
Abstract
In computer vision, the recognition of expressions from partially occluded faces is one of the serious problems. By the prior recognizing techniques it can solve the issue by various assumptions. A benchmark-guided branch was proposed for detecting and eliminating the manipulated features from the occluded regions since the human visual system is proficient for eliminating the occlusion and the appropriate focal point was obtained on the non-occluded areas. In recent years deep learning has attained a great place in the recognition of facial reactions Still, the precision of facial expression is affected by the occlusion and large skew. In this research work, a deep structure-based occlusionaware facial expression recognition mechanism is introduced to provide superior recognition results. Firstly, the required image is taken from publically provided online sources and the gathered images are subjected to the face extraction method. The face extraction method is done via the ViolaJones method for the extraction of redundant patterns from the original images. Secondly, the extracted face features are given to the pattern recognition stage, where the Adaptive CNN with Attention Mechanism (ACNN-AM) is introduced. This mechanism automatically forms the occluded region of the face and the focal point was on the most discriminative un-occluded regions. Moreover, the hidden patterns in the Occlusion aware facial expressions are identified through the Hybrid Galactic Swarm Yellow Saddle Goatfish Optimization (HGSYSGO). Finally, the overall effectiveness of the developed occlusion aware facial expression recognition model is examined through the comparative analysis of different existing baseline recognition techniques.
Keywords
Introduction
In social communication, facial expression has played a significant role in our day-to-day life [1]. Recognition of facial expression has gained more awareness due to their huge implications, which includes video conferencing, health care, virtual reality, cognitive science and driver safety. A great approach of human emotional communication is facial expression [2]. The facial expressions comprise of 55%, whereas voice and language comprise of 38% and 7%, correspondingly. The automatic facial expression recognition with computer vision and artificial intelligence has been implied in diverse areas like human-computer interaction, sign language recognition and human behavior recognition, etc. [3]. The facial expressions are divided into numerous categories, such as anger, fear, disgust, happiness, surprise and sadness [4]. The facial Action Coding System (FACS) was evolved to encrypt the movement of various facial muscles in which Action Units (AUs) describe the facial movement [5]. Most of the developed models are performed by using these action units [6]. Also, to obtain the features for facial expression recognition, the Facial Animation Parameters (FAPs) model was developed.
Using body posture, facial expression, gesture and speech, human emotions can be recognized [7]. By evaluating stress, marketing, medicine, stress and intelligent learning, emotion recognition is a subsidiary [8]. Through facial expressions, the humans can communicate their emotional state to the observer in a natural way [9]. By the position of the muscles and movements, the information and intentions are received from the human face [10]. The facial expression and recognition of emotions have received more attention in different areas of computer vision, which affects computing, human-computer interaction and pattern recognition. It performs a crucial role in huge implementation such as humanoid robots, telecommerce, patient monitoring systems, mood prediction, sentiment analysis and clinical and crime psychology. Regarding the movement of muscles, our face has the default feature of facial recognition [11]. Therefore, demanding key component is the specific feature extraction for recognizing emotions efficiently [12]. The feature extraction becomes more challenging due to the variance in the facial features because of the background noise, illumination variation, pose variation and uneven lighting.
With the popularity of smart devices, deep learning and machine learning-based face recognition technology is experiencing remarkable growth with the rapid evolution in our lives [13]. In a short period of time, facial expression recognition has obtained huge recognition in the field of driving, medical treatment, human-computer interaction, which has become a famous analysis topic in education sectors and industrial sectors [14]. Facial expression recognition means extracting the particular facial expression from the available stable image or motion video sequence to show the intellectual feeling of the object which is recognized [15]. Usually, the available images with a facial expression recognition algorithm are to obtain the features that perform to decide different facial expression categories notably in conventional methods [16]. A covariance pooling layer was discovered by Acharya et al. to obtain the deformations in the regional facial features and the early evolution of each frame features. However, the above introduced methods attained better results greatly, facial expression recognition is still a demanding method because of the occurance of the partially congested faces. Given the variation in poses, Zhang et al. imposed an adversarial autoencoder under several reactions and poses to enhance the performance using face images. In these methods, the dataset is recorded in controlled environments, where the facial images are frontward [17]. Under natural and uncontrollable variations, these models give poor performance in the recognition of human expressions.
The key scope of the developed deep learning-based occlusion aware facial recognition is summarized below.
To design an efficient occlusion aware facial expression recognition approach by deep learning framework to recognize the expressions from the occluded facial images, and it provides highly recognized facial expression recognition results with high accuracy. To implement a HGSYSGO for optimizing the parameters epochs, learning rate and hidden neuron count in Adaptive CNN to enhance the precision and accuracy in the developed occlusion aware facial expression recognition model. To develop an attention-based Adaptive CNN mechanism for recognizing the facial expressions, where the parameters are tuned by the developed HGSYSGO to get rid of occlusion region from the facial regions, and finally it recognize the expressions accurately. To validate the performance of the developed model is analyzed over different conventional facial expression recognition approaches and algorithms to enhance the performance.
The rest of the developed facial recognition approach is systemized as follows: Section 2 explains the existing facial expression techniques with advantages and drawbacks. Section 3 explains the architectural representation of the offered method and the dataset description. Section 4 describes the designed algorithm and the preprocessing using Viola-Jones method. Section 5 tells about the facial expression recognition stage by the attention-based Adaptive CNN. Sections 6 and 7 summarizes the results and performance analysis, and conclusion.
Related works
In 2020, Kim et al. [18] have developed a new strategy where the input given here are the recording videos, depth and color to estimate the dimensional emotion states. This network is known as Multi-Modal Recurrent Attention Networks (MRAN), in which facial recognition is recognized on the basis of attention-boosted feature volumes by learning spatiotemporal attention volumes. The guidance prior for color sequence depth and the thermal sequence was proposed to focus the emotional discriminative regions. For multi-modal facial expression, the standard landmark called Multi-Modal Arousal-based-Valence Facial Expression Recognition (MAVFER) was imposed with thermal recorded videos, color, and depth with the addition of continuous arousal-valence scores. The color recorded datasets having “RECOLA, SEWA and AFEW, and a multi-modal recording dataset including MAVFER” and geographical dimensional facial expression recognition, have resulted the extraordinary uses contrasted to other techniques.
In 2017, Ding et al. [19] have implied a facial expression recognition system based on Local Binary Pattern (LBP) with a double layer to obtain the peak expression frame from the video. This developed method was used to reduce detection time with lower-dimensional size. In order to handle the radiant difference in LBP, the domain named Logarithm-Laplace (LL) was additionally implied for the efficient and strong facial feature for detection. They suggested the Feature Pattern of Taylor (FPT) on the basis of Taylor expansion and LBP to extract sturdy facial features for detection. In the end, the theorem based on Taylor expansion is used to obtain the facial expressions. Depending on Taylor expansion and LBP, an efficient facial feature from the Taylor feature map, the FPT was introduced. The practical results on the JAFFE and Cohn-Kanade data sets were shown enhanced performance. The JAFEE database, FG Net database and CK
In 2021, Arumugam et al. [20] have introduced a sub-band wavelet gradient transform with sub-band selection for the efficient recognition of facial emotions. The wavelet feature consists of both dimensional and spectral domain information that is used to find human emotions through facial expressions. To get the gradient of sub-band, the gradient transform method was explored. Also, to improve the quality of images, the calculation in the edges was performed. With the application of the principal of the Pearson–kernel component analysis method the dimensions were reduced in the obtained features. With the introduced membership of the Gaussian function fuzzy SVM classifier, the facial features were particularly selected and categorized.
In 2021, He et al. [21] have introduced a new technique for finding the expressions of face and recognition of AUs based on their relevancies on the convolutional networks. For the separation and detection of information of facial reactions via the de-expression learning procedure, a conditional Generative Adversarial Network (GAN) was introduced. After that, the representation of dependency lying in the group of AU nodes was achieved by applying a graph convolutional network and the nodes were embedded by the classification of expression components into various patches concerning the AU-related regions. At last, they described the relevancies of expressions and AUs, and in addition, they combined them to loss function to impel the model. Throughout the analysis, the results have shown that this recommended work outperformed than any other popular methods.
In 2020, Chikontwe et al. [22] have demonstrated the learning of generative and particular demonstrations for pose-unvarying face recognition based on a GAN architecture that was used to detach the identity and variations in the pose. Rather than using a single generator an iterative warping scheme performed better results. For face recognition, the features considered by the encoder were posing invariant and through the estimation of databases, this proposed system has shown better results than other methods. As for example, the precision achieved on Feret and Caspeal was high when compared with other methods without the process of warping. Particularly, there exist two notable innovations. Firstly, the synthesis of frontward faced via an encoder-decoder structure in the generator with the differences in the pose was given to the decoder and discriminator, and the performance was based on disentangled architecture GAN. Secondly, in the geometric warp parameter, the real image was synthesized using the generator encoder, and it acted as a spatial transformer network.
In 2022, Liang et al. [23] have explored a convolution-transformer Network with a dual branch that has benefited on facial expression in both local and global details to equip the real-world occlusions and head-pose variant robust FER. This network consisted of two branches. In the analysis of this local modeling capacity of CNN, the local edge details were obtained using CNN in the first branch. In second branch, transformers were introduced in the natural processing of language to achieve fair representation all over the world. Next, hybrid features were used to combine the features, and local–global feature fusion module was explored also, they modified the relationship between those two features. Using this module, the network not only hybrid the features but also learned various features by itself. This experimental results under the evaluation of inner-database and cross-database results in facial expression databases concluded that this introduced method performed well other than the conventional methods and attained efficient execution in a wide range.
In 2020, Hu et al. [24] have proposed a module of occlusion detection depending on symmetric SURF for the purpose of finding the occluded facial images, which were used to find the occlusion area having the horizontal symmetric area . Under the supervision environment, a mirror transition face in painting was introduced to achieve face in painting in quick manner. In addition, a heterogeneous soft partitioning based recognition network was introduced to identify facial reactions. After partitioning, the input was the weights in each part, and this recognition network was useful for the training. At last, for the identification of the reaction the neural network was fed with weighted inputs. By analysis of this developed model, it was revealed that this method has a higher rate of precision when compared with state-of-the-art methods on fer2013 and Cohn-Kanade (CK
In 2019, Li et al. [25] have suggested a CNN with Attention mechanism (ACNN) that was able to differentiate the occluded sectors in the face and the focal point on particular un-occluded sectors. The various characterizations were combined from facial Regions of Interest (ROIs). By this proposed gate unit, the characterization has been weighted and calculated the ductile weight from the sector by its own. With the consideration of various RoIs, the two version of ACNN was employed namely, global-local-based ACNN (gACNN) and patch-based ACNN (pACNN). For local facial patches, the pACNN has more attention to obtain features. Based on visualization results, ACNN was able to change the focus from the patches of occluded regions to other areas. When compared to other conventional methods, the datasets used in-the-lab facial expression in the cross-dataset evaluation protocol; the performance of ACNN was fair.
In 2022, Ye et al. [34] have developed the Convolutional Neural Network and Attention Long Short-Term Memory (CNN-ALSTM) for recognizing the facial expression. Hence, the designed method was incorporated with the two-layer attention mechanism (ACNN-ALSTM) was implemented. Here, the experiments were conducted by two datasets Fer2013 and CK
Problem statement
Existing occlusion aware facial expression recognition models
Existing occlusion aware facial expression recognition models
The recognition of facial emotions has an important activity for designing computer-oriented applications in neuroscience and cognitive science. The occlusion of large skews may affect the accuracy of the facial recognition scheme. However, the differentiation in the poses and facial expressions is efficiently identified by using several deep structure-based approaches. The features and the challenges of the developed deep structures are shown in below Table 1. MRAN [18] effectively extracts spatial information from the collected data. And also, the cost effectiveness is low in this model. But, it does not have the ability to model the variability of the temporal factors from the facial expressions. DLBP [19] sensitively captures different voice, face and biological emotion signals for improving the system’s accuracy, and therefore, it has low computational cost. Yet, it tries to get the motional differences from the continuous frames. Furthermore, the illuminations of the facial expressions are not effectively defined. SMSWT [20] directly minimizes the photometric consistency in spatial and temporal patterns. In addition, it provides high robustness and reliability. Nonetheless, it does not cover the complete range of human emotion variations. Furthermore, the reliability of the system is low. GCNN [21] is highly sensible to resolve the local radiance fluctuations problem. Subsequently, the convergence rate of the model has high. But, it is more troublesome and computationally very expensive. In addition, the pose variations are not effectively determined. GAN [22] helps to get a more strong facial expression feature. Consequently, it highly reduces the time complexity. However, this method mainly requires manual selection to determine the subjective imposition of thresholds. CT-DBN [23] solves the problem of pose difference and data sparsity while considering some uncontrolled conditions.
Nevertheless, the automatic facial expression detection models with some uncontrolled conditions are needed for this model. SURF [24] effectively enables the geometric corrections of the input image in the feature extraction process, and also, the accuracy and the precision of this model were high. But, it mainly focused on recognizing the relation among various temporal feature frames. In addition, several difficulties were acquired while processing large amounts of data. ACNN [25], the preservation of global and local details are high in this model. In addition, it requires low resources for the computation. But, it has low generalization performance because of the usage of conditional probabilities. Therefore, the challenges in the facial expression methods are overcome by the newly developed deep structured based strategy.
Experimented datasets
The data needed to find the occluded aware facial expression recognition are obtained from the website
The dataset 1 (AffectNet) is a new database created to detect facial expressions by collecting annotating facial images from the above-mentioned online source. It consists of more than 1M facial images are collected from the web by analysing three search engines using 1260 emotions-based keywords in six various languages. About half of the restored image was elucidated for seven discrete reactions of the face and the intensity of valence and activation. To classify the images, two baseline deep neural network is used.
The dataset 2 (RAF-DB) is a huge database with around 40 k facial images gathered from the above mentioned online source. Each and every image can be labelled by 40 annotators based on crowdsourcing annotation. In this database, images are in great differences in subjects head poses, lighting conditions, age, gender, occlusions and post-processing operations. This dataset contains huge quantities and rich annotations. It is classified into two sets, namely the training set and the test set for the performance measurement. Here, the size of the training set is five times larger than the test set.
The input images garnered from the AffectNet, and RAF-DB standard dataset are denoted by
Collected sample facial expressions from the traditional databases.
The major limitations of facial expression recognition are the fast attaining rate and depending on the wild performance. Under the guarded lab conditions, the works are created, and tested based on the dependencies of standard datasets, the bias is produced. The lab imagery displays subjects, which preserves a frontal or near-frontal headpose. Under controlled illumination conditions, without considering self occlusions and the quality of the image is usually high. Using video clip stimuli, the behaviour is extracted otherwise adds human-computer interaction. In particular both schemes decrease the complication of the data. The next drawback is the unification of the examination of human facial expressions research in a high-level framework modelling. The human behaviour is examined by various methods, in which facial behaviour identification is one of the main aspects. By observing all the expressions in the face, we are able to understand the human’s emotions. In the case of extracting a good picture, considering the multi-modal view of demonstration helps to formulate the message and to enhance the performance of each of the particular sub-problems along with the analysis of automatic facial expression. The architectural representation of the newly implemented occlusion-aware facial expression recognition model is given in Fig. 2.
Systematic representation of developed deep learning-based occlusion aware facial expression model.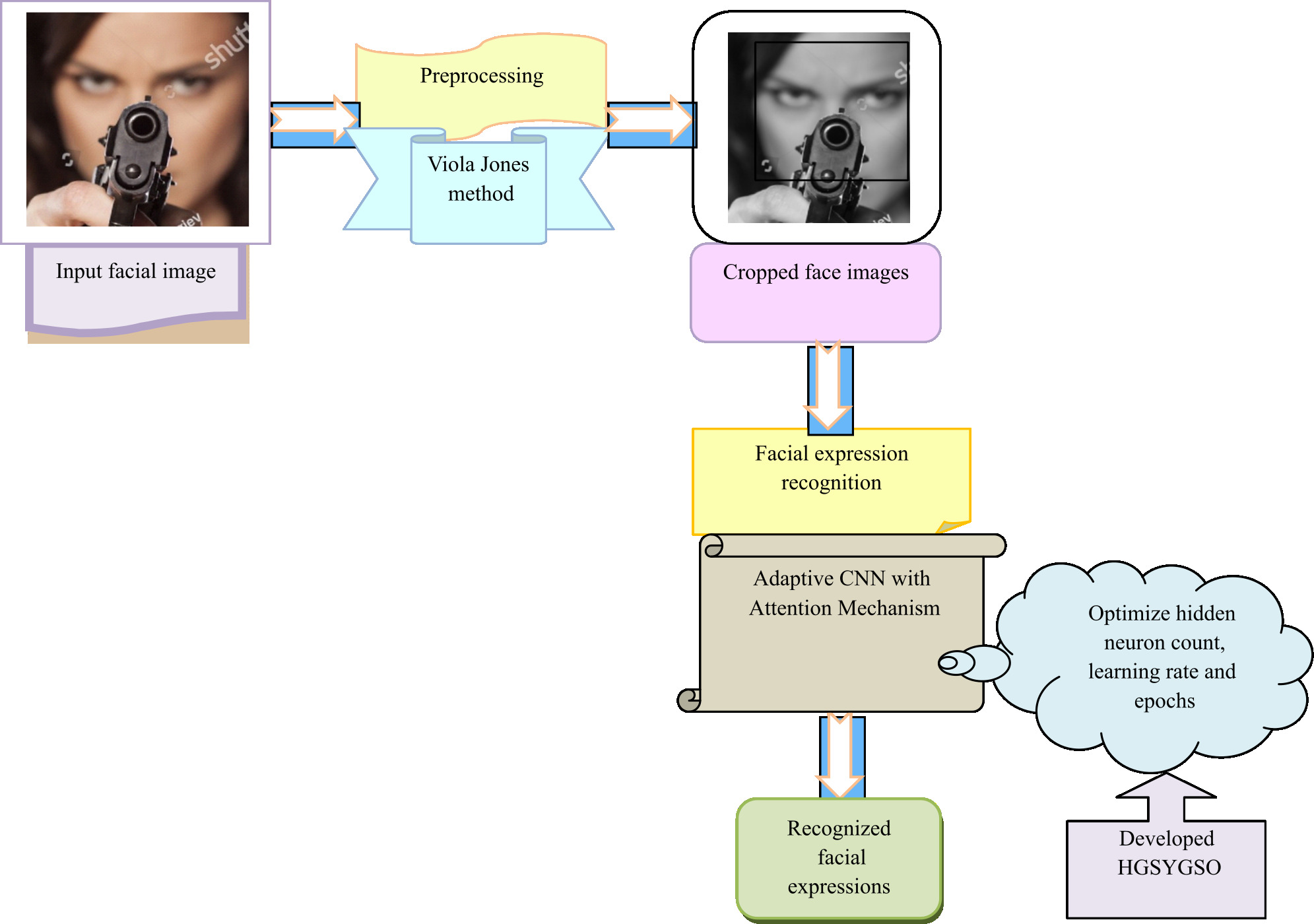
A new deep learning-based occlusion aware facial expression recognition approach is developed to detect the occlusions from the images to provide efficient results over facial recognition. Moreover, this developed occlusion aware facial expression recognition approach is used to improve the precision and accuracy rate excessively. The facial images are gathered from the benchmark databases. The facial patterns from the images are extracted from the facial images by using the Viola Jones method, and then the cropped image is extracted as output. Next, the cropped image is fed as input to the classification stage; where attention-based adaptive CNN is utilized to form the occlusion regions to recognize the expression of individuals. Here, the parameters such as epochs, learning rate and hidden neuron count are optimized with the utilization of offered HGSYSGO. The objective function of this parameter optimization is to attain maximum accuracy and precision rate. The recognized results from the developed occlusion aware facial expression recognition model are compared over different existing occlusion aware facial expression recognition approaches and heuristic algorithms in order to ensure the effectiveness.
Viola Jones algorithm for pattern extraction
The Viola-Jones algorithm is implemented because it effectively extracts the relevant patterns from the facial images. The viola-Jones method [26] uses the input image as
The haar feature is built with two or three rectangles. The haar feature is utilized for the detection purpose to find whether the face is present or absent. There is a particular value for each haar feature, and by taking the area of each rectangle value is formulated, and the result is added. In simple manner, the area of rectangle is found based on the concept of integral image. The value at any location
In the pre-processing phase the integral image
Here, the terms
In segmentation, the output is
The value of the feature is determined by the Haar feature classifier by the rectangle integral for the computation. The weight of each rectangle is multiplied by the haar classifier by the rectangles area and the results are added atlast. These classifiers are divided into various stages. The results are added by the stage comparator, and these added values are compared with a stage threshold. From the Ada Boost algorithm the threshold constant is gained. There is no fixed set number for haar features. In the cascading stage, we can easily encounter the false individual and eliminate. It is eliminated when it does not cross the first stage. If it passes then they proceed to the next stage, and finally the face is detected. The output patterns obtained from the Viola-Jones method is represented as
Resultant face detection from the Viola-Jones algorithm.
The developed HGSYSGO algorithm is used in the developed occlusion aware facial expression recognition model to improve the recognition rate of the developed occlusion aware facial expression recognition model by optimizing the parameters taken from the CNN. The parameters to be optimized from the Adaptive CNN are learning rate, hidden neuron count and epochs. The GSO helps to provide multiple cycles of exploration and exploitation by splitting the search spaces. Consequently, the global optimum gets prevented because of the trapping of local optimum. YSGO helps to enhance the optimization results, but, the convergence rate is low. To resolve these challenges, the HGSYSGO is introduced with newly modified concept based on the fitness function. In our proposed hybrid algorithm
The variable
YSGA: The YSGA approach contemplates the hunting area as the search space. Here, the individuals imitate the group of fish. The algorithm contains two division of search agents, namely blockers and chasers. Among the sub-population, one fish takes the chaser role, and others are observed as blockers. Based on the category, each element undergoes a set of different operations, which copies the various behaviours in the natural hunting process.
A population
Here,
The data set is grouped into
Here,
In a group of goatfish, the chaser fish is denoted as
The new and latest location of the chaser fish is
Here, the variable
Here
Here,
Here
The strategy of blocker fish
Here,
The term
Here,
A change of area is performed for all the goatfish in the cluster, as shown in Eq. (21).
Here,
GSO: In this model, based on the galaxies, movement of stars and super clusters of galaxies, the GSO algorithm works. There is an uneven distribution of stars in the universe they are unevenly dispersed, but they are grouped into galaxies. Overall, the huge galaxies appear as point masses. The stars get drawn to the galaxies in massive amount, and again, the galaxy itself from other great masses is imitated in the GSO algorithm. In the GSO algorithm, a galaxy of stars is parallel to the subswarm and a cluster of galaxies is parallel to the super swarm. The cluster of galaxies is found out using the Centre of Mass (CM) of the galaxies. Likewise, by the individual in the subswarm represents the global best solution. However, in our strategy, the analogy is blocked to clusters of galaxies and galaxies of stars.
In this GSO algorithm, the swarm is a set
Here,
The motion of the subswarm in
The search space is found by the subswarm independently by its own. By the calculation of velocity and position, the iteration starts, and the expressions for velocity and position updates are given in Eqs (26) and (27) respectively.
Here, the
Equation (9) denotes that
The updated equations of the position vectors
Here,
The information is exploited by calculating superswarms that used the best solutions from already computed one by the subswarms. Eventhough the individuals of the superswarms are widely spread when compared with subswarm individuals, the role of superswarm is dependent.
To maintain the unity of solutions, the flow of details from the superswarm to subswarms is influenced by the global best solutions. For the retainment of highly spreaded subswarms and constant global search ability for every time, the feedback should be avoided that helps the GSO strategy.
When the next time starts, the search starts from where it is stopped and with the same accuracy, the search starts to explore the space again, but sub swarms are not restarted. Therefore there is more chance to get local minima for the GSO algorithm, and this is the main thing because any local minimum can eventually be the global minimum. This continual exploration-exploitation cycle can be inbuilt in response for the outperformance of the GSO algorithm.
The pseudocode of the developed HGSYGSO-ACNN-AM-based occlusion aware facial expression recognition method is expressed in Algorithm 1.
CNN architecture
In our proposed work, we have used adaptive CNN [27] for providing a better precision and accuracy rate over the recognition of occlusion aware facial expressions. The extracted features from the viola-Jones are given as the input of the CNN
a) Forward Propagation Process: The fully connected layer and pooling layer convolution come under the first method. The convolution and pooling achieve the learning of facial features and representations. In the convolutional layer, the convolution kernels with various sizes and shapes and local input image features can be obtained. Incase
Here,
Here, multiplicative bias is denoted by
Here,
b) Back Propagation for Parameters Update: Next, the Back Propagation (BP) algorithm was implied to reduce the error between the real target value and model prediction by having with the minimum loss function
Then, the size of the sample is denoted by
Basic construction of the CNN model.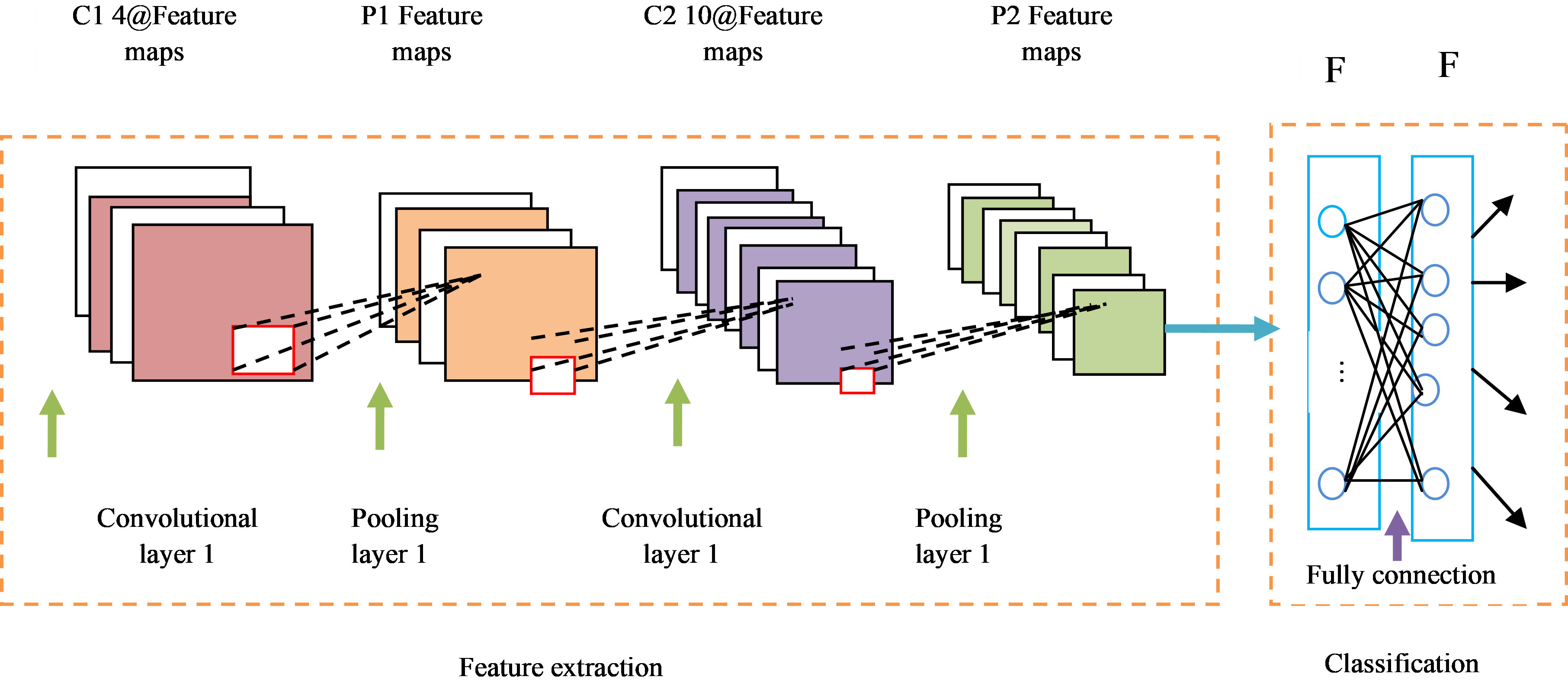
In this developed occlusion aware facial expression recognition model, the Adaptive CNN with parameter optimization are used to increase the precision and accuracy over the recognition. The parameters to be optimized in the CNN are learning rate, hidden neuron count and epochs by developed HGSYGSO. CNN is used to detect patterns in images to recognize objects, classes, and categories very effectively. But the gradient value gets exploded in CNN. Hence, the parameters are optimized to increase the performance over facial recognition. The objective function of the designed facial recognition model with parameter optimization is given in Eq. (38).
Here, the accuracy is denoted by AR , and the precision is denoted as PN. The variable
The “true positive, true negative and also the false positive and false negative values are indicated by the terms
The term precision is termed as the ratio of detected positive value correctly to the summation of all observations that are positively detected, as given in Eq. (40).
The true positive and true negative values are indicated by the terms
To enhance the accuracy and precision occlusion aware facial expression recognition, the CNN model with attention mechanism is introduced. Moreover, by using this attention mechanism, the hidden patterns are effectively learned. A set of query and key-value pairs are present here to map them to a loaded addition output of all values. For the input with key dimension
Here,
Here, the term
Multi-head attention can perform more than single-head attention and makes the network learn quickly. The normalization method was introduced to reduce the data scale in classification precision. The normalization formula can be represented in Eq. (43).
Here, between the interval, [
Developed occlusion aware facial expression recognition using Adaptive CNN with an attention mechanism.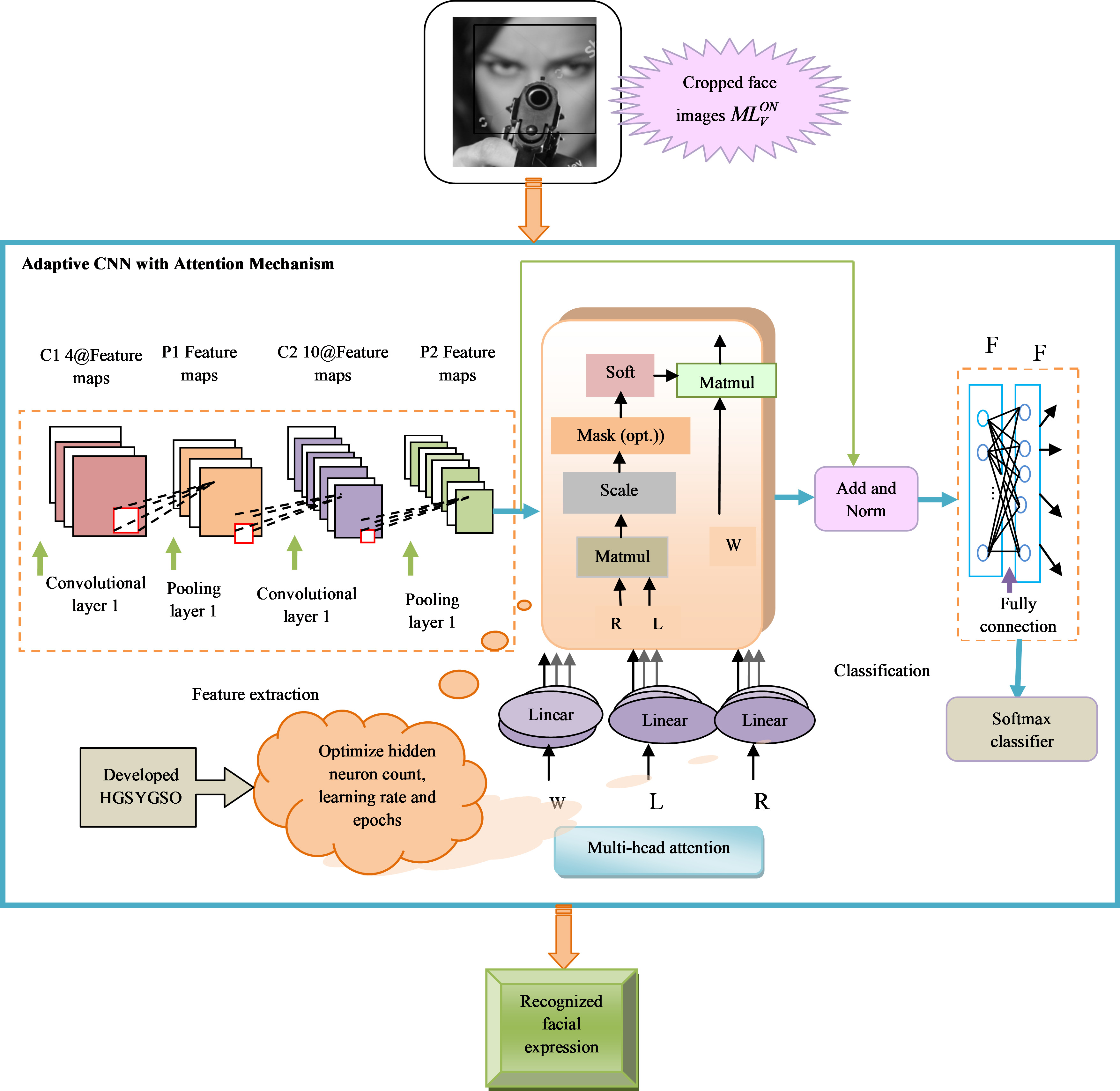
Simulation setting
The newly recommended HGSYGSO-ACNN-AM-based occlusion aware facial expression was implemented in python, and corresponding analysis over current facial recognition methods is used to examine the effectiveness of the designed method. The number of population taken was 10, and the chromosome length taken for facial feature recognition was 7. The efficiency of the system was studied through the measures like accuracy, F1-score and precision. The analysis was took over through the various suggested techniques includes Long Short-Term Memory (LSTM) [28], Radio Frequency (RF) [29], Deep Belief Network (DBN) [30] and Convolutional Neural Network (CNN) [31] and algorithms like Deep Hunting Optimization Algorithm(DHOA) [26], Grey Wolf Optimization (GWO) [27], GSO [32] and YSGA [33].
6.2 Evaluation measures
The other evaluation measures used to estimate the effectiveness are given as follows.
The accuracy value is given in Eq. (39).
The precision value is given in Eq. (40).
F1-score: The F1 score is defined in Eq. (44).
Sensitivity: Sensitivity is calculated using Eq. (45).
Specificity: Specificity is estimated by Eq. (46).
FDR: FDR is calculated using Eq. (47).
FPR: FPR is evaluated through Eq. (48).
FNR: It is evaluated using Eq. (16).
MCC: MCC is computed using Eq. (50).
NPV: It is measured using Eq. (51).
Performance analysis on developed deep learning-based occlusion aware facial expression recognition system regarding “(a) accuracy (b) F1-score and (c) precision”.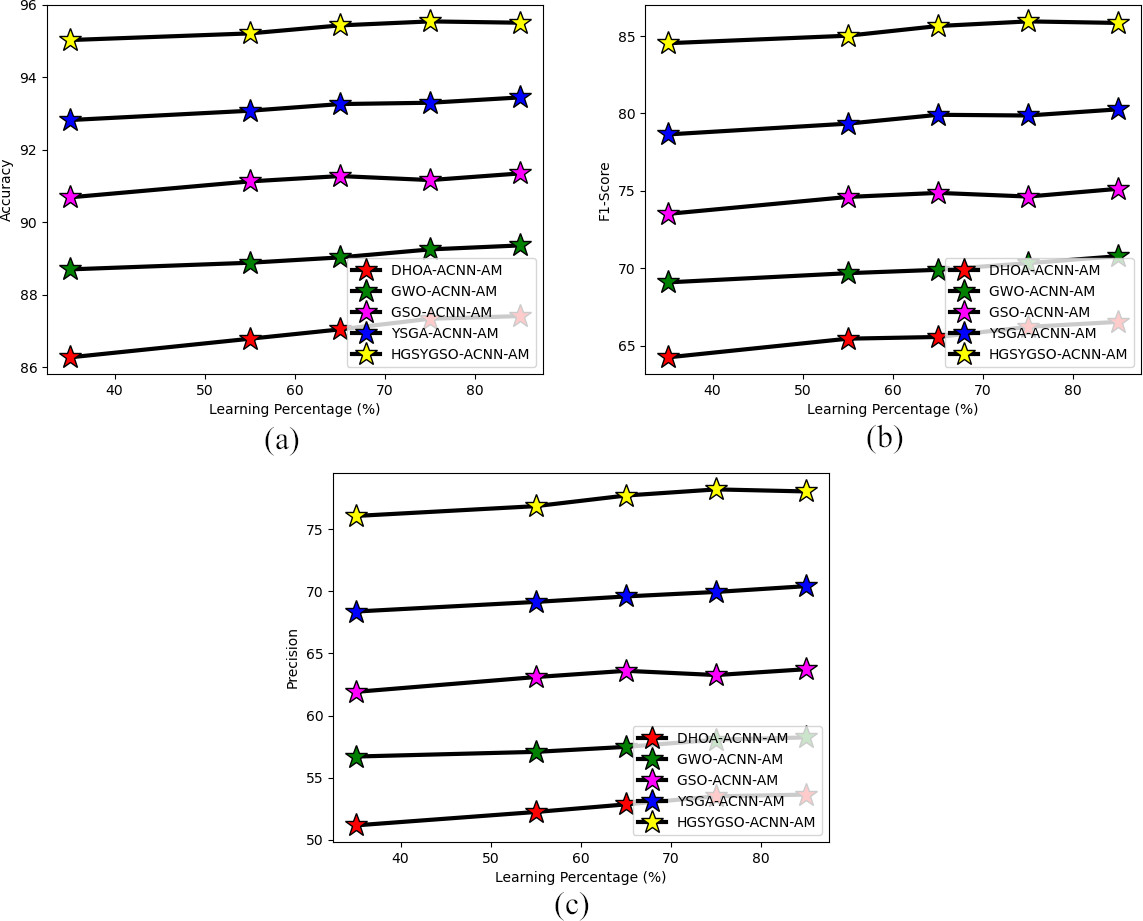
Performance analysis on developed deep learning-based occlusion aware facial expression recognition method via different recognition techniques in terms of (a) accuracy (b) F1-score and (c) precision.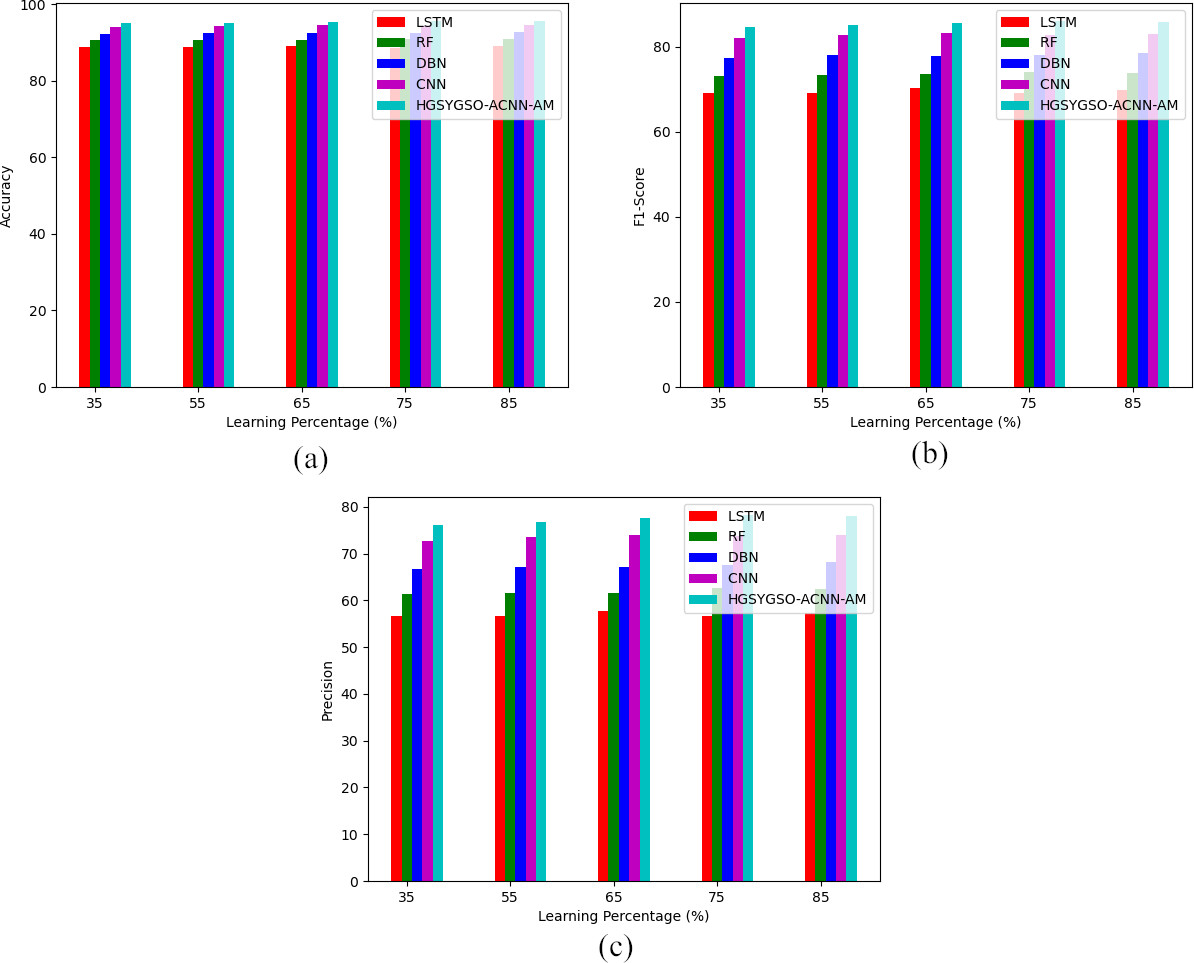
5-fold analysis on developed deep learning-based occlusion aware facial expression recognition method through different algorithms regarding “(a) accuracy (b) F1-score and (c) precision” 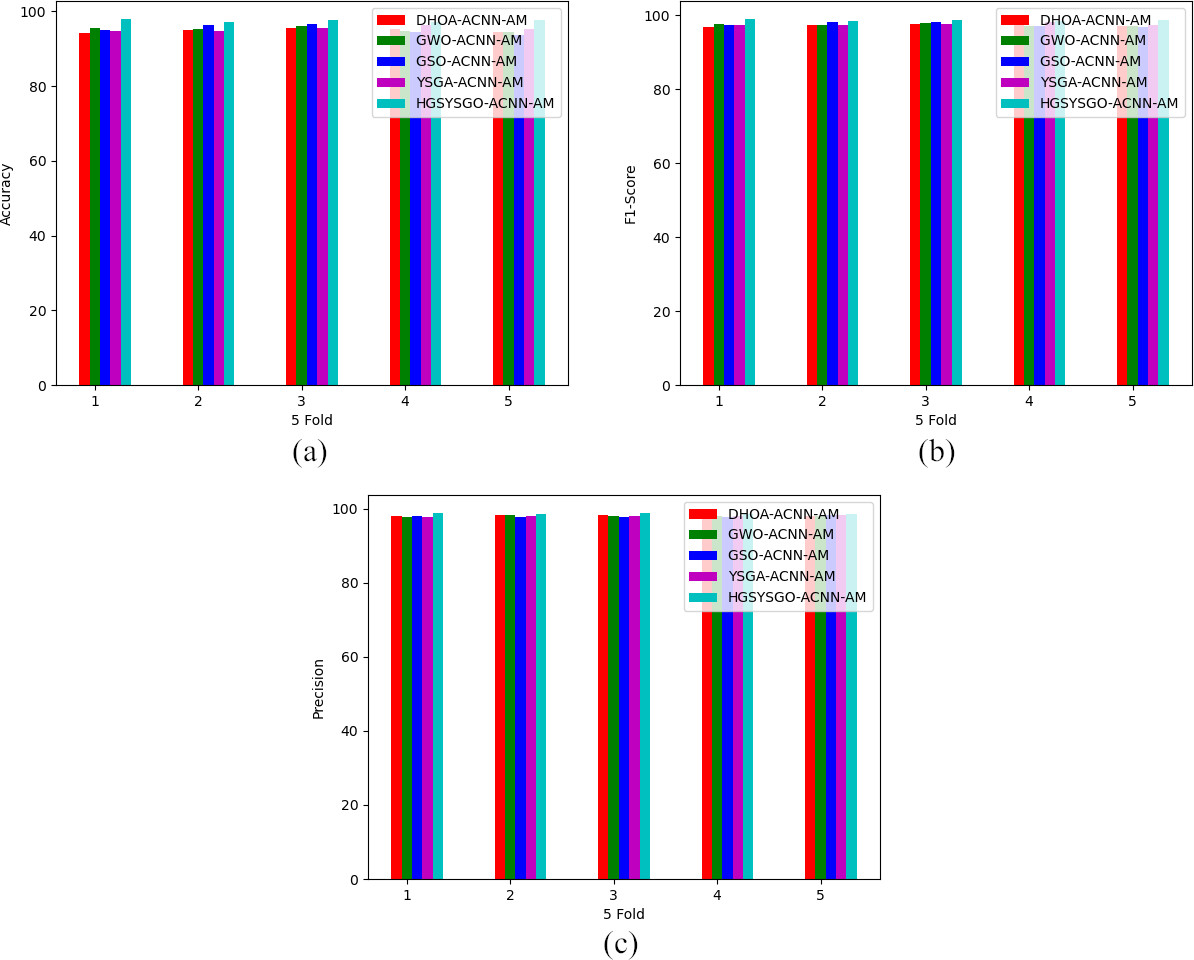
5-fold analysis on offered deep learning-based occlusion aware facial expression recognition method through various recognition techniques with respect to “(a) accuracy (b) F1-score and (c) precision”.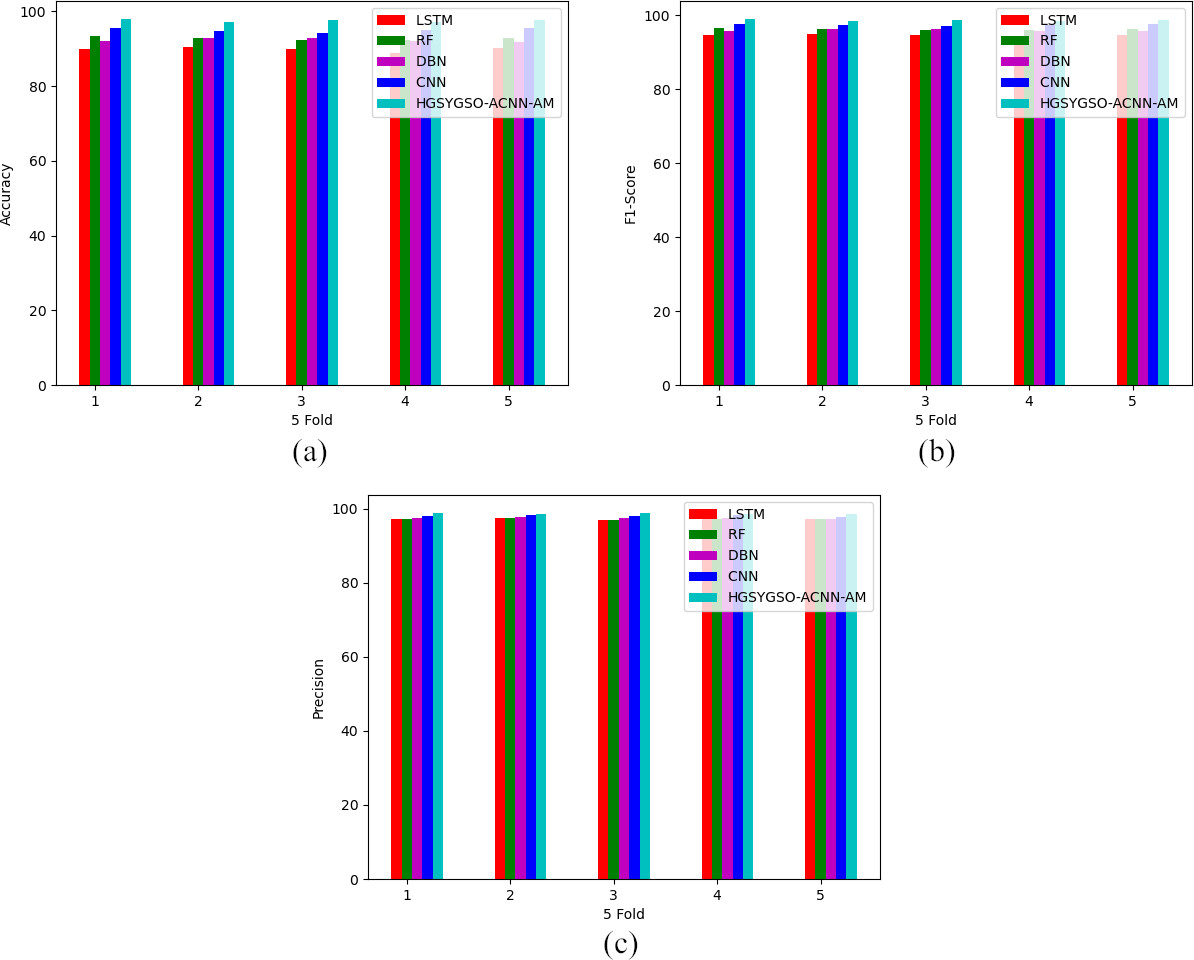
Figures 6 and 7 depicts the estimation of performance on the developed HGSYGSO-ACNN-AM-based-occlusion aware facial expression recognition system by utilizing the similarity measures with the above-mentioned heuristic algorithms. From this analysis, the precision of the proposed HGSYGSO-ACNN-AM-based facial expression recognition system has been obtained with 10.86%, 22.4%, 36.60%, 45.71% improved precision rates rather than other suggested systems such as DHOA, GWO, GSO and YGSA other suggested systems when assuming the learning percentage of 60. Thus, it enhanced the effectiveness of the occlusion aware facial expression recognition system rather than the recommended system.
Performance validation on dataset 1 using 5-fold
Figures 8 and 9 depicts the performance comparison of the developed HGSYSGO-ACNN-AM-based occlusion aware facial expression recognition system over different algorithms and recognition approaches over a variety of suggested models by the standard methods. From the analysis of 5-fold, the developed HGSYSGO-ACNN-AM-based occlusion aware facial expression recognition system acquires with 0.91%, 2.06%, 4.21% and 6.45% improved precision rate rather than the DHOA, GWO, GSO and YGSA when assuming the 5-fold value of 3. The 5-fold on various algorithms shows that the developed HGSYSGO-ACNN-AM-based occlusion aware facial expression recognition system has attained high precision rate than others for all the 5-fold values. Therefore, the overall effectiveness of the proposed HGSYSGO-ACNN-AM-based face recognition method was enhanced by the measures like accuracy, F1-score and precision.
Performance validation on dataset 2 using learning percentage
Figures 10 and 11 show the estimation of performance on the developed deep learning based-occlusion aware facial expression system with the heuristic algorithms by using the similarity measures. From the analysis of the suggested HGSYGSO-ACNN-AM-based occlusion aware facial recognition system obtained with 6.45%, 0.94%, 8.47% and 10.72% improved accuracy rate rather than DHOA, GWO, GSO and YGSA systems such as other suggested systems when considering the learning percentage of 55. Thus, it enhanced the facial recognition system’s efficiency rather than the recognition system. Hence, the overall efficiency of the developed deep learning based-occlusion aware facial expression system has progressed through the metrics.
Performance analysis on developed deep learning-based occlusion aware facial expression recognition system via various optimization algorithms regarding “(a) accuracy (b) F1-score and (c) precision”.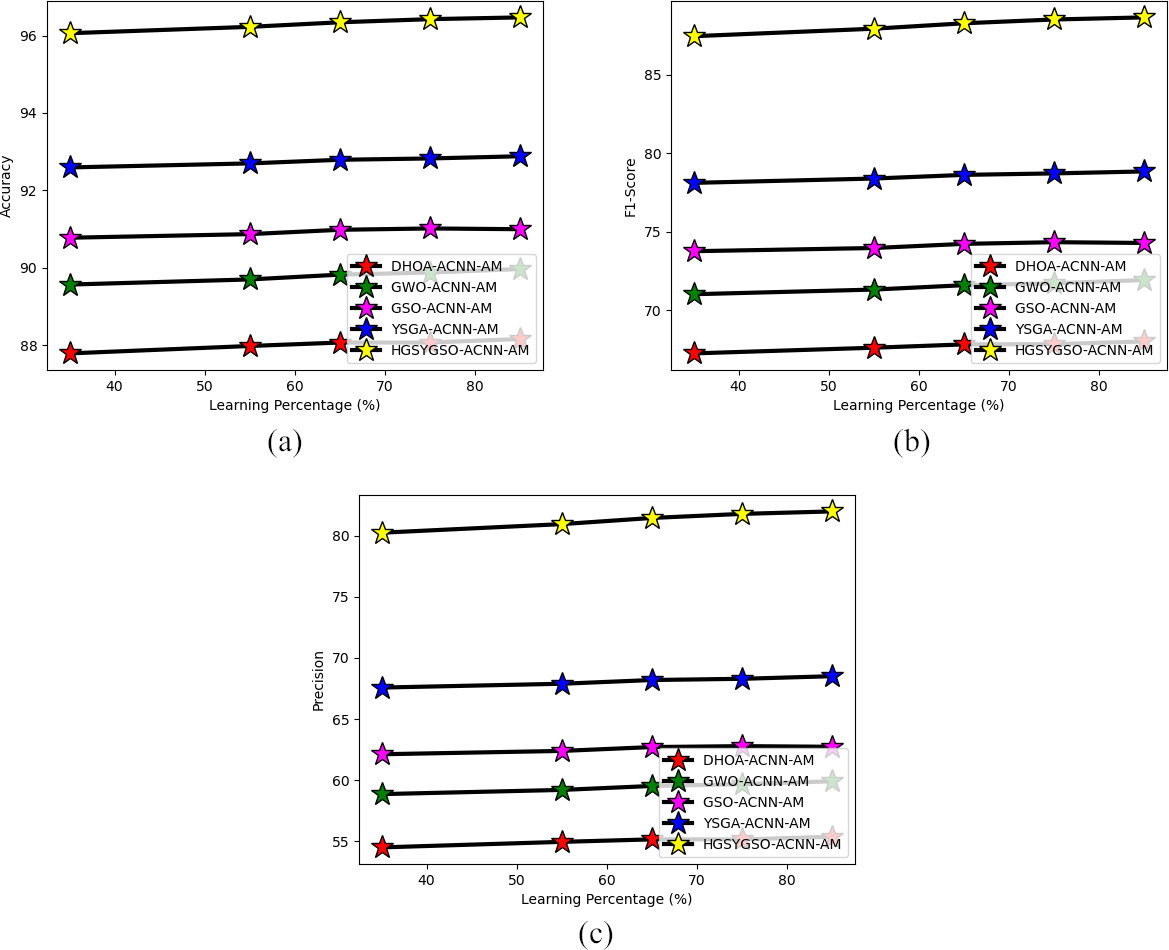
Performance analysis on proposed deep learning-based occlusion aware facial expression recognition system via different techniques with respect to “(a) accuracy (b) F1-score and (c) precision”.
Figures 12 and 13 shows the performance evaluation of the developed HGSYSGO-ACNN-AM-based occlusion aware facial expression recognition system using different algorithms and analysis with diverse suggested models by the performance metrics. From the 5-fold analysis, the developed deep learning based-occlusion aware facial expression recognition method acquires with 4.21%, 3.12%, 2.06% and 0.40% improved precision rate rather than the DHOA, GWO, GSO and YGSA when assuming the 5-fold value of 2. The analysis of 5-fold on various algorithms proves that the developed deep learning based-occlusion aware facial expression recognition has reached a better precision rate when compared to other all the 5-fold values. Hence the performance efficiency of the developed HGSYSGO-ACNN-AM-based occlusion aware facial expression recognition system has improved through the metrics.
5-fold analysis on proposed deep learning-based occlusion aware facial expression recognition method via different optimization algorithms regarding “(a) accuracy (b) F1-score and (c) precision”.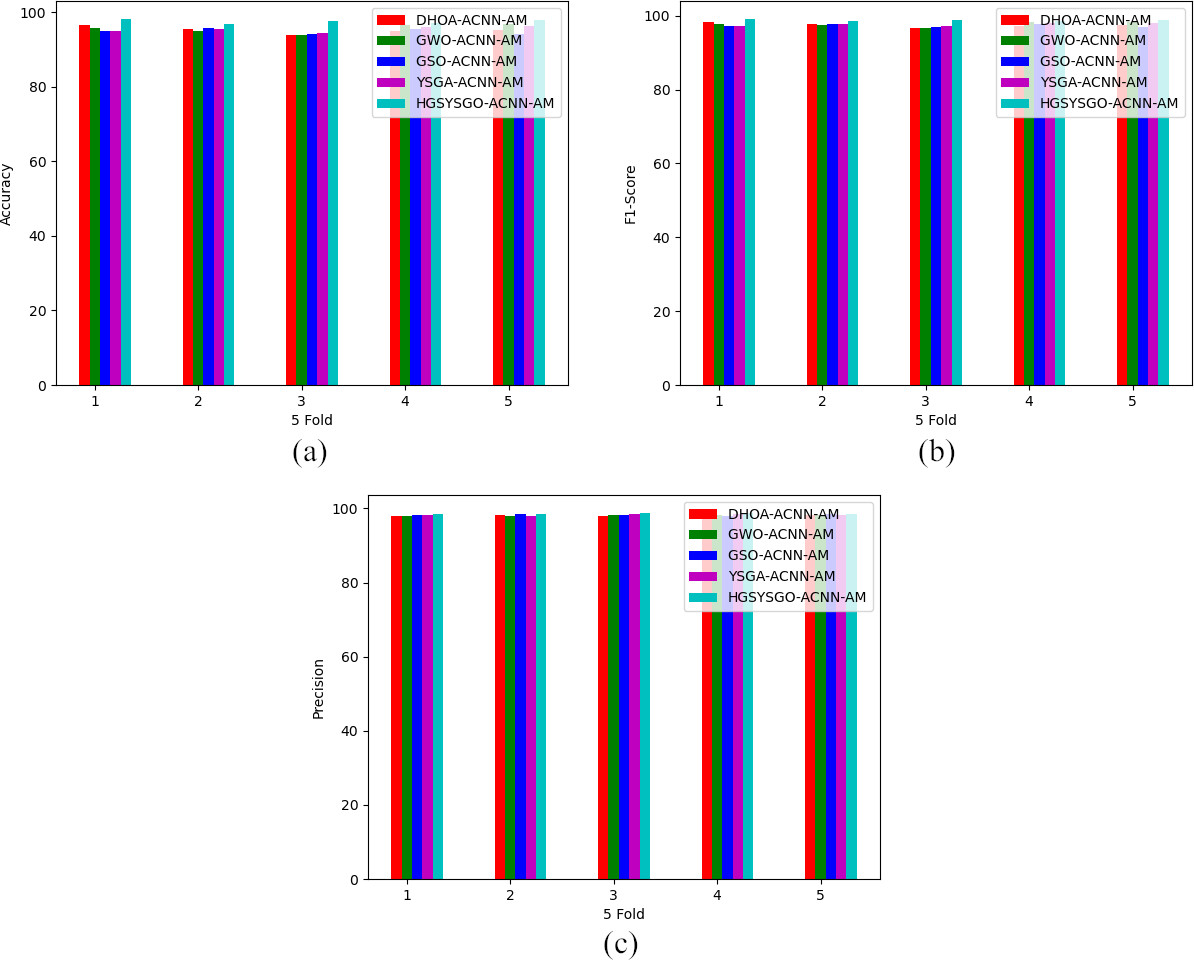
5-fold analysis on proposed deep learning-based occlusion aware facial recognition method through various techniques with respect to “(a) accuracy (b) F1-score and (c) precision”.
Performance evaluation on the developed occlusion aware facial expression recognition system through divergent heuristic algorithms
Performance evaluation on the developed occlusion aware facial expression recognition model through diverse techniques
Tables 2 and 3 illustrate the performance evaluation on the proposed deep learning-based-occlusion aware facial recognition method over various optimization algorithms and divergent conventional techniques regarding the performance metrics. The analysis shows the developed HGSYSGO-ACNN-AM-based occlusion aware facial expression recognition system attained 56%, 4.92%, 7.27% and 9.6% improved accuracy than the LSTM, RF, DBN and CNN techniques. The effectiveness of the proposed occlusion aware facial expression recognition system is extremely maximum high rather than the conventional system.
Conclusion
A new deep learning-based occlusion aware facial recognition method was used in order to recognize the facial reactions by analyzing the facial features with better precision and accuracy rate. Also, this suggested system provided information on the basis of the extracted face features to recognize the expression efficiently. Hence, the two datasets were taken from the occluded occlusion aware facial expression recognition databases. Here, the integral or raw image was given as input to the viola Jones method and the face cropped image was taken as output. Next, the face detected image was fed as input to the classification stage and the output obtained as the recognition of facial features using ACNN-AM method. Here the hidden neuron count, epoch and learning percentage were optimized by the proposed HGSYSGO to increase the performance. Overall, occlusion aware facial expression recognition system has accomplished with improved accuracy of 2.56%, 4.92%, 7.27% and 9.6% than the DHOA-ACNN-AM, GWO-ACNN-AM, GSO-ACNN-AM and YGSA -ACNN-AM. Hence, the overall efficiency of the proposed HGSYSGO-ACNN-AM-based occlusion aware facial expression recognition model has highly enhanced when compared to other methods.