
Abstract
The Internet, e-commerce and telecommunication networks have become a driving force for modern economic growth and development throughout the world. They have also made the underlying network infrastructure the backbone of contemporary life, which enables us to connect to global flows of information, people and goods. Unfortunately, hostile attacks on various network infrastructures by malicious predators have grown significantly over recent years. In this paper, we propose a semi-supervised learning approach, STBoost, which is based on a self-training process and the standard boosting algorithm, for network intrusion detection. The approach has its unique features and can be used with a small set of labeled training data to build up initial models of normal and anomalous network activity behaviors, and then it employs additional unlabeled audit data to further refine the behavior models. We have conducted a number of experiments with the approach on the KDD Cup 99 data set and also compared it with another fuzziness based semi-supervised algorithm and several widely used supervised learning approaches. The experimental results have shown that the proposed semi-supervised approach represents a viable and competitive technique for detecting potential network intrusions.
Introduction
The Internet, e-commerce and telecommunication networks have already become a driving force for modern economic growth and development throughout the world. More people than ever before are using various Internet connected devices to conduct their daily activities in communications, information searching, entertainment and education, and all of these activities are heavily dependent on reliable and secure network connections. Unfortunately, hostile attacks on the underlying network infrastructure by malicious predators have never stopped and in fact, the number of reported attacks has been increased quite significantly. Over the recent years, various network attacks have cost the global economy billions of dollars annually in lost productivity. For instance, the disclosure of business or private financial data to cyber criminals can lead to huge financial loss through Internet banking and other e-commerce services. All network attacks would have the potential for a devastating large-scale network failure, service interruption or the total unavailability of service [1].
To help secure network infrastructure against intentional and potentially malicious threats, various network defense or security systems have been developed and employed. Conventional network security approaches are the mechanisms designed in firewall, authentication tools, and computer servers that monitor, track, and block viruses and other malicious activities. For example, antivirus software is developed and installed in computers and network servers to ensure customer information is not used malevolently. However, as network threats are constantly evolving, using these methods for detecting known attacks is not enough to protect both users and networks. Higher-level software tools are indeed needed and they can help discover a broader range of embedded network intrusions and understand intrusion techniques used by attackers. One approach in this direction is to build intrusion detection systems. Specifically, an intrusion detection system is designed and used to intelligently monitor and analyze network activities such as network traffic and computer usage and to recognize malicious activity patterns, and when such patterns are identified, the system generates alerts to system administrators or security experts and performs some necessary actions to protect the network infrastructure [2].
In this paper, we propose a semi-supervised learning method, named STBoost, for network intrusion detection, and it aims to take advantages of both supervised and unsupervised learning approaches. Specifically, the method uses both labeled and unlabeled training data in an iterative process to progressively and accurately learn normal and anomalous network activity behaviors, respectively, and then applies the learned behavior profiles to new network instances to detect and report any abnormal network events that behave significantly different from the expected normal activity profile.
The rest of the paper is organized as follows. We provide some background and related research work in Section 2. We then present our proposed semi-supervised approach in detail in Section 3. In Section 4, we discuss our experimental setup with a variant of the KDD CUP dataset. Then we provide an empirical analysis of the results and a comparison of the proposed semi-supervised approach with another fuzziness based semi-supervised algorithm [3] and several popularly used and representative supervised learning algorithms. Finally, we offer some concluding remarks in Section 5.
Background and related work
Due to a large and growing number of network intrusions, many organizations have been implementing various software systems to deal with various security breaches. Intrusion detection systems (or IDS) are those that have recently gained a significant amount of interest in the information technology community. An intrusion detection system is a software product that detects and responds to unauthorized use or abnormal activities on computer systems, which may compromise system’s confidentiality, integrity and availability. The primary functions performed by IDS are: (1) monitoring and analyzing user and system activities, (2) accessing the integrity of critical system and data files, (3) recognizing activity patterns reflected known attacks, (4) responding automatically to detected activities, and (5) reporting the outcome of the detection process [4].
Over the past two decades, a number of IDS techniques have been proposed to model network usage behaviors and then use the modeled behaviors to classify new network events as normal or abnormal. There are two major paradigms for designing IDS: misuse detection and anomaly detection. Approaches used for misuse detection, which is also called signature detection, are developed specifically to recognize unique patterns or signatures of known intrusions and to predict and detect subsequent similar attempts. Several supervised machine-learning algorithms such as fuzzy rules [5], neural networks [6], support vector machines [7], genetic programming [8] and decision trees [9] have been used in misuse detection of IDSs during the past two decades. Misuse detection systems are generally capable of detecting abnormal activities quite accurately and therefore they carry a low false positive rate. However, these systems have some drawbacks and cannot detect new types of intrusions. Approaches used for anomaly detection, on the other hand, are designed to profile normal system usage patterns and then to detect possible intrusions based on their deviations from the profiled normal patterns. Anomaly detection systems can potentially detect unknown intrusions but, in comparison to misuse detection systems, they generally carry a higher false positive rate and a lower intrusion detection rate.
The approaches used in anomaly detection can be further categorized as generative or discriminative types [10]. A generative approach builds a model of normal behavior only using normal training data and uses the model to determine new network activities as normal or abnormal, depending upon how well they fit the model. Many generative systems are based on supervised learning algorithms. For instance, association rules [11], neural networks [12], support vector machines [13], nearest neighbors [14] and hidden Markov model [15] have been used for developing generative anomaly detection systems. Such systems have a high dependency on attack-free training data, which, however, may or may not be available in real-world network environments. In addition, normal behavior profiles built by the systems may be no longer accurate or effective in detecting intrusions when the corresponding network environments or services are changed.
A discriminative approach, on the other hand, attempts to learn the distinction between the normal and abnormal behaviors, and for this reason, it requires both normal and abnormal data to be used in training. A number of unsupervised learning algorithms have been proposed in this domain such as [16, 17]. These unsupervised discriminative systems profile normal and abnormal behaviors by using only unlabeled data, which should be readily available in practice. However, it should be noted that the systems assume intrusions are both rare and different from normal activities and consequently they may not be able to detect either attacks that have seemingly legitimate looks or attacks that create a large number of network instances (e.g. TCP SYN-flood). Moreover, the detection rate of unsupervised systems is usually not as high as of those supervised systems that are based on labeled data.
In the last few years, there has been a surging interest in developing semi-supervised learning models in the machine learning community that are capable of learning from both labeled training samples and additional unlabeled data. In particular, the semi-supervised learning paradigm has been successfully used in classification, among a few other areas. Experiments have shown that using both labeled and unlabeled data in an appropriate semi-supervised learning setting can usually help enhance classification accuracy [18]. In the application domain of system intrusion detection, [19] proposed to use two graph based semi-supervised algorithms, namely, Spectral Graph Transducer and Gaussian Fields, and reported that the algorithms achieve higher accuracies in compassion to several supervised approaches such as Naive Bayes, SVM, C4.5 on a small subset of KDD Cup 99 dataset [20]. More recently, a fuzziness based semi-supervised algorithm was suggested by [3] and, using experiments with a variant of KDD Cup 99 dataset, the paper also reported that it outperforms (in terms of accuracy) several similar supervised methods as covered in [19].
In this paper, we propose a semi-supervised approach called STBoost for network intrusion detection and it aims to take advantages of both supervised and unsupervised learning methods. The goals we try to accomplish with the approach are: 1) it can learn to profile normal and abnormal network activities just with a small quantity of labeled samples, augmented by a large amount of available unlabeled data; 2) it carries a high detection rate and a low false positive rate. We describe the approach in detail in the next section.
A semi supervised approach
Like any other semi-supervised approaches, ST-Boost uses both labeled and unlabeled training data for learning normal and abnormal network activity behaviors and then applies the learned behaviors to classify incoming network events. The approach involves an incremental learning or self-training procedure with a base classification algorithm to further refine the behavior profiles. More specifically, given a set of labeled training data of
(the size of
where
where the confidence scores can be expressed as a probability between zero and one. STBoost then adds a portion of the newly labeled data with top confidence scores to the labeled data set
We use the AdaBoost procedure [21] as our base classification algorithm in the semi-supervised learning approach. AdaBoost, or Adaptive Boosting, is a well-known ensemble machine learning algorithm and it can be used in conjunction with other learning algorithms such as decision trees to improve classification performance. The method itself also involves an iterative process that produces a sequence of classifiers or hypotheses and in each step of the process, it builds a classifier that focuses more on the training samples that are misclassified by the previous classifier. This is accomplished by using an adaptive weighting scheme on the training data. Specifically, the boosting procedure takes as input a training dataset, say
and on round
Then, the procedure computes the classification error
and the sample weight update term
which is used to update
and there are no weight changes for the misclassified samples. Once all sample weights are updated, they are normalized and this normalization step effectively increases the weight for misclassified samples and decreases that for correctly classified ones. The process is repeated for a number of times to generates a sequence of classifiers. The final classification output from the procedure is formed by a weighted majority vote of the models
where the weight for the individual model is given by
The STBoost algorithm.
As we mentioned in the previous section, a fuzziness based semi-supervised approach was recently proposed for network intrusion detection [3]. It has two steps in model building. The approach starts with a single layer neural network on the training data, and then applies the network to another unlabeled dataset to obtain their individual fuzzy membership vectors and predicted class labels. Then, using a fuzziness measure based on the entropy over all classes, it categorizes all newly labeled data into one of the low-, mid- or high-fuzziness groups. Finally, the approach re-trains the network by adding those samples with low- or high-fuzziness to the training data. As a semi-supervised scheme, it would be easy to understand that the added samples with low fuzziness should generally carry a low risk to be misclassified and hence, augmenting them into the training data may help strengthen the final learning model. However, this proposition may not be applicable to the samples with high-fuzziness and unfortunately, the authors did not describe or explain in their paper why the samples with high fuzziness should also be included in training.
This approach shares some general ideas with our proposed one but they are still two different semi-supervised learning algorithms. Specifically, both approaches use labeled and unlabeled data to build classification models and apply either fuzziness or confidence score to select more unlabeled data for training. However, the approach from [3] adds more data in training just directly from the initial model and consequently, its overall efficacy may very well depend on the quality of the initial model, which is formed by a single layer neural network. In general, supervised learning algorithms require a sufficient amount of training data in order to achieve decent classification performance. The approach proposed in this paper, however, involves an incremental learning process to add more (unlabeled) data for training. As a result of this, it requires only a small number of labeled samples to train the initial model and can in fact work well when the size of labeled data as few as 200. In a typical real-world network environment, labeled training data can be expensive to obtain and the quantity of such data can also be very limited in supply. A direct performance comparison between these two approaches with a variant KDD Cup 99 data set is provided in the next section.
It should also be pointed out that STBoost has another advantage over other semi-supervised algorithms. Network intrusion detection is generally a highly unbalanced classification problem where an absolute majority of training data belongs to the negative or normal class while a small minority of data belongs to the positive or abnormal class. The unbalanced class distributions in the training data can make a typical classification method to heavily rely on the samples of the majority class. Consequently, it can produce inaccurate predictions of the minority or abnormal class and have an extremely low false positive rate. AdaBoost can actually help alleviate this imbalance data distribution problem, which is an important reason for why we choose it as our base learning algorithm. As aforementioned, AdaBoost adaptively adjusts weight to the training data, depending on how difficult the data can be learned by the system and therefore, if the positive or abnormal class cannot be learned very successfully at early iterations, the system automatically adds more weight to the corresponding training samples and tries to learn them correctly at subsequent iterations. With an adequate integration, AdaBoost has the potential to help deliver good classification results for the network intrusion detection problem.
In this section, we discuss the data set used in our experiments, the experiment setup and results as well as empirical analyses.
Dataset
As one of the very few publically accessible network intrusion datasets, the KDD Cup 99 dataset [15] has been extensively used as a benchmark for analyzing and evaluating IDSs built by various pattern recognition and machine learning algorithms. However, there are some inherent problems with the KDD Cup dataset that have been reported in literature [22]. One of the primary problems associated with the dataset is that it contains a large portion of duplicated records and in fact, it has about 78% and 75% duplicated records in its training and testing set, respectively. These extensively duplicated records can cause learning models to focus more on those frequent records and as a result of this, for instance, the overall intrusion detection performance of a learning model can be heavily influenced by its detection on one or multiple frequent testing instances. In order to address this and other issues associated with the dataset, a modified variant, named NSL-KDD, was proposed [22]. The modified dataset removes all duplicated records in the original KDD CUP and in addition, by partitioning the remaining records into five groups that are based on their numbers of correctly predicted by several commonly used machine learning algorithms, it constructs the new (and also more challenging) dataset by randomly sampling instances from the groups in such a way that the number of records selected from each group is inversely proportional to the percentage of records in the original groups. The NSL-KDD dataset was used in our experiments.
Experiment setup
The NSL-KDD training dataset has a total of 125,973 records with 41 features, and among them, 67,343 records are labeled as normal activity and 58,630 records as intrusion. For our experiments, we performed a number of preprocessing steps with the dataset. More specifically, we first took several small random samples from the dataset with the sizes ranging from 200 and 500 and then examined the distributions on values of all its categorical features. Note that NSL-KDD, which is different from the original KDD Cup, contains only distinct records. We found that a number of its categorical features contain none or very few distinct values and therefore, they may carry either no or very limited value for modeling and predicting network activity behaviors. For this reason, we eliminated five features, namely land, urgent, num_shells, num_outbounds_cmds, and is_host_login from the dataset. In addition, from the remaining categorical features, we also found that some particular categories of the three features, num_failed_login, su_attempted and num_access_files, have only very few values in the samples. We cleaned this by removing a small number of the records from the set that correspond to these category values. The preprocessed dataset has 125,878 records with 36 features.
We used the preprocessed NSL-KDD training data-set for building a semi-supervised learning model STBoost to profile normal and abnormal network activity behaviors and then for analyzing and evaluating prediction performance of the model. In our experiments, we first randomly sampled a small set from NSL-KDD as the labeled dataset to build the initial classifier in our semi-supervised approach. Then, we randomly selected another set from the remaining records as additional unlabeled samples, which has the size that is ten times of the labeled one, to augment the labeled data in the iterative learning process and to further refine network behavior profiles. Finally, we randomly sampled 10,000 from the rest of unselected records to form a set of testing data. We repeated this data selection process ten times and then used averaged metrics to evaluate classification or intrusion detection performance.
As we have discussed earlier, the number of intrusions occurred to a computer network is typically significantly less than that of normal network events. Therefore, in order to simulate a real-world environment, we intentionally formed our testing data with an unbalanced ratio between normal and abnormal records and specifically, the dataset has a 10% of the records representing various attacks and the rest of records representing normal activities. To accommodate this significant imbalance between the classes in the testing data, some adjustments to the learning process, in particular to the training data, should be helpful.
Just like many other imbalance classification problems, if normal records in the training data substantially outnumber abnormal records, then this disparity in counts can cause learning algorithms to be biased towards the more frequent or the normal class and subsequently, it can make a relatively large number of misclassification errors on the less frequent or the abnormal class. One of the most popularly used solutions to work with data having a skewed class distribution is to create a more balanced training dataset between the classes by either under-sampling the majority class or over-sampling the minority class. This approach generally helps reduce the effect of skewed class distribution in the learning process and can produce a more accurate classifier for both the majority and the minority classes. However, this improvement may or may not be able to carry over to the performance of the classifier on new instances and in particular, when there is a substantial disproportion between the training and testing data in terms of their class distributions. In our case, when we use a balanced network training dataset to build a classifier and then apply it to new instances that are quite skewed (in other words, they have significantly more normal instances than abnormal ones), the classifier can misclassify more normal instances than abnormal ones and hence have a high false positive rate.
To find a practically working solution to this problem, we have done a number of extensive experiments with multiple datasets with different compositions of their training and testing data. We found that, given a testing dataset with skewed class distribution, using a training dataset that has a generally proportional but less distinctive class distribution can help build a classifier that achieves a good balance between both classes in terms of classification performance. For our experiments, we chose the class distribution with 36.5% of attack records and 63.5% of normal records when selecting a labeled training dataset to build the initial classifier for STBoost.
Results of STBoost
There are a number of performance metrics that have been proposed for general classification systems. Since intrusion detection is effectively an imbalance classification problem where the training records representing normal activities are typically substantially outnumber the training records representing various network attacks, the classical accuracy measurement is clearly not adequate for evaluating IDSs. Among very few alternatives, intrusion detection rate and false positive rate have been popularly used in the computer security community to gauge IDS performance [17]. For a given testing or deployment dataset, the detection rate specifies the percentage of known intrusions that the system is able to detect whereas the false positive rate represents the percentage of normal events that are misclassified by the system as malicious.
Figure 2 shows the detection rates of STBoost when the training is done with small labeled data sets, augmented by additional unlabeled data sets and Fig. 3 shows the false positive rates of STBoost obtained from the same settings. The size for the labeled data varies from 200 to 600 with an increment of 100 while the size for the unlabeled data is ten times of the corresponding labeled ones, which ranges from 2,000 to 6,000. For instance, the horizontal label of 200/2000 in Fig. 2 (or in Fig. 3) indicates that 200 labeled and 2,000 unlabeled samples are used in training and they are all selected randomly and independently. In addition, the size of the testing data is fixed at 10,000 and the testing samples are also selected randomly and independently. The sample selection process is repeated for ten times and the performance metrics in both figures are the averaged values over these runs.
Detection rates of STBoost with different labeled and unlabeled data sizes.
False positive rates of STBoost with different labeled and unlabeled data sizes.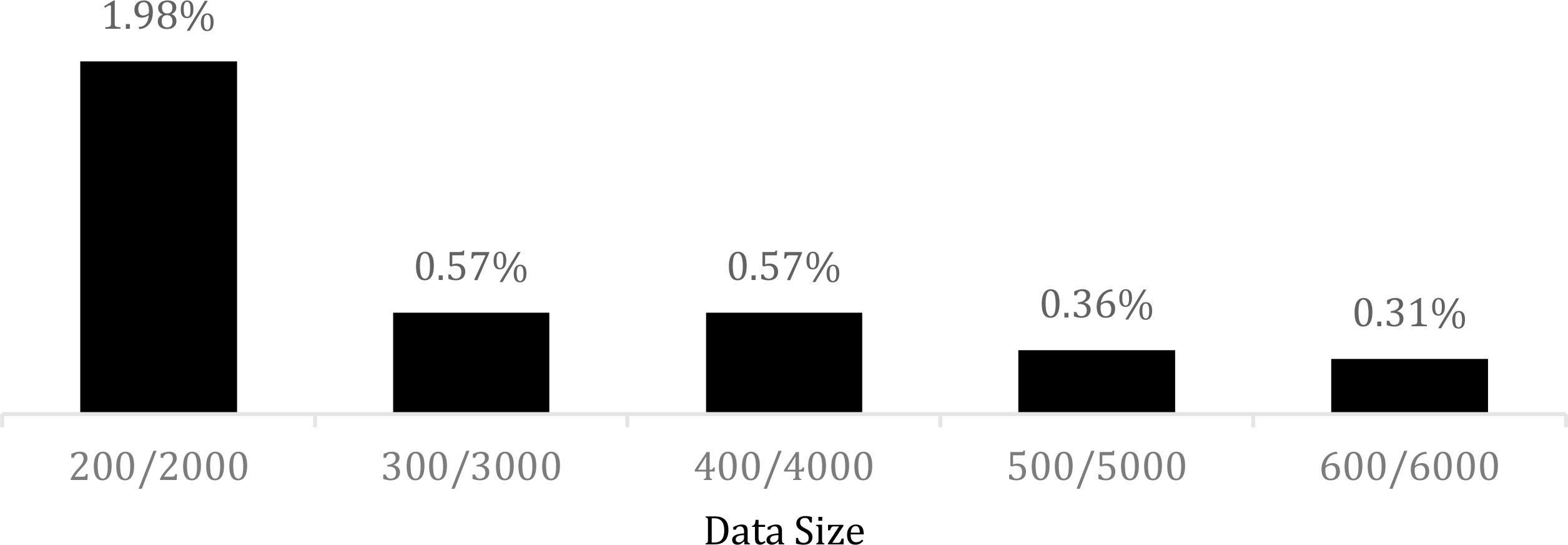
From Figs 2 and 3, it can be seen that STBoost can be very effective for detecting various network attacks. Using additional unlabeled network data to boost the model building, the proposed semi-supervised approach can be particularly successful in achieving in an accurate profile of normal activities, which is reflected by very low false positive rates, while maintaining very good performance in intrusion detection. For instance, when using only 300 labeled training samples to build the initial classifier, STBoost delivers both an impressive false positive rate (0.57%) and a decent intrusion detection rate (96.49%). In addition, the semi-supervised approach demonstrates a sharp reduction in false positive rate when the size of the labeled data changes from 200 to 300 and then a slow decline as the size further increases. For the detection rate, on the other hand, STBoost displays a relatively steady up trend for the size between 200 and 500 and then has a very moderate increase when the size becomes 600.
In order to demonstrate the competitive effectiveness of STBoost, we selected several popularly used supervised learning algorithms, which also represent different learning paradigms, and then compared the performance obtained by these algorithms with that we received from STBoost. These algorithms are: multilayer perceptron neural networks [23], support vector machines (SVM) [24], decision trees [25] and random forest [26]. We also used the NSL-KDD dataset in this comparative experiment. As described in Section 4.2, we first randomly selected a labeled sample set with a size ranging from 200 to 600 for all learning algorithms considered in the experiment and then an augmented unlabeled sample set for STBoost, and finally we randomly selected a testing data set of 10,000 samples for all algorithms. Figures 4 and 5 show the averaged detection rates and false positive rates of all algorithms obtained over ten independent runs, respectively (where we use MP for multilayer perceptron, SVM for support vector machines, DT for decision trees, RF for random forest).
Detection rates of STBoost and several well-known supervised algorithms.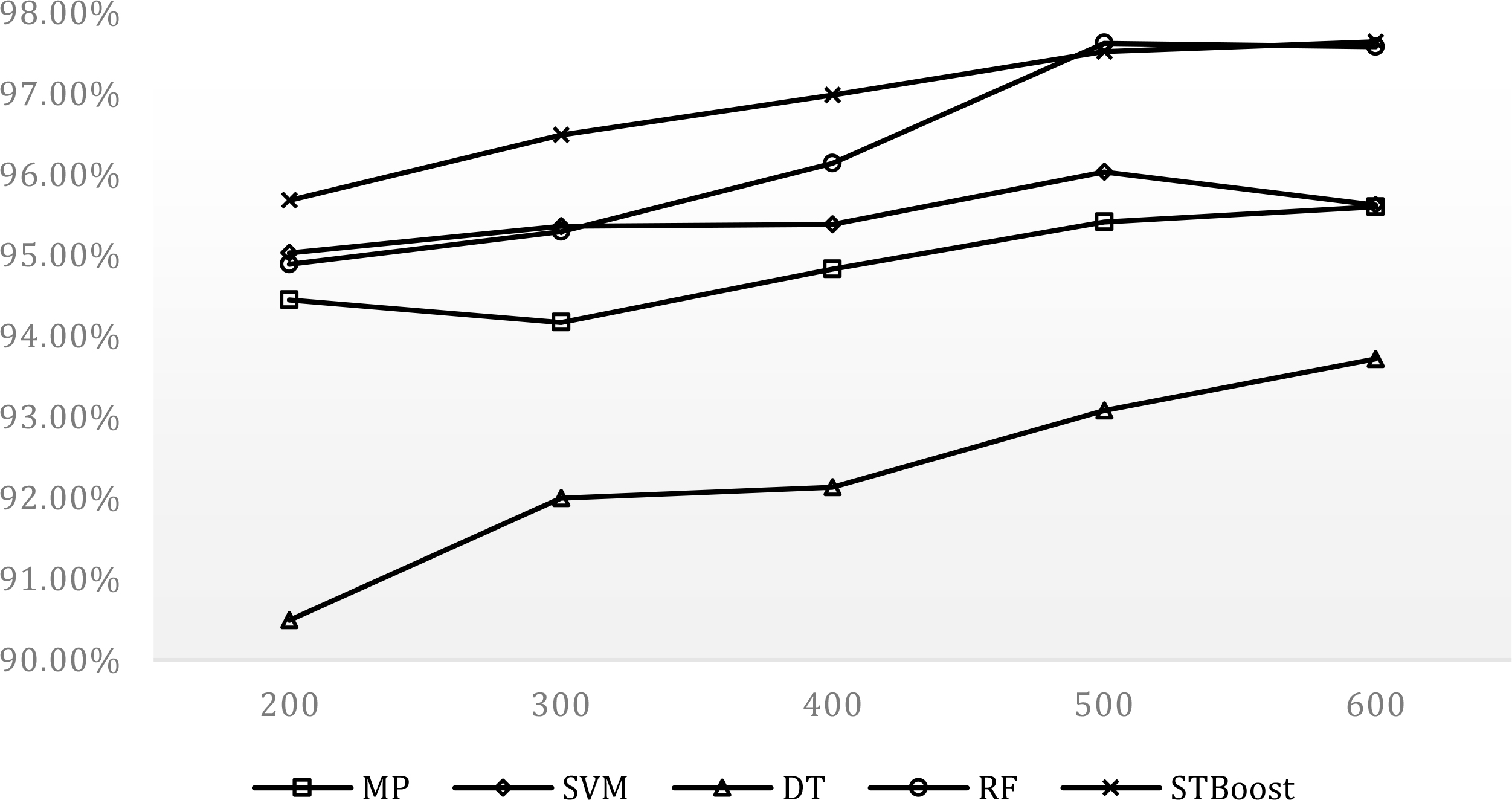
False positive rates of STBoost and several well-known supervised algorithms.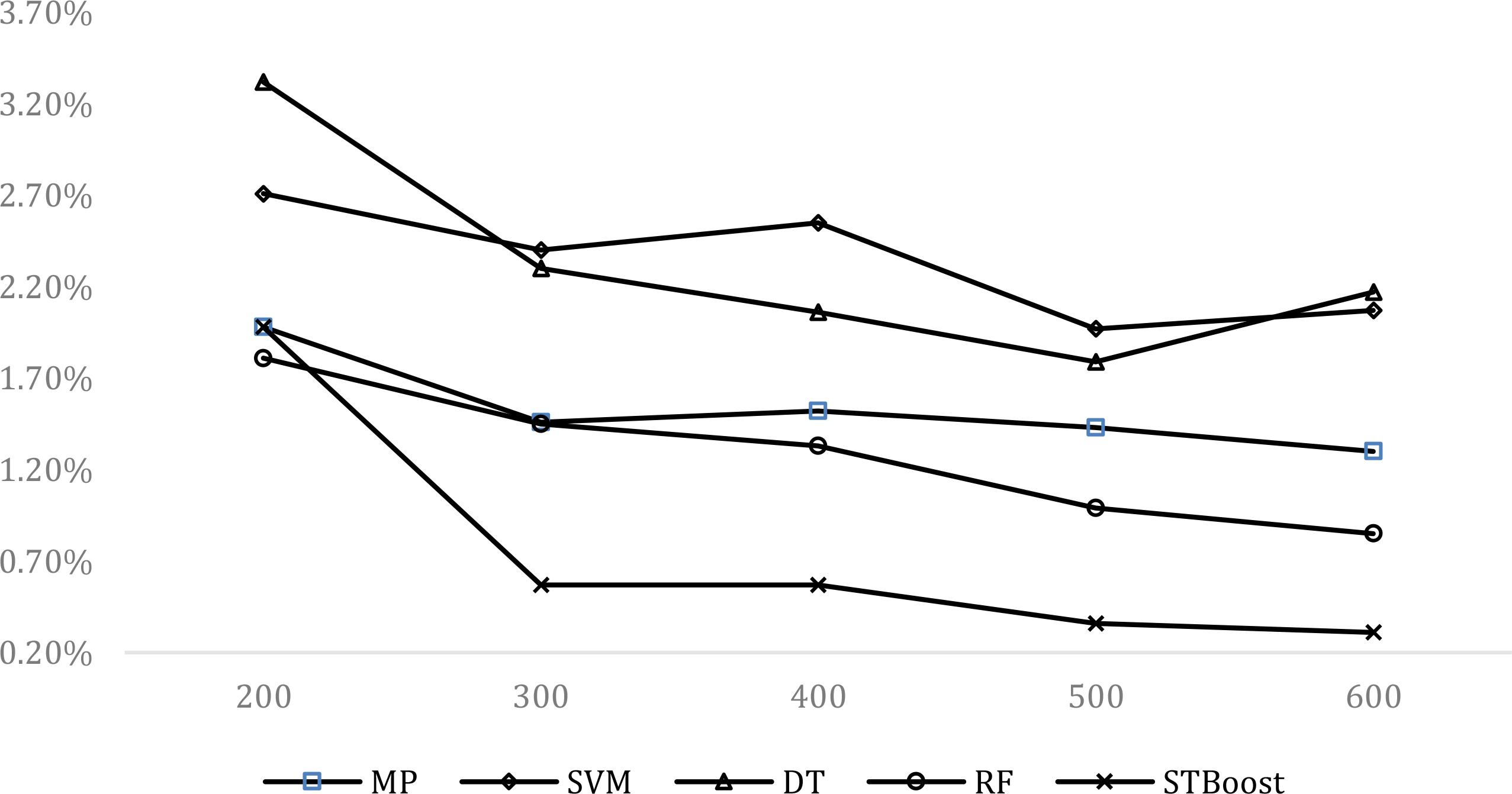
From both Figs 4 and 5, we can provide a few remarks. First, the experimental results on both detection rate and false positive rate indicate that the proposed semi-supervised learning approach can be very competitive in detecting various network intrusions. In fact, for the most cases that are constructed with varying sizes of labeled data, STBoost outperforms all supervised learning algorithms selected for the experiment. In particular, it should be pointed out that STBoost can be much more superior in achieving a low false positive rate than the supervised counterparts in the comparison. For instance, when we use only 300 labeled samples in training, it delivers a false positive rate that is at least 2.5 times lower than all four supervised algorithms.
Second, in any real-world network environments, the occurrences of regular activities should significantly outnumber those of network intrusions and therefore the amount of accumulated labeled intrusion records should be even scarcer. This limited quantity of labeled positive samples can make most supervised learning methods very difficult to model network intrusions accurately. A semi-supervised approach offers an alternative or indirect way to address the problem. It generally uses, in addition to the labeled samples, supplementary unlabeled data that can be easily collected and accessible in practice. Among the unlabeled data, a vast majority of them are normal network records and they can be used to further improve the system profile of normal network activity. Therefore, as a direct positive outcome, they can help reduce the system’s false positive rate. On the other hand, an increased accuracy of the normal profile should also help detect more network intrusions as a by-product.
Average rankings of the algorithms based on detection rate.
Average rankings of the algorithms based on false positive rate.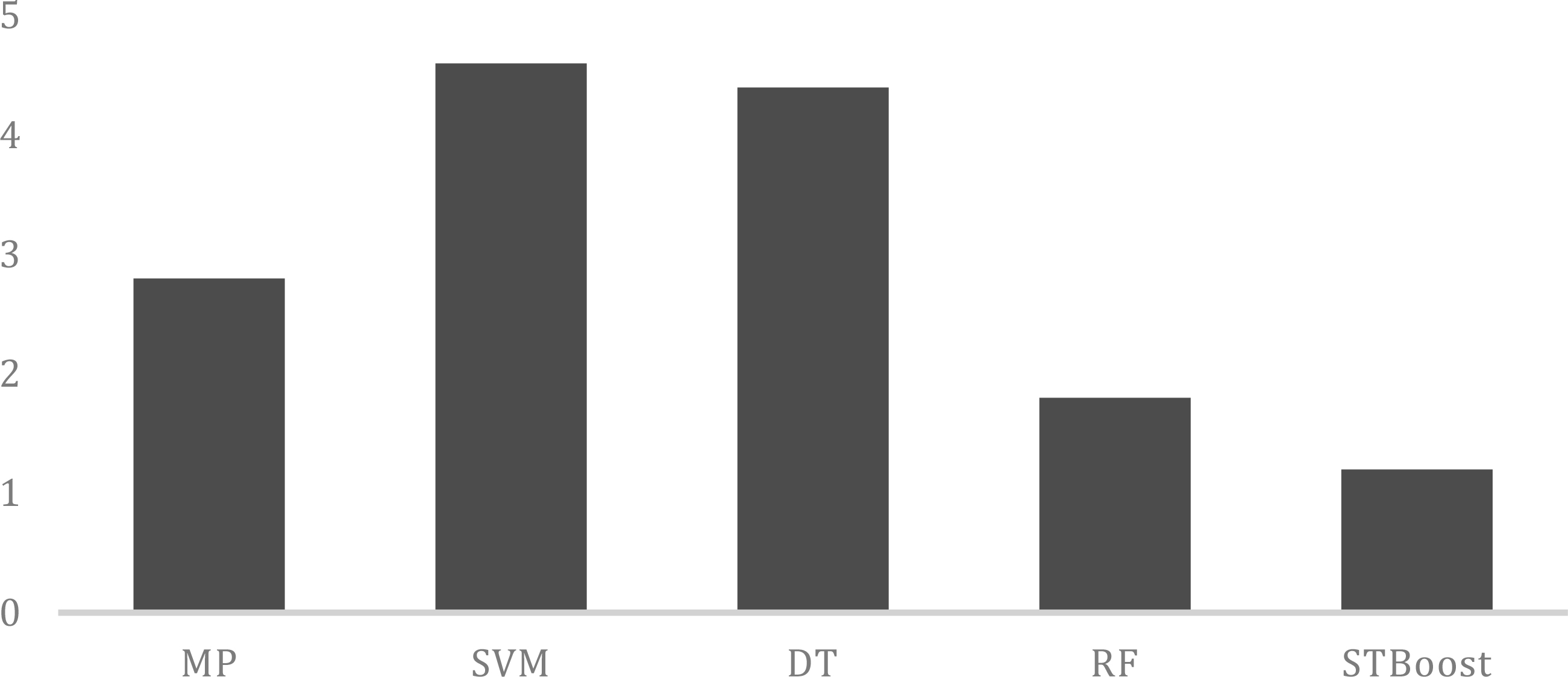
Finally, in order to have a quick view of how good an algorithm is with respect to the rest in the comparison, we also calculated the average rankings of the algorithms based on a performance metric. Specifically, for each training data setting, we assign the rank 1 to the best-performed algorithm and the rank 2 to the next followed-up algorithm, and so on. The final average ranking of an algorithm is computed by the mean value of its rankings over all data settings used in the experiment [27]. Figure 6 shows the average rankings of the algorithms based on detection rate. Figure 7 shows the similar rankings based on false positive rate. It can be observed from both figures that, as a well-known ensemble approach, random forest is a clear winner among four supervised schemes, which is somewhat expected, whereas decision trees is the weakest performer when we consider both detection rate and false positive rate. It can also be noted that, in comparison with others, support vector machines provide a quite high detection rate and hence generate highly accurate profiles of normal network activities but fail to attain a competitively low false positive rate or very accurate profiles of intrusive network events.
Accuracy comparison between STBoost and several other algorithms from [3] when 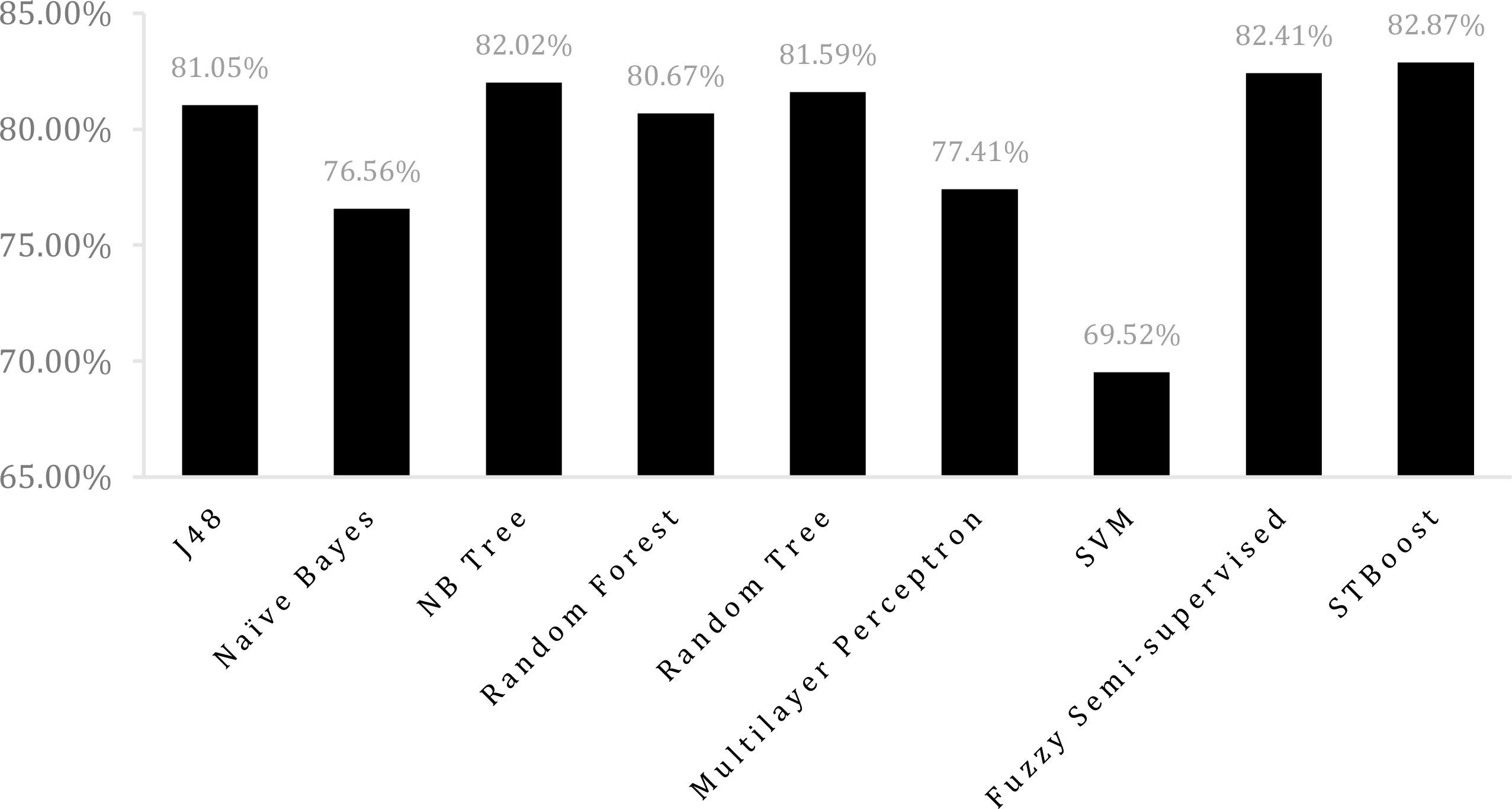
Accuracy comparison between STBoost and several other algorithms from [3] when 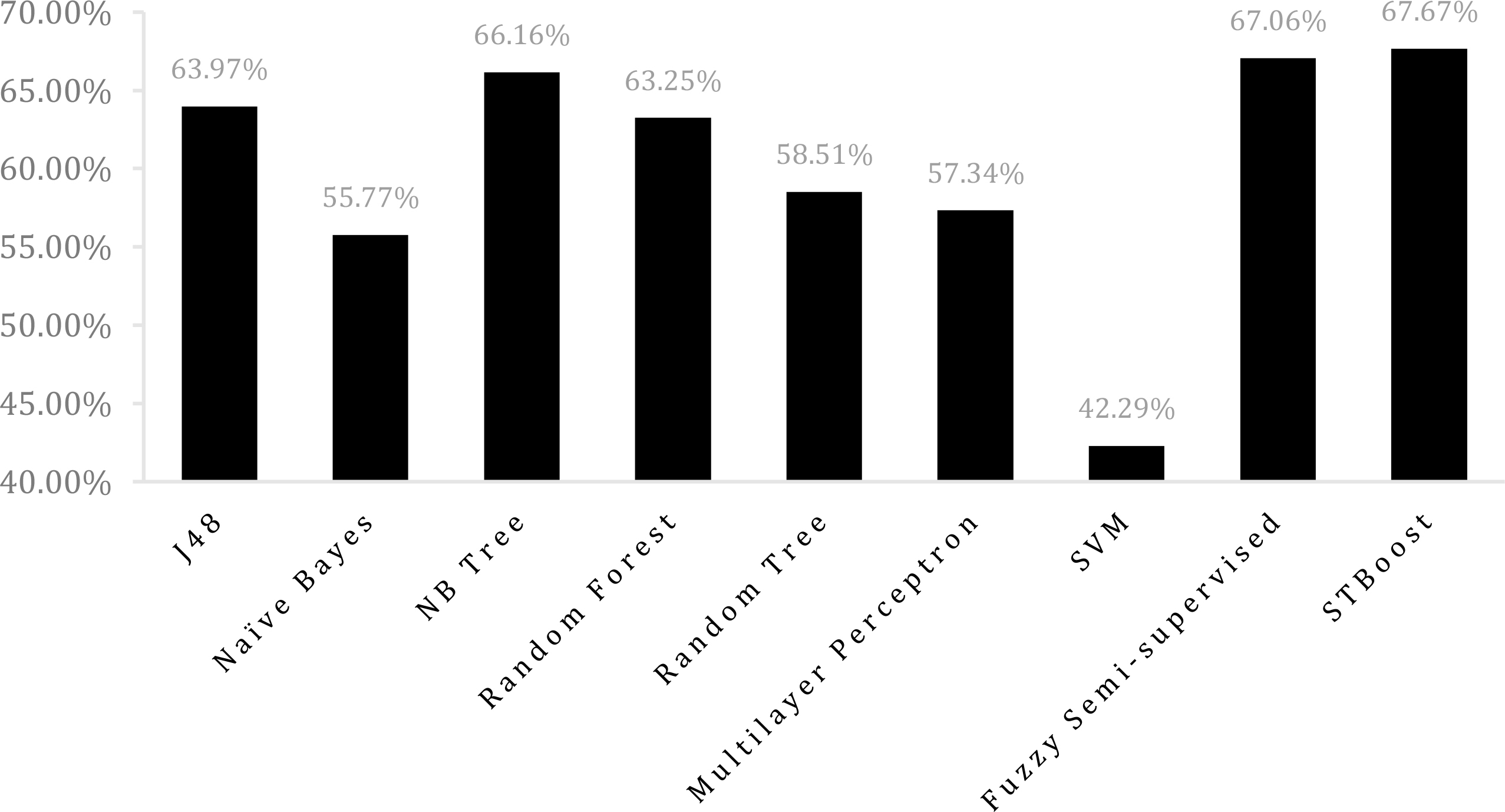
In this subsection, we provide a direct comparison between STBoost and a recently proposed fuzziness based semi-supervised algorithm [3]. There are a few points that need to be noted about the NSL-KDD dataset and performance measurement in intrusion detection. First, as we discussed in Section 4.1, NSL-KDD is an improved variant of the original KDD Cup 99 dataset where all duplicated samples being removed. When using this revised dataset for intrusion detection experiments, one still needs to be careful in sample selection, in particular for designing comparative experiments (as in [3]) to demonstrate one algorithm outperforms others. More specifically, as an example, the testing set
In order to have a direct comparison with the algorithm from [3], we used the same training and testing dataset, respectively, from NSL-KDD. Specifically, we first randomly selected a 10% subset from KDDTrain_20Percent for training and used the rest as additional unlabeled data samples. For the experiment, we used dummy variables to deal with categorical attributes. We then tested the model on both
From the accuracy results shown in Figs 8 and 9, we can see that STBoost delivers better classification accuracies than all other algorithms [3] in comparison when both
We have proposed a semi-supervised learning approach STBoost for network intrusion detection. It is based on a self-training scheme and the standard AdaBoost learning algorithm. STBoost requires a small set of labeled training data and utilizes a large amount of additional unlabeled data in an iterative learning process. The approach aims to use both labeled and unlabeled data in an integrated manner to achieve good performance in detecting intrusions. The methodology behind the approach is practically meaningful as labeled data are usually available with a very limited quantify and unlabeled network audit data are abundant in supply. The experiments with a variant of the well-known KDD Cup 99 dataset as well as a comparison with another fuzziness based semi-supervised approach and several popularly used supervised learning algorithms have shown that the proposed semi-supervised approach represents a viable and competitive method in detecting network intrusions and in particular, it is extremely effective in achieving a low false positive rate.
We would like to continue and expand this network intrusion detection research work in several directions. One direction is to further investigate possible optimal parameter settings with STBoost. For instance, we would like to find out what percentage of incrementally classified unlabeled data should be used in iterations to augment the learning process and what impact it may have on the system’s overall classification performance. Another area in which we plan to explore is the use or development of other potentially suitable base learning algorithms. In addition, we would like to conduct a thorough comparative study in intrusion detection effectiveness that would include STBoost and several other relevant IDS approaches that have been proposed in literature.