
Abstract
Neuro-symbolic approaches combine neural and symbolic methods. This paper explores aspects regarding the reasoning mechanisms of two neuro-symbolic approaches, that is, neurules and connectionist expert systems. Both provide reasoning and explanation facilities. Neurules are a type of neuro-symbolic rules tightly integrating the neural and symbolic components, giving pre-eminence to the symbolic component. Connectionist expert systems give pre-eminence to the connectionist component. This paper explores reasoning aspects about neurules and connectionist expert systems that have not been previously addressed. As far as neurules are concerned, an aspect playing a role in conflict resolution (i.e., order of neurules) is explored. Experimental results show an improvement in reasoning efficiency. As far as connectionist expert systems are concerned, variations of the reasoning mechanism are explored. Experimental results are presented for them as well showing that one of the variations generally performs better than the others.
Keywords
Introduction
A research direction in Artificial Intelligence concerns the combination of two or more intelligent approaches [1, 2, 3, 4]. Each intelligent approach has advantages as well as disadvantages. In certain domains, it is necessary to exploit the advantages of multiple intelligent approaches because the advantages of a single approach do not suffice to handle the tasks or problems involving the specific domains. However, this needs to be done in a way that deals with the individual disadvantages of the intelligent approaches. This is exactly the purpose of combinations of multiple intelligent approaches, i.e., exploitation of overall benefits by surpassing individual drawbacks.
The combination of various intelligent approaches has been researched for decades. Popular combinations concern neuro-symbolic approaches [5, 6, 7], combinations of fuzzy and neural methods [8, 9, 10], combinations of neural networks with genetic algorithms [11, 12, 13], combinations of fuzzy methods with genetic algorithms [14, 15, 16], combinations of rules and genetic algorithms [17, 18, 19] and approaches combining case-based reasoning with rule-based reasoning and other intelligent methods [20, 21]. Based on the aforementioned popular combinations, one may note that usually two approaches are combined. Nevertheless, the combination of more than two approaches has also been explored [21, 22, 23, 24, 25, 26].
Neuro-symbolic approaches intend to combine the complementary features of neural networks and symbolic approaches [5, 6]. Different symbolic approaches have been combined with neural networks. Neural networks provide advantages such as ability to learn from empirical knowledge, generalization and ability to produce outputs from partially known inputs. However, they lack naturalness as it is difficult to comprehend their encompassed knowledge, modularity and the ability to provide explanations for their outputs. Symbolic approaches provide naturalness and ability to provide explanations for the conclusions. However, knowledge acquisition may be difficult resulting in certain cases into incomplete or imperfect knowledge. Another drawback of symbolic approaches may be the difficulty in reaching conclusions from partially known inputs.
An interesting aspect in neuro-symbolic approaches is to retain advantages of the integrated approaches and to provide reasoning and explanation facilities. Examples of two neuro-symbolic approaches that provide reasoning and explanation facilities are neurules and connectionist expert systems.
Neurules constitute a neuro-symbolic approach combining neural networks (i.e., the adaline unit) with symbolic rules [27]. Neurules put emphasis on the symbolic component of the integration and retain to a large degree the modularity and naturalness of symbolic rules. The source knowledge of a neurule base is a symbolic rule base [27] or empirical knowledge (i.e., training examples) [28].
Connectionist expert systems put emphasis on the neural component of the integration. The connectionist knowledge base involves cells that correspond to domain concepts but also a number of random cells that are inserted in order to handle inseparability [29, 30]. Therefore, it lacks the naturalness and modularity of rule bases.
This paper addresses aspects involving the corresponding reasoning mechanisms of neurules and connectionist expert systems that have not been explored in previous publications. More specifically, a parameter involving conflict resolution in neurule-based reasoning is the order of neurules in the neurule base. In this paper, the order of neurules in neurule bases has been adjusted according to the source knowledge of the neurule base and taking into consideration the number of symbolic rules or training examples from which each neurule derives. The results show that with the new order of neurules the performance of the neurule-based reasoning mechanism is improved. As far as connectionist expert systems are concerned, variations of the reasoning mechanism are explored providing experimental results. This paper is an extended and revised version of one presented at the Twelfth International Conference on Information, Intelligence, Systems and Applications (IISA’21) [31].
This paper is structured as follows. Section 2 outlines main aspects about neurules. Section 3 discusses the new ordering of neurules in the neurule base and presents corresponding experimental results for the reasoning mechanism. Section 4 first outlines introductory aspects about connectionist expert systems and then discusses variations of the reasoning mechanism providing experimental results. Finally, Section 5 concludes.
Neurules
Neurules are a type of hybrid rules integrating symbolic rules with neurocomputing giving pre-eminence to the symbolic component. Neurocomputing is used within the symbolic framework to improve the inference performance of symbolic rules. The constructed knowledge base retains the modularity of production rules, since it consists of autonomous units (neurules), and also retains their naturalness in a great degree, since neurules look much like symbolic rules.
(a) Form of a neurule, (b) a neurule as an adaline unit.
The form of a neurule is depicted in Fig. 1a. Each condition
where
<condition>::= <variable> <l-predicate> <value>
<conclusion>::= <variable> <r-predicate> <value>
where <variable> denotes a variable, that is, a symbol representing a concept in the domain, e.g., ‘fever’, ‘pain’, etc, in a medical domain. <l-predicate> denotes a symbolic or a numeric predicate. The symbolic predicates are {is, isnot} whereas the numeric predicates are {<, >, =}. <r-predicate> can only be a symbolic predicate. <value> denotes a value. It can be a symbol or a number. The significance factor of a condition represents the significance (weight) of the condition in drawing the conclusion(s).
Variables are discerned to input, intermediate or output ones. An input variable takes values from the user (input data), whereas intermediate or output variables take values through inference since they represent intermediate and final (output) conclusions, respectively. We distinguish between intermediate and output neurules. An intermediate (output) neurule is a neurule having an intermediate (output) variable in its conclusion.
Table 1 presents an example neurule, from a medical domain. The neurule includes five conditions. Three variables are involved in the conditions. Two of them (i.e., ‘pain’, ‘fever’) are input variables and the other one (i.e., ‘patient-class’) is an intermediate variable. The conclusion contains the output variable ‘disease-type’. All variables take symbolic values.
An example neurule from a medical domain
Neurules can be constructed either from symbolic rules thus exploiting existing symbolic rule bases [27] or from empirical data (i.e., training examples) [28]. In each process, an adaline unit is initially assigned to each intermediate and final conclusion and the corresponding training set is determined. Each unit is individually trained via the Least Mean Square (LMS) algorithm (e.g., [30]). When the training set is inseparable, more than one neurule having the same conclusion are produced. Neurules having the same conclusions are called sibling neurules. In neurule bases constructed from symbolic rule bases, each neurule usually merges two or more symbolic rules.
The conditions of each neurule are organized according to the descending order of the absolute value of their significance factors. This corresponds to the order that conditions are considered during inference. This affects positively the performance of the inference mechanism [32].
Two different inference mechanisms have been presented for neurules, that is, the symbolism-oriented process [32] and the connectionism-oriented process [28]. The symbolism-oriented process gives pre-eminence to symbolic reasoning (i.e., backward chaining) whereas the connectionism-oriented process gives pre-eminence to neurocomputing. Neurule-based inference is more efficient in terms of required computations than the inference mechanisms of symbolic rules [27] and connectionist expert systems [28]. Explanations in the form of if-then rules can be produced for the reached conclusions [32].
For each neurule, two sums are recorded during inference, that is, the ‘known sum’ and the ‘remaining sum’. The remaining sum is the sum of the absolute values of the significance factors of conditions whose value has not been determined. It represents the largest possible absolute value of the contribution of unevaluated conditions. The known sum is the sum of the product of the value of each evaluated condition and the corresponding significance factor. The output of a neurule may be determined if the absolute value of the known sum exceeds the value of the remaining sum. This means that not all conditions of a neurule need to be evaluated in order to determine its output. A neurule is fired (blocked) if its output takes the value ‘1’ (‘
The symbolism-oriented inference process is based on a backward chaining strategy. There are two stacks used, a goal stack (GS) containing the goal facts, where the current goal (Gc) is always on its top, and a rule stack (RS) containing the rules involved in the current inference session, where the current rule (Rc) under evaluation is always on its top. In addition, the working memory (WM) contains facts deriving through inference. The conflict resolution strategy, due to backward chaining and the neurules, is based on the order of neurules in the neurule base. Inference stops successfully, when one or more output rules have fired and the goal stack is empty. It stops unsuccessfully, when there are no facts (conclusions) in WM containing goal variables assigned the TRUE value and no further action can be taken.
The main steps of the symbolism-oriented process are as follows:
Set the goal(s) on GS, the initial facts in the WM and compute the initial sums for each neurule. For each goal in GS:
Find all neurules whose conclusions match Gc and put them on RS. For each neurule on RS:
Evaluate each condition of the neurule. If the variable of the condition has got a value, just update the sums of the neurule. Otherwise, the value of the variable of the condition needs to be obtained. In case of an input variable, ask the user for a value and update the sums of the neurule. In case of an intermediate variable, make it the current goal (Gc) and go to step 2.1. After evaluation of each condition, check if the neurule is fired or blocked and update accordingly the GS and WM. If WM contains any goal facts assigned a true value, return those goal facts; otherwise return failure.
In rule-based expert systems, the inference process includes conflict resolution strategies. These strategies are necessary because the inference process may need to select a specific rule from multiple applicable rules which constitute the conflict set [33]. For instance, the rule base may contain multiple rules having the same conclusion. Therefore, when pursuing a goal, conflict resolution needs to select a specific rule from the ones having the corresponding conclusion.
Various conflict resolution strategies may be applied [33, 34, 35]. They may take into consideration aspects such as the following: (i) the order of rules in the rule base [33, 35], (ii) possible priorities assigned to rules [33] or rule conclusions [35], (iii) the specificity of rules (i.e., more specific rules may be selected) [33, 34, 35], (iv) the recency of working memory items (i.e., the rule corresponding to most recent items is selected) [33, 34, 35], (v) the number of rule conditions not yet evaluated [33] and (vi) random choice of rules [34].
Conflict resolution in the symbolism-oriented process is based on the order of neurules in the neurule base. This means that from the applicable neurules in each step, the neurule preceding the others is selected.
In the experiments done in previous publications, the sibling neurules corresponding to each conclusion were ordered in the neurule base according to the order they were created from the corresponding creation mechanism. More specifically, the neurule creation mechanisms work with (sub)sets of symbolic rules [27] or training examples [28]. Whenever the corresponding training set may be successfully trained, the created neurule is inserted into the neurule base.
The order of neurules containing an output variable in their conclusion also takes into consideration the textual order of the corresponding variable value as given in the variable declaration file. For instance, in case of neurules created from available datasets, the order of variable values is according to the description files of the corresponding datasets. In backward chaining, the order of output variable values in the variable declaration file determines the order of goals in the GS and therefore, the order of examined goals.
In this paper, the order of output variable values is set according to specific criteria. In case of neurule bases constructed from symbolic rule bases, the order of output variable values is defined according to the descending order of the number of symbolic rules containing the corresponding conclusions. In case of neurule bases constructed from datasets, the order of output variable values is defined according to the descending order of the number of training examples with the corresponding output values. Note that the order of intermediate variable values does not play a role because they correspond to intermediate goals pursued when necessary. The order of neurules for each intermediate and output conclusion has also changed. In case of neurule bases constructed from symbolic rule bases, neurules are ordered for each conclusion according to the descending order of the number of symbolic rules they merge. In case of neurule bases constructed from datasets, neurules are ordered according to the descending order of the number of success examples in their training set. A success example in the training set of a neurule is a training example whose output value corresponds to the conclusion of the neurule. Two examples will be given to explain these aspects.
Let us suppose that a neurule base is constructed from a symbolic rule base in a medical domain and the output variable ‘disease’ takes, among others, the values ‘primary-malignant’, ‘arthritis’ and ‘secondary-malignant’. The symbolic rule base contained ten, five and three symbolic rules with the conclusions ‘disease is primary-malignant’, ‘disease is arthritis’ and ‘disease is secondary-malignant’, respectively. For each of these three conclusions, two neurules are produced. This means that six neurules are produced from the eighteen symbolic rules. The neurules containing the conclusion ‘disease is primary-malignant’ appear before the neurules containing the other two conclusions. They are followed by the neurules containing the conclusion ‘disease is arthritis’ and after them appear the neurules containing the conclusion ‘disease is secondary-malignant’. Two neurules are created from the ten symbolic rules with the conclusion ‘disease is primary-malignant’. One of them merges six symbolic rules and the other one merges four symbolic rules. The former neurule appears before the latter. Neurules corresponding to the other two conclusions mentioned in this example are ordered similarly. Table 2 depicts the neurules produced from the aforementioned symbolic rules along with neurules whose conclusions contain the intermediate variable ‘patient-class’. The numbering in the names of the neurules whose conclusions contain the output variable ‘disease’ (i.e., NR
Neurules produced from the symbolic rules in the example
Neurules produced from the symbolic rules in the example
The conclusions, neurules and number of success examples for neurules in Table 2 (order as specified in this paper)
Note that for the output variable ‘disease’, the textual order of the corresponding variable values as given in the variable declaration file is as follows: (i) ‘arthritis’, (ii) ‘primary-malignant’ and (iii) ‘secondary-malignant’. Therefore, according to the previous order of neurules, the two neurules containing the conclusion ‘disease is arthritis’ would appear before the other four neurules. They are followed by the two neurules containing the conclusion ‘disease is primary-malignant’ and last appear the two neurules containing the conclusion ‘disease is secondary-malignant’. The actual order of each couple of neurules as produced from the conversion mechanism does not differ from the previous case. Therefore, according to the previous order and using the aforementioned rule names, the specific neurules would appear in the neurule base as follows: NR
Let us consider another example concerning the lenses dataset of the Machine Learning repository [36] consisting of twenty-four training examples. The specific dataset is used to determine if a patient should be fitted with hard contact lenses or soft contact lenses or if no contact lenses are needed. The dataset consists of four input variables and an output variable. The input variables are the age of the patient (i.e., young, pre-presbyopic, presbyopic), the spectacle prescription (i.e., myope, hypermetrope), whether the person is astigmatic or not and the tear production rate (i.e., normal, reduced). The output variable (lenses-class) takes three values: ‘hard-lenses’, ‘soft-lenses’ and ‘no-lenses’. One neurule is constructed for each one of the conclusions ‘lenses-class is hard-lenses’ and ‘lenses-class is soft-lenses’ (i.e., the corresponding training sets are separable). Two neurules are constructed for the conclusion ‘lenses-class is no-lenses’ (i.e., the corresponding initial training set is inseparable). The number of training examples in the dataset having the first, second and third output value is four, five and fifteen, respectively. This means that the neurules containing the conclusion ‘lenses-class is no-lenses’ appear first followed by the neurule containing the conclusion ‘lenses-class is soft-lenses’. Last appears the neurule containing the conclusion ‘lenses-class is hard-lenses’. Two neurules are created for conclusion ‘lenses-class is no-lenses’ after splitting the initial training set into two subsets, subset1 and subset2. Subset1 contains four success examples and subset2 contains eleven success examples [37]. Therefore, the neurule created from subset2 appears before the neurule created from subset1. Table 4 depicts the corresponding neurules. The numbering in the names of the neurules (i.e., NR
Neurules produced from the lenses dataset (order as specified in this paper)
The conclusions, neurules and number of success examples for neurules in Table 4 (order as specified in this paper)
The previous order of the specific neurules created from the lenses dataset would have taken into account the order of output variable values mentioned in the available description for the specific dataset in the Machine Learning repository [36]. More specifically, the order of the output variable values mentioned in the available description in the repository is the following: (i) ‘hard-lenses’, (ii) ‘soft-lenses’ and (iii) ‘no-lenses’. This means that according to the previous order, the neurule containing the conclusion ‘lenses-class is hard-lenses’ would appear first, second would appear the neurule containing the conclusion ‘lenses-class is soft-lenses’ and then would appear the two neurules containing the conclusion ‘lenses-class is no-lenses’. As far as the order of the last two neurules is concerned, the neurule produced from the aforementioned subset1 would precede the neurule produced from subset2. Therefore, using the rule names in Table 4, the order of the produced neurules would have been the following: NR
The conclusions, neurules and number of success examples for neurules in Table 4 (previous order)
Experiments were run to examine how the new order of neurules in the neurule base affects reasoning performance compared to the previous order of neurules. The experiments were run in nine neurule bases constructed using a neurule-based expert system tool [38]. Information about these neurule bases is given in the following.
Two neurule bases (i.e., NRB1, NRB2) were created through conversion of two equivalent symbolic rule bases involving a medical domain. NRB1 contains 39 neurules created from 68 symbolic rules. NRB2 contains 85 neurules created from 134 symbolic rules. NRB1 includes intermediate and output conclusions whereas NRB2 includes only output conclusions.
The other seven neurule bases were created from datasets available in the Machine Learning repository [36]. The datasets used were car, lenses, monks-1-train, monks-2-train, monks-3-train, nursery and tic-tac-toe. All of them have input variables, one output variable and no intermediate variables. For the creation of the specific neurule bases, the clustering approach with the settings giving the best results was used as described in [37].
Characteristics of rule bases or datasets used to construct the neurule bases
Results for performance of neurule-based symbolism-oriented inference (set {1,
Table 7 outlines the characteristics of datasets and symbolic rule bases used to create the neurule bases. “RB1” and “RB2” denote the two medical symbolic rule bases. For each dataset or symbolic rule base, Table 7 shows the number of input variables, the total number of conditions containing input variables, the total number of discrete values of the intermediate variables (i.e., number of intermediate conclusions) and the total number of discrete values of the output variable (i.e., number of output conclusions). Right after the name of each dataset, the corresponding number of training examples of the dataset is shown within parentheses.
Table 8 presents results for the symbolism-oriented inference process concerning the set {1,
The set {1 (true), 0 (false), 0.5 (unknown)} of input values may be used besides the set {1,
Results for performance of neurule-based symbolism-oriented inference (set {1, 0, 0.5})
Connectionist expert systems as introduced in [29, 30] put emphasis on the neural component. The connectionist knowledge base is constructed from available training examples and dependency information. Dependency information determines the input/intermediate concepts each intermediate/output concept depends on. Training is done for each intermediate/output concept separately using training sets that are created according to the available dependency information. Random cells are introduced in cases of inseparability. Therefore, the overall connectionist knowledge base includes cells that correspond to input/intermediate/output domain concepts and random cells that do not correspond to domain concepts and have no meaning to the user.
As an example, a part of a connectionist knowledge base is given as well as its construction. Let us suppose that a connectionist knowledge base is to be constructed corresponding to the neurules shown in Table 2. The specific connectionist knowledge base contains three output cells, five intermediate cells and input cells corresponding to the domain concepts and based on the available dependency information. The output cells correspond to the output conclusions ‘disease-type is primary-malignant’, ‘disease-type is arthritis’ and ‘disease-type is secondary-malignant’. The five intermediate cells correspond to the intermediate conclusions ‘patient-class is human0-20’, ‘patient-class is human21-35’, ‘patient-class is human36-55’, ‘patient-class is woman36-55’ and ‘patient-class is human56’. The input cells correspond to the conditions containing the input variables ‘fever’, ‘pain’, ‘antinflam-reaction’, ‘joints-pain’, ‘gender’ and ‘age’.
The training sets for each intermediate/output cells were created from training sets derived in the construction process of neurules from symbolic rules. More specifically, the training examples of the combined truth table for each intermediate/output conclusion were used [27]. A simple example will be given to explain this. Let us suppose that there are only two symbolic rules R
A graphical depiction of a part of a connectionist knowledge base.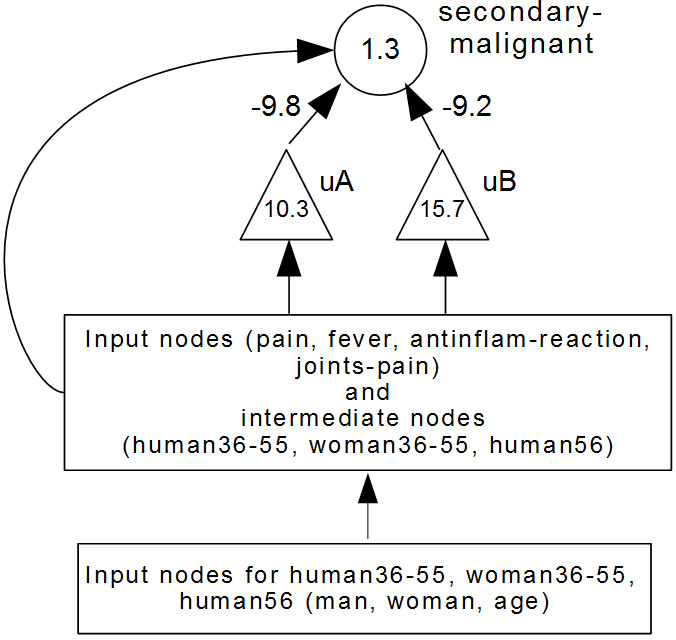
Due to inseparability, random cells need to be inserted among each of the three output cells and the corresponding inputs. The inputs to each output cell are its corresponding inputs as defined in the dependency information of the domain along with the corresponding random cells [29, 30]. Figure 2 graphically depicts the part of the connectionist knowledge base including the output cell ‘disease-type is secondary-malignant’, the two random cells and their corresponding inputs. Table 10 depicts in the form of a matrix the corresponding part of the connectionist knowledge base. The first row of the table depicts the names of intermediate and output cells whereas the first column depicts the names of input and intermediate cells. The names ‘Int. var1 (uA)’ and ‘Int. var1 (uB)’ correspond to random cells and have no meaning to the user.
A part of a connectionist knowledge base depicted in the form of a matrix (corresponding to Fig. 2)
The following two sections present alternative inference mechanisms for connectionist expert systems already introduced in literature and unexplored aspects involving them along with experimental results.
Two alternative inference mechanisms for connectionist expert systems have been presented. These involve MACIE presented by Gallant in [29, 30] and the recency inference engine (RIE) presented by Ghalwash in [39]. Both inference mechanisms use a goal stack to store pursued goals and the working memory to store facts. For each intermediate/output cell, the known and remaining sums are recorded.
The main steps of these inference mechanisms are as follows. The user is asked to provide input data prior the beginning of inference and when necessary during inference. When the value of an input/intermediate cell becomes known during reasoning, the known and remaining sums of all affected cells in the knowledge base are updated accordingly. The goal stack and working memory are also updated. After updates are done and output goals remain in the goal stack, the mechanisms focus on a specific intermediate/output cell and pursue the corresponding goal (backward chaining). The two mechanisms differ in how to determine the cell for which backward chaining will be performed. For this purpose, MACIE uses the ‘confidence measure’ [29, 30] whereas RIE uses the ‘firing ratio’ [39]. These aspects will be explained in the following.
For cells with known outputs, the confidence measure is equal to their actual output. For unknown input cells, the confidence measure is equal to zero. The confidence measure for each unevaluated (intermediate or output) cell is computed based on the confidence measures of their inputs and the corresponding weights. More specifically, it is equal to the ratio of: (a) the sum of the product of the confidence measure of each input and the corresponding weight to (b) the sum of the absolute values of all input weights corresponding to cells whose value has not been determined. MACIE checks only the unevaluated output cells to find the one with the maximum absolute value of the confidence measure. Backward chaining is performed based on the specific output cell.
The firing ratio for each cell is defined as the ratio of the absolute value of the known sum to the remaining sum. All unevaluated intermediate and output cells are checked to find the one with the maximum firing ratio. Therefore, MACIE focuses only on output cells to start backward chaining whereas RIE focuses on both intermediate and output cells. The firing ratio may be computed independently for each cell whereas the confidence measure requires the computation of the confidence measures of all input cells.
The performance of MACIE and RIE were compared by Ghalwash in [39] using two small connectionist knowledge bases. The comparison was done in terms of the convergent rate. In [28], MACIE and RIE were compared in terms of the required computations to produce the output and the convergent rate. Six connectionist knowledge bases created from datasets and symbolic rule bases were used for this comparison. The set of input values used in these experiments was {1,
Unexplored aspects regarding the inference mechanisms of connectionist expert systems
In this section, various unexplored aspects regarding the reasoning mechanisms of connectionist expert systems are discussed. Corresponding experimental results are given. For these experiments, six connectionist knowledge bases were constructed following the procedure described in [29, 30]. Six corresponding datasets were used for these experiments. It should be mentioned that the same datasets were also used in [28] in the experiments involving MACIE and RIE. This enables a comparison with the results presented in this paper.
Two datasets were derived from the two medical rule bases used in the previous section. These datasets were created from training sets derived in the construction process of neurules from symbolic rules. More specifically, the training examples of the combined truth table for each intermediate/output conclusion were used [27].
A further dataset involves the acute dataset introduced in [29, 30]. The specific dataset involves six input variables, two intermediate conclusions and three output conclusions. The other three datasets are the lenses, car and nursery datasets from the Machine Learning repository [36]. For the car and nursery datasets dependency information provided by their donators was also used [40]. This facilitates the creation of the connectionist knowledge bases which is not a straightforward process. The knowledge bases for the car and nursery datasets using the dependency information are named ‘Car-dep’ and ‘Nursery-dep’ in the remaining part of this paper. The dependency information for the car dataset involves three intermediate variables each one taking four symbolic values. This results into twelve intermediate conclusions. The dependency information for the nursery dataset involves four intermediate variables. One of them takes four symbolic values whereas each one of the other three intermediate variables takes three symbolic values. This results into thirteen intermediate conclusions.
An unexplored aspect is to provide experimental results comparing MACIE and RIE for the alternative set of input values {1, 0, 0.5}. For this purpose, experiments were run for this set of input values. The connectionist knowledge bases were constructed using the {1, 0, 0.5} set of values. The inference mechanisms used this set of values to produce outputs.
Experimental results for the {1, 0, 0.5} set of values are presented in Tables 11 and 12. The initials “CKB” stand for connectionist knowledge base. The experimental results involve the mean number of required computations, the mean number of required inputs and the convergent rate. Computations involve the mean number of times that a product of a weight and a corresponding input value were added to the known (weighted) sum of a node The additional computations required in MACIE for the calculation of confidences are displayed besides the “
Results for performance of MACIE (set {1, 0, 0.5})
Results for performance of MACIE (set {1, 0, 0.5})
Results for performance of RIE (set {1, 0, 0.5})
The results concerning the convergent rate show that the performance of the two mechanisms is close. The convergent rate was computed using the number of given inputs and the number of input concepts in produced explanation rules. MACIE performs slightly better in one knowledge base. These results show that in certain cases, MACIE may perform better than RIE in terms of the convergent rate for the {1, 0, 0.5} set of values. In this aspect, the results are similar to the ones reported in [28] for the {1,
We run experiments for variations of MACIE to record how the performance is affected. To the best of our knowledge, four of these variations have not been mentioned by other researchers whereas the other one was mentioned in [29] but not tested.
As already mentioned, MACIE focuses on the output cells to find the one with the maximum confidence and then perform a type of backward chaining. Two variations were tested regarding the aforementioned aspect, that is, which cells will be checked to find the one with the maximum confidence. The former, named henceforth ‘MACIE-variation-1’, checks all unevaluated intermediate and output cells. The latter, named henceforth ‘MACIE-variation-2’, checks only the recently triggered intermediate and output cells. Therefore, MACIE-variation-2 resembles RIE but uses the confidence measure instead of the firing ratio.
Tables 13 and 14 provide results for MACIE-variation-1 and MACIE-variation-2, respectively for the {1, 0, 0.5} set of values. One may note that the results for MACIE and MACIE-variation-1 are close. MACIE-variation-1 requires slightly less computations in three knowledge bases (i.e., acute, lenses, nursery-dep) and slightly more computations in two knowledge bases (i.e., kb1, car-dep). In one knowledge base (i.e., kb2), the results are essentially the same. MACIE-variation-2 gives the same results as MACIE-variation-1 in four knowledge bases and almost the same results in the other two knowledge bases. Compared to MACIE, MACIE-variation-2 gives similar results as MACIE-variation-1. As far as the convergent rate is concerned, all three approaches provide almost the same results in five knowledge bases and in one knowledge base (i.e., kb1), MACIE is slightly better. Therefore, none of the three approaches outperforms the other two in all the knowledge bases. An interesting aspect is to compare the results for MACIE-variation-2 and RIE because MACIE-variation-2 resembles RIE. One may note that the results for these two methods are identical in four knowledge bases if the computations for the confidence measure are not taken into account. In the other knowledge bases, the results are very close for both methods.
Results for performance of MACIE-variation-1 (set {1, 0, 0.5})
Results for performance of MACIE-variation-2 (set {1, 0, 0.5})
Results for performance of MACIE-variation-1 (set {1,
Results for performance of MACIE-variation-2 (set {1,
Tables 15 and 16 provide results for MACIE-variation-1 and MACIE-variation-2, respectively for the {1,
A further variation of MACIE was mentioned but not tested in [29]. This involves the following aspect. As mentioned above, during inference MACIE checks the output cells to find the one with the maximum absolute value of the confidence measure. A variation is to examine the mere value of each confidence measure and not the absolute value. For this variation it is mentioned in [29] that the results will not be very different compared to the typical approach. This variation of MACIE will be henceforth named ‘MACIE-variation-3’. We run experiments for MACIE-variation-3 using the aforementioned six connectionist knowledge bases.
Results for performance of MACIE-variation-3 (set {1,
Table 17 presents results for MACIE-variation-3 for the {1,
Results for performance of MACIE-variation-3 (set {1, 0, 0.5})
Table 18 presents results for MACIE-variation-3 for the {1, 0, 0.5} set of values. Compared to the performance of MACIE, the performance of MACIE-variation-3 is better in two knowledge bases (i.e., kb2 and nursery-dep), the same in one knowledge base (i.e., acute), roughly the same in two knowledge bases (i.e., car-dep, lenses) and worse in one knowledge base (i.e., kb1). Compared to the performance of MACIE-variation-1 and MACIE-variation-2, the performance of MACIE-variation-3 is better in three knowledge bases (i.e., nursery-dep, car-dep, kb2), roughly the same in two knowledge bases (i.e., kb1, acute) and slightly worse in one knowledge base (i.e., lenses). Once again, from the results it seems that MACIE-variation-3 is a more promising variation of MACIE compared to MACIE-variation-1 and MACIE-variation-2.
The basic idea of MACIE-variation-3 may be used in combination with the main ideas of MACIE-variation-1 and MACIE-variation-2. Henceforth, MACIE-variation-1b and MACIE-variation-2b will be named the respective variations of MACIE. In MACIE-variation-1b, all intermediate/output cells will be checked to find the one with the maximum value of the confidence measure. In MACIE-variation-2b, the recently triggered cells will be examined to find the one with the maximum value of the confidence measure. We run experiments for MACIE-variation-1b and MACIE-variation-2b for both sets of input values.
Results for performance of MACIE-variation-1b (set {1,
Table 19 presents results involving MACIE-variation-1b for the set of {1,
Results for performance of MACIE-variation-1b (set {1, 0, 0.5})
Table 20 presents results involving MACIE-variation-1b for the set of {1, 0, 0.5} values. Compared to MACIE-variation-1, the results for MACIE-variation-1b are exactly the same in one knowledge base (i.e., acute), roughly the same in three knowledge bases (i.e., kb2, lenses, nursery-dep), slightly better in one knowledge base (i.e., car-dep) and slightly worse in one knowledge base (i.e., kb1).
Results for performance of MACIE-variation-2b (set {1,
Table 21 presents results involving MACIE-variation-2b for the set of {1,
Results for performance of MACIE-variation-2b (set {1, 0, 0.5})
Table 22 presents results involving MACIE-variation-2b for the set of {1, 0, 0.5} values. Compared to MACIE-variation-2, the results are better in one knowledge base (i.e., car-dep), worse in one knowledge base (i.e., nursery-dep) and roughly the same in three knowledge bases (i.e., kb1, kb2, acute, lenses).
Results for performance of all MACIE approaches (set {1,
Table 23 presents results involving all MACIE approaches for the set of {1,
Average results for all MACIE approaches (set {1,
Table 24 presents the average results for all MACIE approaches for the {1,
Results for performance of all MACIE approaches (set {1, 0, 0.5})
Table 25 presents results involving all MACIE approaches for the set of {1, 0, 0.5} values. The picture is not clear as in the case of the results involving the {1,
Average results for all MACIE approaches (set {1, 0, 0.5})
Table 26 presents the average results for all MACIE approaches for the {1, 0, 0.5} set of values. On average, MACIE-variation-3 gives the best results for mean number of computations and mean asked inputs followed by MACIE. On average, MACIE gives the best result for the convergent rate closely followed by MACIE-variation-3. The average performance of MACIE-variation-3 is affected by its performance in nursery-dep in which it clearly outperforms the other approaches.
This paper discusses aspects regarding the reasoning mechanisms of neurules and connectionist expert systems. These aspects had not been previously explored. More specifically, the order of each neurule is adjusted according to the number of symbolic rules or training examples constituting its source knowledge. This plays a role in conflict resolution during backward chaining. The experimental results show that the performance of the reasoning mechanism is improved.
As far as connectionist expert systems are concerned, five variations of MACIE are explored. More specifically, two variations are presented in this work for the first time. The third one was mentioned in [29] without providing experimental results. The fourth and fifth variations, also presented in this work for the first time, combine the ideas of the first two variations and the third one. To the best of our knowledge, the four of the five variations have not been mentioned in the work of other researchers whereas the other one was mentioned and not tested in previous work.
The experiments showed that none of the alternative versions of MACIE outperforms the others in all cases. However, the third variation performs better than the others in most cases. The experiments were performed using two alternative set of values (i.e., {1,
There are two main directions for future research. One direction concerns the use of combined intelligent approaches in medicine. Combined approaches may be used in various medical domains due to the existence of symbolic and empirical knowledge. The other direction concerns the use of combined intelligent approaches in the construction of an intelligent educational system addressed to early childhood. Few intelligent educational systems addressed to early childhood have been developed [41]. Combined intelligent approaches satisfy the knowledge representation requirements of intelligent educational systems [42, 43].