
Abstract
Big data is the amount of data that surpasses the ability to process the data of a system concerning memory usage and computation time. It is commonly applied in several domains like healthcare, education, social networks, e-commerce, etc., as they have progressively obtained a massive quantity of input data. A major research problem is big data analytics, which can be carried out using expert systems and deep structured architectures. Besides, data wrangling and class imbalance data handling are challenging issues that need to be resolved in big data analytics. Class imbalance data degrade the performance of the classification model, which remains a challenging process due to the heterogeneous and complex structure of the comparatively huge datasets. Thus, the research focused on presenting a Class Imbalance Handling with Optimal Deep Learning Enabled Big Data Classification (CIHODL-BDC) framework. The core perception of the CIHODL-BDC framework helps to classify the big data in the Hadoop MapReduce framework. To accomplish this, the presented CIHODL-BDC model initially performs a data wrangling process is performed to alter the unrefined data into a useful layout. Next, the CIHODL-BDC model handles the class imbalance problem using a grey wolf optimizer (GWO) with Synthetic Minority Oversampling (SMOTE) technique. Besides, the Adam optimizer procedure with the Bidirectional Long Short Term Memory (BiLSTM) approach is performed to categorize the big data. The result analysis of the proposed CIHODL-BDC model is evaluated by two standard datasets. The simulation outcomes revealed the elevated performance of the CIHODL-BDC approach over existing methods.
Introduction
Recently, big data can be described with the help of 3 data features, volume, velocity, and variety [1]. The classification speed of generating as well as processing the key entity according to the utilizations can be mentioned as velocity, while the types and nature of data were named variety. The enormous development of data results in numerous difficulties in processing instead of accessing and storing the data. The data collection became costly, therefore it was mandatory to use the data efficiently, and, for further progression, extra effective systems were advanced for big data processing [2]. Officially, big data means the data capacity that surpasses the ability of data processing of a system concerning memory usage and time consumption. Big data has been utilized broadly in numerous domains, like businesses, medicine, and industry, and it has archived a huge volume of raw data [3]. One such important research issue was data analytics which can be executed based on data mining and ML techniques. Big data mining was generally tough to handle with the recent technologies and data mining software devices because the data size is complex and large [4]. The requirement for smart data analytic techniques increases with the help of big data, such as multi-temporal processing, image processing, data fusion, and automatic classification. Parallelization techniques were advanced ascending with the data existing through increasing the calculations significantly. For overcoming the disadvantages of the big data process, data mining techniques were implemented in the developing technologies [5]. For managing the issues in relation to larger-scale datasets, Google launched the MapReduce structure.
ML and deep learning (DL) techniques have been robustly influenced by the class imbalance issue [6, 7]. The latter means few challenges that occur if the number of samples in a single or more class present in the dataset is lesser than another class, therefore producing a significant degradation of the classifier presentation [8]. In the publications, most of the researchers handling this issue were reported, particularly, the data sampling techniques like Random Over-Sampling (ROS), which imitates specimens from the majority class, and Random based Under-Sampling (RUS), which eradicates specimens from the majority class. Such methodologies bias the discrimination procedure for compensating for the class imbalance ratio [9]. Data sampling techniques have significant disadvantages, like longer training periods and overfitting which may mostly appear if minority specimens were replicated [10]. Besides, information was typical if most of the specimens were eradicated from majority classes, potentially dismissing valuable information for the classifier. Then, highly “intelligent” sampling, techniques including an experiential mechanism, were advanced.
The researchers in [11] suggest a new classification structure for big data which has 2 advanced stages. In the stage of feature selection, the popular Whale Optimization Algorithm (WOA) is used to obtain accurate feature sets. The second one was the pre-processing stage utilizes the LSH-SMOTE and SMOTE systems to solve the class imbalance issue. Next, the WOA
The major scope of the recommended CIHODL-BDC model is to categorize the big data in the Hadoop MapReduce framework. The presented CIHODL-BDC model initially performs a data wrangling process to change the raw key entity into a preferable configuration. Next, the CIHODL-BDC model handles the class imbalance problem using GWO with SMOTE technique. Besides, Adam optimizer with BiLSTM model is performed to classify the big data. The estimation of the suggested CIHODL-BDC method is evaluated by two standard datasets.
Depiction of the proposed model
In this research work, the latest CIHODL-BDC approach is introduced for the classification of the big data process. Here, the MapReduce with Hadoop technique is utilized to manage the big data. The recommended CIHODL-BDC method performs based on a series of sub-procedures, namely data wrangling, SMOTE-based class imbalance data handling, GWO-based parameter tuning, BiLSTM-based classification, and Adam hyperparameter optimizer. Figure 1 depicts the overall process of the CIHODL-BDC model.
Diagrammatic presentation of CIHODL-BDC approach.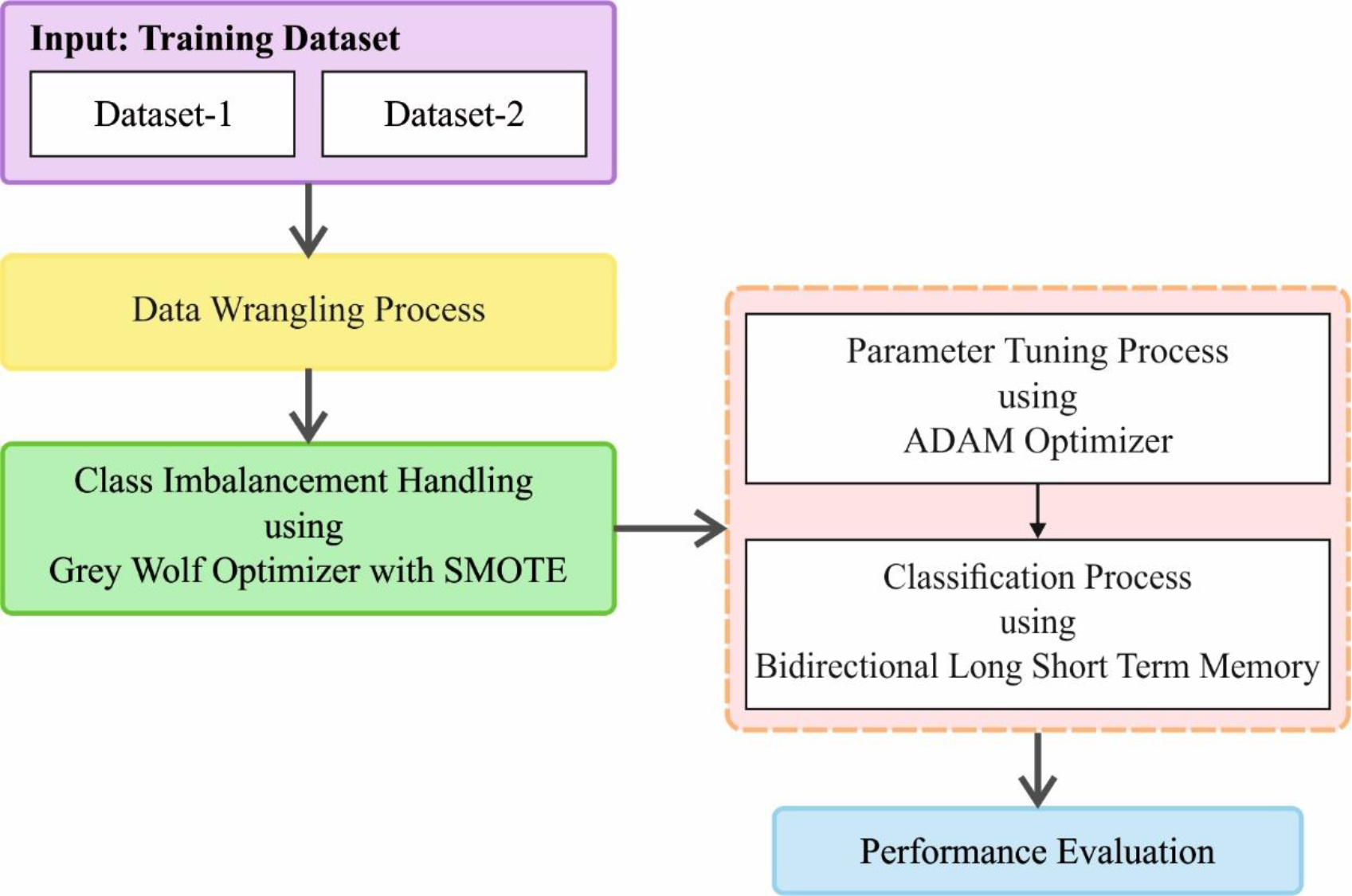
One of the emerging technologies and tools that are widely used in big data is Hadoop. After many years of development, the key application of the Hadoop technological scheme is reasonably tremendous in public sources [16]. The building block of Hadoop is Map Reduce. It is utilized to resolve the application problem of parallel analysis and operation in large-scale data scenarios. Map Reduce can be defined by its two key processes: Map and Reduce. The Map is the mapping process, and Reduce is an inductive process. This process simultaneously implements a sequence of working nodes. Each node performs similar processing in its own managed dataset without data communication. Map-Reduce makes the developer no longer consider the fundamental information while designing large-scale data processing applications, but only realize the respective interface based on the two processes that considerably improve the development efficiency and decrease the development difficulty.
The core concept of this work is helpful for categorizing the big data in the Hadoop MapReduce technique. Initially, there are two datasets are used that is localization and skin data. Here, the Localization data is taken from the actions of 5 people who are ankle right, chest, ankle left, belt, and wearing tags. Accordingly, the skin data is achieved by the R, G, and B values in the face images attained in 2 databases like FERET and PAL. The collected data is further subjected to the data wrangling process. Here, the data is converted and mapped into an actual format to another format for the purpose of generating information in a suitable format for analytics. Then, the SMOTE approach is introduced for handling class imbalance issues. The next phase is the classification process where once the data is balanced, then the classification process takes place using the BiLSTM model. Then the parameter optimization is done by using an ADAM optimizer. Finally, the experimental evaluation is conducted regarding various diverse metrics.
Data wrangling process
Data wrangling includes converting and mapping datasets from the original format to another format so as to generate information in a convenient format for analytics. The aim of data wrangling is to assurance useful and quality information. Data experts typically dedicate most of their time to the data wrangling procedure over the data analysis. In this work, the data wrangling procedure is performed in different forms, namely grouping data, data transformation, missing value replacement, and removal of redundant data. Initially, the data transformation technique is performed where the information in any format is converted into .csv format. Then, the missing value that exists in the data is filled with the mode approach. Next, the unwanted and repeated columns or rows in the data are removed. At last, the dataset grouping is carried out by the built-in function in Pandas that might roll the dataset into different sets.
Data handling process for class imbalance
The SMOTE approach is used to handle class imbalance problems. SMOTE is an over-sampling algorithm to resolve class-imbalance problems. A synthetic sample is produced by SMOTE as follows. Assume that the
The novel sample lies on the line connecting the two vectors. The disadvantage of SMOTE includes variance and over-generalization. SSO refers to Sample Subset Optimization to determine the optimum balanced sample subset. Here, the GWO approach determines an optimum balanced sample set.
GWO approach depends on the hunting activity and leadership level of wolves. Grey wolf often chooses to live in a group [17]. Similar to other SI-based meta-heuristic approaches, GWO initializes the population. Next, the wolf updates its location in the solution space. The mathematical modeling of hunting, leadership, and encircling behaviors are given below: The top three best solutions are regarded as leader wolves, beta (
From the expression,
In Eq. (6), the term Maxiter indicates the maximal iteration count. In the hunting procedure, it is regarded that each of the leading wolves has good knowledge of the prey position. Accordingly, all the wolves upgraded their position according to the position of a leading wolf with the subsequent formula:
Given that,
where
The cost function to be minimized is an error represented as follows
Where
Once the data is balanced, then it performs the classification process by the BiLSTM model. The presented module is based on the LSTM cell; the writing and reading memory cells
From the expression, without taking into account the optional peephole connection,
In Eq. (21)
Structure of BiLSTM.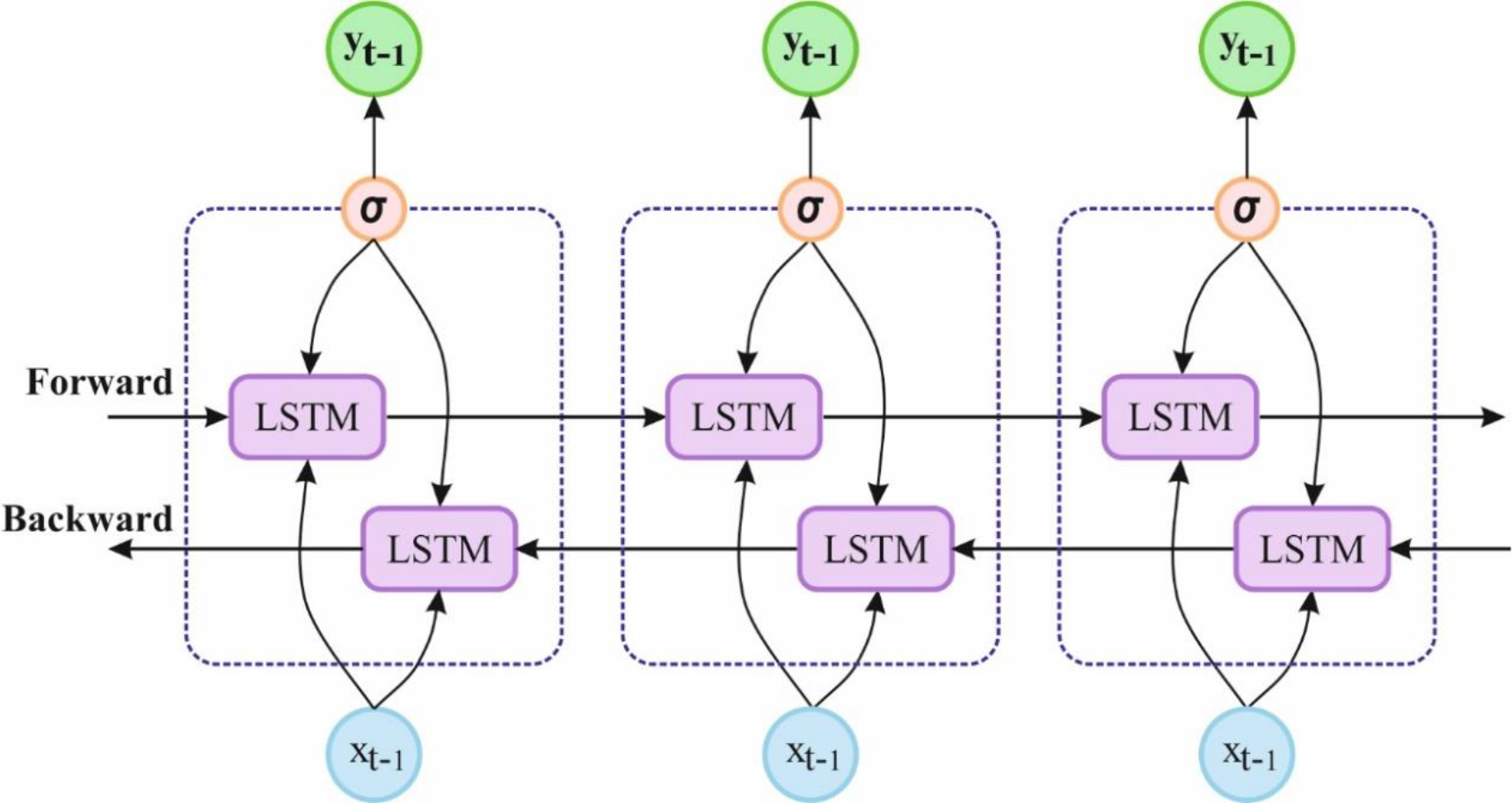
Finally, the hyperparameters related to the BiLSTM model are tuned by the Adam optimizer. Adam is an optimization approach that, rather than the typical stochastic gradient descent (SGD) process, might be utilized for iteratively updating network weights with trainable datasets [19]. The technique is highly effective when it comes to complicated problems with a larger amount of data or variables. It consumes lesser memory and is memory-effective. On the surface, it seems to be a mixture of the ‘RMSP’ algorithm and the ‘GD with momentum’. Two GD methodologies are integrated with the Adam optimizer.
Momentum: This technique employs the ‘exponential weight average’ to accelerate the GD model. The fast convergences to the minima can be accomplished by utilizing the average.
Where,
Root Mean Square Propagation (RMSP): Adoptive learning methodology focuses on enhancing AdaGrad in RMSprop. Instead of AdaGrad, an overall number of squared gradients, the ‘exponentially moving average’ is considered.
Where,
Afterward all the iterations, we instinctively modify the GD so that it remains unchanged and impartial during the process, hence it is called Adam. At present, in place of the standard weight parameter
In every method, this optimizer is utilized due to its minimal memory use requirement and higher efficiency.
Evaluation of the CIHODL-BDC technique is executed by the two datasets such as localization data and skin data. Here, the Localization data has been generated dependent upon the data detailed in the actions of 5 people who are ankle right, wearing tags, chest, and ankle left, and belt. The number of elements and samples from dataset 1 is 8 and 164 860. All the instances procedures localization data is to tag that is detected by element. In dataset 2, the skin data was attained by the R, G, and B values in the face images obtained in 2 databases such as FERET and PAL. The amount of samples accessible is 245 057. Here, the samples contain skin and non-skin samples. The skin instances for this dataset are taken as 50 859 skin instances and also the non-skin instances are taken as 194 198.
Table 1 provides the details of the whole sample that exists in the dataset before resampling and after the resampling process. The table values indicated that the dataset is properly sampled by the GWO-SMOTE technique.
Dataset details
Dataset details
Estimation of the confusion matrices of CIHODL-BDC model (a) 70% of TR dataset-1, (b) 30% of TS dataset-1, (c) 70% of TR dataset-2, and (d) 30% of TS dataset-2.
Figure 3 illustrates the confusion matrix of the CIHODL-BDC technique on the test dataset-1. On 80% of training (TR) dataset-1, the CIHODL-BDC model has recognized the samples from the walking class as 36780. Moreover, the 37849 samples are taken from the falling class, the lying class 36716 samples, and the 37265 samples from the sitting class. While testing (TS) 30% in dataset-1, the CIHODL-BDC approach has recognized various classes like walking, falling, lying, and sitting. Here, the walking class contains 15838 samples, 16219 samples from the falling class, 15578 samples contain the lying class, and the sitting class contains 16068 samples. While evaluating 80% of TR dataset-2, the CIHODL-BDC methodology has predicted skin sample contains 132955 and 133575 samples from the non-skin sample class. While considering 30% of TS dataset-2, the skin sample class is considered as 56843 samples, and 57426 samples are recognized from the non-skin sample class.
Dataset 1 performance analysis of CIHODL-BDC model with 70% of TR data.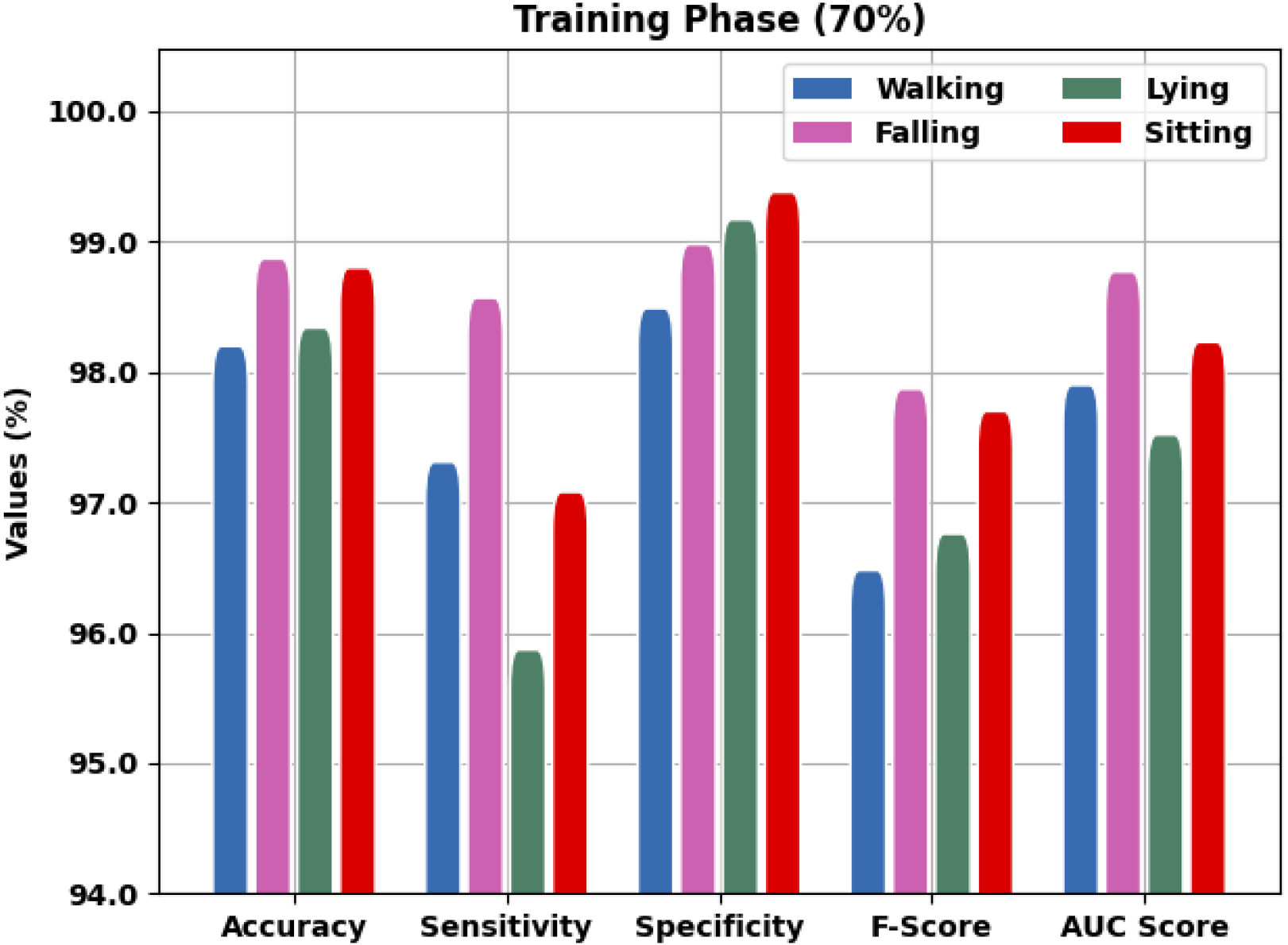
Dataset 1 validation of CIHODL-BDC technique with 30% of TS data.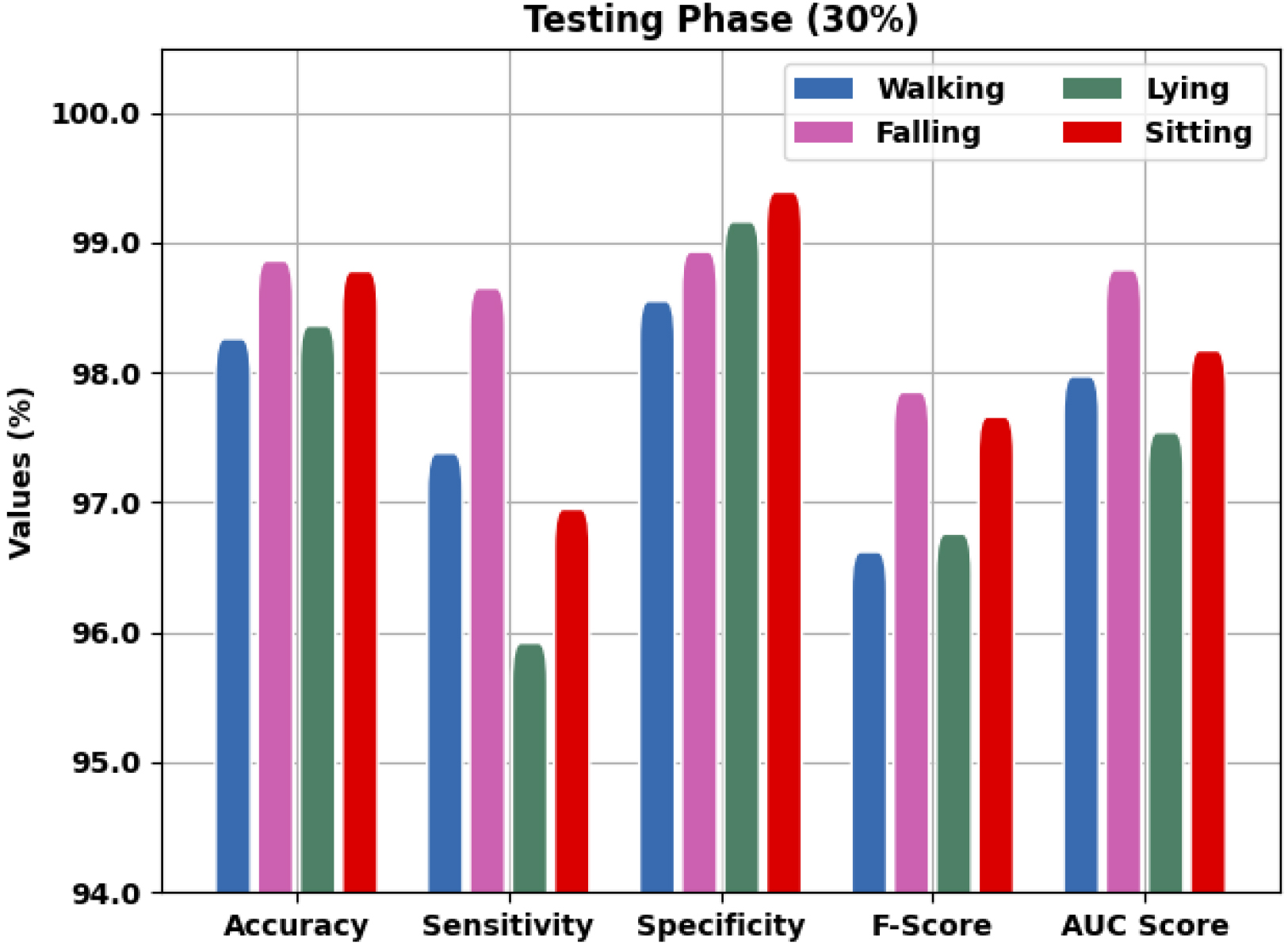
Figure 4 offers result outcomes of the CIHODL-BDC model regarding dataset-1 with 80% of TR data. Here, the CIHODL-BDC approach has recognized walking class samples with
Estimation of CIHODL-BDC approach based on TA and VA analysis under dataset-1.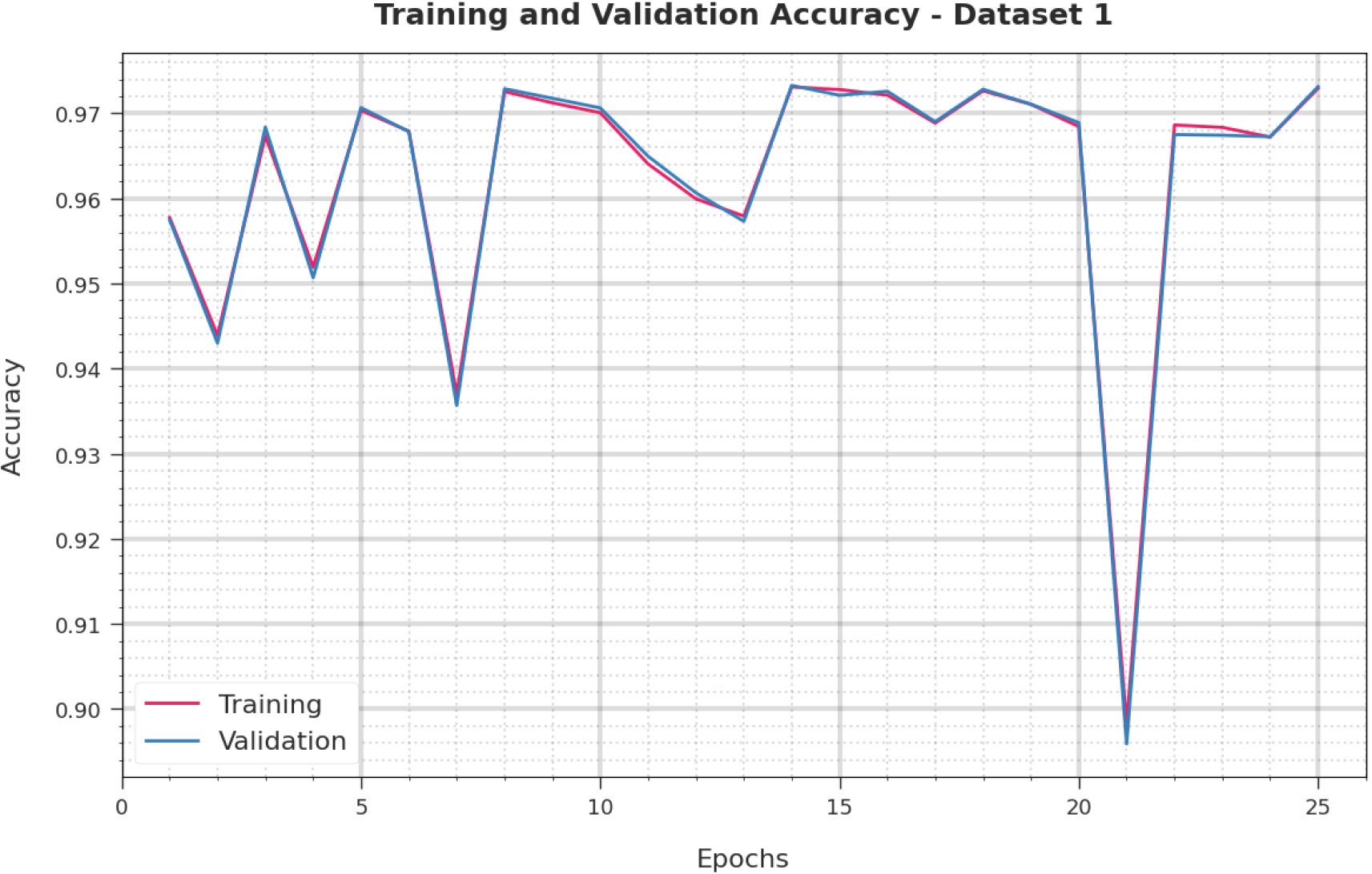
Analysis of VL and TL with the help of the CIHODL-BDC model under dataset-1.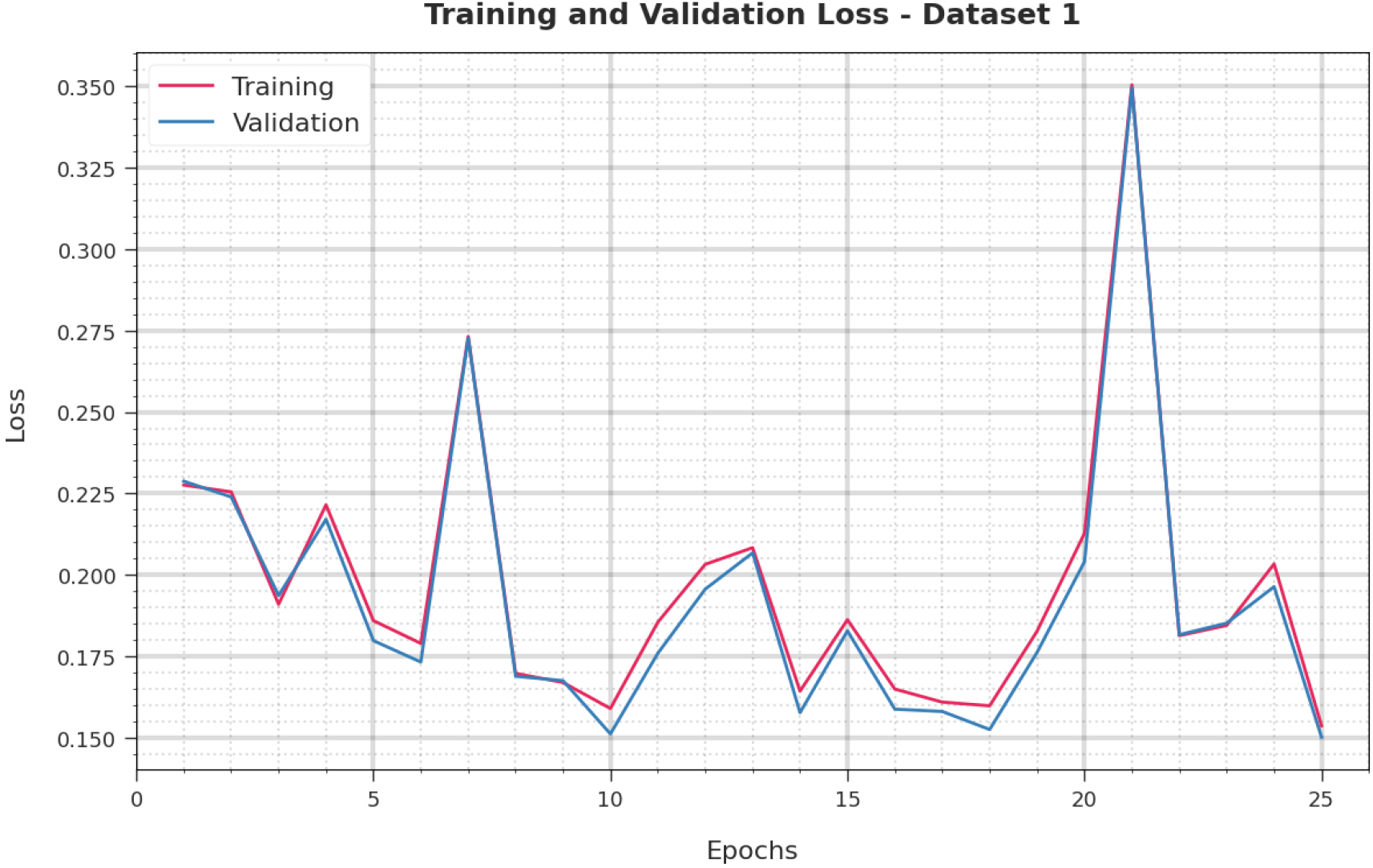
Figure 5 describes the brief experimental analysis of the CIHODL-BDC approach. The dataset-1 for the recommended approach is attained as 30% of TS data. The CIHODL-BDC has accessible effectual classification outcomes. Moreover, the CIHODL-BDC method has recognized walking class instances with
Performance analysis of CIHODL-BDC model under dataset-1 regarding recall and precision.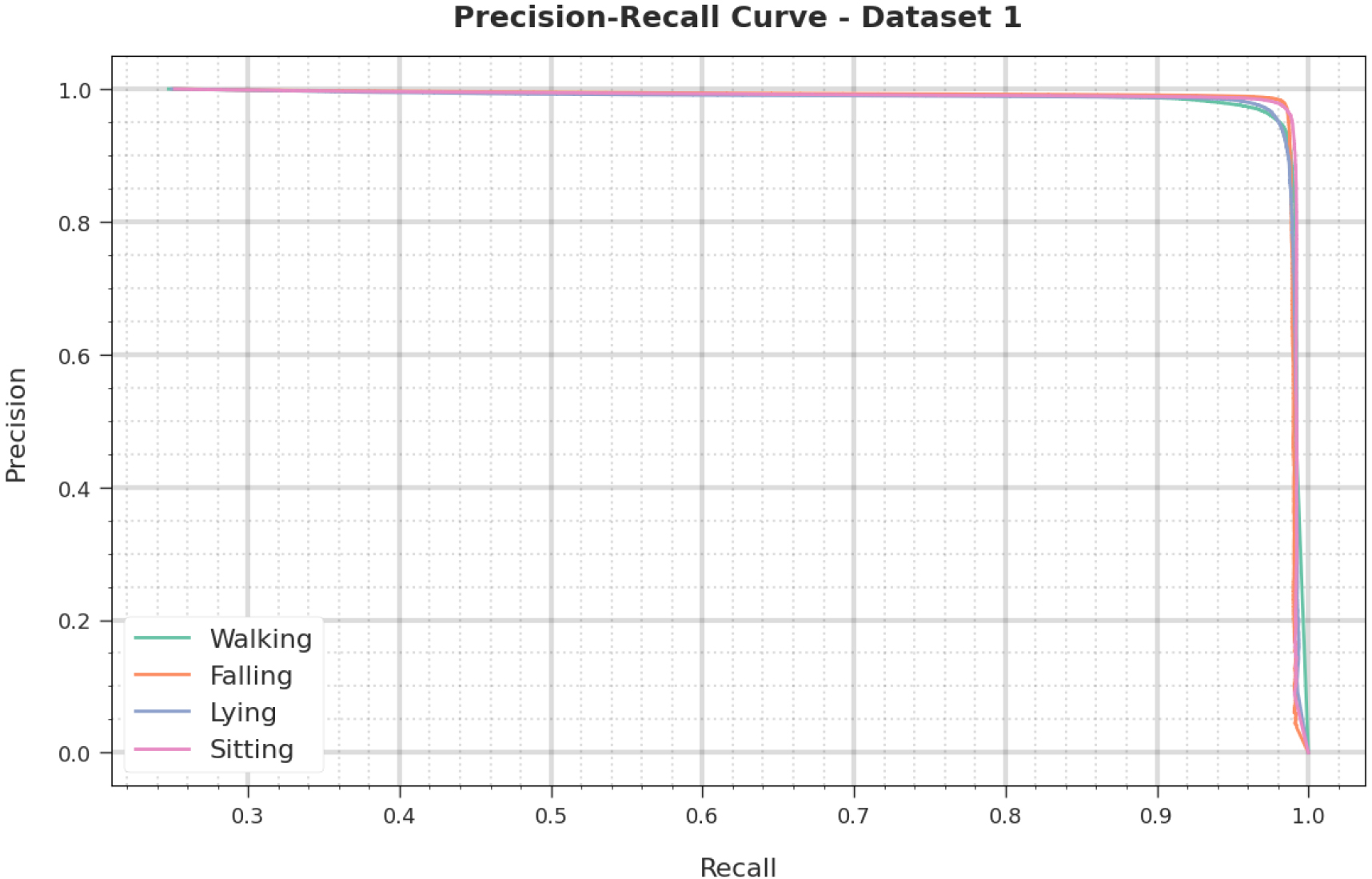
Estimation of ROC curve of CIHODL-BDC approach under dataset-1.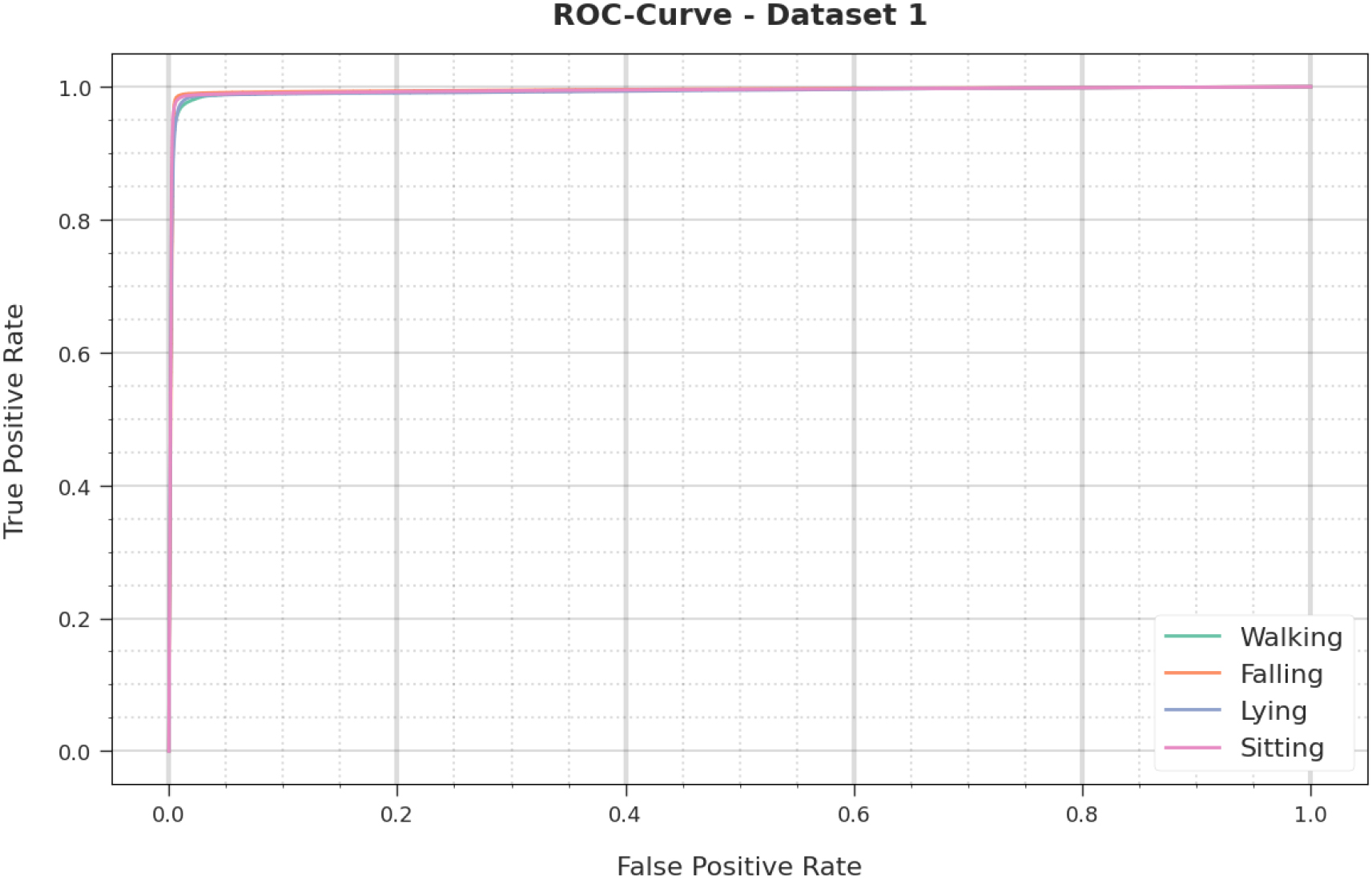
In Fig. 6, the TA and VA are validated by the CIHODL-BDC approach regarding dataset-1. The result validation of the CIHODL-BDC system has attained maximal values. Here, the VA provides better performance than the TA.
Figure 7 shows the analysis of TL and VL using the CIHODL-BDC technique concerning dataset-1. The analysis implied that the CIHODL-BDC algorithm has accomplished worse rates of VL and TL. Here, the performance of the VL is lesser than TL.
Figure 8 shows the evaluation of recall and precision of the CIHODL-BDC approach on test dataset-1. It is analyzed that the CIHODL-BDC method has attained a higher precision-recall performance.
ROC search of the CIHODL-BDC technique on dataset-1 is exposed in Fig. 9. It shows better performance of the CIHODL-BDC system has demonstrated that it can effectively categorize four several classes on the dataset.
The computation of the CIHODL-BDC method with existing classifiers on dataset-1 is provided in Table 2. The analysis of the CIHODL-BDC model has shown enhanced performance over existing approaches. With respect to
Table 2 depicts the overall big data classification outcomes of the CIHODL-BDC approach on dataset 2.
Comparative analysis of CIHODL-BDC approach of dataset-1
Evaluation of CIHODL-BDC model on dataset-2 with 70% of TR data.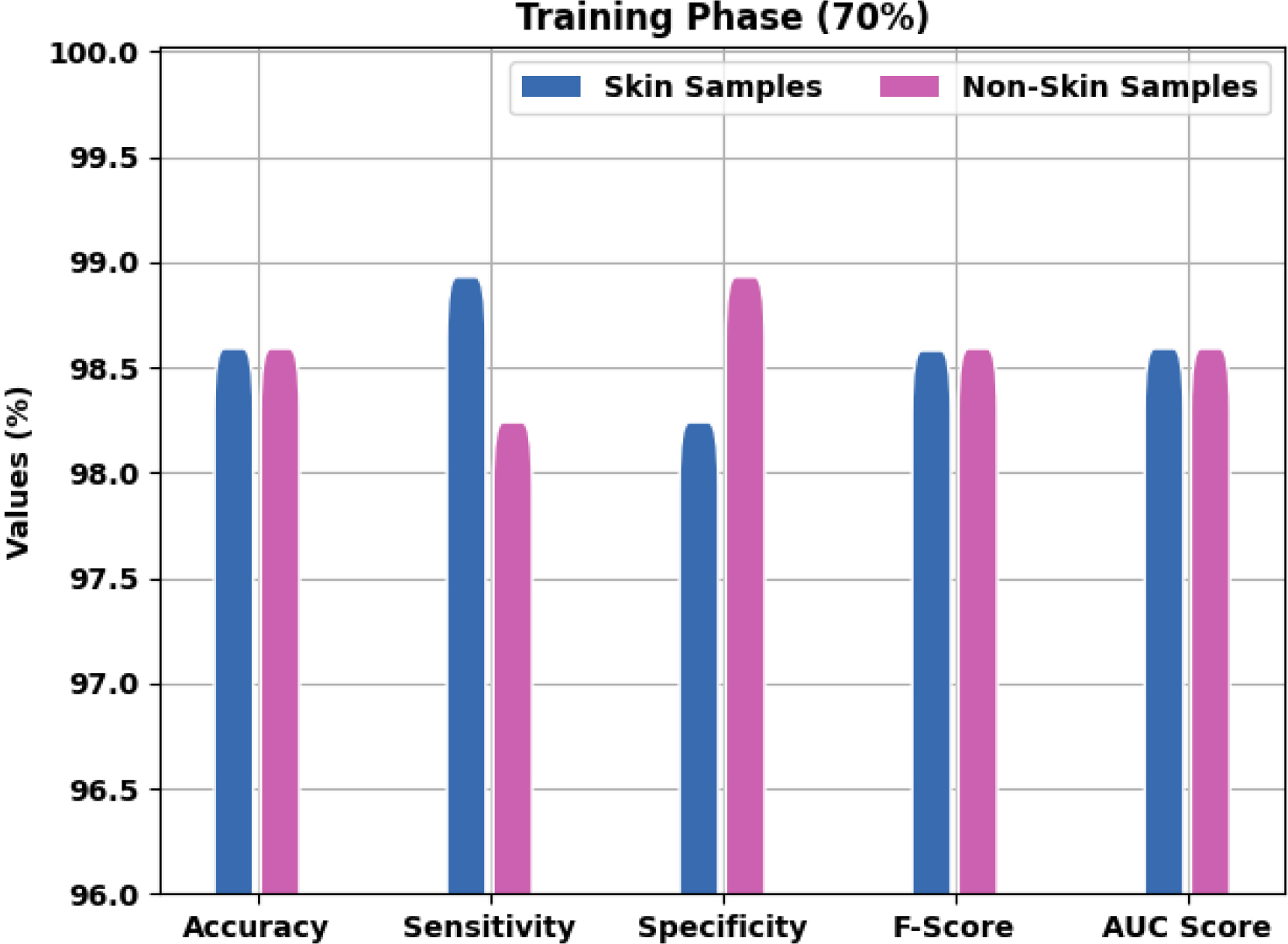
Estimation of CIHODL-BDC technique on dataset-2 with 30% of TS data.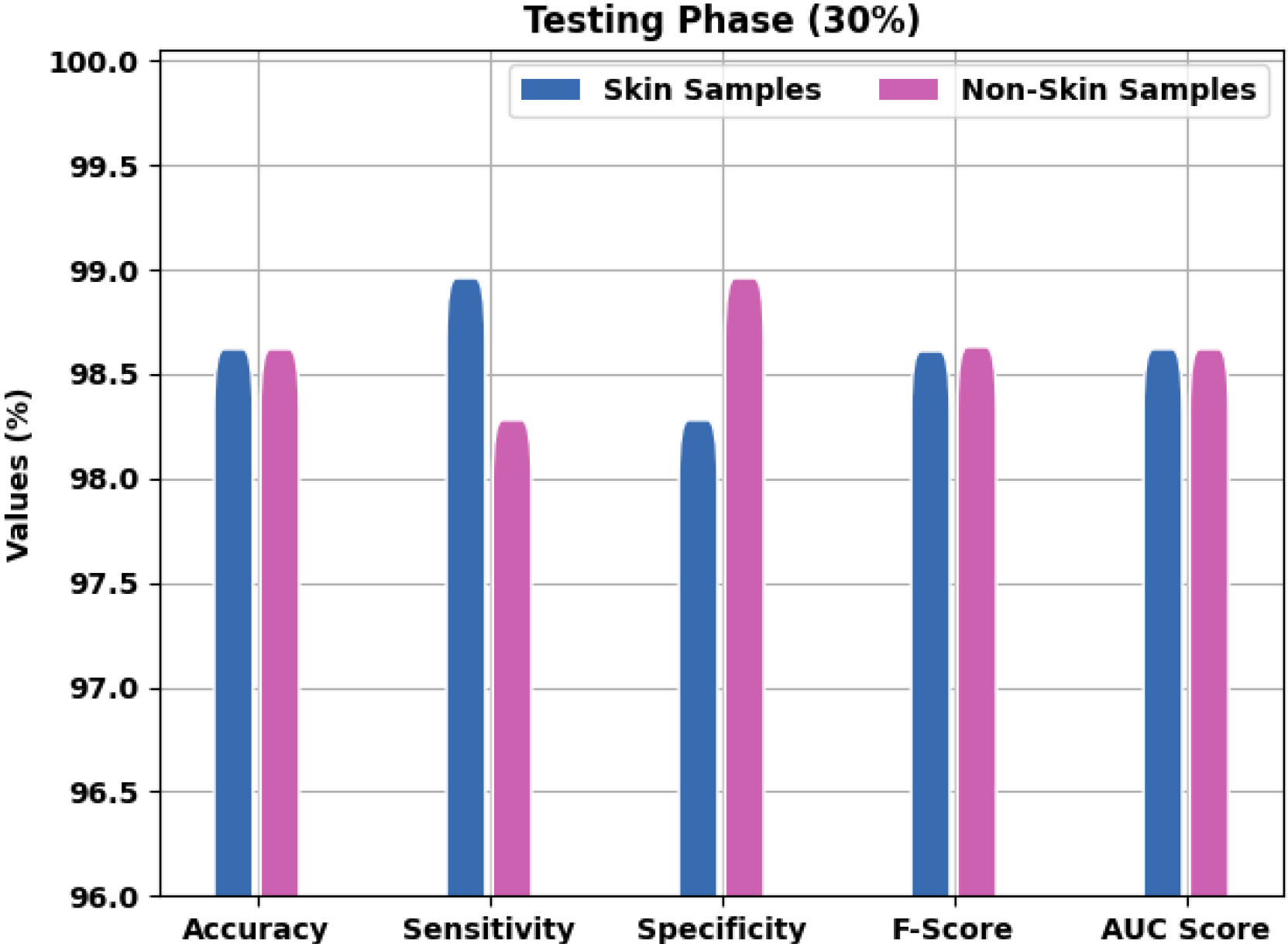
Evaluation of TA and VA of CIHODL-BDC technique under dataset-2.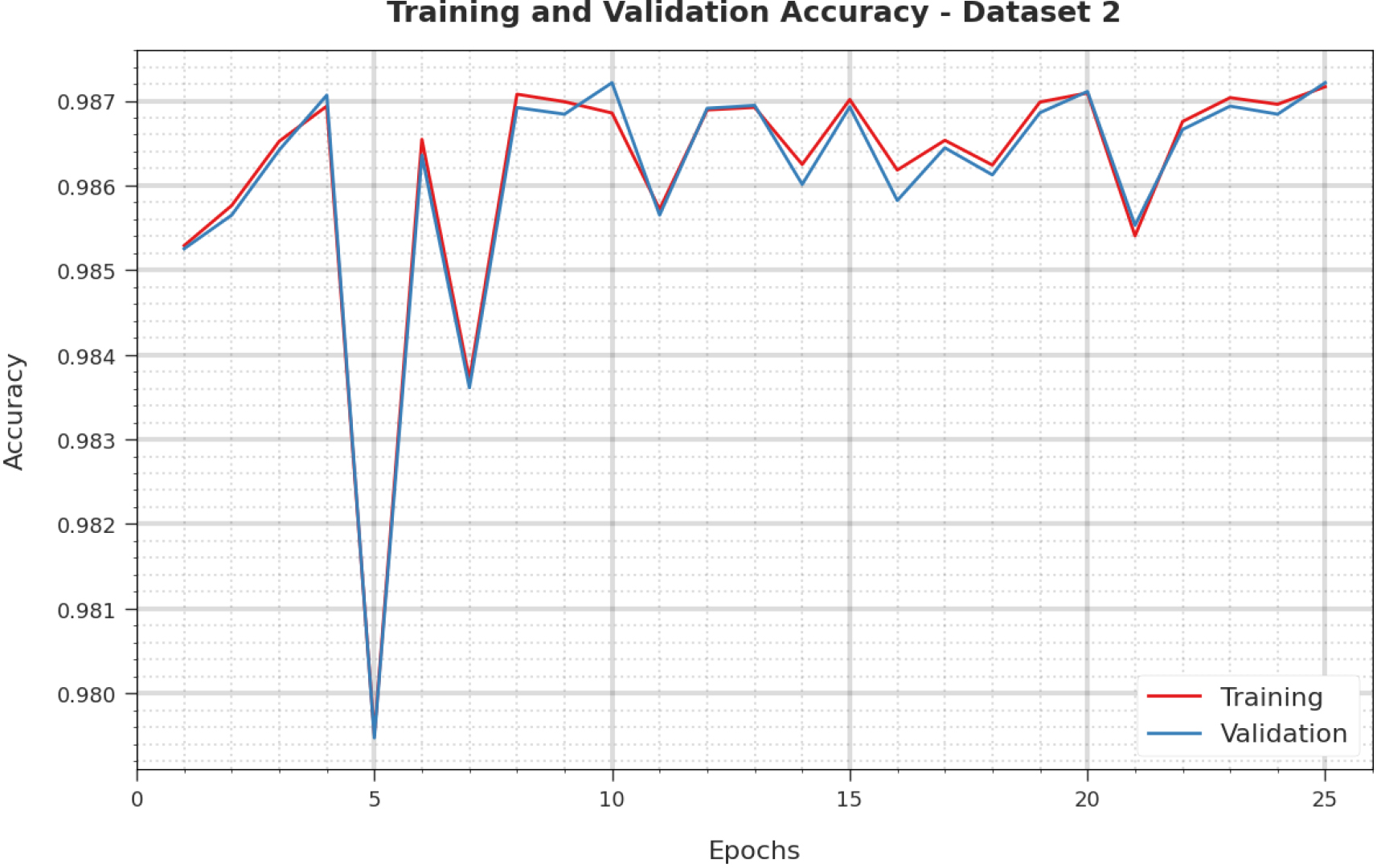
Estimation of TL and VL of CIHODL-BDC model under dataset-2.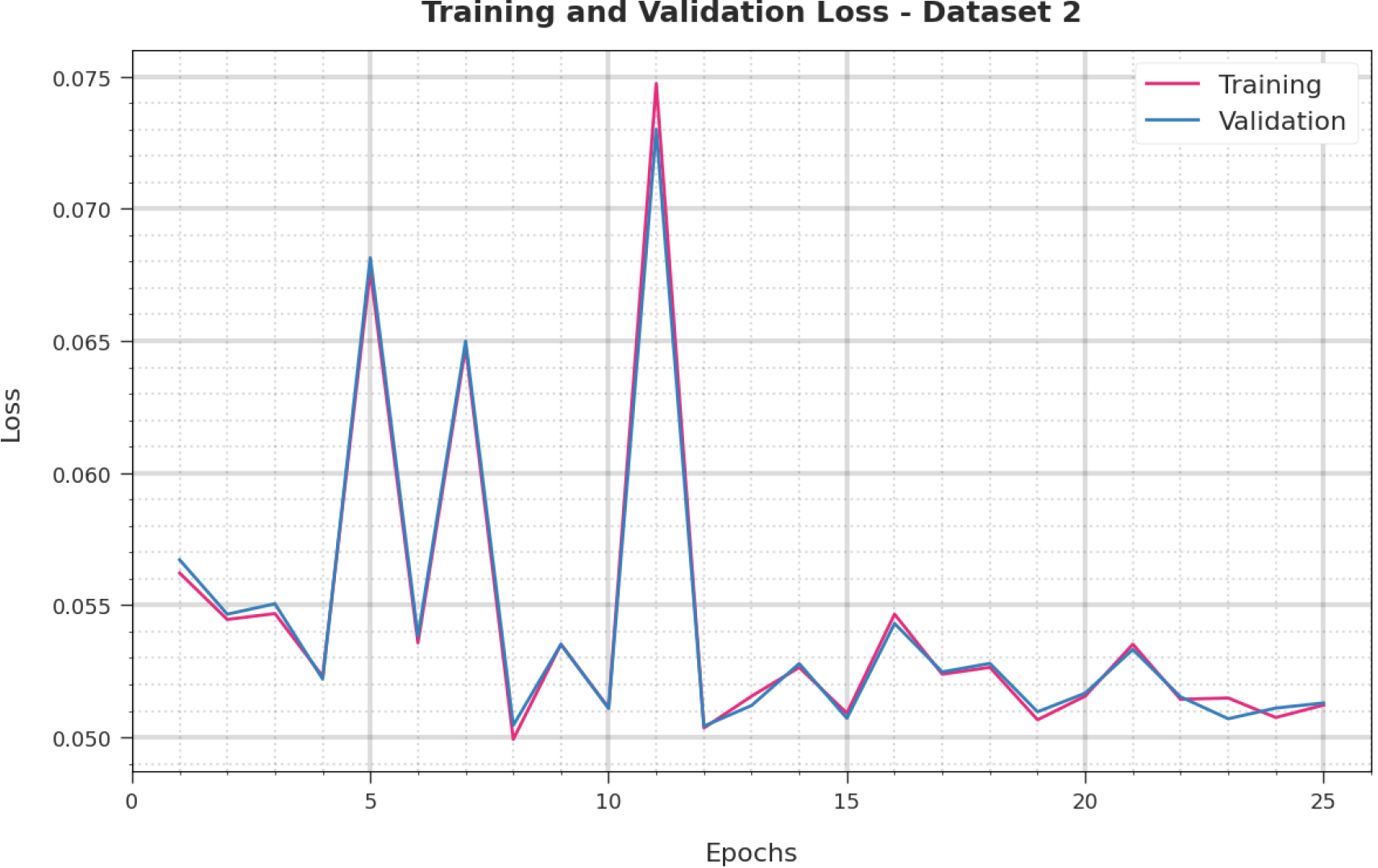
Evaluation of precision-recall analysis of CIHODL-BDC model under dataset-2.
Figure 10 gives a brief analysis of the CIHODL-BDC approach on dataset 2 with 80% of TR data. It referred that the CIHODL-BDC technique has existing effective classification outcomes. For sample, the CIHODL-BDC system has recognized skin class samples with
Figures 10 and 11 depict a brief outcome analysis of the CIHODL-BDC model on dataset-2 with 30% of TS data. The CIHODL-BDC system has identified skin class instances with
Estimation of the TA and VA of the CIHODL-BDC approach of dataset-2 is visualized in Fig. 12. The empirical outcome of the CIHODL-BDC system has achieved enriched rates of VA and TA. The TL and VL obtainead by the CIHODL-BDC methodology on dataset-2 are recognized in Fig. 13. The analysis has revealed that the CIHODL-BDC approach has sophisticated the lower rates of VL and TL. Thus, the performance of the VL is lower than TL.
Evaluation of precision-recall of the CIHODL-BDC methodology on dataset-2 is represented in Fig. 14. While observing, the CIHODL-BDC system has attained increased precision-recall performance.
Figure 15 provides the ROC curve of the CIHODL-BDC model on test dataset 2. The analysis shows that the CIHODL-BDC algorithm has displayed its ability to classify the two diverse classes on the dataset.
Computation of CIHODL-BDC model with baseline algorithms under dataset-2
CT analysis of CIHODL-BDC model with existing approaches
ROC curve of CIHODL-BDC technique under dataset-2.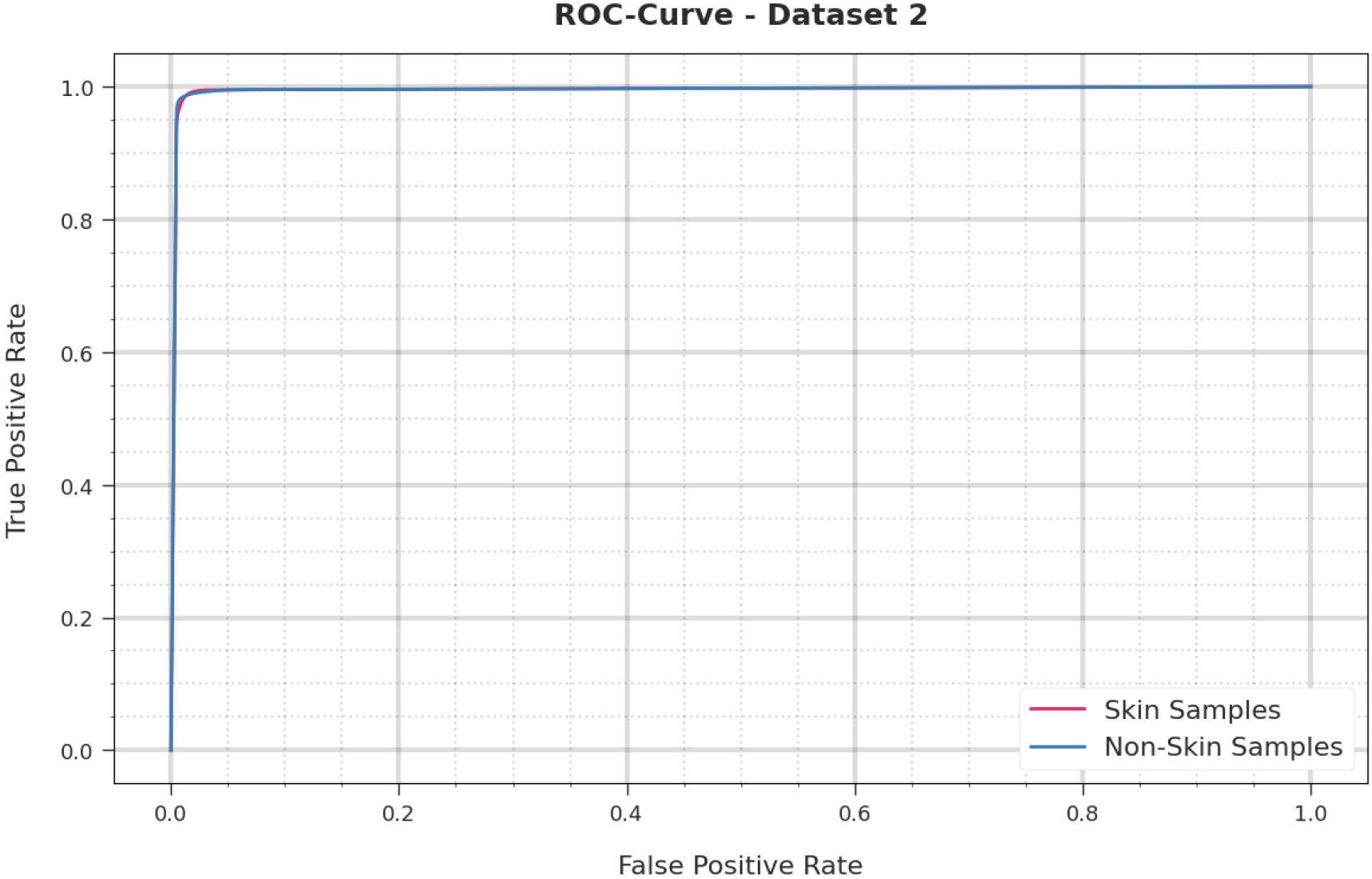
Cross-validation of the CIHODL-BDC method for dataset 1.
Cross-validation of the CIHODL-BDC technique for dataset 2.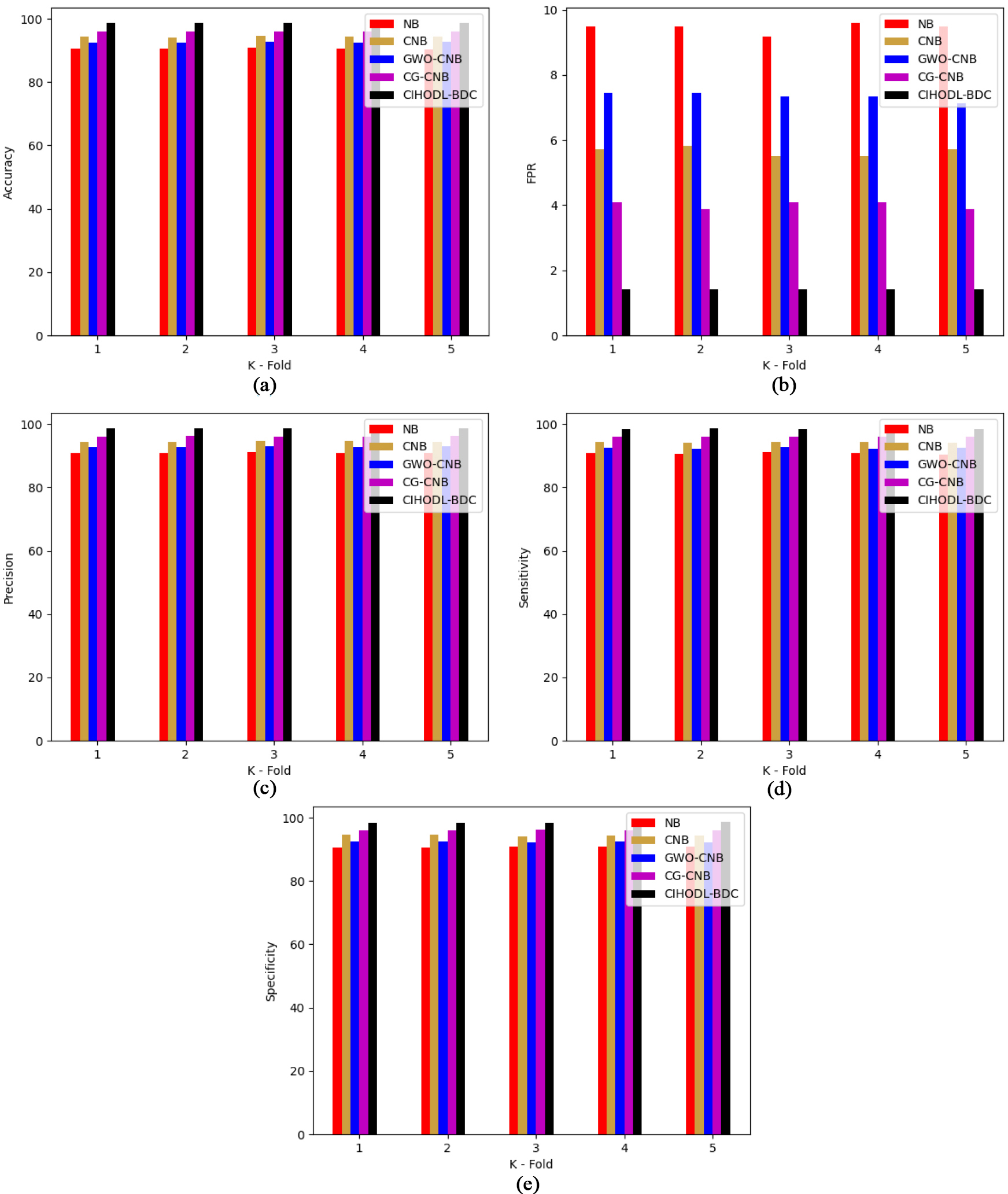
Statistical analysis of the CIHODL-BDC technique
A comparative analysis of the CIHODL-BDC model with several classifiers on dataset 2 is provided in Table 3. The simulation analysis of the CIHODL-BDC model has exhibited improved performance over other algorithms. In terms of
Finally, a computation time (CT) inspection of the CIHODL-BDC model with existing models is compared in Table 4. The result implies that the CNB model has attained the least performance with increased CT of 8 s. Moreover, the CG-CNB model has been validated in a reasonable CT of 6.78 s. However, the CIHODL-BDC model has reached effectual outcomes with a minimal CT of 6.12 s. Throughout the analysis, it is apparent that the CIHODL-BDC model has shown effective big data classification performance over other models.
The cross-validation of the designed approach using deep structured architectures is shown in Figs 16 and 17. While considering Figs 16 and 17, the accuracy rate of the designed approach is elevated than the NB, CNB, GWO-CNB, and CG-CNB. Most of the graph results have attained equivalent performance regarding various standard metrics. The NB model attained the least performance owing to this it easily falls into the local optimum and also it has an unbalanced dataset.
Statistical evaluation of the designed approach using baseline approaches
The statistical analysis of the offered model for the CIHODL-BDC technique is shown in Table 5. While taking Table 5, the statistical significance is done using two phases post-hoc multiple comparison and ranking. At first, the ranking procedure takes place. Secondly, the post-hoc multiple comparison is validated. In the end, the significant step is taken as 0.005. Because the experimental results must have a 5% or the least possibility of occurring null hypothesis to be statistically significant. From the empirical result, the output of the recommended model attains elevated performance.
Conclusion
A novel CIHODL-BDC model was introduced to classify big data. Here, the Hadoop MapReduce approach is performed for handling a huge amount of big data. The recommended CIHODL-BDC model follows a series of sub-processes like data wrangling, SMOTE-based class imbalance data handling, GWO-based parameter tuning, BiLSTM-based classification, and Adam hyperparameter optimizer. The result analysis of the offered CIHODL-BDC technique is estimated with the help of two standard datasets. The comparative study is highlighted to show the efficacy of the CIHODL-BDC technique over existing conventional techniques. Therefore, the CIHODL-BDC technique is utilized as an effective tool to employ the classification of the big data process. However, need to develop effective outlier detection mechanisms for performance improvements. It required the investigation of meta-learning approaches for automatic selection which helps for better feature selection. Effective outlier detection mechanisms can be introduced to further improve the efficacy of classification in the upcoming works. The author will include the meta-learning models for the automated selection of instance types for data sampling of each class.