
Abstract
The study proposes a new algorithm combining a gradient boosting tree algorithm with a hybrid convolutional neural network in order to design a better human resource recommendation algorithm to solve the problem of employment difficulties and recruitment difficulties. The algorithm combines the excellent feature transformation ability of gradient boosting trees with the excellent classification ability of hybrid convolutional neural networks, complementing the shortcomings of each of the two algorithms. The outcomes showed that the algorithm performed best with the learning rate set to 0.3 and the maximum tree depth set to 3. The algorithm now has the lowest loss percentage and highest F1-Score value. The maximum-median hybrid pooling approach used in the study had considerable improvements over the algorithm’s pooling strategy (PS), and it had the greatest recall and F1-Score values of all pooling strategies (0.8108 and 0.7418, respectively). The new algorithm outperformed the gradient boosting tree algorithm and the hybrid convolutional neural network algorithm in terms of recall and F1-Score values, and regardless of the length of the job recommendation, the recall and F1-Score values of the new algorithm were consistently higher than those of the old algorithm. The recall and F1-Score values of the new algorithm, with a job recommendation length of 70, were 0.8198 and 0.7432, respectively, both greater than those of the other algorithms, according to a comparison of it with other conventional HR recommendation algorithms. The study’s newly created algorithm increases the efficacy and precision of HR suggestions.
Keywords
Introduction
As networking and information technology continue to advance, more and more businesses are preferring to hire new employees through online recruitment, which is resulting in a gradual digitization of HR recommendations. Today there is no shortage of online recruitment networks, both domestic and foreign, and these networks are based on the networking of recruitment and employment activities that consider information on employment collection, job information recommendations and the intention of the employed. With the increasing digitisation of employment networks, the number of daily activities on these employment sites continues to break new highs, and the amount of information data that employment networks need to collect and process is exploding. When the data information was less, HR network recommendations, with keyword search, or job classification, could complete the job recommendation work. However, with the overload of information, traditional recommendation methods have been unable to meet the needs of HRs recommendations, and the HRs market gradually emerged as a problem for enterprises to recruit people, while there are still problems in society to find a job. The main reason for the emergence of these contradictory problems is the imperfection of the HR recommendation mechanism. Enterprises do not see the talents they need in the recruitment network, and employed people do not see the recruitment information of their preferred enterprises in the recruitment network, therefore. The strain to find employment in the talent market can be significantly reduced by developing an effective and accurate HR recommendation system [1, 2]. An approach for neural network learning that has recently gained popularity is the convolutional neural network (CNN). Therefore, the study proposes a gradient boosting tree technique, combined with CNNs, to design an algorithm suitable for HR recommendation, to achieve efficient and accurate HR recommendation and alleviate the employment pressure in the job market. The first part is a review of the current state of research on HR recommendation and CNNs at home and abroad. The second part is a study of HR recommendation algorithms, which is divided into two subsections. The first subsection is the collection and processing of HR data, and the second subsection is the design of recommendation algorithms based on hybrid CNNs (HCNN). The third section is an experimental validation of the algorithm designed by the study. The fourth section is the overall summary of the article, describing the results achieved and the shortcomings of the research.
Related works
Excellent HR recommendations can help solve the current dilemma in the job market. To address the issue of data loss in the HR recommendation process, which results in shorter real recommendation resources with fewer information, Z Liu et al. developed an HR recommendation method based on improved frequent itemset mining. The outcomes demonstrate that the method suggested by the authors has the greatest information and the longest recommended resources [3]. When learning the connections between previous users, S Ajoudanian et al. suggested a fuzzy C-mean clustering approach to address the sparsity issue brought on by the lack of collaborative filtering procedures. The outcomes demonstrate that the strategy can produce more individualised recommendations utilising fuzzy logic [4]. T Tao et al. propose an approach using crowdsourced annotations to label training samples in order to solve the problem of supervised learning recommendation models where machine annotation cannot complete high treatment annotated training samples. The approach uses a crowdsourcing mechanism to create a crowdsourced annotation-based training sample labelling task, and then uses two entropy-based ground truth inference algorithms to achieve quality improvement of the crowd-provided noisy labels. The outcomes demonstrated that the method can greatly raise the quality of machine annotation [5].
Sonal Pramod Patil et al. proposed to improve the HCNNs in order to help users identify forged images or video screens in the network. The results showed that the algorithm showed an accuracy of up to 98% on both the test and validation sets [6]. D Daimary et al. designed a new segmentation technique to design an efficient and accurate brain tumour segmentation technique using HCNNs for image segmentation and classification tasks, and the simulation test results of the technique showed higher accuracy [7]. Y Zhang et al. proposed a HCNN algorithm for powder bed fusion in order to solve the learning of extraction of spatial and practical features in the original image, and the results showed that the method can save the processing steps of the image and simplify the process of feature extraction [8].
In summary, HR recommendation technology is now facing problems of recommendation length, quality of recommended information and the amount of information contained in the recommended content, all of which are waiting to be solved. HCNNs are an excellent classification technique that has emerged in recent years. The essence of HR recommendation is the problem of classifying various kinds of information, so the research proposes an algorithm based on HCNN and uses it in the study of HR recommendation.
HCNN-based HR recommendation research
The main content of this chapter, which is a study of HCNN-based HR recommendation algorithms, is divided into two subsections. The first subsection is the collection and pre-processing of HR data, and the study uses streaming distributed data collection techniques, while the second subsection is the design of an HCNN-based HR recommendation algorithm.
Streaming-based distributed HR data collection
The data is collected and processed and can be used for the training of algorithmic models. The data collected for the study will be divided according to the source. When the amount of data information is too large, efficient and high-quality data information collection can help the algorithmic model to improve training optimisation faster. The HR data collection for the study is distributed, and the method can take advantage of the high concurrency of cloud clusters to achieve high quality data collection and improve the availability of the data for subsequent pre-processing. And the method can increase the queue of data collection tasks by adding sub-servers. The flow of streaming distributed data collection is shown in Fig. 1 [9, 10].
Flowchart of streaming distributed data collection.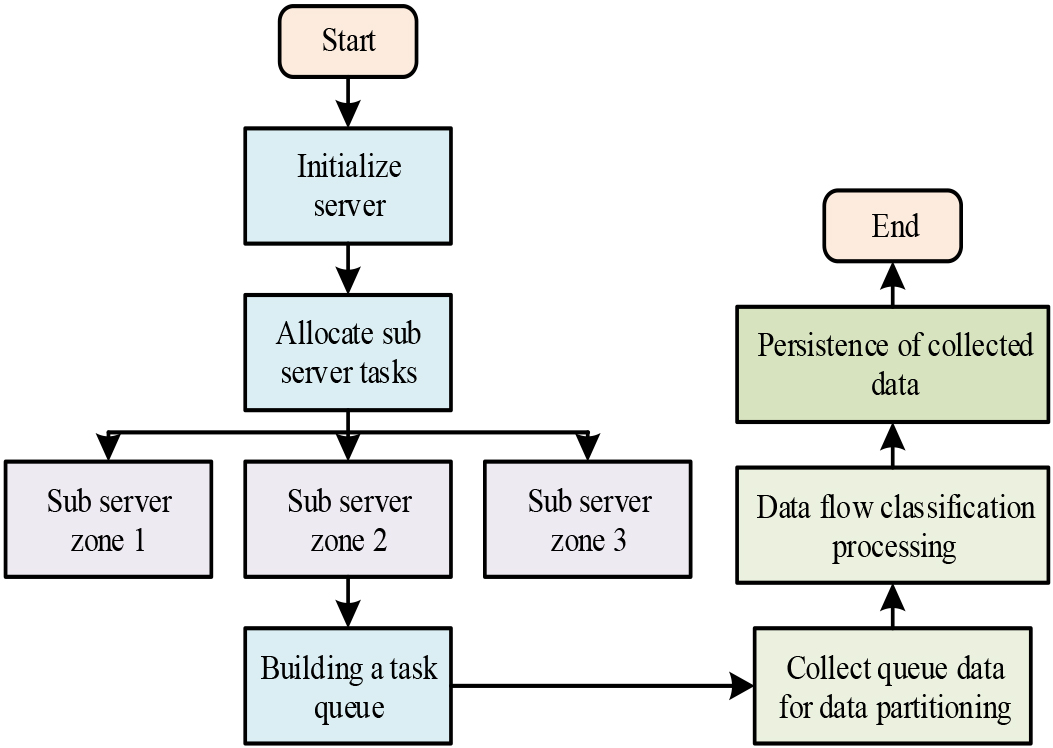
The streaming distributed data collection process is divided into four main steps. Firstly, the cloud cluster server is initialised to distinguish between the main server and the sub-servers. Second, the sub-servers are zoned to distinguish data information from different sources and to create a partitioned collection task queue. Third, through the master server, the sub-server data collection bio-queue is partitioned. The interval of information processing time is used as a criterion to classify the data and create many micro-batch tasks by batching them within a certain period. Fourthly, the primary server runs batch jobs in parallel to partition the data into corresponding data streams. A dataset of unprocessed data is then created after the data has been sorted and saved according to how much memory they take up. This collection method integrates data aggregation and data classification. Streaming distributed data collection requires identification of the source of the data and the classification of the required data by type of source. The main server aggregates the data in multiple threads simultaneously, while the sub-servers queue up the different types of data to be collected. The sub-servers complete the collection of different data at the same time as they complete the collection of the classification of the data and update it in real time. The design of this data collection method is shown in Fig. 2.
After completing its own data collection volume, the sub-server will process the tasks in batches through streaming and the data information is sent to the main server. The master server then performs a categorisation and storage operation on the data stream based on the amount of memory occupied by each batch task. The design of the categorisation process is shown in Fig. 3.
Design diagram for constructing and categorizing task queues in data collection partitions.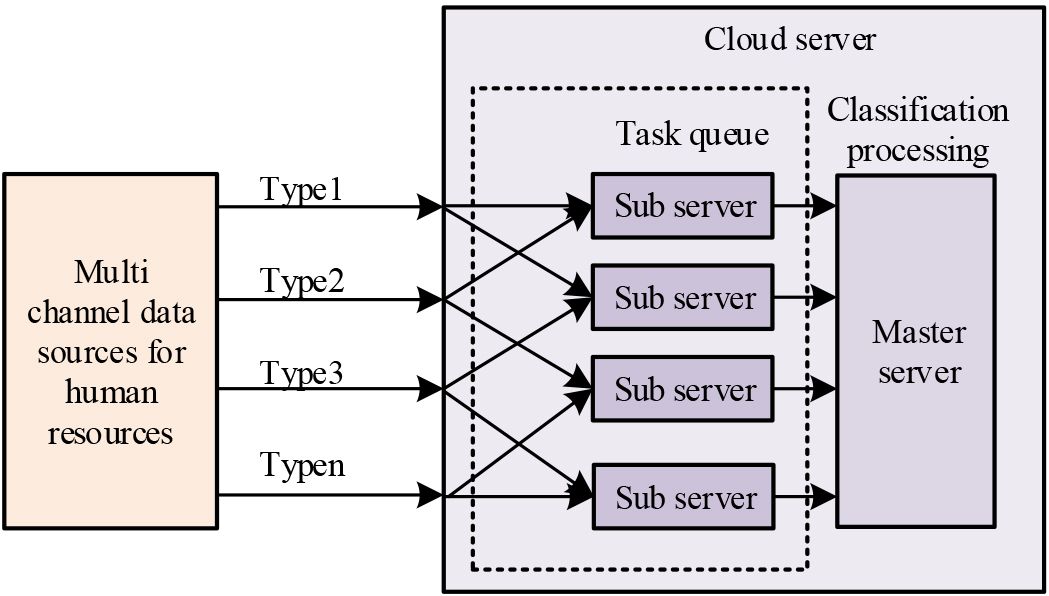
Design diagram for data stream classification processing.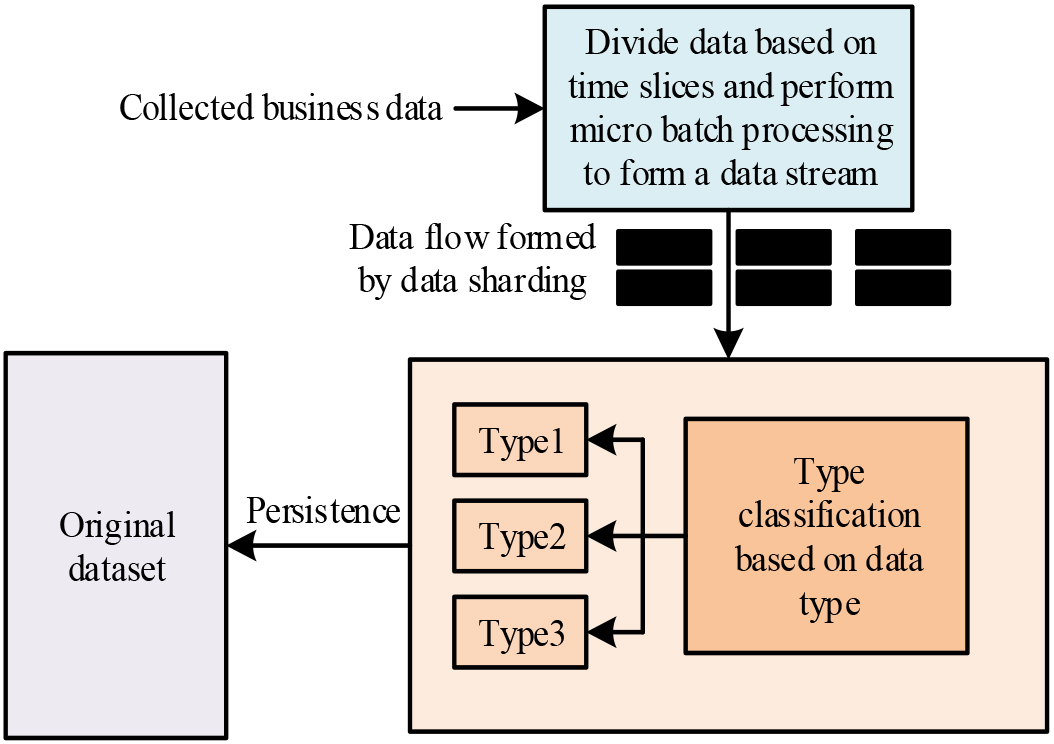
Three categories can be made out of the study’s data collection. The fundamental data of job searchers falls under the first category and includes contact details, residential address, gender, age, length of employment, and anticipated salary. The second category is basic information on job requirements, including job content, job nature, work experience requirements, salary range, job views, working hours, contact details of the person in charge, etc. The third category is the behavioural information of job seekers, including the time period when people look for job information and browse job information. These data can better reflect the various needs of job seekers and recruitment companies, but these directly collected data cannot be directly used for direct training of the algorithm model. The original data set also has many information anomalies and requires data pre-processing before it can be used for training of the model. Problems with the original dataset generally include duplication, invalidation, and missing information. The main reason for duplicate information is that companies usually publish job information in multiple channels, which may lead to slightly different requirements and treatment for the same position due to different publishing channels and different publishing times. Therefore, when classifying the data collected, the data from the same channel for the same job can be eliminated and only the latest data can be retained. This operation will reduce the redundancy of the data information. Invalid information is a problem with the data filled in by the person filling in the data, perhaps because they did not pay attention to the requirements or did not understand the content of filling in the data, so the content can be added or removed. In addition to the above problems, the HR data collection process also collects some useless information, which increases the noise of the training set of the model and needs to be eliminated; the data collected by HR also has the problem of differentiating the text format, which needs to be standardised to increase the training accuracy of the model [11, 12].
The traditional recommendation algorithm leads to low quality of recommended content due to insufficient feature extraction capability, so the study proposes to use boosting tree theory for data feature extraction, and then use CNN to complete HR recommendation. The boosting tree can increase the performance of the model by integrating the data, and can also filter the features of the input data and eliminate the useless features in it. Compared with the original features, the CNN can better process these input features after the boost tree transformation process and improve the quality of subsequent HR recommendations. The flow of boosted tree transformed features is shown in Fig. 4 [13, 14, 15].
Process flow of lifting tree feature transformation.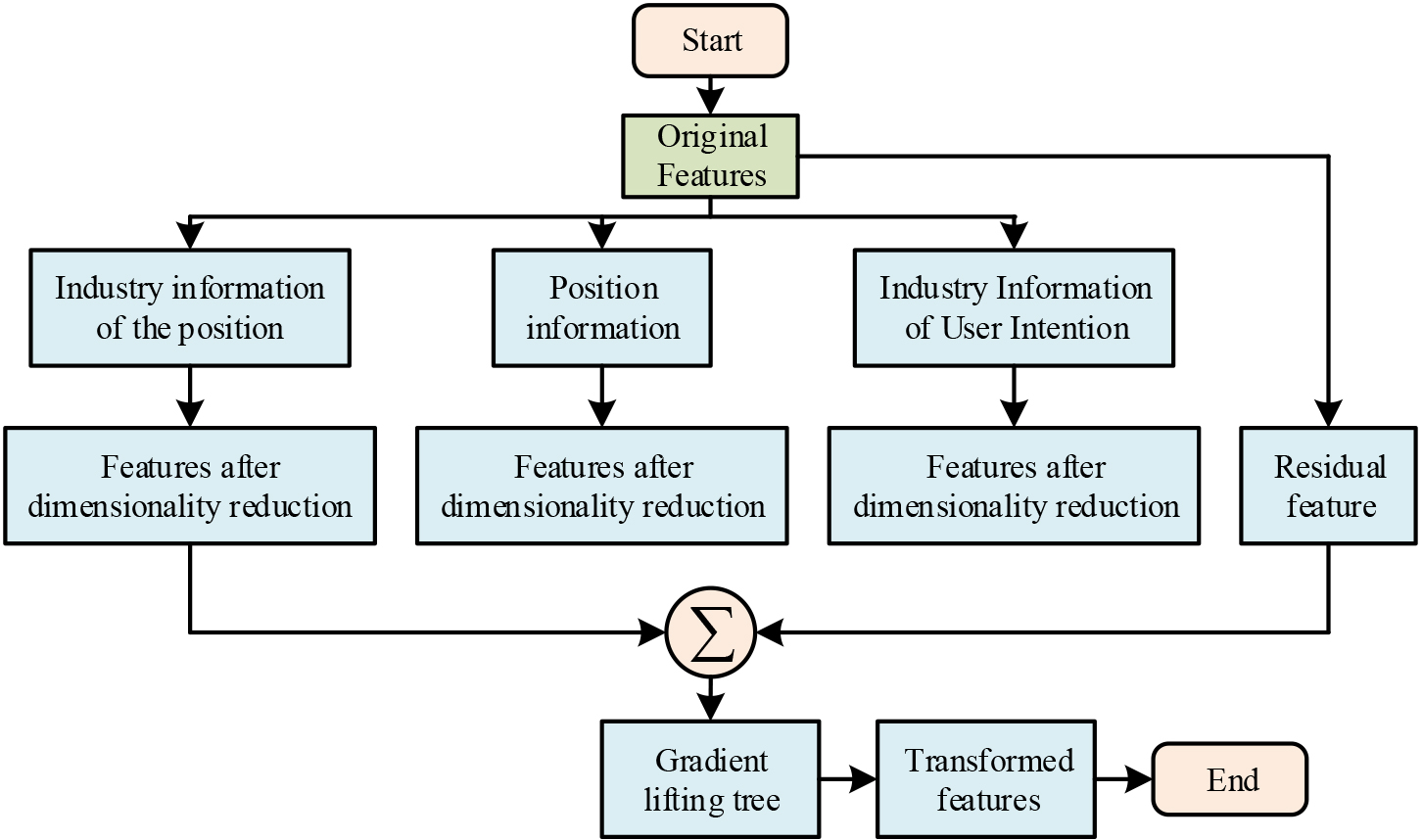
The study completed the pre-processing of the data at the acquisition stage of the data, where the data information was categorised and stored in advance, and the pre-processing has been hot-coded for all types of data. After the hot-coding process, the dimensionality of the single-attribute data will have the problem of dimension doubling, resulting in too high dimensionality, which is not conducive to the simulation training of the algorithm. Moreover, hot coding retains more decimals and does not utilise the feature conversion operation, which can mislead the conversion operation of the feature conversion model and divide the redundant branches. Therefore, before feature conversion, the pre-processed data needs to be dimensionalised, and the dimensionality reduction process studied is shown in Eq. (1).
In Eq. (1),
Feature conversion flowchart.
In the transformation process of the data features, it is necessary to combine the features after dimensionality reduction, with the remaining types of features for the feature transformation process of the lifting tree model, the stitching method is shown in Eq. (2).
In Eq. (2),
Structure diagram of mixed CNN.
The cross-entropy loss function, which is presented in Eq. (3), is used to train the HCNN and assess the model’s training correctness.
In Eq. (3),
In Eq. (4),
In Eq. (5),
In Eq. (6),
In Eq. (7),
In Eq. (8),
In Eq. (9),
The quality of the feature representation information can be enhanced by using this function as the model’s AF. Additionally, the function has stronger noise immunity, which can aid the model in performing the classification more effectively. The model’s pooling layers all employ the same pooling approach, which may result in the loss of feature data. To avoid the loss of characteristic information problem, the study suggests choosing a combination of two pooling algorithms to create a hybrid PS. Equation (11) represents the maximum pooling technique, in which the maximum value in the pooling region is chosen as the pooling feature.
In Eq. (11),
In addition to the two pooling strategies mentioned above, there is also an intermediate value PS, and the expression of which is given in Eq. (13).
To create a hybrid PS, the highest value PS and the middle value PS are chosen. The hybrid PS can take into account both the significant features and the weaker features in the pooled region, and reduce the loss of feature information. In order to address the situation that the cross-entropy function can lead to the model’s under-training whose expression is given in Eq. (14).
In Eq. (14),
The algorithm must first be put into practise before it can be experimentally verified. This section is the experimental verification analysis, which is divided into two subsections, the first for the experimental verification of the adjustment and optimisation of the model, and the second for the experimental verification of the feasibility of the algorithm.
Experimental validation of model adjustment
Positive and negative samples were used to divide the data into two categories in the study. 90% of the collected data was utilised as the training set for the model and 10% as the test set, and the algorithm was built and experimentally validated based on Keras version 2.0.8. The experimental results of tweaking the LR are displayed in Fig. 7.
Figure 7a shows the results of comparing the loss of different LR parameters. With a LR of 0.4 for up to 42 iterations, the lowest loss was attained. The loss is lowest with a LR of 0.3 for iterations over 42. No matter how many iterations there are, the loss is always the highest at a LR of 0.007. The comparative findings for the F1-Score for various LRs are shown in Fig. 7b. The F1-Score value grows as the LR increases and the loss degree keeps lowering when the LR is less than 0.3. When the LR exceeds 0.3, the F1-Score value of the model begins to decline as the LR rises. The model’s loss degree was minimised and the F1-Score value was 0.7301 at a LR of 0.3. Figure 8 displays the outcomes of the maximum tree depth tweaking experiment.
The comparison of the loss of parameters with various maximum number depths is depicted in Fig. 8a. The model converged at 80 iterations, with a loss of about 0.88. The maximum loss was achieved with a parameter setting of 5, and the minimum loss was about 1.17. Figure 8b shows the F1-Score comparison results for different maximum tree depths. When the parameter is set to 3, the F1-Score value is the highest and the model has the lowest loss. Currently, its F1-Score value is 0.7305. The results of the PS optimisation validation are shown in Table 1.
LR optimization experiment results.
Experimental results of different pooling strategies
Results of the maximum tree depth optimization experiment.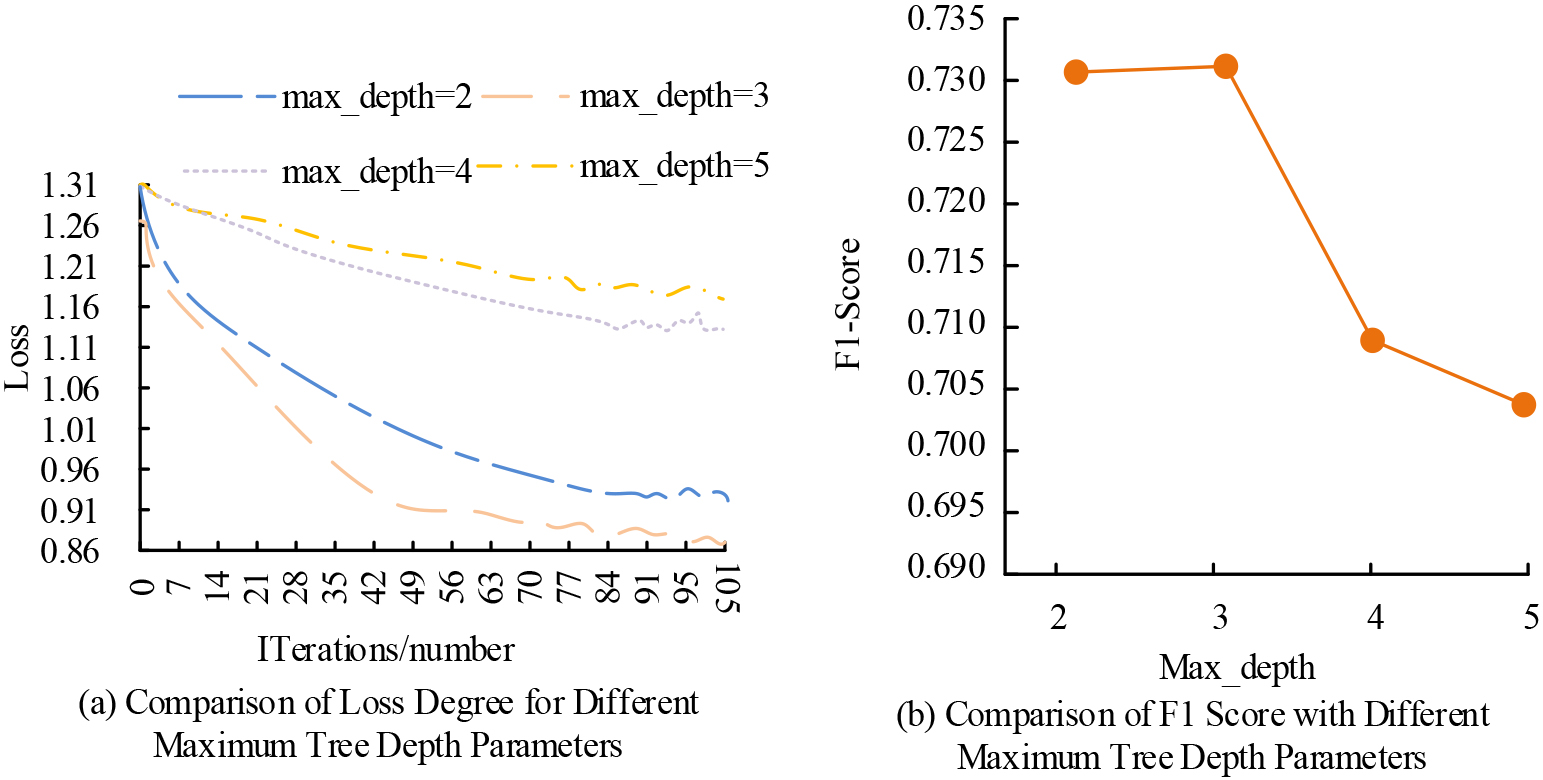
Experimental verification results of loss function improvement.
As can be seen in Table 1, the maximum-median hybrid PS has the highest recall and F1-Score values. With a recall of 0.8108 and an F1-Score of 0.7418, the mean PS had the lowest recall and F1-Score values of any pooling strategy. The F1-Score value was 0.7334 and the recall rate (RR) was 0.7857. The study was effective in optimising the PS. The experimental validation results for the improvement of the loss function are shown in Fig. 9.
The recall outcomes of the model before and after the modification are contrasted in Fig. 9a. The improvement of the loss function had basically no effect on the recall of the model when the job recommendation length was 20 and before, and as the job recommendation length continued to increase, the advantages of the study on the improvement of the loss function gradually manifested. The comparison of the model’s F1-Score before and after the modification is shown in Fig. 9b. Regardless of the length of the job recommendation, the improved model’s F1-Score is consistently a little higher than it was before the improvement.
Performance comparison of three algorithms.
Performance comparison between research design algorithms and traditional recommendation algorithms.
The algorithm studied is a combination of gradient boosting tree and HCNN algorithm. Therefore, the study evaluated the algorithm experimentally with the gradient boosting tree algorithm and the HCNN algorithm in order to confirm the programme’s viability. The findings are displayed in Fig. 10.
Figure 10a shows the results. The algorithm’s RR proposed by the study is always higher than that of the other two algorithms, regardless of the post recommendation length. The difference between the RR of the algorithm designed by the study and the RR of the other two algorithms reaches its maximum when the post recommendation length is after 30. At a post recommendation length of 70, the difference in recall with the gradient boosting tree algorithm is 0.0521 and with the HCNN algorithm is 0.0586. Figure 10b shows the F1-Score comparison results of the three algorithms. The difference with the gradient boosting tree algorithm was 0.0540 for a job recommendation length of 70 and 0.0192 with the HCNN algorithm. finally, the study compared the algorithm with currently used HR recommendation algorithms, and the results are shown in Fig. 11.
Figure 11a shows the results of the algorithm recall comparison. The RR of the research-designed algorithm is always higher than its counterpart, regardless of the post recommendation length. The recall of the research-designed algorithm is 0.8198 for a job recommendation length of 70, while the recall of the rest of the algorithms is 0.6832 currently. Figure 11b shows the results of the algorithm F1-Score comparison. The F1-Score value of the research design algorithm is also always higher than the rest of the algorithms, with the F1-Score value of the research design algorithm being 0.7432 at a job recommendation length of 70 and the highest F1-Score value of the rest of the algorithms being 0.6584.
Conclusion
The study proposes a gradient boosting tree algorithm, which is a new algorithm combined with the HCNN algorithm, for attempt to address the issue of current HR recommendation algorithms, poor recommendation quality and untimely recommendation information. The algorithm uses the boosted tree algorithm to perform data feature transformation, which makes the classification of HCNN algorithm more accurate and efficient. In line with the findings, the algorithm performed best when the LR was 0.3, having the greatest F1-Score value of 0.7301. When the maximum tree depth was set to 3, the algorithm’s F1-Score value was the highest, coming in at 0.7305. The study was effective in optimising the PS, and the algorithm with the optimised PS had the highest recall and F1-Score values of 0.8104, 0.7414 respectively, the study’s improvement of the loss function was effective in general, and the algorithm with the improved loss function had slightly higher recall and F1-Score values than before the improvement. The recall and F1-Score values of the research design algorithm are higher than the rest of the algorithms, and the recall and F1-Score values of the research design algorithm are 0.8198 and 0.7432 respectively for a post recommendation length of 70. The research design algorithm combines the advantages of the HCNN and gradient boosting tree, and complements the shortcomings of each, so that the quality of the algorithm’s HR recommendation has been improved to a certain extent, but the study is not significant in improving the loss function of the algorithm, which can be replaced with a loss function with better effect, and still needs to be optimized.
Footnotes
Fundings
The research is supported by: This article is the 2023 Human Resources and Social Security Research topic in Hebei Province: Research on the Establishment of Talent Evaluation System for Universities in Hebei Province (Project number: JRSHZ-2023-02264) achievements.