
Abstract
Cardiovascular is arguably the most dominant death cause in the world. Heart functionality can be measured in various ways. Heart sounds are usually inspected in these experiments as they can unveil a variety of heart related diseases. This study tackles the lack of reliable models and high training times on a publicly available dataset. The heart sound set is provided by Physionet consisting of 3153 recordings, from which five seconds were fixed to evaluate to the developed method. In this work, we propose a novel method based on feature reduction combination, using Genetic Algorithm (GA) and Principal Component Analysis (PCA). The authors present eight dominant features in heart sound classification: mean duration of systole interval, the standard deviation of diastole interval, the absolute amplitude ratio of diastole to S2, S1 to systole and S1 to diastole, zero crossings, Centroid to Centroid distance (CCdis) and mean power in the 95–295 Hz range. These reduced features are then optimized respectively with two straightforward classification algorithms weighted k-NN with a lower-dimensional feature space and Linear SVM that uses a linear combination of all features to create a robust model, acquiring up to 98.15% accuracy, holding the best stats in the heart sound classification on a largely used dataset. According to the experiments done in this study, the developed method can be further explored for real world heart sound assessments.
Introduction
Nowadays, Cardiovascular disease has become one of the main causes of all diseases & death worldwide. Based on the WHO report, in 2012, about 17.5 million people died from cardiovascular disease that includes about one-third of the global mortality rate. The first step in assessing a heart system in the clinical condition is performing a physical experiment. Heart sounds are the most crucial part of physical experiments & they can recognize heart diseases as well as heart failure, arrhythmias, heart valve failure, etc. Also, heart sounds are one of the most significant signs in early diagnosis of all diseases which can be used in diagnostic experiments. Heart sounds has been used frequently to evaluate heart rate and its functionality [1]. In 1997, Liang et al. [2], proposed a heart sound segmentation algorithm, the authors studied 37 subjects containing normal and abnormal cases. The methodology was based on normalized average Shannon energy of phonocardiogram (PCG) signals, which reduces low frequency noises, and finally based on a threshold, peaks are determined as the heart sounds. In another work [3], they experimented with 77 cases using discrete wavelet decomposition (DWT) as a feature to segment heart sounds into four parts: S1, Systole, S2 and Diastole. Rajan et al. [4], worked on 42 cases containing normal and pathological participants using signal energy and singular value decomposition (SVD) derived from morlet wavelets to identify important activities as useful features for segmenting PCG signals. Sepehri et al. [5], studied 60 pediatric subjects, the study used short-time spectral energy and autoregressive parameters as the distinct features and selected Multi-Layer Perceptron (MLP) as the most effective classifier. Schmidt et al. [6] used duration-dependent hidden Markov models (DHMM) for segmenting heart sounds of 73 subjects. In 2012, Naseri et al. [7] used a combination of frequency-based and amplitude-based features, extracted from sliding windows. The dataset consisted of 52 minute recordings of patients of divergent heart abnormalities. Sun et al. [8], worked on 121 subjects, including 45 normal and 76 abnormal cases. They utilized the attributes of Hilbert transform (HT) to detect the moment segmentation and peak points of heart sounds by using zero-crossing methods. In 2016, Tang et al. [9] introduced clustering to compress of the PCG signals which reduces storage capacity in the recording system, the study acquired varying compression ratios from 20 to 149 times. Dominguez et al. [10], used the a neuromorphic auditory sensor to analyze audio information in frequency boundaries in real time. After that sonograms are created from the frequency information, and fed to AlexNet for classification. In 2018, Latif et al. [11] proposed recurrent neural networks (RNN) to simplify real-time heart rate monitoring of normal and abnormal patients. Garg et al. [12] developed cross recurrence quantification analysis (CRQA), analyzing the harmony between synchronized ECG and PCG signals. In 2020, Krishnan et al. [13], worked on 1081 PCG records with frequency rates of 500 HZ, discrimination was done using one-dimensional convolutional neural networks and feed forward neural networks performed on unsegmented PCG signals.
Materials and methods
Database
The Data used in this study is provided in an open-source database by Physionet from the 2016 challenge. Dataset consists of 3153 recordings, which contains both normal and noisy recordings with such as stethoscope, talking or movement artifacts. Seven hundred and sixty-five of the patients were labeled as pathological. Recordings had a sampling rate of 2000 Hz, and the duration varied between 5 to 120 seconds. More details on the database are provided by Li et al. [14]. In this work, the length of all the analyzed recordings was fixed to 5 seconds to speed up the operation time of the algorithm and also use the same amount of information for each particular subject to prevent overfitting. All the computations were done using MATLAB.
The resulting Markov chain in PCG segmentation using HMMs. Four horizontal steps are related to the consecutive heart sounds, creating a complete cardiac cycle.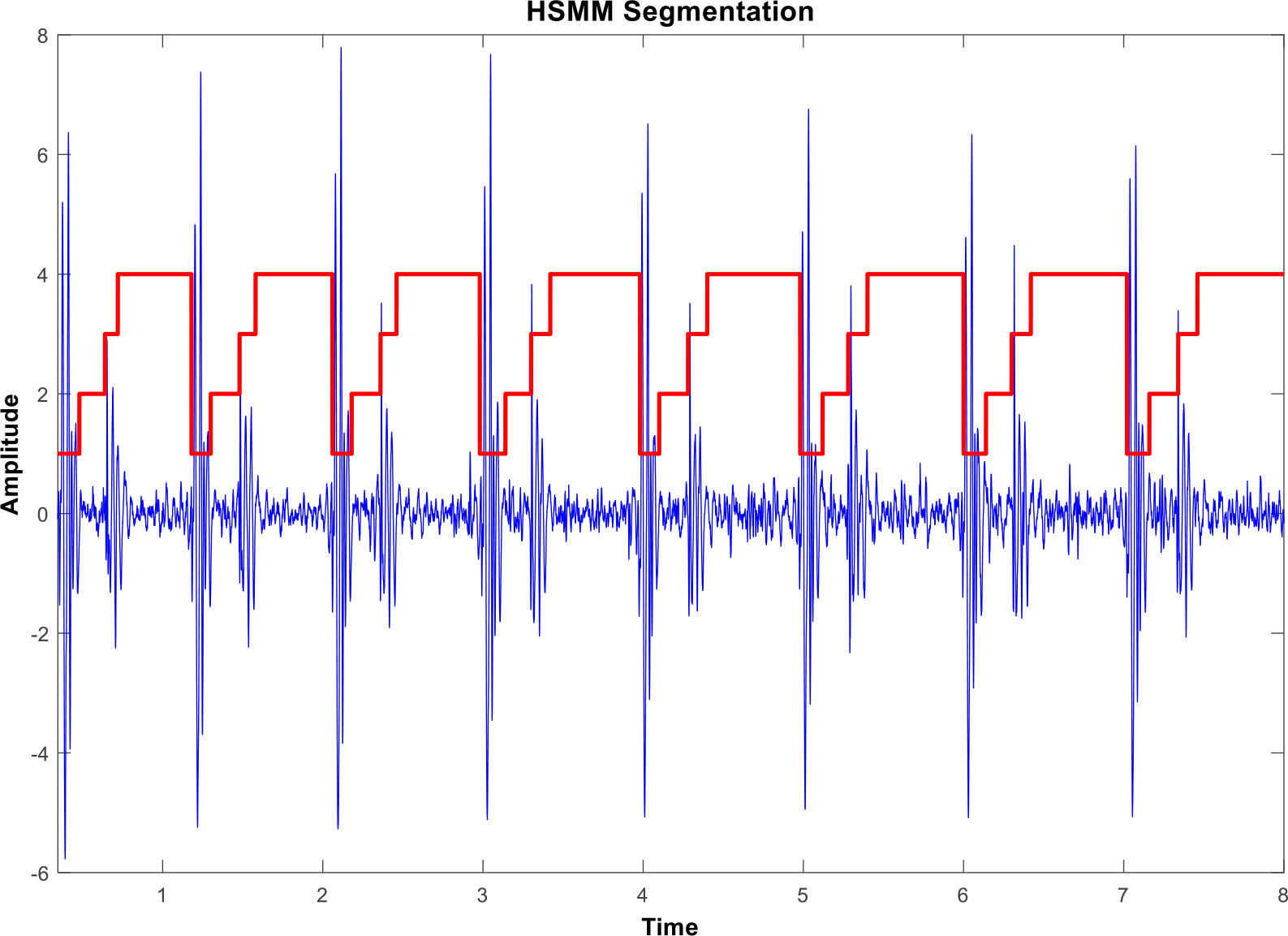
Preprocessing includes having all the recordings resampled to 1000 Hz for processing purposes and a Butterworth bandpass filter of second-order (50–800 Hz), normalization was done to reduce noise effects. Schmidt’s spike removal algorithm was also employed to further make the data suitable for processing. Secondly, state-of-art [15] Springer’s hidden semi-Markov model (HSMM) based segmentation algorithm was applied to each recording to extract the individual heart sounds. Hidden semi-Markov models have an unobservable semi-Markov chain indicating the probability to change state based on the time passed in the current state. Assuming that there are
where
where
where
where
where
In this phase of the work, 61 features are extracted from three different domains trying to represent the data in an elaborate manner. These domains include time-domain, frequency-domain, and time-frequency domain.
CCdis calculation procedure in abnormal patients.
Time-domain features have proven essential because of having the ability to recognize anomalies in heart sounds, including durations, higher-order spectra, and self-similarity techniques. Our time-domain features include 36 features consisting of state durations derived from the semi-Markov chain, which involve mean and standard deviations of heartbeat duration (RR), S1, S2, systole, and diastole intervals. Other Features include mean and standard deviations of interval duration ratios of systole to RR, diastole to RR, and systole to diastole. These features were also included in the sample entry provided by Physionet. We also added some amplitude ratio properties to enhance these 16 features. These features were used by Potes et al. [16] the 1
where the dimensionality of the time-series denoted by
Is measured for a time series:
If
where
CCdis calculation procedure in normal participants.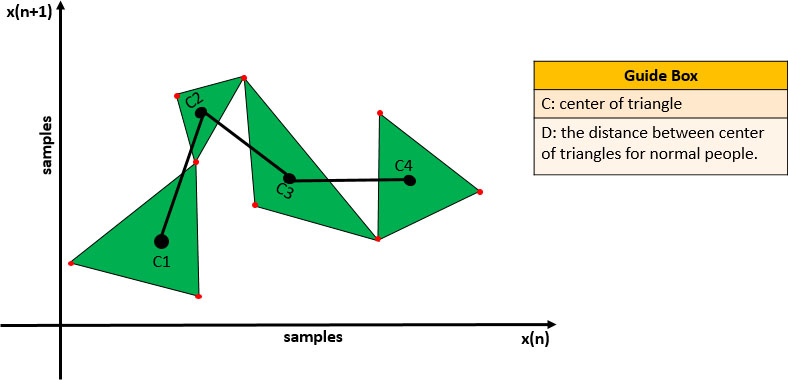
For a time-series:
where centroidX and centroidY demonstrate each triangle centroid’s
with
Figures 2 and 3 show the CCdis calculation procedure in abnormal and normal patients, respectively.
Higher-order spectra [16, 17, 9] were also extracted for every heartbeat: mean and standard deviation of kurtosis in the S1 interval, the standard deviation of skewness in S1 interval, mean and standard deviation of kurtosis in systole interval, mean values of kurtosis and skewness in the S2 interval and mean and standard deviation of kurtosis and skewness in the diastole interval. Kurtosis and Skewness refer to ‘tailedness’ and asymmetry in the probability distribution of a variable around its mean, respectively.
Frequency-domain features are widely used for heart sound classification as heart murmurs can be identified by their frequency components [19, 20, 21, 22]. In this work, initially, power spectrum was calculated for each individual using Welch’s averaged periodogram technique, in this case, the method’s frequency resolution reduction seems a fair trade because of the ability of this technique to improve the results in noisy recordings which is an important issue with the dataset in hand, which has recordings under different conditions. In Welch’s method, first, each signal is turned into overlapping segments then a window function is applied, after that discrete Fourier transform (DFT) is performed to measure a periodogram for each segment, in the end, the averaged periodograms from all segments result in the final power elements of the signal. The parameters used in this method were: Hamming window, 50% overlap as default, in this study mean powers of the specific frequency bands in the ranges: 1–95 Hz, 95–295 Hz, 295–485 Hz, 485–585 Hz, and 585–685 Hz were used concluding 5 frequency-domain features.
Time-frequency features
Twenty Time-Frequency features extracted include generalized Hurst’s exponent applied to wavelet packet decomposition [19, 23, 24, 41] (WPD) coefficients with a depth of 3, the mother wavelet was also selected to be Daubechies 4 [24, 34]. In WPD signal goes through low-pass and high-pass filters simultaneously, resulting in approximate and detail coefficients, respectively (DWT). Equation (14) demonstrates the formula for computing DWT of a time-series:
where the time-series
with
Assuming that the time-series is
where
In the feature reduction procedure, in order to overcome the curse of dimensionality and decrease the time required to train the model, feature reduction and selection [30, 31, 32] methods are performed. Several techniques were examined in this study, namely genetic algorithm (GA) [39, 40], feature ranking, and principal component analysis (PCA) [22, 37, 38]. Feature ranking was evaluated based on
Simplified diagram of a typical genetic algorithm lifecycle.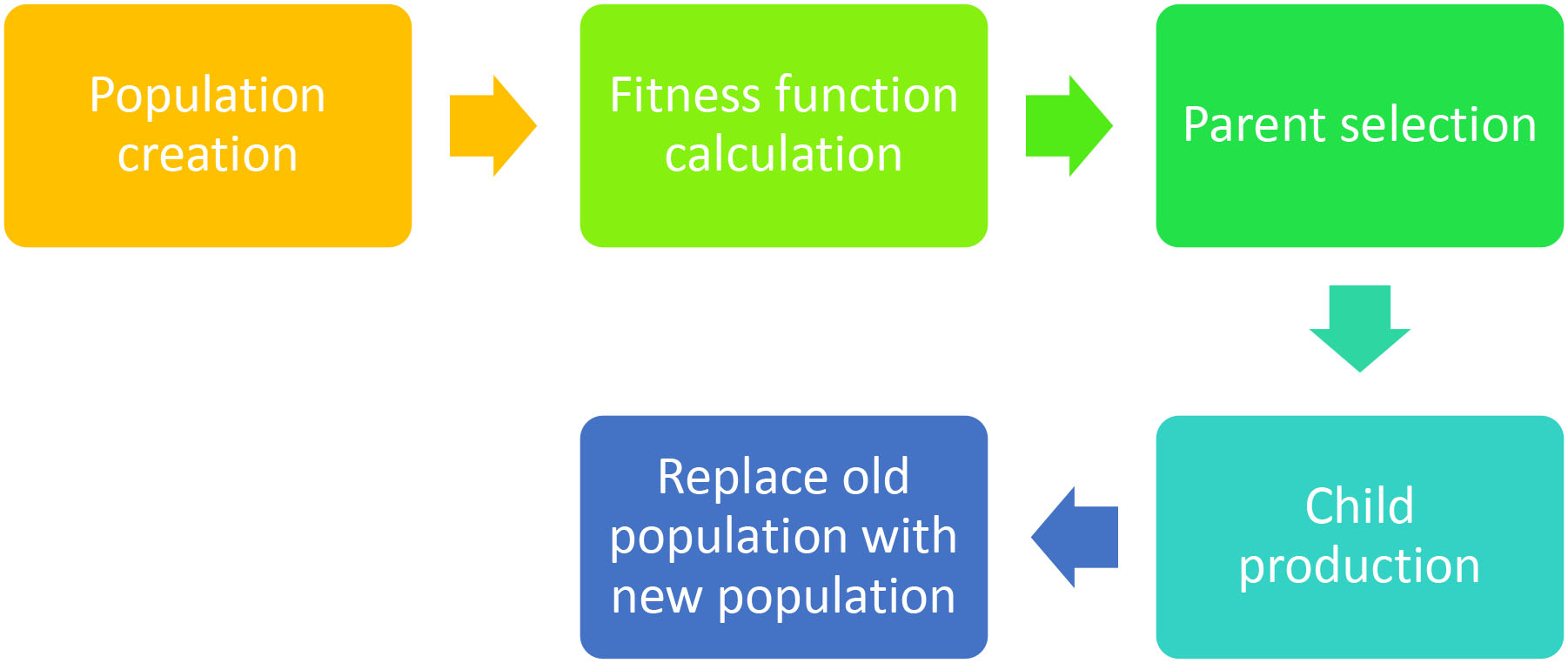
In the GA, initially a population of
Extracted features and reduced spaces derived from the feature space and feature reduction methods were examined to find an appropriate classification method in the classification step. Several popular classification techniques were inspected in this work, such as Artificial neural networks (ANN), Probabilistic neural networks (PNN), Naive Bayes (NB), Adaptive Boosting (AdaBoost), k-nearest neighbors (k-NN), decision tree, linear discriminant analysis, self-organizing fuzzy logic introduced recently by Xiaowei et al. [33], and support vector machines (SVM). An explanation for the best working techniques in this study follows below.
Weighted k-NN
K-nearest neighbor is a lazy machine learning algorithm frequently used in classification problems [34, 35], it’s often desired because of simplicity and also the upside of not making any assumptions about the data, being lazy means that k-NN does not need training and simply makes decisions based on distance compared to existing samples in the feature space. According to
where
SVMs are one of the most used supervised learning techniques for classification and regression [9, 20, 22, 24, 26, 36]. Linear SVM tries to separate the data by finding a maximum-margin hyperplane. It is quite obvious that linear SVM reduces model complexity compared to nonlinear kernel SVMs. In a dataset consisting of
where
where
Figure 5 shows the decision boundary in support vector machines.
Decision boundary in support vector machines.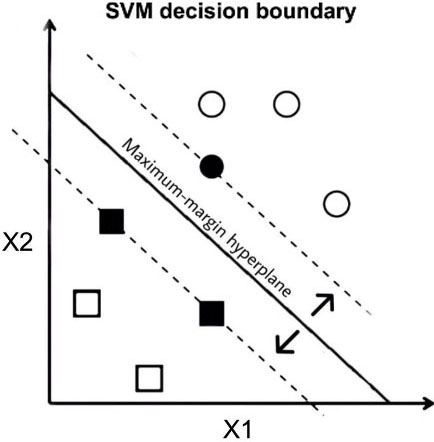
In this stage, 10-fold-cross-validation was performed to measure the reliability of the proposed classification method. Cross-validation is used to find out how well the classification method performs when the test data is unseen. Thus the performance measurement on the whole data seems necessary. In this technique, data is randomly divided into 10 groups, then the classifier is trained using 9 folds, and the testing is done on the remaining fold. This process continues so that all of the 10 folds are once used as testing data, then the average value over these sequences is reported as the final confusion matrix of the classifier. The cross-validation was done several times to ensure that the results are well-grounded. Finally, based on the confusion matrix, sensitivity, specificity, accuracy, and F1 score are calculated for the model.
where TP, TN, FP and FN sand for true positive, true negative, false positive, and false negative, respectively.
Figure 6 shows the block diagram of the proposed method.
Statistical analysis
Student’s
where
Table 1 shows the average values from time-domain features between the groups. Based on interval features, The abnormal group had relatively longer RR segments, resulting in longer heart sounds in general (S1, S2, Systole, Diastole) although with relatively larger deviations. Among the more discriminate features: Amplitude ratios suggest that the abnormal group exhibits a higher relative absolute amplitude with respect to the normal group. Hurst’s exponent results indicate that the abnormal group show more complex behavior compared to the normal group due to lower exponent value. Also, based on CCdis values, the abnormal group demonstrated greater average distance among their structure. Higher-order statistics also showed relatively good discrimination rates as they were also used in heart sound segmentation algorithms resulting in a reliable demonstration of heart sounds. With the abnormal group demonstrating higher mean and deviation in kurtosis of S1, Systole and Diastole, and greater standard deviation in the skewness of the S1 segment, and the normal group showed relatively higher mean kurtosis in the S2 segment. Zero crossing rates were also greater in the abnormal group, showing the fluctuations in heart sounds with a larger standard deviation.
-values and properties of the selected time-domain features. Containing mean and standard deviations for each group, followed up by the
-value
A simple block diagram for the developed technique.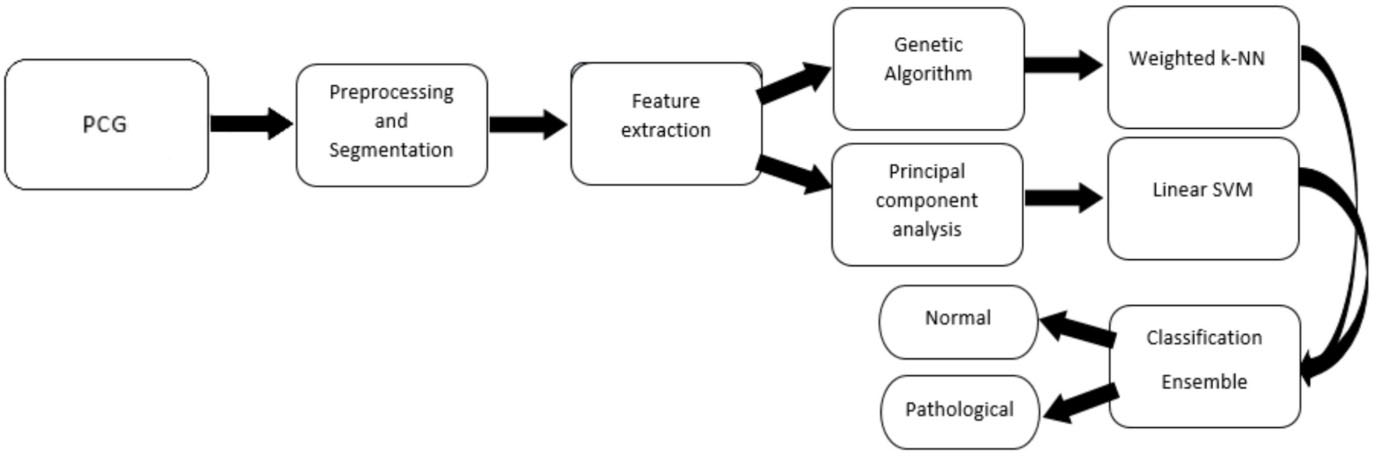
Table 2 shows the mean digits resulting from frequency-domain features in each group. Interesting power relations were observed, the abnormal group showed dominant mean powers up to frequency band of 95 Hz indicating lower murmur frequencies in normal sounds, in oscillations higher than 95 Hz, the abnormal group demonstrated greater mean powers. The difference above was the particular reason to select these bands based on
Time-frequency results
Table 3 shows the mean values in time-frequency features between the two groups. WPD features suggest that 3.3 and 3.6 coefficients are the most discriminate frequencies; these coefficients correspond to frequency bands of (331.25–425) Hz and (706.25–800) Hz, respectively. Also, all MFCC features showed a superior discrimination rate compared to other features, according to
Classification results of the experimental methods used in this study
Classification results of the experimental methods used in this study
Confusion matrix for the ensemble model.
Promising results were observed using SVM and k-NN with respect to other classifiers. Class weights were also computed and considered in loss objectives for a better imbalanced data handling. Ultimately the final algorithm was evaluated using a soft stacking based combination of features from the GA and PCA fed to a weighted k-NN classifier and a linear SVM, respectively. With the k-NN, the best results were observed using 8 GA features, after enormous trials with different scales, the amplitude ratio of S1 to systole, S1 to diastole and zero crossings were multiplied by 3 to increase the robustness of the k-NN. Trailing with the SVM finalized evaluating the first four principal components extracted from the PCA algorithm to be fed to the classifier. Lastly, an ensemble of these models appeared to be sufficient. Table 4 summarizes the classification properties of the different approaches in this study. According to the table the k-NN classifier using 8 features from the GA, excels in specificity (sensitivity
The an ensemble of these two classifiers resulted in a robust model with considerably high discrimination rate (sensitivity
A comparison between the current work and several worth mentioning studies
A comparison between the current work and several worth mentioning studies
Receiver operation characteristics plot of the feature reduction combination approach.
Based on the results section, thirty-nine of the derived features were found statistically significant. According to the results, mean power was relatively higher in frequencies greater than 95 Hz, which can be related to murmurs in the abnormal group since they usually happen in high frequencies. GA summarizes features as eight which also resulted in a considerable classification rate, suggesting that high sensitivity can be obtained even with low- dimensional feature vectors and simple algorithms considering the important role of feature weighting in the k-NN, although according to PCA and SVM, a higher sensitivity needed a linear combination of more than 8 features to acquire a fine amount. Also, based on GA, despite high discrimination rates in Higher-order features, MFCC and generalized Hurst, simple time and frequency domain features seem to represent the data sufficiently. Ultimately stacking two simple machine-learning techniques developed a robust model. Table 5 shows a comparison of this work to other studies in recent years.
As shown in Table 5, the current study outperforms most of the proposed techniques up to this point among the best challenge entries in 2016, Homsi et al. [17] used a combination of three frequently used classification methods [41], Random forest (RF), LogitBoost (LB), and Cost-sensitive-Classifier, to differentiate between the two groups, they acquired an accuracy of 84.48% using an ensemble of these methods. Bobillo [30] used the k-NN algorithm to discriminate among abnormal and normal heart sounds with an accuracy of 84.54%. Kay and Agarwal [37] evaluated their method using Regularized neural networks an achieved an accuracy of 85.20%, although no papers were attached to this entry for more information on the algorithm. Zabihi et al. [25] used an ANN ensemble approach consisting of 20 feedforward networks with 2 hidden layers, each including 25 neurons, the study holds an accuracy of 85.90%. Potes et al. [16] proposed a method based on a combination of AdaBoost and CNN using a threshold decision rule and acquiring an accuracy of 86.02%, with a considerable sensitivity of 94.24%. In 2018 Tang et al. [9] used an optimized SVM with a radial basis kernel, which had a sigma of 14; this work yields an accuracy of 88%
Conclusion
In this paper, we proposed a novel method built on feature reduction combination and classifier stacking on a public database. Relying on the results and discussion sections, the state of the art accuracy of this method can be further developed for real world applications.
Footnotes
Compliance with ethical standards
The authors declare that they have no competing interests. This paper does not contain any studies with human participants or animals performed by any of the authors.