
Abstract
Fingerprint is the oldest techniques for biometric identification. This limb has its own characteristics for each individual to distinguish from each other. Fingerprint is unique and the pattern will never change. Many approaches have been developed in this field research. Bag-of-Visual Words (BoVW) is an approach for fingerprint classification, where the classification is based on the histogram of the frequency of visual words. The problem arises when the fingerprint classification uses the original images in which these images have a large size and in large numbers. It requires large storage space and high computational time. In order to overcome this problem, we propose Singular Value Decomposition (SVD) as compression method that can reduce the storage space. Our proposed method has been evaluated with some experiments based on five different types of fingerprint (whorl, arch, left loop, right loop, and twin loop). Experimental results show that the proposed method reduces the storage space and computational time. Moreover the accuracy of fingerprint classification could be improved.
Introduction
Humans use their body characteristics such as fingerprints to identify and distinguish each other. Fingerprint identification system is growing. This system is widely used in the government and civil applications to identify the suspect, victims of crime, or to safeguard the access of a facility. This is because the object of fingerprint biometrics has several advantages that are unique compared to the other limb of a human. Moreover, the fingerprint is permanent or never change in the person’s life, and relatively easy to classify the form of a unique pattern.
There are two types of fingerprint system. Those that use simple matching score between two fingerprint images and those that use classification model to categorize the fingerprint images [18]. Some studies in the fingerprint system, there are exists three approaches, those are minutiae based, texture based and Bag-of-Visual Words (BoVW) based approach. In the low-quality image, minutiae is not an appropriate approach for fingerprint images, since they will produce low accuracy [2]. Moreover, if the fingerprint is not fully scanned, it leads to poor performance of fingerprint system [20].
In this study, the process of fingerprint classification is performed by using BoVW. This approach uses local features of an image to be used in the classification process. Different with another approach, such as Gabor Filter which is based on global feature, BoVW is robust against changes in scale, changes in light and noise [17].
Many classification tasks used BoVW model in their systems, such as in the medical x-ray images [12], pornography images [4], early Alzheimer disease detection [14], and human action recognition [11]. In recent years, many methods were proposed to improve the performance of BoVW model. Miaojing Shi et al. [13] proposed W-tree to weight each visual word. The results show that their proposed method reduces the computational time of visual words generation.
Chimlek et al. [15] proposed a feature selection method which is based statistical t-test to measure the correlation of each feature. The results show that the proposed method outperforms the another method, such as Document Frequency (DF), Mutual information (MI), Pointwise Mutual information (PMI) and Chi-square statistics (CHI).
Jit Mukherjee et al. [6] proposed to use indexing approach to speed up the matching process of the query image. There are three indexing methods: Locality Sensitive Hashing (LSH), Sphere Rectangle Tree (SR tree) based Indexing, and Choice of Distance Functions. As a result, and norms form as distance functions yielded high computation time compared to others.
In this study, we came up with the problem of a large number of data and storage space. The more original fingerprint image is used, the greater the required storage space. In the adult image detection research area, several researchers proposed the image compression to handle this problem [7, 10]. Singular Value Decomposition (SVD) is a compression method that can reduce data storage space and speed up the computational time.
In our proposed fingerprint classification, we adopted SVD to compress the fingerprint images. Then, the keypoints of compressed images are extracted by Speeded-Up Robust Feature (SURF). SURF is faster in the process of computing and matching [5]. After keypoints are obtained, then it is grouped using K-Means clustering to get the vocabulary. Having the generated vocabulary, visual word histogram is constructed from the training and testing image to be classified by Support Vector Machine (SVM).
In the following sections, we present the detail of our proposed fingerprint classification system. Section 3 explains experiment results and analysis. Finally, section 4 presents the conclusions of this study.
The proposed Bag-of-Visual words approach for fingerprint classification in compress domain
Biometric system is a series of activities for the recognition of biometric characteristics of a person that is performed automatically. Biometrics systems have two models, namely the identification and verification systems. Identification system aims to identify a person’s identity. It needs matching process in the existing training image in the database. Meanwhile, verification system intended to accept or reject the identity entered by someone. In the verification system required data samples to be matched. In this study, we focus on fingerprint classification which the fingerprints have been classified into several categories.
In our model, generally, BoVW consists of three steps as shown in Fig. 1. First, training images extract keypoints and group them to generate visual words. Second, by using the generated visual words, the histogram of visual words of training images is constructed. Finally, extract keypoints of testing images and construct the histogram by using the generated visual words. Both training and testing images are compressed before keypoints extraction. Figure 2 shows the illustration of BoVW. It starts from keypoint extraction and ends with the construction of feature vector of each image. The steps of our proposed model are explained in the following subsection.

The Proposed Fingerprint Classification.
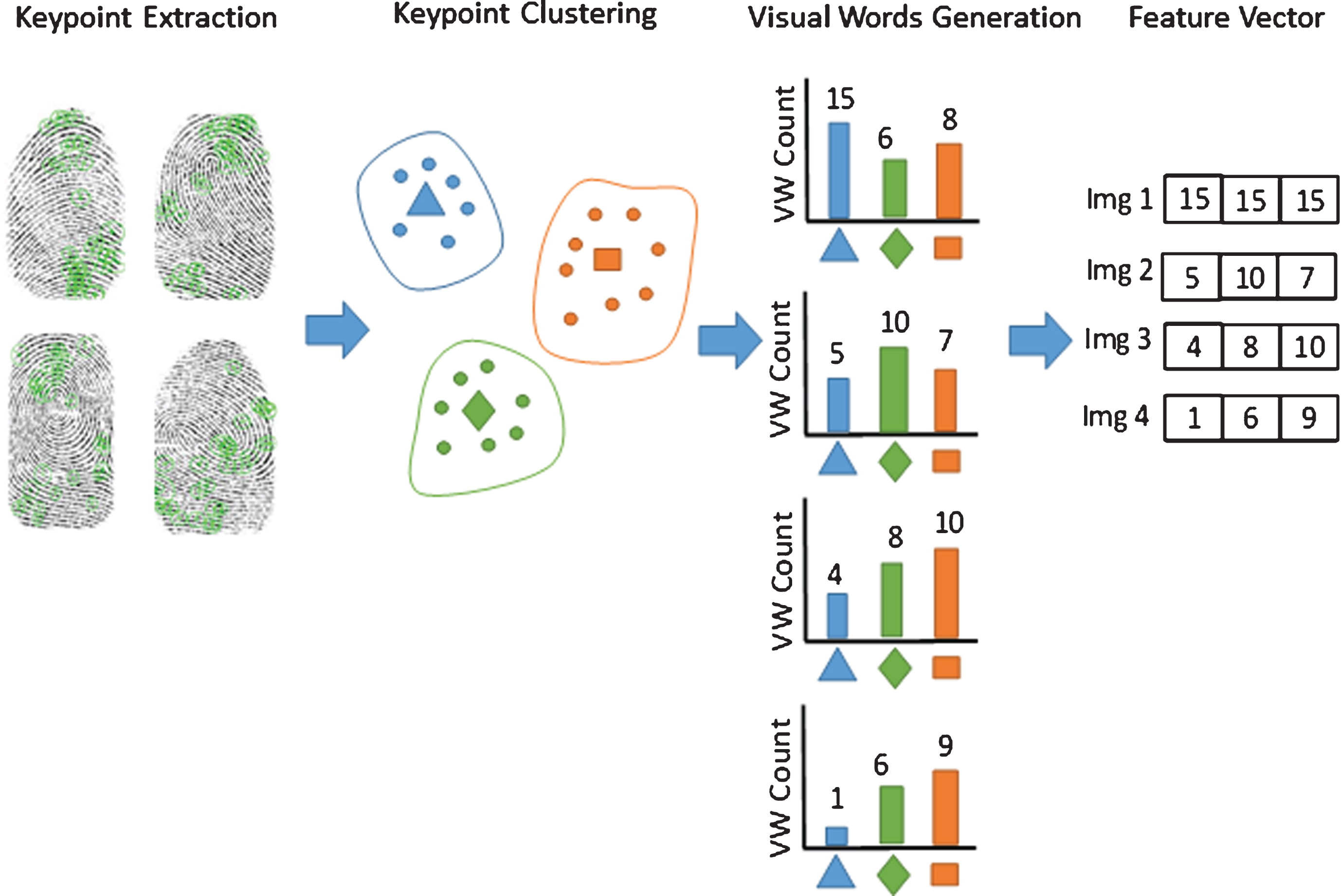
BoVW Illustration.
Singular Value Decomposition (SVD) has been widely used to reduce the large dimension of matrix. It decomposes the matrix into three smaller matrices known as U, Σ, and V
T
. Equation 1 shows the size of each matrix.
The compression of image is performed by defining the value of k-rank of SVD. Smaller rank produces the approximate of the original matrix. In our study, each original fingerprint image is compressed by using the various k values: 5, 15, 30, 45, and 60.
In BoVW model, feature extraction consists of several steps: keypoints extraction, keypoints clustering, and visual words histogram construction. There are several methods to extract the keypoints of an image, such as Scale Invariant Feature Transform (SIFT) and Speeded-Up Robust Features (SURF). Each method has its advantages. SIFT is more robust to image rotation and scale change [3]. However, SIFT has high computational process. Each keypoint in SIFT has 128-dimensional feature space. In term of computational time, SURF is faster than SIFT [1]. Compared to SIFT, each keypoint in SURF has 64-dimensional feature space. Thus, we decided to use SURF instead of SIFT.
Keypoints clustering
Extracted keypoints are used to generate visual words. Thierry Urruty [19] picked some keypoints randomly to become visual words. However, it is an uncommon method. In BoVW model, some researchers [9, 18] used k-means to group the keypoints. In fact, there are another clustering algorithms have been proposed, such as hierarchical clustering, Partitioning Around Medoids (PAM) clustering, and Fuzzy C-Means. K-means is a simple algorithm and widely used for keypoints clustering. K-means algorithm starts by defining the number of clusters and the initial centroid of the cluster. These centroids is randomly picked from the keypoints collection. Next, we measure the distance between keypoints and centroids. The closest distance between keypoints and centroid will be in the same cluster. K-means is an iterative algorithm. The iterative will be stopped if the number of iteration is defined at the beginning, the position of the clusters in the current iteration is the same with previous iteration, or the value of the sum of square error is below than predefined threshold.
In this study, the centroids of the cluster then be-come our visual words. We decided to evaluate the proposed model by using 500 visual words. It means that the keypoints are grouped into 500 clusters. This number is based on previous research [12] which is performed the best accuracy by using 500 visual words. Indeed, the different of data may produce different accuracy.
Visual words histogram construction
Generated visual words are used by training and testing images to construct the histogram of visual words. The histogram shows how many keypoints have the nearest distance to the visual words. Figure 3 shows the visual words histogram of the sample image. After we have constructed the histogram for training and testing images, we further performed SVM classifier to predict the testing images.

The Sample of Visual Words Histogram of Original Fingerprint Image.
Linear Support Vector Machine (SVM) is widely used for classification [16]. The algorithm separated the training data linearly into two classes by constructing the hyperplane between positive and negative class. TemplateSVM is the Matlab function that is used for SVM multiclass classifier. This template provided three kernel function: Gaussian or Radial Basis Function (RBF), Linear, and Polynomial. In this study, the experiment is performed via a linear SVM.
Experimental results
Dataset
In this study, we used 250 synthetic fingerprint images generated from SFingeDemo 4.1. Synthetic Fingerprint Generator (SFinge). This software has been used in Fingerprint Verification Competition FVC2000, FVC2002, FVC2004, and FVC2006. We generated the synthetic fingerprint images with vari-ous fingerprint pattern types, such as whorl, arch, left loop, right loop, and twin loop. We classified manually the fingerprint images into those types as shown in Fig. 4. We split the dataset into training 70% and testing 30%. Feature extraction and classification were performed with Matlab R2014b. Figure 5 shows the compressed fingerprint images by using the various rank of SVD.

Original Fingerprint Dataset.

Compressed Fingerprint Dataset.
We used accuracy rate and computational time to evaluate our proposed model. Accuracy is the ratio of the number of testing images classified correctly and the number of testing images.
Results
Figures 6, 7, and 8 show the comparison of extracted keypoints from original images, compressed images by using SVD rank-5 and rank-60, respectively. As we can see in Fig. 7, keypoints are still successfully extracted from low-rank image compression.

Extracted Keypoints from Sample Original Images.

Extracted Keypoints from Compressed Images with Rank k = 5.

Extracted Keypoints from Compressed Images with Rank k = 60.
The evaluation is performed by using the different rank of SVD as shown in Table 1. Based on the results, the accuracy increase when the rank of SVD is k = 15, and high accuracy is produced by the rank k = 30. The compression can decrease the size of images significantly. The size of total images of our dataset is 20.7 MB. After compression, by using rank k = 5 the total size of images becomes 3.25 MB.
Performance of SVD for Image Compression
In this paper, we have proposed SVD as compression method to reduce the size of a fingerprint images. The proposed method is applied to BoVW based fingerprint classification. The performance of the proposed method was assessed by using accuracy and computational time for a given dataset. The obtained results show that the proposed method improved the accuracy of fingerprint classification. Although, the images have been compressed. Moreover, the proposed method can reduce the time computation of fingerprint classification.