
Abstract
With the modernization of cities, public sculptures are constantly being designed and constructed. The artistic form and image expression effect of sculpture based on intelligent and parametric design needs to be designed and developed to guide and assist the construction of sculpture. This paper applies the NAS architecture search method to explore the field of image expression effect models. Through the end-to-end search of the experiment designed in this paper, the separable convolution lightweight design is used, and the new model AestheticNet is used to predict the image form effect score distribution. Secondly, this paper proposes optimization strategies combining image expression effect theory and convolutional neural network, including improvement of Loss function self-weighted Loss, two-dimensional Attention mechanism – introduction of CBAM, and adaptive pooling layer. Optimization of several aspects, such as adaptive input. Finally, the validation set is compared with other existing image-morphological effect model algorithms, which proves the effectiveness of the customized search scheme. It demonstrates the efficacy of the AestheticNet model compared to other algorithms by validating its prediction of public sculpture image form effect ratings. The artistic form using intelligent and parametric design methodologies may improve. Image expression of sculptures may be enhanced by applying the image form effect model, which should be pervasive. We can use it to intelligently and parametrically guide the design and manufacture of sculptures.
Introduction
The rise of public art has released various possibilities for public sculpture in the formal context and material medium. Some public art practitioners strive to escape traditional narrative figurative thinking and explore China with metaphysical conceptual thinking combined with metaphysical abstract forms. The new presentation methods and certain possibilities of contemporary public sculpture enrich the diversification and diversity of current public art [1, 2, 3]. As the name suggests, public sculptures are sculptures made for public spaces. Historically, public art has been mainly used to refer to places of interest. Public and figurative sculptures in the form of busts or statues of all human beings are extraordinary works of art by illustrious individuals who lived hundreds of years ago. The public sculpture also depicts the historical context and early civilizations of people from geographical backgrounds.
With the advent of the era of intelligent Internet, interconnectivity has turned each screen into a small stage. In this way, the characteristics of the theater are combined with sculpture art and graphic art. In today’s rapid development of science and technology, deep learning and artificial intelligence technology have penetrated all fields of all walks of life with their high efficiency and convenience [4, 5, 6]. It is playing an increasingly important role in the manufacturing sector. The existing state of sculpture is also changing. Sculpture has become a kind of information and data. The inner thought of sculpture is also affected by the Internet environment of Internet thinking, forming a different creative content and direction from previous sculptures.
Regarding interactivity, Under the application of intelligent Internet big data, the interaction of sculpture is not passive but active through network calculation and screening [7, 8]. Painting does not necessarily have to be on canvas or easel. Sculpture is no different. New media can bring more possibilities. Sculpture art has experienced a long development since the Middle Ages. Since the “Venus of Willendorf” in ancient times, sculpture has accompanied human development for tens of thousands of years.
From classical to modernist to post-modern sculpture, every revolution in production technology will bring many changes to the art of sculpture. With the introduction of interactive, dynamic, AR/VR, and data visualization, internet technology has completely transformed the art form of sculpture. It supports sustainability, fosters teamwork, and adjusts to external cues. In the digital era, technology also promotes innovation and increases accessibility. With the advancement of computer hardware and software, the computer gradually became an essential tool for artists. In 1986, Charles Hall developed a digital “STL” file that could change the trajectory of sculpture development. STL file is the most essential basis for sculpture digitalization. So far, the 3D printing file format is still STL. STL files are simple binary computer programming numbers. On the computer, they form triangles. The wide application range of STL files has a significant influence, unprecedented in sculpture digitization [9, 10, 11, 12]. Under the explosive development of the intelligent Internet, many platforms and industries are using intelligent Internet technology to develop. Cloud big data, the products of the intelligent Internet era, are not only for mining commercial interests but also can improve the rapid development of the industry and provide people with more personalized services. In the intelligent Internet era, cloud big data and sculpture digitalization provide customized services that drive corporate innovation and improve user engagement, community involvement, and cultural preservation while maintaining data privacy. In the era of intelligent Internet, the interconnection of cloud big data and sculpture digitization is essential in changing the original traditional production and creation of sculpture. For example, you can set up your shop in the “cloud” of sculpture and collect and organize traditional sculpture scanning and modeling software; the created digital sculpture model is uploaded to the 3D cloud model library platform.
The image beauty of sculpture has a sublime beauty; just like facing the plaster head of David in classical sculpture, you will be infected by the heroic heroism he exudes. Facing the giant Buddha statues in Yungang Grottoes, you will kneel and pray. The symbolic beauty of sculpture also has emotional beauty. Rodin firmly believes that “art is emotion.” Rodin’s sculptures mostly excavate the real emotions of ordinary people and celebrities [13, 14, 15, 16]. The beauty of reality expressed by Rodin is not an external roar but an explosion of inner emotions, the expression of rational and genuine emotion. After Rodin, the expression of sculpture became more accessible. Some used different materials to express rich material image expression effects. The art form and image expression impact model fosters creative quality and continual progress by providing a systematic framework, standardized standards, expert advice, and constructive feedback, thus improving sculpture grading. Some sculptures only became materials, objects, and forms of exploring space theater. They no longer carry any image expression. The reality is beautiful. Unlike virtual beauty, which lacks objective existence, it is like water without a source and wood without roots. It is also different from sculpture. Natural beauty lacks changes and has many limitations. The beauty of intelligent Internet sculpture is multi-perceptual. It is a fusion of network and sculpture. With the beauty of reality, this “in-mix” presentation is a constant exchange between art and popular culture, and it will also be the mainstream of sculpture beauty in the future.
Parametric design technology developed in the mid to late 1990s. Initial research began in some architecture schools, such as Columbia University School of Architecture, British Institute of Architecture School of Architecture, MIT School of Architecture, etc [17, 18, 19, 20, 21]. The technique is explored and mastered by some young and emerging architects and designers and applied to real projects. World-renowned architectural firms such as SOM and Norman Foster Firm have conducted unique research and obtained many influential works. The most representative and influential architect is Zaha Hadid [22]. In 2010, Zaha Hadid’s partner, Patrick Schumacher, proposed the concept of “parametricism” to popularize a series of theories and methods of parametric design to the world. At this time, Zaha Hadid and her firm were pushed to the forefront, and they became the hottest topic in the design and architecture circles. Today, Zaha Hadid Architects is still at the forefront of parametric and digital design. Figure 1 shows the “cloud” parametric public sculpture, and Figure 2 shows the intelligent and parametric design of 3D printed public art sculpture.

“Cloud” parametric public sculpture.

Intelligent and parametric design of 3D printed public art sculptures.
Although image expression will reach a consensus on this issue, some sculptures are indeed more attractive than others, which is currently an emerging field, computational art form, and imagery Expression effect, that is, image quantification. Based on this, there are many attempts to use computers to learn the characteristics of sculpture, imitate the aesthetic process of human beings, and obtain an image expression evaluation of a sculpture to realize the replacement of humans by machines. The image expression of public art sculpture is a subjective cognition and a measure of the machine’s visual perception of the image. The art form and image expression effect model can be used to score sculptures and play a role in many labor-intensive subjective tasks to optimize visual quality, improve user engagement, and reduce errors in the visual perception of sculpture images. Historical, cultural, societal, technological, and economic influences, such as artistic trends, urbanization, social movements, technology breakthroughs, and political views, all impact how people see public sculptures over time. Due to its use beyond picture classification tasks and language models, previous research on Natural Language Processing (NLP) architecture and image expression has been restricted. It is also absent in public sculpture design for NAS architecture to be integrated with image expression evaluation. More models are needed to measure and rate the visual expression of sculptures in public spaces. By developing a more effective model for predicting image form impact scores in public sculptures, this work seeks to promote design, technology, and the arts by combining NAS architectural search capabilities with picture expression assessment.
This paper is research that combines the current hot NAS architecture search technology and image expression. This is the knowledge of two fields. Before this, NAS architecture search was mainly used to search sculpture image classification task networks and the language model in NLP. This article is the first time to use it in image expression. Considering the reality of human beings, scoring is also a subjective matter. Usually, there is still a particular gap in the aesthetics of different people. Currently, most image expression effect models are based on discrete binary classification, which predicts a discrete score value to judge whether the sculpture image is beautiful. Predicting discrete scores for sculptural pictures is essential for objective assessment, comparative analysis, and decision assistance. These scores give quantitative metrics for quality, promote openness, encourage study, honor artistic brilliance, and spur advancement in the art world. Here, we differ from the above approach but choose to model the image expression effect prediction as predicting the distribution of an image expression effect score rather than a simple binary score to be closer to the accurate multi-person score distribution.
The application of intelligent and parametric design in public sculpture art
Parametric design is a new way of creation and a creative thinking tool for artists. During parametric modeling, creators see every step of their shape, which is efficient and intuitive for some builds. The whole process of parametric design is a process of artificial form generation, which forms the most direct relationship with artistic creation activities such as public sculpture. The parametric design methodology has two essential components, which can be divided into “parameter relationship” and “design parameters.” Based on the parameter relationship, by defining the adjustable design parameters, using the algorithm (Algorithm) to construct the design space, to generate the design form, that is, the exploration of the design space, to create a rich design geometry and a large number of creative form solutions. For example, Figure 3 is Rodin’s “Gate of Hell” parametric application in intelligent software.

Parametric application of Rodin’s “Gate of Hell” in intelligent software.
Noise technology, surface noise, creates a texture tool technology on the surface of a sculpture object that cannot be achieved by traditional sculpture. You can choose the size and color of the noise infinitely (as shown in Figure 4). The noise technology can create as many as one billion polygons applied to the sculpture’s surface, which is a considerable workload that cannot be achieved by traditional sculpture language. Using noise technology can make every pore of the character rusted metal, paint, paint peeling, etc. Tiny details: if the conventional hyper-realistic sculpture uses the new noise technology for the final surface treatment, it will produce new visual effects and have a different sensory stimulation.
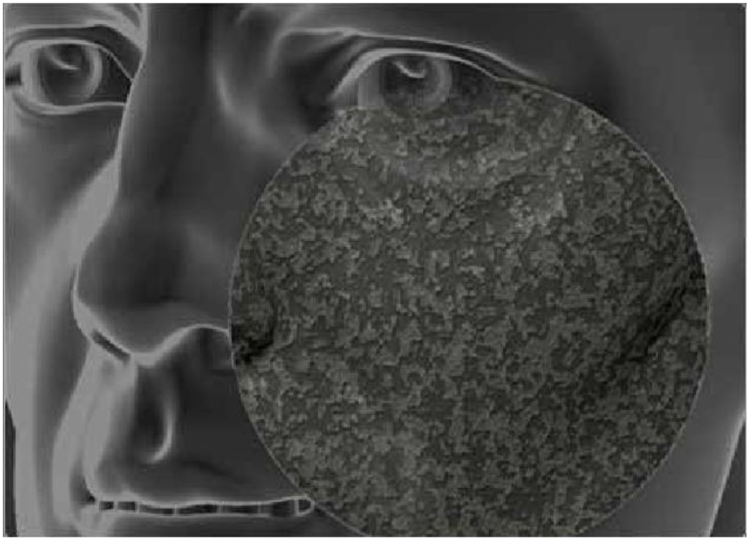
The details of the intelligent parameterized sculpture noise technology processing.
Based on the original artificial neural network (ANN), deep learning uses multiple layers of neurons to extract features by simulating the working principle of the brain to process information. It is often used to solve sculpture image processing, text processing, and natural language problems. Convolutional Neural Networks (CNN) have strong generalization ability and are a kind of network suitable for dealing with sculpture image-related problems. There are many convolution kernels with different weights in the convolution layer. Each convolution kernel can extract a feature. Because convolutional kernels in convolutional neural networks (CNNs) operate through weight sharing, local receptive fields, and hierarchical learning, they are essential for feature extraction from pictures. They surpass conventional models in detecting essential characteristics like edges and intricate patterns in deeper layers, showcasing their usefulness through performance measurements and visualization. Other features can be obtained when different convolution kernels act on the same object. To ensure that the size of the sculpture image after the convolution operation is consistent with the original size, a zero-filling operation is usually used; that is, zero-filling is performed around the sculpture image. The pooling layer mainly removes the background and redundant information and reduces the resolution while the primary feature information remains unchanged. The commonly used strategies are average pooling and maximum pooling. Its significance is in reducing the amount of data calculation, preventing overloading, and making features more accessible to fit when the main features are distributed in space.
Convolutional layers are widely used as feature extractors. The convolution operation will extract different feature information as the input of the next layer. Separable convolution reduces computational complexity and parameter count by segmenting convolution operations into more miniature stages, improving neural network performance. This procedure deconstructs filters, speeds up computations, and enhances performance. It is split into depthwise and pointwise convolution and spatially separable convolution. The parameters of the convolution kernel are updated and adjusted through the backpropagation algorithm. Shallow convolutional layers can extract specific feature information of the target, such as contours, edges, and shapes, and deep convolutional layers can combine low-level semantic features into high-level features with abstract semantic information. After the convolution operation is multiplied with the corresponding position and the offset is added, the feature extraction process is completed. The feature map obtained by the current layer also needs to use a nonlinear function to convert linear features into nonlinearity. This operation maps the feature space to a higher-dimensional feature space to supplement the nonlinear problems that linear features cannot solve. Generalization. The expression is:

Figure 5 below shows the specific process. A 5
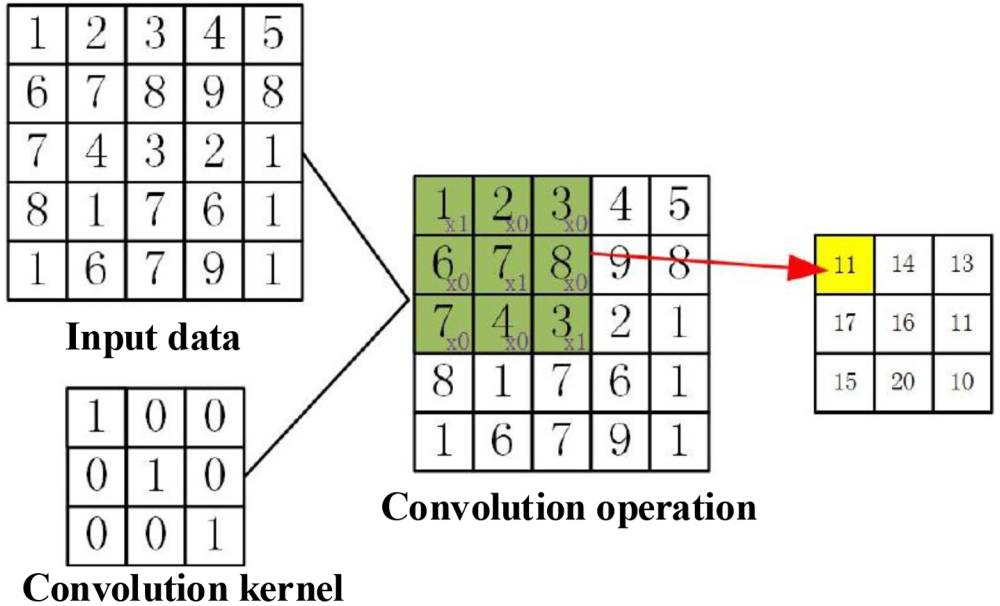
Convolutional layer.
Pooling layers are often used in conjunction with convolutional layers. The pooling layer can input sculpture image, and the reduction of the spatial size information will bring two benefits: first, the reduction of the size will reduce the parameter simplicity, thereby reducing the amount of calculation; second, The reduction in dimensionality forces it to compress the data, and the compression of the data will make its main characteristics more obvious, thereby filtering redundant information. Since the sculptural image space is associative, the pooling operation brings little feature loss. There are two types of operations: max pooling and average pooling. However, the most commonly used is max pooling, which operates by selecting the most significant value in a sliding window, which reduces dimensionality while maintaining features. This operation will cause the feature map to be blurred, and it has been generally proven to be less effective recently and has been gradually eliminated. The pooling operation often uses a step size of 2. Since too large a window will cause severe damage to the data feature points, the window size is also generally selected as 2

The pooling window is 2
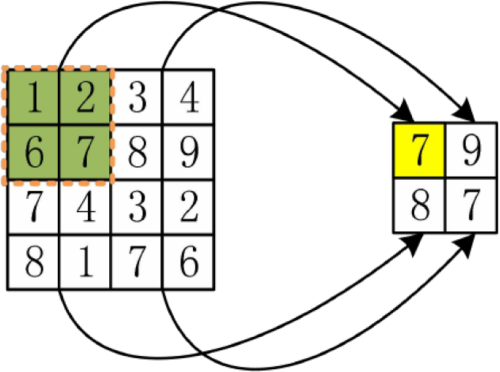
Max pooling operation.
After the convolution and pooling operations, a fully connected layer is finally needed. A fully connected layer after the feature vector conversion can ignore the influence of position and integrate the feature information obtained by convolution and pooling. Finally, the object is sent to the classifier for classification.
The RGBD sensor is mainly composed of a depth camera for acquiring depth information and a color camera for acquiring RGB sculpture images. The time-of-flight principle is the time between the emitted light and the time the infrared light returns from the object’s surface to the sensor. The distance from the object to the camera is obtained by calculating the difference between the two times. Since this scheme is usually accompanied by noise, the accuracy could be higher, and the principle of infrared projection is mainly to protect the encoded. When the light reaches the object’s surface, a speckle will appear. The speckle display will be different at different distances. The object’s distance can be calculated according to the deformation of the cos recording of the internal infrared camera. The two RGBD sensors used in this paper are shown in Figure 7. The Kinnect v2 camera and the D435i camera are based on the principle of infrared projection to determine the distance between the object and the camera.

RGBD depth sensor.
Converting the three-dimensional information of the objects in the scene into two-dimensional details in the sculpture image involves the imaging principle of pinhole imaging in the camera. This principle requires linear transformation between several coordinate systems of the sculpture image coordinate system (XOIY), camera coordinate system (Xc Oc Yc), and world coordinate system (XW, YW, ZW) to complete the three-dimensional coordinate system to the two-dimensional coordinate system. Conversion between systems. The transformation of the three coordinate systems provides theoretical techniques for transforming other coordinate systems. The overall coordinate transformation relationship is shown in Figure 8. The following describes the transformation relationship between the three coordinate systems.
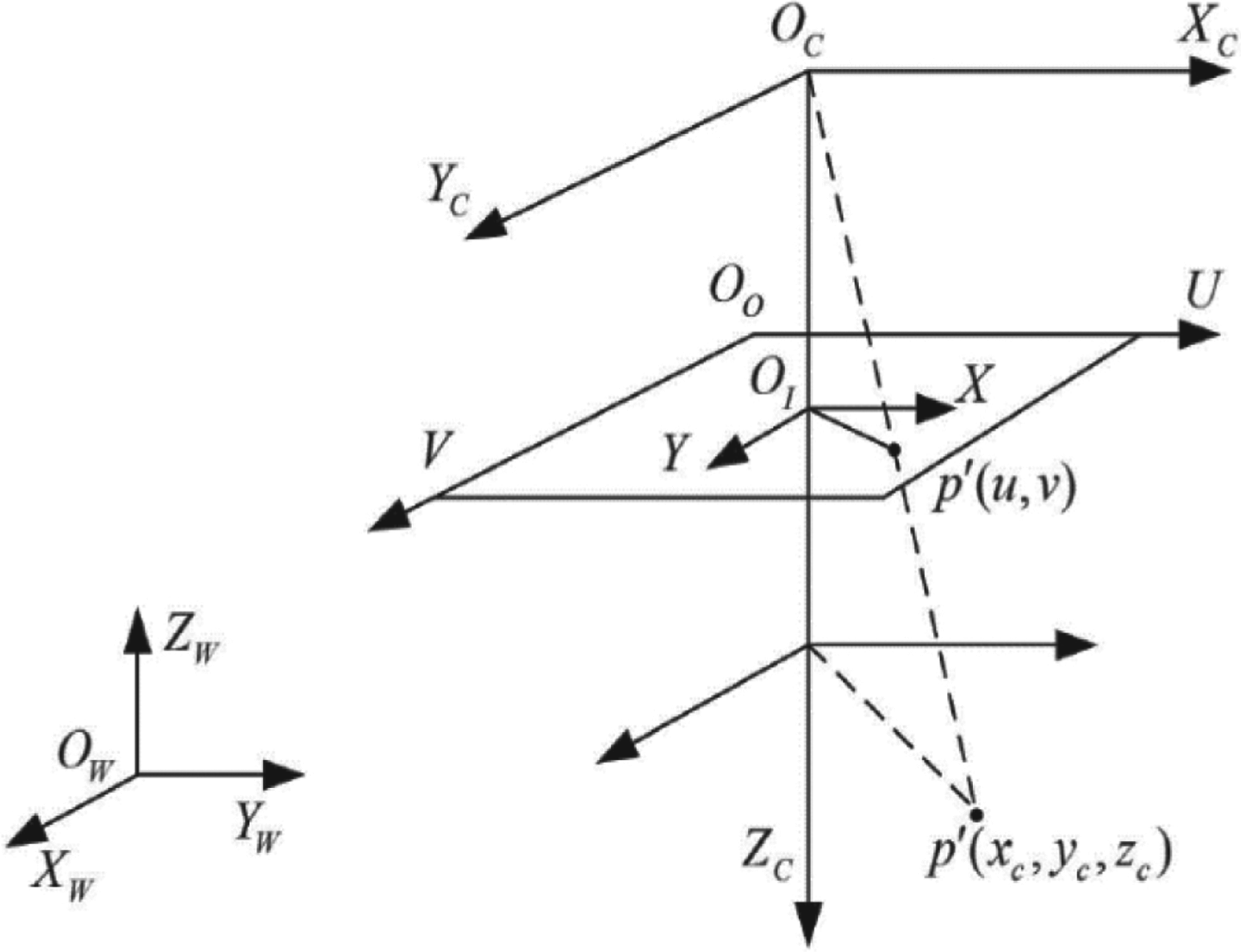
Relationship between camera coordinate systems.
The pvnet network in 2019 proposed that the distance of the feature points from the surface of the object CAD will affect the positioning accuracy; that is, the closer the distance to the object surface, the higher the positioning accuracy. To this end, the author uses the FPS (Farthest point sampling) algorithm to select feature points on the CAD model of the object, as shown in Figure 9, and points out that to take into account the stability of EPNP, the feature points are best on the surface of the object.

FPS feature point representation.
The distance between the collection point and the point set B is calculated, and the maximum value is selected. When the number of the feature point set reaches the predetermined value, Stop when the number n is set. The author pointed out through comparison experiments that
AestheticNet network structure
As shown below, AestheticNet is the model structure obtained in this paper through the NAS architecture search technology on the public art sculpture of the image-morphological effect dataset. Neural Architecture Search (NAS) modularity allows quick exploration of neural network designs and flexible combinations. This methodology facilitates effective search methods, knowledge transfer, and the interpretability of architectural decisions by enabling iterative selection, assessment, and optimization of modular components. Among them, the network inherits the idea of modularization, and the cell is its basic unit. The specific modular structure diagram is as follows.
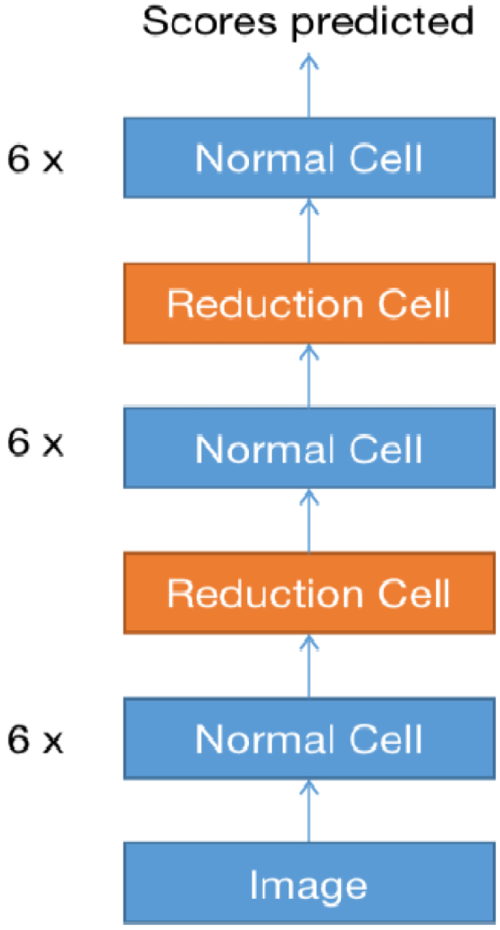
Aesthetic Net modular structure diagram.
Figure 20 is the modular structure diagram of the sculpture image model Aesthetic Net network obtained by the NAS architecture search method on the sculpture dataset. The flow direction of the data is bottom-up, input a sculptured image to be scored, and finally, get a predicted score distribution. The specific size change is achieved by setting different stride lengths. The particular structures of the two types of Cells are as follows.

Schematic diagram of Normal Cell structure.

Schematic diagram of the Reduction Cell structure.
Figures 11 and 12 are schematic diagrams of Normal Cell and Reduction Cell structures, respectively.
Artificial neural networks are getting deeper and deeper, and more and more network designs are also following the idea of modularization, and the basic unit block, cell, and other structures are proposed. To estimate performance, tune hyperparameters, avoid overfitting, choose the best models, generalize to unknown data, and ensure data leakage, it is essential to train and validate model parameters on a validation set throughout network building. For example, Resnet obtains a deeper network by stacking Residual block modules, and SE-Net implements the entire network by repeatedly using the SE-block structure. NAS architecture search also uses the idea of modularity. First, the cell structure is obtained by searching, including normal cells and reduction cells, and then the final network is obtained by stacking. Based on the existing GPU computing resources, the current NAS architecture search algorithm ideas can be summarized as: in some candidate operation sets (operations), hole Convolution, max pooling, average pooling, etc. Combining these operations, a cell structure is obtained, and then the cell structure is combined to obtain a network structure finally. The model parameters are trained and then verified on the validation set. The whole process is repeated continuously until the stopping condition is satisfied, and finally, a better neural network structure is obtained.
The architecture search in this paper uses the traditional differentiable architecture search method at the beginning. DARTS uses gradient-based techniques to optimize neural network designs, enabling differentiable parameter learning. Lowering computing costs and using a discrete design entails gradient computation, bi-level optimization, and backpropagation. Through experiments, it is observed that there are two obvious problems in the traditional differentiable architecture search. One is the problem of memory usage caused by the search algorithm. The conventional GPU memory is not enough to support large batches of training, which indirectly affects the second problem, which is the final effect of the model. GPU memory constraints, decreased performance, and overfitting risk hinder conventional GPU architectural search. Hyperparameter tweaking, investigating different hardware options, and optimizing training protocol are needed to overcome this. Conventional GPU memory restrictions hamper ample batch training for neural networks because of memory management strategies, memory depletion, model size, data storage, efficiency, and batch size trade-offs. The results could have been better; a comparative experiment was conducted, and an incremental differentiable search method was finally chosen. Many variables, including a large search area, resource-intensive training, extensive assessment, iterative procedures, hyperparameter tweaking, resource restrictions, design complexity, and search algorithm efficiency, contribute to the time-consuming nature of architecture search. Weight sharing, early quitting, and proxy models are examples of mitigating techniques. With benefits including differentiability, fast exploration, regularisation, scalability, robustness, and interpretability, incremental differentiable search techniques enhance discrete architectural search optimization by utilizing continuous relaxation and gradient-based optimization. The comparison between the differentiable architecture search method and the progressive differentiable architecture search method is shown in Figure 13.
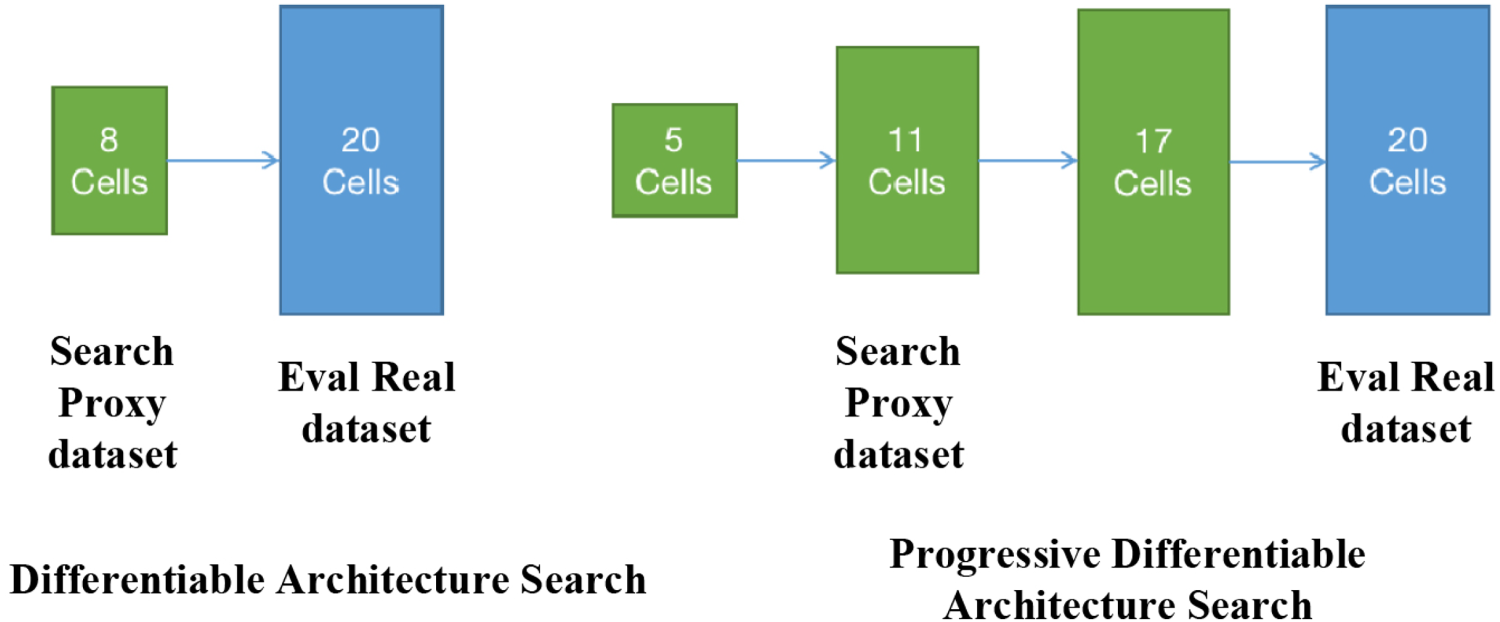
Visualization diagram of differentiable search and progressively differentiable search process.
The architecture search in this paper is firstly trained on a part of the training set; that is, a part of the training set is selected as the proxy training set first, and a proxy model is obtained from the training. The starting point of training the proxy model is to reduce the training cost. By using fewer computer resources, enabling faster iterations, and cutting expenses, proxy model training lowers the cost of training. In addition, it makes it easier to explore broader search areas, prune early, and transfer ideas, which results in more effective architectural search procedures and the identification of high-performing neural network designs. As shown below, a, b, and c in the figure are three search stages: the display of the above-mentioned progressive search process. The corresponding network of the first stage contains 5 Cells, that is, a five-layer network architecture; the second stage is 11 Cells, an eleven-layer network architecture; and the last stage is 17 Cells, a seventeen-layer network architecture. The three search stages are performed on the proxy dataset, and the resulting surrogate model is also trained.
During initialization, there are all possible. The calculation formula for this probability is as follows:
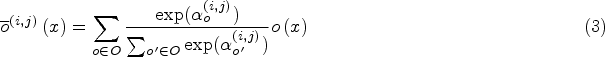
Among them,

Each Cell has two inputs and one output, so adding the input and output, each Cell contains a total of 7 nodes. The network structure is composed. The stride of all operations is 1, the Reduction Cell changes the feature to half of the input, the stride of the operation is 2, and at 1/3 of the network depth and Insert a Reduction Cell at 2/3, and use Normal Cell for the rest.
Each cell has two inputs and one output, so adding the input and output, each cell contains a total of 7 nodes. The network structure is composed. The stride of all operations is 1, the Reduction Cell changes the feature to half of the input, the stride of the operation is 2, and at 1/3 of the network depth and Insert a Reduction Cell at 2/3, and use Normal Cell for the rest.
The architecture search is designed in three stages; this design aims to reduce memory usage. Architecture search is a very time-consuming and memory-intensive process. If you search directly on the image-morphological effect dataset, current general machines and graphics cards cannot support it. Therefore, we have the following two search strategies: video memory and time. The first strategy is to train with a small dataset as a surrogate dataset. For example, when teaching the structure of the classification network, if we want to search the classification network on ImageNet, we can choose to use the CIFAR dataset as a proxy dataset, perform a Cell structure search on this dataset, and then use the ImageNet dataset. Expand the number of network layers on the training to obtain parameters suitable for ImageNet. This article searches for information on the public art sculpture dataset. A range of techniques are used to increase the generalization of a proxy model over various examples, including representative subset selection, cross-validation, transfer learning, data augmentation, regularization, hyperparameter tuning, performance monitoring, domain adaptation, and external evaluation. The public art sculpture dataset is relatively large, so our specific approach is to take part in the public art sculpture training set as a proxy data set to train the proxy model. A collection of public art sculptures is used to train and assess the AestheticNet model. This dataset, which consists of sculpture photos with annotations and labels, is essential to the study since it offers the input data required for the model’s creation and verification. The study aims to investigate the connection between aesthetic expressions in public artworks and picture form effects. The model can learn from the dataset and make accurate predictions about picture form effect scores thanks to the annotations and labels. The diversity and quantity of the dataset add to its generalization and resilience. The dataset is a significant asset for research on intelligent and parametric design in public artworks.
The second strategy is to extend the search stage. We divide the training into three phases to ensure it can be performed under 11G video memory under the 1080Ti or 2080Ti graphics card. In each stage, top-n operations are selected, other candidate operations are discarded in the next stage, and only top-n is reserved as a candidate operation for training. The number of cells is expanded to ensure training under limited memory.
Hollow convolution, also known as dilated convolution, can expand the receptive field of the convolution operation. With weight sharing and uniform filtering across the input, the convolutional operation increases the receptive field without requiring new parameters. Without adding more parameters, methods such as dilated convolutions, layer stacking, stride and padding adjustments, and filter size augmentations broaden the field. Atrous convolution is widely used in semantic segmentation and target detection tasks. By expanding the receptive field, enabling multi-scale feature fusion, and supporting boundary detection, atrous convolution – also called dilated convolution – has dramatically improved semantic segmentation and target detection in computer vision. This has increased the precision and effectiveness of contemporary computer vision architectures. Atrous convolution can expand the receptive field of convolutional neural networks and capture multi-scale context information without introducing additional parameters, extending the receptive field while ensuring the model size. A schematic diagram of atrous convolution is shown below.
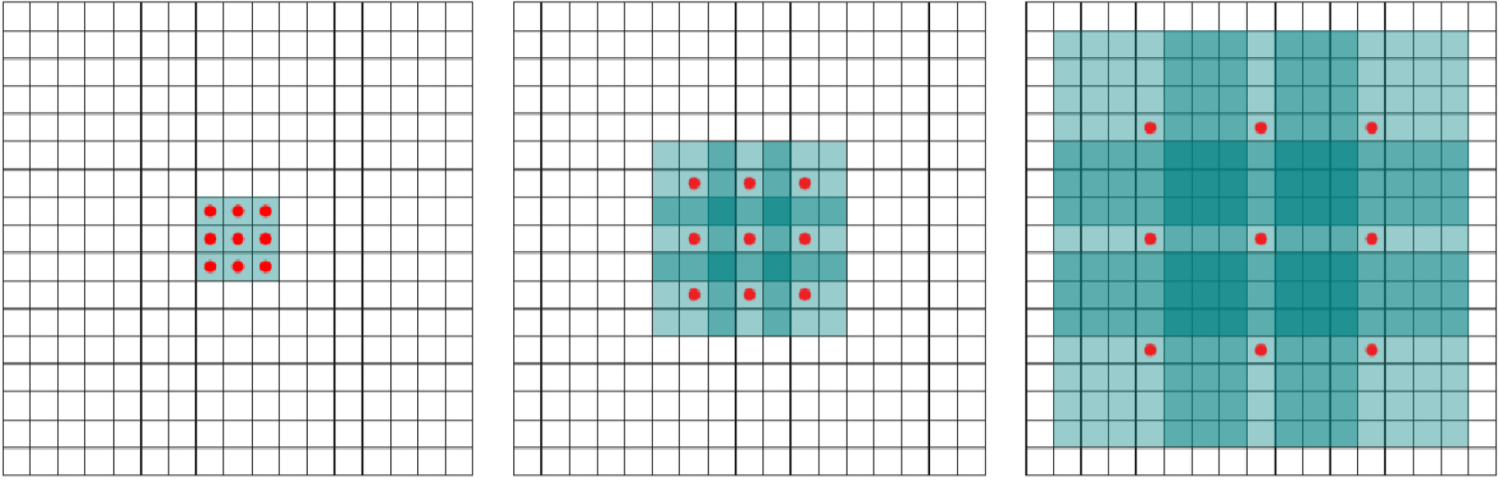
Schematic diagram of hole convolution 1.

Schematic diagram of hole convolution 2.
Figure 14 shows, from left to right, a 3*3-hole convolution with a dilation rate of 1, which is our standard ordinary convolution, and a 3*3-hole convolution with a hole rate of 2 and 3. Figure 15 explains the difference in the working principle of hole convolution and ordinary convolution. The left is the convolution process of ordinary convolution, and the right picture is the convolution process of the whole convolution. We can see that the receptive field of hole convolution is apparent. More significant than ordinary convolution, more peripheral information can be obtained.
Separable convolution, or depthwise separable convolution, is the core module of MobileNet and Xception. The purpose of ordinary convolution is to map both cross-channel correlation and spatial correlation. Reduced parameters in model designs allow for lighter models and quicker inference times because of separable convolution. Although it could compromise training efficiency and representational capability, it enhances regularization, energy efficiency, and deployment flexibility. It affects the deployment and development of deep learning models. The idea of separable convolution is to explicitly decompose the convolution operation into a series of operations that independently view cross-channel and spatial correlation. Thus, the process is simpler and more efficient, and the number of parameters is much lower than that of ordinary convolution, which reduces the amount of calculation needed. The schematic diagram of separable convolution is as follows.
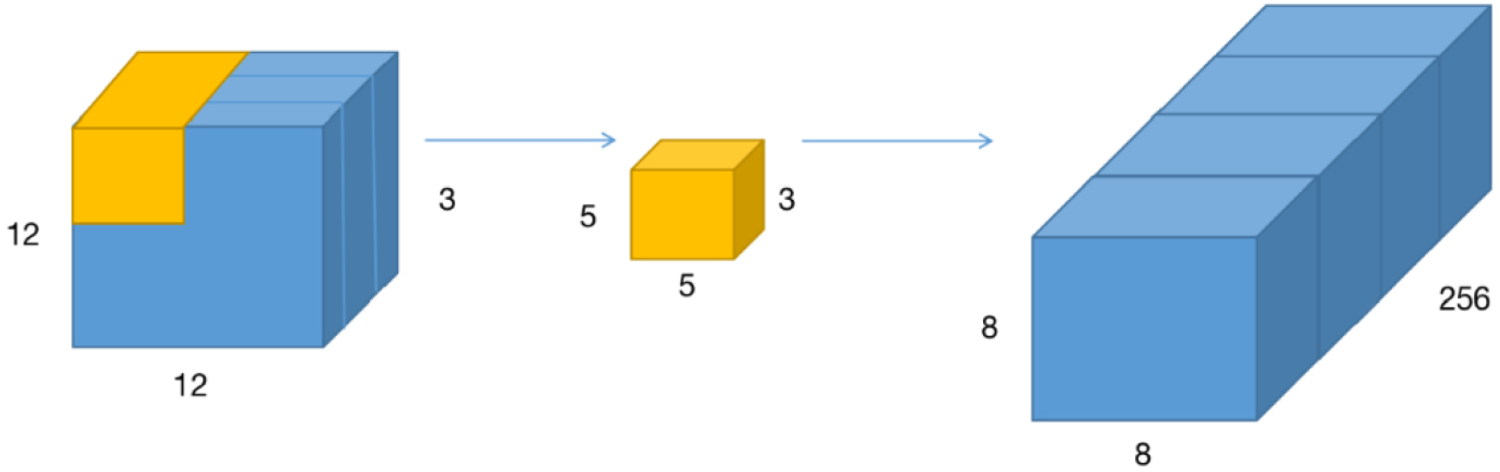
Schematic diagram of conventional convolution.

Schematic diagram of depthwise separable convolution 1.
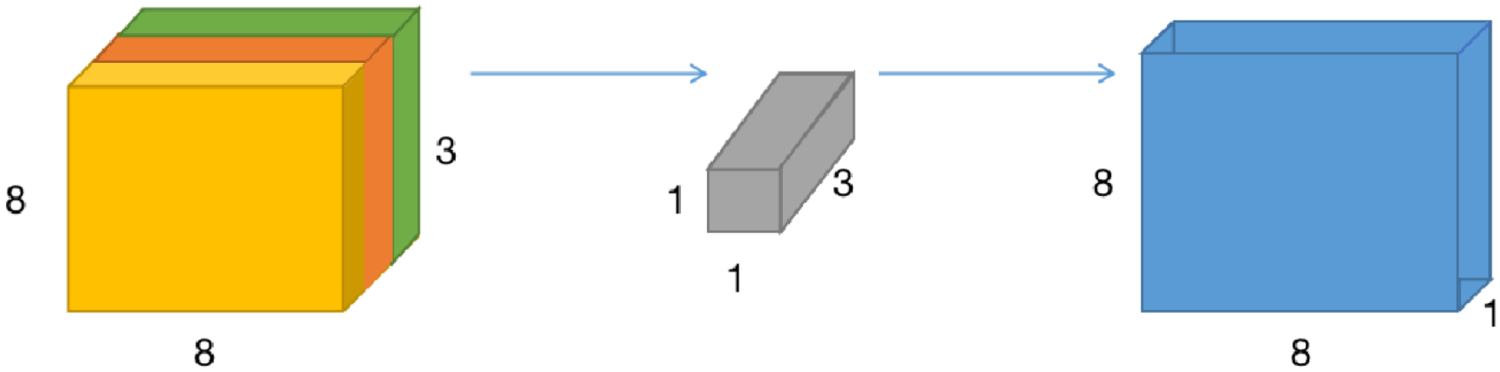
Schematic diagram of depthwise separable convolution 2.
The normal convolution kernel convolves three channels at the same time. That is, three channels output a number after one convolution. The first step uses three convolution kernels to convolve the three channels, respectively, so that three numbers are obtained after one convolution, and then a 1*1*3 convolution kernel is used to obtain a number.
Conventional loss functions include Sigmoid, SoftMax, etc. The formula of the joint SoftMax loss function is as follows:

As mentioned above, in this paper’s experiment, the prediction of image morphological effect scores is simulated as the distribution of predicted image morphological effect scores. The loss function used is EMDLoss, which measures the distance between the two distributions. Combined with this task, our loss function can be expressed as follows:
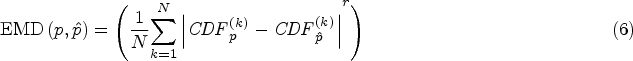
Based on observations, we found that the data distribution of the public art sculpture scoring habits also aligns with human scoring habits. Then, through analysis, this paper finds that the distribution of the data set itself can be used as a weighted item. This weight item represents the distribution of the data set itself, and we can use this distribution feature to calculate the loss function. By introducing the Weight term, this paper proposes a self-weighted excavator distance, SELF_WEIGHTED_EMD Loss function, by multiplying the original EMD loss function by the distribution itself, the improved loss function is as follows:
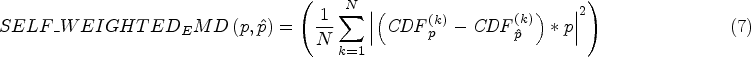
The spatial Attention mechanism module is shown in Figure 19. The maximum pooling and average pooling are performed in the spatial dimension. Also, the final input to the sigmoid activation function scales the weight value between 0 and 1. The formula is as follows: The two operations are parallel, output to the multi-layer perceptron, the output results are added together element by element, and finally, the sigmoid function; the formula is as follows:
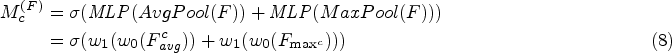

Spatial attention mechanism.
Aesthetic annotations Aesthetic quality annotations. This part of the label is what we use in the image form effect experiment. Each sculpture image corresponds to several photographers, photography enthusiasts, and professional sculpture image workers. Scores: The participants who scored a sculptured image ranged from 78. It ranged from 549 to 549, with an average of about 210 points per image, and the voting score ranged from 0 to 9. The labeling format, the distribution of the mean and variance of the scores are as follows.
Annotation example of public art sculpture dataset.

Multi-feature point collection of public sculptures.
The art sculpture image forms an effect data set introduced in the previous section. The validation set contains 25600 sculpture images. The evaluation indicators are also mentioned above, using four indicators: accuracy, LCC linear correlation coefficient, EMD excavator distance, and SROCC to measure the effect of the model. Since we first obtained AestheticNet on the public art sculpture dataset through NAS architecture search in the previous chapter, the following experimental results will compare AestheticNet with some existing image morphological effect networks on the public art sculpture dataset. Second, we will gradually compare the experimental results according to the previous optimization strategy and get the experimental results analysis.
During our experiments, we first searched for surrogate models of image-morphological effects on a training set of public art sculptures through the number of layers of the proxy model is 8. The second step is to obtain the final 20 layers using the Normal Cell and Reduction Cell obtained during the search process of the proxy model. Imagination form effect model. However, there are problems with this search method. First of all, the number of layers of the proxy model is 8. The Cell structure obtained by searching on the proxy model is directly used in the 20-layer network structure, and there will be a depth gap problem; secondly, this method tends to Select the skip-connection structure, that is, zero operation, because this operation can speed up forward/backward propagation, resulting in faster gradient descent, but too many skip-connection operations will seriously affect the effect of the model; finally, this method under The memory usage is significant. If a single 2080Ti has 11G of video memory, more is needed to support a large batch size, resulting in too long training time.
Table 1 is the experimental comparison of differentiable and progressively differentiable architecture searches. Similarly, 5 is divided into the dividing point, and sculpture images are divided into two categories: high-quality and low-quality. The accuracy and recall rate of each class were calculated, respectively. The high-quality sculpture image was used as the positive class to calculate the accurate recall rate. The low-quality sculpture image was used as the positive class to calculate the precise recall rate. At the same time, the correct rate of the second classification was calculated.
Comparison of differentiable architecture search and progressive differentiable architecture search


The standard deviation of the label of the public art sculpture data set.
We found that progressively differentiable architecture search methods outperformed differentiable architecture search methods experimentally. Many techniques, such as self-weighted Loss, Channel-wise Attention Mechanism (CBAM), and an adaptive pooling layer, have improved the AestheticNet model. Giving each data point a distinct weight enhances the Loss function and increases learning capacity. The Channel-wise Attention Mechanism concentrates on pertinent elements in sculptural images to improve picture form effect predictions. More effective feature extraction and improved depiction of picture form effects in public artworks are the outcomes of the adaptive pooling layer, which dynamically modifies the pooling process based on input data. With these efforts, we want to improve the prediction power of the AestheticNet model for image form impacts in public sculptures, advancing intelligent and parametric design in public art. In the above steps, we searched the resulting model AestheticNet because it contains depthwise separable convolution isotypes; a significant advantage is that the model parameters are small and relatively lightweight and can be deployed on small devices such as mobile terminals without requiring too high equipment hardware conditions. Comparison of parameters of essential backbone feature extraction networks such as DenseNet and comparison of whether pre-training models are needed.
AestheticNet and common feature extraction network parameter comparison table

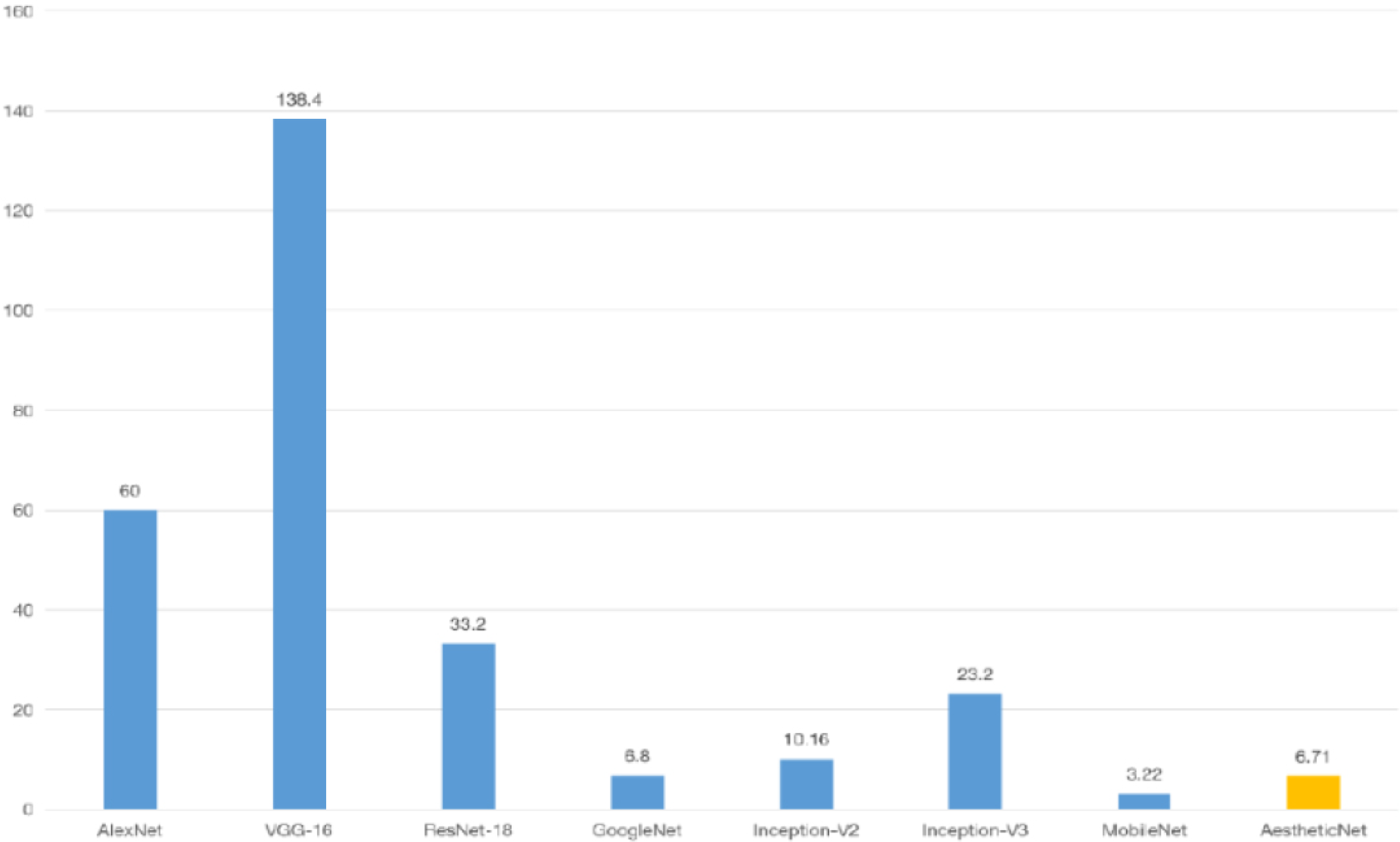
Comparison of AestheticNet and common feature extraction network parameters.
After completing the AestheticNet training, we test it on the test set. For the final score, we will follow the previous related work and consider the sculptural image morphological effect score greater than 5 points as a high-quality sculptural image shape effect is transformed into a binary classification problem, and the accuracy rate. Healthcare, banking, retail, manufacturing, transportation, energy, education, entertainment, and security are just a few areas that have transformed thanks to deep learning and AI technology. These developments strengthen automation, predictive maintenance, supply chain optimization, risk assessment, diagnostics, and quality control while improving customer insights and supply chain optimization. Compared with some existing research, the experimental results are summarized as follows.
Comparison table of proposed and existing techniques

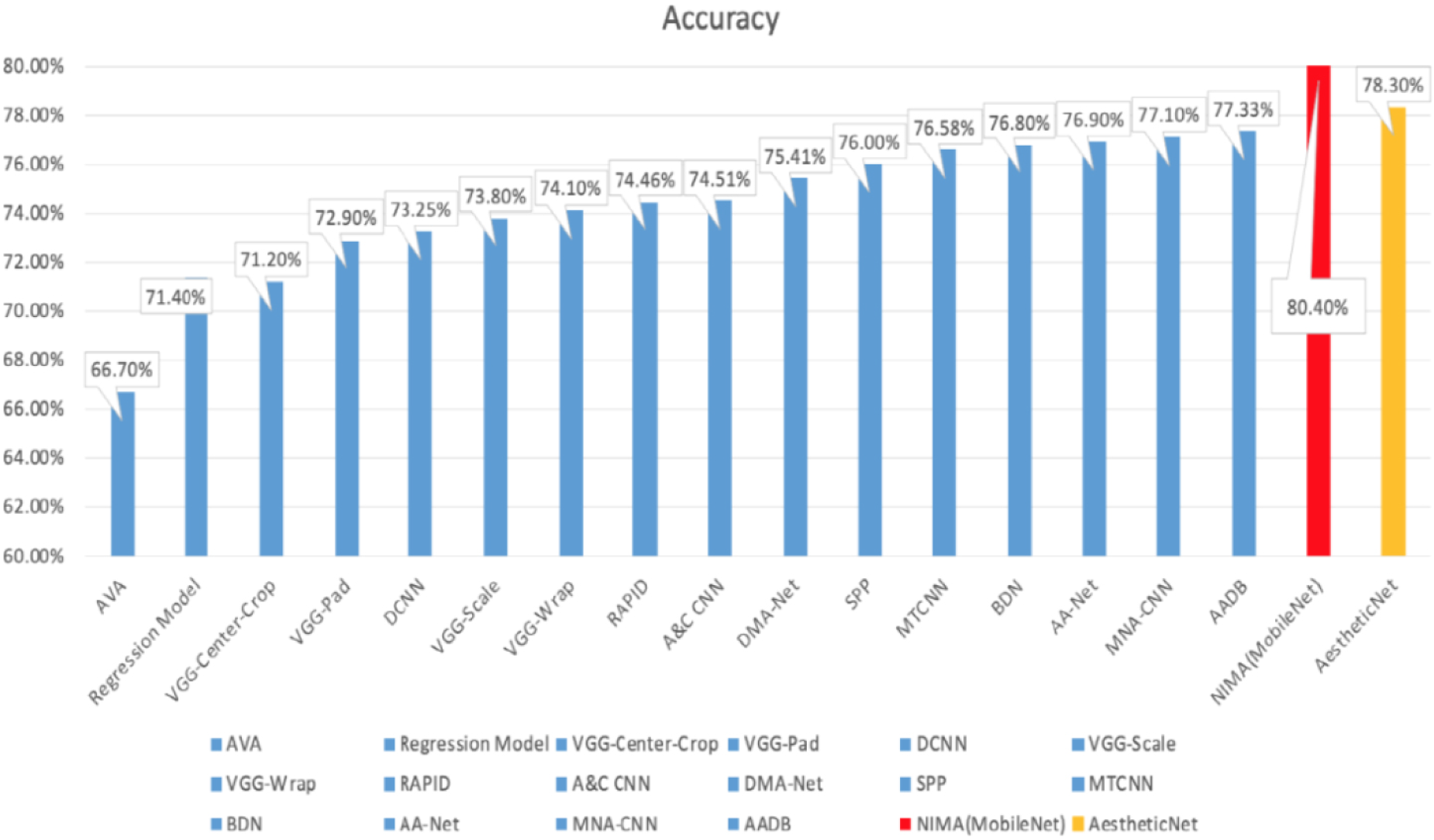
A comparison between AestheticNet and other image morphological effect models.
This study examines the use of augmented and virtual reality technologies in public art design. It seeks to expand the processes used in creating public art, alter how it is displayed, and investigate novel applications of public art design. The author examined cutting-edge technological methods and cooperative innovation in China through in-depth case studies, technical demonstrations, and creative practice with virtual reality technology. The study discovered that contemporary technology is being utilized to enhance public art and culture and that public attention to public equipment based on sensors and virtual reality technology has grown by over 60% [23]. Twenty students with backgrounds in design are used in the study to assess sculpture pictures as it investigates how traditional cultural imagery is expressed in sculpture modeling. Statue sculptures from Yulin Grottoes were utilized to gather data, which was then put into the DE-GWO model to forecast traditional cultural images. The study’s findings, which emphasize the expressive style of traditional cultural imagery in sculpting art, showed a strong match and predictive strength between expected and actual values [24]. The research proposes a generative confrontation network model for creative picture-style transmission. After optimizing the model, spectral normalization and a fresh residual structure are added. The ResNet network handles problems with gradient disappearance and network deterioration. According to experiments, the suggested model has a higher approval rate and a better visual experience among young people, with a 58% evaluation rating. When converting picture styles, the enhanced algorithm performs better than the original [25]. Table 3 shows that our proposed NAS architecture is more efficient than the previous techniques.
The main introduction is to use the NAS architecture search technology to carry out customized searches on the public art sculpture data set. The new model AestheticNet obtained by the search can predict the distribution of image morphological effect scores and compare them with other existing image morphological effects on the validation set. The model algorithm is compared, which proves the effectiveness of the customized search scheme. Secondly, the improvement of the EMD Loss function is based on observing the result distribution. Considering that the score represents the distribution’s characteristics, we propose a self-weighting method to improve the loss function; we introduce a two-dimensional Attention mechanism to simulate human beings. This method is currently prevalent in computer vision deep convolutional networks. Finally, the image shape effect model obtained by training is used to predict the score of the image shape effect sculpture images with manual scoring in some datasets, and the effectiveness of the image shape effect model is proved by comparing the results of manual scoring. With real-time image analysis techniques, multi-modal data, transfer learning, and human-centric assessment methodologies, the project seeks to improve intelligent public sculpture design while promoting multidisciplinary collaborations and resolving ethical issues.
Footnotes
Funding
Shanxi provincial education reform project, project number: RC2300003281; Language combination center project, project number: RZ2300000098.
Conflict of interest
Authors do not have any conflicts.
Data availability statement
No datasets were generated or analyzed during the current study.
Code availability
Not applicable.
Authors’ contributions
Wei Li, is responsible for designing the framework, analyzing the performance, validating the results, and writing the article.