
Abstract
A considerable percentage of software costs are usually related to its maintenance. Program comprehension is a prerequisite of the software maintenance and a considerable time of maintainers is spent to comprehend the structure and behavior of the software when the source code is the only product available. Program comprehension is one of difficult and challenging task especially in the absence of design documents of the software system. Clustering of software modules is an effective reverse-engineering method for extracting the software architecture and structural model from the source code. Finding the best clustering is considered to be a multi-objective NP hard optimization-problem and different meta-heuristic algorithms have been used for solving this problem. Local optimum, insufficient quality, insufficient performance and insufficient stability are the main shortcomings of the previous methods. Attaining higher values for software clustering quality, attaining higher success rate in clustering of software modules, attaining higher stability of the obtained results and attaining the higher convergence (speed) to generate optimal clusters are the main goals of this study. In this study, a hybrid meta heuristic method (ARAZ) includes particle swarm optimization algorithm and genetic algorithm (PSO-GA) is proposed to find the best clustering of software modules. An extensive series of experiments on 10 standard benchmark programs have been conducted. Regarding the results of experiments, the proposed method outperforms the other methods in terms of clustering quality, stability, success rate and convergence speed.
Keywords
Introduction
Software change several times during development phase and especially after it has been delivered. Changing a software product or component after delivery is named as software maintenance. Software maintenance is performed to repair software faults, adapt the software to a different operating environment and improve the software functionality. About 60% to 70% of software costs are usually related to its maintenance [6, 15, 19]. Before making a change in a piece of software, the maintainer should gain a complete understanding about the structure and behavior of the software (program comprehension). Program comprehension is a prerequisite of the software maintenance and a considerable time of maintainers is spent to comprehend the structure and behavior of the software [7, 15, 18, 20]. Program comprehension is one of difficult and challenging task especially in the absence of design documents of the software system. Program comprehension techniques and tools can reverse engineer an existing code of software system to generate an abstract structural model; hence, the software maintenance cost can be notably reduced using the generated structural models of software.
Software clustering is one of helpful methods to understand the large software system when the source code of the software system is the only product available. Software clustering decompose the software system into smaller manageable subsystems containing similar modules. Clustering of software modules is an effective method for extracting software architecture and structural model [1, 3, 10]. Software clustering is carried out according to the relations among the modules which are demonstrated by module dependency graphs (MDGs). The rationale behind clustering software modules is to produce clusters with maximum cohesion (intra cluster relations) and the minimum coupling (inter cluster relations) [1, 3, 4, 7]. Finding the best clustering is considered to be a multi-objective N-P hard optimization-problem. Hence, different meta-heuristic algorithms have been applied for solving this problem [3, 4, 5, 9]. In the related works which have been conducted up to now, different objectives have been considered in this research problem. Some of these objectives are as follows:
Obtaining higher quality for software module clustering (MQ) Providing higher stability of the values obtained from clustering methods Obtaining higher success rate in achieving the best MQ value by the clustering methods
For fulfilling the above-mentioned objectives, different studies proposed several meta-heuristic algorithms such as hill climbing (HC), genetic algorithms (GA), particle swarm optimization (PSO), multi-objective evolutionary algorithm, artificial bee colony algorithm (ABC) [2, 3, 4, 5, 11, 14, 16, 18, 17]. The drawbacks of these methods are the main motivations of this study. Regarding the results of conducted experiments, the main drawbacks of these methods are as follows:
In some of previous methods like HC based method, despite high clustering speed, the results are likely to be local optima. Late convergence to the optimal results are the other shortcoming in some of the previous methods such as GA. Inefficient performance of some previous methods in clustering software with a large number of modules and communications is the other important drawbacks. The considerable variance among the results of different executions of a method is considered as instability of the method. Instability and low success rate in achieving the best clustering quality are the other shortcomings of the previous methods.
The proposed fitness function in [4] had the highest application in clustering studies. In the present study, a method (ARAZ) has been proposed for clustering software modules based on the hybrid algorithm of PSO and GA. The purposes of the present study are as follows:
Attaining higher values for software clustering quality (MQ) Attaining higher success rate in clustering of software modules with the best MQ value Attaining higher stability of the obtained results Attaining the higher convergence (speed) to generate optimal clusters
The main contributions of this study are as follows:
Combining PSO and GA for optimal software clustering Producing the high-quality clusters of software modules, especially for large software Generating more stable results compared with the previous heuristic-methods Attaining higher convergence and success rate compared with previous heuristic based software clustering-methods
The paper is organized as follows: Section 1 reports the introduction to the study which includes the significance and justification for the present study and the purpose of the study. Section 2 briefly reviews the related works. Section 3 introduces and clarifies the proposed method (ARAZ) in line with improving the clustering of software modules via the combination of PSO and GA. Section 4 reports the simulation of the proposed hybrid algorithm in details and the experiments on 10 real data. Also, discussion of the results and their comparison with those of PSO and GA are reported in this section. Finally, in Section 5, the contributions and findings of the study are concluded and reiterated and directions for further research are given.
Mancoridis et al., proposed methods for automatic clustering of software modules using HC and GA algorithms [8]; this method responded well to several software systems. Then, they developed Bunch clustering tool in 1999 which can automatically analyze and cluster different software systems. Mitchell [3], in 2002, introduced several heuristic algorithms to automatically analyze source code and then cluster it into subsystems. The input of Bunch tool is the module dependency graph (MDG) of the input program and includes three fitness functions. The fitness functions of Bunch are BasicMQ, TurboMQ and ITurboMQ [2]. Also, they presented better results in HC algorithm than those of GA.
In 2011, Praditwong et al., introduced two novel multi-objectıve approaches, namely maximum cluster approach (MCA) and equal cluster approach (ECA) for clustering software modules [4]. The obtained results of the study indicated that the multi-purpose approach was significantly better than the single-purpose approach. These two proposed approaches i.e. MCA and ECA, were regarded as a milestone in software clustering studies. The applied graphs in this approach were considered as both weighted and unweighted graphs. The main objective of MCA approach was to achieve a high degree of cohesıon and low coupling in such a way that the number of produced clusters is maximized and the number of single-module clusters is minimized. On the other hand, ECA encourages and stimulates the production of clusters with approximately equal number of modules. The objectıve function applied in this study was the most well-known objectıve function in the realm of clustering software modules. The results of the application of ECA and MCA in the multi-objective method in comparison with single objective HC method indicated that:
Multi-objective approach is able to present notably better results for the weighted and unweighted graphs. Although multi-objective method produces desirable results, the single-objective method outperformed it in the unweighted graphs. For achieving maximum cohesion and minimum coupling, ECA provided better results in the multi-objective approach. In the multi-objective approach, double more effort was required for obtaining better results.
In 2016, Kumari et al., proposed automatic clustering of software modules [5]. They introduced two new multi-objective formulas for clustering software modules where cohesion and coupling were separately considered. The results of this experimental study revealed that the multi-objective approach provides significantly better solutions than the single-objective approach. In 2017, a multi-objective clustering method has been proposed for software modules [11]. Their purpose was to produce automatic clustering solutions which simultaneously optimize several contradictory clustering criteria. Until the development of this method, multi-objective evolutionary algorithm (MOEA) was considered as the best choice for solving this type of problems. However, it was observed that the performance of MOEA algorithm is reduced for optimizing several objectives which have more than two objective functions. For solving this problem, artificial bee colony algorithm (ABC) was proposed with five objective functions. The comparison of the results indicated that ABC method significantly outperforms the other existing methods.
In 2017, a method using particle swarm optimization (PSO) algorithm has been proposed for optimizing the clustering of software modules [9]. They improved clustering with respect to the following factors: optimizing the relations within clusters, relations among clusters, the number of clusters and the number of modules within each cluster. The results obtained in this study were compared with those of GA, HC and simulated annealing (SA) algorithms. The results indicated that the proposed method was notably effective and promising for clustering software modules. For sorting out the problems of slow convergence speed, poor clustering results and complicated algorithm, in 2018, Sun et al., used probability selection in which software system is converted into a complex network diagram [10]. Then, merger, adjustment and optimization operations are used for clustering software modules.
In [13], ant colony optimization (ACO) algorithm was used for the optimal clustering of software modules. Each independent cluster (a subsystem) includes highly dependent modules. Ant colony optimization (ACO) algorithm is a heuristic algorithm based on swarm intelligence which is used for solving several search-based optimization problems. In the proposed algorithm, each ant is regarded as a possible response for the clustering problem. A clustering with maximum quality includes the maximum number of cohesion and the minimum number of coupling. Intra-connections indicate the relation among the modules within the clusters and the inter-connections show the relation among the modules of different clusters. This method was experimented using a limited number of datasets. The results of conducted experiments on the three real data sets confirm the performance and stability of this method compared with the previous heuristic-methods. In [8] a new clustering method named Neighborhood tree has been proposed; this method creates a neighborhood tree using available knowledge in an ADG and uses this tree for clustering the modules of software. The results of experiments indicate the success of the algorithm in extracting an acceptable architecture in a reasonable time compared with some of the previous methods. In this method, the size of generated subsystems was not considered into accounts; also, this method is not compared with novel meta heuristic based methods. The comparison of the experimental results indicate the simplicity of the algorithm, little time complexity and high convergence speed. Indeed, this algorithm provides a simple but effective method for sorting out the problem of clustering software modules.
Software modules are clustered based on the relations among the modules which are depicted via module dependency graphs (MDGs). In each MDG, nodes represent modules and edges stand for the relations among the modules. The resulting graph edges can be weighted or unweighted. In case they are unweighted, the weights of all the edges are assumed to be equal to one and illustrate the relations among modules which are one-way or two-way. However, if graph edges are weighted, the weights indicate the number of relations among the modules. These relations are the same as calling modules by one another. The resulting graph will be considered as the input of the clustering algorithm [1, 2]. For automatic production of MDG, source code analyzing tools are used. Some samples of these tools are as follows: CIA for C, Acacia for C and C
Illustrating a clustering array.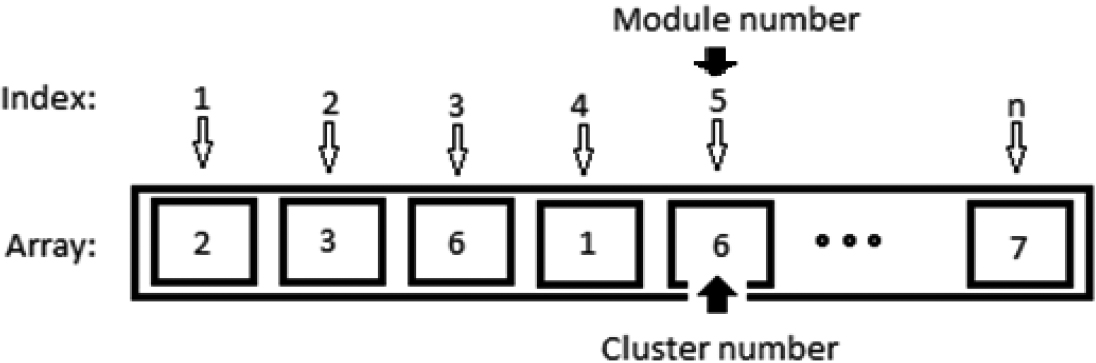
A clustering a software with nine module.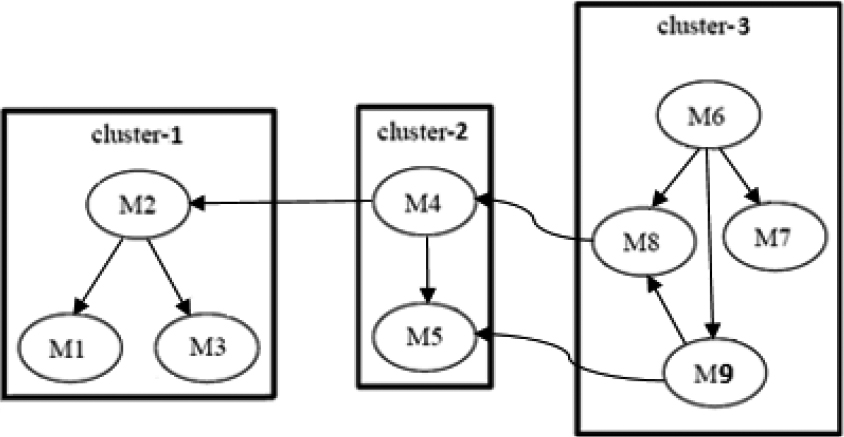
The clustering array of the clustered software shown in Fig. 2.
In order to overcome the drawbacks of previous software clustering methods (inadequate MQ, low convergence, inadequate success rate and low stability), we proposed a heuristic based software module clustering method using PSO and GA. The proposed method uses the capabilities of both heurıstıc algirthms. PSO is regarded as a particle swarm-based optimization algorithm [12]. This algorithm was modeled from the group flying of the birds and the group movement of the fish. Each member of the group is defined by two vectors, i.e. speed and position in the search space. In all the iteratıons, the new position of the particles is updated by vector of speed. The updating is done by using the best position found by the particle itself (X
Optimizing the position of each particle in PSO algorithm using the best experience of each individual particle and the best experience of all the particles.
In this study, optimizing clustering quality and achieving fast data convergence to the optimal response with respect to PSO and GA algorithms, we proposed a hybrid algorithm including both PSO and GA. In this algorithm, in the stage on updating speed vector of all the particles, two well-known operators of the genetic algorithm, i.e. crossover and mutation, were used for updating and optimizing the position of the particles. GA is regarded as one of the most significant population-based meta-heuristic algorithms which is used for salvıng optımızatıon problems [21]. The structure of the genetic algorithm includes chromosome, fitness function, population size and selection algorithm. Chromosome is a string or sequence of bits which is considered to be the coded form of a possible response to the problem. The objective/fitness function is a function within which the value of problem variable is inserted; hence, by defining and applying this function, the best possible response for the problem is detected by the genetic algorithm [14]. Crossover and mutation are two major operators of GA for generating new chromosomes from their parents. In the issue of clustering software modules, each chromosome is implemented by clustering array that is shown by Fig. 1.
Given the different objective/fitness functions introduced by researchers in the related works, the one used in [2, 3, 8, 13] was applied in this study for clustering software modules. The purpose of this function was to reduce relations among clusters and enhance relations among modules within the clusters as much as possible. This fitness function or MQ criterion makes a balance between cohesion and coupling of clusters. The enhancement of the cohesion and the reduction of the coupling improves the MQ score. Equation (1) illustrates the fitness function (MQ) that is used in this study. In Eq. (1), variable
The flowchart of the proposed PSO-GA algorithm is given in Fig. 5.
Flowchart of the proposed PSO_GA algorithm.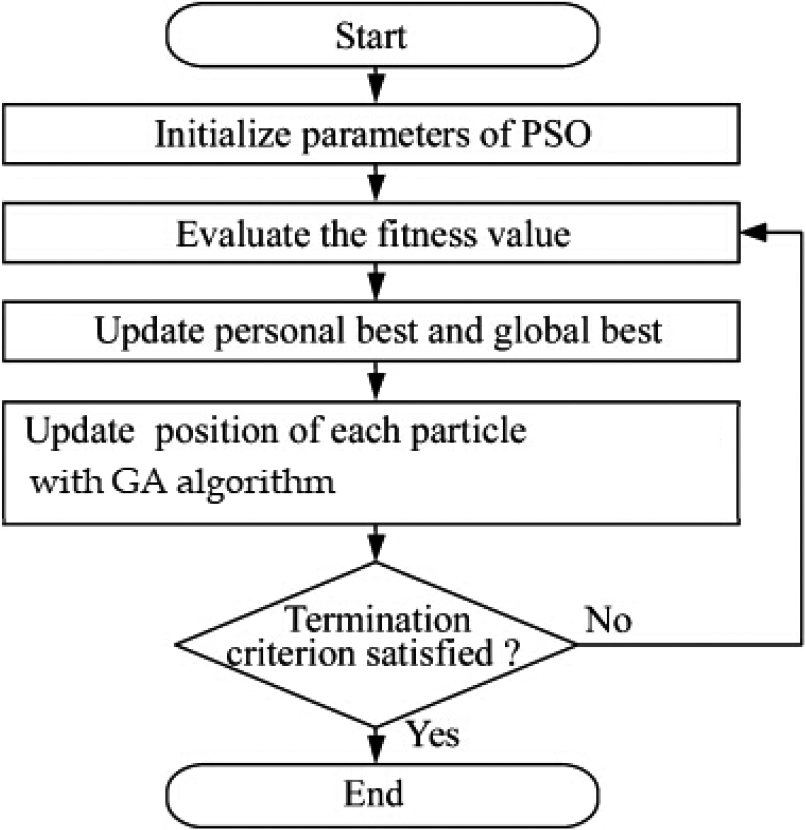
The execution of evolutionary algorithms begins with the production of the initial population. In this algorithm, before the production of the initial population, the best particle of the group (X
Updating position of each particle with GA algorithm
By executing the first iteration of the algorithm, the position of the best group member (X
applying crossover operator on X As shown in Fig. 6, for using the personal experience of each particle and the experience of all the group members, we used 2-point crossover operator which is considered as one of the significant functions of the genetic algorithm. Accordingly, X
Executing crossover operator on the position of the best local X and the best global X for finding the next best position or X By obtaining the position of X applying mutation operator on the particles of X As the problem relations become more complicated, we can use all four stages of the mutation operations on X In Eq. (4), the number of variables or clusters which are mutated in each chromosome is denoted by Nmu and the mutation percentage is indicated by mu. The mu rate depends on the number of the available modules in the program and is represented by nVar in the equation. In this study, the mu rate in low-module programs ranges from 0.03 to 0.05 and in high-module programs, it ranges from 0.01 to 0.02. Regarding high-module programs, if mutation is done on higher number of clusters, it leads to the collapse of the extracted clusters; Also, it will prevent the optimal clustering or leads to late access to the optimal clustering.

The list of 10 benchmark MDGs along with the number of modules and edges of the corresponding programs
Data obtained from 10 executions of PSO-GA, PSO and GA methods on the RCS, INCLE, GRAPPA and Modulizer MDGs with three different clusters’ number
Data obtained from 10 executions of PSO-GA, PSO and GA methods on the Compiler, Mtunis, Bison and Boxer MDGs with three different clusters’ number
Data obtained from 10 executions of PSO-GA, PSO and GA methods on the acqCIGNA and Ispell MDGs with three different clusters’ number
In this study, the following 10 benchmark programs, i.e. RCS, INCLE, grappa, modulizer, compiler, Mtunis, Bison, Boxer, acqCIGNA and spell were evaluated as the inputs of the three clustering algorithms of PSO, GA and the proposed PSO-GA algorithm. Each benchmark includes the MDG of the corresponding program. Edges in each MDG are considered as unweighted. Table 1 gives the characteristics of the benchmark programs. The number modules and related edges of each benchmark program were illustrated in Table 1. Each benchmark MDG was clustered by three different clustering methods which differed from one another in terms of the number of cluster. This task was done to evaluate the effectiveness of the clustering methods for fındıng the best clustering. Each experiment was executed for more than 10 times. The proposed PSO-GA clustering method was implemented in Matlab. Tables 2–4 give the results related to the best value of the clustering quality (MQ) for 10 executions of PSO, GA and the proposed PSO-GA algorithms. In this study, for comparing the performance of the different clustering algorithms, we examined the values related to the best MQ value.
Evaluating the proposed method based on the MQ criterion
Table 5 depicts the average MQ values obtained by different clustering algorithms in MDGs of different benchmark programs. It was found that all three clustering algorithms were able to identify the best software clustering when the programs included a number of modules less than 38 and the number of edges less than 180. Hence, the competition among clustering algorithms is more focused on the programs with higher number of modules and edges (real-world size programs). According to the given average MQ values in Table 5, it was observed that, PSO-GA algorithm outperformed PSO algorithm in 60% of the programs. Also, PSO algorithm outperformed GA algorithm in some of the benchmark programs. Hence, it can be argued that PSO-GA algorithm had better results than the other two algorithms and PSO had better results than GA.
The particle swarm optimization (PSO) algorithm, is a metaheuristic algorithm based on the concept of swarm intelligence; it has been successfully applied in many areas such as solving complex mathematics problems existing in engineering. In PSO algorithm, the search can be carried out by the speed of the particle. The disadvantages of PSO algorithm are that it is easy to fall into local optimum in high-dimensional space and has a low convergence rate in the iterative process. Also, low quality of the obtained solutions is the other drawback of the PSO algorithm. On the other hand, mutation and crossover are regarded as two significant operators of GA which are used for finding a spot in the search space. In order to overcome the problems of PSO and GA combination of GA and PSO can combine the advantages of PSO and GA and improve the overall performance. Combining these two algorithms together means to create a compound algorithm that has practical value. Regarding the results of our experiments, combination of PSO and GA outperforms the previous methods in the software module clustering problems. Indeed, the results confirm the higher performance of the PSO_GA in this problem (software module clustering). Table 5 depicts the quality of generated clusters by different methods. In this table the effectiveness of different method in clustering the modules of a software were directly compared.
The measured clustering quality for each method with 10 executions
The measured clustering quality for each method with 10 executions
The standard deviation among the obtained values of MQ by different clustering methods
The stability of PSO-GA, PSO and GA clustering algorithms on 10 benchmark MDGs.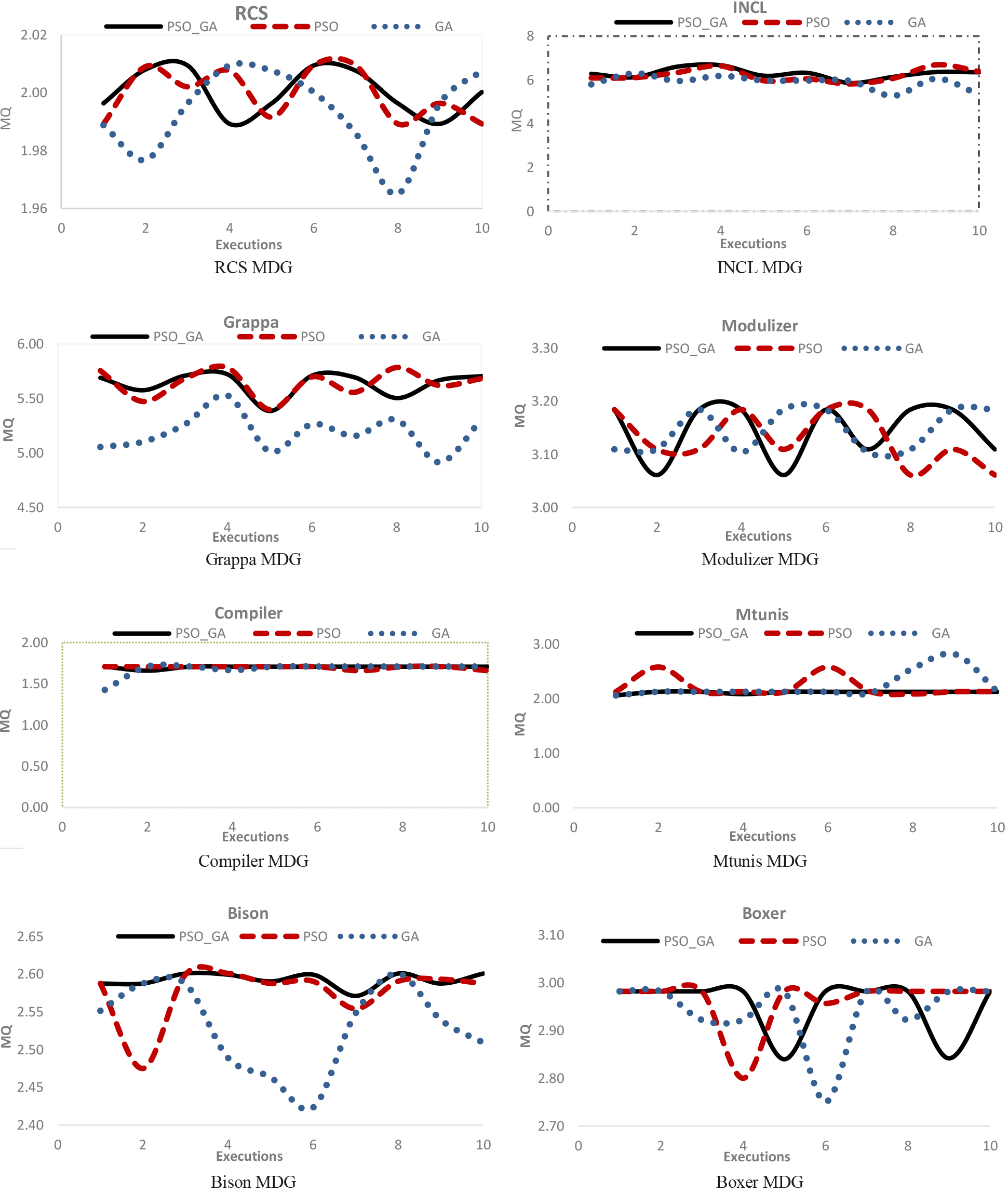
continued.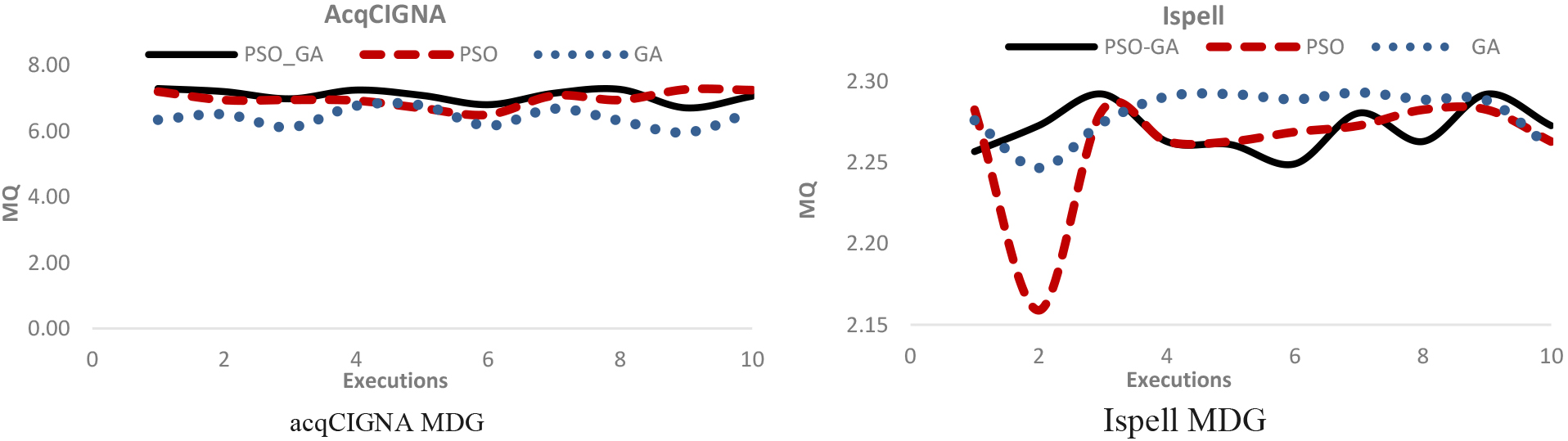
Standard deviation (SD) is one of the measures of dispersion which indicates that how far data is from the mean score or mean data. The lower the standard deviation of the given data, the lower the dispersion of the data. Hence, data stability will be high. On the other hand, a big SD stands for more dispersion and the instability of the given responses by the clustering algorithm. Table 6 shows the standard deviation among the values of MQ obtained from 10 executions of each clustering algorithms on different benchmark MDGs. given in Table 6, it can be observed that the highest stability is related to mtunis MDG with 20 modules and 67 edges in which SD value is 0. Regarding the results shown in Table 6, PSO-GA algorithm had more stability than PSO and GA algorithms in 60% of the programs. Also, it was found that the stability of data in PSO algorithm was more than that of GA algorithm. Figure 7 illustrates the curves related to the stability of different clustering algorithms on 10 benchmark MDGs in 10 times executions. In sum, it can be maintained that stability of PSO-GA algorithm was better than that of PSO and the stability results of PSO was better than those of GA algorithm.
Evaluating the proposed method based on the success rate in achieving the best clustering quality
According to the success percentage (rate) given in Table 7, it was observed that the success percentage of PSO-GA algorithm was more than that of PSO algorithm in 40% of the programs and it was more than that of GA algorithm in 50% of the programs. Also, in 30% of the programs, all the three algorithms had identical success percentage. Furthermore, in 20% of the programs, the results of PSO algorithm were better than those of GA algorithm. In 30% of the programs, GA algorithm performed better than PSO algorithm. In the columns marked by unknown, the clustering algorithms had different results in different iterations. Hence, the success percentage was not measurable in those programs. In sum, PSO-GA algorithm had better results than the other two algorithms and the success percentage of GA algorithm was 10% more than that of PSO algorithm.
Success percentage of the clustering algorithms in finding the optimal clustering
Success percentage of the clustering algorithms in finding the optimal clustering
Fast data convergence to the best response refers to the fact that clustering algorithm is able to identify the best clustering in few number of iterations. Figure 8 has depicted data convergence of PSO-GA algorithm, PSO and GA algorithms to optimal response in 10 benchmark programs. It was found that, in 90% of programs, the convergence of PSO-GA algorithm was faster than the other two algorithms. Also, convergence of PSO algorithm to optimal response was faster than that of GA algorithm. In sum, PSO-GA algorithm had faster convergence to optimal response than PSO and GA algorithms.
Convergence of PSO-GA, PSO and GA algorithms on 10 benchmark MDGs.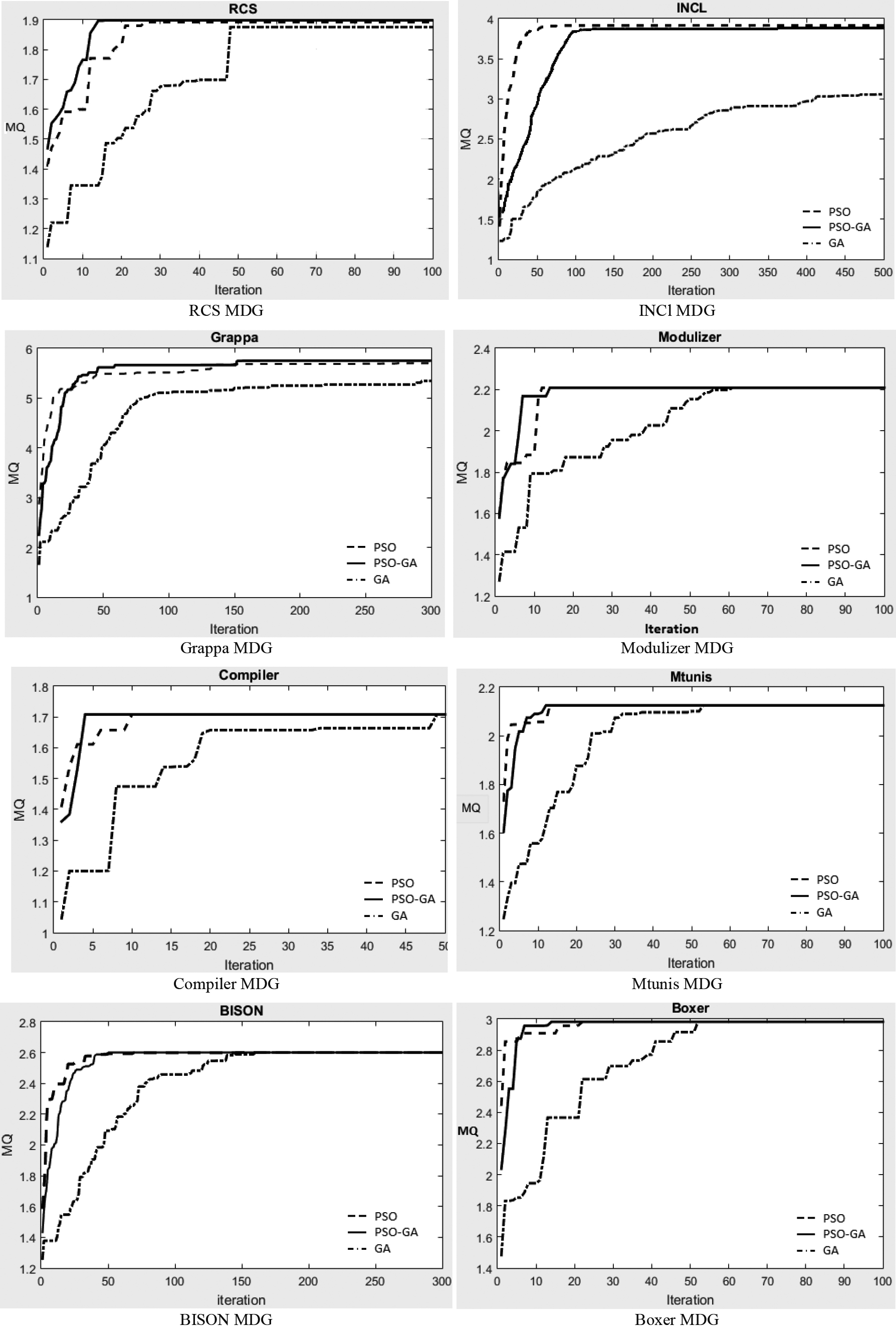
continued.
In this paper, we focused on the issue of software module clustering which refers to grouping of interdependent software modules within a group. The rationale behind software clustering was to produce clusters with the highest internal relations among the modules in a cluster (cohesion) and minimum external relations with other different clusters of the software (coupling). Identifying the best clustering is considered to be a non-definite multipurpose problem. In this paper, we introduced PSO-GA algorithm for improving data convergence speed to optima response, for enhancing data stability and for optimizing software clustering quality. We conducted experiments on 10 standard benchmark MDGs and each experiment was replicated for 10 times. Finally, the obtained results of PSO-GA algorithm were compared with those of PSO and GA. Regarding the results of experiments, the PSO-GA algorithms outperforms the other algorithms in terms of MQ, stability, success rate and convergence speed.
Drawbacks and directions for further research
On average, in 90% of the programs, the proposed method (ARAZ) using PSO-GA algorithm managed to access optimal response better than PSO and GA algorithms. However, since the proposed PSO-GA algorithm in the Incl program produced poorer responses than PSO algorithm, further research studies and experiments should be conducted for investigating the proposed algorithm on programs with higher number of modules and edges. Hence, future studies should be done on benchmark programs with more than 300 edges. Furthermore, in future studies, the proposed PSO-GA algorithm can be investigated and studied on weighted graphs. The other shortcoming of the proposed method is that the size of the generated clusters is not considered into the fitness function; hence, taking the size of clusters into account is the other future study.
This study was not funded by any third party and the authors declare that they have no conflict of interest.