
Abstract
Anomaly detection is an important issue, which has been investigated in various research fields and application domains. Many anomaly detection techniques have been developed exclusively for certain application domains, in contrast, others are more general. This survey aims to create a structured and comprehensive overview of the research on anomaly detection. First, we tried to introduce the concept of anomalies and types of anomaly detection. We have tried to classify anomaly detection according to their application and then categorized their techniques. For each application and technique, we have described key assumptions, which are used by the techniques to distinguish between normal and abnormal behavior. For each application, a basic anomaly detection technique has been provided, in the end; the differences among existing techniques in each specific category are discussed. Furthermore, we tried to describe the advantages and disadvantages of each technique in that field. In addition, we tried to bring some data sets that were used in some papers in order to test your methods with them. We hope that this survey provides a better concept of the various directions, which has been researched on that specific topic.
Introduction
The goal of anomaly detection is to recognize groups of instances, which are infrequent within data. A most likely definition of anomaly is given by Hawkins as [1] “an observation which deviates so much from other observations as to arouse uncertainties that it was produced by an alternate mechanism”.
Although anomaly detection has received significant attention, the automatic classification anomalies still remains an unsolved problem [2].
Anomaly detection refers to the problem of finding patterns, which do not conform to common behavior. These unusual patterns are often referred to as anomalies, outliers, aberrations, surprises, exceptions, contaminants or peculiarities in various application domains. Anomalies and outliers are two well-known terms used in the context of anomaly detection. Anomaly detection have been used extensively in a wide range of applications such as intrusion detection for cyber security, credit card fraud detection [3, 4], insurance or health care, military surveillance for enemy activities and fault detection in safety critical systems. The significance of anomaly detection is that anomalies in data can provide significant (and often critical) actionable information in a wide range of application domains. For example, anomalous traffic pattern in a computer network could mean that a hacker is using sensitive data. An anomaly in health for example in MRI image may show presence of malignant tumors. In credit card transaction data, an anomaly could indicate credit card or identify theft. Over time, a wide range of anomaly detection techniques have been implemented and applied in several research communities. Many of these approaches have been developed for exclusive application domains, while others are more general. In Fig. 1, a timeline of researches in the literature is shown. Growing interest in this domain is obvious in recent years.
The rest of this paper is organized as follows. In Section 2, types of anomalies in various areas are introduced. In Section 3, application of anomaly detection and their methods are discussed separately. For each application and technique, this survey described key assumptions, which are used by the techniques to distinguish between normal and abnormal behavior. For each application, a basic anomaly detection technique has been provided, in the end; the differences among existing techniques in each specific category are discussed. Furthermore, we tried to describe the advantages and disadvantages of each technique in that field. Moreover, according to needs of researchers, some data sets that were used in some papers in order to test the methods are introduced. Section 4 presents online streaming anomaly detection. As data is going to be enormous, researchers are trying to provide different solutions from traditional methods. Finally, conclusions are presented in Section 5.
Classification of papers based on published year.
Based on number of parameters, anomalies or the abnormal activities can be classified into different categories. We will discuss types of anomaly below.
Based on nature of anomalies
We divided anomalies into mainly three categories based on the nature and scope of anomalies:
Point anomalies
If a data instance (i.e., a point) has different behavior than the rest of the data instances, it is referred to as point anomaly or global anomaly. Point anomalies are the simplest types of anomaly in data sets, however, it has some major problems in finding suitable measurements in variation of the instance from other detected point anomalies. For example, in one network if we assume that every nodes of network must have at least two neighbors connected to it, the points that have less than two connected links are said to have anomalous behavior. In Fig. 2, the points in V1 group are predicted to be anomalous points. One of the subsets of point anomalies is called local anomalies. This happens when a point have anomalous behavior related to its local neighborhood. If we assume an example, we group a set of individuals based on their links in the network as friends and check their income (some parameters), a particular individual, let say A, might be having a fairly low income compared to his friends suspecting a local anomaly while overall in the global context his income might be insignificant as many people may have similar income representing a normal behavior. This behavior is depicted in Fig. 3a and b.
Point anomalies.
(a) Groups on the basis of friendship links; (b). Groups according to income.
This type of anomaly also is referred to as conditional anomalies in the data set. It is when the data instance has significant deviates from others in a specific context. One example of contextual anomaly is temperature that might be considered as a contextual anomaly. For example, today’s temperature is 28
Behavior attributes: For defining these attributes, characteristics of an object are considered to detect anomalous behavior of the object. In the example above, the temperature and humidity can be used as behavior attributes. According to [5], usually proximity based methods are used for contextual anomaly detection.
Contextual attributes: These attributes define the context of the object. In our example, contextual attributes for temperature are date and location.
Collective anomalies
When a collection of data objects as a whole behaves differently from others, it will be called anomaly, but the data objects individually may not be anomalous. Figure 4 shows a collective anomaly because density of this area compared to others is very high; however, they do not consider each of the points on that area. In reality world, if a model of Car Company has a problem, this is natural but whenever for example hundreds of that car models have the same problem it seems to be collective anomaly.
Collective anomalies.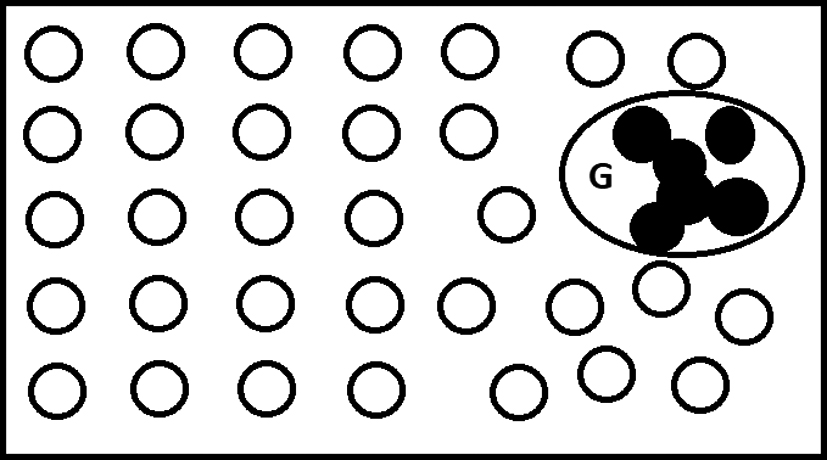
For detecting collective anomalies, there are several methods, which were used, but one of best-known methods is to consider the behavior of the group of objects with the background information about the relationship among those data objects.
Horizontal anomalies are another type of anomaly that have been emerged in social networks [6], which depict the presence of anomalies based on the different sources of data available.
For example, the same user may be present in different communities on different social networks. Similarly, a user may have similar kinds of friends on a number of social networks (e.g., Facebook, Google
Based on static/dynamic nature of network/graph structure
According to [7], based on the network structure being used to distinguish anomalies, they are classified as static or dynamic. Bibliographic networks are one of static networks that allow the changes to happen slowly over time. On the other hand, dynamic networks such as mobile applications, allow continuous changes and faster communications in the networks.
Dynamic anomalies: Changes in the network with the passage of time occurs. For example, it may involve changes in the way interactions take place in the network.
Static anomalies: According to the rest of the network by ignoring the time factor, static anomalies occur and only the current behavior of a node is analyzed.
Based on information available in network/graph structure
According to [7], anomalies based on the type of information available at a node or an edge, can be classified into labeled or unlabeled.
Labeled anomalies
In the labeled anomalies, both structure of the network and the information gathered from vertex or edge attributes are important. An example of these anomalies is labels on nodes that may specify the attributes of individuals involved in the communication activity and on the edges represent their interaction behavior.
Unlabeled anomalies
Unlabeled anomalies that are just related to the network structure. The techniques have been used to detect these types of anomalies consisting of static unlabeled anomalies, static labeled anomalies, dynamic unlabeled anomalies and dynamic labeled anomalies. In static unlabeled anomalies, it occurs when behavior of an individual remains static and the attributes, such as age of individuals involved, type of interactions, and its duration are ignored due to unlabeled nature of the network in which labels on nodes and edges are ignored. In static labeled anomalies, labels on the vertices and edges are also considered, and then the anomalous substructures found are referred to as static labeled anomalies. In the product review system, a bipartite graph with one subset of vertices as users and other as products is taken, in which the edges between the subsets represent the product reviews. Hidden labels are assigned to both users and products. For users, the label can be in the form of honest or fraudulent and for the products, it could be either good or bad. A normal honest user will give accurate results, i.e., for good products, they give positive response and for bad ones, they will give negative reviews whereas fraudulent users are understood to do the reverse. Dynamic unlabeled anomalies arise when we have dynamic networks that change with time. For example, on the pattern of interactions, according to [8], there are maximum of six ways, in which a maximal clique can evolve: shrinking, growing, splitting, merging, appearing or vanishing. When the normal behavior does not result in any network change, it results in any neighborhood changes predicted as an anomalous behavior. When in a dynamic network, an anomalous behavior is observed by considering labels of the vertices and edges; it results in anomalies observed to be classified as dynamic labeled anomalies.
Based on behavior
Another class of anomalies are named as, “white crow anomalies” and “in-disguise anomalies” (see Fig. 5) is presented by [8].
White crow anomaly
When a data object deviates remarkably from other observations, it is white crow anomaly. For example, if the probability of one event is more than 1, which is impossible, then, it is taken as a white crow anomaly.
In disguise and white crow anomalies.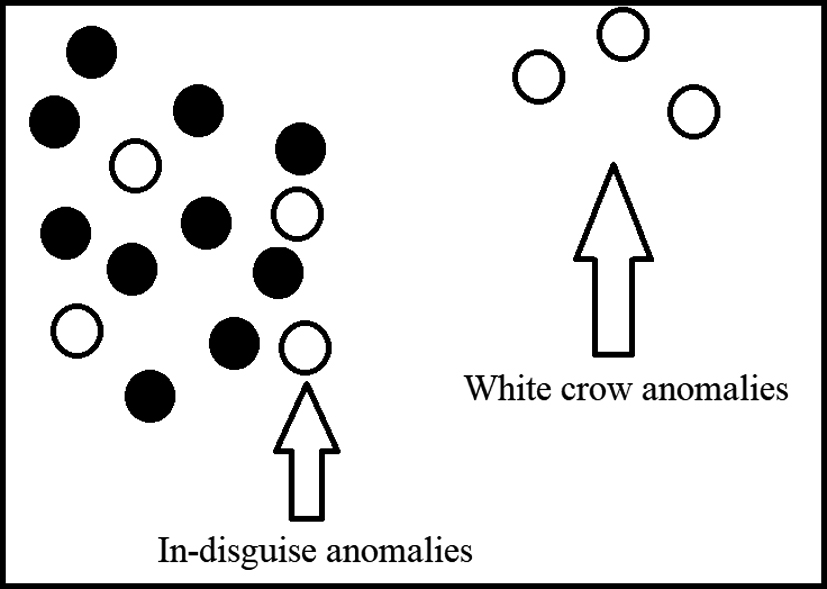
A small deviation from the normal pattern called in-disguise anomaly [9]. For example, if someone tries to access to someone’s social network account and would not want to be caught; so, he will try to behave in the same manner as a normal user. Such anomalies are recognized through strange patterns, which also include uncommon nodes or entity alterations. These are difficult to be detected as they are hidden inside the network.
Based on structural operations on network/graph structure
Another type of anomalies in social networks according to Eberle and Holder [9] is based on structural operations. This classification consists of three properties as follows:
Insertion: It deals with the existence of an unexpected edge or vertex in the graph. Modification: It deals with the presence of an unexpected label on an edge or a vertex. Deletion: The last one deals with the absence of an expected vertex or an edge.
In another work by [10], network and social networks anomalies are considered as follows:
Near stars/cliques: When completely discon- nected (Near Stars) or all connected neighbors (Near Clique) exist, it will be considered as anomaly because it is very rare.
Heavy locality: It determines the presence of an anomaly when heavy weight around a particular area or a group is suspicious.
Particular dominant links: At a particular node or link as compared to other nodes when there is unexpected presence of heavy load, it specifies an unusual activity.
Anomalous vertices
The goal of anomalous vertex detection is to discover a subset of the vertices such that every vertex in the subset has an ‘irregular’ evolution compared to the other vertices in the graph.
Identifying vertices that contribute the most to a discovered event (also known as attribution), such as in communication networks [11], and observing the shifts in community involvement [12] are some typical applications of this type of anomaly detection.
Anomalous edges
Edge detection aims to discover a subset of the edges such that every edge in the subset has an ‘irregular’ progress, optionally identifying the time points where they are abnormal. In a static graph, a distribution of the edge weights can be found, and according to the probability of its weight, each edge can be assigned a score. But, due to the temporal nature of dynamic graphs, two new main types of irregular edge progress can be discovered: (1) abnormal edge weight evolution [13], where the weight of a single edge oscillates over time and has inconsistent spikes in value, and (2) figure of unlikely edges in a graph between two vertices that are not typically connected or part of the same community [14].
Anomalous sub-graphs
The sub-graphs that are identified or tracked are typically bounded, such as to those discovered by community detection methods. Matching algorithms are needed for tracking the sub-graphs along time steps, like the community matching technique used in [15]. Anomalies of this type are exclusive for dynamic networks, and consist of communities that merge, split, disappear, and appear again frequently, or show a number of other behaviors.
Event and change detection
Event detection has encompassed much broader scope in comparison with the previous three types of anomalies, targeting to identify time points that are significantly different from the rest. Isolated points in time where the graph is not similar to the graphs at the previous and following time points show events. To measure the similarity of two graphs, one approach is comparing the signature vector of summary values extracted from each graph, such as average clustering coefficient [10]. Complementary to event detection, there is change detection. It is essential to notice the distinction between event and change detection. Change points choose a point in time where the entire behavior of the graph changes and the difference is maintained until the next change point, while events show isolated incidents.
Anomalies in wireless sensor networks
According to [16], various types of anomalies in Wireless Sensor Networks (WSN) are node anomaly, network anomaly and data anomaly, which are described below.
Node anomaly
These types of anomalies can be discovered during failure of WSN node or power problems. Failure of solar panel or fluctuations in power of various components can result in this type of anomaly. Node anomalies can occur due to hardware or software problems in the WSN nodes.
Network anomaly
Unexpected fluctuations in the signal strength and connection issues can be applied to identify network anomalies. Complete loss of connectivity or episodic connectivity can be applied to detect intrusions in the network.
Data anomaly
An intrusion try can be detected from disordered data communication.
Sensor data quality is crucial for right decision-making. Cryptographic and key management techniques are not enough to ensure the integrity of data, as they cannot protect sensor nodes from insider attacks such as data fabrication. Hence, anomaly detection models are proposed to identify any abnormal behavior in sensor data streams.
Applications of anomaly detection
In this section, we are trying to cover a comprehensive review of anomaly detection applications in various fields.
Intrusion detection to cloud systems
Providing on-demand, convenient, network access to a shared pool of configurable computing resources (e.g., applications, storage, services servers and networks) is the aim of cloud computing [17]. In cloud services, security is one of the most important problems. It suffers from different types of attacks such as Denial of Service (DoS), Distributed Denial of Service (DDoS), IP spoofing, Address Resolution Protocol spoofing, Routing Information Protocol known attacks such as, DNS poisoning, Flooding, etc.
Availability, confidentiality and integrity of cloud resources and services are three important factors in cloud computing. According to [18], the aim of attackers is to interrupt these factors as follows:
Insider attack: It happens when an authorized cloud user tries to gain unauthorized privilege in order to interrupt confidentiality of services, it is called insider attack. Their purpose is revealing important information to others or doing fraudulent activities.
Flooding attack: In flooding attack, attacker tries to send a huge number of packets from an innocent host in the network in order to interrupt service availability to an authorized user (flood victim). Types of packets can be TCP, ICMP, UDP or a mixture of them. The result of flooding attack can cause significantly raise the usage bills.
User to root attacks: Attackers try to sniff password in order to get access to authorized user’s account. They scan and record passwords that are broadcasted or used on a cloud. The attacker can exploit vulnerabilities for gaining root level access to the system by gaining access to user’s account.
Port scanning: The aim of port scanning tools is probing a server or host for filtered ports, open and closed ports. Port scanner is often used by administrators to verify security policies of their networks, and it is used by attackers to identify network services running on a host and exploit vulnerabilities. TCP scanning, SYN scanning, FIN scanning, UDP scanning, ACK scanning, Window scanning and etc. are some various port scanning techniques.
Attacks on virtual machine or hypervisor: One of the disadvantages of hypervisor is being potentially attacked, either from the network layer or from the host running on that hypervisor. Much the same as other devices, desktop machines and infrastructures, a hypervisor on a network behaves to respond to connections through standard TCP/IP by default. Thus, it makes the hypervisor being locatable on the network and consequently susceptible to traditional network enumeration attacks such as NESSUS and NMAP. For companies who invested in the cloud computing or hosting servers in large datacenters attacking the hypervisor from the guest or virtual machine is much more dangerous and an unfamiliar concept. The attacker can gain control over installed VMs by compromising the lower layer hypervisor. SubVir, BLUEPILL and DKSM are some known attacks examples on virtual layer. Hackers through these attacks can be able to compromise installed-hypervisor to gain control over the host.
Backdoor channel attacks: It allows the intruder to gain remote access to the infected node in order to compromise user confidentiality. For example, hacker takes control of victim’s resources in DDoS attack by using backdoor channels.
In order to detect intrusions, different systems have been implemented as follows.
3.1.1.1. Host based intrusion detection systems (HIDS)
HIDS by collecting information such as file system used, network events, system calls, etc. detects intrusion for the machine. They do this by analysing and monitoring the information from a specific host machine. These systems observe behavior of the program, modification in host kernel and host file system. If there were a deviation from expected behavior, it reports the existence of an attack. Choosing system characteristics to monitor determines the efficiency of HIDS [19] proposed HIDS based architecture for cloud environment. In the proposed architecture, each node of Cloud/Grid contains IDS that provides interaction among service offered (e.g., PaaS), storage service and IDS service. When large numbers of training samples are applied for behavior analysis method, results of the research [19] describe very low the false negative alarm and false positive rate [20] proposed self-similarity based lightweight intrusion detection method for cloud computing by using the number of events from the Windows’ security event log that is extracted. The process of feature selection creates groups by combining EventID and security ID (SID) in Windows system. Then, self-similarity of each VM is measured. In [20], for calculating self-similarity two techniques are proposed; cosine and hybrid. The deviation of calculated similarity from normal behavior creates alerts. Self-similarity based approach is cost effective and efficient for detecting an anomaly in the cloud environment. However, the drawback of this approach is that it works only for Windows system. In [21], an abstract model for intrusion detection and severity analysis to provide the overall security of the cloud was proposed. It consists of six components including system call handler, detection module, security analysis module, profile engines, global components and intrusion response system [21].
3.1.1.2. Distributed intrusion detection system (DIDS)
Over a large network, a Distributed IDS (DIDS) consists of several IDS (e.g., NIDS, HIDS, etc.), communicating with each other, or with a central server that enables network monitoring. The components of intrusion detection collect the system information and convert them into a standardized form in order to be passed to a machine that aggregates information from multiple IDS and analyzes the same, called central analyzer. DIDS has both advantages of the HIDS and NIDS and can be used for detecting unknown and known attacks [22] proposed a cooperative agent based approach individual NIDS module. It notifies other regions, if any cloud region detects intrusions in each area. When a new attack is detected, then new blocking rule is added to block list. Hence, this type of detection and prevention helps to resist attacks in cloud [23] proposed a mutual agent based approach in cloud computing to detect DDoS attack. Mutual agent at that region notifies other regions when any intrusion region detected. The intensity of alerts provided from other regions is calculated for each region. Then, new blocking rule is added into block table at each region, if a new attack is detected. Therefore, DDoS attack is detected in the whole cloud by using mutual cooperation among cloud regions.
3.1.1.3. Hypervisor-based intrusion detection system
At hypervisor layer, there is a platform to run VMs Hypervisor-based intrusion detection system. This type of IDS lets the user to analyze and monitor communications between different VMs, between a hypervisor and VM and also within the hypervisor based virtual network. According to [24], VM introspection based IDS is one of the examples of hypervisor based intrusion detection system. In cloud computing, one of the most important techniques is hypervisor based IDS, to detect intrusion in a virtual environment.
3.1.1.4. Intrusion prevention system (IPS)
The proposed network intrusion detection and prevention approach by [25] does not need installing IDS on each node. The benefit of this approach is solving transferring alert message and trust issue. It also reduces overhead and no false alarm rate. Lee et al. [26] represented Cumulative-Sum based Intrusion Prevention System (CSIPS) for preventing DoS or DDoS attacks. They used three detection algorithms (called outbound, inbound and forwarded) and packet classification algorithm, which efficiently detect DDoS attack and logs, has sent to remote IPS machine cooperatively. IPSs are mainly categorized into two classes: Network based IPS (NIPS) and Host based IPS (HIPS). In another work by [27], they presented an IPS model based on dynamically distributed cloud firewall linkage. Authors introduced the structure and function of Cloud Firewall.
3.1.1.5. Intrusion detection and prevention system (IDPS)
It is very useful to combine IDS and IPS, which is named IDPS. IDPS identifies stops and reports intrusions to security administrators. Using proper configuration and management of IDS and IPS can reduce security issues [28] reported how intrusion detection and prevention can be used together to improve security, and also discussed different approaches to design, configure, and manage IDPS. According to [28], IDPS can be categorized into three broad categories: stateful protocol analysis, signature-based, and anomaly-based. On the type of events that they monitor and the ways in which they are deployed, IDPS can be divided into four groups based on [28]: (a) Network-Based (b) Host-Based (c) Network Behaviour Analysis (NBA) (d) Wireless.
3.1.1.6. Network based intrusion detection systems (NIDS)
According to [29], in static graphs, techniques focused on anomaly detection, which do not change and are capable of representing only a single snapshot of data. Examples of dynamic networks, which are unlike static networks, are constantly undergoing changes to their structure or attributes, consisting of global financial systems connecting banks all over the world, electric power grids connecting geographically distributed areas, and social networks that connect users, businesses, or customers using relationships such as friendship, collaboration, or transactional interactions [29]. Detection of ecological disturbances, such as wildfires [30] and cyclones [31]; intrusion detection for individual systems [32] and network systems [33]; identifying abnormal users and events in communication networks [34]; and detecting civil unrest using twitter feeds [35] are some samples.
Solutions to attacks
3.1.2.1. Firewalls
Firewall protects the front access points of the system and is treated as the first line of defense. Firewalls are used to deny or allow protocols, ports or IP addresses. It diverts incoming traffic according to a predefined policy. Several types of firewalls are discussed in [36].
3.1.2.2. IDS and IPS techniques
Signature-based intrusion detection attempts to define a set of rules (or signatures) that can be used to decide that a given pattern is that of an intruder. As a result, signature-based systems are capable of attaining high levels of accuracy and a minimal number of false positives in identifying intrusions [37]. In cloud, signature-based intrusion detection technique can be used for detecting a known attack. Approaches presented by [38, 39, 22, 40] used signature-based intrusion detection system for detecting intrusions on VMs (or front end of cloud environment).
3.1.2.3. Anomaly detection
The key element for using this approach efficiently is to generate rules in such a way that it can achieve lower the false alarm rate for the unknown as well as known attacks.
[41] presented a lightweight intrusion detection system to detect the intrusion in real-time, efficiently and effectively. In this work, behavior profile and data mining techniques are automatically maintained to detect the cooperative attack. In cloud, large numbers of events (network level or system level) occur, which makes difficult to monitor or control intrusions using anomaly detection technique [24, 19, 42, 43] proposed anomaly detection techniques to detect intrusions at different layers of cloud.
According to Fig. 6, IDS-based techniques and their usages can be categorized as follows:
IDS techniques.
3.1.2.4. Artificial neural network (ANN) based IDS
The goal of using ANNs for intrusion detection is to be able to generalize data (from incomplete data) and to be able to classify data as being normal or intrusive [44]. Types of ANN used in IDS are as [44]: Multi-Layer Feed-Forward (MLFF) neural nets, Multi-Layer Perceptron (MLP) and Back Propagation (BP [45] proposed a three layer neural network for misuse detection in the network. The feature vector used in [45] was composed of nine network features (Protocol ID, Source Port, Destination Port, Source IP Address, Destination IP Address, ICMP Type, ICMP Code, Raw Data Length, Raw Data). However, intrusion detection accuracy is very low [46] presented MLP-based IDS. They revealed that inclusion of more hidden layers increased detection accuracy of IDS. This approach improves detection accuracy of the approach proposed in [45, 47] compared the rate of successively finding intrusion with MLP and Self-Organization Map (SOM) and revealed that SOM has high detection accuracy than ANN. It is claimed that Distributed Time Delay Neural Network (DTDNN) [44] has higher detection accuracy for most of the network attacks. DTDNN is a simple and efficient solution for classifying data with high speed and fast conversion rates.
3.1.2.5. Fuzzy logic based IDS
Fuzzy logic [48] can be used to deal with inexact description of intrusions [49] used relative fuzzy-entropy as a heuristic, Ant Colony Optimization (ACO) in order to search for a global best smallest set of network traffic features for real-time intrusion detection data set. They used UCI benchmark data set and the algorithm was best suited for real valued data sets [50] proposed Fuzzy IDS (FIDS) for network intrusions like SYN and UDP floods, Ping of Death, E-mail Bomb, FTP/Telnet password guessing and port scanning. In [51], an anomaly detection system at hypervisor layer named hypervisor detector is developed and evaluated to detect the malicious activities in cloud environment. The proposed hypervisor detector is implemented with Adaptive Neuro-Fuzzy Inference System (ANFIS). The ANFIS model integrates the artificial neural network (ANN) and fuzzy inference system into a composite ensuring that there are no limitations to distinguish the pertinent features of ANN and fuzzy inference system. The approach proposed by [50] cannot be used in real time for detecting network intrusions as the training time is significant by more. Features for comparison are taken from network packet header. This approach is used for large-scale DoS/DDoS attacks. To reduce training time of ANN, fuzzy logic with ANN can be used for fast detection of unknown attacks in cloud.
3.1.2.6. Association rule based IDS
Some intrusion attacks are formed based on known attacks or variant of known attacks [48] proposed network-based intrusion detection using data mining techniques. In this approach, signature-based algorithm generates signatures for misuse detection. However, a drawback of the proposed algorithm is its time consumption for generating signatures [52] solved the database scanning time problem examined in [48]. They proposed scanning reduction algorithm to reduce the number of database scans for effectively generating signatures from previously known attacks. However, it has very high false positive alarm rate since unwanted patterns are produced [53] proposed length decreasing support based Apriori algorithm to detect intrusions to reduce production of a short pattern as derived by [48, 52]. It is faster than other Apriori-based approaches.
3.1.2.7. Support vector machine (SVM) based IDS
SVM [54, 55] is used to detect intrusions based on limited sample data, where dimensions of data will not affect the accuracy [56] proposed an IDS using PSO-SVMs for parameter optimization and feature optimization leading to higher accuracy. The integration of an IDS into Mobile Ad hoc Network (MANETs) used in [57] as a dependable and powerful solution. This IDS is capable of detecting the DoS type attacks at a high detection rate with fast computing speed. It is proved that the proposed IDS upgrades the reliability of the network notably by detecting and eliminating the malicious nodes in the system. In another work by [58], a monitoring technique for detecting Dos attacks in Wireless Mesh Networks (WMN) has been designed. Packet delivery ratio, average packet drops and delay metrics are the evaluation factors. It has been proved that proposed IDS successfully eliminates the malicious nodes and improves the packet delivery ratio while reducing the packet drop by integrating a priority mechanism into the system. However, the efficiency of the approach mentioned is just tested for static mesh networks and its efficiency under mobile networks has not been analyzed yet.
3.1.2.8. Genetic algorithm (GA) based IDS
GA were originally introduced by John Holland in [59] and it was inspired from natural evolution. In fact, GA is looking for optimum solution within a population of candidate solutions that are traditionally shown in the form of binary strings called chromosomes. Genetic algorithms (GAs [60] are used to choose network features (to define optimal parameters) which can be used for achieving result optimization and improving the accuracy of IDS in other techniques. In [61], seven features of the captured packet were used (namely Duration, Protocol, Source_port, Destination_port, Source_IP, Destination_IP, Attack_name). The proposed method used support confidence based simple and flexible framework for fitness function. For detecting network intrusions, generated rules were used. In another work presented in [62], Genetic Programming (GP) based approach to generate rules from network features were designed. Note that GP [63] is an extension of genetic algorithms that shows each one by a tree rather than a bit string. Because of hierarchy nature of the tree, GP can provide various types of model such as mathematical functions, logical and arithmetic expressions, computer programs, networks structures, etc. For deriving rules, they used support confidence based fitness function, and it classifies network intrusions effectively. The disadvantage of this method is training time period for the fitness function [64] proposed information theory and GA-based approach for detecting abnormal behavior. According to mutual information between network features and type of intrusion, a small number of network features closely with network attacks was detected. However, discrete features are considered on this approach. Another method presented in [60] is used to detect anomaly and misuse by a combination of fuzzy logic and genetic algorithms. Fuzzy logic is used to set quantitative parameters in intrusion detection, whilst genetic algorithm is used to discover best-fit parameters of the introduced numerical fuzzy function. Best-fit problem has been solved as reported by [62]. Clustering genetic algorithms were used to solve the computer network intrusion detection problem in [65]. It shows an efficient intelligent intrusion detection system. The combination of two stages into the process including clustering stage and genetic optimization stage were used. Not only the proposed algorithm is able to cluster the cases automatically, but also detects the unknown intruded action.
3.1.2.9. Artificial immune systems (AIS)
Artificial immune systems in intrusion detection are spreading for two subjects. Firstly, high level of protection from invading pathogens in human immune system brings in a robust, self-organized and distributed manner. Secondly, the techniques used in computer security before were not able to deal with the dynamic and increasingly complex nature of computer systems and their security.
Several AISs have been designed for a wide range of applications including document classification, fraud detection, and network-and host-based intrusion detection [66]. AISs can be widely split into two categories based on the mechanism that they run: network-based models and negative selection models. Network-based models refer to systems which are largely based on Jerne’s network theory [67] which identifies that interactions occur between antibodies and antibodies as well as between antibodies and antigens. Moreover, in negative selection models, for generating a population of detectors, they use negative selection.
Summary of IDS/IPS techniques
Dasgupta and Attoch-Okine [68] compared network and negative selection-based approaches to AIS design. Forrest et al. [69] proposed a self-oneself model that probabilistic individual antibodies do not interact. Several applications of AISs were considered, including anomaly detection, fault diagnosis, pattern recognition and computer security. In the field of computer security, they discussed virus detection and process anomaly detection, with several different approaches. Changes in behavior in UNIX processes can be detected through short-range correlation of process system calls. Detection of viruses can be done through detecting changes to files. Another way is using a signature-based approach and monitoring decoy programs, observe how they were changed, and build signatures from this for the main system. Another approach proposed by Aickelin et al. [70] discussed the application of danger theory to intrusion detection. They target to design a computational model of danger theory, which they consider critical in order to define, explore, and discover danger signals. They tried to build novel algorithms and used them to design an intrusion detection system with a low false positive rate. The correlation of signals to alerts and alerts to scenarios is considered particularly important. Their proposed system that was built on previous work in immunology by Matzinger [71] and work on attack correlation, collects signals from hosts, the network and elsewhere, and correlates these signals with alerts. The classification of alerts is good or bad in parallel to biological cell death by apoptosis and necrosis. Apoptosis is the process of cells death as a natural course of events. On the other hand, necrosis is opposite of that, where cells die pathologically. They wish that alerts could also be correlated to attack scenarios. The origination of these signals is not yet clear, and they will probably come from a combination of host and network sources. Traffic normalizers are some examples, i.e., a device that sits in the traffic stream and corrects potential ambiguities in this stream, packet sniffers. The danger algorithm is, however, yet used as the correlation algorithm. Whether the system actively responses to attacks is also not clearly yet. At the end, Aickelin et al. [70] concluded that if this approach works, the scaling problems of negative selection should be solved, but a large amount of research still remains to be done.
In [72], an adaptive immune system mechanism through unsupervised machine learning approaches is proposed to classify network traffic into either self (“normal”) and non-self-profiles (“suspicious”). Their approach distributes the NIDS among all connected network segments, allowing NIDS in each segment to identify potential threats individually and enabling the sharing of identified threat vectors between the communicating distributed NIDSs [72].
Negative selection algorithm: The mammalian immune system to select and elimination of harmful pathogens from the body is the basis of Negative Selection Algorithm. The human immune system produces gene libraries that develop antibodies through the gene expression process, which attach to pathogens and neutralize their impact on the body. The signature of the antigen is recognized and the population of antibodies is consulted to discover the antibody that is genetically designed to combat that antigen.
Clonal selection algorithm: The Clonal Selection Algorithm is the result of the Clonal Selection theory of immunity. The human body is successful at protecting the body from foreign pathogens that cause illness, it can be simulated in a security context to prevent and detect computers. In network intrusion, the artificial immune model consists of three different evolutionary stages Negative Selection, Clonal Selection, and gene library evolution. When an antigen is exposed, the bone marrow cells produce antibodies, which divide and secrete plasma cells through mitosis. After the response of these cells to the antigen, and store memory cells, which identify the type of antigen after the initial exposure. By reacting to this pathogen faster and skipping the detection phase of the response, these memory cells improve the speed of the response process. In artificial immune system, by creating artificial cells that treats like real body cells to detect the pathogen, and clone artificial antibodies to overwhelm the pathogen and perform the artificial response to eliminate the virus. The system is able to do self-detection, and implements an automated response to return to a normal state [5].
3.1.2.10. Hybrid techniques
Hybrid techniques use the combination of two or more techniques mentioned above. NeGPAIM [73] is based on a combination of two low level components including fuzzy logic for misuse detection and neural networks for anomaly detection, and also one high level component which generates central engine analyzing outcome of two low level components. One advantage of this technique is that it does not need dynamic updates of rules [74] presented an approach which uses a combination of Naive Bayes, ANN and Decision Tree (DT) classifiers on three separate sets of data input in order to better the performance of IDS. It is beneficial to use soft computing techniques on traditional IDS for Cloud environment. However, each technique has some pros and cons, which affect the performance of IDS. For example, higher time consumption to learn ANN network and less flexibility are the major disadvantages of ANN. Combining fuzzy logic to data mining techniques promote flexibility. GA with fuzzy logic improves performance of IDS, since GA selects best-fit rules for IDS. For matching patterns in a specific manner rather than general GA, it has better performance. In [75], an integrated fuzzy GNP rule mining with distance-based classification was proposed for network intrusions with high accuracy of detection rate. A density-based fuzzy imperialist competitive clustering algorithm was proposed by [76] under hybrid clustering method to improve the accuracy of intrusion detection.
As we discussed above, each technique has used widely and has some pros and cons. In Table 1, a brief description of each technique characteristics is shown.
Fraud detection
Fraud is an intentional deception with the aim of obtaining financial gain or causing loss by implicit or explicit trick [77]. Fraud is a public law violation, in which the fraudster tries to reach an unlawful advantage or causes irreparable damage. The approximation of damage losses made by fraud activities shows that fraud costs a very considerable amount of money. Statistics from the Internet Crime Complaint Center show that there has been a significant rising in reported fraud in last decade [7]. Financial fraud losses across payment cards, remote banking and cheques totaled £755 million in 2015, an increase of 26 percent compared to 2014. Prevented fraud totaled £1.76 billion in 2015. This represents incidents that were detected and prevented by the banks and card companies and is equivalent to £7 in every £10 of attempted fraud being stopped [78]. Fraud detection involves detecting infrequent fraud activities among numerous legitimate transactions as fast as possible. Fraud detection methods are developing rapidly in order to adapt with new incoming fraudulent strategies across the world. However, development of new fraud detection techniques becomes more difficult due to the severe limitation of the ideas exchange in fraud detection. The amount of fraudulent transactions is usually a very low share of the total transactions. Therefore, the detection of fraud transactions in an accurate and efficient way is difficult and challengeable. Hence, implementing an efficient method, which can distinguish rare fraud activities from billions of legitimate transaction, looks essential.
Types of fraud techniques
The classification of frauds can be broadly categorized into traditional card related frauds, merchant related frauds and Internet frauds.
Merchant related frauds: The methods used for committing credit card frauds are described below:
Merchant collusion: Merchant collusion is a type of fraud which is done and operates by merchant owners or their employees scheme to commit fraud using the cardholder accounts or by misusing the personal information. They take the information about cardholders to fraudsters.
Triangulation: This type of fraud occurs when products or goods are offered at heavily discounted rates and are also shipped before payment at websites. The buyer while browse the site and place the online information such as name, address and valid credit card details to the site if he likes the offer. When these details received from fraudsters, they order it from a legitimate site using stolen credit card details. The fraudsters by using the credit card information purchase their needs then.
Internet related frauds: The internet brings fraudsters a base to make the frauds in the simplest and the easiest way. With the development of trans-border, economic and political spaces, a new worlds market has become available on the internet, capturing consumers from most countries around the world. Most commonly used techniques in Internet fraud are as follows [79]:
Site cloning: When fraudsters close an entire site or just the pages from which the customer made his purchases. The details entered by customer will be received and send the customer a fake receipt of the transaction through the email just as the real company would do.
False merchant sites: For completing details such as name and address to access the webpage where the customer gets his products will be required. Many of these sites claim to be free, but a valid credit card number to confirm an individual’s age will be needed.
Credit card generators: Some computer programs are capable of generating valid credit card numbers and expiry dates. From a single account number, these generators work by creating lists of credit card account numbers. This generator is used by card issuers to generate other valid card number combinations.
Lost/Stolen cards: This is the easiest way for the fraudsters where he gets the information of the cardholders by finding or stealing a credit card without requiring any on the modern technology.
Account takeover: When the valid customer’s personal information is taken by the fraudsters, it happens.
Cardholder-not-present (CNP): CNP transactions are done only on the internet that do not need any physical presence of card or cardholder at the point-of-sale. This takes many kinds of transactions such as orders taken over the phone or Internet, by mail order or fax. In such transactions, retailers are unable to physically check the card or the identity of the cardholder, which makes the user anonymous and able to hide their real identity.
Fake and counterfeit cards: This is another kind of fraud where the counterfeit cards with lost or stolen cards pose highest rank in credit card frauds. Fraudsters always try finding new and more creative ways to create counterfeit cards. Some of the techniques used for creating false and counterfeit cards are as follows:
Erasing the magnetic strip: When the fraudsters erase the magnetic stripe by using the powerful electro-magnet tools, it happens. The fraudster then misuses the details on the card and they match the details of a valid card, which they may have attained. For example, when the fraudster starts using the card, the cashier will swipe the card through the terminal several times, before understanding that the metallic strip does not work properly.
Creating a fake card: Sophisticated machines have become available for creating a fake card from using the scratch. Although fake cards require a lot of effort and skill to be produced, it is a common fraud. Modern cards are having many security features designed for making it difficult for fraudsters to make good quality fraudulent. Holograms are one of the best prevention methods in the credit cards that makes very difficult to forge cards effectively.
Skimming: One of the most popular and fast emerging types of credit card fraud is skimming. Skimming is involved in most Counterfeit fraud cases. When the actual data on a card’s magnetic stripe is electronically copied onto another, it is called skimming. Fraudsters carry pocket skimming devices, a battery-operated electronic magnetic stripe reader, in order to swipe customer’s cards to get hold of customer’s card details.
Phishing: This type of fraud used to steal a person’s identity. It is commonly performed via spam e-mail or pop-up windows. Phishing happens when a malicious person transmitting lots of false e-mails. The e-mails seem to be from a website or company you trust, for example your bank. The message tells you to cooperate the company with your personal details consisting your payment card details. They can assert that the reason for this is a database crash or things like that.
According to fraud facts report [80], the behavior of fraud losses of cards changed from 2006 to 2015. Figure 7 shows the types of losses percentage. There are different types of fraud. We will categorize them according to their applications as follows:
Definition of credit card fraud can be “Unauthorized account activity by a person in which the account was not pre designated” [79].
The payment card industry has grown exponentially during last few years. Fraud tends to be committed to certain patterns and that it is possible to detect such patterns, and as a result fraud.
(a) Credit card losses by type at 2015; (b) Credit card losses by type at 2006.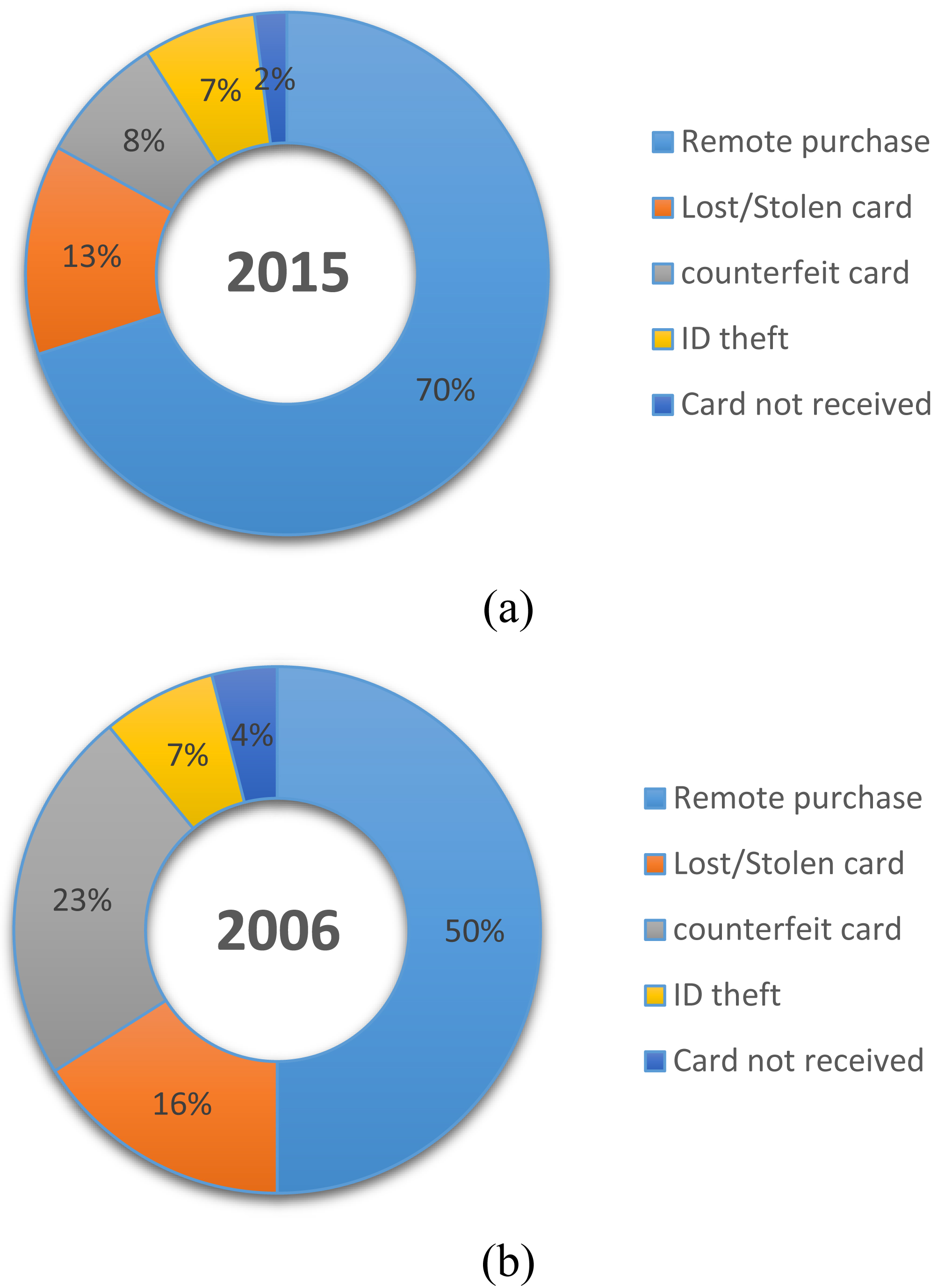
When a particular consumer uses its credit card, a fixed pattern of credit card usage exists, that is made by the way consumer uses its credit card. Using the last one or two years, data can be used for training neural network about the particular pattern of using a credit card by a particular consumer. The neural network can be trained based on information regarding to various categories about the card holder, such as occupation of the card holder, income, occupation may fall in one category while in another category information about the large amount of purchased are placed, this information include the number of large purchase, frequencies of large purchase, location where these kinds of purchase are taken place etc. within a fixed time period [79].
Fraud detection techniques can be classified into supervised based, unsupervised based and statistical based techniques as shown in Fig. 8.
In supervised learning, for designing models, samples of both fraudulent and non-fraudulent records, associated with their labels are used. These techniques are mostly used in fraud analysis approach. Back Propagation Network (BPN) is one of the most popular supervised neural networks. A multi-stage dynamic optimization method, that is a generalization of the delta rule, is used to minimize the optimize function [81, 82, 83]
Credit card fraud detection techniques.
It has been observed that credit card fraud detection has two highly specific characteristics. First, obviously the very limited time span in which the acceptance or rejection of decision has to be made. Second, the large amount of credit card operations that should be processed at a given time [279].
Three layers BPNin combination with genetic algorithms (GA) for credit card fraud detection were proposed by [84]. In this work, genetic algorithms were used to make a decision about the network architecture, dealing with the network topology, number of hidden layers and number of nodes in each layer.
In another work presented by [85], a parallel granular neural network (GNN) is used to accelerate data mining and knowledge discovery process for credit card fraud detection. GNN is one type of Fuzzy Neural Network on the basis of Knowledge Discovery (FNNKD). The average training errors were less in the presence of larger training data set.
In [86], a CNN (Convolutional Neural Network)-based fraud detection framework was used to capture the inherent patterns of fraud behaviors learned from labeled data. Many transaction data is represented by a feature matrix, on which a convolutional neural network is implemented to identify a set of hidden patterns for each sample. They stated that experiments on real-world massive transactions of a major commercial bank show its superior performance in comparison with some state-of-the-art methods. In order to implement a CNN to credit card fraud detection, we need to transform features into a feature matrix to fit the CNN model. It includes over 260 million transactions of credit cards in a year. About four thousand transactions are labeled as frauds and the rest are legitimate transactions. The CNN model compared with SVM and some neural networks provides better performance.
The other type is unsupervised techniques. In this type, the previous knowledge of fraudulent and normal records in unsupervised learning is not essential. These methods increase alarm rate for those transactions, which are most different from the normal ones. These techniques are mostly used in user behavior approach. ANNs can provide a good result, if enough large transaction data set exists. They require a long training data set. Self-organizing map (SOM) is one of the most popular unsupervised neural networks learning which was proposed by [87]. It operates in two phases: training and mapping. In the first phase, the map is built and weights of the neurons are updated iteratively, based on input samples. In the second phase, test data is classified automatically into normal and fraudulent classes through the procedure of mapping [88]. After training the SOM, new unseen transactions are fed to the network and it classifies into normal and fraud clusters, if it is similar to all normal records, it is classified as normal. The same procedure happens for fraud transactions either.
3.2.2.1. Artificial immune system (AIS)
The two major response of immune and defense are as follows: innate immune response and acquired immune response. The body’s first response defense consists of the outer, unbroken skin and the “mucus membranes” lining internal channels, such as the respiratory and digestive tracts. Acquired immunity starts defending whenever the harmful cells could pass through the innate immune defense. In fact, adaptive immune response based on antigen-specific recognition of almost unlimited types of infectious substances carries out, even if previously unseen or mutated.
The acquired immune response is mighty of “remembering” every infection; therefore, a second exposure to the same pathogen is dealt with more efficiently.
AIS is a recent sub-field based on the biological metaphor of the immune system [89]. The immune system can identify self and non-self-cells, or more specific, between harmful cells (named pathogens) and other cells. The ability to recognize differences in patterns and capability of detecting and eliminating infections precisely has possessed the engineer’s intention in all fields. The main concepts that have used are negative selection algorithm, immune networks algorithm, clonal selection algorithm, and the dendritic cells algorithm.
Comparison of NN, GA and AIS methods, which are mostly used in credit card fraud detection
3.2.2.2. Negative selection
NSA (Negative Selection Algorithm) which was proposed by [90] is a change detection algorithm based on the T-Cells generation process of biological immune system. Since it was first designed, it has attracted many researchers’ attention in AIS and has gone through some phenomenal evolution. NSA has two stages: generation and detection. In generation phase, the detectors by trying some random processes are made and censored by trying to match self-sample. Those entrants that match (by the affinity of higher than affinity threshold) are removed and the rest are known as detectors. In detection stage, the set of detectors are used in validating whether an incoming data instance is a self or non-self. If it matches (if its affinity was higher than affinity threshold) any detector, it is claimed as non-self or anomaly.
3.2.2.3. Clonal selection
This theory is proposed for the immune system to describe the basic features of an immune response to an antigenic motivation. The selection mechanism ensures that only those clones (antibodies) with higher affinity threshold for the encountered antigen will pass. On the basis of clonal selection principle, clonal selection algorithm was initially designed in [91] and formally described in [92]. The general algorithm was called CLONALG.
Gadi et al. [91] used AIRS in the field of transactional credit card fraud detection in [91]. AIRS is a classification type algorithm that is based on AIS, which uses clonal selection to create detectors. AIRS creates detectors for all of the classes in the database and uses k-Nearest Neighbor (KNN) algorithm in detection stage in order to classify each record.
Soltani et al. proposed AIRS on credit card fraud detection in [93]. According to long training time of AIRS, authors have designed the model in cloud computing environment to shorten the time. MapReduce API had been used which works based on Hadoop distributed file system, and generates the algorithm in parallel.
RamaKalyani and UmaDevi proposed a model for credit card fraud detection based on the principles of GA in [94]. The aim of the approach was developing a synthetizing algorithm for creating test data and detecting fraudulent transaction.
Table 2 depicts a comparison of structure between three methods, which are mostly used in credit cards that fraud detects them briefly.
3.2.2.4. Hidden markov model (HMM)
An HMM is a double embedded casual process, which is implemented to model much more complicated casual process in which the model is implemented in a much more complicated casual process in comparison to a traditional Markov model. The base of the system is assumed to be a Markov process with unseen states. In simpler Markov models like Markov chains, states are deterministic transition probabilities are only unknown parameters. On the other hand, the states of an HMM are hidden, but state dependent outputs are visible. In fraud detection of credit card transaction, an HMM is trained for modeling the normal behavior encoded in user profiles. In this model, a new incoming transaction will be classified as fraud if it is not accepted by the model with high enough probability. Each user profile contains a set of information about 10 recent transactions of that user such as time, category and amount for each transaction. HMM creates high false positive rate [95]. Bhusari et al. [56] utilized HMM for detecting frauds with low false alarm.
3.2.2.5. Support vector machine (SVM)
SVM [57] is a supervised learning approach with associated learning algorithms that is capable of analyzing and recognizing patterns for classification and regression tasks. SVM is a binary classifier. The underlying idea of SVM was discovering an optimal hyper-plane, which distinct instances of two given classes, linearly. This hyper-plane was assumed to be located in the gap between some marginal instances called support vectors [77].
SVM has been implemented successfully to a wide range of applications. In credit card fraud detection, Ghosh and Reilly [96] proposed a model using SVMs. In this research, a three-layer feed-forward neural network was used for detecting fraudulent credit card transactions through only two passes required to check a fraud score in every two hours.
Chen et al. [97] implemented a Binary Support Vector System (BSVS), in which support vectors were chosen by GA. In this model, SOM was first tried to obtain a high true negative rate and after that, BSVS was used to improve training the data according to their distribution.
In [98], a classification model based on decision trees and SVM were designed for detecting credit card fraud. In this work, a comparative study between SVM and decision tree approaches in credit card fraud detection with a real data set was presented. The results revealed that the decision tree classifiers such as CART (Classification and Regression Tree) perform much better results for SVM in solving the problem.
3.2.2.6. Bayesian network
A Bayesian network is a graphical model that shows conditional dependencies between random variables. The basic graphical model is directed acyclic graph. Bayesian networks are effective for identifying unknown probabilities given known probabilities in the presence of uncertainty. Bayesian networks can play an important role in modeling conditions where some basic information is already known but incoming data is uncertain or partially unavailable [99]. The aim of using Bayes rules is often used for the prediction of the class label related to a given vector of features or attributes. Bayesian networks have been used successfully for different fields of interest for instance churn prevention [100] in business, pattern recognition in vision [101], generation of diagnostic in medicine [102] and fault diagnosis. Besides, these networks have been implemented to identify anomalies and frauds in the field of credit card transactions or telecommunication networks.
3.2.2.7. Expert systems
Rules can be created from information, which are gained from a human expert and saved in a rule-based system as IF-THEN rules. Knowledge base system or an expert system is the information, which is cumulated in knowledge base. The rules in the expert system are used in order to do operations on a data to conclude to reach appropriate inference. Financial analysis and fraud detection are one example of the areas, which it can be used. By using expert system doubtful activity or transaction can be detected from deviations from “normal” spending patterns [103].
3.2.2.8. Fuzzy darwinian system
One type of Evolutionary-Fuzzy system named Fuzzy Darwinian Detection [104] generates GP for improving fuzzy rules. This system includes GP part combined with the fuzzy expert system. It achieved the results of very high accuracy and low false positive rate in comparison with other, but it is extremely expensive.
3.2.2.9. Statistical distribution based methods
Statistical Distribution based techniques are basically built on key assumption that is [5]: “Normal data instances happen in high likelihood regions of a model, while anomalies happen in the low likelihood regions of the model.” According to [5], there are two types of statistical methods. These are Parametric and Nonparametric.
The assumption of parametric techniques is that the normal data is created by a parametric distribution with parameters
The structure of the model in non-parametric statistical techniques is undefined, however, it is determined from given data instead. Such techniques usually provide fewer norms regarding the data, such as density smoothness, in comparison with parametric techniques. The easiest non-parametric statistical technique is using histograms to keep up a profile of the normal data.
3.2.2.10. Markov chain model
Markov Chain Model is one of the statistical based models proposed in detecting anomalies [105] implemented a discrete-time stochastic process to show how a random variable varies at discrete points in time. A Markov chain model is used to show a temporal profile of normal behavior in a computer and network system. The learning model is from historical data of normal profile behavior. Let
The probability distribution of the state at time
A state transition from time
and an initial probability distribution [106]:
where
The probability that a sequence of states
The disadvantage of statistical methods does not certify that all anomalies will be found for the cases where no specific test was developed.
Some of the main approaches as mentioned above (e.g., Bayesian, Neural Network, SVM and etc.) can be categorized into three groups [107].
In [107], proximity and distance terms implemented to represent similarity and differences are the key approaches applied for detection of anomalies in any network. Proximity based anomaly detection techniques analyze each object with respect to its neighbors. Normal data objects and their neighbors have close proximity, i.e., following a dense neighborhood pattern that anomalous objects deviate far away from their nearest neighbors. Proximity based techniques can be mainly categorized into distance based and density based [108, 107].
Distance based techniques compute the anomaly score by implementing the deviation of a data object to its
Density based techniques calculates the score of an anomaly by using the relative density of each data object. These techniques work by the density of an object and density around its neighbors. For a normal object, densities are supposed to be same whereas for anomalous objects they are different. The notion of relative density is usually used to measure the degree of anomalous behavior of an object [110] proposed Outlier Detection implementing In-degree Number (ODIN) score of an object. In-degree number score is the number of
Advantage and disadvantages of anomaly detection approaches [107]
Advantage and disadvantages of anomaly detection approaches [107]
In cluster-based approach, often anomalies belong to a small sparse cluster or do not belong to any cluster while the normal objects are a section of large and dense clusters. Clusters of the data objects can be implemented by trying numerous approaches such as, Two-Step Anomaly Detection Approach Using Clustering Algorithm [114], Online clustering for evolving data streams with online anomaly detection [115], Clustering and Unsupervised Anomaly Detection with l 2 Normalized Deep Auto-Encoder Representations [116], K-Means, K-Medoids for small data sets, CLARANS [117] and CLARA [118] for large data sets and Chameleon [119], BIRCH [120] for doing macro clustering on micro clusters. In cluster based anomaly detection methods, if the object does not belong to any cluster, the density based clustering methods can be applied like DBSCAN. DBSCAN proposed in [121] investigates the density around each object and the one being isolated or of less density than others is considered as an anomaly. This approach can detect the clusters with arbitrarily any shape. A number of modified variants of DBSCAN such as, FDBSCAN [44], L-DBSCAN [122], C-DBSCAN [123], P-DBSCAN [124], and TI-DBSCAN [125], NG-DBSCAN [126], DSET-SCAN [127] have also been implemented to detect the anomalies effectively. If the distance between object and cluster to which it is closest is large, then methods mentioned above can provide a better way to detect the anomalies. However, they concentrate more in order to discover the clusters and consider any point not related to any cluster as noise, which in a way is assumed to be anomalous. For solving such problems, numerous advanced methods as Cluster based Local Outlier Factor (CBLOF) and the corresponding algorithm FindCBLOF [128] are designed to find the encountered anomalies. Some of other methods like SOM as an unsupervised method designed by Kohonen [129],
Classification based approaches
Classification in [54] is defined as a supervised method with two steps, i.e., a learning step and a classification step. In the learning stage, a training set of labeled data instances are applied to construct a classification model and in the classification step, the designed model is used to predict the class labels for the data. Both the steps are stated as the training and the test stages. For detection of anomalies, the training data objects are labeled as ‘normal’ and ‘anomalous’.
Data sets used by researchers
Data sets used by researchers
In one class model, only a single labeled class is defined, i.e., classifier is designed to just define the normal class and all those data objects that belong to that class are act as normal whereas the ones that do not fit in the defined class behave as anomalies. Some examples of one class models applied for anomaly detection are one-class SVM [132], Gaussian model description (GAUSSD) [133], Principal Component Analysis Description (PCAD) etc.
If data objects do not belong to a single class, it belongs to multiple classes. A number of classifiers are available for the classification issues. Some of them are capable of anomaly detection discussed above.
Summary of pros and cons of each approaches mentioned above have been depicted in Table 3.
An effective frauddetection technique should be capable of addressing these problems in order to gain the best performance [77].
Imbalanced data: The credit card fraud detection data has imbalanced nature. It means that just small portion of all credit card transactions are fraudulent. The results in the detection of fraud transactions are very difficult and imprecise rate of fraud.
Different misclassification importance: Various misclassification errors have various importance. Misclassification of a normal transaction as fraud is not as harmful as detecting a fraud transaction as normal.
Overlapping data: Many transactions may be considered as fraudulent, while they are not false positive, a fraudulent transaction may also seem to be normal (false negative). Hence gaining a low rate of false positive and false negative is a key challenge of fraud detection systems.
Lack of adaptability: Classification algorithms are commonly faced with the issue of finding new types of normal or fraudulent patterns. The supervised and unsupervised fraud detection systems are inefficient in detecting new patterns of normal and fraud behaviors.
Fraud detection cost: The system should take into account both the cost of fraudulent behavior that is detected and the cost of preventing it.
The mentioned methods in any field definitely need a credible data set for testing, and examine efficiency in comparison to other’s related work. The lack of publicly available database has been a limiting factor for the publications on financial fraud detection, particularly credit card transactions.
Table 4 brings you some credit card fraud detection data set, which had used real or synthetically generated data set.
Evaluation
A variety of measures for various algorithms has been implemented for evaluation. False Positive (FP), False Negative (FN), True Positive (TP), and True Negative (TN) and the relation between them are four well-known quantities which usually adopted by credit card fraud detection researchers for comparison of different approaches’ accuracy. The mentioned parameters are defined as follows:
FP or false positive rate: The portion of the non-fraudulent transactions, which are classified as fraudulent transactions wrongly.
FN or false negative rate: The portion of the fraudulent transactions, which are classified as normal transactions wrongly.
TP or true positive rate: The portion of the fraudulent transactions, which are classified as fraudulent transactions correctly.
TN or true negative rate: The portion of the normal transactions, which are classified as normal transactions correctly.
Table 5 shows the details of the most well-known formulas which are used mostly for evaluation of the methods.
Credit card fraud detection evaluation measures
Insider trading is one of the many white-collar crimes that can contribute to the inconsistency of the economy. Commonly, the finding illegal insider trades have been a human-driven procedure. Formally, insider trading is not always illegal. Insider in a company consists of either Officers (CEO, CFO), large shareholders (
Engelen [136] tried a case-based method and measured the attempted prosecution by Belgian authorities of insider trading around a revenue declaration in Bekaert, NV. In a case that was examined, because it was one of the first cases trying to prosecute insider trading under a new law, the Appeals Court adjudicated that the information used by the accused parties was not valued relevant and hence was not privileged because it had already been revealed that the firm would pay a revenue and revenues have been found to be irrelevant to the markets.
The available data is gathered from several heterogeneous sources such as stock trading data, option-trading data, and news. The data has temporal associations since the data is collected continuously. The temporal and streaming nature has also been exploited in certain techniques [137].
In [138], the collected data were used to construct networks which capture the relationship between trading behaviors of insiders. They compared the reported price of the transaction (purchase or sale) with the market closing price of the company’s stock on the same day of the transaction. This anomaly ranking can be used by investigators to prioritize cases for further analysis [138].
Stock market fraud detection
Stock fraud commonly occurs when brokers try to manipulate their customers into trading stocks without regard for the customers’ real interests. Stock fraud can happen at a company level, or by a single stockbroker. Corporate insiders, brokers, underwriters, large shareholders and market makers are likely to be manipulators [139].
[139] used an unsupervised technique named Peer Group Analysis (PGA) for fraud detection. The objective of PGA is to define the expected pattern of behavior around the target sequence in order to find the behavior of similar objects, and then to detect any variances in evolution among the expected pattern and the target.
The most important feature of PGA depends on its concentration on local patterns rather than global models; a sequence may include unusual in comparison to the whole population of sequences but may show unusual properties when compared with its peer group. That is, it may start to deviate in behavior from objects to which it has previously been similar.
According to [140], assume that we have observations of
Medical and public health anomaly detection
The fast growth of using electronic health records and computerized systems has led to newly evolving opportunities for better detection of fraud and abuse. Emerging new techniques in machine learning and artificial intelligence bring attention to automated methods of fraud detection. Combination of automated methods and statistical knowledge led to a newly emerging interdisciplinary branch of science that is named Knowledge Discovery from Databases (KDD) with the core of data mining.
According to the expansion of IT technologies, increased attention has concentrated on smart health service platforms to identify emergency situations relevance to chronic disease, telemedicine, silver care, and wellness. Moreover, there is a high plea for technologies which can properly judge a situation and provide suitable countermeasures or health information if an emergency situation happens [141]. With the emergence of IT convergence technologies, there has been a growing demand for different real-time smart health services. Smart health service detects and monitors a patient’s daily health status without considering location and transmits it to the medical information center. It is capable of providing disease information and guidelines for doctors to quickly and precisely diagnose patients with lifestyle diseases detection [142, 143] and tracing with a CCD (Charge-Coupled Device) camera in the convergence supervision sector are required. There are some issues for detecting and tracing real-time bio-images. Some examples are cases in when a camera moves, a part of the traced object is covered by another object, tracing fails, or the noise removal damages accuracy that is mentioned in [144]. Computer hardware and software have improved in terms of both quality and quantity. The user-interface has developed to incorporate three-dimensional graphics and real-time voice output. Hence, an innovative bio-interface related to users must be created. A mobile virtual interface, which can be shown through biometrics described in human motions, would play an important role in the interplay between computers and humans [141].
Supervised methods needs confidence in the right classification of the records. Moreover, they are beneficial in detecting previously known patterns of fraud and normal. Therefore, the models should be frequently updated to reflect new types of fraudulent behaviors and changes in the regulations and settings [145]. Examples of the supervised methods that have been implemented to health care fraud and abuse detection consists of decision tree like [146] that used six statistical techniques correlation analysis, logistic regression and classification tree for detecting provider fraud, and classification trees for finding provider fraud is another method used in [146, 147], genetic algorithms [148] and Support Vector Machine (SVM [149, 150].
Using decision tree, decision makers can choose best alternative and traversal from root to leaf indicates unique class separation based on maximum information gain. Decision Tree is widely used by many researchers in the healthcare field.
Another technique that is used in health anomaly detection is SVM. The support vector machine classifier creates a hyper plane or multiple hyper planes in high dimensional space that is used for classification, regression and other efficient tasks. Various kernel function such as polynomial, Gaussian, sigmoid etc., are used in this area.
Naïve Bayesian classifier has shown great performance in terms of accuracy so if attributes are independent of each other then we can use it in the medical field. Bayes theorem concentrates on prior, posterior and discrete probability distributions of data items. Bayesian Belief Network is widely used by many researchers in the healthcare field.
Different techniques used for health anomaly detection
Different techniques used for health anomaly detection
Regression is used to find out functions that explain the correlation among different variables. A mathematical model is constructed using training data set. In statistical modeling, two kinds of variables are used where one is called dependent variable and another one is called independent variable and usually represented using ‘Y’ and ‘X’. There is always one dependent variable while independent variable may be one or more than one. Regression is a statistical method, which investigates relationships between variables. Logistic regression does not consider the linear relationship between variables [151]. Regression is widely used in medical field for predicting the diseases or survivability of a patient.
When fraudsters become notified about a particular detection method, they will change their strategies to prevent detection. As mentioned above, supervised methods in detecting previously known patterns of fraud and abuse are useful. In theory, we can implement unsupervised approaches to detect new types of fraud or abuse. Unsupervised methods usually evaluate one claim’s attributes relevant to other claims and determine how they are related to or differ from each other. Hence, it can clear sequence and association rules among records, define anomaly record(s) or group similar records [145]. Examples of the unsupervised methods that have been used for health care fraud are clustering [152, 153, 154], outlier detection [154, 155].
The detection system can be categorized based on data, structure, and the analysis method. The detection system can be classified into host-based detection and network-based detection systems. Host-based detection analyzes objects, time, and abnormal type based on life-logs.
Detection systems based on analysis method can be categorized into either misused detection or anomaly detection. Misused detection is applied to detect known attacks by targeting weakness of the system. Since researchers must consider various known-attack patterns for their detection system, a great amount of maintenance is required. Moreover, the system cannot find attacks that are entered into the system, which makes the system penetrable to emulated attacks or cheats. Anomaly detection makes a profile for normal behaviors, CPU usage, files attributes, and changed information. When an abnormal pattern is detected, it is compared with the previously saved profile. If the detected abnormal pattern reaches a threshold value, it is considered as an anomaly situation. As profiles are composed based on previous behaviors, the error rate is high since a proper decision cannot be made on current behavior patterns. Table 6 shows different techniques used for health anomaly detection.
With the increasing trend of online social networks in different domains, social network analysis has recently grown rapidly. Online Social Networks (OSNs) have obtained the interest of researchers for their analysis of usage as well as detection of abnormal activities.
Anomalous activities in social networks represent unusual and illegal activities showing various behaviors than others present in the same structure. Sometimes, it becomes hard to analyze the social networks since their large size and complex nature and it becomes necessary to prune the networks to consists just the most relevant and significant relationships. In some applications, the scope of which anomaly is present is considered by giving a degree of being an outlier to each object in the data set. For example, [111] called this degree as Local Outlier Factor (LOF). OSNs are often shown as graphs in which users are observed as nodes and interactions between users as edges, which can be either labeled, or not. Usually binary and static social links are considered in which only the presence of a link is considered sufficiently good but users’ actual communication activity is given no importance.
OSNs are often shown as graphs in which users are represented as nodes and interactions between users as edges, which can be either labeled, or not. Often binary and static social links are considered in which just the presence of a link is considered sufficiently good but users’ actual communication activity is given no importance [178].
The graph resulting from such networks consists of user interaction activities is named an activity graph [179, 180] which can either be a basic activity graph or a weighted one. Basic activity graph shows the graph in which every pair of nodes has the same type of edges irrespective of strong or weak ties in among them whereas weighted activity graph is the one in which strength of the active link is also taken into account.
It has been observed that for any type of social network, analysis of one or more of the three influence factors is targeted subject node (node influencing others), a tie or a social link (communication link between nodes) or an object node (the node being influenced [181].
The graphical delegation of the social networks leads to the applicability of different anomaly detection methods. Proximity or similarity measures defined in data mining methods do not seem much appropriate for social networks. In social networks may be defined on the following basis the same [107]:
Structure context-based similarity: It is a local cluster or neighborhood based similarity in a way that nodes having the same neighborhood are considered as similar. A number of mutual friends usually make similar decisions and provide determining the relation of them.
Similarity based on random walks: This type of similarity could be well known by this example. Suppose information or message requires to be forwarded to multiple users. However, at an initial stage, it is sent to just two users A and B who forward it to others. Now, the closeness or similarity could be captured by the simultaneous receipt of the message from both A and B to the nodes. Therefore, here similarity is shown as a random walk measure over the network.
Anomaly detection techniques in social networks can be categorized as follows [107].
Behavior based techniques deal with the behavioral characteristics of the users. For example, the number and content of messages, the content of the items shared, the number of likes or comments on a post and duration of a conversation are some of the behavioral properties.
Content based filtering is one of the prominent and well-known behavior based approaches which anomalous behavior is detected by searching for the internal content of the sent and received messages. A trained classification model that may be implemented in the analysis phase is constructed using the content of the messages. For example, [182] proposed a Filtered Wall system which certain set of filtering rules were implemented by the users to prevent the unwanted and irrelevant posts from their walls. However, some smart malicious users are intelligent enough to deceive others by behaving similarly to the legitimate users. In social network scenario, Sybil attacks and cloning attacks are two of the quite popular attacks nowadays [183, 174, 174, 172, 172].
Even the complicated techniques like Honeypots implemented to detect the spammers fail to attract anomalous users in most of the situations. PCA is unsupervised statistical anomaly detection technique that was used by [184] for detecting the anomalous behavior in individuals. The evaluation was implemented on Facebook data set and a number of fake and compromised users were identified. The evaluation factors of normal and anomalous distributions were judged by observing the ‘like’ activities of the users, e.g., by observing the pages ‘liked’ by a user, the number of posts/pages liked at a particular period of time. The motivation for using this technique was the increment of fake Facebook like purchases, fake reviews for reviewing websites, followers on Twitter etc. Apart from these, an important contribution of this work was the detection of click spam highly prevalent nowadays in ads.
Moreover, the profile information of a user was used by Xiao et al. [185] to detect fake accounts in online social networks using certain supervised machine learning techniques for feature extraction and cluster building. The proposed technique is a faster and more efficient way to detect fake accounts as it only uses the attributes entered by a user during registration i.e., profile creation.
Structure based techniques
Structure based techniques work on the basic axiom of using structural properties to check the specification of normal and anomalous users. When a specific graph metric is discovered for different nodes or structures and the nodes showing different values than other users, then it is considered as anomalous. Any deviation from known pattern shows the anomalous behavior. The structural properties have been implemented by most of the researchers working in social network domain to define a number of new approaches for detecting anomalies in online social networks. For example, [186] studies the structural characteristics of the networks to predict various behaviors of individuals in link mining. A normal trend depicts that consumers, whose friends spend a lot, spend a lot themselves either. The concept of link analysis is appropriate for both heterogeneous and homogeneous networks, however, in the concerned work, the graphical structure of heterogeneous networks with different types of nodes or edges is given more concentrated [186] covered eight link mining tasks with their respective algorithms and grouped the defined tasks under three categories, namely object-related, link-related and graph-related. Most of the structure based link prediction methods show poor performance because of the involvement of prediction of future relationships likely to occur [187]. A number of complicated tasks such as Anomalous Link Discovery (ALD) was implemented which consists of only the prediction of anomalous relationships rather than all the consisted relationships. The results revealed that almost any prediction model has done quite well for ALD.
In social networks, link prediction is highly profitable for identifying friendship links among various users as such techniques are a good way to test connected, missing and corrupted links. Hence, they easily try to analyze the dynamics and prediction of future link behaviors.
Spectral anomaly detection techniques
Spectral anomaly detection techniques provide anomaly detection using some spectral characteristics in the spectral space of a graph. Various complex measures used which are applicable to the adjacency matrix such as Eigenvalues or Eigenvectors [188] or the different hyper graph algorithms used for Laplacian graphs [189] are focused on these methods. A social network graph is partitioned into different groups or communities in most of the approaches. Partitioning is done either by deleting the links among different nodes or implementing certain clustering-classification algorithms and measures. Some of the advanced techniques obtain the structural concept of centrality. For example, community structures were designed by Girvan and Newman in [190]. As shown in Fig. 9, communities in the form of various friendship groups were generated in which the strength of links among the nodes in a community or friendship group is dense whereas between various groups is sparse.
Friendship links depicting centrality.
The concept of between’s mainly shaped by Freeman [191] is modified to work for edges instead of vertices to detect the number of shortest paths among a set of vertices that go through the edge under consideration. The consequence proposed is that the edges with high value of between’s centrality determine the points where a network is expected to break and therefore are separated. Generally, in online social networks high between’s centrality is seemed to be at the junction of densely connected network groups. It results in a number of highlighted groups could be specified by eliminating the set of links from a graph.
Ying et al. [188] detected the malicious nodes by computing the spectral coordinates or the spectra i.e. the Eigenvalues or Eigenvectors for the normal and anomalous users with an exclusive reference to RLA’s. RLA’s was emphasized because the prior knowledge regarding which node is the attacker and which one is the victim node, were absent. If fake links or nodes were present, it affects the value of the graph spectra. Spectral coordinates of a victim node are implemented to analyze the interdependency among the victim and the attacker nodes, by computing the spectral coordinates for attacking nodes. The results revealed that malicious users govern the attack set and each attacking node is linked to a number of victim nodes as shown in Fig. 10.
Network collection of objects and the relationships is a robust way to depict connections between them. Some examples are global financial systems, which connect banks across the world, electric power grids connecting geographically distributed areas, and social networks that connect users, businesses, or customers using relationships such as friendship, collaboration, or transactional interactions.
Describing relationship between attacking and victim nodes.
Possible changes consist of insertion and deletion of vertices (objects), insertion and deletion of edges (relationships between objects), and modification of attributes (e.g., vertex or edge labels). One major issue over dynamic networks is anomaly detection – finding objects, relationships, or points in time that are not the same as others. There are many high-impact and practical applications of anomaly detection such as detection of ecological disturbances, like wildfires and cyclones; intrusion detection for individual systems and network systems; identifying abnormal users and events in communication networks, and detecting civil unrest using twitter feeds [107].
Methods of anomaly detection in dynamic networks can be categorized as follows (as shown in Fig. 11).
Overarching approach classification and types of anomalies they detect.
Community-based methods track the evolvement of communities and their related vertices in the graphs over time. The various approaches vary in two main aspects: (1) for the community structure they analyze and (2) the definitions of communities they use.
The vertex detection logic in community detection can be used for detecting anomalies. A Group of vertices that belongs to the same community is expected to behave the same. It means that if at sequential time steps, one vertex in the community has a remarkable number of new edges added, the other vertices in the community would also have a considerable number of new edges. If the rest of the vertices in the community did not have new edges added, the vertex that did is anomalous.
In sub-graph detection logic Instead of looking at individual vertices and their community belongingness, by observing the behavior of communities over time, entire sub-graphs that behave abnormally can be detected.
Using change detection logic in community detection Changes are detected by partitioning the streaming graphs into coherent parts based on the similarity of their partitioning (communities). The starting of each segment shows a detected change.
Compression
In this section, we are going to discuss the methods that are all based on the MDL principle. The MDL principle and compression techniques based on this maxim extract patterns and regularity in the data to achieve a compact graph representation. Applying this maxim to graphs is done by using the adjacency matrix of a graph as a single binary string, flattened in row or column main order. The data-specific features are all derived from the encoding cost of the graph or its specific substructures; therefore, anomalies are then defined as graphs or substructures that prevent compressibility.
When the edge is included, an edge in compression methods by trying edge detection logic in compression methods is considered anomalous if the compression of a sub-graph has higher encoding cost than when it is omitted.
The main idea is that sequential time steps that are very similar can be grouped together leading to low compression cost. Increase in the compression cost means that the new time step differs considerably from the previous ones, and thus implicates a change.
Matrix/tensor decomposition
These techniques try to show the set of graphs as a tensor, it also thought of as a multidimensional array, and perform tensor factorization or dimensionality reduction. For modeling a dynamic graph as a tensor, the easiest method is to build a dimension for each graph aspect of interest, e.g., a dimension for destination vertices, source vertices, and time.
One of the most popular methods for matrices is Singular Value Decomposition (SVD [192], and for higher order tensors (
Here, by using vertex detection logic Matrix decomposition is used to obtain activity vectors per vertex. A vertex is characterized as anomalous if its activity changes significantly between consecutive time steps.
In event detection logic, there are two major approaches: (1) Tensor decomposition estimates the original data in a reduced dimensionality, and the indicator of how well the original data is estimated is reconstruction error. (2) Singular values and vectors, as well as Eigenvalues and Eigenvectors, are traced over time in order to find notable changes that exhibit anomalous vertices.
Change detection logic in compression is as: the activity vector of a graph,
Distance measures
The metrics measured in graphs such as the number of vertices are typically structural features. The difference or similarity, which is inversely related, can be calculated once the summary metrics have been found for each graph. The metrics were chosen to extract and compare, and the methods they use to determine the anomalous values and corresponding graphs make different algorithms. Using the idea of distance as a metric to measure change is natural and widely used in [194, 195, 196].
By using edge detection if the evolvements of some edge attribute (e.g., edge weight) differ from the ‘normal’ behavior, then the corresponding edge is considered as anomalous.
A sub-graph with many ‘anomalous’ edges is assumed as anomalous.
In event detection, assumed a function
Probabilistic models
With a basis in distributions, probability theory, and scan statistics, these methods typically construct a model of what is considered ‘normal’ or expected, and any deviations from this model named as anomalous.
For vertex detection, there are two main approaches: (1) creating scan statistics time series and detecting points that are several standard deviations from the mean, (2) vertex classification [29].
For edge detection, communications (edges) are modeled using a counting process, and edges that deviate from the model by a statistically significant amount are flagged [29].
For sub-graph detection, fixed sub-graphs (e.g., paths and stars), multi-graphs, and cumulative graphs are used to construct models onthe expected behaviors. Deviations from the modelssignify an anomalous sub-graph [29].
And for event detection deviations from the models of the graph likelihood or the distribution of the Eigenvalues reveal when an event occurs [29, 197, 198, 199, 31, 9, 200, 201, 202, 203, 204, 205, 206, 207, 30, 208, 209, 210, 211, 212, 33].
According to the types of anomalies they find, a fair qualitative comparison can be made. The methods are again partitioned below:
Vertices methods: The online method proposed by [15] is the earliest design with available software, which models the frequency of the connections among vertices as a process of counting and uses Bayesian learning and predictive
Edges methods: The proposed method in [15] is the only Bayesian learning technique that identifies anomalous edges explicitly. However, the tensor methods proposed in ParCube [215], can find the reconstruction error at arbitrary granularities, even on a per cell basis. Hence, they are capable of identifying anomalous edges; however, for each edge, the reconstruction error must then be held, or the user must provide individual edges of interest to test.
Sub-graph methods: For finding optimal anomalous sub-graphs, NetSpot [216] is presented. Its alternating optimization approach limits the method to work on an entire graph series simultaneously. A set of highly anomalous sub-graphs and their corresponding time windows is the result of the algorithm, solving the issue of attribution and requiring no further analysis on the part of the user. While the authors assign outlier scores to the edges in the network in their own way, it would be fascinating to utilize an algorithm exclusively designed to assign outlier scores to edges in a network [14, 15, 217]. Preprocessing the networks using an auxiliary edge scoring method helps a mapping from the ones that do not fit the requirements of being weighted, plain, and undirected to networks that do.
Events/changes methods: DeltaCon [218] provides a graph similarity scoring function based on a number of desirable principles [215]. It has been shown to effectively distinguish between, and correctly mark as more important, the removal of ‘bridging’ edges and edges with higher weights, compared to edges that do not affect the overall structure if removed or have a low weight. Anomalies are found by finding the similarity between two adjacent graphs in the stream, flagging those, which are sufficiently different from their immediate neighbors as outliers. While not as robust as methods such as [15] that perform both sequential and retrospective analysis, there is a commensurate decrease in the runtime, scaling linearly with the number of edges in the networks.
There are many publicly accessible data sets for testing the available methods or for personal use as shown in Table 7.
Data sets used by researchers
Some of the application of WSNs.
Wireless sensor networks (WSNs) are networks of tiny, low cost, low energy, and multifunctional sensors which are densely deployed to monitor a phenomenon, track an object, or control a process [224]. WSNs are proposed in many application domains, which consists of personal, business, industry and military applications (as shown in Fig. 12). In a personal application like home automation, for business applications sales tracking, industrial applications such as architectural and control, finally in military applications such as enemy target monitoring and tracking [224, 225, 226]. One of the most important factors in the IOT (Internet of Things) paradigm mentioned in [227] is the WSNs because they act as a digital skin that provide a medium to access information about the physical world by any computational system. Different technologies are proposed to build the integration of WSNs with IOT such as the 6LowPAN standard defined by IETF [228] that let the transmission of IPv6 packets in computational limited networks. Sensor data analysis is of high importance to decision makers. It was reported by [229] that the reason of using a WSN is not only to collect data from the field of deployment, but also more significantly the analysis of this data at timely manner that makes them some major decisions. Hence, the data quality is the main concern since it reflects the true world state of WSN applications. Unfortunately, the raw measurements gathered by sensor nodes, especially from large scale WSNs, often have inaccuracy and incompleteness [54]. These inaccurate sensor measurements may be generated due to reasons related to sensor device itself or the sensing environment. Resource limitations of sensor devices in terms of storage, energy, processing, and bandwidth may lead to node failures and therefore, reporting of anomalous readings. Other reasons that are related to the environment consists the anomalies and the difficulties of the deployment area may also result in erroneous data [230, 231]. In addition, malicious attacks such as denial of service, sinkhole, black hole, selective forwarding, and wormhole attacks [226, 232, 233] may also contribute to making such inaccurate and low quality data. Moreover, physical interruptions such as destruction or movements of sensor devices caused by humans or animals may influence the data collection process and lead to anomalous measurement [224].
The anomaly detection techniques for traditional networks focus on the network layer itself, while data on the application layer of WSN are more important to be concerned [234, 235].
Anomaly detection solutions in WSNs are caused by their detection effectiveness and their efficiency in employing the limited network resources [229]. Detection effectiveness is shown by detection accuracy, detection rate, and false alarms. Detection efficiency is shown by energy consumption and memory usage.
Five major requirements are important to design effective and efficient anomaly detection models, which consist of dimension reduction, online detection, distributed detection, adaptive detection and data correlation exploitation.
Online detection certifies that real-time anomalies are not missed while distributed detection certifies that the limited resources are efficiently employed by distributing the computational load over the network. Data reduction that tries to decrease the dimension of data to improve the efficiency exploits the feature correlation in a distributed structure. Adaptive detection is crucial for real time detection in dynamic environments where the changes in data distribution affect the detection efficiency. Correlation in sensor data of close neighborhoods was discovered to improve the detection efficiency by the mean of distributed detection in close neighborhoods [236, 237].
Anomaly detection in wireless sensor networks: In WSNs, anomalies can be defined as those important deviations in the sensing data measurements from the normal sensed data profile [5]. These anomalies happen as result of several reasons and between them are errors in the measurements made by faulty sensor nodes, some noise generated by external factors, actual events because of the changes in the sensed environment, or malicious attacks launched by in danger sensor nodes. The following depicts challenges and requirements of anomaly detection in WSNs.
Classification of anomaly detection in WSNs: we classify the existing anomaly detection models based on the detection method used to design the model into statistical-based, nearest neighbor based, clustering-based, classification-based, and others (as shown in Fig. 13) [238, 239, 240].
Classification of methods used in WSN anomaly detection.
The statistical-based anomaly detection models are the earliest models designed for anomaly detection and mostly used for one dimensional data sets [194]. If the probability of a pattern with respect to the statistical model is low, it is considered as an anomaly. According to [229] WSNs and classified into parametric and non-parametric techniques. In the parametric techniques, it is assumed that the data is created from a known distribution and then the parameters of the distribution are easily approximated from this data. In the non-parametric techniques, the main data distribution is not known a priori.
Palpanas et al. [241] designed a distributed deviation detection model in WSN to eliminate the unnecessary communication overhead and computational cost. This model named kernel density, which is based on a non-parametric statistical technique. This model was not evaluated experimentally and only described theoretically to magnitude the tradeoff among detection effectiveness and efficiency.
The work presented in [242] is an upgrade of the kernel density estimator based model designed in [241] by adapting a cluster based structure for WSN.
According to [243], there is five online and distributed statistical-based outlier detection methods for WSNs called Temporal and Spatial real-data-based Outlier Detection (TSOD), Temporal Outlier Detection (TOD), spatial Predicted-data-based Outlier Detection (POD), Spatial Outlier Detection (SOD), and Spatial and Temporal Integrated Outlier Detection (STIOD). It was surveyed that the TOD lowered the communication overhead however made the low accurate detection. On the other hand, SOD reached high accuracy rate, however with high communication overhead. POD and STIOD have lowered the communication overhead, however still with low accuracy rate. TSOD is the best option among those five techniques as it brings better detection accuracy of outliers locally at each node.
Nearest-Neighbor-Based Anomaly Detection Models for WSNs: They have been proposed for anomaly detection in computer networks with the assumption that normal patterns of data are always discovered in a dense neighborhood while the anomalous ones are far from their neighbors [5].
In [244], an in-network outlier detection model was designed based on the calculation of the distance similarity among data instances to discover the global anomalies in WSN. In this model, each node implements the distance similarity to discover the anomalies and spread its result to its direct and next hop neighbors. Other nodes do this the same until all nodes comply on a common decision about anomalous measurements. However, the diffusion communication leads to high-energy consumption exclusively when dealing with large scale WSN.
In [245], an in-network outlier cleaning and removal method for WSNs was implemented. The wavelet-based method was proposed for outlier correction and the neighboring Dynamic Time Warping (DTW) distance based similarity method was proposed for outlier detection and removal. The wavelet approximation method was obtained to correct the short and occasionally appeared outliers. Authors asserted that since the short outliers are of high frequency, they could be detected by trying the first few wavelets that show the sensing series. Moreover, the application of wavelets enhanced reduction of the dimension of data and therefore decreased the communication cost in the network.
In [245], the model that they designed used the PCA for reducing the dimension of data variables and then calculates the distance metric. It was claimed that the dimensionality could be reduced to one in any situation when validating with a static IBRL data set. However, the unsupervised distance-based model needs to be validated for dynamic data sets such as environmental ones to certify the dimension reduction claims.
Clustering-based anomaly detection models for WSNs
Clustering models are amog the most important data mining models, which are proposed to group similar patterns with the same characteristics into clusters. A cluster is anomalous if it is either smaller than or distant from other clusters in the data set [229, 246, 247].
In [248], they surveyed that a distributed anomaly detection model based on clustering and k-NN technique was designed. Each sensor node gathers the data and does the clustering locally instead of transmitting the whole data to the base station or cluster head.
The model was evaluated against the baseline centralized model. It was reported that distributed model presents usually similar accuracy but with high communication overhead reduction in comparison to the centralized model.
It was shown that the distributed approach accuracy is similar to the centralized approach, while reducing the communication overhead notably.
In [249], they studied an Elliptical Summaries Anomaly Detection system (ESAD). Data metrics are gathered at individual sensors and converted to elliptical summaries using the same method of [250]. To detect anomalies, the single linkage clustering algorithm was applied to extracts clusters from heterogeneity data that groups normal and anomalous metrics in different clusters.
Classification-based anomaly detection models for WSNs
In [251], a Quarter Sphere Support Vector Machines (QSSVM)-based distributed anomaly detection model was designed to detect the anomalous experiments in the data. The model structure is the same as the structure of the model designed by similar authors in [248].
An adaptive and online one-class SVM based anomaly detection model was implemented in [252] based on the model designed in [253]. The same as models in [253, 251], the one-class QSSVM method was also applied for this model. The difference here is the online training of the SVM in which the normal reference model revealed by the radius
Advantages of using anomaly detection in WSN
Providing data reliability and quality is one of the most important motivations for anomaly detection in WSN. Since sensor data can be corrupted and damaged because of many reasons like reading errors, faulty sensors, or malicious attacks. Event reporting is another reason for implementing anomaly detection since many WSNs have been used lately for monitoring various kinds of phenomena, like weather changes and fire detection proposed in [254, 255]. The application of anomaly detection for event detection uses in detecting such a disaster or major problem in its early stage and uses in making decisions accordingly [229, 256, 257]. Sensing data are gathered in the shape of data streams which may be large volumes of real observations gathered from the environment [258]. Some WSNs are designed just for gathering one type of data such as temperature, light, humidity. This kind of data is called unvaried data. Multivariate data are recent WSNs, which is designed to collect multiple types of data from the field simultaneously. Usually more than one sensor to gather different types of data at the same time in each node. In the multivariate data, each type of data is called an attribute or feature. If one or more of its attributes are anomalous, the measurement considers it anomalous. With unvaried data, the anomaly detection can be easily obtained by observing that the single data attribute is anomalous in comparison with the attributes of other data instances. anomaly detection in multivariate WSNs is challenging because the individual attributes may not exhibit anomalous behavior but when they collected, may display anomalous behavior [211].
Limitations of WSN techniques
The significant challenge of anomaly detection in WSN is the way of achieving high detection efficiency with minimum energy cost.
Other challenges that should be considered during the implementation of suitable anomaly detectionsolution for WSNs are as follows [259]:
Computational and storage resource limitation: WSNs are made up of cheap sensors, which are really resource limited in terms of memory, and processing. The process of anomaly detection in WSN needs the using of the computational and storage resources for processing data in real time.
Communication overhead: Some traditional anomaly detection solutions are designed based on the centralized approach in which the data is gathered from sensors and delivered completely to be processed by the cluster head or the base station. But, the cost of data transmission is several orders of magnitude higher than the cost of data processing [224].
Dynamic network topology change: The stimulus of nodes in some WSN applications and the communication failures increase the network topology change. This change negatively influences the reliability of the normal reference model proposed by the anomaly detector.
Network heterogeneity: Sometimes, the application of WSN needs to use various types of nodes or devote different jobs to different nodes. In addition, the current sensor nodes might be equipped with many sensors for measuring various environmental phenomena simultaneously.
Dynamic streaming data: Another significant issue is the dynamic streaming nature of sensing data. There is no former knowledge available to design the normal distribution of sensing data.
Network scalability: Some WSNs applications developed over the time therefore some nodes may be added to the network. As a result, the old normal reference model, which was built for the network, needs to be updated. The high false alarm rate resulting from the development put a challenge to anomaly detection. In addition, the large amount of data produced due to network size development is also a problem for real time detection [229].
High dimension data: As network size may increase, the dimensionality of the gathered data may also increase. The increase of data dimensions results in a higher computational cost that use the energy and memory of sensors. As the anomaly detection process relies on the data metrics, the increase of data dimension becomes a challenge for efficiency aspect of anomaly detection.
Attacks on various network layers: There are different types of attack on each layer of WSN. We will discuss them briefly as follows:
Denial of service: Attack limited memory and less computational capacity of wireless sensor network can cause them vulnerable to denial of service attack [260].
Misdirection attack: In this type of attack, the information is lead to fake path. It changes the routing information of network and influence the connection negatively. Misdirection is a network layer attack. Authentication techniques among transmitter and receiver, multi hop routing, etc. can be used to detect misdirection attack [16].
Selective forwarding: Optional forwarding is a network layer attack. In this type of attack, a fake node acts like an actual node and lead the packets to a wrong path but optionally drops some of the packets so that it becomes hard to detect the intrusion. verification based routing, multi data flow and detection based on neighboring information can be proposed to identify this type of intrusion [260].
Sink hole attack: Sink hole attack occurs in a data link layer. This type of attack happens when an intruder comes with an agreement with a sensor node or presents a fake node in the sensor network. When a forged node absorbed the network traffic, an attack is implemented. Once the attack is successful, the fake node can do different malfunctions such as dropping all or selective packets and alteration of data [260].
Sybil attack: This happen when a malicious sensor node uses multiple identities to do an attack. In wireless sensor network, all the sensor nodes work well but this type of attack targets this cooperation and disturbs the routing and communication process [261].
Wormhole attack: Another data link layer attack is wormhole attack. In this type of intrusion, a malicious or forged node registers all the information and leads it to wrong way. This attack can happen without the knowledge of cryptography of actual wireless sensor node [262, 263].
Hello flood attack: In wireless sensor networks, routing protocols use Hello packets for detection of neighbors. Inthis type of attack, fake packets are used to cover hello packets and to attract the sensor nodes [263]. Attackers with ample radio resources and processing capabilities can create this type of attack. The victim node will detect false hello packet as normal node.
Note that limitations of WSN techniques are stated in Table 8.
One of the most basic aspects of video anomaly detection is video feature representation. Several research works have been done in discovering the right representation to do anomaly detection in video streams accurately with an acceptable false alarm rate. But, due to large variations in environment and human movement this is very challenging [266].
To reach the aim of automatically detecting anomalous events, some dynamics of events have to be obtained in order to detect the presence and the spatial location of an anomaly present in the scene [266].
Challenges in modeling a good representation
According to high dimensionality nature of the video, they cannot feed into a classifier directly: they have much information redundancy hence cause high computational complexity.
The key to any successful application is choosing the right feature. But, it is very challenging due to the following reasons [266]:
Action pattern variations within the same class: The class can be a set of the action (e.g., walking, clapping), or a set of the type of event (e.g., normal, abnormal). There exists a high variety of data within one class, due to the changes in style and appearance. The delegation should be general to cover the variations between human movements, human-human and human-object interactions.
Environmental variations and noise: The real-world scenes consist of a lot of noise and may differ a result of illumination changes and background dynamics. The features must be capable of covering the environmental variations for the method to perform under noisy environment. Conventional features used for anomaly detection: There is plenty of features for using anomaly detection. We will discuss some of which are used most in researches.
Optical flow-based descriptors: [267] proposed a region-based descriptor called “Motion Context” to describe both movement and appearance information of the spatio-temporal segment. The report used Edge Orientation Histogram (EOH) as appearance descriptor and Multi-Layer Histogram of Optical Flow (MHOF) as motion descriptor. Then for each query spatio-temporal segment, it looks for its best match in the training data set, and specifies the normality using a dynamic threshold. This approach is more efficient in comparison with their previous work using sparse approach. The same category of descriptors is spatio-temporal video volume descriptors (HOG3D) proposed in [268]: these volumes are specified by the histogram of the spatio-temporal gradient in polar coordinates [269]. In [270], 3D gradient features of each spatio-temporal cube are exploited from the video sequence and trained to gain sparse combinations with allowable reconstruction errors.
Trajectory based sparse reconstruction: [271] utilized a route based joint sparse reconstruction framework for video anomaly detection, which depends on good tracking to exploit trajectories. Inspired by [272, 267], the authors use Multi-scale HOF (MHOF) as the feature descriptor to implement the basis for sparse representation. The fundamental underlying assumption of these methods is that any new feature representation of a normal/anomalous event can be approximately modeled as a (sparse) linear combination of the feature representations of previously observed events in a training dictionary [273].
Online anomaly detection has the benefit that it can let experts do corrective actions as soon as the anomaly has happened in the sequence data. In this approach, anomalies are detected using PCA with oversampling strategy. PCA is a way of identifying patterns in data and expressing data in such a way as to focus their likenesses and variances. PCA is an unsupervised dimension reduction method. PCA is a statistical method that uses an orthogonal transformation to change over a set of observations of probably correlated variables into a set of values of linearly uncorrelated variables called principal components. The number of principal components is less than or equal to the number of original variables [274].
Platforms used in online anomaly detection
Platforms used in online anomaly detection
Streaming analytics: Data streams can be viewed as a continuous stream of events happening quickly. Processing such high-speed data as and when it flows into the system before entering the database is known as streaming analytics. Streams process data as it flows into the application, the vast amount of data flows at greater speed over the network today [275].
Applications of streaming analytics are found across industries namely, personalized e-commerce marketing, notifications by banks, actuators embedded in physical objects, real-time fraud detection, data and identity protection services, analysis of data generated by sensors [276] proposed an online anomaly detection algorithm based on Kolmogorov-Smirnov goodness of fit test to detect anomalous access requests in the cloud environment at runtime. Recognizing individual data points as anomalous can bring about false alerts. Hence, they proposed a way to deal with detecting anomalous user requests, which show as changes in the system behavior conflicting with what is normal. The proposed online anomaly detection algorithm shows the statistical process of anomaly detection. An anomalous window conveys more information and represents a pattern or distribution of an unusual characteristic of data. After receiving a window, the framework makes its cumulative distribution function. It cumulates the most recent
One of the biggest challenges for fraud detection systems is the tremendous growing amount of transactions. Current fraud detection systems need to be more effective and scalable in order to handle such large amount of incoming data. Hence, using Big Data technology is the best solution for this problem. Many Big Data platforms are released to store and process data in recent years. The MapReduce framework was proposed in 2004 [277]. Apache Hadoop is presented as the most popular open-source implementation of MapReduce and DFS for large-scale data processing and storing. However, Hadoop has a poor performance on iterative and online computing. Apache Spark allows users to persist the data in memory and is the most popular batch-processing platform for iterative computing. Storm is the most widely used real-time streaming processing system. Storm’s applications are submitted as topologies. These topologies usually contain two components, which are called spout and bolt. Spout is the source of streams in topology. It reads tuples from an external source and sends them into the topology. Bolt processes the data once a tuple. HBase4 is an open source distributed key-value store developed on top of the distributed storage system HDFS [278].
[278] proposed a hybrid framework with Big Data technologies to solve performance challenges faced by online credit card fraud detection systems. As a real time system, not only the need to consider the performance issues during data storing, model training, data sharing and fraud detection, but also take care of the integration problems of them since any slow component could become a bottleneck of the whole system should be considered [278]. The framework that was proposed in [278] aims at fusing different detection algorithms to improve accuracy and using a four-layer design to handle data storage, model training, data sharing and online detection. We implement the framework with latest Big Data technologies, which help to build a scalable, fault-tolerant and high performance system.
Note that platforms used in online anomaly detection are stated in Table 9.
In this work, we have discussed different ways in which the problem of anomaly detection has been formulated in literature, and have attempted to provide an overview of the huge literature on various techniques. For each category of anomaly detection techniques, we have identified a unique assumption regarding the notion of normal and anomalous data. When applying a given technique to a particular domain, these assumptions can be used as guidelines to assess the effectiveness of the technique in that domain. Ideally, a comprehensive survey on anomaly detection should allow a reader to not only understand the motivation behind using a particular anomaly detection technique, but also provide a comparative analysis of various techniques. However, the current research has been done in an unstructured fashion, without relying on a unified notion of anomalies, which makes the job of providing a theoretical understanding of the anomaly detection problem very difficult.
There are several promising directions for further research in anomaly detection. For example, in the field of anomaly detection in dynamic networks, it is relatively young and is rapidly growing in popularity, as indicated by the number of papers published in the past five years. Another example could be handling the problem of highly imbalanced data sets especially in credit card fraud detection.
Many techniques discussed in this survey require the entire test data before detecting anomalies. Recently, techniques have been proposed that can operate in an online fashion. Such techniques not only assign an anomaly score to a test instance as it arrives, but also incrementally update the model. Another upcoming area where anomaly detection is finding more and more applicability is in complex systems.