
Abstract
In computer vision, recognizing human activity or behavior is a core challenging problem. This article provides a crisp study of human activity recognition systems in the area of visual surveillance. These systems are used for analysis and understanding of the human behavior. The study starts with the description of various emerging video processing domains, followed by a general process of human action recognition. Then the article covers human detection techniques from images and video. Finally, article also provides a survey of different features and models used in activity recognition systems and an overview of benchmark dataset of video surveillance. From this state-of-the-art survey, researchers can outline promising directions of research.
Introduction
Visual surveillance is becoming vital for protecting people and property in the recent era when crime rates are increasing [15]. As high-quality cameras are now available easily, many surveillance cameras are already installed around us, but there is a lack of manpower to look after continuous activities happening 24 hours a week [22]. Moreover, such surveillance system produces a lot of video data which leads to increased storage requirements [18]. This storage requirement can put an additional financial burden. Hence, we require an efficient visual surveillance system, which helps to reduce large manpower, human errors, and storage cost [6]. Such problems motivate us to study visual surveillance among other emerging video processing domains like video summarization, video retrieval, video labeling, video clustering, and video classification. In this article, video surveillance or visual surveillance terms are used interchangeably.
Surveillance cameras can be a far more useful if instead of passively recording footage, they can be used to detect events requiring attention as they happen, and take action in real time. In most of the surveillance systems closed-circuit television (CCTV) cameras are used. Thermal cameras, which are also called infrared cameras, are used for night surveillance. For real-time surveillance, we require live streaming of data, which needs to be transformed in form of the frame from surveillance device to the processing device. In addition, the optimal frame rate for any surveillance can be based on criteria, like a scene under surveillance, movement in relation to camera frame, camera sensor features, and available light. The preferred standard frame rate is 25–30 frames per second (fps), which requires a bandwidth of 7–8 Mbps [45] for data transfer. As we reduce the frame rate, less bandwidth is required for processing.
Moreover, the video process of surveillance systems has inherited difficult challenges while approaching a computer vision application, such as occlusion (overlapping region) handling, poor illumination or luminance, camera calibration, sensor noise, and dynamic background changes [6, 8, 22]. We can handle poor illumination or luminance and noise problems in data using more reliable features.
A few surveys exist on Human Action Recognition (HAR). However, the surveys do not suffice all the aspects of HAR systems to neophytes. Hence, we write this article to provide soup to a nuts survey of human activity recognition methodologies for person detection, features identification and models used for HAR. Next, we mention important situations in which this work can become a crucial guide for conducting research: (i) Choosing and understanding interrelation of a particular video processing domains. (ii) Understanding of exhaustive taxonomy of HAR. (iii) Deciding about which HAR system classification to work on based on the number of people involved in the activity. (vi) Choosing the best person detection technique from image or video data. (v) Deciding the best approach for action recognition. (vi) Selecting the best video processing technique for each step of HAR. (vii) Understanding of feature detector-descriptor approach thoroughly. (viii) Selecting the appropriate activity classification model. (ix) Choosing the best tool and libraries for HAR system implementation. The researchers who have to satisfy formal requirements, the extensibility, availability of source code, proper documentation, and many other criteria are important for making the final decision. (x) Deciding datasets for either controlled or uncontrolled environment based on different criteria, like the number of actor involved, resolution, scenario considered etc.
This article is divided into ten sections. The article present a survey on various video processing domains and a general process of HAR in Section 2.1; Section 2.2 presents survey work done by researchers for action recognition. In Section 3, we presents the taxonomy for Human Action Recognition (HAR), which provide overall idea of survey carried out. In Section 4 we presents a Human action Recognition taxonomy. Subsequently, the article presents the human detection techniques in Section 5. In addition, Sections 5.1 and 5.2 provide survey of techniques used by researchers to detect human from images and video data, respectively. Moreover, Section 5.2 considers various techniques for the video data, which are captured from either static and/or moving cameras. From which one can select best person detection technique for their work environment. Section 6 presents survey and analysis of HAR. Specifically, Sections 6.1 and 6.2 present a survey of 15 selected papers covering major problems applied in HAR using video processing techniques and 3-D space-time volume features, respectively. Above all, Section 6.3 presents the types of extensively surveyed features used by researchers for HAR. In addition, article also presents feature detector-descriptor approach used for activity recognition. From this knowledge naive researcher in this domain can understand the HAR system classification and can choose best features for their system. Furthermore, the article present a survey of activity classification models in Section 7. We present survey and analysis of tools and technologies available for video processing, along with action video dataset for controlled and un-controlled environment in Section 8. Conclusively, Section 9 presents proposed work and methodology based on our findings and Section 10 summarizes the work in form of conclusion.
Interrelated video processing steps in various related domains
Interrelated video processing steps in various related domains
Types of emerging video processing domains.
In this section, we present overall gist of video processing domains.
Background knowledge
This subsection describes importance of human action recognition (HAR) followed by the general process of HAR.
Video processing domains
The research community is pursuing research in many video processing domains. These emerging domains are shown in Fig. 1.
The first domain is video surveillance, which is the means of watching the video over electronic equipment such as closed circuit television (CCTV). A great implication of video surveillance is for monitoring the behavior and activities of people, basically for protecting, directing, and managing them. Nowadays, surveillance is used by government firms at many places for public safety, which lends a helping hand to the surveillance authority to detect criminals and provide adequate evidence to closely surveil. For example, in Indian Railway, video surveillance is important security requirement to be provided at waiting hall, railway yard, reservation counter, parking area, platforms, main entrance/exit etcetera of the railway station to capture images and examine human behavior. Proprietary firms also provide surveillance for the prevention of crime, investigation of crime and gathering of intelligence [20].
The second domain, video summarization is a process of presenting and creating a concise view of entire video. This technique aims at extracting features from frames and then clustering the features in order to group the frames with similar content. The most representative sample from each cluster is selected as key-frame, which shall compose final video summary. The Third important domain is video retrieval [40], which is a problem of retrieving a relevant video from a large video collection over world wide web. It is a content-based visual information retrieval (CBVIR) problem. Mainly, video retrieval is a two-step process, where the first step is to extract representative features from video frames and then to find an appropriate homogeneity model to select identical video frames from the whole collection of videos.
The fourth domain is video labeling or annotation, which is the process of adding semantics and descriptors to the video contents to enrich the result of video search. Due to the explosive growth of video data, it is very much required to retrieve and access the desired video data. Hence, video labeling is becoming an essential step for many computer vision applications to annotate the data automatically rather than manually, which requires intensive labor cost. Next two domains are video clustering and classification. Both methods are used in pattern classification. Video clustering is an unsupervised learning method where grouping is done based on the similarity, which can predict the cluster of any new sample. Whereas, video classification is a supervised learning method which requires labeled training set with examples from each category. Based on similarity to the parametric model, decides a class of a new sample. Next domain is video compression. Video compression methods (codecs) orchestrate video signals which can dramatically minimize the storage and bandwidth by discarding insignificant information.
There are other video processing domains which are also popular in research community such as Video steganography, which is a technique for secure data transition; Video mosaicking for transferring maximum information from video frames into a large view image; and Photosynth, which is a technique to combine a collection of images from different viewpoints into an extended panoramic image. However, review of these domains in detail is out of our scope of the article.
Although the objective of each video processing technique is different, there could be some common intermediate processing steps. To emphasize similarity, we present Table 1 showing various steps of different video processing domains. We have identified the following processing steps across different domains: scene understanding (SU), object identification (OI), object tracking (OT), feature extraction (FE), Bag-of-Visual-Words (BoVW), and model generation (MG). For each, video processing domain, common steps are marked with tick. We have also presented additional steps required for each domain in a separate column. Using the information in Table 1, a researcher can understand interrelation among the domains and can apply the knowledge into another domain. Out of these video processing domains, our focus is on visual surveillance.
General process of human (object) action recognition.
In general, a video processing task follows four steps, namely object segmentation, object classification, object tracking, and activity recognition, in Fig. 2. We now describe each step in detail underneath.
Object or motion segmentation
In computer vision, object segmentation deals with identifying moving objects like human, bird, vehicle or animal from the video data. Moving objects can be extrected by motion segmentation. Few approaches to motion segmentation are background subtraction [2, 6, 9, 12, 19], foreground extraction [12], temporal differencing [5, 18] or using optical flow [1].
Object classification
The second step of HAR is object classification, which is the process of classifying the object of interest. In video surveillance, object classification is carried out using shape-based [1, 2, 8], color-based [14], and motion-based techniques [6, 8, 15]. Researchers have categorized object or motion segmentation and object classification as a low-level vision problem.
Object tracking
Object tracking is the process of estimating path followed by the particular object in the image plane. This path is a trajectory of the object. Object tracking can be difficult due to illumination changes, complex object shape, and full or partial occlusion etc. Many well known trackers are used like Mean-shift tracking [2], Kalman filter [6, 9, 18], KLT tracker [3, 15], Optical flow [1, 8, 17] etc. Object tracking step is categorized as intermediate-level vision problem by researchers.
Taxonomy of human activity recognition (HAR).
Activity recognition
In the computer vision, one of the most challenging tasks is behavior learning of moving objects and understanding of activity from the visual surveillance. Hence, this step is categorized as a high-level vision problem. The research in this domain mainly focuses on detecting endangering human behavior or suspicious human activities. If an abnormal behavior is detected then an alert message can be generated.
This subsection presents survey works that has been done by researchers for different domains such as action classification, abnormal activity detection, and types of datasets available in visual surveillance.
Chaquet et al. [21] have presented a survey on video datasets available for human action and activity recognition. Their work contains a precise survey of controlled and uncontrolled datasets and video repositories which are available on-line. They have considered different characteristics of datasets like a number of actions, the number of views, indoor or outdoor scenes, static or dynamic camera movement etc. Ko [22] have reviewed on behavior analysis in video surveillance for homeland security. Their paper briefly described techniques for object and motion detection, object classification, object tracking, and motion extraction techniques. In their work, Section-VII the person identification techniques are missing. However, they have discussed major existing behavior understanding methods.
Significant application domains are discussed by Ke et al. [24] and have presented a review on video-based HAR. They have made a survey on object segmentation, feature extraction, activity detection, and action classification techniques. Poppe [33] also presented a survey on vision-based HAR. In their work, they have discussed the challenges and characteristics of the video processing domain and common datasets. The authors have also reviewed different image representation and action classification techniques.
A review of intelligent multi-camera video surveillance is presented by Wang [35], which covers multi-camera calibration, tracking, and activity analysis. The author has worked on re-identification of the same person and presented a survey on object re-identification techniques, followed by HAR in multiple camera views. Vezzani et al. [36] have presented a survey of people re-identification in Surveillance and Forensics. The authors have discussed work done in people re-identification, machine learning with the application scenarios, followed by datasets available for people re-identification.
Dawn and Shaikh [39] have presented a survey on HAR with spatiotemporal interest point detector. They have reviewed components of STIP-based HAR techniques, followed by some popular features detectors and descriptors. Then they have presented performance comparison of STIP-based methods on Weizmann [51] and KTH [50] datasets, and also shown a brief overview of related datasets available for HAR.
Taxonomy of HAR
Classification of human activity recognition (HAR).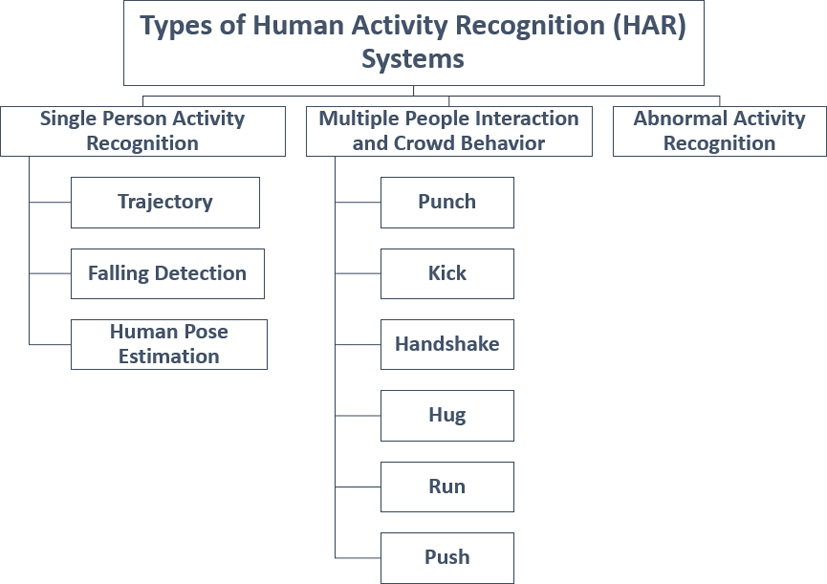
We present an overall glimpse of the survey that we carried out in Fig. 3. Mainly, our survey is branched into five parts namely, Types of Activities; Human Detection Techniques for Types of input; Approaches for HAR; Classification of Models; and Tools and Video dataset.
The HAR systems are classified based on the number of people involved in activity: Single Person Activity, Two people interaction or crowd behavior, and Abnormal activity. The survey carried out for Types of Activity is present in Section 4. One of the foremost step in HAR is to detect a human from the image or video data. The survey of different techniques for human detection is carried out in Section 5.
There are different approaches followed by the researchers for activity recognition task: Using video processing techniques, feature-based method, and body modelling. The first approach is using background modeling and tracking the bounding box region. In Section 6.1, we present an extensive survey of work done in HAR using various video processing techniques. The second approach is a feature detector-descriptor approach for finding a trajectory of a person using local sparse features from 3-D space-time video volume. Spatio-temporal interest points (STIP) are extracted from video data. We present a concise survey of work done in HAR using STIPs from 3-D space-time video volume in Section 6.2. The third approach is a modeling a 3-D human body shape and identification of human activities using wearable sensors. Activity recognition using 3-D human body shape modeling and wearable sensors give good accuracy, but the computation of 3-D joints is very tedious and use of sensors incur extra cost. The detailed survey of Body modelling and wearable sensors is out of the scope of the article. The feature detector-descriptor approach is widely used by researchers because STIPs are proved invariant to rotation, scale, and translation. Hence, the detector-descriptor approach provides better accuracy for action recognition. The survey of detector-descriptor approach is carried out in Section 6.3.
To classify actions, different classification models are used. We present the survey of classification models in Section 7. There are different tools and languages which supports vision processing. The survey of tools and dataset is present in Section 8.
Basically, human activity recognition systems are classified into three categories, which is prepared and shown in Fig. 4.
Single person activity recognition
In this subsection, we present an overview of various types of single person activities recognition.
Trajectory:
A trajectory [43, 44, 45] is a path that a person follows as a function of time. The trajectory of a tracked person in a scene is used to analyze the activity or behavior of the tracked person. Wang et al. [30, 34] have used dense trajectory feature to find out human action and shown promising results. We describe trajectory in more detail in Section 6.3.1.
Falling down detection:
Another well-known topic of single person activity recognition is the fall down detection [2, 9]. Falling detection is essential for security and safety environments, mainly for the elderly who live alone at home and also for child-care systems. Yang et al. [2] have worked on home safety. In 2016, Zulkifley et al. [9] have extracted unique features that can detect falling down and aggressive behavior.
Human pose estimation:
Human pose estimation [5, 8, 18] is also a popular topic in the computer vision research community. The estimation of human postures like standing, sitting, or sleeping etc. convey significant information to find out human activity (e.g. full cross legs posture in a series of frames defines running activity). Sivarathinabala and Abirami [8] proposed work for human pose recognition system.
Two or multiple people interaction and crowd behavior
Two or Multiple people interaction and the crowd behavior [3, 8, 11, 13, 18, 19, 30, 34, 36, 40, 41, 43, 47, 48] have drawn attention recently due to the needs of environment security in several ways. Recognizing/Surveilling two-person activity and/or crowd behavior like punch, kick, handshake, hug, kiss, run or push etc. is of paramount importance to find out normal behavior of the people, which will help to find the behavior of the persons or the activities happening in a crowd. Lao et al. [1] have worked on crowd behavior actions like people counting using Viola-Johns face detector and running detection using optical flow. A review of crowd analysis is presented by Kumar and Sureshkumar [12]. The authors have tackled three most important issues including abnormal crowd detection, crowd tracking, and crowd behavior understanding using Gaussian Mixture Model (GMM), blob analysis, and Histogram of Oriented Gradients (HOG). Laptev et al. [44] have worked on human actions in realistic video settings using spatio-temporal features. To extract feature authors have used Bag-of-Features method and non-linear support vector machine (SVM) for classification of activity. Work on two-person interaction detection system using improved dense trajectory and 3D spatio temporal interest points (STIP) is presented by Shu et al. [46]. The authors have used HOG, Histogram of Flow (HOF) and Motion boundary Histogram (MBH) methods for feature extraction.
Abnormal activity recognition
An anomaly (rare events) is known as unusual or abnormal activity [3, 12, 36]. Such activities very much depend on the contexts and the surrounding environment, which are not observed frequently. Otherwise, it is normal or usual activity. A suitable approach is to build a model by training normal actions and consider new observation as unusual or abnormal if they deviate very much from the trained model. Al-Nawashi et al. [5] have worked on an intelligent surveillance system for abnormal HAR in an academic environment. The authors have used the temporal differencing method to detect moving object, followed by erosion and dilation binary statistical operations to remove noise. Using shape model they have extracted human motion region and contour coordinates, which are fed to SVM to classify normal or abnormal activity. The authors have implemented intelligent surveillance system using MATLAB application tools. Elarbi-Boudihir and Al-Shalfan [18] have modeled a system to detect an abnormal activity. They have used temporal differencing method for object detection. To track an object binary statistical operations and Kalman filter method is used. The authors have used SVM classifier to classify the behavior and C++ machine learning API to implement the scenario.
Survey and analysis of person detection
In this section, we have prepared a classification of the techniques for detecting the human object from image and video data. This classification of techniques is shown in Fig. 5.
Person detection techniques from images and video.
Haar-like features
The Haar-like features are image features used for object recognition. Haar wavelets are used in real-time face detection. The method works with only image intensities (i.e., the RGB pixel values at each and every pixel of the image). A Haar-like feature considers adjacent rectangular regions at a specific location in a detection window. There are basically three types of features as shown in Fig. 6. The white area of detection window is subtracted from the black once. The features are extracted from the sub-windows of the sampled image as shown in Fig. 7. The main advantage of the Haar-like feature is fast calculation using an image representation technique called an integral images. The concept of the integral image can be found in [60].
Basic three types of Haar features.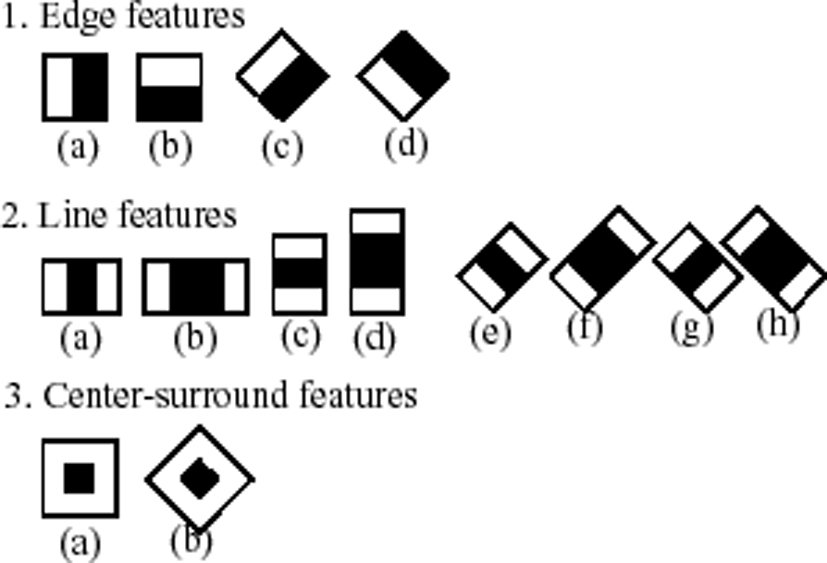
Features extracted from sub window of the sampled image [1].
Lao et al. [1] adapted the Viola-Jones face detector and proposed Haar-like rectangle features to detect a face. There are variety of applications where this technique can be utilized like, people counting, special person prohibition to access the restricted area and so on.
The process of background subtraction.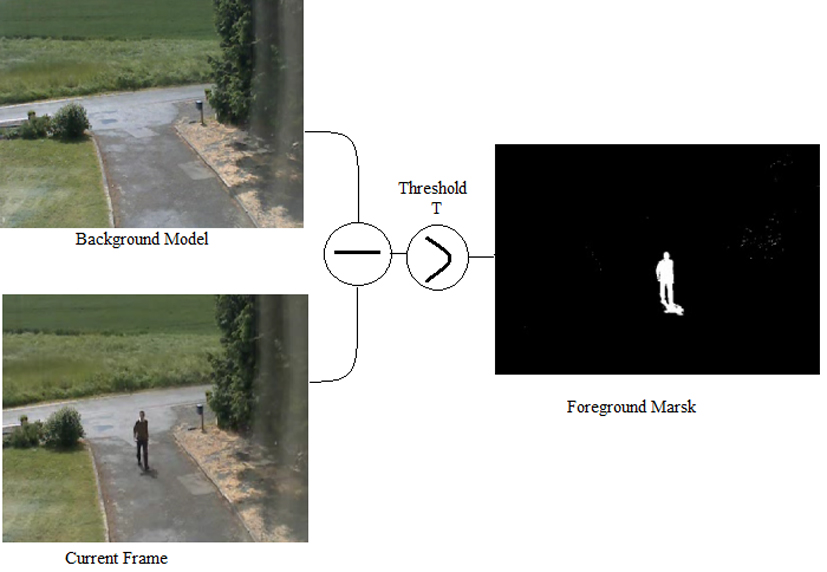
HOG [49] are the feature descriptors widely used in computer vision and image processing to detect the human object. The technique counts occurrences of gradient orientation in small patches of an image. Figure 16 shows the HOG feature extraction method. The HOG person detector uses a sliding detection window which is moved around the image. At each position of the detector window, a HOG [49] descriptor is computed for the detection window which is distributed over eight bins. The HOG descriptor is shown to the trained SVM, which classifies HOG feature descriptor as either person or not a person. Nazare and Schwartz [6] adopt this technique for object detection. We discuss this method in Section 6.3.2 in detail.
Principal component analysis (PCA)
PCA is useful in finding the patterns in high dimensional data and converting data in such a way that it highlights differences and minimize similarities. More importantly, PCA is used for compressing data without losing orthogonal features. To recognize a human face, face templates can be used. The method places the templates at every location on the given image and compares the pixel values in the underlying image region. If the object is scaled, rotated or skewed on the image then, every possible transformation of templates are required, which take a lot of memory. Hence, efficient way to store and search for a match is required. To reduce these costs, a dimensionality reduction method is used to store the image in terms of eigenvectors of the covariance matrix of the face image vectors. The eigenvectors are also called eigenfaces which provide a means of providing data compression. But this technique has a problem with occlusion and outliers.
AdaBoost [1] and Support vector machine (SVM [1, 3, 5, 11, 18] are gaining popularity for person classification from images. AdaBoost [1] is an adaptive boosting, machine learning meta-algorithm. An one AdaBoost model can be combined with subsequent AdaBoost weak learner classifiers to enhance the performance. However, AdaBoost model is sensitive to outliers and noise. Morphological operators are applied to remove noise. We found that the combination of HOG [49] feature vector with SVM classifier, and that of Haar-like feature with AdaBoost classifier gives the best accuracy.
An example of person detection technique using GMM. Image source: [57].
A video is captured by closed-circuit TV (CCTV) cameras. These cameras can be of two types. The first is static camera i.e. located at fix position and the second is a moving camera. A number of cameras are deployed at airports, homes, giant corporate buildings, academic or government organizations, and hospitals. Also, cameras are heavily used for traffic monitoring and border protection, to capture human motion. In this section, we present techniques to detect a person from video for both the type of camera: static and moving.
Static camera
This subsection presents the techniques to detect human from static camera, which are fixed location cameras that do not have any tilts or pans. Videos are captured at a single viewpoint; hence, human or object detection techniques are simpler compared to the techniques used for moving camera.
Background subtraction
Background subtraction [2, 6, 10, 16, 20] is a popular method to detect object from the consecutive frames, which is illustrated in Fig. 8. Each frame is compared with previous frame pixel by pixel which removes identical pixels. By subtracting same pixels, method distinguish background and foreground object in a frame. In paper [9], authors have used background subtraction method along with the optical flow to mask the moving region to detect aggressive behavior. Kumar et al. [12] and Niu et al. [19] have also used this technique to fragment the object. Moreover, image and video data may contain noise. The random brightness and distorted color information in an image can destroy the important information. To remove noise some morphological operations, erosion and dilation are applied to the segmented image. Erosion removes all the single pixels. After eroding an image, a dilation operation is applied, which makes object large and fills the gaps in between and makes interested object clean. And then detected object can be fed to subsequent steps of video processing.
An example of Lukas-kanade-Tomashi tracker. The red dots denote LKT feature points and yellow line denote the tracking by one LKT tracker. Image source: [24].
Gaussian mixture model (GMM)
GMM [11, 14] is unsupervised foreground extraction technique. The method models values of pixels as one type of distribution. To deal with different background situations like illumination changes, shadows, clutter and other arbitrary, instead of one Gaussian per pixel, method models a mixture of Gaussians. To allow adaption to multimodal environments, GMM [14] has been applied in many fields. In 2016, Marsden et al. [3] have used Gaussian mixture based model to segment foreground. The history of each pixel is modeled by a mixture of
Segmentation by tracking
Tracking methods are divided into three categories: Point tracking, silhouette tracking and kernel tracking. Using interest points, silhouette of an object, and moving regions frame by frame, we can segment the motion of an object by tracking. The task of segmentation/tracking of a video object emerges in many applications like video conference, surveillance and bank transactions monitoring.
In the moving camera, two types of motions are captured: the motion of the camera and the motion of an object. Therefore, to handle multiple motions temporal differencing and optical flow based methods are used to detect a human from the video.
Temporal differencing:
The most suited method to extract foreground in the moving camera is temporal differencing [7, 20] method. In 2012, Elarbi-Boudihir and Al-Shalfan [18] have detected moving object in video stream using temporal differencing method. Also In 2016, Al-Nawashi et al. [5] have used temporal differencing method and then located motion regions using Gaussian function. In videos captured by moving camera, the background is changing over time. Hence, it will be inappropriate to generate background model in advance. Instead, method detects the moving object by taking the difference of consecutive frames
The difference result is binarized in order to separate changed pixels and we get motion image
where
Optical flow:
Another technique for segmentation of motion in moving the camera is optical flow [4]. It denotes the displacement of the same scene in the frames at different point of time. Lucas-Kanade-Tomasi (LKT) [24] feature tracker effectively work on local pixel value and robustly selects corner feature points of the reference image patch. An example is shown in Fig. 10. Optical flow is discussed in more detail in Section 6.3.2.
In this section, we present a survey of related problems in HAR based on a number of people involved in activities by using video processing techniques followed by a survey of work done using 3-D space-time volume features.
Survey and analysis of related problems in HAR using video processing techniques
This subsection describes the major works that have been done by researchers in different domains of video surveillance such as pose estimation, action recognition, and abnormality detection etcetera. We have highlighted the techniques and methodologies that are used by researchers. The survey is based on a number of people involved in an activity such as single person activities, two people interaction, and crowd activities. Tables 2–4 present the survey of total 15 major headway selected research papers for single person activity, two people activity and crowd activity, respectively.
We prepared the survey based on following criteria: object or motion detection techniques, object classification techniques, object tracking techniques, behavior analysis, features extracted, models used, the dataset used, actions targeted, challenges addressed, and accuracy achieved. From the Tables 2–4 we can see, the majority authors have used background subtraction technique for object segmentation. If images or videos are captured from a single viewpoint, background subtraction technique proves to be less expensive and more efficient. This technique is discussed in Section 5.2.1 in detail. To track an object, the majority of researchers have used KLT-tracker. Because this method is robust to occlusion and also computationally efficient. In Section 5.2.2 we illustrate KLT-tracker with figure. To classify actions, support vector machine (SVM) is majorly used with Bag-of-Visual-Words (BoVW) feature extraction method. We discuss classification models in Section 7 in detail. By using tabular information, the naive researcher can thoroughly understand and outline the methodologies used by the researchers for HAR.
Survey of related problems in HAR using 3-D space-time volume features
This subsection describes the major works that have been done by researchers for Human Activity Recognition (HAR) using 3-D spatio-temporal features. Human activity is described as a time series of human postures. To capture maximum information from videos, we require efficient feature representation techniques. We present a survey of work done by researchers using lower level features such as spatio-temporal interest point (STIP). To detect interest points various methods are used namely Harris corner detector, Minimum eigenvector, Fisher vector, and 3-D scale invariant feature transform (SIFT). To detect the motion of object, trajectories are formed around the feature detector. Basically, there are four types of trajectories namely, Dense Trajectories [34, 42, 47], KLT Trajectories [30], SIFT Trajectories [30] and dense cuboid [48]. Now we present related work done by different researchers.
Human interaction recognition using improved spatio-temporal feature extraction technique is used by Sivarathinabala and Abirami [8] for object detection. The spatio-temporal interest points are detected using the Harris corner detector. These points are then analyzed and tracked using optical flow to find out motion of an object. Computed Feature descriptors are then fed to Hierarchical-SVM (H-SVM) to recognize human interaction. The authors have presented worked on UT-interaction [28] and BIT interaction [29] dataset and considered five types of actions like Running, Handshake, High-five, Push and Punch activity. With a Bag-of-Feature extraction technique, they have achieved 58.20% accuracy on UT-interaction [28] dataset and using their own method they have achieved 90.1% of accuracy.
Wang et al. [30] have presented action recognition by dense trajectories. The feature trajectories are tracked using KLT tracker and matching SIFT descriptor. Authors sampled the dense points from each frame and tracked using optical flow field. They have used
Survey of HAR for single person activities
Survey of HAR for single person activities
| Ref. No. | Object segmentation | Object tracking | Behavior analysis | Features extracted | Classification model | Dataset | Human action targeted/challenges addressed | Accuracy/ framerate |
|---|---|---|---|---|---|---|---|---|
| [8] | Blob | Optical flow | Not available | Harris corner detector, HOG descriptor | H-SVM | UT-interaction [28], BIT interaction [29] | Poses like handshaking, kicking, punching/occlusion | UT-90.1%, BIT-88.9% |
| [11] | Blob fusion algorithm,GMM, fuzzy models | Linear sum assignment problem (LSAP), KF, SVM kernel | Not available | Global color histogram (GCH), Local binary pattern (LBP), HOG | Not available | CAVIAR (Context – aware vision using image-based active recognition [26] | Entry and exit, loitering event, un attended cash desk/Occlusion management | 86.4%/5-Fps |
| [13] | Motion interchange pattern (MIP) | Large displacement optical flow (LDOF) | Self-similarity matrix (SSM) based on HOLDOF | Torso (body excluding the head and neck and limbs) | Structured SVM (S-SVM) | TVHI | Handshake, hug, high five, kiss | Not available |
| [18] | TD, erosion and dilation | KF | Threshold | Corners, area, ratios | SVM | Not available | Not available | Not available |
Survey of HAR for crowd activities
trajectory, Histogram of Oriented Gradient (HOG), and Histogram of Optical Flow (HOF) feature descriptors. These descriptors are normalized with L2 normalization. Therein unnecessary camera motion generated by optical flow is suppressed by applying Motion Boundary Histogram (MBH), where derivatives are computed separately for horizontal and vertical components. To generate a codebook Bag-of-Features method is used. The authors have used non-linear SVM with
Kantorov and Laptev [42] have presented work on efficient feature extraction techniques, feature encoding techniques, and classification for action recognition using motion information in video compression. They have encoded feature vector using Fisher vectors (FV) and discriminated actions using Gaussian mixture model (GMM), which is a fast linear classifier. The authors shown the use of sparse MPEG flow instead of dense optical flow. This technique improves the feature extraction process. Then HOG [49] is computed to discretize MPEG flow into eight orientation bins and one no motion bin. Similarly, MBHx and MBHy are discretized. For each descriptor, vocabulary (codebook) is constructed using K-means. They have used non-linear SVM with
Types of features used for activity recognition.
Feature extraction, a two-step process: Feature detection and feature descriptor.
Shi et al. [48] have done work on Human Action Recognition (HAR) using trajectory-based representation. In their paper, they represented actions by extracting spatio-temporal features. Spatio-temporal interest points (STIP) are detected using cuboid detector using scale-invariant feature transform (SIFT) and build trajectories by matching STIPs in consecutive frames. The trajectory exploration is done using KLT tracker. For each motion trajectories HOG, HOF, and MBH descriptors are computed. They have fixed Bag-of-Visual-Words size to 3000. For classification of actions, they have used non-linear SVM classifier with
Nour et al. [52] have presented work on HAR based on co-occurrence of visual works. In their work, the 3D-XYT volume is extracted using the 3D-SIFT technique. Then for two-person interaction, a two-dimensional co-occurrence matrix is constructed. The experiment is performed on UT-interaction dataset [27], which contains two sets namely set 1 and set 2. The videos of set 1 are taken with slightly different zoom rate, and their backgrounds are mostly static with little camera jitter. The videos in Set 2 are taken in a windy day, thus background is moving slightly and they contain more camera jitter. For set 1 they have used K-NN classifier using Euclidean distance function and got 40.63% of accuracy. For set 2 SVM classifier with the polynomial kernel is used and got 66.67% of accuracy. The experiment was carried out in the static background with two performers (actors).
Lo and Tsoi [54] have presented work on HAR based on motion boundary dense trajectory technique. In their approach, interest points are selected using Harris corner condition. Then these points are tracked frame-by-frame and trajectory can be extracted. The optical flow field is computed over a two-frame sequence t and t+1 using median filtering. To form a trajectory descriptor, the tracked points of subsequent frames are then concatenated temporally. Then HOG, HOF and MBH descriptors are used to find out the shape of a trajectory or local motion information. To convert the local descriptors from a video into a fixed dimensional vector, Bag-of-Features method is used and the codebook is constructed using K-means clustering algorithm. For classification they have used, non-linear SVM with
This subsection presents types of features followed by feature detector-descriptor approach. Moreover, it also presents feature vector encoding methods used by researchers.
There are basically two types of features, such as low level (local) features and high-level (holistic) features. The prepared classification of types of features is presented in Fig. 11. Local features are most commonly used features as they are less sensitive to noise, viewpoint, and illumination changes. These features are extracted by detecting an interesting points in frames. The high-level (holistic) features capture structural information related to the action being performed. Once local interest points are detected, a descriptor is found around the interest point. The descriptors capture local information like SIFT, color, trajectories, texture-based, or shape-based [53] information for a detector.
In computer vision, the feature extraction process is a two-step process, which is shown in Fig. 12. The first step is the finding feature detector and the second is to compute the local descriptors for this feature detector. The feature detector tries to locate the important key points in the sequence of frames. Once key points are identified, its specifications are described by the feature descriptors. Next we describe the popular feature detector techniques, followed by feature descriptors [53].
In Section 6.3.1 we present a survey of Feature Detectors used for activity detection, and in Section 6.3.2, we present the survey of feature descriptors used for activity recognition. Initially, Motion History Images (MHI) [17] and Motion Energy Images (MEI) [13] methods are used by researchers as temporal image templates which show, how the object is moving and where the motion has occurred respectively. These templates are matched using the nearest neighbor approach against the examples of given motions learned. However, the problem is method lose some useful information and it also requires adequate training samples. Moreover, if one person partially occludes other, the motion and shape information may get lost. To overcome these problems nowadays, enhanced descriptors are used like Histogram of Oriented Gradient (HOG) [49], Histogram of Optical Flow (HOF) [42, 43, 44, 49] and Motion Boundary Histogram (MBH) [41, 42, 43, 44].
Feature detector
In this subsection we present different feature detectors.
Space-time interest point (STIP)
Interest points are the feature points or corner points. Interest points are points having a well-defined position in an image, as shown in Fig. 13. Minimum Eigenvector detection techniques are used to find interest points. These spatio-temporal corners are located in a region that shows a high variation of intensity in all the directions
STIPs detection for two person Kick activity. The STIP detection is done on an image of UT-interaction dataset [21].
Step by step trajectory formation process. The trajectory formation is done on an image of UT-interaction dataset [21].
Improved dense trajectories
A trajectory is the path followed by the object. In other words, it shows a pattern of motion. Figure 14 depicts the step by step trajectory formation process. For action recognition, the motion is a most important thing to identify. Thus, dense trajectories are very much used to track the motion of the person [30]. These trajectories can be computed by tracking feature points through multiple frames either using optical flow or KTL Tracker [15] or by matching Scale Invariant Feature Transform (SIFT) [6] descriptor. Then local descriptors like HOG and HOF are computed around the trajectory. Figure 15 represents the steps to compute trajectory in detail. Initially, feature points are computed on each spatial scale to guarantee equally cover all spatial positions and scale. The authors [41] have used sampling step size
Extracting Dense Trajectories. Image source: [41]. Left, Densely sampled feature points on each spatial scale. In middle, Tracking feature points separately on each spatial scale using median filtering for L frames in a dense optical flow field. Right, 
A process of the HOG feature extraction method. Image source: (a) the input image; (b) gradient map with gradient strength and direction of a sub-block of the input image; (c) accumulated gradient orientation; and (d) histogram of oriented gradients [54].
Histogram of oriented gradient (HOG) plotting on interest points. The HOG plots are computed on an image of UT-interaction dataset [21].
Histogram of oriented gradients (HOG)
Yang et al. [49] have proposed a HOG feature descriptor for robust object recognition. The HOG [24, 30, 34, 41, 42, 43, 44] is calculated based on evaluating normalized local histograms of image gradient orientations in a dense grid, by considering fine-scale gradient and fine orientation binning. The process of HOG feature extraction is illustrated in Fig. 16. An
Magnitude and orientation of an image gradient of all trajectories around a point
Histogram of optical flow (HOF)
The HOF [42, 43, 44, 49] is a statistical representation of orientation and magnitude of optical flow. Optical flow shows the direction of motion of the objects in an image (frame). It computes the two-dimensional displacement vectors, assuming same motion in neighboring pixels and intensity. The change in the pixel to the next frame for location
By, expanding terms of Eq. (5) we get Eq. (6.3.2).
In Eq. (6.3.2), if we ignore the higher order terms, we get the following Eq. (7).
where
By brightness consistency assumption,
The Optical flow is computed for an image patch of
Motion boundary histogram (MBH)
Optical flow nearly captures all kinds of motion. Video data may have camera motion and foreground motion. The Motion boundary histograms (MBH) [41, 42, 43, 44] were proposed by Dalal et al. to suppress camera motion. The smooth variation of camera motion cancels out by computing local derivatives of the flow. MBH is calculated for human motion recognition by gradient optical flow separately for horizontal (MBHx) and vertical (MBHy) flows. Both histogram vectors are normalized separately using L2 Norm. MBH is very robust to the camera motion than optical flow. Therefore, this descriptor is more discriminative for action recognition.
To encode features, Bag-of-Features or Fisher vector (FV) techniques are used. Bag-of-Visual-Words (BoVW) [30, 34, 41, 42, 44, 46] is very popular technique. The codebook is generated by a set of local descriptors, then they are summarized into a fixed length vector. A fixed number of features are extracted from each descriptor randomly and are clustered using the K-means clustering method. Descriptors are assigned to the closest cluster using Euclidean distance. The problem with BoVW method is, it considers the only frequency of words and also very sparse having a lack of effective representation. To address this issue, higher order visual information is captured by the Fisher Vector method and used in large-scale image classification [34, 47]. Fisher Vector uses Gaussian Mixture Model (GMM) [3, 4, 14] to encode the feature.
Survey and analysis of models used for activity classification
To achieve good performance, selection of good classification algorithm for the selected feature is essential. This section presents well-known models that are used for activity classification. The activity recognition is seen as the problem of classification of video clips into different categories (labels). A generalized process of video classification is shown in Fig. 18. Extracted features are encoded using an feature encoding mechanism and generates a codebook. Then codebook (encoded features) is fed to the classification model. And finally, model classifies the action performed in a video.
Support vector machine (SVM)
Support vector machine (SVM) [1, 3, 8, 13, 18] is the eminent class of discriminative classifier. SVM model uses a kernel function or basis function that will map the original problem of finite dimensional space to much higher dimensional space to make separation of classes easier. Support vector machine with RBF Gaussian kernel is widely used in a Bag-of-Words feature context [41, 42, 44, 46] which is majorly used in Human Activity Recognition (HAR). Wang et al. [30, 34] have also used non-linear SVM with
Block diagram of video classification. Image reference: [58].
Survey on image processing and computer vision tools and libraries
For pattern classification, Gaussian mixture model [3, 4, 14] is a powerful probabilistic model. Each human action is represented by a GMM by clustering the motion in every training sequence. The GMM is trained using the Expectation-Maximization (EM) algorithm. EM algorithm initializes by performing K-means algorithm. K-means is employed with N different random initialization. When EM converges, cluster labels are obtained. A GMM the is fastest to learn mixture model. The method only maximizes the likelihood. thus, it is computationally efficient.
Hidden markov model (HMM)
The generative models have very powerful algorithms known as Hidden Markov Model (HMM) and Markov random process. HMM, [17] proved best with sequential information set, hence it works well with the speech-related task. The feature vector (observation sequence) can be a discrete symbol or continuous density. Based on that, HMM can be either Discrete HMM (DHMM) or Continuous Density HMM (CDHMM). In HAR, for every action, one HMM is generated and its probability is computed. Then for the new testing set, the model will compute its probability. Based on similarity measures, the model will classify the human action performed.
Video surveillance benchmark dataset for constrained and unconstrained environment.
Survey and analysis of tools
In this section, we present tools and libraries which are available for vision processing tasks. Table 5 presents these tools and libraries along with their advantages and disadvantages. Most popular languages are: MATLAB (Matrix Laboratory) is a high-perfor- mance language for technical computing [5]; OpenCV (Open Source Computer Vision) library for real-time computer vision [6]; BiOps package in R-Tool which provides some image processing capabilities; Python programming language is also used in computer vision and has gained good popularity because of the good support of the scripting language. Other libraries are also available i.e. Matrix imagine library (MIL) and Image Toolkit (ITK) in form of C and C++ languages [18]. There are some other C++ libraries like Clmg, vgui, and iLab Neuromorphic Vision are popular for vision processing. Moreover, an open source Java computer vision library BoofCV is written from scratch for real-time computer vision. Another C++ and .NET Adaptive Vision Library is created for industrial image analysis applications. Many other software tools and packages are available and considered in detail in [55, 59].
Block diagram of proposed work.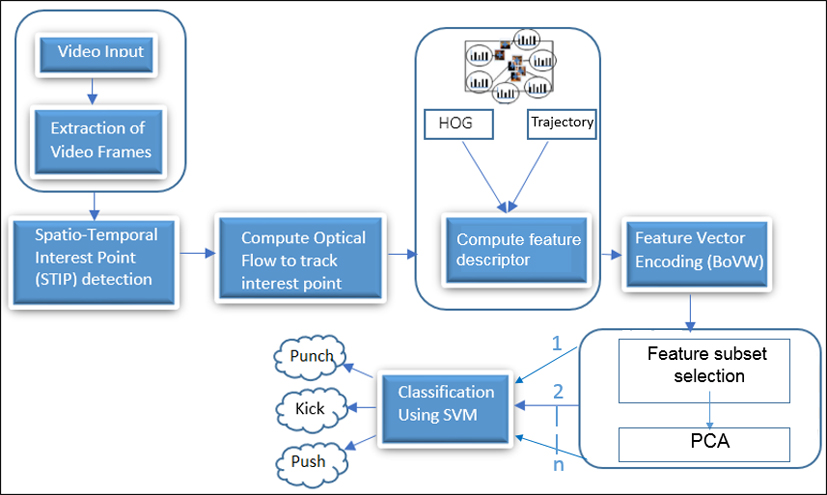
Video surveillance benchmark dataset for the constrained and unconstrained environment for HAR is shown in Fig. 19. In the unconstrained or uncontrolled environment, the data were collected in an outdoor environment using video surveillance cameras of various qualities with the uncontrolled background. In addition, the activities are performed by different performers (or actors) with different clothing conditions and doing multiple activities. This type of datasets are UCF Sports action dataset [25], CAVIAR [26], Human motion dataset [27], UT-interaction [28], PETS [56], BIT-interaction dataset [29]. Whereas, in controlled or constrained environment background is static with no change in illuminance and appearance. In a controlled environment, the same actors are performing different activities. The KTH [50] and Weizmann [51] datasets follow under the controlled environment category. In an uncontrolled environment, it is challenging to recognize the action performed due to variation in camera position (different viewpoint), changing background with different actors and clothing conditions. We have compared different video datasets based on various characteristics like: No. of Actions performed; No. of Actors; Resolution; Frames per second (Fps); Total no. of videos; various scenario considered; Types of HAR system based on people involved, are depicted in Fig. 19.
Proposed work
Based on the analysis and findings carried out in each section we have prepared our proposed work in the same direction. In our work, we want to model the activities to find out human aggression, which may cause a serious problem. We try to recognize the unpleasant and harmful behavior of humans. Thus, we consider three different activities like punching, kicking and pushing back. We will use UT-interaction [28] and BIT-interaction [29] datasets for our work to identify two people interaction activities. In UT-interaction dataset, videos are divided into two sets: The set 1 is made of 10 video sequences taken on a parking lot. The videos are taken with slightly different zoom rate, and their backgrounds are mostly static with little camera jitter. The set 2 is taken on a lawn on a windy day. The background is moving slightly (e.g. tree moves), and they contain more camera jitters [28]. And BIT-interaction dataset contains 100 videos for each action. Initially, we need to preprocess the video data to its same codec information. Frames are extracted from the video to its fixed height and width. Once preprocessing is done, we have followed the step as shown in Fig. 20. In the next subsections, we present each step of proposed work in detail.
Spatio-temporal interest points detection
Once we have frames ready, we have to detect the interest points. We will use spatio-temporal interest points (STIP). These local features are robust and less sensitive to noise. To detect interest points Minimum Eigen Feature detection [8, 18, 30, 46] method will be used in our work. From all the detected points, we will select the strongest points which carry maximum information. These are really good features to track [48] because they are scale and rotation invariant. STIP points are described in Subsection 6.3.1.
Feature points tracking using optical flow
To find the pattern of motion we have to observe the optical flow of human performing an action, which is a distribution of apparent velocities. There are two methods to find an optical flow, namely Horn-Schunck and Lukas-Kanade. Horn-Schunck is a global method and more sensitive to noise. Lukas-Kanade [1, 3, 8, 9, 24] is a local method and assumes that flow is constant in the local neighborhood of the pixel. This method is less sensitive to noise. The Lukas-Kanade method is only used when the motion flow between two images is small. We will use Lukas-Kanade method to find the motion of an object.
Compute feature descriptor
Based on a survey carried out in Section 6.3.2. We will use improved dense trajectory to captures human motion. We find out the trajectory to get motion features. To calculate the trajectory, feature points are tracked up to the next L number of Frames (e.g. 14 or 15 frames) using optical flow. In addition, the tracked points of subsequent frames are then concatenated temporally up to the
Feature vector encoding
The feature descriptors which are generated in the previous step are large in size. Therefore, to reduce the space (memory) and time required by machine learning operations, we need to limit the size of the feature descriptor. We will apply a feature subset selection method to avoid the curse of dimensionality. In order to convert the local descriptors from a video into a fixed-dimensional feature vector, we will project original high-dimensional data into a lower-dimensional subspace using random matrix [30, 34, 41, 48, 54] whose columns have fix lengths. Once features are selected, we will apply principal component analysis (PCA) technique to reduce the dimensionality of data, which reduces the data down into its basic principal components (PCs) and store them in an ordered fashion. The PCs are the eigenvalues of a covariance matrix and hence, they are orthogonal. Furthermore, the first PC retains maximum variation that was present in the original components. Using this method, we will generate the Bag-of-Visual-Words (BoVW) [30, 34, 41, 42, 44, 46] which can be fed to a classifier.
Classification
Generated visual-words in previous step are fed to the SVM classifier to classify the action performed. We will use the non-linear SVM classifier with a multi-dimensional
Conclusion
In this article, the objective is to explore the concepts of video surveillance and specifically, human action recognition (HAR) because automated human activity recognition is becoming crucial in this modern era. This article discussed the concepts of human action recognition in depth. The article presented a taxonomy, having multiple dimensions, of HAR followed by different techniques to recognize human from the image and video data. Furthermore, the article has also provided a survey and analysis of related problems in HAR using various video processing techniques. The article broadly presented the survey of work done in HAR using 3-D space-time features. Specifically, article presented types of features used for HAR along with feature detector-descriptor approach to model the human activity. The article also discussed classification models used for human activity recognition. In addition, the article also presented computer vision tools in trends followed by benchmark human activity dataset.
We have utilized our survey and study presented in this article to propose our research work. This article also presented a detailed schematic diagram of proposed work and discussed each step in detail. Our method differs from a previous Bag-of-Visual-Words (BoVW) generation techniques. In our proposal, we have selected strongest spatio-temporal interest points (STIP), which are scale, rotation and viewpoint invariant, to reduce the noise and redundancy level. Based on this survey we have found out best feature descriptors for the feature detector, which carry maximum physical and temporal information in video data. Surveying and reviewing existing available work help us to comprehend and answer following questions in a better way: Different video processing domains, with strategies of steps involved in general video surveillance systems; Different approaches to recognize human activity; How to detect and analyze actions and behavior for different HAR systems such as, Single person activity, Two-person interaction and Crowd behavior. Rigorous study of this article can assure newbie to understand and apply knowledge in promising directions of research.