
Abstract
There is an increasing demand for high-quality translations in the realm of intelligent English translation. This paper optimized the traditional Transformer algorithm by enhancing position coding and the softmax layer. Bidirectional long short-term memory (BiLST) was employed to realize position encoding, capturing both contextual and positional information simultaneously. Additionally, the softmax function was replaced with the sparsemax function to obtain sparser results. The translation performance of some algorithms on Chinese and English datasets was compared and analyzed. It was found that that the optimized Transformer algorithm performed better than the RNNSearch, ConvS2S, and Transformer-base algorithms in terms of bilingual evaluation understudy (BLEU) score on the test set. It achieved an average BLEU score of 23.72, representing an improvement of 1.56 over the RNNSearch algorithm, 1.17 over the ConvS2S algorithm, and 0.73 over the Transformer-base algorithm. The parameter quantity of the optimized algorithm was 6.83 M, which was 0.05 M higher than the Transformer-base algorithm. Furthermore, its running time was 4,862.76 s, showing a marginal increase of 0.21% compared to the Transformer-base algorithm. These findings validate the reliability of the optimized Transformer algorithm for intelligent English translation and its potential practical application.
Introduction
With society’s continuous development and progress, there is an increasing demand for extensive cross-linguistic communication. Translation, as an indispensable part of cross-linguistic communication, has been the subject of in-depth study. However, traditional human translation is increasingly unable to meet the wide range of needs in terms of speed and cost. This has led to the emergence of computer-based intelligent translation as a key area of research. Intelligent translation can quickly complete the translation of large-scale cross-language materials [1], playing a crucial role in international communication, such as business translation and travel translation [2]. Consequently, improving the quality of translation has become an important task [3]. The significance of intelligent translation has led to extensive research on intelligent translation algorithms [4]. For instance, Pielka et al. [5] learned contradiction-specific sentence embeddings in German translation using a recurrent neural network (RNN), and their proposed method demonstrated good performance based on dataset evaluation. Vathsala et al. [6] implemented code-switching and transliteration based on a long short-term memory (LSTM) network for translating social media data. It was trained using 1 M data for transliteration and translation of Twitter data. Lee et al. [7] proposed a reinforcement learning-based attention mechanism to ensure translation quality and address latency issues in intelligent translation. They obtained better translation quality through experiments. Raju et al. [8] focused on parallel corpus building and the out-of-vocabulary issue in English-to-Telugu translation. They found that effective preprocessing improved the parameters of translation such as accuracy, perplexity, and bilingual evaluation understudy (BLEU) score. English, a widely used language worldwide [9], holds excellent application value in intelligent translation research. Therefore, this paper optimized the current Transformer algorithm for intelligent English translation, obtaining an optimized algorithm. The reliability of this method was demonstrated through experimental analysis, providing a new and effective approach for intelligent English translation. Furthermore, this research contributes to the theoretical directions for further exploration of the Transformer algorithm.
An optimized Transformer algorithm
Transformer algorithm
The Transformer algorithm employs the Seq2Seq architecture [10], where encoders are positioned on the left and decoders on the right. Each encoder consists of a multi-head self-attention layer and a feedforward neural network (FFN) layer. Residual connection and layer regularization are utilized. The decoder incorporates a masking operation to selectively conceal specific information from influencing parameter updates. The Transformer algorithm encompasses several pivotal components, which are outlined below.
(1) Attention mechanism
The Transformer algorithm uses an attention mechanism with Query-Key-Value, written as:
where
The Transformer algorithm combines multiple attention mechanisms, i.e., the multi-head attention mechanism, written as:
where
(2) Feedforward neural network
The FFN maps the results obtained from the multiple attention layers to a new space through a fully connected network, which can be regarded as two convolutional layers, and its computational formula is:
where
(3) Residual connection and layer regularization (Add&Norm)
Residual connection mitigates the problem of vanishing gradients, and layer regularization facilitates faster convergence. Their equations are:
where
(4) Position coding
The attention mechanism in the Transformer algorithm does not represent the positional information of the word, as the positional encoding needs to be added at the time of input. The calculation formula of positon coding is:
where pos is the word position and
Optimized position coding
In the Transformer algorithm, the position encoding lacks contextual information. To enhance the performance of English intelligent translation, this paper introduces an optimization technique for position encoding. LSTM is a special kind of RNN [11], which has a unique advantage in the capture of long-distance information, and it mainly realizes the information transfer through three gates.
(1) Forgetting gate: it determines what information needs to be passed or discarded:
(2) Update gate: it determines what information needs to be updated in the cell:
Then, the candidate cell is:
The updated cell is:
(3) Output gate: it decides the next hidden state. Its equation is:
Finally, the output of the hidden layer state at time
In the above equations,
Unidirectional LSTM can only process undirectional information, so when applied to location coding, it can only process preceding context. To capture contextual information at the same time, this paper uses a bidirectional LSTM (BiLSTM) [12], which realizes the integration of the position information and the contextual information. At time
As to BiLSTM-based position coding, the word vectors are taken as input sequences and fed into BiLSTM for training to get output vector
Optimized softmax layer
In the Transformer algorithm, a softmax layer is used in the decoder part to get the word with high probability as output:
To obtain a more sparse output, this paper uses the sparsemax function [13] instead of the softmax function:
Based on the sparse mix function, the output case of the decoder is computed:
where
In addition, for the softmax function in the attention mechanism, the same sparsemax function is used instead, i.e.,
Results and analysis
Experimental setup
The experiments were conducted on a Linux environment using Python 3.6 as the programming language and TensorFlow as the deep learning framework. The Chinese-English dataset from the WMT17 corpus was used for training, newsdev2017 was used for validation, and newstest2017, cwmt2018, and newstest2018 were used as the test sets. The data underwent various preprocessing steps, including cleaning, letter case conversion, word segmentation, and byte pair encoding (BPE) [14].
The proposed method in this paper was compared with the following intelligent translation methods.
(1) RNNSearch [15]: This method utilized 1,000 neurons in the hidden layer, 620 as the word embedding dimension, 5e-4 as the initial learning rate, a batch size of 128, and the Adam optimizer.
(2) ConvS2S [16]: The codec in this method employed 512 neurons in the hidden layer, 512 as the word embedding dimension, 0.25 as the initial learning rate, and a batch size of 64.
(3) Transformer-base [17]: It refers to the conventional Transformer algorithm utilizing identical parameter configurations as the optimized Transformer algorithm proposed in this paper.
Transformer algorithm parameter settings
Transformer algorithm parameter settings
The effectiveness of intelligent translation was evaluated based on BLEU [18]. BLEU is an algorithm based on the n-gram model. First, the n-gram of each sentence was computed. Correction precision
where Count is the frequency at which the n-gram appears in the model-generated sentences, and Max_Ref_Count is the maximum frequency at which the n-gram appears in the reference corpus.
BLEU is calculated by the following formula:
where
Figure 1 shows the improvement achieved by the optimized Transformer algorithm compared with the existing intelligent translation methods in terms of BLEU score.
According to Fig. 1, using the newstest2017 dataset, the BLEU score of the RNNSearch, ConvS2S, and Transformer-base algorithms was 22.21, 22.76, and 23.22, respectively. Among these algorithms, the Transformer-base algorithm demonstrated superior performance in intelligent translation. Additionally, the optimized Transformer algorithm proposed in this paper achieved a BLEU score of 24.08, exhibiting an improvement of 1.87, 1.32, and 0.86 compared to the previous three algorithms, respectively. Similarly, the optimized Transformer algorithm achieved the highest BLEU scores on the cwmt2018 and newstest2018 datasets. When comparing the average BLEU scores on the three test sets, the optimized Transformer algorithm outperformed the RNNSearch algorithm by 1.56, the ConvS2S algorithm by 1.17, and the Transformer-base algorithm by 0.73. These results confirmed the effectiveness of the optimized algorithm for English intelligent translation.
Then, comparative experiments were conducted on the optimized part, and the outcomes are presented in Table 2.
Comparative experiments for the optimized parts
Comparative experiments for the optimized parts
According to Table 2, in the part of position coding optimization, the Transformer-base algorithm adopting the original position coding achieved an average BLEU score of 22.99 on the test set. However, by switching to BiLSTM position coding, the average BLEU score improved to 23.67. This improvement of 0.68 indicated that BiLSTM performed better in position coding and effectively utilized contextual information, resulting in improved translation quality. Moving on to the softmax optimization part, the Transformer-base algorithm adopting the softmax function yielded an average BLEU score of 22.99 on the test set. However, by implementing the sparsemax function instead, the score increased to 23.26. This improvement of 0.27 suggested that utilizing the sparsemax function enhanced the sparsity of results during probability normalization, thereby effectively enhancing translation quality.
Finally, the effect of the optimized Transformer algorithm on the parameter quantity and running time was compared (Table 3).
Comparison of parameter quantity and operation time
Comparison of BLEU score between various algorithms on the test set.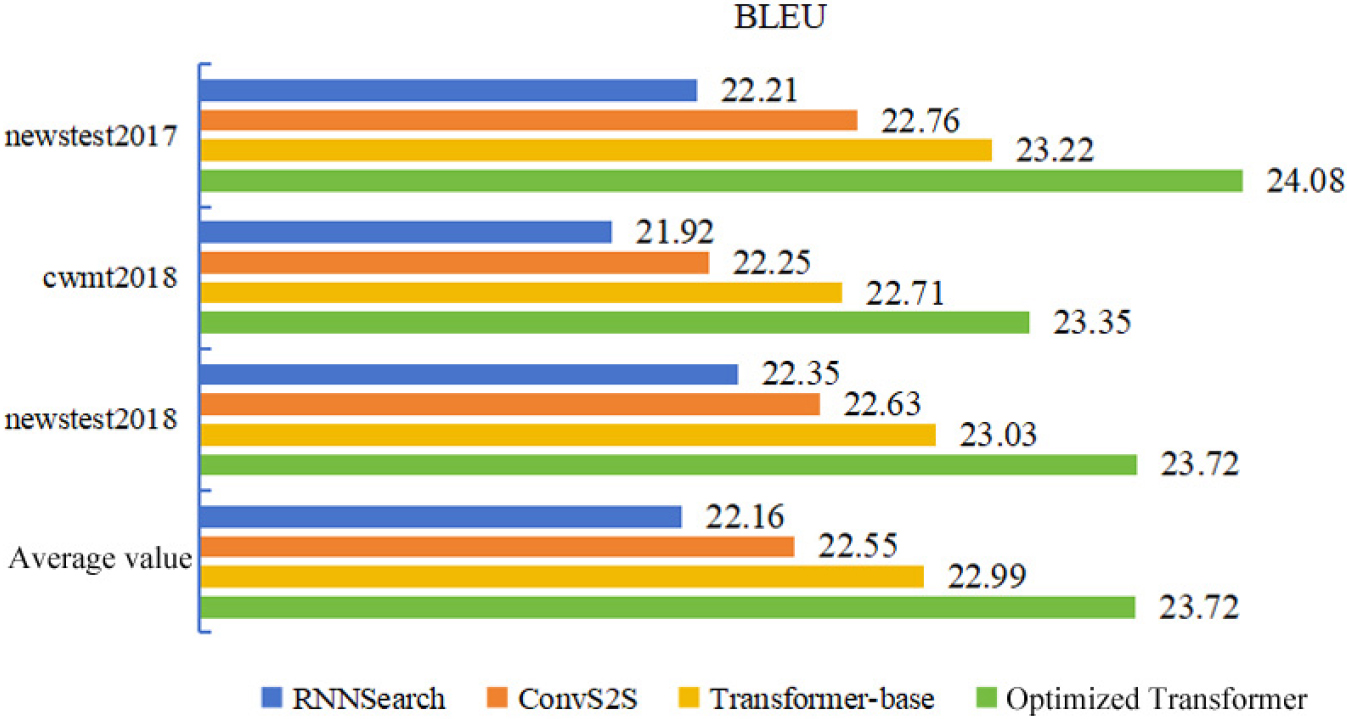
According to Table 3, the parameter quantity of the optimized algorithm was 6.78 M, which was 0.05 M higher than the Transformer-base algorithm (6.78 M). It indicated that the improvement had a small increase in the parameter quantity. The average running time of the Transformer-base algorithm for the test set was 4,852.33 s, whereas the optimized Transformer algorithm had an average running time of 4,862.76 s, showing an increase of 10.43 s compared to the former. These results indicated that the optimized algorithm slightly increased the overall running time. However, considering the BLEU score, the optimized Transformer algorithm not only increased the parameter quantity by 0.05 M and the running time by 0.21% but also brought a significant improvement of 3.18% in the BLEU score. Overall, it demonstrated excellent performance in English intelligent translation.
This paper focuses on optimizing the traditional Transformer algorithm in terms of position coding and the softmax layer to obtain an optimized Transformer algorithm. Comparative experiments found that the optimized Transformer algorithm outperformed the RNNSearch, ConvS2S, and Transformer-base algorithms on the test set, achieving an average BLEU score of 23.72. Despite a slight increase in parameter quantity and running time, it did not significantly add to the computational burden. Therefore, the optimized Transformer algorithm is promising for practical applications in intelligent English translation and provides a novel reliable approach for intelligent English translation. This work provides theoretical support for better application and optimization of the Transformer algorithm in the field of intelligent translation. However, the present study also has some limitations, such as only considering intelligent translation between Chinese and English and lacking analysis of the algorithm’s translation performance on longer texts. In the future, there will be experiments on intelligent English translation in more languages to understand the applicability of this method. Further research will also be conducted on translating longer texts. Additionally, lightweight design considerations for the algorithm are needed to ensure translation performance while reducing complexity and improving computational efficiency.