
Abstract
In this manuscript proposes an efficient big data security analysis on HDFS based on the combination of Improved Deep Fuzzy K-means Clustering (IDFKM) Algorithm and Modified 3D rotation data perturbation algorithm using health care database. To compile a similar group of data, an Improved Deep Fuzzy K-means Clustering (IDFKM) Algorithm is used as partitioning the medical data. After clustering, Modified 3D rotation data perturbation technique is used to satisfy the privacy requirement of the client. Modified 3D rotation Data Perturbation technique perturbs each and every sensitive data of the cluster and all the key parameters values used for clustering have warehoused in the database file sector. The proposed approach is executed by Java program, its efficiency is assessed by Health care database. The metrics under the study of memory usage attains higher accuracy 34.765%, 23.44%, 52.74%, 18.74%, lower execution time 35.23%, 23.76%, 27.86%, 27.76%, higher Efficiency 26.85%, 38.97%, 28.97%, 35.65%. then the proposed method is compared with the existing methods such asSecurity Analysis of SDN Applications for Big Data with spoofing identity, Tampering with data, Repudiation threats, Information disclosure, Denial of service and Elevation of privileges (STRIDE), Big Data Analysis-based Secure Cluster Management for using Ant Colony Optimization (ACA) Optimized Control Plane in Software-Defined Networks, System Architecture for Secure Authentication and Data Sharing in Cloud Enabled Big Data Environment using LemperlZivMarkow Algorithm (LZMA) and Density-based Clustering of Applications with Noise (DBSCAN), Big Data Based Security Analytics using data based security analytics (BDSA) approach for Protecting Virtualized Infrastructures in Cloud Computing respectively.
Keywords
Introduction
“Big Data” implies volume, velocity and type of data, which is complicated to examine the use of conventional typical data processing sites [1]. Now, the sources of data production are rapidly enhanced, viz streaming machines, maximal throughput instruments, sensor networks, telescopes, also creates huge amount of data [2]. Big data plays a significant part in variouscontexts, likeindustry, natural resource organization, healthcare, scientific research, business management, social network, public administration. Moreover, it is characterized by 10V’s Volume: Big data is implicated by big volume. In recent years, the sources of data production are maximized, which contributes to the data diversity, viz audio, video, text, large-scale imageries. Regular data processing methods need to be improved to process large amounts of data [3]. Velocity: The incoming data has been raised. The term velocity signifiesspeed of data production. The social media data explosion isvaried, also caused types of data. At present, people does not focused old post (tweet, status updates etc.), but noticing the latesthot updates [4]. Variety: raised the collection of data types. For eg, certain organizations utilize the given kind of data formats: database, excel, CSV, which is saved in plain text file. Notwithstanding, the data may not be in the expected format and it may cause difficulties in processing. To deal this problem, the organization needs to identify a data storage scheme that can examine various data [5]. Value: It does not be useful to have continual data until it is converted as value. It is important to understand that Big Data does not always mean value [6].
Visualization is a noteworthy key to create big data an integral portion of decision making. Big Data impact in healthcare. Currently, the system of health care is quickly adopting medical data that enlarge the health records size are accessed electronically [7, 8]. A recent study illustrates six utility cases of big data to lessen the patient cost, triage, readmissions. In other studies, big data utilization cases in healthcare is separated as count of categories, viz medical decision support, administration with delivery, user behavior, maintains services.
•
To process the data, the existing method contains Hadoop map reduce structure. The map-reduce structure consumes more time to process the datadue to the rapid improvement of data [9]. The Hadoop Distributed File System (HDFS) utilizes map reduce to analyze the data. After every operation, it takes a backup of all data in a physical server [10]. This is executed because the data is stored on RAM is volatile likened to the data stored on the physical server. This reduces the scalability of the system and takes more time to share and secure data in the Hadoop file, which reduces the accuracy of system and the privacy of the user.
•
To overcome the above issues this work is motivated. This method will secure the privacy of the user by securely share the medical health care records in the Hadoop system using clustering and data perturbation method with less computation time and reduces the complexity of privacy protection with better accuracy.
•
The novelty of the proposed Improved Deep Fuzzy K-means Clustering (IDFKM) Algorithm and Modified 3D rotation data perturbation algorithm is used to store and secure the HDFS from big dataset.
This manuscript proposes an efficient big data security analysis on HDFS based on combination of Improved Deep Fuzzy K-means Clustering (IDFKM) Algorithm [11–13] algorithm and modified 3D rotation data perturbation algorithm [14–16] using health care database. To compile a similar group of data, an Improved Deep Fuzzy K-means Clustering (IDFKM) Algorithm is used based on its similarity among various clustering methods and the Partition algorithm finds the clusters altogether as an initial partition of data. After clustering, Modified 3D rotation data perturbation technique is used to satisfy the privacy requirement of the client. Modified 3D rotation Data Perturbation technique perturbs each and every sensitive data of the cluster and all key parameters values used for clustering have warehoused in the database file sector.
• This manuscript proposes an efficient big data security analysis on HDFS depending on the combination of Improved Deep Fuzzy K-means Clustering (IDFKM) and Modified Three dimensional rotation transformation (M3DRT) algorithm using health care database. To compile a similar group of data, a clustering algorithm is used based on its similarity among the various clustering methods and Partition algorithm finds the clusters altogether as an initial partition of data [17–19]. After clustering, by Modified Three dimensional rotation transformation (M3DRT) algorithm technique, to satisfy the privacy requirement of the client. Modified Three dimensional rotation transformation (M3DRT) algorithm technique perturbs each and every sensitive data of the cluster and all the key parameters values used for clustering have warehoused in the database file sector. The proposed approach is executed with the help of Java program, its efficiency is assessed by Health care database. The metrics under the study of memory usage attains precision, recall, accuracy, F-measure, aggregating time, efficiency, execution time. The proposed method is compared with existing methods such as STRIDE [20], SDN-ACA [21], LZMA- DBSCAN [23] and BDSA [25] for securing and storing the data in efficient manner.
The remaining section of this manuscript is designed as follows. Section 2 delineates the related work. Section 3 describes about the proposed data privacy method. Section 4 demonstrates the experimental outcomes with discussion. Finally, section 5 concludes the manuscript.
Related works
Several investigation works were already presented in the literature depending on big data security using clustering methods.Certain works are reviewed here,
Ahmad et al., [20] have presented the analysis of security features with STRIDE threat modeling technique. Software Defined Networking (SDN) maximizes the Hadoop presentation by enhancing the usage of bandwidth along network management. Safety attacks in the controller of SDN with switches can co-operate the entire Hadoop system causing loss or manipulation of valuable data. The3 advanced methods are selected, which consider accelerating the data transmit amid the cluster nodes. The aim wasexamine the safety features of SDN utilizations. Every methods requiredenhancementfor gain secure. While other methods were protected by the use of additional security measures, Pythia find the most secure model. Here using the evaluation metrics are Accuracy, Recall, F-measure. The advantages of this model was less expensive, to improve the robustness of its security infrastructure and the limitation was reduces scalability.
Wu et al., [21] have presented Big Data Analysis-based Secure Cluster Management for Optimized Control Plane in Software-Defined Networks. A secure authorization mode was presented for cluster management. Also,the ant colony optimization approach was presented that performs big data analysis withactivation scheme that enhances the control plane. Simulations prove thesuperiority of presentedmethod. The presented method wasenhancing the security. Here using the evaluation metrics are energy consumption, delay, traffic rate. This approach was used to improve the security and efficiency SDN control plane and the limitation was restrained processing power, long control latency, lesser control plane reliability.
Shamsi and Khojaye [22] have introduced a protection in the context of big data, systems, estimating the strengths and weaknesses of its protection strategies. Here, the data-anonymization technique was used. Big data processes were involved to solve computational issues for business intelligence with forecast testing.The advantage of this method was to protect confidential information in big data systems. The disadvantage was lack of computational complexity. The performance metrics was Accuracy, Sensitivity and Specificity.
Narayanan et al., [23] have suggested a big picture of dealing the major complexity of Big data security over Cloud. Where, the new system architecture named Secure Authentication including Data Sharing in Cloud (SADS-Cloud) enabled Big Data Environment. The suggested method involves 3 models (i). Big Data Outsourcing, (ii). Big Data Sharing (iii). Big Data Management. At 1st model, data owners were recorded to Trusted Center utilizing SHA-3 Hashing approach. At 2nd models, data users contribute the secured file recovery. At 3rd model, 3 processes were activated for organizing Big data as follows: Compression, Clustering, Indexing utilizing LemperlZivMarkow approach (LZMA), Density-based Clustering of Applications with Noise (DBSCAN), Fractal Index Tree was utilized to index the files at Cloud database. The suggested method was tested for the given metrics: Information Loss, compression ratio, throughput, encryption with decryption time, information loss, compression ratio, and efficiency. The advantages of this approach were in secure file retrieval and reduce the total energy consumption. The drawback of this approach was data loss.
Bin [24] have presented the “Internet of Things” and “Big Data” turned into a field of firmly related innovation use. The step by step process of adequately discover significant model connections big data at Internet of Things was helpful for directors settling on right choices on the organization’s future advancement patterns. Conventional K-means calculation streamlined create its appropriate requirements of Big Data RFID Internet of Things information. The K-means examination was executed in light of the Hadoop cloud clustering stage. The advantage of this method was improved clustering efficiency and the disadvantage of this method was long control latency and low control plane reliability.
Win et al., [25] have presented a big data based security analytics (BDSA) for identifying thesuperior attacks in virtualized infrastructures. From the guest virtual machines, network logs together with user application logs were saved in HDFS. Extraction of attack properties was enabled with the help of graph-based event correlation along Map Reduce parser depend potential attack paths recognizing. The purpose of attack was acts via 2 stage machine learning called logistic regression for computing conditional probabilities of attack depends on attributes, also belief propagation was employed to scale the belief in existence of attack depending on them. The tests were carried out to assess the presented method through feasible malware and compare with other methods for virtualized infrastructure. The outcomes demonstrate that the presented method was effective to detect attacks with minimal performance overhead. The detection time was the main performance metric in this approach. The main advantages of this model were detecting both botnets and VM malware drawback was occasional latency increase owing to SSH server reset through guest VMs.
Xiong et al., [26] have introduced an online system for active semi-supervised spectral clustering, which choose pair-wise constraints as clustering proceeds depending upon the uncertainty lessening policy. By first-order Taylor expansion, the anticipated uncertainty lessening issue was decayed as gradient including step-scale, determined through utilization of matrix perturbation theory including cluster-assignment entropy. Here, human client pair wise queries were presented only the better candidate sample. Moreover, three distinctive pictures of datasets, lot of regular UCI AI datasets and quality dataset were considered. The advantage of this method was minimizing the uncertainty of the clustering problem and the disadvantage of this method was high computational complexity and limited scalability.
Wang and Singh [27] have suggested the theoretical characteristics of general subspace clustering algorithm called sparse subspace clustering (SSC). The suggested model considered the common fully deterministic mode, where basic subspaces and data points within every subspace were deterministically situated the broad range of dimensionality lessening systems that drop in subspace installing structure. The different private SSC approach was used and set up both security and utility assures the suggested strategy. The advantage of this approach was efficient computation and compressed measurement. The limitation of this approach was strong convexity of dual problem. Here, the performance metrics were Accuracy, Sensitivity and Specificity.
Table 1 shows the Comparison for existing methods. Here the existing methods are compared with the Author Name/Year, Method, Advantages, Disadvantages, and Performance Metrics.
Comparison for existing methods
Comparison for existing methods
Secured information transmission by the proposed approach
Figure 1 portrays the proposed framework. The medicinal services and enormous informational index in the HDFS framework is represented in Fig. 2. The Hadoop Distributed File System (HDFS) denotes crucial information framework of stockpiling employed to many applications. Blocking a lot of information in the business to actualize an appropriated record framework, it provides elite access with information transverse throughout intensely adaptable clusters Hadoops.

Block diagram for HDFS big data system.
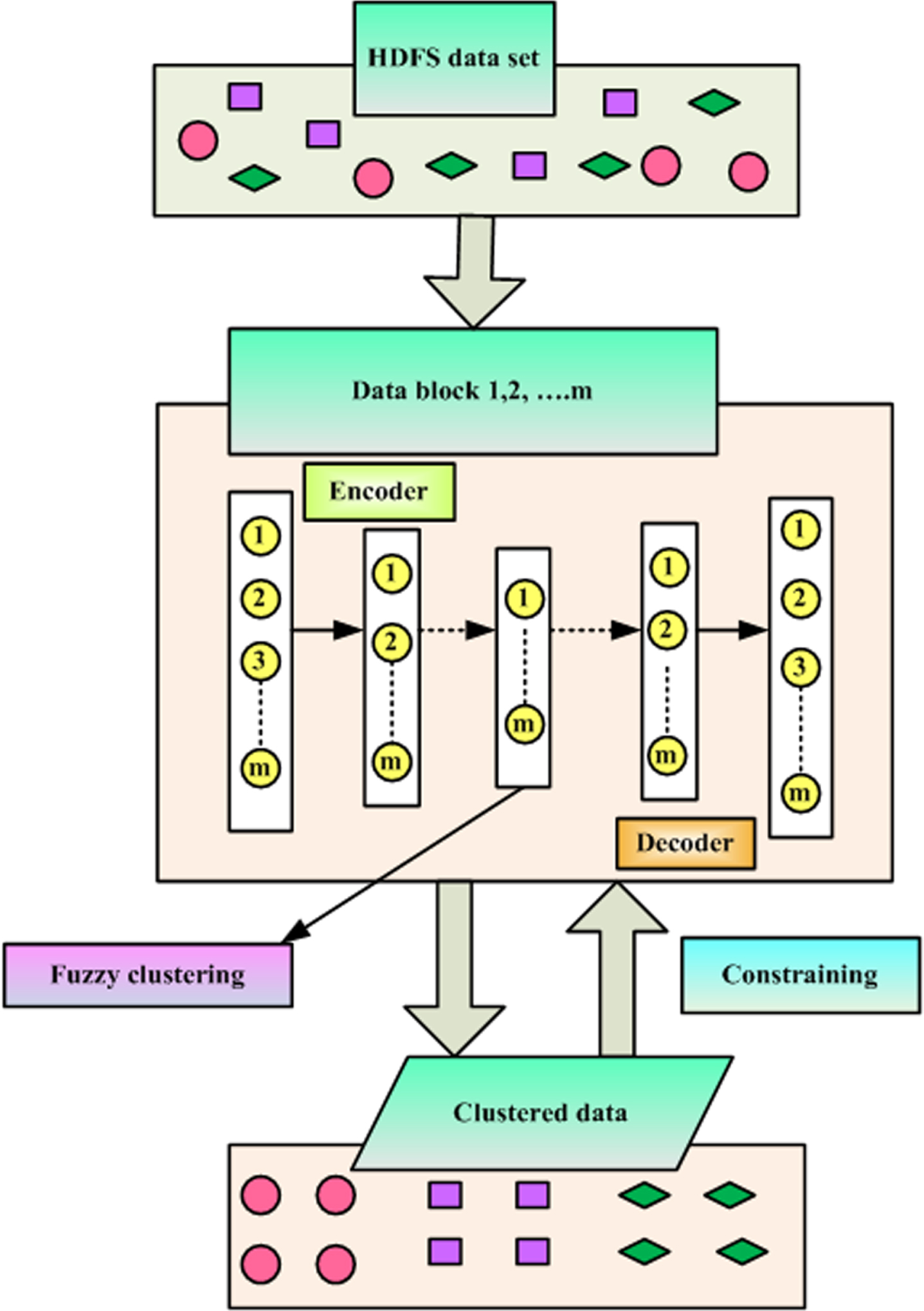
HDFS design with IDFKM.
In HDFS big data system, split at peripheral aggregates and distributes them different blocks of cluster, due to this enormously permitted expert by parallel organization. Here, the time aggregation method is established by advanced clustering algorithm IDFKM applicable with subdivided blocks. The HDFS is distributed similar in fashion. The single name of the node takes a way in the data is stored in the servers of the cluster known as Data Nodes. The data is placed in data blocks of data nodes is stored in the files of HDFS. These files are separated as one or more segments and then stored in the single data nodes. These segmented files are called blocks. The block is defined as the little amount of data in HDFS that can be read/write. The size of the default block is 64 MB, it is increased as per the need to change the configuration of HDFS.
The privacy of the grouped information has been achieved through M3DRT is employed for clustered information, and creates complexity to be perceived by unauthorized clients. The perturbed information is warehoused in the perturbed database. Here, each datum contains a tremendous proportion of data, along these lines, the calculation and the correspondence overhead has occurred. The database contains diverse sensitive scraps of information. It joins emergency information, drugs, immunization, hypersensitivities and other prosperity information. At any time an approved client/service provider sends a request for the data about a particular patient, while the social insurance application requests the perturbed database for the specific subtleties
Therefore, the high dimensional dataset is isolated into numerous gatherings depending on its identicalness by using the grouping system. The application can get the recovered data from the database gives the expected data to the client. The proposed framework is exceptionally intended to be remarkably deficiency tolerant. The database recreates or duplicates as every bit information of numerous methods as well as conveys duplicates with single data, setting as not less than unique duplicate at alternative server rack to another. Therefore, information about DB is blocked to get elsewhere within a cluster. It guarantees organization can continue though information is recovered. The Partitioned K-means clustering count provides the ideal result over other existing strategies.
In this Improved Deep Fuzzy K-Means clustering is used to tackle the problems of the deep learning. several neural network based clustering algorithms have been developed to tackle the data with more complex structures. Auto-encoder is a symmetric neural network that reconstructs data points via multiple layers. Stacked autoencoder (SAE) and structured auto-encoder (StructAE) incorporate graph-based clustering to achieve clear deep representations. However, both of them perform deep feature extraction and clustering in separate phases with high dependence on pre-trained similarity matrix. Accordingly, they become laborious as graph-based clustering models on big datasets. Deep embedding clustering (DEC) is a well-known deep model which performs clustering and network training simultaneously. However, it performs clustering through SGD which results in slow convergence. Here, the Fuzzy clustering algorithm is broadly employed to practical applications. Improved deep K-Means fuzzy variations are the big proportion of common approach for FCM. Figure 2 shows the HDFS Design with IDFKMClustering, which is deployedto train the Neural Network,hence the auto-encoder will map the data to extract the deep feature space. Besides, IDFKMperforms deep features extraction as well as clustering simultaneously. (1) The Adaptive loss functions has beenemployed to upgrade the insensitivity of proposed method for outliers and adaptive weights. A proficientapproach is generated and guaranteesto incorporate a local minimum for dealing the issue. (2) encoder (3) decoder. Then the proposed model does not require anything like graph-based information and the affinity with the centroid matrix is updated via closer format solution than the SGD. Hence, it worksproficiently in big data. The primary goal of an algorithm is grouping data’s correspondence based on its aspects, and then it can be aggregated. The improved k-means original variation is given in Equation (1):
All of uppercase italic boldface letters represent matrices, lowercase italic boldface letters represent vectors.
The uppercase curlicue letters signifies functions, italic letters signifies scalar values. N t indicates transpose of N . n i indicates i th row of matrix N, n j specifies j th column of N, n ij implies entry of i th row with j th column of N. |N| implicates the absolute value of matrix N, ∥N ∥ f as Frobenius norm of N . 1 = [1, 1, . . . . . , 1] t ∈ ℑ d×M, the l2,1-norm is defined as the Equation (1), ℑ is represented as the data batch.
These proposed algorithms are used in the fuzzification layer with the purpose of big data security.
Several auto-encoder variations are deemed to acquire optimum deep representation of raw data. For eg., stacked auto-encoder (SAE) utilizes the data points likeness as the auto-encoder input, also trained them layer-wise. After training, few clustering model, viz K-Means is carried out to get the final partition. Notwithstanding, the proficiency of SAE isdepending upon the similarity matrix. To tackle the problem of securing and storing the medical data in Hadoop file are used in IDFKM algorithm. Then the loss functions are explained in below steps 1. Adaptive Loss function, 2. Cost Function of IDFKM. The Fuzzy c means algorithm with the clustering function is given as the entropy regularization.
a) Adaptive loss functions δ -norm for finding the problem in securing the big data in Hadoop
In terms of metrics, the l2- norm is sensitive to huge data outliers along strength to the smaller loss, when l1-norm is sensitive to the smaller loss along strength to the huge one.This is strong for outliers in spite of smaller or larger losses to create the robust loss. The δ- norm is expressed in Equation (2)
The robust loss function containsgivenfeatures: ∥N ∥
δ
signifies non negative with convex that is appropriateto loss function ∥N ∥
δ
has double differentiate, also simply to optimization When When ∥n
i
∥ 2 >> δ, ∥ N ∥
δ
→ (1 + δ) ∥ N ∥ 2,1 When δ → 0, ∥ N ∥
δ
→ ∥ N ∥ 2,1 When
At sum, adaptive loss operation interpolates amid the l1- and l2-norm through modifying δ parameter. For solving problem (1), a common robust loss function is suggested as the Equation (3)
IDFKM uses a neural network that contains (N + 1) layers to map raw data for non-linear feature space, here N represents even number. First
From Fig. 2, suppose G(0) = X in = [x1, x2, . . . . x N ] ∈ ℑ D×N implicates input matrix of 1st layer along N samples, then every data point g(0) implicates column of the matrix G(0) including dimension D. Then the output of encoder is given in Equation (4):
where,
In case G(0) = A ∈ ℑ f×M as the input of the network, and the other
E(n) and y(n) denotes weight matrix, bias of associated layer respectively. In this the objective of the DFKM algorithm is to reduce the data dimensionality error.
So, IDFKM method is proposed utilizing the objective function of improved fuzzy k-means, RLFwith auto-encoder for securing the big data in Hadoop for minimizing the loss function of IDFKM is expressed in Equations (6)–(9).
Data perturbation (DP) is a common data mining strategy for privacy protective. The complexity of DP is how to balance the 2 conflict aspects:(i) privacy secure (ii) data utility. In this mode, the attributes have been separated as 3 groups, and every group of attributes rotates around various axes pair. Here, the rotation angle is chosen, because variance based privacy metric attains higher that creates difficult to reconstruct the original data. The equation of the M3d rotation and data Perturbation for securing medical data along the pair is given in Equations (10)–(12)
Equations 10–12 shows the M3D rotation matrix along pairs between the points remains almost equal.The normalization moderate utilized in Min M ax strategy. Then the meaning of this sentence is Data set is regularized utilizing Min M ax and converting the attribute values as [0, 5] range. Everyacquired triplet has been rotatearound a pair of axis (AB, BZ, XZ) with the aim of increasing the amount of perturbation to elements without affect the spatial distance. The related rotation matrix is computed to every rotation. To various values of Φ, determine the rotated triplet V′ = V × R q as well as a graph is plottedamid the angle H and difference variation. It provides the range for Φ such that minimal secure threshold need for every attribute is fulfilled by Φ. The variance vs angle graphs for 3triplets rotate with XZ axis and the changes are added in Section 3.1.2 in the revised manuscript and the changes are highlighted in blue color. For the rotation process to secure the medical data, it consists of the 4 steps. Figure 3 shows the flow chart for Modified 3D rotation transformation (M3DRT) approach for securing medical data in Hadoop.The step by step procedure is given below,
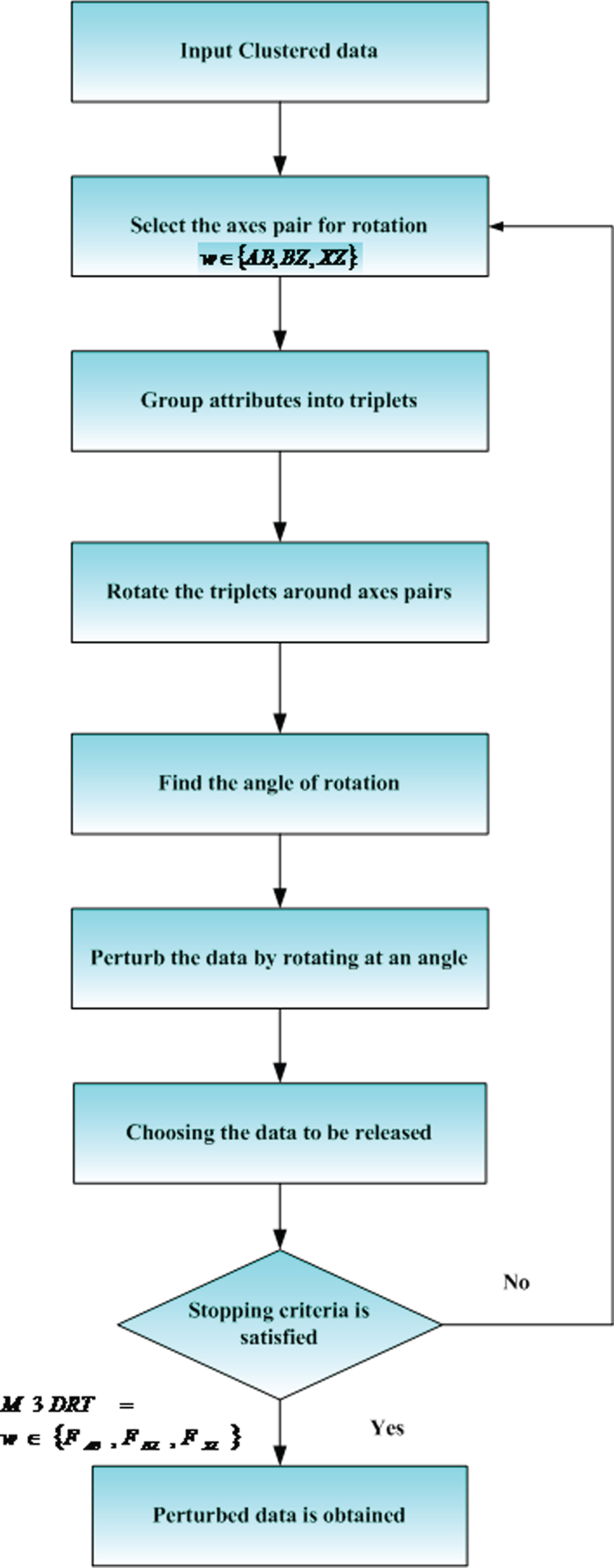
Flow chart for M3DRT.
Select the axis pair w∈ { AB, BZ, XZ } then determines the rotation matrix for w. The medical data pair equation is given in Equation (13),
Then the modified three dimensional Rotation Transformation is given as (F, Φ, V), where L is the number of attributes, Φ is represented as the array of security threshold angle, F is represented as the Normalized data matrix.
Group the attributes into L triplets (X a , X b , X c ). Here a ≠ b ≠ c the triplets have been complied serially. After compiling, if remains one attributes, the final attribute on the left is compiled with prior 2 attributes. Whereas, if remains 2 attributes, the final 2 attributes consolidated to the prior attribute. In this way, the medical data is grouped and secured in the Hadoop file.
Here the number of triplets is given as k← ⌈ L/ - 3 ⌉ with every axes pair w∈ { AB, BZ, XZ } and its range is from φ w .
To different rotation angles, rotating the triplets surrounding axes pairs w at 3D plane. To acquire the perturbed dataset f w , M3-D Rotation is activated on every triplet C and specified axes pairs w, C′ and C is represented as the variance of the triplets and its equation is given in Equation (14):
The value of rotated datasets implies φ function that represents rotation matrix T w about w - th axis pair. This step is used to determine the angle of the rotation to avoid the risk for securing the data in Hadoop.
Rotated dataset consists of given steps:
Determine the rotating triplet on angle Φ found in step 4. Then the security range is computed as φ L (Range), such that variance (X a - X′ a ) ⩾ δL1, variance (X b - X′ b ) ⩾ δL2, and variance (X w - X′ w ) ⩾ δL3, Where δL3 ∈ Φ L , then the range φ L (Range) is given as φw? (Range) ← φ w (Range) ∩ φ L (Range), β w is the rotation angle such that β w ∈ φ w . Then the medical data secured equation is given in Equation (16):
To every perturbed data sets F, w∈ { F AB , F BZ , F XZ } measure the variance. The data F w along greatest value of variance is deemed into final perturbed data F′. Then the final secured data is stored in the Hadoop file and the secured medical data equation is given in Equation (17):
Let F denotes number of medical data and L denotes number of attributes. The processing time of M3DRT approach is C (F × L).
Process of retrieving the data
Figure 3 shows the Flow chart for M3DRT. Data recovery is one of the difficult errands in the data innovation field.. From Fig. 3 the clustered data is given to the M3DRT, then the rotations are selected based on the Data perturbation (DP) process. Then the axes pairs are selected based w∈ { AB, BZ, XZ } then determines the rotation matrix for w. Then the axes pairs rotated based on the Group the attributes into L triplets (X a , X b , X c ). Here a ≠ b ≠ c the triplets have been complied serially, then finds the angle, then perturb the data by rotating at an angle and then finally choose the data released. The detailed descriptions of flow chart is given in step by step procedures explained in Section 3.1.2.
In the hash map [28] the clustered original information can be extricated from all the perturbed qualities. Before creating the report of client, the framework checks the entrance control table concerning whether the client approaches the characteristics of their inquiries. Clients can get unique information only for the attributes, generally, just perturbed information is shown up in the report, which is presented in Fig. 4. The Healthcare information proprietor needs to offer authorization for getting the information of every single potential client depending on their prerequisites. Such clients incorporate different medicinal services experts just as various therapeutic insurance agencies or associations. Here, the trait based access control is portrayed. At first, the framework necessitates the portion of the client’s traits get before the social insurance information. The framework assigns rights to that customer based on those properties. On the off chance that client’s ascribes neglects to coordinate predefined values, the client will be denied access to the information. In the meantime, the framework gives consent to such an extent that approved clients can get just certain pieces of the social insurance information: they can’t get to other information zones in the database. To access the database, authorized clients receive a final report, which contains unique information about the attributes they hold. The authorized clients acquire just perturbed information for every single other feature.
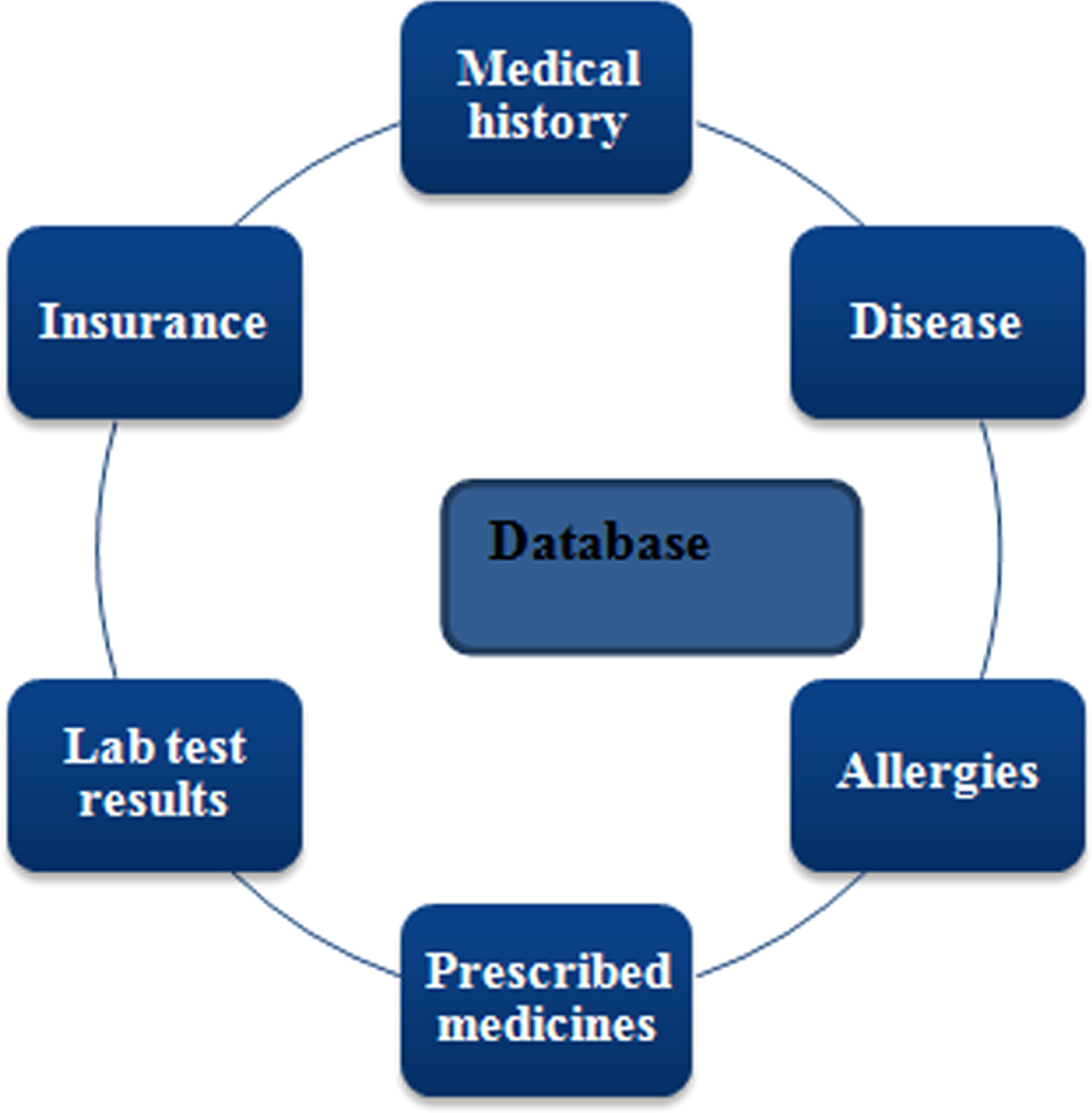
Health care database.
Here, the proposed privacy protection is described and the implementation criterion is used to analyze the algorithm. This method is analyzed by memory usage, accuracy, recall, precision, F-measure, clustering time and time of execution. The JAVA simulations run in PC with Intel Core, 2.50 GHz CPU, 8 GB of RAM, and Hadoop 64Bit 64Bit on Ubuntu 14 64 Bit. Here, HDFSbased on Combined IDFKM-M3DRT technique for privacy preservation is implemented. Table 1 shows an example of health insurance database in hadoop.
Performance and analysis
The big data security interpretation based on Improved Deep Fuzzy K-means Clustering (IDFKM) Algorithm with Modified Three dimensional rotation transformation (M3DRT) algorithm in Hadoop Distributed File System (HDFS) collected from medical data set for increasing the storing capacity in the process.
Dataset description
Here, the health data is collected from Big Geno-mics Data(BGD) (https://cran.rproject.org/web/packages/BGData/readme/README.html). The user-specific analysis is permitted by dynamic data visualizations, also gain newly experiences, then thedata is generally access via Global Health Data Exchange. This method provides private healthcare big data in Hadoop Distributed File System (HDFS) and is controlled by only by valid user. This method securely keeps the healthcare big data in block chain for attaining accountability, integrity, security. Patients may achieve entire control over the blocks, here their data is saved by using crypto graphic functions. This method achieves following advantages while using HDFS such as low cost, because this software is a open source and stores large amount of data, provides more scalability by adding more number of nodes, so the system grows quickly through less system administrations, This system is highly portable among the Hadoop distributions, that facilitate for reducing vendor specific locking constraints, it has high storage flexibility and stores Unstructured data such as text, images and videos directly into the system, Inherent data protection, self-healing capabilities, the system works on the basis of, when a node does not take action, then the task is redirected to other virtual nodes to ensure the delivered computing is not fail. It signifies hardware independence that is Data with application processing is secured against hardware fault.
The primary focus of M3DRT is to provide security before conveying the data. In the proposed method, the healthcare database contains various types of information about the patient. Figure 4 depicts the healthcare database. Here, Medical history, insurance details, diseases, allergies, medicines, lab tests and lab resultsare considered. With the M3DRT calculation, the alternative required perturbed data is provided. It is additionally conceivable to pick any number of segments for the annoyance procedure. Annoyance procedure can be used for security and sparing can be used for data stream mining.
Table 2 shows the Health insurance details in database. The M3DRT strategy with the extension of Gaussian noise is completely splitting for assessing exceptional motivating force from the perturbed data. The M3DRT is an improvement to turn annoyance by joining additional parts, for example, irregular interpretation perturbation and noise expansion development to the fundamental sort of multiplicative perturbation. The major aim is to change given enlightening accumulation of data into perturbed dataset that satisfies given security essential with least information loss for the proposed data examination task.
Health insurance details in database
Health insurance details in database
Precision, Recall, F-Measure, Accuracy, Specificity are utilized for measuring the performance metrics.
Precision
It is defined as the Positive predictive values; it is expressed in Equation (18).
F-measure
It determines utilizing the given Equation (19)
Accuracy
The accuracy contains the total number of the classification results. The values are determined by the following Equation (21)
Clustering period
Clustering Time is an unsupervised data mining technique for organizing data points into groups based on their similarity.
Security level
Security level is a measure of the strength that a cryptographic primitive.
Efficiency
Efficiency is the ratio of output power to input power, and multiply the result by 100. The values are determined by the following Equation (22)
Here, the performance analysis of proposed IDFKM-M3DRT method is compared with the existing methods such as STRIDE [20], SDN-ACA [21], LZMA- DBSCAN [23] and BDSA [25] for securing and storing the data in efficient manner.
Table 3 shows the security level, attack level and efficiency of the proposed IDFKM-M3DRT and existing methods STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA respectively. The existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 87.4%, 89.6%, 85.2% and 91.6% low security level. But the proposed IDFKM-M3DRT method achieved 97.5% high security level. The existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 10.7%, 12.6%, 15.4% and 11.5% high attack level. But the proposed IDFKM-M3DRT method achieved 5.4% low attack level. The existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 85.2%, 87.6%, 58.1% and 89.2% low efficiency. But the proposed IDFKM-M3DRT method achieved 96.8% high efficiency.
Security level, attack level and efficiency of proposed IDFKM-M3DRT and existing methods
Security level, attack level and efficiency of proposed IDFKM-M3DRT and existing methods
Figure 5 shows the time taken to perturb health data of proposed IDFKM-M3DRT and existing methods STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA respectively. At file size 10 mb the existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 4856, 3546, 3659 and 4385 low time taken to perturb health data. But the proposed IDFKM-M3DRT method achieved 5115 high time taken to perturb health data. At file size 20 mb the existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 6434, 7622, 6451 and 6878 low time taken to perturb health data. But the proposed IDFKM-M3DRT method achieved 6545 high time taken to perturb health data. At file size 30 mb the existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 12475, 14363, 11734 and 17563 low time taken to perturb health data. The proposed IDFKM-M3DRT method achieved 11445 high time taken to perturb health data. At file size 40 mb the existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 18364, 20463, 18465 and 19464 low time taken to perturb health data. The proposed IDFKM-M3DRT method achieves 15855 high time taken to perturb health data. At file size 50 mb the existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 25373, 25385, 24365 and 21047 low time taken to perturb health data. The proposed IDFKM-M3DRT method achieved 22456 high time taken to perturb health data.
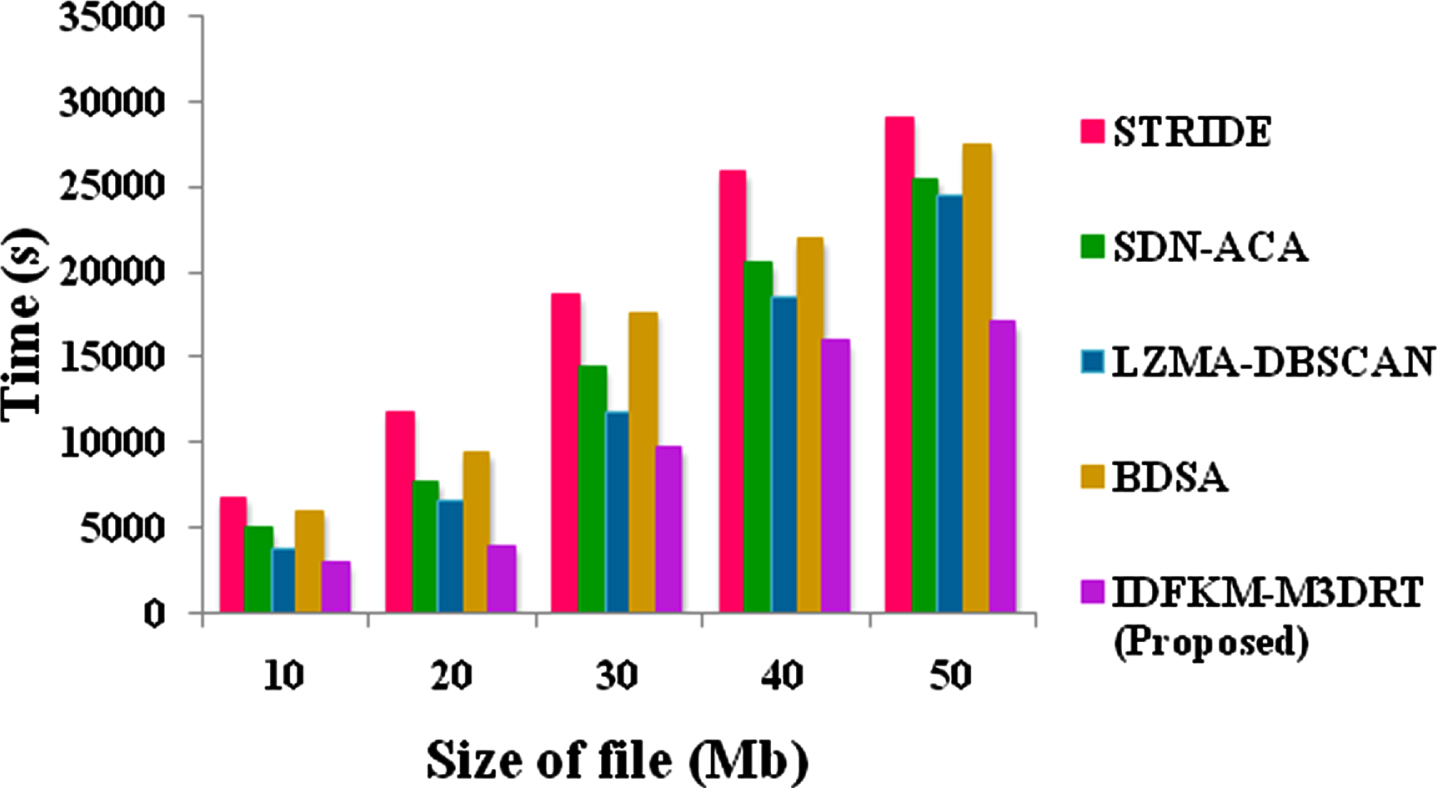
Time taken to perturb health data proposed IDFKM-M3DRT and existing methods.
Table 4 shows the Time taken to de-perturb health data of proposed IDFKM-M3DRT and existing methods STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA respectively. At file size 10 mb the existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 5823, 4895, 5934 and 3745 high time taken to de-perturb health data. But the proposed IDFKM-M3DRT method achieved 5333 low time taken to de-perturb health data. At file size 20 mb the existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 7453, 7742, 7324 and 7259 high time taken to de-perturb health data. But the proposed IDFKM-M3DRT method achieved 7124 low time taken to de-perturb health data. At file size 30 mb the existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 11484, 13985, 12846 and 11757 high time taken to de-perturb health data. The proposed IDFKM-M3DRT method achieved 10177 low time taken to de-perturb health data. At file size 40 mb the existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 18567, 17485, 15485 and 18467 high time taken to de-perturb health data. The proposed IDFKM-M3DRT method achieves 17661 low time taken to de-perturb health data. At file size 50 mb the existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 21983, 19465, 18455 and 23893 high time taken to de-perturb health data. The proposed IDFKM-M3DRT method achieved 17340 low time taken to de-perturb health data.
Time taken to de-perturb health data proposed IDFKM-3DRT and existing methods
Table 5 shows the Memory usage on perturb health data of proposed IDFKM-M3DRT and existing methods STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA respectively. At file size 10 mb the existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 4835266, 5978776, 6230968 and 6650936 high Memory usages on perturb health data. But the proposed IDFKM-M3DRT method achieved 4707464 low Memory usages on perturb health data. At file size 20 mb the existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 5869371, 4987883, 4956458 and 5245575 high Memory usages on perturb health data. But the proposed IDFKM-M3DRT method achieved 4904680 low Memory usages on perturb health data. At file size 30 mb the existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 6328583, 5868947, 5284758 and 5757853 high Memory usages on perturb health data. The proposed IDFKM-M3DRT method achieved 4835266low Memory usages on perturb health data. At file size 40 mb the existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 6947372, 6274685, 5968343 and 5969839 high Memory usages on perturb health data. The proposed IDFKM-M3DRT method achieves 4747584low Memory usages on perturbs health data. At file size 50 mb the existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 7253634, 6936746, 6395786 and 6763837 high Memory usages on perturb health data. The proposed IDFKM-M3DRT method achieved 4845857 low Memory usages on perturbs health data.
Memory usage on perturb health data
Table 6 shows the Memory usage on de-perturb health data of proposed IDFKM-M3DRT and existing methods STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA respectively. At file size 10 mb the existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 4866748, 4684724, 5284739 and 5837517 high Memory usage on de-perturb health data. But the proposed IDFKM-M3DRT method achieved 4644388 low Memory usage on de-perturb health data. At file size 20 mb the existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 5285475, 4938272, 573393 and 5856207 high Memory usage on de-perturb health data. But the proposed IDFKM-M3DRT method achieved 4267659 low Memory usage on de-perturb health data. At file size 30 mb the existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 5846387, 5538227, 5943684 and 6382722 high Memory usages on de-perturb health data. The proposed IDFKM-M3DRT method achieved 4267659 low Memory usages on de-perturb health data. At file size 40 mb the existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 6385883, 6184739, 6737825 and 6947286 high Memory usage on de-perturb health data. The proposed IDFKM-M3DRT method achieves 3457079 low Memory usage on de-perturb health data. At file size 50 mb the existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 7838627, 7943783, 7235636 and 7462629 high Memory usage on de-perturb health data. The proposed IDFKM-M3DRT method achieved 7150936 low Memory usage on de-perturb health data.
Memory usage on de-perturb health data
Table 7 shows the Precision of proposed IDFKM-M3DRT and existing methods STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA respectively. At file size 10 mb the existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 77.58%, 82.45%, 78.46% and 84.76% low Precision. But the proposed IDFKM-M3DRT method achieved 90.45% high Precision. At file size 20 mb the existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 83.56%, 86.46%, 81.03% and 86.79% low Precision. But the proposed IDFKM-M3DRT method achieved 92.66% high Precision. At file size 30 mb the existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 82.45%, 89.57%, 75.83% and 88.56% low Precision. The proposed IDFKM-M3DRT method achieved 93.43% high Precision. At file size 40 mb the existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 86.45%, 90.02%, 79.58% and 87.56% low Precision. The proposed IDFKM-M3DRT method achieves 95.34% high Precision. At file size 50 mb the existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 91.46%, 93.85%, 87.68% and 90.17% low Precision. The proposed IDFKM-M3DRT method achieved 96.45% high Precision.
Performance of precision
Table 8 shows the confusion matrix of proposed IDFKM-M3DRT and existing methods STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA respectively.
Confusion matrix
Table 9 shows the recall of proposed IDFKM-M3DRT and existing methods STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA respectively. At file size 10 mb the existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 85.25%, 78.98%, 66.92% and 71.92% low recall. But the proposed IDFKM-M3DRT method achieved 93.11% high recall. At file size 20 mb the existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 87.46%, 82.58%, 69.20% and 75.28% low recall. But the proposed IDFKM-M3DRT method achieved 94.35% high recall. At file size 30 mb the existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 89.26%, 86.37%, 73.95% and 78.23% low recall. The proposed IDFKM-M3DRT method achieved 95.23% high recall. At file size 40 mb the existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 91.89%, 89.10%, 77.39% and 85.28% low recall. The proposed IDFKM-M3DRT method achieves 96.83% high recall. At file size 50 mb the existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 92.16%, 91.02%, 83.25% and 89.25% low recall. The proposed IDFKM-M3DRT method achieved 97.83% high recall.
Performance of recall
Table 10 shows the F-measure of proposed IDFKM-M3DRT and existing methods STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA respectively. At file size 10 mb the existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 84.57%, 72.94%, 82.48% and 79.37% low F-measure. But the proposed IDFKM-M3DRT method achieved 92.04% high F-measure. At file size 20 mb the existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 86.48%, 75.73%, 85.47% and 81.37% low F-measure. But the proposed IDFKM-M3DRT method achieved 93.14% high F-measure. At file size 30 mb the existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 88.94%, 78.13%, 87.03% and 84.28% low F-measure. The proposed IDFKM-M3DRT method achieved 93.88% high F-measure. At file size 40 mb the existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 90.81%, 82.36%, 91.37% and 86.37% low F-measure. The proposed IDFKM-M3DRT method achieves 95.14% high F-measure. At file size 50 mb the existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 93.26%, 87.27%, 92.46% and 88.19% low F-measure. The proposed IDFKM-M3DRT method achieved 96.85% high F-measure.
Performance of F-measure
Table 11 shows the clustering period of proposed IDFKM-M3DRT and existing methods STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA respectively. At file size 10 mb the existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 13.46%, 12.57%, 11.25% and 14.37% high clustering period. But the proposed IDFKM-M3DRT method achieved 10.55% low clustering period. At file size 20 mb the existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 19.25%, 18.36%, 17.36% and 18.46% high clustering period. But the proposed IDFKM-M3DRT method achieved 16.43% low clustering period. At file size 30 mb the existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 24.57%, 22.57%, 24.36% and 25.84% high clustering period. The proposed IDFKM-M3DRT method achieved 20.54% low clustering period. At file size 40 mb the existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 28.46%, 27.57%, 28.36% and 28.37% high clustering period. The proposed IDFKM-M3DRT method achieves 26.44% low clustering period. At file size 50 mb the existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 36.95%, 37.98%, 36.37% and 36.36% high clustering period. The proposed IDFKM-M3DRT method achieved 35.23% low clustering period.
Clustering period
Table 12 shows the accuracy of proposed IDFKM-M3DRT and existing methods STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA respectively. At file size 10 mb the existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 73.57%, 67.96%, 73.56% and 74.68% low accuracy. But the proposed IDFKM-M3DRT method achieved 84.77% high accuracy. At file size 20 mb the existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 77.12%, 69.01%, 75.46% and 76.27% low accuracy. But the proposed IDFKM-M3DRT method achieved 93.14% high accuracy. At file size 30 mb the existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 79.25%, 74.62%, 77.83% and 78.26% low accuracy. The proposed IDFKM-M3DRT method achieved 90.34% high accuracy. At file size 40 mb the existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 82.95%, 78.26%, 79.36% and 80.62% low accuracy. The proposed IDFKM-M3DRT method achieves 91.77% high accuracy. At file size 50 mb the existing STRIDE, SDN-ACA, LZMA- DBSCAN and BDSA methods was achieves 85.65%, 81.92%, 82.36% and 87.32% low accuracy. The proposed IDFKM-M3DRT method achieved 93.66% high accuracy. Figure 6 shows the Computational complexity.
Performance of accuracy
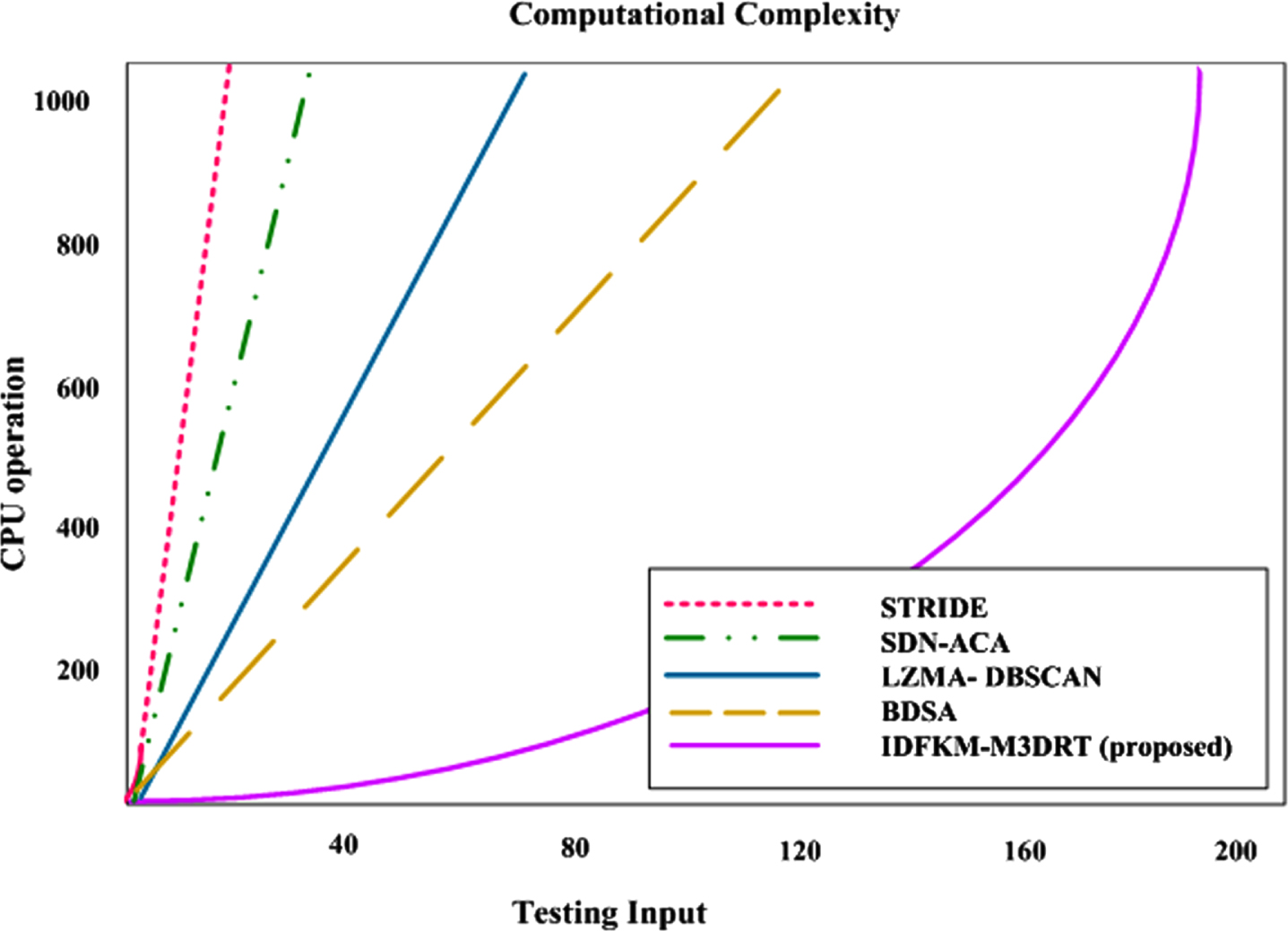
Computational complexity.
This manuscript proposes the Big Data in Hadoop Distributed File System (HDFS) in the light of combinedIDFKMandM3DRT approach is successfully implemented. The proposed method is implemented in Java programming and its performance is assessed by Health care database and the metrics under the study are memory usage, higher precision 34.75%, 25.86%, 23.75%, 33.78%, higher recall 23.86%, 27.97%, 22.97%, 37.97, 31.867%, lower aggregating time 35.23%, and the proposed method is compared with the existing method such as Security Analysis of SDN Applications for Big Data with spoofing identity, Tampering with data, Repudiation threats, Information disclosure, Denial of service and Elevation of privileges (STRIDE), Big Data Analysis-based Secure Cluster Management for using Ant Colony Optimization (ACA) Optimized Control Plane in Software-Defined Networks, System Architecture for Secure Authentication and Data Sharing in Cloud Enabled Big Data Environment using Lemperl Ziv Markow Algorithm (LZMA) and Density-based Clustering of Applications with Noise (DBSCAN), Big Data Based Security Analytics using data based security analytics (BDSA) approach for Protecting Virtualized Infrastructures in Cloud Computing respectively. The advantages of this method have less computation time as well as reduce the complexity of privacy protection with better accuracy.
The limitation of this work is this paper discusses only about Electronic Health Record (EHR). The other sources of big data in healthcare are not discussed. The other sources of big data in healthcare are Medical Imaging Data, Unstructured Clinical Notes and Genetic Data. This are discussed in future work and combine the various other sources of big data in healthcare such as social media, web searches and mobile devices and developing the knowledge system. Also for security purposes block chain based cryptography hash technique can be used for securing and sharing more pseudonymity details of different users and to reduce the complexity of the access of the authorized company.