
Abstract
Learning algorithms are often equipped with kernels that enable them to deal with non-linearities in the data, which ensures increased performance in practice. However, traditional kernel based methods suffer from the problem of scalability. As a workaround, explicit kernel maps have been proposed in the past. Previously for the task of streaming Kernel Principal Component Analysis (KPCA), an explicit kernel map has been combined with a matrix sketching technique to obtain scalable dimensionality reduction (DR) algorithm. This algorithm is limited by two issues, both pertaining to the explicit kernel map and the matrix sketching algorithms respectively. As a solution, two new scalable DR algorithms called ECM-SKPCA and Euler-SKPCA are proposed. The efficacy of the proposed algorithms as scalable DR algorithms is demonstrated via the task of classification with many publicly available datasets. The results indicate that the proposed algorithms produce more effective features than the previous algorithm for the classification task. Furthermore, ECM-SKPCA is also demonstrated to be much faster than all other algorithms.
Introduction
The technique of Principal Component Analysis (PCA) has been used successfully for DR in many applications such as change detection in satellite images [1, 2], analysis of gene expression data [3], stellar spectral classification [4] etc. The simplicity and power of this technique has made it very popular among the data mining practitioners. However, PCA is not capable of capturing non-linearities in the data well, which results in poor performance in certain datasets. To address this issue, Schölkopf et al. [5] proposed a non-linear variant of PCA called KPCA. KPCA has gained popularity due to its ability to discover Principal Components (PCs) from data of complex non-linear nature more effectively than PCA. This algorithm has been deployed in a number of applications like face recognition [6], stock price prediction [7], non-linear process monitoring [8] etc.
Both algorithms discover PCs for the data in a similar manner. The main difference between PCA and KPCA arises in the domain in which the algorithms operate. In PCA, works on the data in its input space, whereas, KPCA works on the data in a very high dimensional space or feature space. KPCA proceeds by applying a non-linear function to the given data, and then discovering the PCs similar to the PCA algorithm. This non-linear map,
KPCA first involves transforming the data in the input space to a higher dimensional space (feature space),
where
Obtain the kernel matrix by applying the kernel function on all pairs of data points.
Center the kernel matrix in the feature space so that its mean is zero. Here matrix
Eigen decompose the kernel matrix in order to obtain the PCs.
Re-represent the data by projecting the data points on to the PCs obtained.
Kernelized versions of many machine learning algorithms have emerged in the past, among these are KPCA, kernel ridge regression (KRR), kernel based clustering. Despite its popularity, kernel based algorithms suffer from scalability issue. KPCA requires huge amounts of computational time and space when the data is large (number of examples are typically of the order of a few thousands). For a matrix
Besides, the scalability issue, when data is arriving in a streaming manner, it is no longer possible to apply the standard KPCA algorithm. Explicit feature maps such as Random Fourier Features (RFF) have emerged as an effective alternative. They serve as approximations to some well known kernel functions. RFF has a parameter
RFF-SKPCA is affected by the problems of RFF and FD. The RFF kernel map is associated with a time-accuracy trade-off which is influenced by its parameter
In this work the issues related to the time-accuracy trade-off and matrix sketching part of the previous work are addressed. The proposed algorithms make use of accurate kernel maps Explicit Cosine Map (ECM) and Euler kernel map that were recently proposed by [11] and the
The main contributions of this work are as follows.
Fast and accurate SKPCA algorithms called ECM-SKPCA and Euler-SKPCA are proposed. The benefits of using the proposed methods over RFF-SKPCA for scalable DR is demonstrated via classification tasks.
In this work, the proposed scalable DR algorithms are used as feature extraction algorithms. For the evaluation of the proposed algorithms, a linear classifier is used. A linear classifier is used in order to demonstrate the influence of the kernel part of the algorithms being compared. Large datasets (
Related work
In this section, we review dimensionality reduction methods that include linear and non-linear (kernel based) methods that are applicable to large datasets.
Linear methods
Incremental PCA (IPCA) [12, 13] is popular method to perform dimenisonality reduction in a streaming fashion. It estimates the eigenvectors by considering the datapoints one at a time. The advantage of this approach is that the whole data need never be stored, instead its features are extracted in a streaming manner. This approach is particularly useful in datasets with very large number of instances. Sparse PCA (SPCA) [14] is another approach to perform dimensionality reduction. In SPCA, the eigenvectors are constrained to have at the most
Non-linear methods
KPCA is a non-linear extension of PCA. It has been demonstrated to extract representative features from complex datasets. However, KPCA suffers from scalability issues due to its
RFF
Rahimi and Recht [15] proposed an explicit feature map called RFF. It is based on Bochner’s theorem, that relates a positive definite function with a positive measure. For a Gaussian kernel is given in Eq. (2), its Fourier transform is
given in Eq. (3), which is a positive measure and hence a probability distribution by Bochner’s theorem.
Let
The second last equation is obtained using Monte-Carlo sampling for integration. An explicit map
The RFF kernel map is defined as follows.
Here, let
Variants of RFF: Few variants that improve the speed of the kernel mapping have been proposed in the past. These include Fastfood [16], Orthogonal Random Features (ORF) [17], Structured ORF (SORF) [17]. The kernel mapping time of the variants are as follows. Fastfood has runtime
Ghashami et al. [9] showed that RFF can be used in conjunction with FD in order to perform SKPCA. There are two main tasks in RFF-SKPCA.
Kernel mapping part using RFF Sketching using FD
Let the original data point be denoted by
Here
This explicit kernel map was first proposed by Liwicki et al. [18]. It is basically a map
Here
First, the issues associated with the kernel mapping part are described. Lopez-Paz et al. [19] proved that
The second issue concerns the effectiveness of FD in computing PCs. Accurately discovering PCs is an important part of SKPCA. This in turn ensures that the features obtained after projecting the data points on to the PCs are good enough for the successful application of some learning task such as classification. The nature of data also plays a significant role in determining how well FD performs. As demonstrated by Francis and Raimond [10],
The vanilla Euler kernel map [18] has three issues associated with it. The first issue has to do with its complex valued mapping. Since the output (mapped data points) are complex-valued, they cannot be used straightforwardly in learning algorithms that expect real-valued inputs. The second issue has to do with the redundancy involved in storing the same information in the real and imaginary parts of the complex-valued input. This implies that
The third has to do with the lack of involvement of all the attributes in the final mapped output. The vanilla Euler map simply associates a mapped output (
The first issue associated with previous kernel based sketching algorithm is the requirement of large
Complex-valued mapping: The solution is to use a real-valued mapping instead.
Redundancy in storage: This can be remedied by using just the real part of the kernel map.
Lack of involvement of attributes: This can be solved by applying a linear map (
where
The second issue is the lack of effectiveness of FD in producing good PCs. The construction of accurate sketches is crucial in discovering good PCs. FD is less accurate sketching method than
As discussed by [11], ECM can overcome the limitations of RFF. It takes the following form.
Here
The time taken to apply ECM to a
The Euler kernel mapping is done as follows. The time required to apply the map to a
In this section, the proposed algorithms, ECM-SKPCA and Euler-SKPCA are explained in detail.
ECM-SKPCA
The steps are given in Algorithm 3.1. First, the matrix
where
[H] : ECM-SKPCA
Euler kernel map can also be used to map data points to the kernel space. The SKPCA algorithm with Euler kernel map is referred to as Euler-SKPCA. The ApplyFeatureMap() applies the Euler kernel map of Equation (13) to the data points. The rest of the steps are the same as in Algorithm 3.1.
Experimental evaluation
In this section the effectiveness of the proposed kernel based sketching algorithms as feature extraction techniques is demonstrated. First, the features are extracted using the algorithms:
Setup
All experiments were carried out in a Linux machine with 1.7GHz Intel Core i3 processor and 4GB of RAM. The code was written in Python. The matrix sketching algorithms,
Datasets used and their characteristics
The datasets used for the evaluation of the algorithms are described below. The description of the datasets are given in Table 1.
Datasets and their characteristics
Datasets and their characteristics
Coding-Ribonucleic acid (COD-RNA) [20]: It contains 488565 genome sequences, each having 8 attributes. The number of class 0 instances and class 1 are 325710 and 162855 respectively. PPMI [21]: This dataset contains 3684 patient records, out of which 1333 belong to class 0 and 2351 belong to class 1. The number of attributes in this dataset is 34. The dataset can be downloaded from HTTP: This dataset contains 200000 instances, out of which 160555 belong to class 0 and 39445 belong to class 1. The number of attributes in the dataset is 41. The dataset can be obtained from UCI repository [22]. Spam: This dataset contains spam as well as normal (ham) messages. It can be downloaded from Usenet: This dataset contains email messages that belong either of 2 classes. It can be downloaded from ISOLET [23]: This dataset contains spoken English recordings of 30 speakers. 26 classes in this dataset with a total of 7797 instances. Data belonging to classes 1 and 15 were used in this work. The number of instances of classes 1 and 15 are 240 and 240 respectively. The size of the dataset used is HAR [24]: It contains data belonging to 6 classes with a total of 10299 instances. Size of the dataset is MNIST [25]: It contains data belonging to 10 classes and the total number of instances is 70000. Data belonging to classes 1 to 10 were used in this work. The size of the dataset used is PeMS SF [26]: This dataset contains 963 columns and 63360 rows.
There are two kinds of results that are considered: Classification accuracy and the time taken to run the algorithms.
(a) Classification accuracy
Comparison of accuracy for various values of 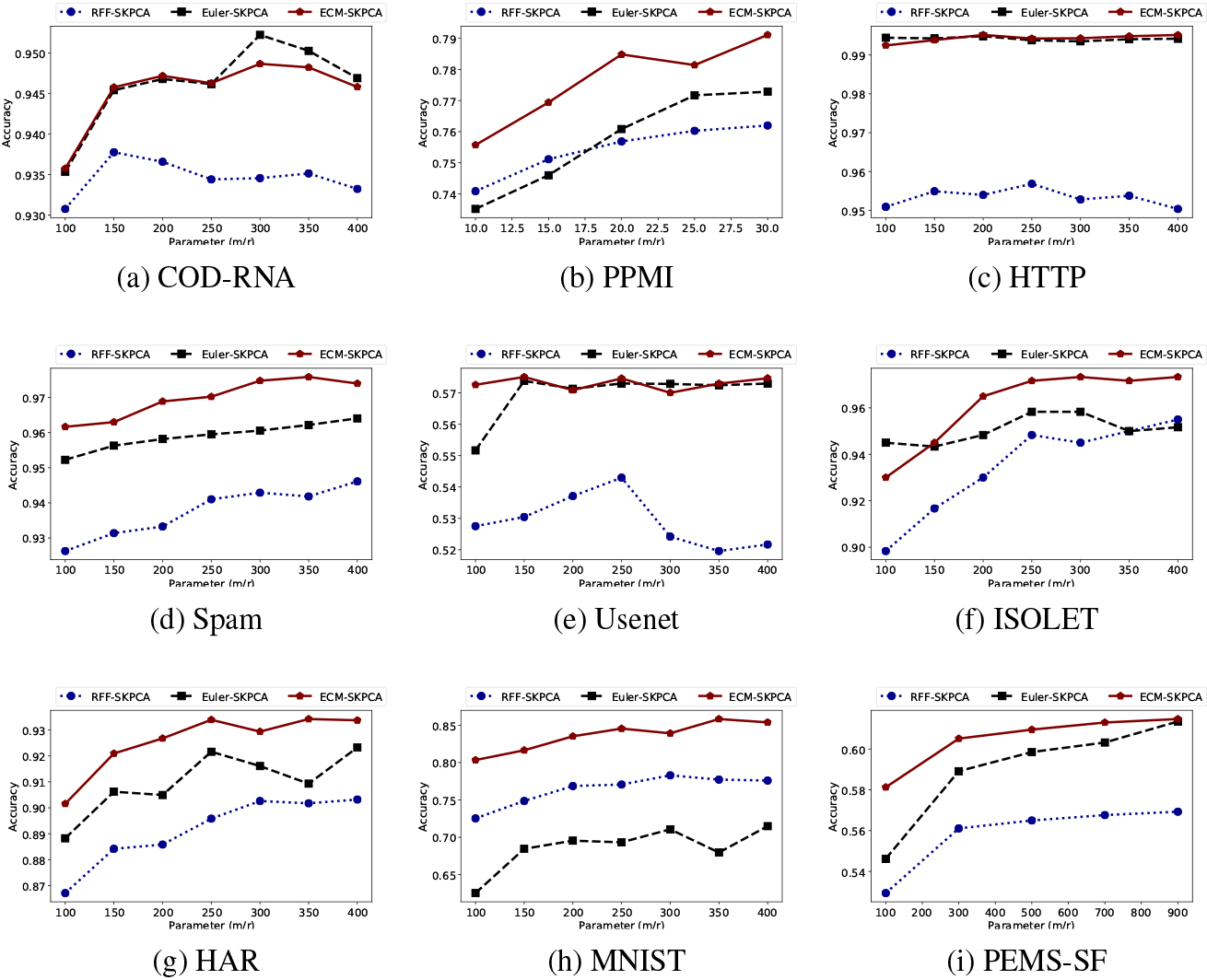
After the feature extraction is done on the datasets, the classification accuracy on the test set is recorded. Each feature extraction algorithm has a parameter
For large as well as small datasets, the combination the proposed algorithm ECM-SKPCA and SVM obtains the best accuracy for all values of
In the case of RFF-SKPCA, it can be observed that it obtains lower accuracy than ECM-SKPCA on all datasets, for all values of
Variation of feature extraction time with parameter (
Summary of best accuracy obtained for each dataset
In this section, the time taken to extract the features is measured for each value of the parameter
In the previous section, it was confirmed that ECM-SKPCA is indeed the fastest algorithm. In the task of scalable dimensionality reduction using approximation schemes, there is always a trade-off between the time to run and the performance of the algorithm (in terms of error or accuracy). In this work, an approach to achieve a scalable dimensionality reduction method has been demonstrated to be effective in terms of classification accuracy, while being faster than a previous related approach. The summary of best classification accuracy obtained by all the algorithms and corresponding values of
Good overall classification accuracy: In all datasets, ECM-SKPCA + SVM obtains the best classification accuracy. This is confirmed by the results in Fig. 1 and Table 2. Euler-SKPCA
Better classification accuracy time trade-off: The experimental results indicate that good accuracy of classification is obtained by ECM-SKPCA + SVM for even small values of
Faster: The proposed algorithm, ECM-SKPCA is clearly the fastest algorithm, while Euler-SKPCA is the slowest. This is confirmed by the results in Fig. 2. This speedup has been achieved as a result of using a faster kernel map.
Kernel based DR algorithms are useful in extracting meaningful features from complex datasets. An existing algorithm, RFF-SKPCA combines the power of kernels and a matrix sketching algorithm, FD for performing DR. This algorithm requires the parameter
Footnotes
Acknowledgments
This publication is an outcome of the R&D work undertaken project under the Visvesvaraya PhD Scheme of Ministry of Electronics and Information Technology, Government of India, being implemented by Digital India Corporation.