
Abstract
Feature selection (FS) has become an essential task in overcoming high dimensional and complex machine learning problems. FS is a process used for reducing the size of the dataset by separating or extracting unnecessary and unrelated properties from it. This process improves the performance of classification algorithms and reduces the evaluation time by enabling the use of small sized datasets with useful features during the classification process. FS aims to gain a minimal feature subset in a problem domain while retaining the accuracy of the original data. In this study, four computational intelligence techniques, namely, migrating birds optimization (MBO), simulated annealing (SA), differential evolution (DE) and particle swarm optimization (PSO) are implemented for the FS problem as search algorithms and compared on the 17 well-known datasets taken from UCI machine learning repository where the dimension of the tackled datasets vary from 4 to 500. This is the first time that MBO is applied for solving the FS problem. In order to judge the quality of the subsets generated by the search algorithms, two different subset evaluation methods are implemented in this study. These methods are probabilistic consistency-based FS (PCFS) and correlation-based FS (CFS). Performance comparison of the algorithms is done by using three well-known classifiers; k-nearest neighbor, naive bayes and decision tree (C4.5). As a benchmark, the accuracy values found by classifiers using the datasets with all features are used. Results of the experiments show that our MBO-based filter approach outperforms the other three approaches in terms of accuracy values. In the experiments, it is also observed that as a subset evaluator CFS outperforms PCFS and as a classifier C4.5 gets better results when compared to k-nearest neighbor and naive bayes.
Keywords
Introduction
As technology evolves, size of the data increases rapidly, and this causes problems for effective and efficient data management. We are in the era of big data where in several areas such as, healthcare, social media, internet applications, etc. large amounts of data are generated at an unprecedented speed [17]. In addition to the important features in big data, it also includes so many unimportant features that lead to the curse of dimensionality problem. Due to high storage and computational cost, curse of dimensionality affects the performance of the algorithms. At that point, to reduce the dimension of the big data, it is necessary to apply machine learning techniques. Feature extraction and feature selection are the two most commonly used techniques for the dimensionality reduction.
In feature extraction (FE), original high dimensional features are first combined and then projected into new feature space with lower dimensionality. On the other hand, feature selection (FS) selects a subset of important (relevant) features for model construction by excluding irrelevant and redundant features. In terms of readability and interpretability, FS is better than FE [18].
FS is a very important pre-processing step for machine learning. It does not only decrease computational expense by reducing the number of exploited features but also increases the accuracy of the learning model by eliminating redundant or irrelevant features [22]. FS is indeed a difficult process. For example, a feature that seems to be unnecessary or irrelevant alone, can be very useful when combined with other features. Therefore, attention should be given when deciding which feature should be discarded and which feature should not be discarded. To accomplish this, all combinations of features in the dataset should be considered. However, for a dataset with N features, 2 N possible different sets of features arise. Thus, as the size of the dataset increases, the solution space increases exponentially.
In the literature, existing FS methods can be categorized into three classes, i.e., filter methods, wrapper methods and embedded methods. Filter methods rank the features based on a certain criteria and some examples of these methods are chi-square analysis [43], rough set and fuzzy-rough set-based dependency [27, 28], information gain, and symmetrical uncertainty [36], group-based fuzzy-rough FS (FRFS) [27], probabilistic consistency-based FS (PCFS) [23] and correlation-based FS (CFS) [21]. On the other hand, wrapper methods [4, 44] contain learning algorithms. Wrapper methods generally provide better solution, but it takes more time to execute when compared to the filter methods. Embedded methods are similar to wrapper methods but feature selection is performed during the training process. In our study, we focus on the filter methods and use two commonly preferred subset evaluators: i) PCFS and ii) CFS where more information can be found in the experiment and results section.
FS problem is in the group of NP-hard problems. Therefore, there is no polynomial time exact method for this problem. However, heuristics and meta-heuristics are proven to be successful for supplying powerful and flexible search strategies to generate high-quality solutions for NP-hard problems in acceptable run times. Heuristics and meta-heuristics generally utilize random processes in the discovery of the search space to deal with the combinatorial explosion caused by the use of exact methods. Even though they have stochastic designs, their well-engineered exploration and exploitation strategies provide superiority to their search process. A main benefit arises from their attainment to abstain from local minimum approving degeneracy of the objective function during their progress.
In this study, we firstly build an extendable framework where search algorithms, evaluators, learner algorithms and datasets are integrated in a plug and play fashion. As the search algorithms (which are used to generate the subset of the features), four different meta-heuristics are used: migrating birds optimization (MBO), simulated annealing (SA), differential evolution (DE) and particle swarm optimization (PSO) algorithms. To our best, this is the first time that MBO is applied to solve the FS problem. MBO algorithm is inspired from the V formation of the migrating birds in real life [6]. Solutions (corresponding to birds in the analogy) are initialized randomly in the solution space and they try to move to better positions by searching their neighborhood. Throughout the algorithm, the birds share their unused neighbors with the follower birds which are placed in V formation hypothetically. SA is proposed by Kirkpatrick et al. in 1983 [35]. SA is a very powerful and popular meta-heuristic for optimization. It is designed to escape from local optimum where the algorithm may select even worse solutions as a new solution with a low probability. DE algorithm is an evolutionary computation technique that looks for the optimal solution for a problem by iteratively trying to enhance a possible solution with respect to a given measure of quality [16]. The particle swarm concept is originated from the simulation of behavior of biological organisms. The starting point was to simulate visually the nuanced but unpredictable motion of bird flocking. The particle swarm optimization (PSO) algorithm imitates the flying birds and their information exchange ways to solve optimization problems [34].
Comparison of algorithms is performed on the datasets taken from the UCI Machine Learning Repository [25] by using the aforementioned subset evaluator techniques and the accuracy values computed by widely used classifiers: k-nearest neighbor, decision tree (C4.5) and naive bayes. Several high dimensional and low dimensional datasets are used. As a benchmark, we get the accuracy values by using classifiers with full number of features. Then four meta-heuristic based search algorithms are compared with each other and also with the benchmark accuracy.
The contributions of this study are: A novel MBO-based filter approach is proposed for the FS problem. Its performance is compared with three well-known meta-heuristic based filter approaches with respect to two different subset evaluators, three different classifier algorithms, on the datasets that vary from high dimensional to low dimensional. Performance of two well-known subset evaluators are compared under three different classifiers on the datasets having different characteristics.
For the rest of the paper, the organization is as follows. In Section 2, problem definition and literature survey are given for the FS problem and four meta-heuristic algorithms. In Section 3, how these algorithms are applied to FS problem is explained in details. Computational experiment setup is given in Section 4. The details of results and discussions are given in Section 5 and paper is concluded with some future works in Section 6.
Problem definition and literature review
In this section, feature selection problem is briefly defined and related literature survey is given. Also, the meta-heuristics used in this study are explained briefly with their literature survey on the FS problem.
Feature selection
In general, FS algorithms are separated into three groups: i) wrapper approaches, ii) filter approaches and iii) embedded approaches. In wrapper approaches, evaluation process includes learner / classification algorithms. In these approaches, newly generated cluster is sent to the classification algorithm and the classification algorithm provides a feedback about this cluster. According to the feedback from the classification algorithm, the wrapper approaches form a new cluster again and send it to the classification algorithm. This process continues until a pre-determined stopping criterion is met. On the other hand, the filter approaches work without the learner / classification algorithms. In this case the feedback is taken from the evaluators which return much more promptly (in polynomial time). Due to high complexity in wrapper approaches, they are slower and have higher calculation cost than filter approaches [29]. Embedded approaches are similar to wrapper approaches, however feature selection is performed during the training process.
Various strategies have been used in FS in order to generate the feature subsets while searching for the best subset. Some of these are greedy search based sequential forward selection and sequential backward selection methods. However, these methods have troubles related to high calculation cost and getting stuck at local optima. As the success of wrapper approaches mainly depends on using efficient search strategies, various meta-heuristic methods (genetic algorithms, ant colony optimization, particle swarm optimization, etc.) have been used in feature subset creation and search operations. This is due to the fact that, meta-heuristics give the global optimum or the results close to the global optimum with low calculation costs. In recent years, various meta-heuristic-based algorithms have been applied to solve the FS problem in the literature [2, 42].
Oh et al. developed the hybrid genetic algorithm (HGA) for the FS problem [14]. In that study, in order to make a more careful search, the local search method parameterized by the fluctuation factor is placed inside the HGA. However, PSO algorithm with the same fitness function developed in [19] gave better performance than the HGA. In another similar study, Jing [37] developed an HGA for subset selection by incorporating a local search operation based on rough set theory to fine-tune solutions for the genetic algorithm. Hamdani et al. developed the multipurpose (number of properties and classification performance) FS algorithm, however this algorithm was not compared to any of the other FS algorithms [38].
Nieto et al. introduced a modified binary differential evolution algorithm for the FS problem using a support vector machine classifier as a wrapper method [15]. However, this algorithm needs too many iterations (4000) to perform well. Khushaba et al. used statistical feature distribution criteria to assist the evolution process in DE while selecting the most promising feature subset [31]. However, the algorithm lacks the ability to discover the optimal feature subset size because its functionality is limited to selecting feature subsets with a predetermined cardinality [1]. Using this drawback, Al-Ani et al. used a new DE algorithm to identify related feature subsets. In this algorithm, a series of wheels is created and these wheels are used to create a feature subset. In that study, the authors proposed that the search area could be narrowed with the help of the wheel approach. In another study, DE-based FS algorithm is designed for implication analysis in a resource-deficient language [39].
Gao et al. developed ant colony optimization (ACO)-based wrapper-oriented FS algorithm to detect intrusion into the network [11]. Fisher’s discriminant ratio is adopted as a heuristic information for ACO. In another study, ACO and rough set based hybrid algorithm is proposed for the FS problem [12]. The proposed method starts with the features in the core of the rough set. However, this method was not compared with the commonly used FS algorithms.
Wang et al. used PSO algorithm to search the optimal feature subsets and to apply rough set-based reduction [40]. Liu et al. used multi-swarm PSO algorithm for the FS problem [41]. Recently, the multipurpose dual PSO algorithm, which takes into account both the number of features and the classification performance, is proposed in [2]. In this proposed PSO algorithm, factors such as crowd, mutation and dominance were taken into consideration. As a result of the experiments, it has been shown that the proposed algorithm obtains a better feature subset than traditional FS algorithms.
Search algorithms
Migrating birds optimization
One of the recently proposed swarm intelligence techniques is Migrating Birds Optimization (MBO) algorithm. As a search method, this algorithm has an initialization approach of using a set of predefined solutions corresponding to birds in a V formation and starts to search off from its neighbors. The algorithm begins with the initial solution (representing the leader bird) and continues up to the lines of tails in the bird flock. Each solution is replaced by the best neighbor solution only if it has an improvement. There is a repetition mechanism in which not only the previous solution makes benefits to the next solutions but also a solution assesses its neighbors for the replacement of the current solution. Improvement of all solutions by this neighbor method is followed by one of the second solutions in the V form taking the first place to start another loop. The algorithm runs until the stopping criteria are met [6]. MBO is a new solution approach for the FS research field. In our preliminary work, performance of MBO on FS problem is compared with some meta-heuristics under one classifier and one subset evaluator. It is shown that, MBO outperforms other algorithms [10].
Particle swarm optimization
Simulation of behavior of biological organisms has given way to the particle swarm concept that has simulated unpredictable and nuanced motion of bird flocking as a starting point. With this in mind, particle swarm optimization (PSO) algorithm tries to find a potential solution imitating the flying birds or particles with certain velocities and the information exchange among them. Velocity tuning of the particle is done according to the flying experience and others’ experience in the swarm. PSO has not only a wide usage area in hard combinatorial optimization problems but also high performance on feature selection problem since particle swarms have a chance to discover the best feature combinations while flying within the problem space. PSO has shown such a strong search capability in the problem domain that it explores near optimal solutions in reasonable computational time [16, 40]. Liu et al. proposed an improved version of PSO [41] and Chuang et al. made improvements on binary PSO using catfish effect [20] for the feature selection problem.
Simulated annealing
Simulated Annealing (SA), proposed by Kirkpatrick et al. in 1983 [35], is one of the oldest and stochastic meta-heuristics that tries to find an approximate solution to the global optimum. SA makes use of annealing metallurgical technique that heats and cools metals repeatedly to get benefits like increasing the size and reducing the faults in order to reach the best quality. SA can also be used for feature selection problem working on just one feature subset to search the most appropriate solution to reach the thermal equilibrium while other population-based algorithms in this area manage selecting and improving multiple possible solutions. SA adjusts the temperature parameter using a cooling rate once it becomes in a fine state according to pre-given improvement criteria. Clearly can be inferred that one can get high efficiency in decreasing computational time by managing only one subset, however this may also result in lack of finding the best solution if initial settings are not adjusted well enough. Diao and Shen worked SA on FS problem and made comparisons among other nine meta-heuristics [26]. Meiri and Zahavi applied SA approach to FS problem in marketing applications [30].
Differential evolution
Differential Evolution (DE) algorithm, which is an evolutionary computation (EC) technique, iteratively tries to find the optimal solution to improve a possible solution in terms of a given measure of quality. DE is a less-expensive and easy to implement stochastic direct search method with a few predetermined parameters as compared to other EC techniques. In multi-dimensional real-valued optimization problems, DE starts searching with a randomly-generated initial candidate solution in order to find global optimum avoiding local optimum solutions. Mutation and crossover operations, which indicates DE as evolutionary, take place after the initialization step to get a better population [3, 34]. DE is used for FS by Hancer et al. [7] and it is mixed with artificial bee colony algorithms to get a hybrid approach by Zorarpaci and Ozel for feature selection purposes [8].
Application of algorithms to feature selection problem
The reader can easily recall that the aim in the FS problem is reducing the number of features (dimensions) while keeping the accuracy value at least same as in the original dataset. Also recall that filter approach is one of the most commonly used FS algorithms due to its speed where subset evaluators are used to measure the quality of the feature subset. In this study, we investigate the performance of i) search algorithms and ii) subset evaluators from different perspectives. Performance evaluation of search algorithms is done in terms of their accuracy values and number of exploited features found by three different classifiers through applying two evaluators. On the other hand, performance of subset evaluators in terms of accuracy value and exploited number of features are explored under three classifiers where they coordinate with four search algorithms. Furthermore, all of these algorithms are integrated in a framework which can be extended in any dimension very swiftly.
In this study, we focus on filter approaches and proposed a novel filter approach based on MBO. The performance of MBO is compared with three state-of-the-art meta-heuristic based filter approaches from several perspectives. In our framework, MBO, PSO, SA and DE are used as the search algorithms to find the feature subsets. Then probabilistic consistency-based FS (PCFS) and correlation-based FS (CFS) are used to judge the quality of the feature subsets. After the best subset is decided by a search algorithm (through communicating with the evaluators several times), its true performance is determined by a classifier algorithm. As classifier algorithms, we preferred to use three most commonly used classifiers, k-nearest neighbor, naive bayes and decision tree (C4.5). General structure of our framework for the proposed algorithms is shown in Figure 1.
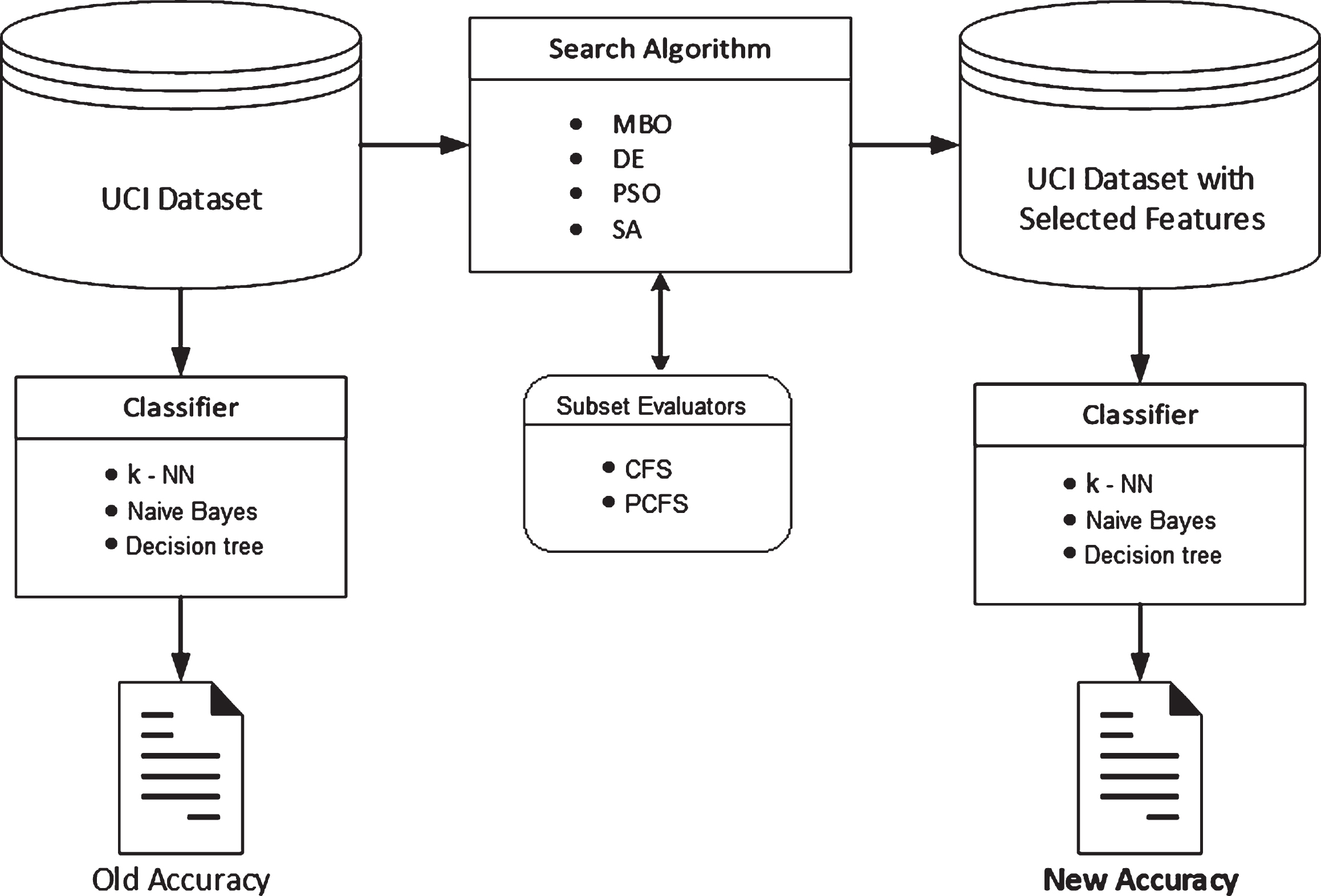
The framework designed for comparing the algorithms on the feature selection problem.
In order to apply meta-heuristic algorithms to a problem successfully, defining a solution and creating a new solution from an existing one (neighbor generation) are the most important parts. In this study, for MBO algorithm, we define a solution as a vector having their elements as the weight values of features in [0,1] range. By rounding its elements to the nearest integer, this vector is transformed into a binary-valued vector. Thus, ith element in the vector indicates the selection status of the ith feature. In the initialization phase of the search algorithm, solution vectors are generated by assigning random weight values to their elements. In the neighbor generation phase, we modify the current solution vector by mutating all elements by small incrementations or decrementations (t) obtained by using Eq. 1.
Representations of a solution and neighbor generation are shown in Figure 2 on a hypothetical dataset having five features. As shown in Figure 2, a solution vector having (0.80, 0.34, 0.21, 0.55, 0.49) as its elements is mutated. In this mutation, let r = 0.02 and let the two invocations of the G (0, 1) produce 0.40 and 0.15, respectively. Then, by applying Eq. 1 we obtain a neighbor solution having (0.818, 0.358, 0.228, 0.568, 0.508) as its set of values. Observe the selection status of features for both original vector and neighbor vector (1 means the feature is selected, whereas 0 means the feature is not selected). At each iteration, current solution and newly generated solution are compared according to a score computed by the subset evaluator methods where a higher score means better quality. Algorithm runs until a stopping criterion is met.
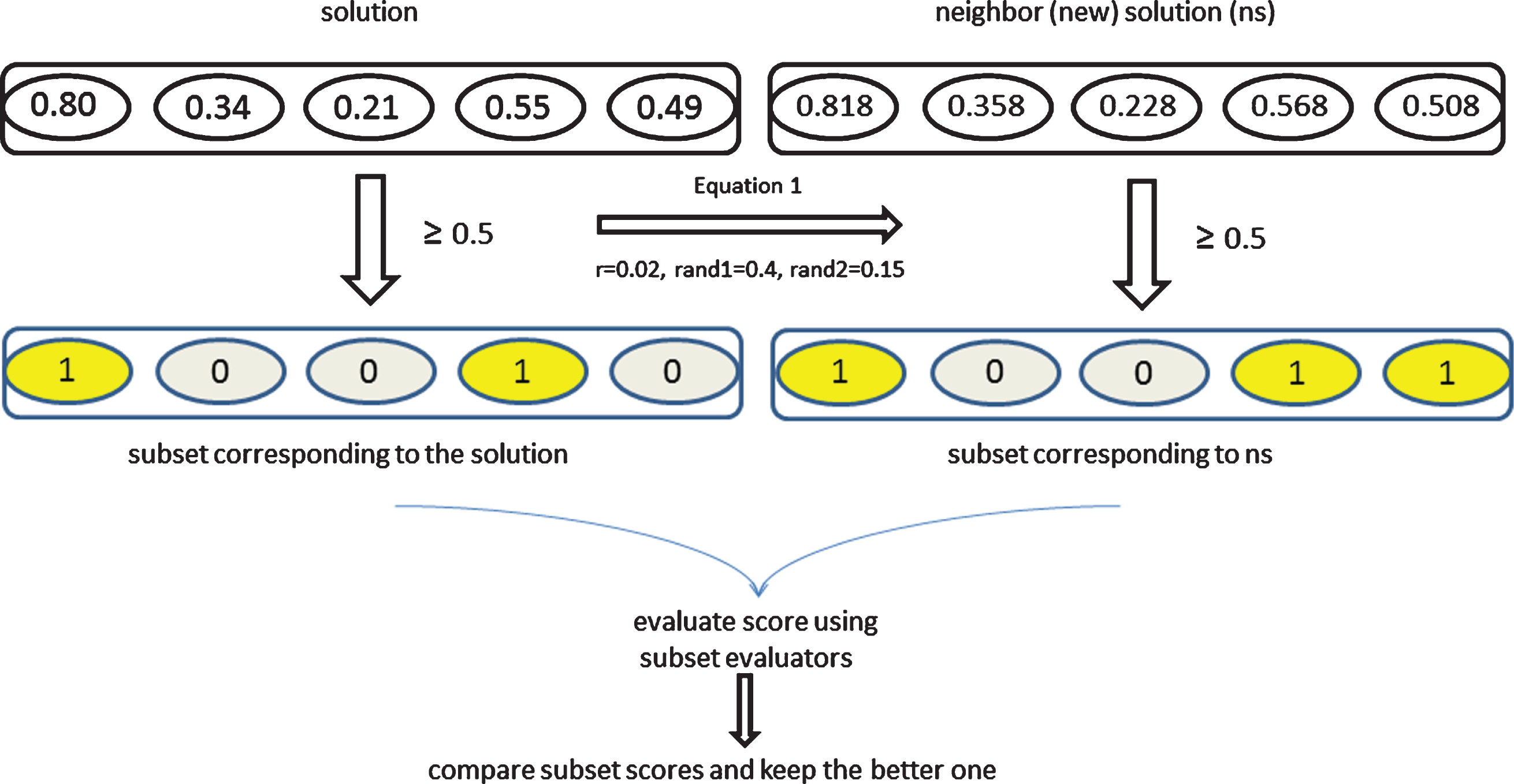
Solution and neighbor generation.
Initial solutions for SA, DE and PSO are generated by using same way as in MBO. New solution is generated in SA by using the same neighbor generation mechanism of MBO. Mutation and crossover operations for DE are implemented as given in [7]. Change velocity and change position operations for PSO algorithm are adapted from [33] and modified for the FS problem.
When the algorithm stops, it gives its best feature subset found so far as an output. This feature subset is then sent to a classifier algorithm to get an accuracy value that corresponds to this subset. Four search algorithms are compared with each other and benchmark (classifier performance with full set of features) according to accuracy values found by them with respect to two different subset evaluators and three different classifiers. In the same way, subset evaluators are also compared with each other.
In this section, we provide details of the computational experiment setups and exploited algorithms. Firstly, we will present the details of the datasets that we used in the computational experiments. Then, we will explain the parameters of the search algorithms. It will be followed by the subset evaluators and classifiers.
Datasets
To examine the performance of the algorithms, we used 17 datasets taken from UCI machine learning repository [25]. In order to obtain a comprehensive understanding regarding the performance of the selection algorithms and evaluators, we used both small sized and large sized datasets where size refers to the number of features (in line with the context of the manuscript) small refers to datasets having less than 100 features and large refers to datasets having more than or equal to 100 features. Table 1 gives information about the datasets where the range of number of features changes from 4 to 500. The datasets also differ in terms of number of instances and classes where their ranges change from 101 to 20000 and 2 to 41, respectively. Also note that the dataset named "arrhythmia" has some missing values in four features, therefore they are removed in the data preparation step.
Description of UCI datasets
Description of UCI datasets
The parameters of the search algorithms used in our implementation are as follows: MBO: number of birds (nob), number of neighbors (non), number of flapping (nof), overlap factor (olf) and radius (r). PSO: inertial weight (ω), ϕ1 and ϕ2 are the acceleration coefficients, number of generations (nog) and number of solutions (nos). SA: initial temperature (T), number of iterations in each temperature (R), temperature decrease ratio (a), increase ratio of R (b) and radius (r). DE: crossover rate (cxp), mutation rate (mp), differential weight (F), number of generations (nog) and number of solutions (nos).
In order to get the best performance from the algorithms, we need to use their best performing values. These best performing values are taken from [10] where the same algorithms were applied to the same problem (See Table 2). After defining best parameters, in the detailed experiments, the number of solutions that algorithm can generate while surfing in the solution space is limited to 50000 for each algorithm. The experiments are repeated ten times and results are presented as average of these ten runs.
Values of parameters used in the fine tune experiments.(Bold ones are the best) [10]
Values of parameters used in the fine tune experiments.(Bold ones are the best) [10]
In the evaluation of the feature subsets, we implemented two different subset evaluators; probabilistic consistency-based FS (PCFS) [23] and correlation-based FS (CFS) [21] where computational complexity and characteristics differs from each other. PCFS focuses on inconsistency measure where it aims to identify a group of features that are inconsistent and removes unrelated features. As mentioned in [23], a pattern is a part of an instance without class label. In other words, it is a set of values of the feature subset regarding a specific instance. In PCFS, consistency measure is defined by inconsistency rate and calculated in three steps. If two instances have same feature value but different class label, then this pattern is called inconsistent. The inconsistency count for a pattern of a feature subset is the number of times it appears in the data minus the largest number among different class labels. The inconsistency rate of a feature subset is the sum of all the inconsistency counts over all patterns of the feature subset that appears in the data divided by the total number of instances [23].
CFS identifies subsets of features that are highly correlated with the class but uncorrelated with each other (see the Eq. 2).
In order to judge the quality of the subsets found by four algorithms, three commonly used classification methods, namely, k-nearest neighbor (k-NN) [5], naive bayes [9] and decision tree (C4.5) [32] are used. k-NN is a lazy technique that classifies a new instance according to the majority of class labels of its k nearest neighbors. In our experiments, we used 5-nearest neighbors. C4.5 is a tree-based classification technique that consists of leaf, root, branches. From root to leaf nodes, each path represents the classification rules. Naive bayes is another commonly used classification technique based on bayes theorem. In our implementations, we used Waikato Environment for Knowledge Analysis (WEKA) libraries for these three classification techniques.
In the classification part, we used 10 fold cross validation for the data validation. Each dataset is divided into 10 folds with roughly equal sizes and nine of them are used as training set and the remaining one is used for test set. Each fold is used as test set once while the remaining folds are kept as training sets and then average of 10 (number of folds) processes is taken to compute the performance of the classifier.
Results and discussion
After fine tuning the parameters for all algorithms, we made an extensive set of tests for comparing performance of the search algorithms and subset evaluators.
We conducted experiments on 17 datasets where each dataset has different characteristics. In the experiments, MBO is compared with PSO, SA and DE algorithms in terms of accuracy values and average number of features in the subsets found by them. Table 3 presents accuracy values (in terms of percentages) of search algorithms with respect to PCFS and CFS using the classifiers; k-nearest neighbor (KNN), naive bayes (NB) and decision tree (C4.5) whereas Table 4 presents the number of exploited features by these algorithms in a similar way.
Accuracy values (%) of search algorithms with respect to PCFS and CFS using KKN, NB and C4.5 (bolds are best values)
Accuracy values (%) of search algorithms with respect to PCFS and CFS using KKN, NB and C4.5 (bolds are best values)
Average number of features found by search algorithms with respect to PCFS and CFS using KKN, NB and C4.5 (bolds are best values)
The first and most general conclusion from these tables can be drawn by making a general assessment of the overall performance of the algorithms. According to Table 3, when we check the accuracy values of all algorithms, it is seen that except few of the datasets, search algorithms performs better than benchmark values. Remember that, benchmark results are obtained by using only classifiers with full set of features. As seen in Table 4, on all datasets, search algorithms perform better than benchmark values in terms of number of exploited features. The reader should also recall that the goal in the FS problem is reducing the size of datasets while keeping the original accuracy value or even try to increase it. Therefore, results presented in Table 3 and Table 4 show that our search algorithms are applied to the FS problem successfully.
Next, we are going to make an analysis of which evaluator, learner algorithms and search algorithms are performing better. To start with the evaluators, the percentage of decrease on exploited number of features is 38% for PCFS whereas it is 50% for CFS, on the average (which can be extracted from Table 4 easily). Therefore, CFS presents a significantly better performance in decreasing the number of features. Furthermore, the accuracy performance of search algorithms are better when they exploit the CFS evaluator rather than PCFS. This can be observed from Table 3 from the bottom rows showing the average accuracy value for each classifier.
If we take a look at the performance of classifiers, it is seen that C4.5 gives better results than KNN and NB classifiers. When they use full set of features, C4.5 gives 80.15% accuracy value, whereas KNN and NB give 77.75% and 75.26%, respectively, as the average of 17 datasets (see the bottom rows of Table 3 showing the average accuracy value for each classifier). The same performance order is observed when these algorithms are run with feature subsets selected by the search algorithms. Therefore, we can say that among these three classifiers, it is better to use C4.5 rather than KNN and NB.
Once the winners of evaluators and learner algorithms are disclosed, we can focus on the performance of the search algorithms. As the first observation, we can easily say that MBO is the best performing search algorithm. This can be verified by the average performances of the search algorithms given at the bottom rows of the Table 3. Furthermore, the search algorithm showing the best performance with the best learner (C4.5) and best evaluator (CFS) is the MBO algorithm (see the results at the intersection of C4.5 and CFS in Table 3). Therefore, among the search algorithms MBO is significantly better than others. After MBO we observe DE showing the next best performance.
In Table 5 and Table 6, number of winning cases for each dataset are shown according to the accuracy values and number of features, respectively. That is, each column in these tables shows for how many files (out of 17 files), a search algorithm outperformed the others. Note that the sum of figures in each column may exceed 17 due to draws. From Table 5 we observe that MBO outperforms the other search algorithms for most of the evaluator and learner combinations.
Number of winning cases in terms of accuracy
Number of winning cases in terms of average number of features
Feature selection is a very important pre-processing step for machine learning. It does not only decrease computational expense but also increase the accuracy of the induction algorithm by eliminating redundant or irrelevant features. In this study, we developed a framework in which a novel feature selection integration of several approaches is proposed. Furthermore, it is the first time that MBO algorithm, as a state-of-the-art optimizer, is applied to the feature selection problem, to our best. Our framework gives the opportunity to compare the performance of four metaheuristics (MBO, PSO, SA and DE) which are mounted as selection mechanism and two evaluators (PCFS and CFS) which are the auxiliary elements in the filter approach. The performance calculation is done by exploiting three different classifier algorithms, namely KNN, NB and C4.5. Computational experiments are conducted on a large set of datasets, in contrast to the existing studies in the literature. Results show that among the search algorithms, MBO gives better accuracy values than the others on the average and we can say that MBO algorithm works best for a wide variety of datasets. From the evaluators perspective, we observe that CFS evaluator provides better results than PCFS. Furthermore, our framework gives us the chance to compare the learner algorithms. From this perspective, we observed that C4.5 provides significantly better results on the average.
As a future work, a novel wrapper approach may be developed by integrating the MBO algorithm with several induction algorithms. Besides, our framework can be extended by including other classical metaheuristics, evaluators and learner algorithms.