
Abstract
Feature elimination happens because either the features are irrelevant or they are redundant. The major challenge with feature selection for clustering is that relevance of a feature is not well defined. In this paper, an attempt to address this gap is made. Feature relevance is firstly defined in terms of Variability Score (VSi), a novel score which measures a feature’s contribution to the overall variability of the dataset. Secondly, feature relevance is evaluated using entropy. VSi is a multivariate measure of feature relevance, where as entropy is univariate. Both of them have been used in a greedy forward search to select optimal feature subset (FSELCET –VS, FSELECT –EN). Redundancy is handled using Pearson’s correlation coefficient. Dataset characteristics also influence result. Therefore it is recommended to apply both and adopt the best for that particular dataset. Extensive empirical study over thirty publicly available datasets show that the proposed method produces better performance compared to a few state of the art methods. The average feature reduction produced is 44%. No statistically significant reduction in performance (t = –0.35, p = 0.73) when compared with all features was observed. Moreover, the proposed method is shown to be relatively computationally inexpensive as well.
Introduction
Feature selection is one of the most important preprocessing steps in data mining and knowledge engineering. The basic objective of feature selection is to remove irrelevant and redundant features. Let ‘S’ be the set of ‘n’ features given as (f1, f2, …… …… , fn), ‘b’ be the number of features to be selected (b < n), let ‘B’ (B1, B2, …… …… , Bnb) denote the set of all possible subsets with ‘b’ features, from the set of ‘n’ features and let nb = C (n, b) represent the cardinality of “B”. Therefore, the problem of feature selection can be stated as finding B0 such that J (B0) ≥ J (B i ) ∀ Bi ∈ B. This definition assumes that the number of features to be selected is known. ‘J’ may be any evaluation measure of feature subset quality. Feature selection is also known as variable selection, attribute selection or variable subset selection.
Feature selection offers the following few benefits [1–3]
(i) Better model understandability and improved visualization
Visualization is meaningful when there are two or three features. In case of more number of features, combination of two or three features from the available features may be used for visualization. With reduced feature subset, number of such combinations reduces significantly. Also with lower number of features, the comprehensibility of the model increases.
(ii) Generalization of the model and reduced over fitting
With removal of redundant, irrelevant and noisy features, the model become generalized and over fitting is reduced. Usually this results in better performance of the model.
(iii) Efficiency in terms of time and space complexity
Both training and execution time is improved with the reduced number of features. Understandably, the data collection effort and data storage cost are also reduced.
Because of the above mentioned merits, feature selection has many applications in medical science [5], banking and finance [6], power sector [7], software engineering [8], spectroscopy [9], hypertension diagnosis [10] etc. In this context, it is worth mentioning that dimensionality reduction (Principal Component Analysis, Singular Value Decomposition, and Factor Analysis) is an alternative way of reducing the size of the problem. However as observed in [2] and [4], the semantics of the features are lost when they are transformed through projections. Consequently, it becomes difficult to incorporate domain knowledge of the features while building the model. It may be noted, subspace clustering [36], is another approach of handing the problem of dimensionality reduction.
Feature selection happens by elimination of redundant and irrelevant features. The concept of relevance or importance of a feature is well defined in case of a supervised problem and is typically assessed by some measures of association between the features and the target variable. But, absence of the said target variable, in case of unsupervised tasks, makes the feature selection process much more complex, and hence an open problem [31].
In this paper, a measure named as variability score (VSi) for feature relevance has been proposed based on variability of the overall dataset measured in terms of the eigen values and eigen vectors. VSi has been used in a greedy forward search (FSELECT-VS) setting to produce an optimal feature subset. VSi is a multivariate measure as the relevance of a feature increases with its’ ability to explain the overall variability of the dataset. Recent researches [34, 35] emphasize the role of dataset characteristics in choosing a feature selection method. Therefore to make the proposed approach more generic the entropy of the feature which is a univariate measure is also used in a greedy forward search setup (FSELECT-EN), and finally it is recommended to apply both of them and select the method which produces better result for that particular dataset. Inter feature correlation has been considered to restrict inclusion of redundant features in both the approaches.
The organization of the paper is as follows: In Section II, a brief outline of feature selection methods is provided with a short review on feature selection methods for clustering. The proposed feature importance score named as variability score, and its empirical properties has been proposed and discussed in Section III. The greedy forward search algorithms using variability score and entropy have been explained in Section IV. Section V, describes materials and methods for the experimental setup. Section VI presents the results and discussions of the experiments. Section VII, summarizes the paper with concluding remarks and future scope of work.
Feature selection
Feature selection is a widely researched area. There are numerous proposals of feature selection methods in last three decades. A feature selection method can be categorized by answering the following questions. a) What approach is being used? b) Whether the method is for a supervised task (Classification) or an unsupervised task (Clustering)? c) How the feature subset reduction is achieved and d) what kind of output the feature selection method produces?
Approach
As noted in [2–4, 9] there are four standard approaches or core philosophies of building a feature selection approach, which may be described as follows:
Supervised or unsupervised
Unsupervised tasks are undoubtedly more challenging compared to supervised tasks [13]. As a result, feature selection has also been very clearly defined for classification or supervised tasks. Feature selection generally embraces the following two principles [14]. Relevance of a Feature: If a feature is relevant, then it has a strong influence on the class separability. As previously described, this particular aspect is not well defined for clustering. Redundancy of a Feature: A feature is redundant, if variability of the feature is explained by any other feature or combination of features.
Subset reduction technique
The basic strategy of feature selection will start with the simple assumption that the features are independent of each other. In this case, the features are ranked according to various properties of the features like correlation, fisher score, mutual information etc. (For Classification). These methods can be considered as univariate as they consider all features independently.
Alternatively, search based strategies can also be used for feature selection. An exhaustive search is computationally prohibitive. Other variants like greedy (both sequential backward or forward), simulated annealing, hill climbing etc. are used for better computational efficiency. Evolutionary algorithms like genetic algorithm (GA) have also been used to prune the search space [16, 20]. In case of filter techniques, the merit or quality of a feature subset is evaluated by measures like CFS (Correlation based feature selection) [17] or mRMR (minimum redundancy maximum relevance) [18]. A feature selection approach based on search generally has the following steps [1, 19]. Selection of initial set of features. Generation of next set of features. Evaluation criteria for the feature subsets (How good that particular subset is?). Stopping Criteria.
Feature selection through clustering deserves a special mention, where each feature is represented by some of its property (mostly statistical properties or meta features) and then they are clustered. Subsequently a representative feature is selected from each of the feature clusters. Feature clustering provides a better computation complexity because clustering, is not as involved as search [20, 21]. Another alternative approach of non-search based techniques is graph based techniques, where a dense sub graph indicates group of correlated features [22].
Output
As briefly described in Section 2.3, the feature selection method will either produce a score for each feature and a ranked list, or it can also produce an optimal subset. Few of the methods may produce a number of optimal subsets with a ‘goodness of fit’ measure of feature subset quality. Whichever approach may be followed, all of them need to deal with the question of feature subset cardinality. For determining the number of features there can be several strategies. It can be selected [19], either as an absolute number, or as a fraction of total features or as a threshold value of an evaluation measure. Number of features to be selected can also be determined based on the gradient of any evaluation measure.
Important dimensions of feature selection methods as discussed above are depicted in Fig. 1.
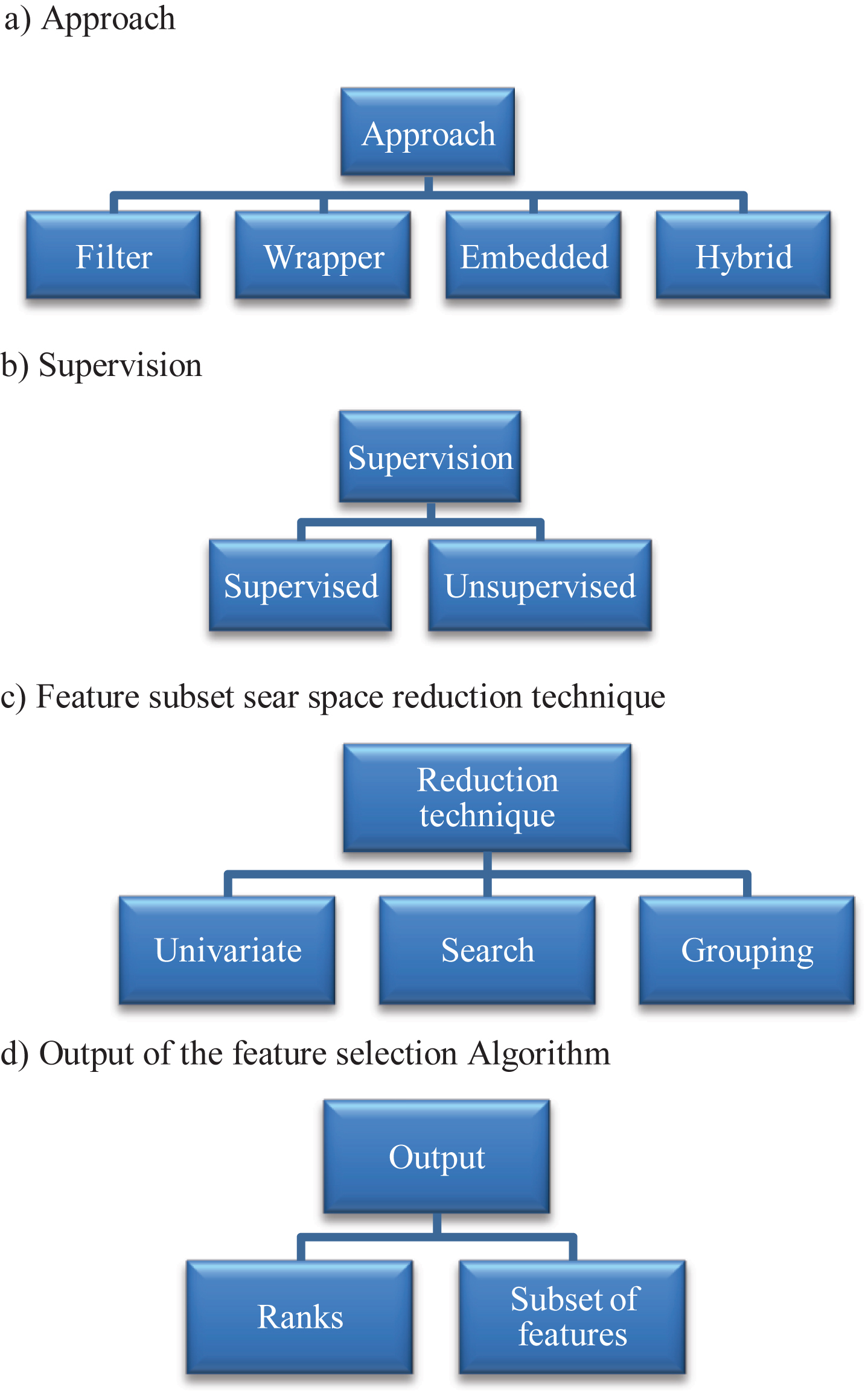
Feature selection method characteristics.
Clustering can be thought of as a task of dividing n-objects in k-groups such that clusters are well-formed, i.e. i) similarity between the items within a cluster (Cohesion) is very high and ii) similarity between items of different clusters is very low (Separability).
In the paper [23], a novel feature selection method named principal feature analysis (PFA) is proposed, where features are represented in terms of their contribution to the principal components and then subsequently features are clustered into ‘k’ groups. The value of ‘k’ depends on the proportion of variability that is to be retained. In a well cited work [20], the authors have defined a measure of association based on linear dependency named as Maximal Information Compression Index (λ2) which is calculated by determining the smallest eigenvalue of Σ, where Σ denotes the correlation/ covariance matrix. The value of λ2 is zero when the features are linearly dependent and increases as the amount of dependency decreases.
Finally, all features are expressed in terms of λ2 with remaining features. Next, clustering is performed on the features to pick the best features. One representative feature from each cluster is picked subsequently. Generally this is either the cluster center or the feature closest to the cluster center. In paper [21], authors carry out feature selection for clustering in the domain of bioinformatics using feature clustering. It is also based on the same feature similarity measure as proposed in [20].
In one of the earliest works in feature selection for clustering authors have used an entropy based method [24]. The score for each feature is calculated considering pair wise similarity between each data point and hence it is computationally extensive. Finally, the above measure is used to rank the features. One other noteworthy method is based on the laplacian score [11], where features are evaluated based on locality preserving power of the features. The process involves, evaluating individual features by pairwise comparison of data values, where if the data points are not ‘close’ enough, it is marked ‘0’ or else it is marked by , where xi and xj are ith and jth value of the feature ‘x’ and ‘t’ is a constant. SPEC [30] is another neighborhood based method similar to [11], in fact it may be shown that, laplacian score is a special case of the same.
For a supervised problem, importance or relevance of a feature is easy to determine. It can be obtained by measuring the correlation coefficient, mutual information or Fisher’s Score between the feature and the target variable. However the problem is not that simple to solve in an unsupervised task. In this section, a novel measure of feature importance is proposed for unsupervised problem. It is based on principal component analysis of the dataset.
Principal component analysis (PCA) is one of the oldest and most used methods for multivariate analysis of data. In principal component analysis, given an input matrix (n x m), an output matrix(n x m) is produced by projection. The rows of the output matrix are called principal components which conform to the following rules Variability is highest in the direction of the first principal component and then gradually it decreases with each component. The principal components are unrelated i.e. orthogonal to each other.
The variability score is then proposed based on the following intuitions. Higher the correlation of a feature with the principal components, higher is the capability of the feature to explain total variance of the dataset. These correlation coefficients need to be suitably weighed and combined to arrive at a score for feature importance. The weight should vary based on the individual principal component’s ability to explain the overall variability of the dataset.
VSi indicates the variability score of the ith feature and VS is the set containing the VSi of individual features given as {VS1, VS2, …… …… , VSn), where n is the number of features in the dataset.
Detailed steps of computation of Variability Score (VS) are enclosed below: -
In the above equation, Σ denotes the correlation matrix, A is a matrix whose columns are the orthonormal eigenvectors of the matrix Σ and Λ is given as below matrix
The theoretical maximum value for VSi is 1 when the dataset itself is univariate. Therefore, VSi gives a positive value between 0 and 1. An empirical analysis of VSi has been conducted over 51 publicly available datasets which consists of 3674 features.
Observations from the empirical distribution are as follows: The values are mostly concentrated in lower range of VSi. The maximum values are in the range of 0.72 to 0.75. The mean is 0.14 and median is 0.11. It has a skewness of 1.55 and kurtosis of 2.74. The standard deviation is 0.13.
In Fig. 2, the empirical distribution as obtained from all the features is represented using a histogram. In Fig. 3, average VSi of each dataset is presented with a histogram.

VSi Empirical distribution.

Mean VSi of datasets.
Apart from VSi, entropy has also been used to measure importance of a feature. The rationale of using both the measures is that, while VSi focuses on overall variability of the dataset, entropy focuses on variability or information richness of individual features. Recent researches [34, 35] emphasizes on the role of dataset characteristics in choosing a feature selection method. In the proposed approach, as both the univariate and multivariate measures of feature importance is employed, it is much more generic theoretically.
Correlation coefficient has been used here for removing redundancy. Some important properties of the correlation coefficient, are that the value varies between –1 and +1, higher the absolute value, higher is the strength of the relationship between the variables. It is also symmetric, i.e., correlation coefficient between x and y and correlation coefficient between y and x is same. Correlation coefficient exhibits the property scale invariance.
As noted in [26] values of ≤ 0.35 are generally considered to represent low or weak correlation, values lying between 0.36 and 0.67 are considered to be medium or moderate correlation and values between 0.68 and 1.0 indicate strong and high correlations. Especially values ≥ 0.9 are considered as very high correlation. Some other important measures are namely Fisher’s Score, mutual information, and relief etc. However none of the other measures of dependency has such wide acceptability and clear semantics attached with it.
Next greedy forward search algorithms FSELECT-VS and FSELECT-EN have been outlined which uses VSi and entropy respectively.

The same process is implemented with Shannon’s Entropy as well.
FSELECT –EN, is very similar in working as that of FSELECT –FS, this uses the entropy of the features as opposed to VSi.

Both the above methods are computationally very inexpensive as they apply greedy forward search. VSi has a linearity assumption. Entropy is more generic. VSi considers overall variability of the dataset where as entropy considers individual variability of the features.
Hence it is recommended to use both the methods and use the one which is giving better result for that dataset. It is to be noted, that in individual capacity both these algorithms outperform some of the existing state of art feature selection methods. The final recommended method has been illustrated in Fig. 4.

Proposed Final method
The salient points of the experimental setup as far as materials and methods are concerned are as follows: - 30+ datasets are used from publicly available sources [27, 28]. These are basically datasets used for classification, which has been used for clustering by removing the class or target column. Actually there are many internal cluster validity measures like Silhouette Coefficient, Sum of Square Error (SSE), entropy etc. different indices give varying amounts of emphasis on cohesion and separability and hence are subjective. With labels available external cluster validity measure can be applied. The dataset details are given in Table 1. The datasets are quite varied, with some datasets having more than 100 features (Digits, lsvt, Mdlon) Most of the datasets have more than 2 classes making the datasets complex, with some having 10 or more classes (Segment, Yeast, Leafs, Dow, Digits etc,) Feature selection is performed by using the two algorithms FSELECT –VS and FSELECT - EN as explained in Section IV. The values of the parameters α (Correlation Threshold) and β (Variability Retained) have both been set at 0.9. Both methods have been combined in the final proposed method as explained in Fig. 4. Feature selection have also been performed using few existing methods [11, 23] for comparison. For determining cardinality of the optimal feature subset, β have been used. So all the methods have been compared keeping the same level of feature reduction. The feature subsets have been compared based on the purity, which is a standard external measure of cluster validity. The clustering algorithm used in this setup is K Means and the purity reported in the results sections is an average of 100 iterations. The computational environment used is ‘R’ [29].
Dataset details
Dataset details
The comparisons of purity of all the methods across the datasets have been given in Table 2. At first, it is established that the feature reduction is achieved by the proposed method without any statistically significant performance degradation. Then the proposed approach is compared with other state of the art algorithms for a performance comparison.
FSELECT –VS, FSELECT –EN, PFA [23], EVA [20], Laplacian Score [11], proposed (best of FSELECT –VS, FSELECT –EN) and “All features” have been denoted as (1), (2), (3), (4), (5), (6) and (7) respectively in subsequent text.
After analysis of the results in Table 2, it can be seen (1), (2), (3), (4), (5), (6) and (7) produce average purity of 67.3%, 66.8%, 67.4%,66.7%, 65.81%,, 68.51% and 68.79% respectively. Results produced by the proposed method (Which picks best result from FSELECT –VS and FSELECT –EN) is the closest to results obtained with all features and it achieves the same, with close to 44% (average) reduction in the feature set cardinality (Table 2 % Reduction Column).
One of the criteria of feature reduction is that it should not result in any corresponding decrease in performance measure as compared with all features. So a pair wise t-test has been performed between results obtained by each of the 6 methods (1–6) and that obtained using all features (7). The pair wise t-test between the results obtained from (6) and (7) is not statistically significant. (t = –0.35, p = 0.73). Same holds true for (1) and (2). It is to be noted that for (3) and (5) performance degradation because of the feature subset reduction is statistically significant. (4) Exhibits again no statistically significant performance degradation. The results of the pair wise t-tests with all features have been presented in Table 2a. The summary results are shown in Table 3a and b. Table 3a contains average value of purity and average of the ranks. Table 3b furnishes head to head performance against the other methods. (W indicates ‘Win’, D indicates ‘Draw’ and L indicates ‘Loss’) Average value is not a good metric to compare methods [32]. It is quite possible that for a particular dataset a method achieves superior performance by quite a margin which makes up for marginal under performance across datasets. As an example for a particular dataset CTG, (4) achieves 46% better result than (5). Therefore, a rank based comparison is done, where ranking is done based on the performance. Lower the rank of a method better is the performance. The average rank achieved by (1), (2), (3), (4), (5), (6), (7) are 3.28, 2.97, 3.66, 3.59, 4.25, 1.88 and 2.72 respectively (Table 3a). It can be observed that, at individual level both (1) and (2) outperform (3), (4) and (5). In (6), when the better of (1) and (2) is picked; there is significant improvement in average rank and in fact this is the only method to achieve better rank than full feature set option. A comparison has also been made in terms of absolute number of cases where each of the methods gives equivalent or better performance as compared to (7). (1), (2), (3), (4), (5) and (6) have the count of such cases or datasets as 18, 15, 15, 14, 13 and 20 respectively.
Clustering Accuracy across datasets and Method
Clustering Accuracy across datasets and Method
Result of pair wise t-tests
Overall comparison between the methods
Comparing the win loss of the methods
Comparison of execution times (in seconds)
It can also be seen FSELECT –VS enjoys most number of no loss situation cases and a better average purity, FSELECT - EN on the other hand achieves the best rank across datasets. Hence the combined scheme (6), to pick the best from these two has been proposed. As previously discussed, it can be seen from Table 3a, that by both average rank and average purity (6) is the best method.
In terms of computational complexity, a greedy search is quite efficient as compared with other methods; a comparison of execution time is presented in Table 4. The comparison has been limited to datasets having relatively larger number of rows or columns. The execution time has been measured in seconds.
It can be observed that, (1) and (2) take far lesser time as compared to (3), (4) and (5). The neighborhood based method (5) is most expensive, followed by clustering based methods (3) and (4). The proposed algorithms (1) and (2) demonstrate most efficient execution in terms of running time. Our finally proposed method (6) picks the better of (1) and (2). Therefore, it naturally possesses the same executionefficiency.
Relevance of a feature for unsupervised problems is not adequately defined. To address this gap, in this paper, a novel variability based score named as VSi has been proposed to measure feature importance for unsupervised problems. The above measure has been used for selecting feature subsets (FSELECT –VS) in a greedy forward search method. Correlation coefficient has been used to filter out redundant features. It can be seen, FSELECT –VS gives the best performance among the methods in terms of count of datasets in which it gives better or equivalent features as compared to using all features. Similar setting has also been used where feature importance has been measured using Shannon’s Entropy (FSELECT –EN). In the proposed framework, it is recommended to apply both the methods and select the one, which is better performing for that particular dataset.
Comparison with all featuresand the proposed method
On an average a 44% reduction in feature subset is achieved. It is also demonstrated that, the reduction is achieved without any statistically significant decrease in performance (t = –0.35, p = 0.73). In 19 out of 32 datasets a better or equivalent result is obtained. In terms of average ranks, the proposed method outperforms significantly (1.88 as opposed to 2.72).
Three widely cited techniques have been selected for comparison with the proposed method.
Comparison with other state of the art methods;
The proposed method is superior in terms of average accuracy, average rank, as well as by count of datasets in which better or equivalent results are achieved. Most importantly, superior results are achieved with a much reduced execution time.
This procedure may be extended to other nonlinear relationships as well. Nonlinear measures of the relationship between variables, as outlined in [30] or non linear PCA can be a used to relax the linearity assumption.