
Abstract
Uniform Resource Location (URL) is the network unified resource location system that specifies the location and access method of resources on the Internet. At present, malicious URL has become one of the main means of network attack. How to detect malicious URL timely and accurately has become an engaging research topic. The recent proposed deep learning-based detection models can achieve high accuracy in simulations, but several problems are exposed when they are used in real applications. These models need a balanced labeled dataset for training, while collecting large numbers of the latest labeled URL samples is difficult due to the rapid generation of URL in the real application environment. In addition, in most randomly collected datasets, the number of benign URL samples and malicious URL samples is extremely unbalanced, as malicious URL samples are often rare. This paper proposes a semi-supervised learning malicious URL detection method based on generative adversarial network (GAN) to solve the above two problems. By utilizing the unlabeled URLs for model training in a semi-supervised way, the requirement of large numbers of labeled samples is weakened. And the imbalance problem can be relieved with the synthetic malicious URL generated by adversarial learning. Experimental results show that the proposed method outperforms the classic SVM and LSTM based methods. Specially, the proposed method can obtain high accuracy with insufficient labeled samples and unbalanced dataset. e.g., the proposed method can achieve 87.8% /91.9% detection accuracy when the number of labeled samples is reduced to 20% /40% of that of conventional methods.
Introduction
Diversified development of network resources has brought great convenience for people’s daily life. However, the increase in the number and types of web sites has also led to many network security problems, such as viruses and malicious URLs. This paper focuses on the detection of malicious URLs. A malicious URL is a link to illegal webpage, which will try to lure users to visit a malicious webpage by clicking a link, and the malicious codes in those webpages would lead to malware installation, personal information leak, Internet fraud, etc [1]. Phishing URL is one typical kind of malicious URLs. According to the Phishing Activity Trends Report [2] published by the Anti-Phishing Working Group (APWG), the total numbers of phishing sites detected by APWG in the first and second quarters of 2019 were 180,768 and 182,465, respectively. In recent years, the number of phishing URLs detected continued to grow and caused substantial economic loss. According to Gartner Survey, phishing attacks cost 3.5 million users $3.2 billion every year. Therefore, finding an effective malicious URL detection method to maintain network security is of great importance.
In general, there are two main problems in malicious URL detection task: First, the number of malicious URLs and benign URLs is unbalanced. Malicious URLs are more difficult to collect than benign URLs, and their percentage is usually very small [3]. The imbalance between positive samples and negative samples reduces the effectiveness of the detection model [4, 5], while many existing research methods often ignore this. Second, obtaining sufficient labeled URL training samples is difficult. Although there are many URL samples exist in the Internet, the label information is not always available and labeling samples manually is time consuming and expensive. Moreover, in the actual application environment, URL generation is very fast, and obtaining a sufficient number of the latest labeled URL samples is a great challenge. Therefore, how to train a detection model with insufficient labeled samples while avoiding the decline of accuracy is of great importance.
In this paper, a semi-supervised learning approach for malicious URLs detection based on generative adversarial network (GAN) [6] is proposed to solve the two problems above. Semi-supervised learning enables the full use of unlabeled samples, solving the problems of insufficient labeled samples and the GAN model enables the generating of synthetic samples, solving the problems of class imbalance. In summary, the main contribution of this paper is as follows:
1) The proposed method can reduce the impact of malicious and benign URL imbalance because when the unbalanced dataset is used to train the discriminator, the generator continuously generates synthetic samples and increase the number of insufficient malicious samples.
2) The proposed method only needs a few labeled URL samples to train the classification model but still achieves higher accuracy than that of existing methods.
3) The proposed approach can automatically extract URL features without the need to extract features artificially from data sets for training models, which reduces the workload compared with traditional methods and the unacceptable effect of improper feature selection.
The remainder of this paper is organized as follows. Section 2 gives a brief review on existing malicious URL detection methods. Section 3 is devoted to the detailed description of the proposed methods. The experimental results and analysis are provided in Section 4. Section 5 concludes the paper.
Related work
This section describes the current common methods for detecting malicious URLs, and summarizes their advantages and disadvantages in actual detection.
Blacklist-based method
The blacklist-based method is the most traditional and direct method to detect malicious URL [7]. When using the blacklist-based method to determine whether a URL is malicious or not, the URL is searched in the blacklist first, and the malicious URL will be identified and blocked if it is in the blacklist already. The blacklist recognition method is very simple and has a high accuracy rate. This method can easily filter malicious URLs from the blacklist database. Although blacklist technology is one of the most commonly used methods in many interception systems such as Google Safebrowsing, it still has many disadvantages. The blacklist-based method cannot intercept malicious URLs outside the database. Therefore, blacklist-based method requires adding all known malicious URLs to the database. However, new malicious URLs are produced frequently every day, and the blacklist database cannot be completely exhaustive. Consequently, only relying on the blacklist-based method will miss intercepting a large amount of newly generated malicious URLs. Moreover, as the blacklist database grows, the time to query the database also increases [8].
Content-based method
The content-based methods use webpage contents to detect whether the URL is normal or malicious. This method first extracts features from web content, including HTML document, Javascript code and images contained within the webpage. The extracted features are then used as the basis for malicious URL detection [9, 10]. The content-based method has two issues: The first one is the time-consuming problems due to the analysis of the source code and content of the entire webpage. The second one is the low efficiency problem due to the fact that the phishing malicious webpage may have the same contents as the original webpage. Moreover, the extracted features may be inaccurate. All of these limitations reduce the reliability [11] of the content-based malicious URL detection method.
Machine-learning-based method
In recent years, machine learning has become one of the engaging topics in current research. Different kinds of machine learning-based approaches have been used to detect malicious URLs and have achieved good results. Huang et al. [12] proposed a phishing URL detection method based on support vector machine (SVM), and achieved good detection effect on data set PhishTank. However, the training speed of SVM method will be reduced due to high-dimensional features. In [13], the authors proposed a method for titanium alloys classification based on the combined use of Wiener Polynomial and SVM to reduce the training time. Random forest (RF) [14] classifier is used to detect malicious URLs and is combined with other classifiers to construct a strong classifier for better classification performance [15]. A new non-iterative neural-like structure based on the Geometric Transformations Model [16] is designed, which is capable of high-speed training and solving large-dimensional tasks. Izonin et al. [17] used non-iterative approaches based on a Successive Geometric Transformations Model (SGTM) to solve the multiple regression task. Bahnsen et al. [18] proposed an active URL detection system based on LSTM, which uses URLs directly as input of the machine learning models to detect malicious URLs. Compared with the method that rely on expert experience to extract features, the LSTM method can achieve a good classification accuracy without manually extracting features.
In order to solve the problem of insufficient labeled samples in malicious URL detection, {many scholars pointed out that unlabeled samples can also be used, related works include Positive and Unlabeled (PU) learning [19, 20] and Semi-supervised learning [21–23]. The current semi-supervised learning methods for malicious URL detection often use labeled samples to train the classifier first, then the unlabeled samples are tagged by the trained classifier and reused as labeled samples to train the classifier [24]. Without directly using the unlabeled URL itself, the unlabeled samples with an unreliable label still cannot solve the imbalance issue. To achieve better detection accuracy, many improved versions of semi-supervised learning are proposed, such as CoForest [25], S3VM [26] and Self-trained rotation forest algorithm [27]. A comprehensive review of semi-supervised learning method can be refer to [28]. .
Preliminaries and the proposed approach
In this section, the pre-processing of the URL data is first introduced. Then the structure and principle of GAN model are discussed. Finally, the semi-supervised learning theory is introduced into the field of malicious URL detection, and the semi-supervised learning approach is proposed for malicious URL detection based on GAN.
Data preprocessing
Different URL samples have different characteristics. Before input into the deep learning training model, the URL samples and their labels need to be preprocessed uniformly to obtain a unified representation. URL samples are first segmented into character because Chinese and several abbreviations often appear in the URLs, and using character-level feature [29, 30] is more applicable. According to one-hot coding, the positive URL is labeled as [1, 0], and the malicious URL is labeled as [0, 1].
As shown in Figure 1, a URL is mainly composed of protocol, hostname, port, path and other parts. Before splitting the URL sample into characters, the unnecessary port and the inconsequential protocol part are discarded. Second, a vocabulary that contains common characters in all URLs is built, which contains numbers 0-9, the uppercase and lowercase letters “-Z”, “a-z”, and special characters such as “/”, “.”, “_”, “?”, “@”, “% ”. In this paper, the built vocabulary has 94 characters. Each character in the URL is encoded as a 94-dimensional vector by one-hot encoding, and all the URLs are clipped into 200 characters for easy processing. The excess part is discarded for URLs longer than 200, and NULL is used for padding URLs shorter than 200. Through the above steps, each URL is converted into a matrix with a dimension of 200 × 94. Converting URL samples into ont-hot coding is shown in Figure 2.
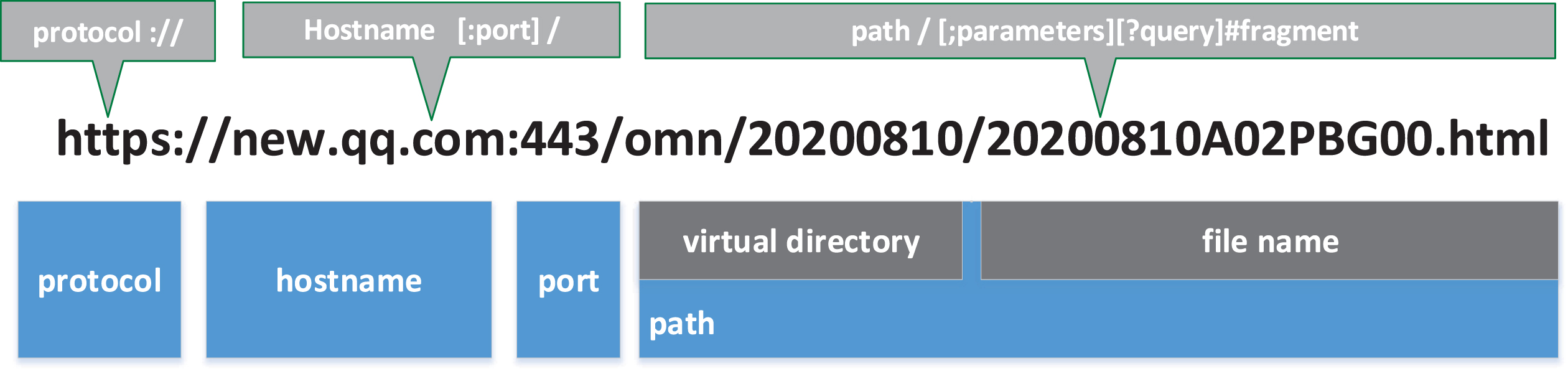
Structure of the URL.

Convert the URL sample to a one-hot encoding.
In [6], Goodfellow et al. proposed a deep learning model called GAN, which is now widely used in computer vision, natural language processing and audio processing. At present, GAN is mainly used to generate images [31, 32], but it also has great application potential in generating other kinds of data [33]. The GAN theory was inspired by the adversarial training game [34] between two network parties. The structure of the GAN model consists of two parts, namely, generator G and discriminator D. The generator is used to synthesize a fake sample from a random noise vector z, and the discriminator is used to distinguish whether the input is a real sample or a fake one. During the joint training of the generator and the discriminator, the generator generates samples that are real enough to deceive the discriminator, and the discriminator tries not to be deceived and to distinguish the synthesized samples from the real samples. Finally, these two models reach a Nash equilibrium, the generator generates synthesized samples that are very similar to the original ones and the discriminator can hardly distinguish them.
The GAN model is trained under the min-max rule according to the following loss function:
This paper introduces GAN into the field of malicious URL detection, and proposes a semi-supervised learning malicious URLs detection approach based on the GAN framework, which makes full use of two characteristics of the GAN model. First, GAN is an unsupervised learning model, which can make full use of unlabeled data to train the generator and the discriminator through adversarial training. Second, during the training of the GAN model, the generator in GAN can continuously synthesize samples and increase the number of rare samples. These two characteristics make GAN suitable for malicious URL detection since the malicious URL detection has the problem of insufficient labeled samples and unbalance dataset, whereas the GAN model can perfectly solve them. Figure 3 shows that the proposed GAN-based malicious URL detection model includes generator G and discriminator D.
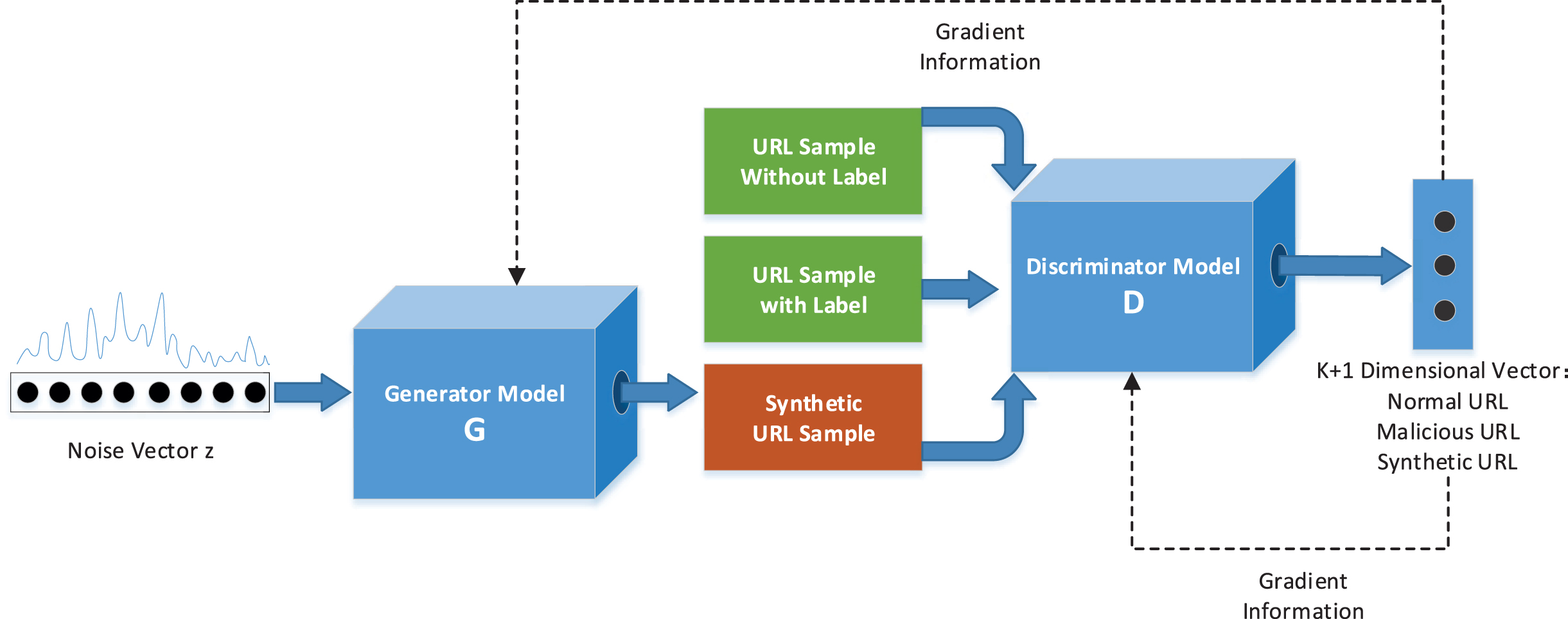
Structure of the detection model and the whole process.
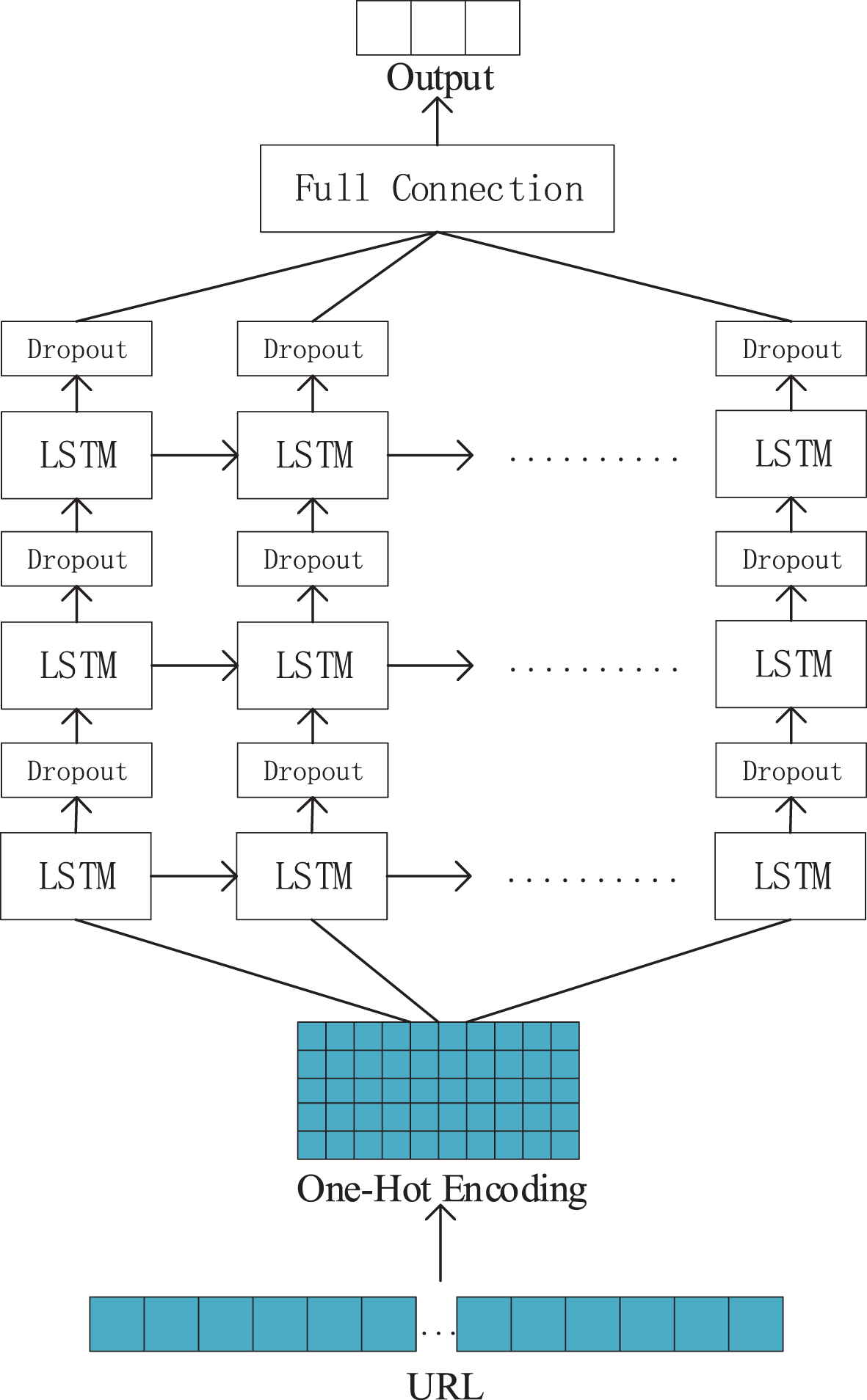
The network structure of the discriminator.
The network structure of the discriminator is shown in Figure 4. It includes three LSTM layers, because RNNs are suitable for processing sequence data. An original URL sample is first converted to a one-hot encoding and then input to the network. The characters converted to vectors are input into LSTM layer one by one, and the time series features between them are extracted through LSTM layer. Each LSTM layer is followed by a dropout layer to avoid over-fitting. The output from the network’s final dropout layer is entered into a full connected layer for classification.
The input of the discriminator network includes three kinds of data: (1) labeled URL sample x, (2) unlabeled URL sample
For the supervised learning loss part, the labeled samples from real dataset are used to train the discriminator. The discriminator needs to distinguish specific categories of the real samples. The loss function L
D
-
sup
is as follows:
The input of the generator model is vector of noise z, which obeys a Gaussian distribution P z and the output is the synthetic samples that matches the distribution of real samples. The network contains three full connection layers as hidden layer and each full connection layer followed by a dropout layer. During the semi-supervised training of the discriminator model, half of the training samples are synthesized by the generator. The generator’s loss function L G consists of two parts. The first part Lfake_unsup is from the training of GAN as shown in Equation (6), and the other part Lfeature_matching is from the feature matching.
In the training of feature matching, we followed the idea of Bad GAN theory [35] that the distribution of the synthetic samples is better not be completely matched to the real samples. A perfect generator can generate a perfect distribution as real data, but the generalization ability of discriminator is limited during semi-supervised learning [36]. Instead, though a bad generator may not synthesize a distribution that exactly matches the distribution of the real sample, it can generate samples that close to the boundary , thus force the split plane to have a large margin to get better generalization ability. How a perfect generator and a bad generator influence the decision boundaries of the classification model is shown in Figure 5. The blue and red dots represent positive and negative samples respectively and the green dots represent the synthetic samples, specifically, the green dots along the decision boundary of perfect generator is synthesized by bad generator.
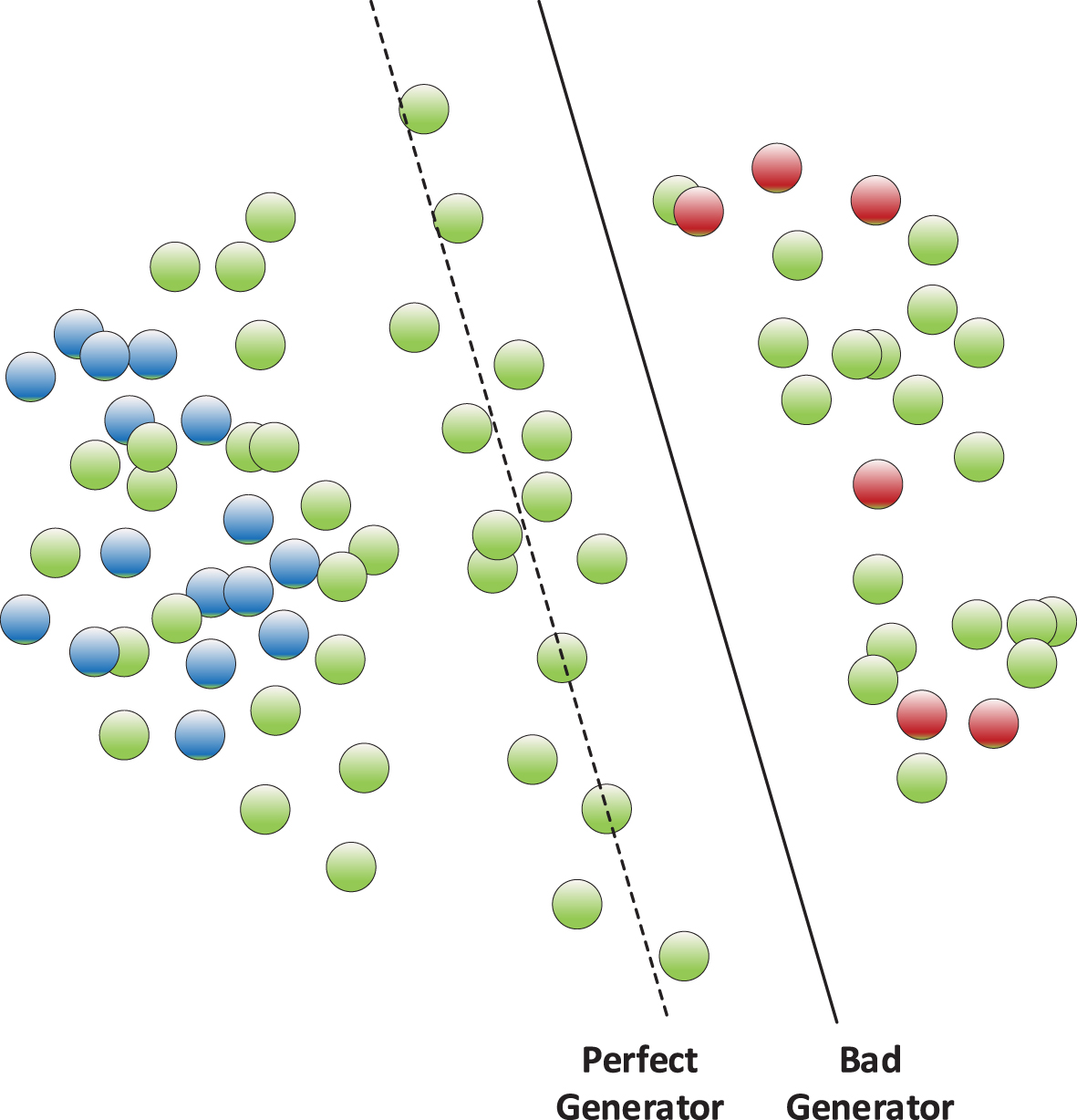
Principle visualization of bad generator: The bad generator can generate the complement samples in feature space, and these complement samples help the discriminator obtain the correct decision boundaries.
Let f (x) denote the output of each feature layer of the discriminator model before the last layer. To integrate the idea of bad GAN, a parameter w is used in the feature matching loss function Lfeature_matching:
Experiments design
A URL dataset containing malicious URLs and benign URLs was constructed to train the model and verify the detection accuracy of the approach. The benign URLs were obtained from Alexa 3 , containing 41227 samples and the malicious URLs were obtained from PhishTank 4 , containing 20613 URL samples. The number of malicious URLs in the dataset was less than that of benign URLs to simulate the real environment where the number of different class of URL samples is unbalanced. The number of malicious URLs only accounted for 1 / 3 of the total number of dataset samples. In addition, only a small part of the URL samples was tagged with positive labels and negative labels, while the rest of the URL samples are unlabeled. Table 1 shows a collection of five benign URL samples (positive) and five malicious URL samples (negative). Some synthesized URL samples by the GAN’s generator model are listed in Table 2.
URL
URL
Synthetic URL
Experiments were carried out on the above dataset, 80% of the dataset was used as the training dataset and the remaining 20% was used as the test dataset. The main parameters of the training process are as follows: The batch_ size for training was set to 50. The learning rate of the model was set to 0.00005 and optimized by Adam optimizer.
Under the condition that only 20%, 30% and 40% random data in each group were labeled, the experimental results were compared with those of the existing detection method based on SVM [12] and the detection method based on LSTM [14] as shown in Table 3. The structure of the LSTM method is the same as that of the discriminator, which is composed of three layers of LSTM neural network. The neuron nodes of each layer are set at 128,256,256, and Dropout is set at 0.5. The kernel function of SVM use RBF (radial basis function). From Table 3, we can see that the detection accuracy of the traditional malicious URL detection method based on SVM and LSTM algorithm is lower than ours when the number of labeled samples is relatively small. When there are only 20% labeled data, the proposed method can still achieve the detection accuracy of 87.8%, outperforms other two methods by a large margin, which means that our method is more practical in real application environment.
Detection Accuracy of Common URL Detection Method
Detection Accuracy of Common URL Detection Method
To further validate the effectiveness of the proposed method under the condition of insufficient labeled samples, three more objective evaluation metrics are used, including the precision rate, the recall rate, and F1 score. When the number of labeled samples was increased from 5% to 40%, the experimental results were shown in Table 4, from which we can see that the evaluation metrics decrease when the labeled samples are reduced. When the percentage of labeled samples drops from 20% to 10%, the performance drops the fastest, but still the precision rate can achieve 87.0% when only 10% labeled samples are used for training. When the labeled samples accounted for 30% and 40% of the dataset, the proposed method achieved good performance in terms of four metrics.
The Performance with Different Percentages of Labeled Samples
Moreover, in order to verify the statistical independence, 5-fold cross-validation was performed. The results are compared with the semi-supervised method based on SETRED, Self-training using C4.5 [37], CoForest [25] and S3VM [26]. These algorithms used the parameters presented in literature [38]. The experimental results are shown in Table 5, from which we can see that among four semi-supervised learning methods, the proposed approach achieves the highest classification accuracy for three settings. Compared with the self-training method, the proposed method has a significant improvement in accuracy when the number of labeled URL samples is relatively small. This is because our approach uses unlabeled samples directly for training through the discriminator loss function to avoid using too many mislabeled samples. Moreover, our approach uses LSTM algorithm to build the discriminator, which can more fully extract the semantic information of the URL dataset and avoid the influence of manual selection of URL features. Friedman test was carried out on the experimental results in Table 5, and the value of p was 0.007, which proved that the data presented significant differences In addition, as shown in Table 4 and Table 5, the accuracy results of the proposed method obtained by one random test and by the five-fold cross validation are very close to each other, which also proves the stability of the proposed method.
Detection Accuracy of Semi-Supervised Learning Method (5-fold CV)
During the training, since the proposed model has to train both the LSTM discriminator and the generator, the overall training is time-consuming. The proposed model gradually converges at 10,000 iterations, while under the same setting, the LSTM algorithm only needs 3000 iterations to converge. Considering the performance improvement by the GAN model, it is worth sacrificing the training time.
This paper introduces GAN into the field of malicious URL detection and proposes a semi-supervised malicious URL detection approach to solve the problems of insufficient number of labeled samples in malicious URL detection and the imbalance of negative samples and positive samples in URL datasets. By constructing the supervised loss function and the unsupervised loss function, this detection approach can make full use of the labeled samples, the unlabeled samples, and the synthetic samples to train the classifier together. In this manner, the detection approach can solve the class imbalance and insufficient number of labeled samples problems. In addition, this approach does not need to design features with expert knowledge manually and can extract features automatically, resulting in a better generalization ability.
The proposed method also has some limitations. One is that the proposed may be easily attacked by adversarial examples, since the many unlabeled samples are used to train the network. The other is the long training time. In future, we will study further to solve the above two problems. In addition, we will also investigate how to deal with the case that when fewer labled samples are availabe or when the imbalance is more serious.
Compliance with ethical standards
This work is supported by the Key Areas Research and Development Program of Guangdong Province (grant#2019B010139002), the project of Guangzhou Science and Technology (grant#202007010004), and the project of Guangzhou Science and Technology (grant#202007040005). The authors declare that they have no conflict of interest.