
Abstract
Human action recognition has been widely used in fields such as human–computer interaction and virtual reality. Despite significant progress, existing approaches still struggle with effectively integrating hierarchical information and processing data beyond a certain frame count. To address these challenges, we introduce the Multi-AxisFormer (MAFormer) model, which is organized in terms of spatial, temporal, and channel dimensions of the action sequence, thereby enhancing the model’s understanding of correlations and intricate structures among and within features. Drawing on the Transformer architecture, we propose the Cross-channel Spatio-temporal Aggregation (CSA) structure for more refined feature extraction and the Multi-Axis Attention (MAA) module for more comprehensive feature aggregation. Moreover, the integration of Rotary Position Embedding (RoPE) boosts the model’s extrapolation and generalization abilities. MAFormer surpasses the known state-of-the-art on multiple skeleton-based action recognition benchmarks with the accuracy of 93.2% on NTU RGB+D 60 cross-subject split, 89.9% on NTU RGB+D 120 cross-subject split, and 97.2% on N-UCLA, offering a novel paradigm for hierarchical modeling in human action recognition.
Introduction
In the context of burgeoning advancements within computer vision, the domain of human action recognition has emerged as a focal point for scholarly inquiry. The primary objective of this endeavor is to precisely categorize sequences of human actions gleaned from video or sensor data. The import of this work is profound, given its broad utility, most particularly in the realm of enhancing human-computer interaction [2]. The ability to comprehend and decipher human actions has the potential to significantly transform user engagement and system efficacy. Traditional strategies in human action recognition encompass a spectrum of methodologies, including video-centric [9,22], skeleton-centric [12,33], and heatmap-centric [37] approaches. Among these, the skeleton-based approach stands out for its proficiency in efficient processing and resilience against background noise and lighting interference.
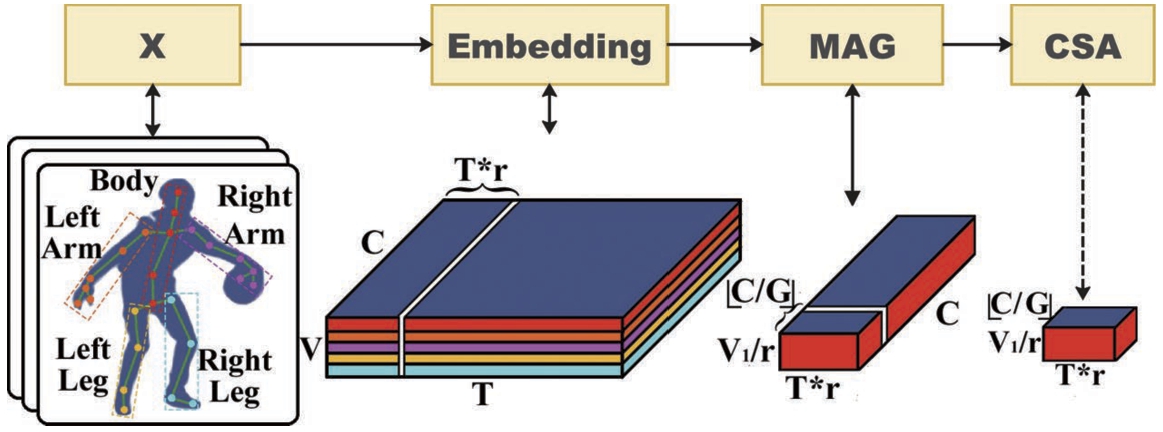
Visualization of the data and feature transformation process, illustrating the Cross-channel Spatio-temporal Aggregation (CSA) module with dashed lines indicating the channel grouping stage’s data shape, and solid lines for input data shape. The CSA module, part of the Multi-Axis Grouping (MAG) structure, encodes joint feature sequences at fixed frame rates, leveraging cross-channel aggregation for effective feature extraction across body parts in action sequences. Parameters: C – number of channels, G – number of channel groups, r – sampling frame rate, T – number of frames, V – total number of nodes,
Within the realm of skeleton-centric approaches, Graph Convolutional Networks [13,15,19] and Transformers [1,4,29] have been pivotal in addressing several intrinsic difficulties and challenges. Central to these challenges is the accurate capture and interpretation of the spatial relationships and dynamics of skeleton joints – an area where GCNs shine due to their proficiency in modeling the human body as a graph. This graph-centric methodology facilitates an understanding of the structural interdependencies among body parts, enabling the model to garner more nuanced spatial information. However, these methods often struggle with effectively capturing long-term dependencies. Conversely, Transformer-based methods have garnered increasing attention in recent years. The superiority of Transformer methods over GCNs primarily lies in their adeptness at managing temporal dynamics and long-range dependencies within action sequences. Transformers, equipped with their sophisticated self-attention mechanism, excel in capturing the temporal correlation among joints – a pivotal element in deciphering human actions that manifest across disparate temporal segments. This facet of their functionality enables a more refined interpretation of sequential data relative to GCNs, which predominantly concentrate on spatial relationships. Although an array of innovative and efficacious methodologies has arisen within the sphere of human action recognition, these approaches have encountered certain limitations and opportunities for enhancement remain. It is a well-established fact that humans are endowed with an innate capacity to comprehend complete actions by observing movements of specific body parts, thereby underscoring the pivotal role of local information priors regarding the human body in the realm of action recognition. However, a significant drawback of numerous contemporary models is their inadequate ability to glean such complex information, particularly with respect to physics-based hierarchical limb structures. This shortcoming curtails their effectiveness in extracting hierarchical features that are indispensable for a thorough grasp of human actions. Additionally, Transformers frequently incorporate Positional Encoding (PE) to enhance their grasp of the sequential order within inputs. Traditional PE approaches, such as absolute positional encoding, often rely on fixed coding vectors that are constant across all positions within the input sequence. This approach can engender positional biases, wherein the model becomes overly reliant on specific positional information, compromising its ability to extrapolate and comprehend the external structure of features, thereby impacting the model’s generalization skills [10,21,27]. Furthermore, Transformer-based methods commonly utilize Multilayer Perceptron (MLP) structures as Feed Forward Networks (FFN). However, research has identified redundancies in the computations within MLPs, emphasizing the necessity for more efficient FFN architectures to fully realize the intrinsic potential of Transformers [32,40]. To address these challenges, we propose enhancing the model’s ability to grasp the correlations and structural complexities both within and among the features. To internalize the features, it is crucial for the model to develop a comprehensive grasp of the distinctive morphology of the human body. This deepened understanding will enable the model to fully appreciate the physiological architecture of key limbs, moving beyond a mere spatial distribution of joint points. Externally, the model must engage in a systematic analysis of the structure of the action itself. This recognition includes the insight that an action is composed of multiple subsequences. By enhancing the model’s capacity to identify and comprehend the interdependencies among these subsequences, it can attain the proficiency to adeptly handle actions encompassing diverse frame counts. A holistic strategy that analyzes both intrinsic and extrinsic features is essential for facilitating a more nuanced and thorough interpretation of human actions.
In this paper, we introduce a novel architecture designed to model the spatial and temporal structures inherent in human behavior, thereby addressing the aforementioned issues and challenges. Our model endeavors to refine the understanding of correlations and structures within features by employing a novel approach to data organization on multiple dimensional axes, thereby capturing richer dependencies, as illustrated in Fig. 1. We term this architecture Multi-AxisFormer (MAFormer). Within this method, we present a Cross-channel Spatio-temporal Aggregation (CSA) module that encodes joint feature sequences sampled at fixed frame rates according to physical hierarchies, leveraging cross-channel aggregation for effective feature extraction. Specifically, we deploy parallel sub-networks within multiple channel groups to facilitate multi-scale feature extraction from action sequences across various body parts. We name this structure Multi-Axis Grouping (MAG). The features are then fused for cross-spatio-temporal feature aggregation, serving as the result of the Transformer structure. In addition, we propose a Multi-Axis Attention (MAA) module that utilizes the CSA module as its feed-forward network (FFN) to achieve more comprehensive feature aggregation. To mitigate the model’s over-reliance on specific location information, we integrate the Rotary Position Embedding (RoPE), which enhances the model’s extrapolation and generalization capabilities through enhanced relative position awareness. Furthermore, previous research [3,31] has investigated the influence of activation functions on Transformer models in specific quantized settings. Building on this work, our study also examines the effects of various activation functions on the performance of our model, thereby optimizing the potential of self-attention mechanisms.
For this paper, the main contributions are as follows:
To augments the model’s comprehension of correlations and structural intricacies both within and among the features, a MAG structure combining cross-channel multi-scale spatio-temporal aggregation with fixed frame rate sampling is proposed, achieving better robustness and generalization ability.
To better obtain the mutual position correlation among the features, the RoPE is introduced to reduce the position bias of a specific position, enabling the model to process data that exceeds the training frame count and enhancing the model’s extrapolation capability.
To enhance feature extraction while reducing redundancy, a MAA module is proposed, applying a presented CSA module to aggregate local spatio-temporal features instead of the original FFN method of aggregating only in spatial dimensions, enhancing the model’s long-term information memory capability.
The progress in deep learning has notably propelled research in human action recognition. The domain primarily revolves around the spatial analysis prowess of Graph Convolutional Networks (GCNs), whereas Transformer-based approaches are increasingly being favored for their advanced capability in managing temporal dynamics and scalability.
GCN-based methods. Skeleton data presents challenges for traditional vector sequence processing, which struggles to mimic the complex spatio-temporal configuration and correlations of human joints. In response, researchers have increasingly turned to topological graph representations that are more naturally aligned with the structure of skeleton data. Graph Neural Networks (GNNs), and specifically Graph Convolutional Networks (GCNs), have emerged as a focal point of innovation in this area. Chen et al.’s Multi-scale Spatio-Temporal GCN (MST-GCN) [6] expands the receptive field in both spatial and temporal dimensions, offering a more holistic perspective on human movement. Chen (B) et al.’s Channel-wise Topology Refinement GCN (CTR-GCN) [5] focuses on dynamic topology and multi-channel features, starting with a shared topology matrix as a universal prior for channels and refining it through the inferrence of channel-specific correlations. Chi’s InfoGCN [8] utilizes an information bottleneck learning objective to learn compact and information-rich latent representations, complemented by an attention-based graph convolution to infer context-relevant skeleton topologies. Ke et al. propose the Spatio-Temporal Focus (STF) [13] framework for skeleton-based action recognition, utilizing spatio-temporal gradients to guide the learning process. Lee et al. propose a Hierarchically Decomposed Graph Convolutional Network (HD-GCN) [15] for skeleton-based action recognition, using a novel HD-Graph to identify relationships between distant joint nodes and an A-HA module to highlight key edge sets. Cheng et al. introduce the Feature Refinement Head (FR Head) [39] for differentiating between ambiguous actions, striving for a more discriminative representation of the skeleton.
However, GCN-based methods encounter difficulties in handling long-term dependencies, which limits their ability to capture the complexity and hierarchical features of human actions. To address these challenges, our model employs a transformer architecture and integrates the concept of GCN-based approach for capturing local relationships between nodes, while also incorporating physical priors related to the human skeletal structure. This integration allows for more accurate extraction of hierarchical features and a more comprehensive understanding of complex actions, leading to improved performance in action recognition tasks.
Analysis among various algorithms
Analysis among various algorithms
Transformer-based methods. Many methods, such as LSTM, Transformer, etc., contribute to solving the long-term dependency problem, and Transformer-based methods stand out among them. Transformers show promising potential in handling sequence data, leading to their application in skeleton sequences for spatio-temporal modeling. Qiu et al. propose STTFormer to capture multi-joint dependencies between adjacent frames and aggregate sub-movement features [20]. Wang et al.’s IIP-Transformer [30] focuses on action recognition using part-level skeleton data encoding. Liu et al. introduce the Kernel Attention Adaptive Graph Transformer Network (KA-AGTN) [17], capturing various high-order joint dependencies. Zhu et al. propose MotionBERT [41], pretraining a motion encoder to recover 3D motion from 2D observations using diverse data, representing a unified approach in the field. Ahn et al. propose the STAR-transformer [1], integrating full, zigzag, and binary spatio-temporal attention modules to effectively represent and balance cross-modal video and skeleton features for improved action recognition performance. Wang et al. introduce 3Mformer [29] to enhance skeletal action recognition by modeling higher-order motion patterns with hypergraph-based Transformers. Chen et al. propose a transformer-based model [4] with a feature fusion module, utilizing a pre-trained Swin-Transformer for hierarchical feature extraction and fusion to enhance human action recognition in still images.
Compared with the GCN method, Transformer-based methods, while powerful in capturing long-term dependencies, often struggle with spatial modeling and lack access to crucial prior information about human body structure, such as the topological information inherent in graph structures. This deficiency hampers their ability to accurately model the complex and hierarchical nature of human actions, particularly in relation to physics-based limb structures. Table 1 exhibits various comparisons among such algorithms. Our approach addresses these limitations by integrating the strengths of Transformer architectures with enhanced spatial modeling capabilities. We incorporate a detailed understanding of the human skeletal structure, leveraging local information priors to better capture the intricacies of human movements. By doing so, our model not only retains the ability of Transformers to manage long-term dependencies but also improves the extraction of hierarchical features essential for a comprehensive understanding of human actions.
Notations
In this paper, regular font is used for scalars, e.g., (x, y, z). Boldface Lowercase is used for vectors, e.g., (
Self-attention mechanism
In Transformer models, the input sequence

Architecture of MAFormer. The MAG performs physics-based hierarchical coding on key point feature sequences sampled at a fixed frame rate, and the CSA performs cross-channel feature aggregation. The MAA module uses the CSA as FFN and employs the
The objective of our study is to refine the model’s grasp of the intercorrelations and intricate structures inherent in individual features as well as their relationships, thereby boosting its proficiency in action identification. To this end, we aim to endow the model with a nuanced understanding of anatomical limb architecture derived from physics, along with temporal patterns underpinning action dynamics and multi-dimensional spatial feature interactions.such information facilitates the model in artfully blending immediate local features with broader contextual global features. In response to these requirements, we introduce MAFormer – a novel framework that employs a Multi-Axis Grouping (MAG) strategy for the hierarchical encoding of keypoint sequences extracted at a consistent frame rate. This is coupled with a Cross-channel Spatio-temporal Aggregation (CSA) module, designed for the efficient amalgamation of cross-channel features. To further augment feature interaction and reduce architectural complexity, we propose the Multi-Axis Attention (MAA) module. This module leverages CSA to facilitate Feed-Forward Network (FFN) operations on feature maps, thereby enhancing cross-channel communication and dimensionality reduction. In addition, the MAA module harnesses Rotary Position Embedding (RoPE) for positional encoding, which bolsters the model’s capacity for extrapolation and generalization. Subsequently, a Temporal Convolutional Network (TCN) module is integrated to facilitate the aggregation of long-term features, optimally utilizing transient relational information. The methodological flowchart delineating the sequence of information processing is presented in Fig. 2. We proceed to outline the technique in alignment with the informational processing sequence, providing a coherent narrative of the model’s architecture and operation.
RoPE
RoPE is a relative position encoding method proposed by Roformer to help the model analyze the structure of features, thus enhancing its extrapolation capability [27]. The purpose of RoPE is to find a function f to encode the vectors
Encoder
For humans, an action can also be recognized when only part of the body or partial movement is seen. Because in many actions, some limbs move more frequently while other limbs may remain stationary. In addition, some motion trajectories can be inferred from visible parts. Inspired by this intuition, we propose a new architecture that captures rich local information from a part of the action sequence to infer global information, thereby aiding human action recognition.
MAG module. As an important module to enhance the model’s understanding of the correlation and structural complexity within and among features, the MAG combines cross-channel and multi-scale spatio-temporal aggregation with fixed frame rate sampling. It divides the human body into five parts according to the physical structure, namely body, left arm, right arm, left leg, and right leg. Denoting the according frame numbers of each part as
As shown in Fig. 2, global average pooling and 1 × 1 convolution to are utilized to encode the global spatial and temporal information of the input sequence respectively, splicing them into the same dimension, i.e.,
MAA module. The output of the MAG module contains spatio-temporal related features of the aforementioned five different limb action sequences, which are aggregated through spatial splicing and Multi-Axis Attention (MAA) mechanisms, as shown in Fig. 2. Among them,
The attention map is multiplied by
In the preprocessing stage of most action recognition methods, a hyperparameter frame count T is set, and the frame count is unified by cutting the sequence exceeding T frames and padding the sequence less than T frames to facilitate the calculation of the model. This can lead to that the models are often compelled to allocate additional attention scores to unnecessary frame features. The introduction of the β aims to adjust the contrast of the Softmax function, thereby reducing the competition among attention scores. This allows the model to assign lower weights in specific situations. In the FFN process, the CSA module is utilized for feature aggregation, enabling the acquisition of multi-scale spatio-temporal feature information.
TCN. Regarding fixed frame sampling, the output features contain feature information of some sub-actions of the input [20]. In this module, the model restores the previous frame sampling operation to obtain
Four-stream ensemble
Existing research indicates that integrating various modalities, like joint, bone, joint motion, and bone motion, can substantially improve human action recognition [24,25]. In this paper, our evaluation focuses on models utilizing these four modality streams. Specifically, the bone stream, which employs bone modality as its input, is adopted from 2s-AGCN [25], while the approaches for joint motion and bone motion streams are in line with DGNN [24]. The final outcome is derived from a weighted average based on the inferential outputs of these models.
Ablation study of Top-1 accuracy (%) with different groups. The baseline means using MLP as FFN in the original method. Note that in this experiment, the MAG module is not applied
Ablation study of Top-1 accuracy (%) with different groups. The baseline means using MLP as FFN in the original method. Note that in this experiment, the MAG module is not applied
To validate the effectiveness and advantage of the proposed MAFormer, we conducted comprehensive experiments on the NTU-60, NTU-120 and N-UCLA datasets. Furthermore, we performed a comparative analysis with current popular models and detailed ablation studies to explore the performance of the proposed modules under various conditions.
Datasets
Experimental settings
All experiments are performed on 2 GTX Titan GPUs. The skeleton sequences processed as in [5] are set to 120, 120, 56 frames for NTU-60, NTU-120, and N-UCLA, respectively. For most ablation experiments, the joint modality of NTU-60 under the X-Sub setting is used and the frame number is set to 60 frames. No other data processing or augmentation is applied for fair comparisons. Our model is trained utilizing a stochastic gradient descent (SGD) optimizer with a Nesterov momentum of 0.9, and the weight decay is set to 0.0005. The Cross-entropy is taken as the loss function. The training epoch is set to 90 for NTU-60 & 120, and to 30 for N-UCLA. The training epoch is set to 90 for NTU-60 & 120, and to 30 for N-UCLA. The initial learning rate is 0.1, and a warm up strategy is employed in the first 5 epochs for more stable learning [11]. For the NTU-60, NTU-120, and N-UCLA datasets, the learning rate is decayed at epochs on
Ablation study of Top-1 accuracy (%) with different activation functions. The baseline means using original Softmax. Note that in this experiment, the MAG module is not applied
Ablation study of Top-1 accuracy (%) with different activation functions. The baseline means using original Softmax. Note that in this experiment, the MAG module is not applied
To analyze the impact of the different components of the proposed MAFormer, we examine the performance of our model under different configurations and conditions.
Number of G in CSA. The channel dimensions are grouped into multiple sub-features in the CSA structure, the FFN of the MAA module. This experiment was designed to explore the impact of varying the number of channel groups G to be in equilibrium between capturing detailed information and computational efficiency. For different G in the CSA, we calculated the model’s parameter amount and its Top-1 accuracy rate on the NTU-60 under the X-Sub setting, as shown in Table 2, with the best performance marked in
Our findings indicate a modest decrease in the model’s parameter count with increasing G values. This trend suggests that the model becomes increasingly compact as G rises. Concurrently, the rate at which parameters decrease diminishes as G increases further, suggesting an approaching limit to this module’s compression capability. The model’s accuracy exhibits minor fluctuations across varying G configurations. Notably, the model attains its peak accuracy at 89.4% with G set to 16, surpassing the Baseline by 0.4%. This configuration also results in a reduction of 0.29M parameters compared to the Baseline.
These observations underscore that elevating G can preserve or slightly enhance accuracy while marginally reducing the model’s complexity. Furthermore, a G value of 16 appears to offer an optimal balance, yielding higher accuracy with a comparatively lower parameter count.

Accuracy variation with respect to different parameters, the MAFormer is trained on the 120-frame NTU-60 under X-Sub setting with the RoPE in this experiment.
Activation function in FFN. Many studies have proposed the impact of activation functions on Transformer models in certain quantized scenarios [3,31]. Inspired by these works, we also explore the impact of different activation functions on the performance of our proposed model, attempting to further harness the potential of self-attention mechanisms. We explored the impact of using different activation functions on model performance, as shown in Table 3 and Fig. 3a. The model with the Tanh activation function achieves an accuracy of
RoPE. In this experiment, we explore the impact of the RoPE on the model’s extrapolation and generalization ability. In our study, it is observed that the MAFormer, when utilizing traditional PE method, performs poorly in predicting new data that exceeds the frame count range of the training dataset. Conversely, when employing the RoPE operation, MAFormer shows considerable ability of predictive capability. To validate its effectiveness in forecasting actions beyond the training frame count, we configures the test set with varying frame numbers and subsequently computed the model’s test accuracy for each configuration. The experimental results are illustrated in Fig. 3b.
It can be seen that the MAFormer exhibits remarkable stability in accuracy across a large range of frame counts. The variations in accuracy are relatively insignificant, suggesting that the model maintains its performance effectively even as the frame count deviates from the training set’s frame count. Interestingly, the model achieves its peak accuracy at 144 frames (90.7%), slightly higher than the training frame count of 120. This indicates an optimal extrapolation range where the model performs best.
In addition, as the frame count increases beyond 144 frames, there is a gradual but consistent decrease in accuracy. However, this decrease is marginal, suggesting that while the model is optimized for a certain range of frame counts, its performance degradation is controlled and minimal even at higher frame counts. The consistency in performance across different frame counts and the minimal decrease in accuracy at higher frame counts imply that the inclusion of the RoPE in MAFormer effectively enhances its extrapolation ability. The model is capable of handling variations in frame count without significant loss in accuracy, showcasing its robustness and adaptability.
Overall, these results demonstrate the efficacy of the MAFormer model with the RoPE, particularly in maintaining high accuracy across varying frame counts and showing resilience against performance degradation with increased frame numbers. This underlines the model’s strong extrapolation capability and potential for practical application in diverse scenarios where frame count variability is a factor.
Four-stream ensemble.
Top-1 accuracy (%) of the methods using various data modalities on the NTU-60 and NTU-120 datasets
Performance comparison between MAFormer and prevailing methods in skeleton-based human action recognition tasks on the NTU-60, NTU-120, and N-UCLA datasets
In our study, a four-stream ensemble approach is employed to evaluate the trained models, encompassing joint, bone, joint motion, and bone motion streams. These individual streams, along with the ensemble methods, are assessed using the MAFormer on the NTU-60 and NTU-120, with results detailed in Table 4.
Analyses reveal a progressive enhancement in model performance with an increasing number of streams in the ensemble method. Specifically, on the NTU-60 under the X-Sub benchmark, employing joint + bone and the four-stream ensemble methods results in accuracy improvements of
The performance of our proposed MAFormer was assessed across three widely recognized benchmarks, and its efficacy was benchmarked against several contemporary leading methods. As depicted in Table 5, the MAFormer demonstrates superior performance over the compared methods in various settings, particularly when the number of streams is equivalent. Specifically, when the joint motion and bone motion streams are not incorporated, the MAFormer (2 s) achieves a
The comparative analysis distinctly illustrates the robust performance and potential of our MAFormer model, and highlights the efficacy and promising potential of our model in the realm of human action recognition.
Discussion and analysis
The visualization of attention scores comparing a specific joint to all other joints within sampled segments of three distinct actions, as depicted in Fig. 4, reveals a striking pattern. The figures predominantly show an increased focus on joints in the initial frames of the actions. This phenomenon can be attributed to the fact that initial movements are typically more unique and informative, thus playing a critical role in action recognition. For actions such as “Taking off Glasses” and “Touching Pocket,” the early movements are essential for the model to differentiate them from similar actions. The variance in attention scores across different actions suggests that the model modulates its focus in response to the distinct dynamic characteristics of each action. The observed pattern in the attention scores reflects the model’s learning mechanism, which emphasizes the early stages of an action. This emphasis could be a consequence of the training data’s characteristics or the inherent design of the model’s attention mechanism, which may be optimized to capture the onset of actions with greater precision. It implies that models should not only concentrate on the entire duration of an action but also should assign greater importance to the initial movements. These insights can inform future advancements in model architecture and training methodologies, thereby enhancing the accuracy and efficiency of human action recognition.
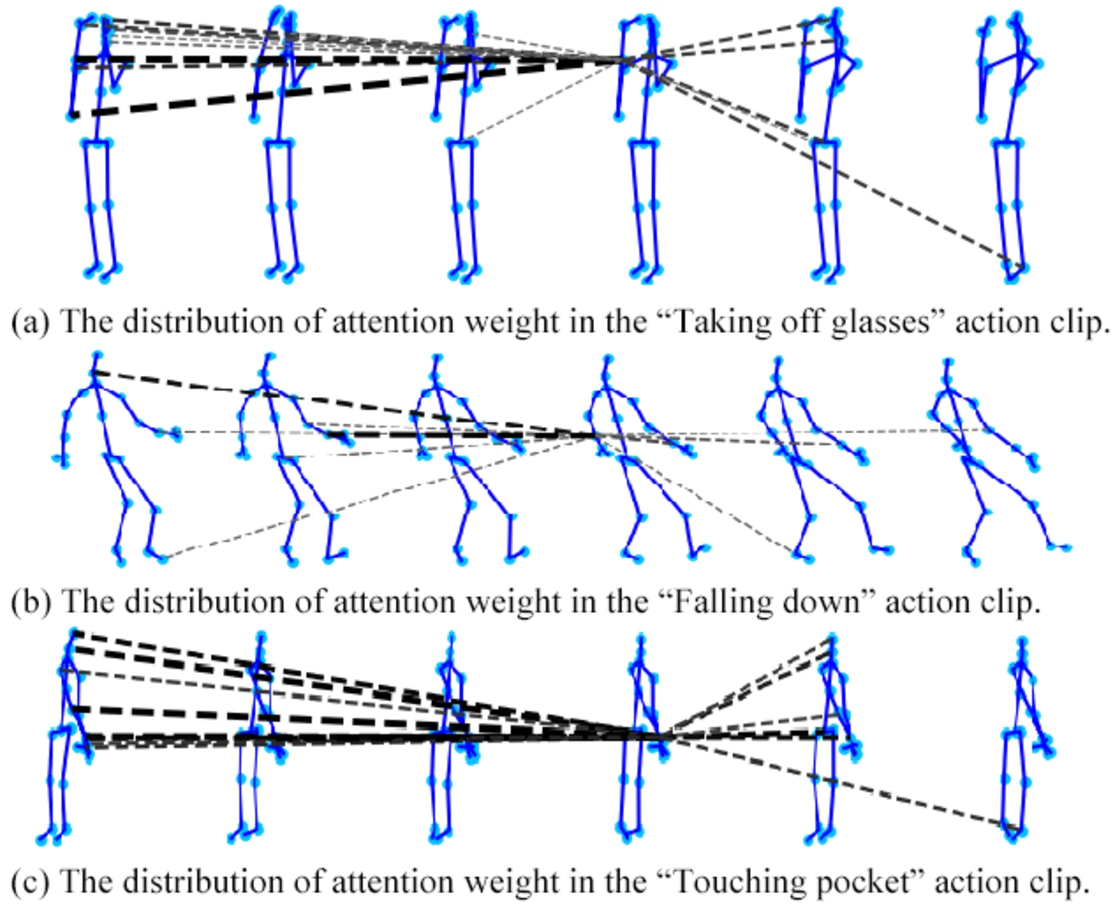
Attention distribution of certain joint points and others in different action sampling clips. The thickness and color depth of the dotted line represent higher attention scores. For the sake of simplicity, only lines with scores exceeding 0.7 are shown.
Despite the MAFormer exhibits commendable performance on the NTU-60, NTU-120, and N-UCLA datasets, these datasets are not without limitations or biases, for example, specific demographics, actions, or environmental conditions may not fully represent all real-world scenarios. In practical applications, the optimization of MAFormer model’s performance relies on video data captured from multiple perspectives by different cameras. For scenarios where multiple cameras cannot be deployed, data augmentation techniques can be used to simulate actions from different perspectives, thereby extending the model’s adaptability. Furthermore, the current implementation of MAFormer is restricted to the fusion of four streams, thereby leaving the potential advantages of incorporating additional stream combinations largely untapped. An exciting direction for future research is to replace certain modules in MAFormer with Vision Transformers (ViTs) or similar architectures, and apply the model to a broader range of tasks, such as scene classification and segmentation.
Conclusions
In summary, this study significantly contributes to the domain of human action recognition. The proposed MAFormer model, which is hierarchically structured and operates across spatial, temporal, and channel dimensions, fills critical voids in existing methodologies, especially in handling hierarchical information within action sequences. The novel employment of the CSA module for feature extraction and the FFN of MAA module enhances the model’s capacity to process multi-scale information, thus boosting its generalization performance. The integration of the RoPE within MAFormer noticeably strengthens the model’s extrapolation and generalization abilities, differentiating it from traditional approaches. Our extensive comparative experiments and evaluations unambiguously demonstrate MAFormer’s superiority over mainstream methods, highlighting its effectiveness in capturing local dependencies within action sequences more proficiently. By augmenting the understanding of correlations and structural complexities both within and among the features, MAFormer showcases its potential and superiority, achieving competitive performances against some state-of-the-art methods.
Footnotes
Acknowledgements
This work is supported by National Natural Science Foundation of China (62376286 and 62105038) and Research and Development Program of Beijing Municipal Education Commission (KM202211232001). We are grateful for the support of the organizations.