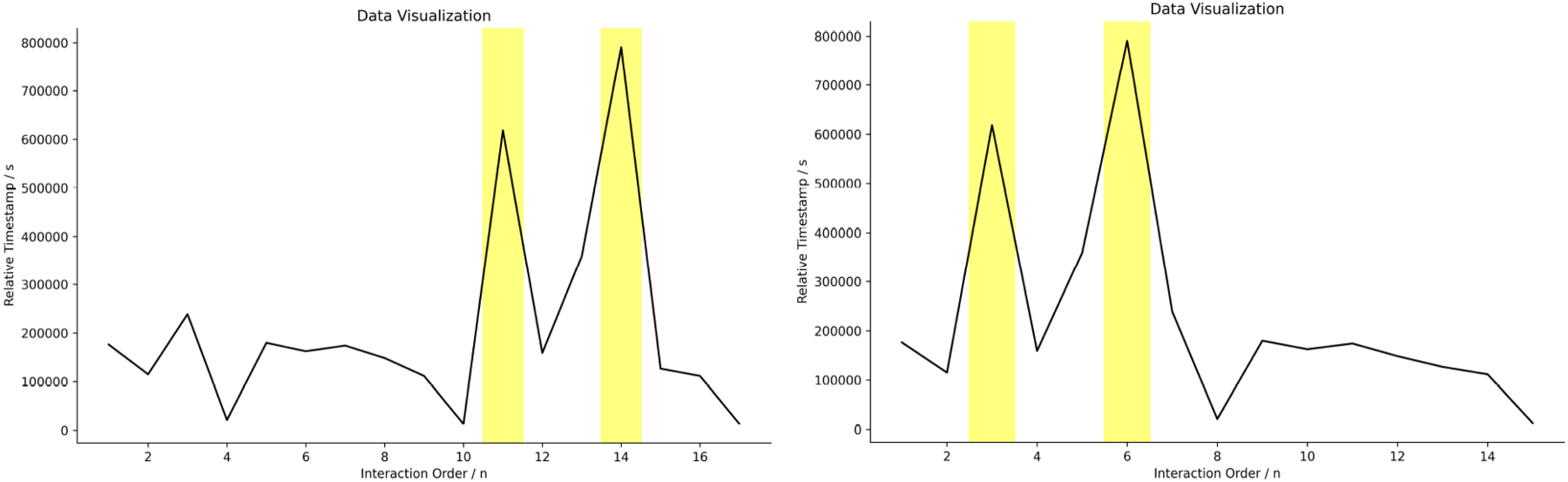
User sequential interactions correspond to examples of relative timestamps, with anomalies highlighted in yellow for emphasis.
Problem definition
Prediction Problem Description: Similar to related work such as [14], we initially represent the item space with a set of size N denoted as V and the user space with a set of size I denoted as U. For each user
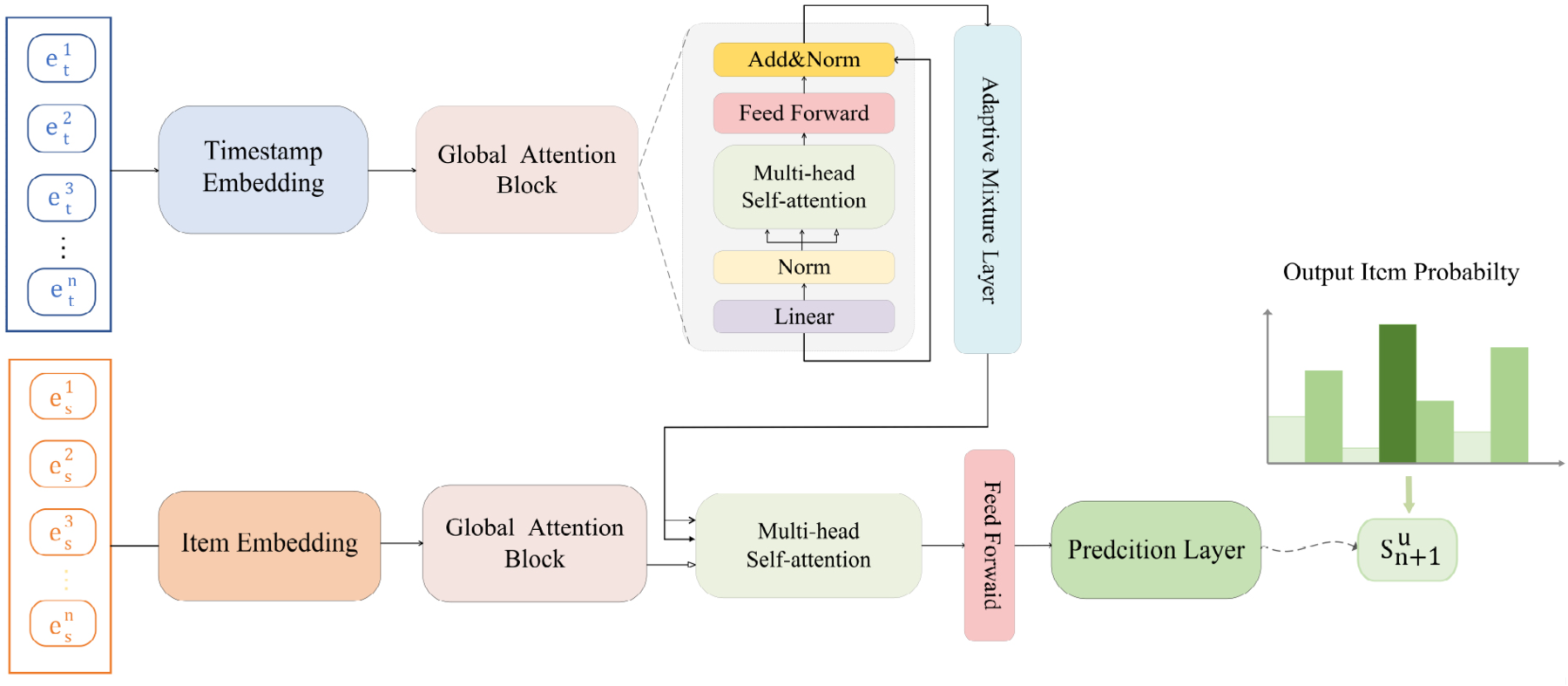
The overall framework of TLSTSRec.
Overview of the Model: The proposed Time-Aware Long and Short-Term Transformer for Sequential Recommendation (TLSTSRec), as illustrated in Fig. 3, comprises three primary components. The first segment is the embedding layer, which transforms temporal and item interaction information into an embedding matrix. The second segment constitutes the core interaction layer. In the upper section, the personalized temporal embedding layer introduces time information to the encoder layer. The global attention blocks in the encoder layer capture long-term and short-term information independently, subsequently dynamically merging them. In the lower section, the initial use of the global attention block captures item-related information. Subsequently, the multi-head attention combines the temporal information from the encoder block with the item information from the preceding global attention block. The third segment involves the output prediction layer, utilizing the amalgamated embedding vectors of timestamps and items for predictive modeling. Specific details of each component will be elaborated upon in the subsequent sections.
We create a learnable embedding matrix

It is worth noting that the position embedding used here differs from the fixed position embeddings in Transformers, employing trainable position embeddings provides more flexible position information and enhances performance [13,14].
Personalized timestamp embedding layer
Specifically, given the fixed-length time sequence
Expressing the maximum relative time interval as
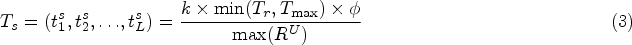
We employ a learnable embedding matrix

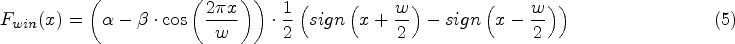
In this context, the function
It can be observed that this window function adopts a compound function combining a rectangular window. In the transition region of the window boundary, a smooth transition is employed, gradually changing the values from the window boundary to the transition area. This approach allows for more accurate calculation of the relative time interval sequence, thereby more precisely revealing potential implicit information in preceding and succeeding behaviors. The specific weight calculation is illustrated in the accompanying figure.
As both the encoder and decoder utilize multi-head attention, the introduction of Global Attention Block becomes essential. Global Attention Block can be regarded as a neural network module based on the self-attention mechanism, effectively modeling sequential patterns. Here, we employ scaled dot-product attention, with the attention input consisting of three matrices: Q, K, and V. The specific definitions are as follows:
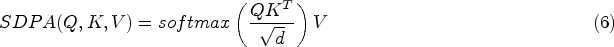
In the context of sequence recommendation models, SDPA is commonly used with the same objects as query, key, value [3,10,14], and the scaling factor helps avoid issues like gradient vanishing or exploding, especially in high dimensions. To enhance sensitivity to local information and capture fine-grained structures in the sequence, we modify SDPA by prohibiting connections between
In addition, multi-head attention
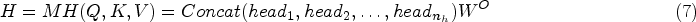
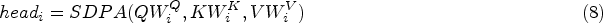
In this context, the matrices
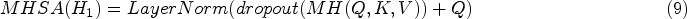
Finally, using the symbol O to represent the output of the entire process of the Multi-Head Self-Attention Block:

In future research, we will explore integrating item attributes and item popularity into the self-attention mechanism, which promises to be an interesting and meaningful endeavor.
Encoder layers
Through the personalized time embedding layer, we acquire
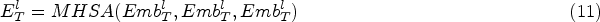
The multi-head attention utilizes the same object,
While MHSA is capable of aggregating all-time embedding vectors using adaptive weights, it is still a linear transformation. Therefore, we adopt a variant of the Feedforward Neural Network based on a Gated Linear Unit, which facilitates learning more intricate representations. The Transformer with a Gated Linear Unit outperforms the version with Feedforward Neural Network [31].

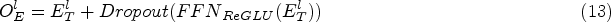
Since the short-term and long-term timestamp sequences capture information at different time scales, the short-term sequence may reflect the user’s recent interests and behaviors, while the long-term sequence may contain habits and preferences over a longer time range. By separately processing these two types of timestamp sequences, the model can better capture user behavior patterns at different time scales. The short-term and long-term information is then weighted to obtain the final time information. Therefore, we adopt an Adaptive Mixture Layer to adjust the personalized trade-off between long-term and short-term sequences. Specifically, this is achieved by employing average pooling followed by a linear layer with sigmoid activation function to obtain coefficients for the time sequences.

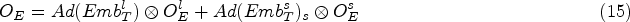
To simplify the description of the entire process, the procedure of the encoder is defined as follows:

In the decoder layer, a combination of global attention and multi-head attention is utilized. The initial global attention incorporates information from the item embedding layer, while the subsequent multi-head attention on the right receives input from the output

The multi-head attention on the right is used to establish connections between the encoder and decoder, integrating time and item information. Here,

To capture key features in the sequence and enhance the model’s performance and expressiveness, a method similar to Eq. 13 is employed:

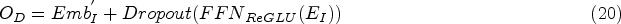
To simplify the description of the entire process, the procedure of the decoder is defined as follows:

To better capture the complex relationships between input and output sequences, a multi-layered encoder and decoder structure is employed. The detailed structure is illustrated in Fig. 3. Their role is to comprehensively capture the intricate relationships between input and output sequences, enhancing the model’s representational capacity, especially when dealing with long sequences and data with hierarchical features. Additionally, the multi-layered structure improves the model’s robustness, aids in generalization, mitigates overfitting issues, and enhances both training and inference efficiency.
Therefore, a stack of N encoders and M decoders is used, with each decoder block’s input coming from the output of the last encoder. As a result, the


After multilayer block, the preference scores of users for each item are computed as follows:

Where
In the preceding context, we know that the user’s interaction sequence with items,

In the context where
The binary cross-entropy loss is employed as the objective function:

The sigmoid function is defined as
In this section, TLSTRec will be empirically evaluated based on real datasets from two different domains, providing answers to the following questions:
Experimental settings
Datasets
The two datasets utilized for experimental evaluation are sourced from the real world and widely employed in relevant research [9,10,14,34], with detailed data descriptions available in Table 1.
Steam [9]: This benchmark dataset is derived from the prominent online video game distribution platform, Steam, covering the time span approximately from 2010 to 2017.
Userbehavior [35]: Provided by Alibaba, this dataset encompasses user behavior data from the online shopping platform Taobao. The included user data comprises clicks, purchases, items added to the shopping cart, and product preferences.
For both datasets, actions such as reviews, clicks, or adding items to the cart are considered implicit feedback and are sorted by timestamp. A similar preprocessing procedure is applied to Steam, wherein items with fewer than 5 interactions lacking meaningful features are discarded. In the case of Userbehavior, users are sorted by their user IDs, and the interaction sequences of the top 100,000 users are extracted. Users with more than 300 interactions or fewer than 20 interactions are then excluded.
Concerning the evaluation, the leave-one-out evaluation method is adopted to partition these two datasets [9,10,14,13]. This method is extensively used in the evaluation of sequential recommendation. Specifically, for each user u and their interaction sequence
Basic dataset statistics.
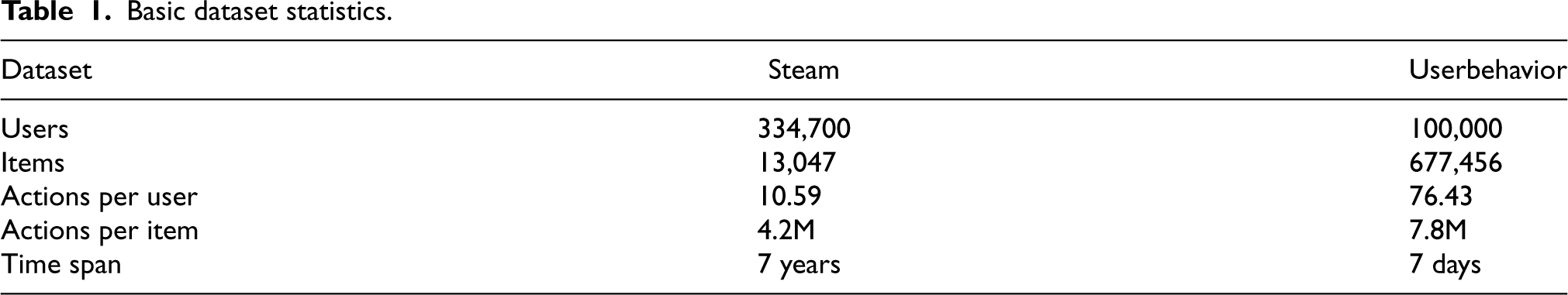
Basic dataset statistics.
Following evaluation standards [9,10,14,13], we employed five evaluation metrics: NDCG@5, NDCG@10, Hit Rate@5, Hit Rate@10, and MRR. HR focuses on the accuracy of the model, NDCG emphasizes the position of the user’s desired items in the model’s recommended list, favoring higher positions. MRR highlights the position of the user’s desired items in the model’s recommended list, favoring higher positions.
To tackle the computational time challenge of ranking items based on preference scores in large datasets, we randomly selected 100 users who had not previously interacted with the items and ranked these newly sampled items alongside the actual items [10,14,13]. Subsequently, the evaluation metrics were computed based on these 101 items.
Baseline models
To demonstrate the effectiveness of our proposed TLSTSRec, we compare it with various categories of recommendation models, including classical general recommendation models (PopRec) that do not consider sequential patterns, matrix factorization (MC) based models (TransRec, Caser), Recurrent Neural Network (RNNs) based models (GRU4Rec, GRU4Rec
PopRec: The popularity-based recommendation model recommends items based on their frequency of occurrence.
TransRec [36]: A simple yet representative dual-tower recommendation framework is employed for modeling user feedback of mixed modalities.
Caser [20]: Caser embeds a sequence of items into an “image” and captures higher-order Markov chains by applying convolution operations to the “image”.
GRU4Rec [37]: A sequential recommendation model that employs stacked Gated Recurrent Units (GRUs) to capture and leverage sequential patterns in user-item interactions.
GRU4Rec
SASRec [9]: SASRec is a groundbreaking model based on self-attention (SA) that leverages the encoder component of the Transformer. Additionally, it employs the dot product between the successive underlying features of the most recent item and the embedding of the target item as a scoring function.
FDSA [10]: FDSA utilizes independent self-attention modules to model item transition patterns and feature transition patterns.
TiSASRec [14]: Based on self-attention, absolute positional information and relative time interval information are incorporated.
CatGCN [23]: A state-of-the-art model that optimizes initial node representations by modeling feature interactions before graph convolution.
CTGNN [24]: A state-of-the-art model that integrates item category and interaction time information, using a multi-layer graph convolutional network and a temporal self-attention network.
TAT4Rec [13]: State-of-the-art models leverage the Transformer to model time and items separately.
For fair comparison, we employed the code provided in the literature for Caser, GRU4Rec, GRU4Rec
Implementation details
We implemented TLSTSRec using PyTorch. The default configuration includes two encoder blocks and two decoder blocks, with a maximum sequence length
The recommendation performance is presented in the table, with the optimal outcome in each row highlighted in bold, and the second-best outcome underlined.

The recommendation performance is presented in the table, with the optimal outcome in each row highlighted in bold, and the second-best outcome underlined.
Performance comparison
Table 2 shows the recommendation performance of our model and baselines on the two datasets. Firstly, FPMC and TransRec are methods based on project state transitions. It can be observed that their performance on the relatively sparse Steam dataset is better than that of Userbehavior. Models based on neural networks (i.e., Caser, GRU4Rec, GRU4Rec
We can observe that our proposed TLSTSRec outperforms eleven competing models across three standard ranking metricss, particularly demonstrating excellent performance on the Userbehavior dataset. This superiority stems from the specially designed encoder and decoder structure, as well as the incorporation of personalized long-term and short-term time information. Additionally, for dense datasets, the embedded module of the window function enables precise time modeling. The limited improvement observed on the Steam dataset may be attributed to the excessively sparse nature of the temporal data, constraining the effectiveness of the personalized time embedding module. This challenge underscores a significant hurdle in the field of sequential recommendation.
Secondly, Fig. 4 illustrates the impact of a key hyperparameter – the dimension size. We can see TLSTSRec consistently outperforms other models on the Userbehavior dataset as the dimension varies. When the dimension exceeds 30, the TLSTSRec model surpasses all other models on the Steam dataset. The impact of dimensions on SA/RNN-based models is more pronounced in the Userbehavior dataset, suggesting that neural network models may be more susceptible to dimension changes in datasets with dense user behavior.

Models’ performance (NDCG@10) under different dimension size.
The first major contribution of TLSTSRec is a novel window function-based embedding module, designed to transform timestamps into time embedding matrices. The second contribution is a personalized long-short-term time embedding structure for integrating time information. Consequently, we conducted a detailed ablation study to understand the impact of these two crucial components in our model.
Influence of window function-based time module
Our proposed model, TLSTSRec, employs a novel personalized time embedding module based on a window function to handle timestamps. This ensures that similar time intervals are transformed into similar embedding matrices. To assess the influence of the window function-based time module, we conducted experiments by removing the window function from the time embedding layer. The removal of the window function-based time module implies a decrease in accuracy when computing time embedding vectors, as similar timestamps, can no longer be transformed into similar embedding vectors. As shown in Fig. 5, without the window function, the performance consistently decreases, indicating that maintaining the continuity of timestamps contributes to capturing temporal information.
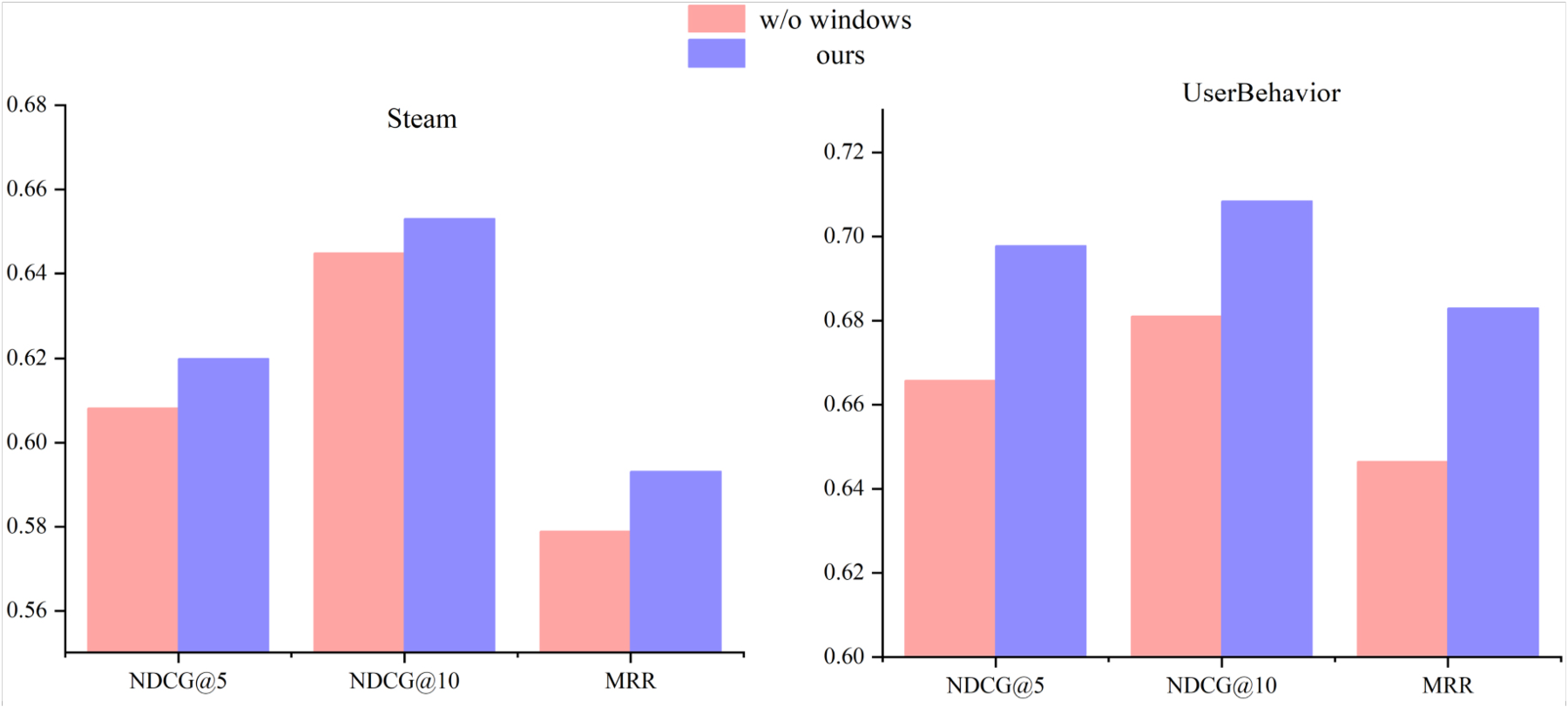
Impact of window function-based embedding.
To understand the influence of the proposed merging timestamp information in the encoder-decoder structure, we replaced the output of the encoder block
As depicted in Fig. 6, the model’s performance significantly declines when the merging timestamp information is removed, indicating that timestamp information contains crucial user interaction features. It helps the model to better model users accurately, especially considering the proposed encoder-decoder structure, which effectively integrates time and interaction information.

Impact of merging long short-term time information.
Number of bins
Table 3 illustrates the impact of the number of bins for timestamps on both datasets. A larger number of bins implies that the temporal embedding layer can employ a more complex trainable embedding matrix
From the data presented in Table 3, it can be observed that the number of bins for timestamps has a minimal impact on the performance of TLSTSRec on Steam, consistently exhibiting good performance. However, in the Userbehavior dataset, a smaller number of bins leads to a decrease in performance. This decrease may be attributed to the more frequent item interactions in the Userbehavior dataset, necessitating a larger embedding matrix
The impact of bins is depicted, Optimal outcomes are highlighted in bold, while the second-best outcomes are underscored.

The impact of bins is depicted, Optimal outcomes are highlighted in bold, while the second-best outcomes are underscored.
Dropout [38] has proven to be a successful method in mitigating overfitting issues in deep learning models. Hence, we employ varying dropout rates to observe their impact on experimental performance. As depicted in Table 4, we observe a more pronounced variation in model performance with changes in the dropout rate for Userbehavior. This observation may be attributed to the fact that more intensive user behavior is more susceptible to the effects of dropout compared to Steam.
The impact of dropout is depicted, with the optimal outcomes highlighted in bold, while the second-best outcomes are underscored.

The impact of dropout is depicted, with the optimal outcomes highlighted in bold, while the second-best outcomes are underscored.
Due to TLSTSRec’s utilization of an encoder-decoder structure to capture user preferences from timestamps and items, questions arise about whether it also has advantages in terms of computational efficiency. Therefore, we compared the training time per epoch and the total training time to convergence on the Steam dataset for SA-based models, including SASRec, FDSA, TiSASRec, and TAT4Rec. We set the dimensions of these five models to 50, with a learning rate of 0.001. From Fig. 7a, SASRec achieves the fastest training speed with its simplest model structure. It is known that SASRec exhibits significant improvements in efficiency compared to existing RNN/MC-based models, primarily due to the parallelizability of the self-attention mechanism. From Fig. 7b, it can be observed that TLSTSRec converges only slightly slower than SASRec and is marginally faster than TAT4Rec and TiSASRec. The comparable convergence speed between TLSTSRec and TAT4Rec is attributed to their similar utilization of temporal information. From the above results, it can be observed that our proposed TLSTSRec has the second fastest testing speed, which makes TLSTSRec feasible for practical application scenarios.

The comparison of training speeds per epoch (a) and total training time to convergence (b) among SA-based models.
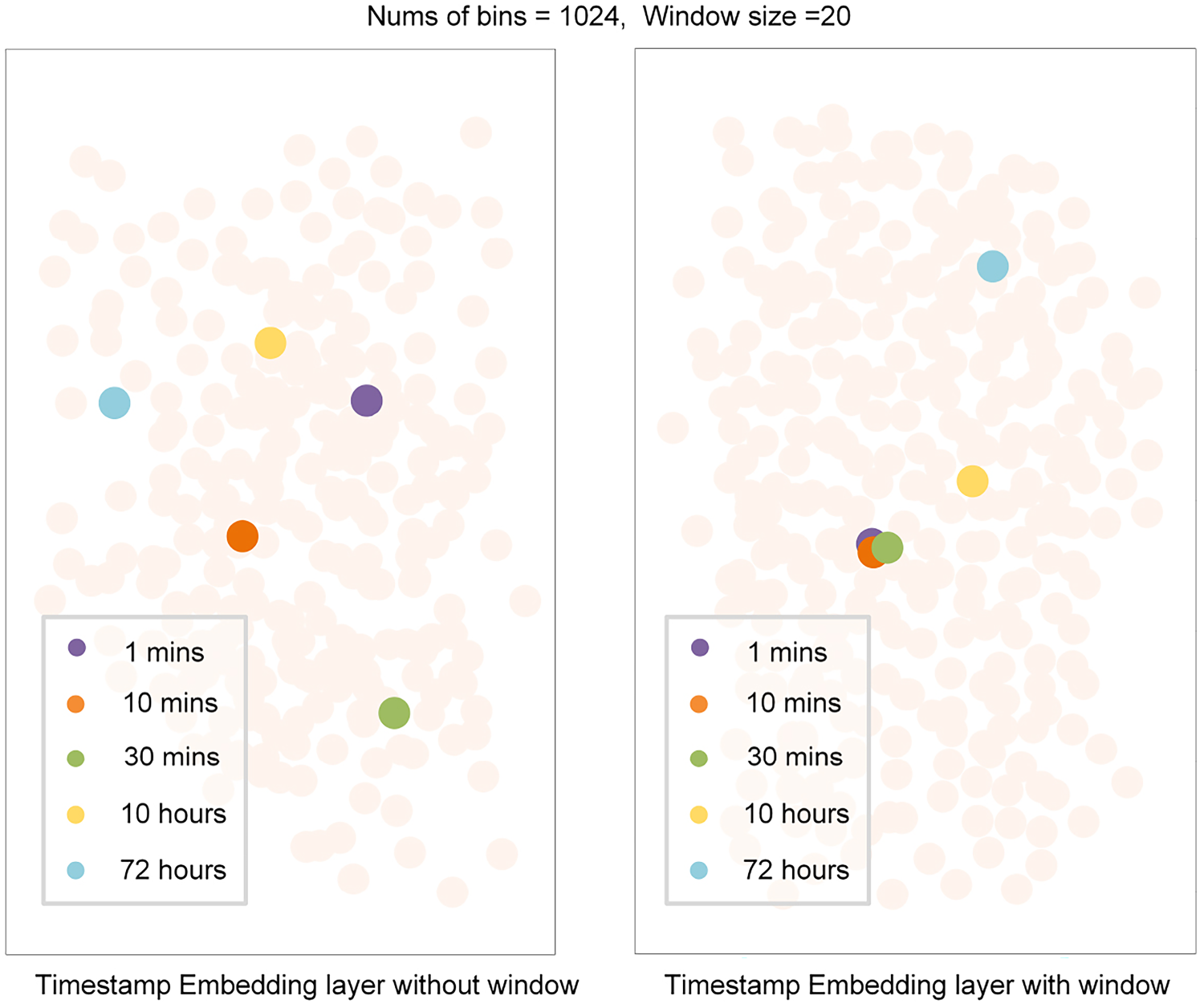
Comparison of personalized timestamp embedding layer without and with window by visualization.
As described in Section 3.3, the personalized timestamp embedding layer can transform similar timestamps into similar time embedding vectors using an embedding method based on a window function, which is beneficial for mining the potential similarity in time information. To evaluate the effectiveness of the personalized timestamp embedding layer and observe the visual changes with embedding methods using and removing the window function. We selected five timestamps: 1 minute, 15 minutes, 30 minutes, 10 hours, and 72 hours. Then, we conducted experiments using these two different embedding modules and transformed these five timestamps into time embedding vectors. Subsequently, we used T-SNE [39] to project the time embedding vectors into a two-dimensional space. Figure 8 illustrates the distribution of the five timestamp vectors under different embedding methods. It is evident that, the five timestamps exhibit an irregular distribution when the window function is removed. However, when the window function is applied, the closely related timestamps (1 minute, 15 minutes, and 30 minutes) exhibit a clustered distribution, indicating their similarity in time information, while timestamps with large time spans (10 hours and 72 hours) are positioned far apart, suggesting that they represent distinct time information.
Conclusion
To address the challenges posed by the limitations of modeling information and the variability of user preferences in sequential recommendation systems, we propose a novel time-aware Transformer model. In the real world, user interests and item popularity frequently change [11]. Our model combines long-term persistent preferences with short-term immediate interests, adjusting the personalized trade-offs between long-term and short-term sequences through adaptive fusion layers. This configuration enhances the model’s ability to comprehensively and effectively capture information. As demonstrated in Section 4.2.1, our model outperforms eleven competing models across three standard ranking metrics, as shown in Table 2. We also conducted experiments to assess the impact of the critical hyperparameter dimension size on recommendation performance. Figure 4 demonstrates that our model exhibits distinct advantages across all dimensions within the Userbehavior dataset, which is characterized by its rich temporal information. This finding further validates the adaptive fusion layer’s capability to model temporal information effectively. Additionally, we leverage temporal information to address the limitations of modeling information by employing a trainable timestamp matrix. This matrix models temporal information by incorporating both time duration and spectrum. This innovative multidimensional temporal information modeling approach allows for more effective adaptation to the continuously evolving patterns of Userbehavior over time. The effectiveness and interpretability of our model are further confirmed through ablation studies in Section 4.3 and visualization experiments in Section 4.6, where we analyze the visual distribution of time-embedding vectors.
Despite the excellent performance of our proposed time-aware Transformer model across various aspects, it still has certain limitations. Through a comprehensive analysis of these limitations, we aim to provide insights for future research improvements. The effectiveness of the TLSTSRec model is influenced by the density of the temporal data. In datasets with sparse temporal interactions, such as the Steam dataset, the performance improvements offered by TLSTSRec are constrained. Sparse datasets fail to provide sufficient information, thereby impeding the moduleâĂŹs ability to accurately capture and model user interactions.
In future work, we aim to explore the integration of more comprehensive information, including item categories and user personal information such as age and gender. This auxiliary information can further enhance prediction performance and reduce the model’s excessive reliance on temporal data. Furthermore, as demonstrated in Section 4.5, our model exhibits commendable computational efficiency. Consequently, future research will investigate the application of TLSTSRec in various online scenarios. This includes exploring music recommendation by combining user interaction timestamps with music category information and conducting e-commerce recommendations (such as those on Taobao and Amazon) by integrating implicit user interactions, item categories, and user personal information including age and gender. This exploration promises to be both interesting and meaningful.
Footnotes
Appendix
See Table 5.