
Abstract
With the continuous development of science and technology, it has become possible to acquire and process massive high-resolution image data. The amount of high-resolution image data is huge, and the traditional single-machine computing and processing methods may become inefficient, which is difficult to meet the needs of real-time or large-scale data processing. This article selected a high resolution satellite remote sensing image from the Landsat dataset for processing. Gaussian filtering was used to denoise the image, followed by K-means algorithm for image segmentation. The image data was then transmitted and stored and the results of image data processing were merged. Data processing efficiency and storage space utilization were analyzed for different data segmentation and storage methods. According to the experimental results, it could be concluded that the method of image resolution segmentation not only had fast processing speed, but also produced higher data quality. The storage space utilization rate using AWS S3 (Amazon Simple Storage Service) storage solution was the highest, reaching a maximum of 0.98. The response time was the shortest, around 100 ms. AWS S3 showed the highest read speed, between 147 MB and 154 MB per second. It could be seen that when processing massive high resolution image data, appropriate segmentation methods and storage schemes should be selected. The research and application of distributed computing and storage strategies for massive high resolution image data posed certain theoretical and technical challenges, which could promote the development of distributed computing and storage technology, technological progress and innovation in related fields.
Keywords
Introduction
With the continuous progress of technology and the expansion of application fields, the amount of image data obtained is increasing, requiring more efficient storage and processing methods. Processing massive high resolution image data is a challenging issue that requires finding suitable distributed computing and storage strategies to improve processing efficiency and data utilization. In the traditional centralized computing mode, the efficiency and cost of processing large-scale data are limited. Therefore, it is necessary to use distributed computing and storage technology to divide the data into multiple small blocks and allocate computing tasks to multiple nodes for parallel processing, to improve processing efficiency and reduce computing costs. Massive high resolution image data processing is an important challenge in many fields, such as satellite remote sensing, medical imaging analysis, video surveillance, natural disaster early warning, etc. These fields require rapid and accurate processing and analysis of massive high resolution images to extract valuable information and knowledge. These data are usually used in fields such as medical image diagnosis and remote sensing image analysis, but the massive amount of data and complex image information make their processing difficult. To address this issue, it is necessary to study corresponding distributed computing and storage strategies to better manage and utilize this data Distributed computing and storage technology can accelerate the processing and analysis process of image data, improve data utilization and value and provide support for intelligent and automated image analysis.
The processing of massive high resolution image data has become an important field of technological development and application. Artificial intelligence continues to generate great interest in medical imaging. The potential applications are broad, including the entire medical imaging lifecycle from image creation to diagnosis and result prediction. Willemink Martin J described the basic steps in preparing medical imaging data in artificial intelligence algorithm development, explained the limitations of current data management and explored new methods to address data availability issues [1]. Overlearning refers to network learning of functions with very high variance to model training data perfectly. Unfortunately, many application fields cannot access big data, such as medical image analysis. The image enhancement algorithms discussed by Shorten Connor included geometric transformation, color space enhancement, kernel filter, mixed image, random erasure, feature space enhancement, adversarial training, generation of adversarial Sexual network, neural style transfer and meta learning [2]. The purpose of Joyce K.E was to provide a practical guide for data collection considerations based on drones. He hoped to minimize the amount of trial and error required to obtain high-quality, mappable data by outlining the principles and practices of using drones to collect data, especially in marine and freshwater environments. Due to the use of remote sensing and photogrammetry theories, the collected data was suitable for measurement and quantitative data analysis [3]. Traditional image processing methods are no longer able to meet the needs of these applications, so new data processing strategies are needed. Previous studies have highlighted the potential application of massive high-resolution image data processing, and provided key insights in artificial intelligence, image enhancement algorithm and UAV data collection. However, the access restriction of big data is still a common challenge, which needs new data processing strategies to solve. Future research should focus on integrating these methods to improve the comprehensive processing efficiency of massive high-resolution image data.
Distributed computing and storage technology can improve data processing efficiency and storage space utilization by dividing data into multiple parts for processing. The storage and query of remote sensing images are important contents in geographic information processing, playing an important role in the real-time processing of massive remote sensing images. In response to the problems of single node failure, low scalability and low processing efficiency in traditional remote sensing image processing, Jing Weipeng proposed a distributed storage and query scheme for remote sensing data based on HBase (Hadoop Database). This method first used a uniform grid to partition remote sensing images and designed an indexing scheme based on a combination of grid and curve based on the partitioning results. Then, by utilizing the filtering mechanism of HBase, a filtering column family was designed to achieve the goal of filtering data during queries. Besides, parallel processing methods were used for parallel writing and querying of image data [4]. To address the contradiction between the practical needs of embedded front-end running artificial intelligence and its own performance deficiencies, Li Ximeng proposed a distributed artificial intelligence computing architecture system that could be flexibly deployed. Through a carefully designed network communication program, the data that embedded devices needed to calculate was sent to the cloud and then high-speed computing was carried out using the cloud’s workstation cluster. The distributed feature endowed the system with a certain degree of disaster recovery redundancy, effectively avoiding the collapse of the entire system due to the collapse of a few computing nodes, using cluster computing mode and greatly reducing the system’s requirements for the number of public networks [5]. However, they did not process high resolution image data, only analyzed it.
The challenges of processing high-resolution image data mainly include storage requirements and computing resource pressure. High-resolution images contain a large number of pixels, which leads to a huge amount of data and requires more storage space. At the same time, processing these data requires a lot of computing resources, which may lead to the inefficiency of traditional computing methods. To efficiently store and calculate data, this article adopts a scheme of using Gaussian filtering and K-means algorithm for image denoising and segmentation to satisfy the processing requirements of high resolution image data. The efficiency and utilization of different data segmentation and storage methods are analyzed. The experimental results show that the method of image resolution segmentation has faster processing speed and higher data quality and the AWS S3 storage scheme has the highest storage space utilization. This indicates that when processing massive high resolution image data, appropriate segmentation methods and storage schemes should be selected. This article adopts an image denoising and segmentation scheme based on Gaussian filtering and K-means algorithm and focuses on studying the applicability of image resolution segmentation methods in processing massive high resolution image data.
Distributed computing and storage strategies for high resolution image data
High resolution image data
High resolution image data refers to digital images with high pixel density and high definition, which are usually used in printing, medical imaging, geological exploration, satellite remote sensing and other fields [6, 7]. High resolution image data usually has higher clarity and details and can present very realistic image effects. High resolution image data can be a single image or a collection or sequence of multiple images [8, 9]. In the field of digital images, PPI (Pixels Per Inch) and DPI (Dots Per Inch) are commonly used to describe the resolution of an image. The resolution of high resolution image data is usually higher than 300 PPI or 1200 DPI.
High resolution image data is widely used in various fields [10, 11]. In the field of printing, high resolution image data can ensure the quality and clarity of printed matter. In the field of medical imaging, high resolution image data can help doctors make more accurate diagnosis and treatment plans [12, 13]. In the field of geological exploration, high resolution image data can be used to discover mineral resources and groundwater resources. In the field of satellite remote sensing, high resolution image data can be used to monitor surface environment and meteorological changes.
Processing high resolution image data is often a challenging task. Due to the large number of pixels contained in high-resolution image data, processing requires a large amount of computation, which poses high requirements for computer performance. To process high resolution image data, parallel computing and distributed storage technologies are commonly used to improve computational efficiency and data transmission speed. Meanwhile, professional image processing software and hardware facilities are also needed to achieve tasks such as preprocessing, analysis and display of high resolution image data.
High resolution image data has significant application value in many fields, as it can provide richer information and more accurate data, helping people make better decisions and judgments [14]. Although there are certain technical challenges in processing high resolution image data, with the continuous development of technology, its application prospects are still very broad. The technical challenges of processing high-resolution image data mainly include huge data volume, high computational complexity and large storage requirements. Because high-resolution images contain more details, it leads to a huge amount of data, which puts higher demands on computing and storage resources. At the same time, the processing of high-resolution data requires more complex algorithms and models, which increases the computational complexity. These challenges need to improve processing efficiency through effective distributed computing and storage strategies on the premise of ensuring data quality.
High resolution satellite remote sensing images.
The Landsat dataset is satellite remote sensing data initiated by the United States Geological Survey to monitor global land surfaces. This article selects the Landsat dataset for experimental testing, where Landsat 1–7 satellites obtains over 3 million remote sensing images with resolution ranging from 60 meters to 15 meters. The Landsat 8 satellite was launched in 2013 and has since obtained millions of high-quality remote sensing images. This article performs preprocessing, segmentation, aggregation and other operations on a certain image in this dataset and saves it on AWS S3 (see Fig. 1).
Landsat data set is a collection of remote sensing images obtained by Landsat series satellites, including Landsat 1 to Landsat 7. This data set contains more than 3 million remote sensing images, covering a wide range. The resolution varies from 60 meters to 15 meters, which provides multi-spectral and high-resolution image data for regular observation of the earth’s surface.
Apache Spark is a fast, universal, scalable, and fault-tolerant distributed computing system developed by the Apache Software Foundation, mainly used for large-scale data processing. To achieve this goal, a distributed computing framework such as Apache Spark can be used to divide the dataset into several small blocks, with each node processing a subset of these small blocks and writing the results back to AWS S3. Specifically, the following steps can be performed:
Uploading the dataset to AWS S3, it is divided into k small blocks.
Each node reads its own allocated small blocks and performs operations such as cropping, scaling and normalization on the images within them to generate processed image data.
The processed data is wrote back onto AWS S3 for subsequent training, validation and testing tasks.
By using distributed computing and storage strategies, the processing and analysis of image data can be accelerated and the efficiency and accuracy of data processing can be improved.
Apache Spark is an open source distributed computing framework, which provides efficient and easy-to-use data processing and analysis tools. Spark accelerates the processing of large-scale data by dividing the data set into small pieces and processing each node in parallel.
In the system model of distributed computing and storage strategy of high-resolution image data, the high-resolution satellite remote sensing image data from Landsat dataset is input, and the image data is Gaussian filtered to remove noise and smooth the image. The preprocessed image is segmented by K-means algorithm, and the image is divided into different regions or clusters. Distribute the segmented image data to different computing nodes and perform processing operations in a distributed manner. Each computing node extracts the features of the allocated image area, and the processed image data is transmitted to the storage node, using AWS S3 storage strategy. The image region results processed by each computing node are merged to generate a complete processing result.
High-resolution image data has rich details and clarity, which can provide more accurate and fine image information. This is of great value in the fields of satellite remote sensing, medical imaging and geological exploration, which supports accurate analysis, diagnosis and decision-making, and provides a more reliable data base for scientific research and practical application.
In distributed computing and storage, data is usually divided into multiple parts according to certain rules. Each part is called a “data block”, which can improve data processing efficiency and parallelism. Parallelism refers to the number of tasks or task flows that occur simultaneously in distributed computing. These data blocks can be distributed and stored on different nodes to achieve distributed storage. Due to the parallel processing of data blocks, multiple computing nodes in a distributed computing cluster can be utilized to simultaneously process different data blocks to improve data processing efficiency and accelerate task completion speed.
Parallelism refers to the ability to process multiple tasks or data blocks simultaneously in distributed computing. By dividing the data into multiple parts, the system can execute these parts in parallel on different processing nodes, thus improving the overall data processing efficiency. Parallelism allows the system to handle multiple tasks at the same time, speeds up the calculation process and improves the overall performance of the system.
In distributed storage, distributed file systems are generally used, such as HDFS (Hadoop Distributed File System), AWS S3, Ceph, etc. These distributed file systems ensure the reliability and security of data by storing data blocks on multiple nodes and using complex backup and recovery strategies. Meanwhile, these distributed file systems can automatically handle data node failures and data replication issues to ensure high availability and fault tolerance of data.
For the processing of image data, distributed computing and storage technology can generally be used to accelerate processing and improve efficiency.
Image data preprocessing
High resolution satellite remote sensing denoising image.
Firstly, it is necessary to preprocess the original image, including removing noise, adjusting color and brightness and other steps. This can reduce the errors and noise interference in image processing. Due to various interferences that may occur during image acquisition, such as electronic noise, changes in lighting and vibrations, denoising techniques are needed to mitigate these effects. Denoising techniques include median filtering, mean filtering, Gaussian filtering, etc., which can remove random or periodic noise from images. This article selects Gaussian filtering method to denoise high resolution satellite remote sensing images and the denoised image is shown in Fig. 2 [15, 16, 17].
The formula of the two-dimensional Gaussian filter is:
The Bilateral filter can balance the edge information of the image and remove noise and its formula is:
The Gaussian mixture model can effectively remove the Gaussian white noise in the image and its formula is:
Image data segmentation refers to dividing an image into multiple small blocks according to certain rules or algorithms, to process data separately at multiple nodes. It can extract target information from images and provide more accurate information for subsequent image processing tasks such as detection, recognition and analysis, which has the advantages of improving processing efficiency and accuracy. The main purpose of image data segmentation is to improve processing efficiency, while also facilitating the processing of large-sized image data. Common image segmentation methods include threshold segmentation, edge segmentation and K-means algorithm.
This article adopts the K-means algorithm for image data segmentation [18, 19]. The K-means algorithm is a clustering algorithm that divides data by clustering data points. For image data, it can be regarded as a set of data points composed of several pixel points. Therefore, the K-means algorithm can divide the image into K regions, thereby achieving image data segmentation.
The steps for image data segmentation using the K-means algorithm are as follows:
Treating each pixel in the image as a data point, it is composed into a set of data points. Initializing K cluster centers, K pixels are randomly selected as cluster centers. For each pixel, calculating its distance from the center of each cluster, it is assigned to the cluster represented by the nearest cluster center. The center of each cluster is recalculated based on the new cluster allocation results.
The above steps 3 and 4 are repeated until the cluster center no longer changes or the predetermined number of iterations is reached.
High resolution satellite remote sensing segmentation image.
Finally, K clusters can be obtained, with each cluster representing a portion of the image. Each cluster can be considered as a block and sent to multiple nodes for parallel processing to improve processing efficiency. The final image obtained is shown in Fig. 3.
The K-means clustering method can classify pixels with similar characteristics into the same category and its formula is:
The relevance vector machine clustering method can project pixels into a high-dimensional space by mapping and cluster in this space. Its formula is:
Image data transmission and storage are important steps in distributed image processing. During the transmission process, factors such as bandwidth and network latency need to be considered, while also ensuring the reliability of data transmission. In the storage phase, redundant backup and data recovery strategies are usually adopted to ensure the reliability and fault tolerance of data. Distributed file systems such as HDFS, Ceph, etc. can be selected based on actual situations to store and manage data. This article transfers the segmented image data blocks to different nodes for processing and stores them in a distributed file system. During storage, redundant backup and data recovery strategies can be adopted to ensure data security.
Image data processing
When image data is divided into multiple blocks and dispersed on different computing nodes, it is necessary to ensure that the image blocks on each node can be effectively processed, which requires parallel computing to accelerate processing speed and improve efficiency. Through parallel computing, the computing resources of multiple computing nodes can be fully utilized, greatly reducing the completion time of the entire image processing task. During the processing, parallel computing can be achieved through multiple processes or threads and the number of processes or threads can be adjusted according to the actual situation to fully utilize the computing resources of each node.
Aggregation of processing results
The advantage of data aggregation and consolidation lies in the ability to aggregate and combine information from multiple data sources, improve the efficiency and accuracy of data processing and support deeper data analysis and decision-making. The results obtained from processing on different computing nodes need to be aggregated and merged to obtain complete image processing results. In this process, it is necessary to pay attention to factors such as data transmission bandwidth and network latency to prevent data loss or inaccurate processing results. For the consolidation of processing results on different calculation nodes, multiple methods can be used, such as ensemble learning, voting, etc. Ensemble learning can get better results by integrating different models and algorithms, while voting method can get the final result by voting the processing results of different computing nodes.
Impact of different data segmentation and storage methods on data processing efficiency and storage space utilization
Experimental design
Data collection and processing
Firstly, it is necessary to collect some high resolution image data as experimental samples and divide the data into multiple small blocks according to certain rules. Different segmentation methods may generate data blocks of different sizes, quantities and shapes, so effective recording is necessary in experiments for subsequent evaluation.
Data storage
Selecting different data storage schemes for comparison based on experimental requirements, open-source distributed file systems can be chosen, such as HDFS, Ceph and AWS S3. In the process of data storage, it is necessary to consider data backup and recovery strategies to ensure the reliability and security of the data.
Data processing
When conducting data processing in a distributed computing framework, it is necessary to consider issues such as the loading and processing speed of data blocks, as well as load balancing and fault tolerance of computing tasks. Popular computing frameworks such as Apache Spark or TensorFlow can be used and algorithm improvements can be made based on experimental needs.
Experimental evaluation
Finally, evaluating the experimental results and comparing the effectiveness of different segmentation methods and storage schemes are necessary. Collecting indicators such as computing time, storage space utilization and data read and write speed, their advantages and disadvantages are analyzed.
By testing the impact of different data segmentation and storage methods on data processing efficiency and storage space utilization, important reference and guidance can be provided for the research of distributed computing and storage strategies for massive high resolution image data.
In five independent tests, the data processing time and quality scores under three schemes were evaluated. Average computing time, image resolution and data quality are used as evaluation criteria. Through many experiments, the performance of each scheme under different conditions is comprehensively considered to ensure the accuracy and reliability of the experimental results.
Data dissection
Impact of different segmentation methods on data processing time
Data processing time and data processing quality under different segmentation methods.
This article compares the impact of three different segmentation methods on data processing time, with scheme A segmented according to image size, scheme B segmented according to image resolution and scheme C randomly segmented. To prevent accidental testing, this article conducted 5 separate tests for this experiment, testing the data processing time and data processing quality scores under three different schemes (the full score is 100 points, and the higher the score, the better the quality). The experimental results are shown in Fig. 4.
As shown in Fig. 4, Fig. 4(a) shows the processing time under three different schemes and Fig. 4(b) shows the data processing quality scores under three different schemes. According to Fig. 4, different segmentation methods had varying degrees of impact on data processing time and quality. The method of segmentation based on image resolution was faster than the method of segmentation based on image size and the processed data quality was higher, reaching a maximum of 95 points. The method of random segmentation resulted in longer calculation time and relatively low data processing quality, with a minimum score of only 68 points. Therefore, when processing massive high resolution image data, appropriate segmentation methods should be selected to obtain higher quality and efficiency data processing results.
Storage space utilization and response time under different storage schemes.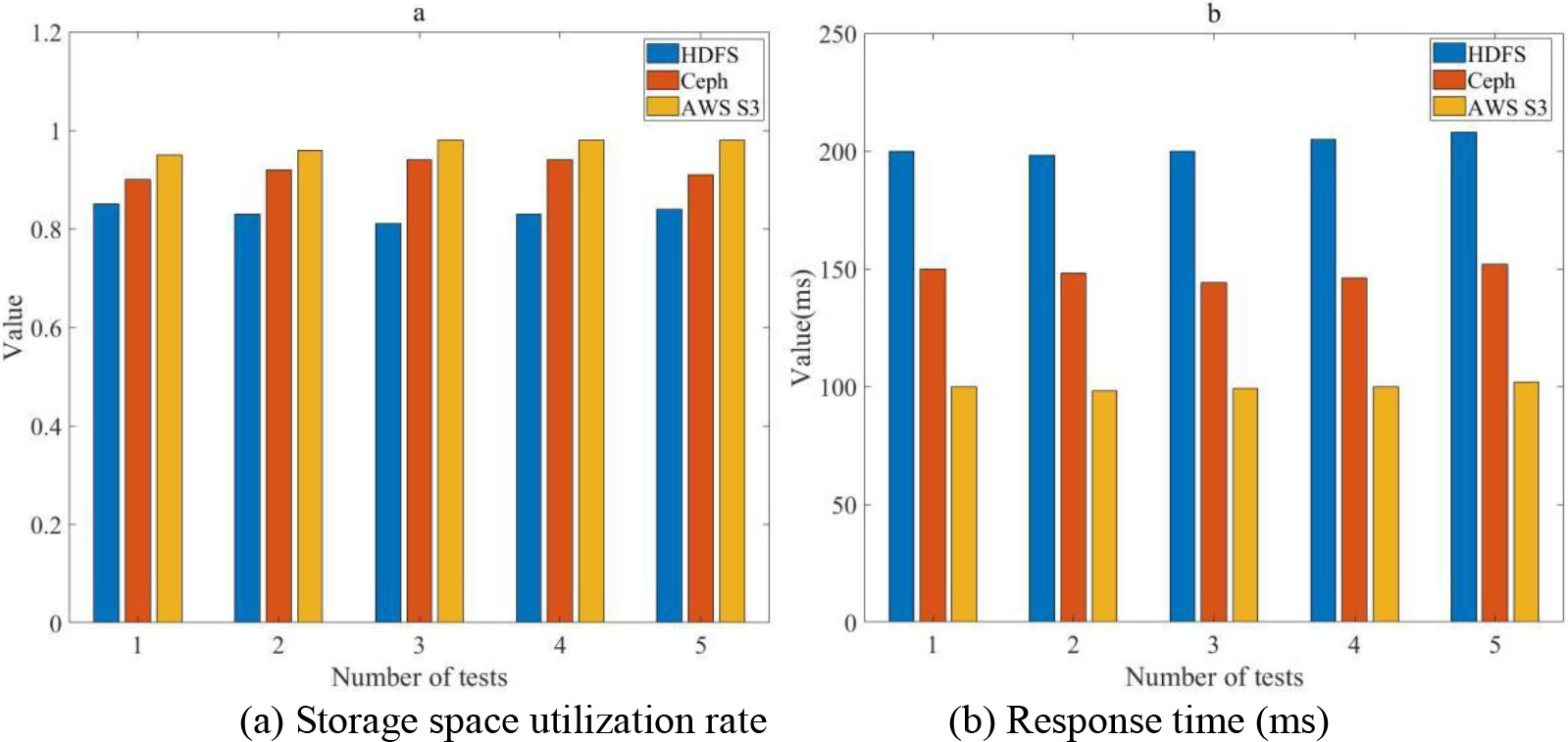
This article compared the effects of three different storage schemes on storage space utilization and response time and the experimental results are shown in Fig. 5.
As shown in Fig. 5, Fig. 5(a) shows the storage space utilization under three different storage methods and Fig. 5(b) shows the response time under three different storage methods. Seen from Fig. 5, different storage schemes had varying degrees of impact on storage space utilization and response time. The AWS S3 storage scheme had the highest storage space utilization rate, reaching a maximum of 0.98 after five tests. Compared to the Ceph scheme, the storage space utilization rate was slightly lower. The storage space utilization rate of the HDFS scheme was relatively lower. Besides, the AWS S3 storage scheme had the shortest response time, around 100 ms, followed by Ceph and HDFS. From this, it can be concluded that multiple indicators should be considered to evaluate the performance of different storage schemes and the optimal storage scheme should be selected to achieve more efficient data storage and processing.
This article compared the effects of three different storage schemes on data read and write speed and the experimental results are shown in Fig. 6.
As shown in Fig. 6, Fig. 6(a) shows the data read speed under different storage schemes and Fig. 6(b) shows the data write speed under different storage schemes. The speed of data read and write varied among different storage schemes. The data read speed ranged from 95 MB to 154 MB per second, while the data write speed ranged from 80 MB to 128 MB per second. It can be seen that different storage schemes had different advantages and limitations in reading and writing data. In terms of data reading, AWS S3 showed the highest speed, between 147 MB and 154 MB per second. The read speeds of Ceph and HDFS were slightly lower, ranging from 115 MB to 120 MB per second and 95 MB to 100 MB per second, respectively. Therefore, if quickly reading a large amount of data in a short period of time was needed, the AWS S3 storage scheme should be considered. In terms of data writing, AWS S3 showed the highest speed, between 120 MB and 128 MB per second. Therefore, if quickly writing a large amount of data was needed, using the AWS S3 storage scheme was essential.
Impact of different algorithms on computational time
Algorithm of this paper (s)
Algorithm of this paper (s)
Traditional algorithm (s)
Data read and write speeds under different storage schemes.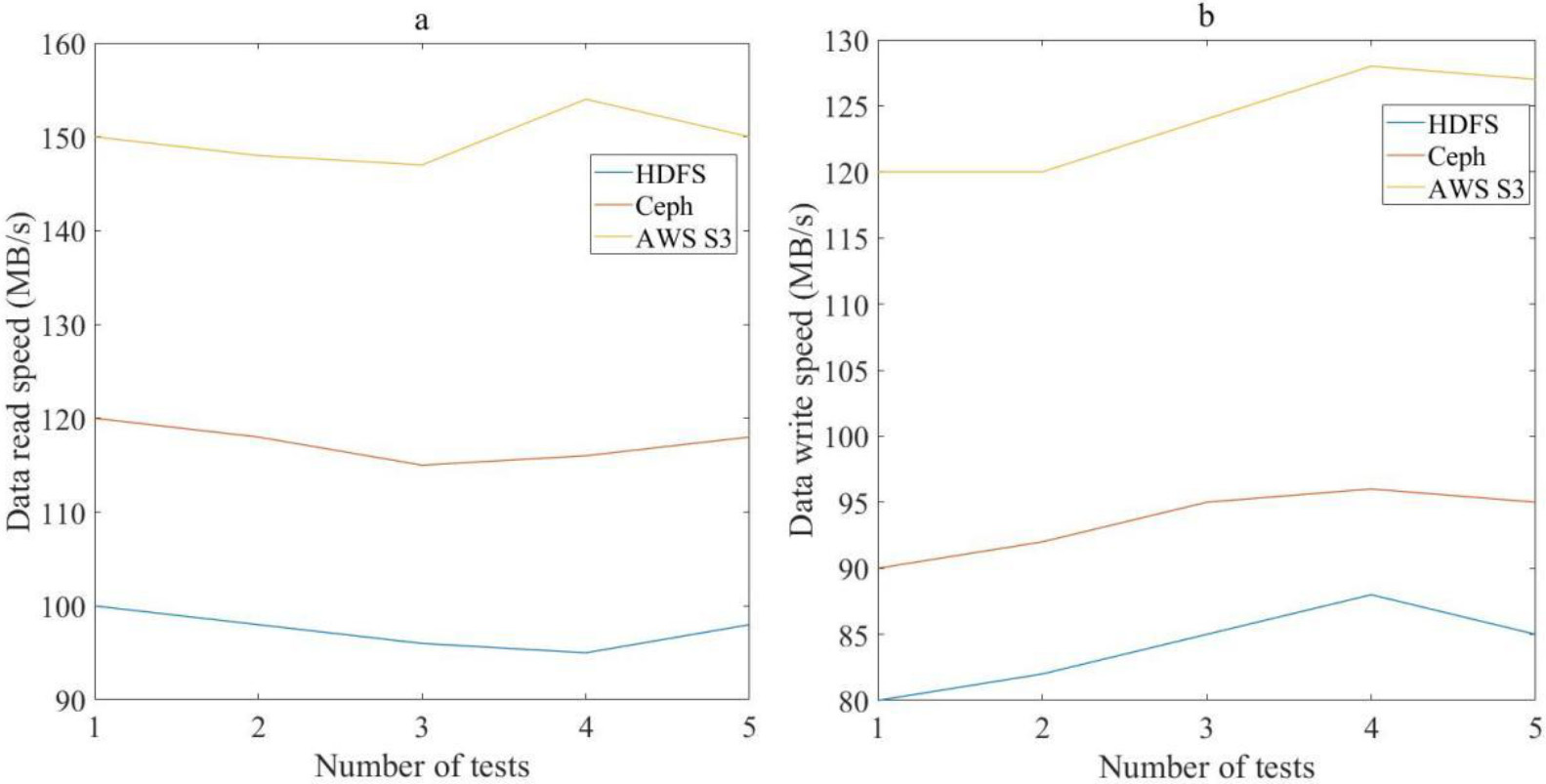
This article compared the impact of two different algorithms on computational time and the experimental results are shown in Table 1 and Table 2.
As shown in Table 1 and Table 2, the algorithm proposed in this paper has significantly improved computational time compared to traditional algorithms. After calculation, the average time for loading data in the algorithm in this article was 10.0 seconds; the average time for calculation was 919 seconds; the average time for saving results was 5 seconds. The average time for loading data in traditional algorithms was 21.6 seconds; the average time for calculation was 1831.6 seconds; the average time for saving results was 8.4 seconds. Therefore, the calculation time of the algorithm in this article was better than that of traditional algorithms. For some application scenarios that requires long-term computation and have large datasets, the algorithm proposed in this paper may better meet practical needs.
In this paper, the distributed computing and storage strategy for processing massive high-resolution image data is deeply studied. It is observed that the segmentation method based on image resolution has obvious advantages in processing speed and data quality compared with the segmentation method based on image size. This may be because image resolution segmentation can extract image features more effectively and reduce the influence of noise, thus improving data quality. Gaussian filter and K-means algorithm are used to denoise and segment the image, and satisfactory results are obtained. Different storage schemes also have a significant impact. AWS S3 storage scheme performs well in storage space utilization, response time and reading speed, which may be related to its high scalability and optimized architecture. However, comprehensive factors such as cost and data security should be considered when selecting storage schemes.
Conclusions
Through experimental analysis, the following conclusion can be drawn: For data processing time and data processing quality, the segmentation method based on image resolution was faster and produced higher data quality than the segmentation method based on image size. The method of random segmentation resulted in longer calculation time and relatively low data processing quality. In terms of storage space utilization, AWS S3 storage scheme had higher storage space utilization compared to Ceph and HDFS. In terms of data read and write speed, AWS S3 showed the highest speed in both data read and write. In terms of algorithm, this algorithm had a significant improvement in computational time compared to traditional algorithms. When processing massive high resolution image data, appropriate segmentation methods, storage schemes and algorithms should be selected to achieve higher quality and efficiency in data processing. In this paper, individual algorithms and storage schemes are tested from only one perspective, and the impact of other methods on processing massive amounts of high-resolution image data needs to be further explored.
Funding
This work was supported by Key Laboratory of Philosophy and social Science in Hainan Province of Hainan Free Trade Port International Shipping Development and Property Digitization, Hainan Vocational University of Science and Technology. This work was supported by Hainan Provincial Natural Science Foundation of China in 2021 under Grant No. 421RC609.
Data availability
No data were used to support this study.
Footnotes
Conflict of interest
The authors declare that they have no competing interests.