
Abstract
As one of the key research directions in the field of computer vision, human action recognition has a wide range of practical application values and prospects. In the fields of video surveillance, human-computer interaction, sports analysis, and healthcare, human action recognition technology shows a broad application prospect and potential. However, the diversity and complexity of human actions bring many challenges, such as handling complex actions, distinguishing similar actions, coping with changes in viewing angle, and overcoming occlusion problems. To address the challenges, this paper proposes an innovative framework for human action recognition. The framework combines the latest pose estimation algorithms, pre-trained CNN models, and a Vision Transformer to build an efficient system. The first step involves utilizing the latest pose estimation algorithm to accurately extract human pose information from real RGB image frames. Then, a pre-trained CNN model is used to perform feature extraction on the extracted pose information. Finally, the Vision Transformer model is applied for fusion and classification operations on the extracted features. Experimental validation is conducted on two benchmark datasets, UCF 50 and UCF 101, to demonstrate the effectiveness and efficiency of the proposed framework. The applicability and limitations of the framework in different scenarios are further explored through quantitative and qualitative experiments, providing valuable insights and inspiration for future research.
Introduction
Human Action Recognition (HAR) aims to classify human actions and has been a prevalent task to solve using deep neural networks based on attention. HAR is fundamental for several application domains such as robotics [1] surveillance and security [2, 3] and autonomous driving [4, 5]. Although HAR has many important applications, it is a difficult problem to solve suffering from a large volume of video data, untrimmed videos, multiple actors, action classes, etc. Previous works [6, 7, 8] have focused and worked on long-time HAR, which depends on long-term past and future information. But a more practical application for real-time applications performs short-time HAR, which relies only on near past information.
In solving HAR problems, Convolutional Neural Network (CNN) based methods are usually complex and require a large number of parameters to train the model, which increases the computational overhead. On the other hand, the Transformer network [9] can produce a much smaller number of trainable parameters because it can process data in parallel, which improves the computational efficiency compared to sequential data input in LSTM. Transformer is an extension of LSTM and was proposed in 2017, and has since been widely used in the field of Natural Language Processing (NLP). In 2020, Dosovitskiy et al. [10] first introduced a Transformer to the field of computer vision (CV) by proposing a Vision Transformer (ViT). In recent years, researchers have started combining the attention mechanism with convolutional neural networks for human action recognition. This approach effectively improves the performance of the model. Among them, Mazzia et al. [11] proposed the Action Transformer (AcT) model, which applies the Transformer to human action recognition by removing the bottleneck of a dataset based on body joints (keypoints) extracted from video frames. Methods for extracting body joints use pose estimation algorithms such as OpenPose [12] and PoseNet [13]. However, these methods have limitations in terms of speed and accuracy. To address this problem, we propose a new approach that combines a CNN with a Transformer. Firstly, image keypoint features are extracted using MoveNet [14], and then spatial features are extracted using a pre-trained CNN model. Finally, spatio-temporal features are processed using a Transformer encoder to classify the frame sequence into activity classes. This approach combines high-precision keypoint detection with high-speed detection capability, improving the performance of the HAR model. The main contributions of the work presented in this paper are summarized as follows:
We propose a new framework for human action recognition which successfully extracts spatial features with rich information using three pre-trained CNN models by transfer learning technique. Convolutional feature extractor is introduced to work on real RGB image frames for richer learning space. Using latest pose estimation algorithm as model feature extractor and building a training and inference pipeline with convolutional feature extraction for transformer encoder. Performing varied experimentation to demonstrate the relevance of various architectural design choices and their impact on performance and complexity. We also evaluated the proposed framework on two benchmark datasets, UCF 101 and UCF 50, and achieved high accuracies of 87.50% and 83.41%, respectively.
The rest of the paper is organized as follows. Section 2 will provide an in-depth analysis of related work in the field of human movement recognition. Section 3 will present a detailed description of our proposed framework for human movement recognition. Section 4 will evaluate the performance of the proposed framework using a benchmark dataset and discuss the results. Finally, Section 5 will summarise the main contributions of this paper and suggest some future research directions.
HAR, as one of the most active research directions in the field of video understanding, plays a crucial role in overall video understanding. Currently, HAR employs a variety of forms, such as appearance, depth, optical flow, and body skeleton, to understand the video content more comprehensively. Among them, deep learning models, especially CNNs, play an important role in HAR. CNN have been the core technology for many visual recognition tasks. For HAR, Simonyan and Zisserman [15] proposed a standard approach to average the prediction results of two separately trained 2D CNN by capturing complementary information on appearance and motion simultaneously. One CNN processes RGB frames and the other processes optical flow frames. Another popular HAR method is 3D ConvNet, which is capable of modeling temporal information without relying on optical flow information. The work of Ji et al. [16] further develops 3D ConvNet by performing 3D convolution operations to extract motion features from spatial and temporal information. With further research, pose estimation algorithms have gradually been combined with HAR to provide new ideas for solving the occlusion problem. For example, Angelini et al. [17] proposed ActionXPose, an action recognition method based on 2D pose estimation. The method utilizes OpenPose for skeleton feature extraction and employs a long-term memory neural network (LSTM) and a 1D CNN for classification. In addition, the classification process incorporates the MLSTM-FCN structure [18], which combines 1D CNN, LSTM [19], and squeezing and stimulated attention mechanisms [20]. In addition, Graph Convolutional Network (GCN) based approaches have advantages in processing data with generalized topologies, such as human skeletal data. Compared with CNN and RNN, GCN can dig deeper into the intrinsic features of the data. Graph convolution [21, 22], as a typical GCN method, can show good performance in processing human skeletal data. Yan et al. [23], in their study, first applied a graph convolution neural network to action recognition and proposed a spatio-temporal graph convolution network (ST-GCN). This method uses OpenPose to extract skeleton data from videos and uses graph neural network GCN combined with spatio-temporal information to achieve action classification. This innovative approach provides important insights for subsequent researchers. Li et al. [24] further optimized this approach by proposing a structure graph convolutional network (AS-GCN) and introduced an Encoder-Decoder structure, called an A-link inference module (AIM), to capture potential dependencies specific to actions. This approach combines action structure graph convolution and temporal convolution, aiming to learn spatial and temporal features for action recognition. Shi et al. [25] also proposed a structure graph convolution network (2s-AGCN) based on their previous work, and this approach makes full use of the correlation information between the joints and the skeleton to further improve the accuracy of action recognition. However, skeleton-based action recognition faces a challenge: the lack of long-term contextual information. To solve this problem, Cho et al. [26] applied Self Attention Network to skeleton-based action recognition, which effectively dealt with this problem by focusing on long-term dependencies. In recent years, with the development of machine translation converters, powerful architectures such as BERT [27] and GPT [28] proposed by Vaswani et al. [9] have made remarkable achievements in the field of NLP. Plizzari et al. [29] explored further on this basis and proposed a two-stream spatiotemporal Transformer network model (ST-TR) based on the dual stream spatiotemporal. This model fuses the Transformer’s self-attention mechanism with graph convolution and shows excellent performance in capturing dynamic dependencies between joints. The Transformer architecture has also been applied to vision tasks. Dosovitskiy et al. [10] introduced Vision Transformer (ViT), a purely Transformer model that performs classification tasks directly using image patches. Gowda et al. [30] further showed that convolutional stems can significantly improve optimization stability and increase peak performance. In addition, Mazzia et al. [11] extended the idea of ViT to the field of HAR by proposing an AcT. AcT encodes the estimated pose information from the video and performs action classification using ViT. Unlike previous approaches, this paper proposes a human action recognition architecture based on CNN and ViT. In addition, we use the latest pose estimation algorithm as a feature extractor for the model and investigate the model at different scales, examining the effects of the number of parameters and the number of attention heads on the model.
Proposed method
Our goal is to classify the temporal sequences of images i.e., video, into different class labels representing the type of action happening in the scene. A graphical visualization is given in Fig. 1. More formally, given a sequence of frames
Architecture of proposed model.
MoveNet is a lightweight human pose estimation model based on the CentreNet model, proposed by Google in 2021. The model uses MobileNetV2 [31] combined with Feature Pyramid (FPN) as a feature extractor. The feature extraction network outputs four headers, where the Centre is used to predict the geometric centroid of the human body. By multiplying each pixel by weight, the human body center coordinates closest to the center of the image are selected. Keypoint Regression uses the selected human body center point coordinates to perform a rough 17-joint coordinate regression. A keypoint Heatmap is used to obtain more accurate keypoint locations. Finally, the corresponding offset values in the Local offset Header are added according to the coordinate points to get the final pose estimation results. This process is illustrated in Fig. 2.
MoveNet architecture.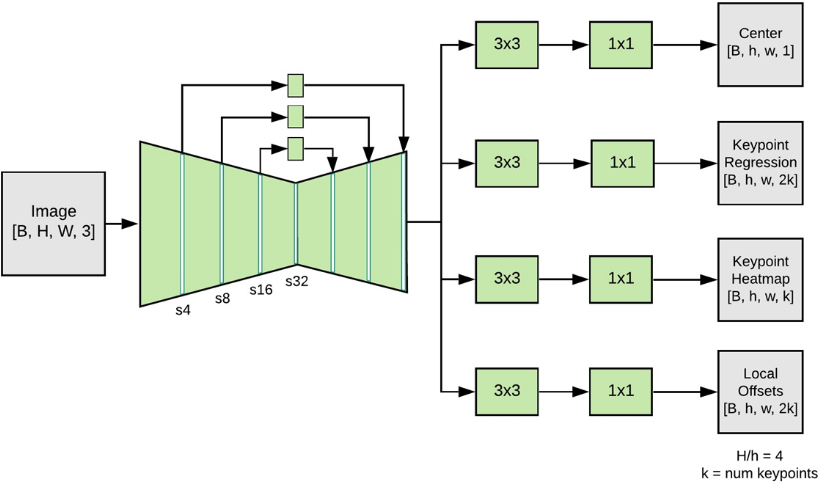
Feature extraction from input frames using convolutional layers helps transformers to focus on better feature representations. Given a sequence of input frames
Here
ResNet-18, the basic architecture of the network is ResNet with a network depth of 18 layers as shown in Fig. 3. ResNet (Residual Network) addresses the issue of gradient vanishing or gradient explosion during the training of deep neural networks by introducing residual blocks, enabling them to be trained to greater depths. Residual blocks form the core component of ResNet-18, each comprising two 3
Resnet 18 architecture.
EfficientNet is a model proposed by Google Research in 2019 to optimize model size and computational efficiency while maintaining model accuracy as shown in Fig. 4. The main goal of EfficientNet is to optimize model size and computational efficiency while maintaining high accuracy to adapt to different computational and resource constraints and to achieve optimal performance. EfficientNet successfully achieves the goal of optimizing model size and computational efficiency by synchronizing network depth, width, and resolution using an innovative scaling approach. EfficientNet is typically based on pre-trained models (e.g., ResNet or MobileNet) as the underlying network, which provides a stable and efficient starting point. Through deeply separable convolution and linear bottleneck techniques, the EfficientNet module effectively reduces the number of parameters and the computational effort of the network while maintaining good performance. EfficientNet further improves the efficiency and speed of processing data by adopting the structure of bottleneck convolution and extended convolution. By fine-tuning the network coefficients, EfficientNet achieves the goal of achieving optimal performance with given computational resources. Specifically, it first fixes a coefficient and then uses a network search method to find the best combination of
EfficientNet architecture.
WideResNet is a network architecture that improves on ResNet by increasing the width of the network, aiming to improve the expressiveness and performance of the model. Despite the increase in the number of parameters and computational complexity, WideResNet demonstrates efficient computational performance and excellent results. WideResNet effectively enhances the expressive power of the model by expanding the width of the network, thereby improving performance. Despite the increase in the number of parameters and computational complexity of WideResNet, its efficient computational performance and excellent performance make it an effective network architecture.
Sequence-level embedding
In our approach, we can use an arbitrary number of frames
Then, we apply positional encoding
A complete Transformer Encoder module comprises multiple Transformer Blocks, each including Layer Normalization (Norm), a Multihead Self-Attention Mechanism, Residual Connection, and MLP layers. After processing through these Blocks, the dimension of the input sequence remains unchanged. The module initially normalizes the input sequence through the Norm layer to expedite model convergence. Subsequently, the multi-head self-attention mechanism captures contextual information in the input sequence, enabling the model to comprehend the data from various perspectives by splitting the input into multiple heads and independently computing attention weights. The computed attentional weights are then residually concatenated with the original input to address the gradient vanishing problem. Following this concatenation, the data undergoes another normalization through the Norm layer. Finally, image features are extracted through an MLP layer consisting of a Fully Connected Layer, GELU activation function, and Dropout. This MLP layer facilitates global feature interaction by modeling global information and transforming the input image information into a high-dimensional feature vector. Multi-head attention serves as the core component of the Transformer model for capturing contextual information in the input sequence. The mechanism decomposes the input sequence into multiple sub-sequences and independently computes attention weights for each sub-sequence. These weights are then combined to produce the final attention weights. This design enables the model to simultaneously attend to different parts of the input sequence, thus more effectively capturing contextual information. In the multi-head attention mechanism, the token of each sub-sequence is mapped to three matrices,
Each head is a Scaled Dot-Product Attention module. By dividing the input sequence into multiple parts and performing the attention computation separately, Multi-Head Attention can understand the input data from several different perspectives, thus enhancing the model’s representational capabilities. This design makes the model more flexible in dealing with complex linguistic phenomena and improves the memory ability for long sequences. At the same time,
In this way, the Scaled Dot-Product Attention module can capture important features in the input data and compare them with other tokens to generate outputs with rich contextual information. In Multi-Head Attention, multiple Scaled Dot-Product Attention modules work in parallel to understand the input data from different perspectives, which further enhances the model’s representational capabilities.
The left side demonstrates the Architecture of Transformer Encoder while the right side demonstrates the Multi-Head Self-Attention Model.
Our architecture for Transformer Encoder uses similar approach as Vison-Transformer and Action-Transformer. It contains repetitive blocks of an encoding block consisting of Multi-headed Self Attention (MSA) and Multi-layer Perceptron (MLP). Multi-headed Self Attention uses multiple number
were
We select the first element
We first discuss the datasets used for experimentation in Section 4.1, then discuss the evaluation metrics using which we present our results in Section 4.1–4.4.
Datasets
We use UCF 50 [37] and UCF 101 [38] which are challenging in terms of large variations in camera motion and object appearance in contrast to MPOSE 2021 dataset which was presented by Mazzia et al. We also extracta 10-class subset (UCF 10) from UCF 50 using the first ten classes of the dataset for experimentation. UCF 50 has 50 action categories and has 4790 training videos and 1891 testing videos. Similarly, UCF 101 has 101 action categories. The first fold of UCF 101, which we use, contains 9537 training videos and 3783 testing videos in the testing set. Since every video has a long variable length, it is further split into multiple patches of
Evaluation metrics
We use Top-l and Top-5 classification accuracy on the test datasets of UCF 50 and UCF 101. Moreover, to observe and compare the complexity of our models, we also present GFLOPs, i.e., Giga Floating Point Operations persecond.
Training
Optimization of the whole pipeline is done using Cross-Entropy Loss which is averaged over the examples in training batch
For optimization, we use AdamW [40] optimizer with a learning rate of 0.00003. We use a maximum batch size of 8 during training, and we could not test it beyond this batch size due to GPU constraints. Moreover, we initialize the weights
In the Transformer Encoder, we keep the dimension
We perform multiple experiments and ablation studies to validate our architectural choices. Therefore, we set up our experiments on different datasets, i.e., UCF 10, UCF 50, and UCF 101.
Number of attention heads
We perform experiments with a different number of attention heads as shown in Table 1. We observe increasing attention heads to eight overfits and decreasing attention heads to two underfits. So, four heads provide a better trade-off. Moreover, GFLOPs don not differ that much. These experiments use WideResNet-50-2 on UCF 50 with 128x128 resolution.
Number of classes
In this experiment, we see the effect of the number of classes on classification accuracy as shown in Table 2. The number of classes increases the complexity of the problem, and it becomes difficult to classify the classes correctly. We see a similar trend from the results, and as the number of classes increases, the accuracy drops.
Top-l, Top-5 accuracies and GFLOPs for different number of attention heads
Top-l, Top-5 accuracies and GFLOPs for different number of attention heads
Top-1, Top-5 accuracies and GFLOPs on different number of classes
We aim to check the effectiveness of different feature extractors to generate better features for Transformer as shown in Table 3. We see that the WideResNet-50-2 has produced slightly better accuracy when compared to other models but uses a lot more GFLOPs when compared to EfficientNet V2S which produces good enough accuracy. We also correspond to the baseline and see convolutional features perform much better. These experiments were performed with two attention heads on UCF 50 with 128
Top-1, Top-5 accuracies and GFLOPs on different feature extractors
Top-1, Top-5 accuracies and GFLOPs on different feature extractors
We experiment with freezing the weights and fine-tuning end-to-end to analyze the effect of lmageNet pre-training for feature extractors as shown in Table 4. Fine-tuning the feature extractor end-to-end gives better accuracy on UCF 101 as the information flow from the transformer to the feature extractor fine-tunes the model specific to the task. Here the resolution is 224
Top-l accuracy comparing frozen vs. fine-tuned models on UCF 101 dataset
Top-l accuracy comparing frozen vs. fine-tuned models on UCF 101 dataset
While observing the impact of the number of frames for experimenting on UCF 101 and four attention heads, we see that 30 frames per video gave us better accuracy compared to 50 frames per video, so higher the number of frames does not imply better accuracy as shown in Table 5. Here the resolution is 224
Top-l accuracy comparison between 30 and 50 frames on different feature extractors
Top-l accuracy comparison between 30 and 50 frames on different feature extractors
Comparison of the performance of our proposed method with state-of-the-art on UCF 101 dataset
Comparison of the performance of our proposed method with state-of-the-art on UCF 50 dataset
Classification embeddings comparison between baseline MLP and our method WideResNe-502 using video class tokens.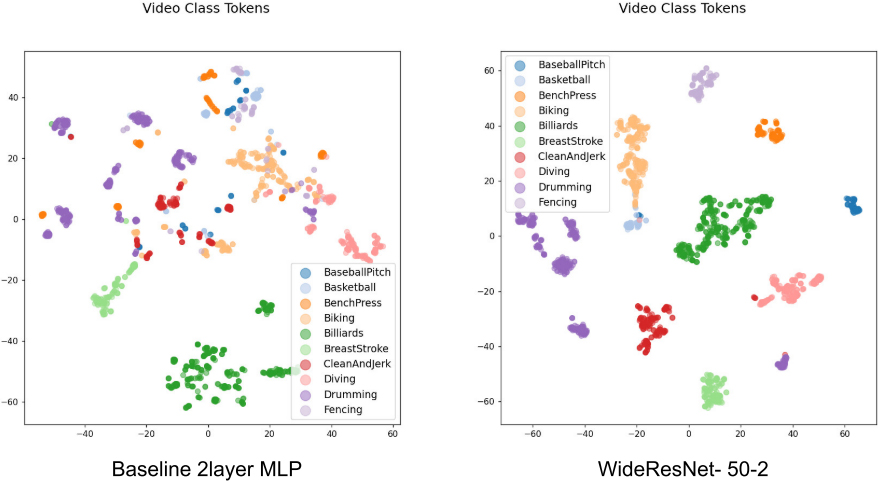
Confusion matrix on UCF 50. The verticaaxis represents True Label, and the horizontal axis represents predicted labels.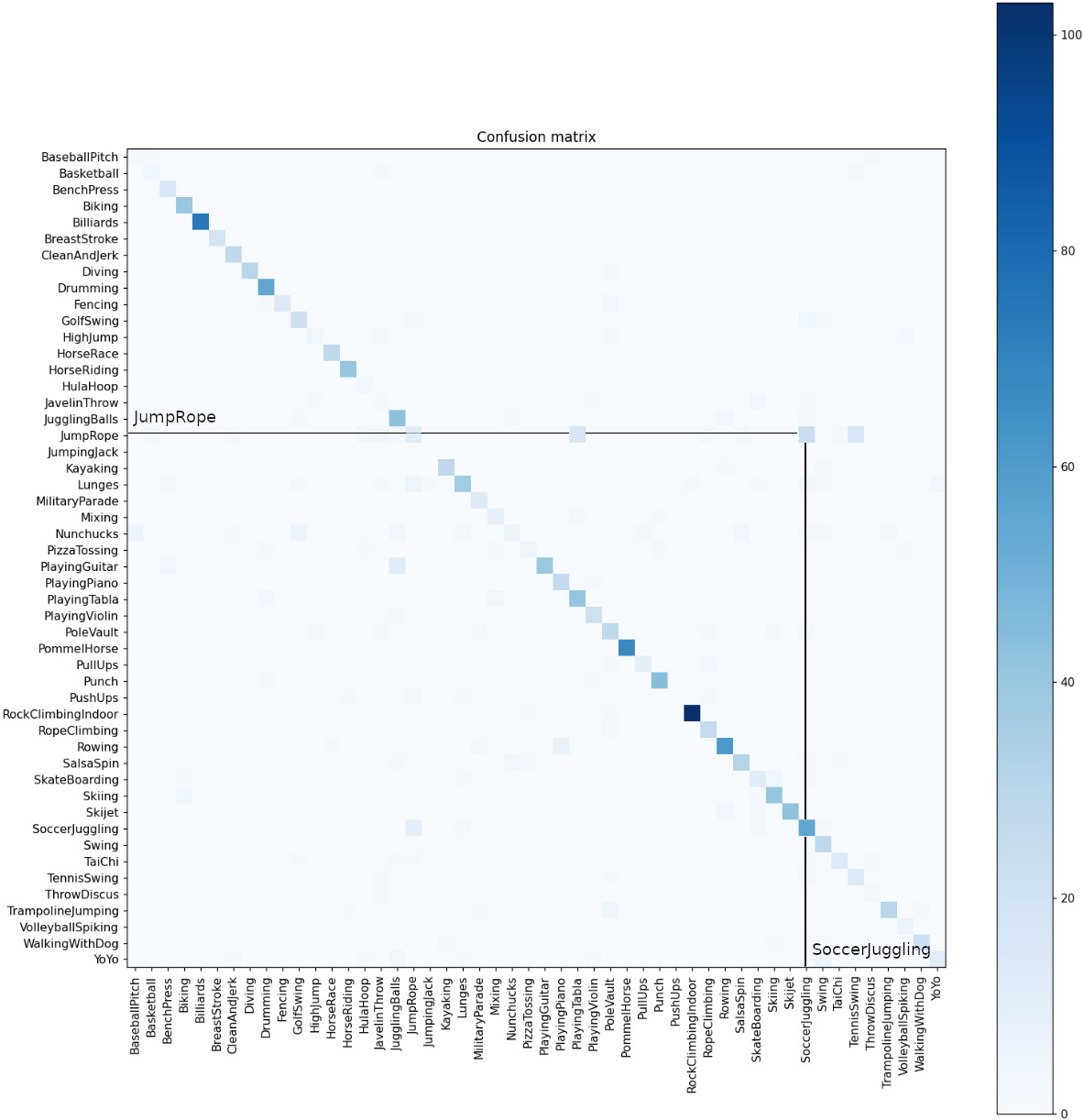
On the UCF 101 dataset, our proposed method demonstrates outstanding performance with an accuracy of 87.50% as shown in Table 6. In comparison, the Dual Input Sequential Network (DISNet) proposed by Sahoo et al. [43] achieves an accuracy of 54.96% on the UCF 101 dataset, significantly lower than our method. This finding further confirms the higher classification accuracy and robustness of our approach in handling complex action recognition tasks. The two-stream CNN method suggested by Nguyen et al. [43] attains an accuracy of 86.10% on the UCF 101 dataset. While this result is already relatively high, it is slightly less accurate compared to our method. This indicates that our method holds a significant advantage in feature extraction and integration, leading to more accurate recognition of different actions. The pre-trained two-stream CNN method proposed by Kim et al. [44] achieves an accuracy of 87.50% on the UCF 101 dataset, a result comparable to our method. However, our method combines CNN with transform, endowing it with higher generalization ability and robustness.
On the UCF 50 dataset, our method demonstrates excellent performance with an accuracy of 83.41% as shown in Table 7. The LC
Comparison of sequence-level embedding with baseline MLP
We visually analyze (see Fig. 6) the difference between learned class tokens for baseline MLP and convolutional feature extractor and observe that class tokens accumulate better information for classification tasks bringing better disparity between examples of different classes. We use UCF 10 for better illustration purposes.
Limitations
Our approach does suffer from misclassifications in a similar data regime. For example, actions with similar body movements like JumpRope and SoccerJuggling get misclassified due to similar hand and leg movements. See Fig. 7 for confusion matrix on UCF 50. Such misclassification indicates the model’s vulnerability toward adversarial attacks such as evasion attacks.
Conclusion
This paper aims to address the human action recognition problem and proposes an innovative deep-learning framework for this purpose. The framework utilizes state-of-the-art pose estimation algorithms to precisely extract human pose information from RGB image frames. To effectively capture rich spatial features, a pre-trained CNN model is employed for extracting the pose information. Subsequently, the training inference pipeline for transformer encoder convolutional feature extraction is constructed using the Vision Transformer for feature fusion and classification, thereby enhancing the model’s accuracy and robustness. To validate the effectiveness and efficiency of the proposed framework, we conduct exhaustive experiments on two benchmark datasets: UCF 101 and UCF 50. The experimental results demonstrate high accuracy on both datasets, reaching 87.50% and 83.41%, respectively. In the future, we plan to benchmark on more extensive datasets such ActivityNet/Kinetics, to validate its generalization ability. Additionally, we aim to explore extending the framework to areas like zero-shot classification and domain adaptation while enhancing the model’s robustness against adversarial attacks.
Footnotes
Acknowledgments
This research supported by the Open Project Program of The Key Laboratory of Cognitive Computing and Intelligent Information Processing of Fujian Education Institutions, Wuyi University.
Conflict of interest
The authors declare that they have no conflict of interest.
Data availability
The dataset used in this research are publicly available from the following websites:
UCF 101:
UCF 50: