
Abstract
We trace the evolution of open government data (OGD) publication among U.S. health agencies to illustrate how OGD goals and benefits might be achieved. Our novel conceptual framework illustrates the implicit logic underlying OGD activities in the health domain and their anticipated impact on population health. We conducted semi-structured interviews with 50 diverse practitioners and policymakers from local, state, and federal agencies, and non-governmental organizations. Using a positive deviance approach, we identified innovative U.S. health agencies that were early OGD adopters. We analyzed transcripts using a grounded theory methodological approach to identify common themes. Results indicate that the OGD movement is marked by three major eras (pre-OGD early activities, Open Data 1.0, and Open Data 2.0), and U.S. health agencies are in different stages of evolution. Among innovative jurisdictions, OGD transitioned from an early focus on releasing large volumes of data to a more demand-driven approach to promote meaningful user engagement with data. Although engagement strategies could yield benefits, limited evidence exists on best practices for engaging diverse data users and many jurisdictions have not yet transitioned to this later phase. Our conceptual framework could be adapted for other domains to help visualize how successful OGD initiatives might unfold.
Introduction
Since U.S. President Barack Obama’s 2009 executive order (Obama, 2009) to promote government transparency, public participation, and collaboration within government and with private partners, agencies at all levels have released record volumes of “open data” that are free, available in non-proprietary formats, and searchable. The implicit logic is that users of open government data (OGD) will take innovative data-driven approaches to promote government transparency, improve government performance, foster engagement between government and its people, create jobs, and build economic value (Gurin, 2014; Linders, 2012; O’Reilly, 2010). In the health domain, this logic further implies that OGD will be used to make health information more accessible, support health application development, and improve the quality of the healthcare delivery system; which would serve to empower healthcare consumers and increase overall public health (Martin & Begany, 2017; Martin et al., 2014, 2015).
A critical assumption underlying the premise that opening data will lead to data-related actions is that users will discover and engage with the data (Attard et al., 2015; Chan, 2013; Gascó-Hernández et al., 2018; Janssen et al., 2012; Khayyat & Bannister, 2017; Lassinantti et al., 2019; Ruijer & Martinius, 2017; Safarov et al., 2017; Susha et al., 2015b; Weerakkody et al., 2017; Wirtz et al., 2019; Zuiderwijk et al., 2015, 2018). Earlier work suggests that user engagement with OGD can be facilitated with greater support mechanisms (e.g. mentoring and training), visualization of open data, better quality open data infrastructure, and reciprocal interaction between open data providers and users (Janssen et al., 2012; Susha et al., 2015b). Further approaches for improving users’ engagement with OGD include raising awareness of OGD and providing easily replicable examples of OGD use (Khayyat & Bannister, 2017), using OGD in digital data journalism (Felle, 2016), providing interactive map applications (Gagliardi et al., 2017), and providing context-specific OGD skills training (Gascó-Hernández et al., 2018). However, most government organizations have limited interaction with their open data users, systematic frameworks of user engagement strategies are lacking (Susha et al., 2015b), and organizations do not prioritize open data users or open data sustainability.
To advance the discussion on how to achieve the goals of OGD publication, we trace the evolution of health related OGD in innovative U.S. jurisdictions that have already shifted away from simply releasing data and towards strategies to engage users. We use a positive deviance approach (Bradley et al., 2009; Klaiman et al., 2013) to recruit key informants at U.S. government health agencies and other organizations that were early innovators in publishing OGD. We report on the evolution of their OGD programs, factors that enabled their shift towards prioritizing strategies to engage health data users, and recommendations for other jurisdictions seeking to achieve long-term benefits from OGD activities. We use health as a case for understanding the evolution of OGD publication more generally because it is an area of early activity, making it an information-rich case for a deeper understanding of its implementation. Due to the complex nature of the open data ecosystem and anticipated benefits of OGD, described more below, focusing on one domain allows for a more nuanced understanding of the progression of OGD activities.
Literature review
This narrative literature review begins with a discussion of the implicit logic underlying OGD initiatives and introduces a conceptual framework, in the form of a logic model, for how OGD creates beneficial outcomes. We continue with a review of prior work that addresses the history and evolution of OGD and then conclude with a description of the current study and its contributions.
The implicit logic and assumptions driving OGD activities
As earlier noted, the implicit premise of investing in OGD initiatives is that OGD will be used to achieve a variety of societal benefits. Past work has discussed different aspects of the implicit logic and assumptions behind OGD activities, with some simply acknowledging this logic, its assumptions, and related literature (Attard et al., 2015; Gurin, 2014; Khayyat & Bannister, 2017; Lassinantti et al., 2019; Linders, 2012; O’Reilly, 2010; Martin & Begany, 2017; Martin et al., 2015; Martin et al., 2014; Ruijer & Martinius, 2017; Safarov et al., 2017; Susha et al., 2015b), and others conducting empirical research on specific aspects (Chan, 2013; Gascó-Hernández et al., 2018; Janssen et al., 2012; Weerakkody, et al., 2017; Wirtz et al., 2019; Zuiderwijk et al., 2015, 2018).
Figure 1 illustrates the implicit logic underlying OGD activities and their expected social impact in the health domain, based on a synthesis of our past work (Begany & Martin, 2017; Martin & Begany, 2017; Martin et al., 2014, 2015, 2017, 2018) and recent recommendations from the National Committee on Vital and Health Statistics on maximizing the value of HealthData.gov, the federal open health data repository (National Committee on Vital and Health Statistics, 2017). Our conceptual framework focuses on health data to provide more specific information on anticipated short-, medium-, and long-term impacts; these general principles would apply to other domains such as education or the environment.
Implicit logic guiding the release of open health data and anticipated outcomes. Source: Authors’ synthesis of earlier work (Begany & Martin, 2017; Martin & Begany, 2017; Martin et al., 2014, 2015, 2017, 2018).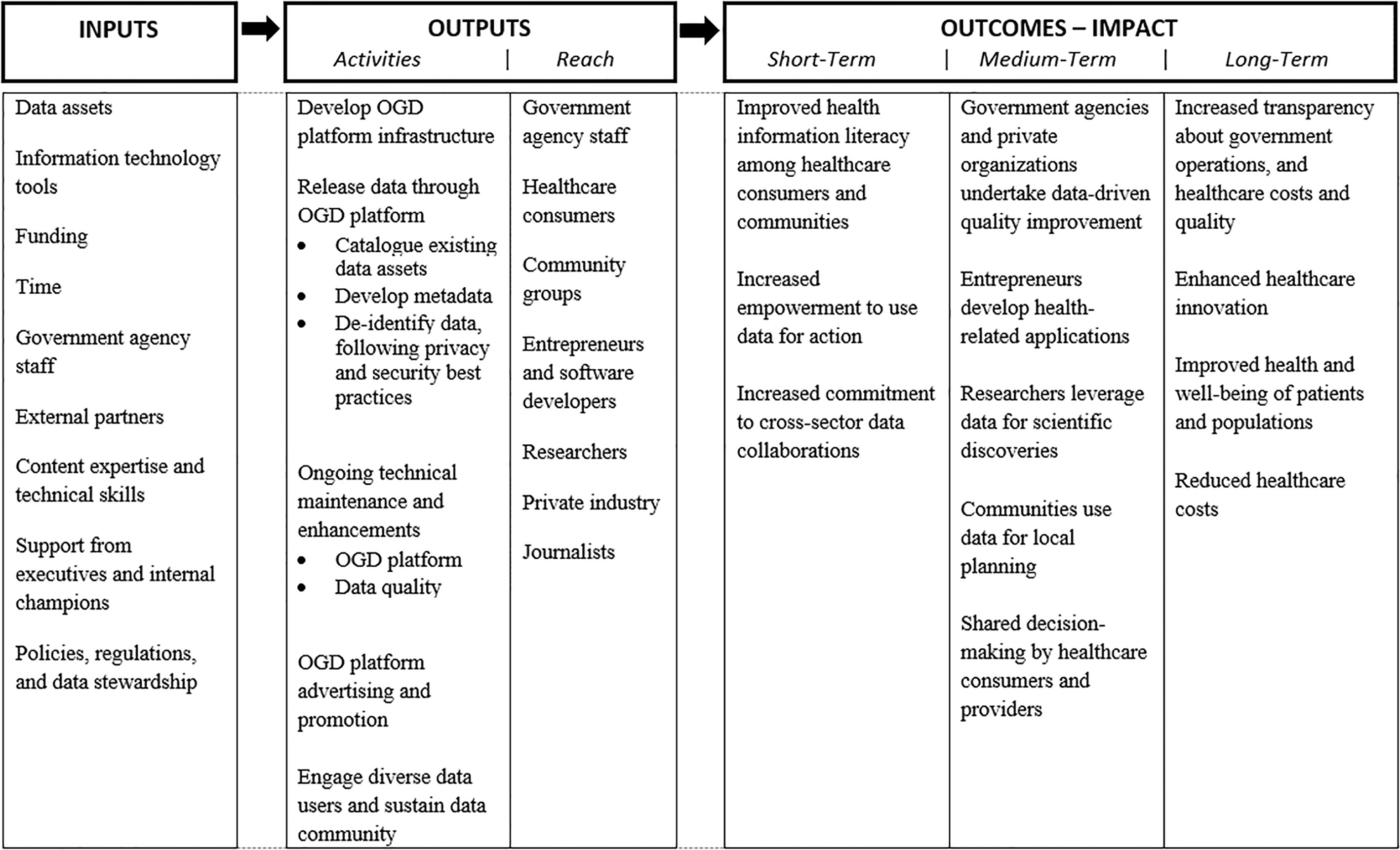
OGD activities require numerous material, financial, human resources, and policy-related inputs. Health departments oversee the collection of diverse data, including population health surveys (such as the National Health and Nutritional Examination Survey [NHANES]), administrative data (such as all-payer hospital discharge records, Medicaid claims, and prescription drug monitoring program databases), disease registries (such as state HIV reporting systems and the Surveillance, Epidemiology, and End Results [SEER] national cancer registry), vital statistics, and food safety inspection reports. Information technology tools are required for the secure sharing of protected information, de-identification of personally identifiable information, and hosting OGD in interactive platforms for the public. Funding includes both public and private sources, including foundations such as the Robert Wood Johnson Foundation and California HealthCare Foundation. Government agency staff include data owners and analysts (to supply data and develop metadata), informaticists to de-identify datasets and perform other coding to prepare OGD datasets for public release, and managers who understand the data context and have sufficient expertise to interact with technical experts. External partners include individual consultants and organizations such as the Health Data Consortium (no longer in existence) and Code for America. Given the sensitive nature of health data, OGD need to be released under “stringent privacy, security, and confidentiality protections” (National Committee on Vital and Health Statistics, 2017); this entails considerable work to de-identify datasets and make expert determinations on a case-by-case basis.
Various activities support OGD programs’ overarching aim to facilitate the discovery, access, and use of publicly available health data. Many activities are technically oriented, such as developing OGD platform infrastructure, cataloguing existing data assets, developing metadata to facilitate data users’ understanding, and de-identifying data following privacy and security best practices. There is also ongoing technical maintenance and enhancements to both OGD platforms and data quality as data users identify errors in the data and make additional requests. Additionally, there are activities to develop and sustain communities of data users, including general OGD platform advertising and promotion, and outreach to specific data user communities. Data users targeted by OGD programs are diverse and include government agency staff who have improved access to data resources across agency divisions, healthcare consumers, community groups, entrepreneurs and software developers, researchers, private industry, and journalists.
Short-term outcomes include improved health information literacy, as healthcare consumers can view more accurate and comprehensive information on their providers and healthcare facilities, such as the rate of performing unnecessary or inappropriate medication treatments (U.S. News & World Report, 2016). Journalists have used OGD to highlight systemic, problems in the healthcare system, such as high variation in costs for common surgical procedures (Crain’s New York Business, 2014). As these health data become available openly, healthcare consumers and community groups will be empowered to take action, such as using food safety inspection reports to inform decision-making on where to dine, selecting medical providers based on objective information about their quality, and engaging in community learning initiatives that draw on local data to identify priorities. OGD may also increase commitment to cross-sector collaborations. OGD development and promotion activities among diverse participants can facilitate open data ecosystems; once these ecosystems are established, their participants can share ideas and leverage each other’s strengths to use data for action and healthcare innovation (for example, collaborations among public health content experts and developers to link Yelp to food safety inspection data).
These short-term outcomes will lead to several medium-term outcomes: government agencies and private organizations undertaking data-driven quality improvement, entrepreneurs developing health-related applications, researchers leveraging data for scientific discoveries, communities using data for local planning, and shared decision-making among healthcare consumers and medical providers. Ultimately, this will lead to increased transparency about government operations – a frequently cited goal of OGD (Obama, 2009, 2013). In the health domain, OGD may also improve transparency on healthcare costs and quality, and healthcare innovation more broadly. Efforts to improve medical decision-making, facilitate data-driven quality improvement, and enhance community planning are ultimately intended to improve the health and well-being of individual patients and populations. Improved health outcomes, combined with higher quality care, may also reduce healthcare costs.
While the underlying logic behind OGD activities can be concisely represented in a conceptual framework diagram such as ours, other researchers examining the achievement of OGD objectives have questioned the underlying assumptions of OGD (Zuiderwijk et al., 2018) and the benefits, adoption barriers, and “myths” related to OGD (Janssen et al., 2012). The stated objectives of OGD initiatives are frequently disconnected from their actual achieved benefits, and benefits yielded are not consistently related to their OGD initiatives’ objectives (Zuiderwijk et al., 2018). For example, the objective of one OGD initiative, Greece’s Diavegia Transparency Programme, was to increase democratic accountability, but increases in transparency were achieved instead. Objectives are more frequently achieved by national and state OGD initiatives, compared to local and regional initiatives. Interviews with 14 Dutch government officials identified several assumptions, such as OGD can strengthen government accountability, build trust between government and citizens, and improve citizen satisfaction; and that OGD is vital to economic growth and creates value. There also exist several myths, including “the publicizing of data will automatically yield benefits,” “it is a matter of simply publishing the data,” and “every constituent can make use of open data” (Janssen et al., 2012). These myths assume that data users become aware of OGD, are able to identify the correct OGD for their needs, and have the necessary skills to interpret and use OGD.
Additional studies examine data users’ perspectives on OGD, as the underlying logic assumes that data users will discover and utilize OGD (Gascó-Hernández et al., 2018; Weerakkody, et al., 2017; Wirtz et al., 2019; Zuiderwijk et al., 2015). A survey of German citizens found that citizens are motivated to use OGD when they are perceived to be easy to use and useful, and when they expect to achieve benefits such as government transparency, participation, and collaboration. Citizens’ expectations affect their word-of-mouth communication with others about their intention to use OGD and whether they recommend using OGD (Wirtz et al., 2019). A similar survey of U.K. citizens’ perceptions and intention to use OGD revealed that they are only likely to use OGD if they perceive a clear advantage to doing so (Weerakkody et al., 2017). A cross-national survey of attendees at four OGD conferences found mixed results regarding the acceptance and use of OGD, suggesting that more government effort is needed for OGD to be successful (e.g. demonstrating the benefits of OGD use, raising awareness about OGD, and making OGD technologies easier to use) (Zuiderwijk et al., 2015).
Gascó-Hernández et al. (2018) addressed the common OGD assumption that data discoverability and accessibility will yield innovative uses by examining skills training, a key barrier to use. By examining three cases of OGD training and engagement initiatives in three different countries, they highlight that simply being aware of OGD and its benefits does not necessarily facilitate its use. Rather, users need context-specific training on OGD appropriate to their current level of analytic skills. Preliminary findings from another case study of a Singaporean OGD platform indicated that certain open innovation strategies (e.g. creating an open data platform and encouraging user participation) can be employed to achieve OGD benefits (Chan, 2013).
Although OGD is a nascent research domain (Charalabidis et al., 2015; Horrigan et al., 2015; Hossain et al., 2016; Khayyat & Bannister, 2017; Ruijer & Martinius, 2017; Safarov et al., 2017; Susha et al., 2015b; Weerakkody, et al., 2017; Zuiderwijk et al., 2015), prior research has identified some circumstances and events that catalyzed and sustained the OGD movement, including aspects of OGD’s foundations and progression in the U.S. (Luna-Reyes & Najafabadi, 2019; McDermott, 2010; Peled, 2011; Thorsby et al., 2017; Zhu, 2017).
Luna-Reyes and Najafabadi (2019) used a framework of four basic conditions of OGD success (technology, community, policy, and data) to understand the primary factors for successful OGD programs in several case studies, based on the analysis of documents, websites, and open data portals. They traced the evolution of OGD in five federal agencies (US Departments of the Treasury, Transportation, Energy, Agriculture, and Labor) in relation to specific federal legislation and agency specific OGD projects. They note that the current phase of OGD is focused on applications to foster economic development and efficiencies in government, but initiatives have recently stagnated.
McDermott (2010) reviewed existing public documents related to key legislations that spurred the OGD movement (the Paperwork Reduction Act, the E-Government Act, the Freedom of Information Act, and the OPEN Government Act) to assess their sustained impact on open government initiatives. The author concludes that although activities to achieve open government have been underway for decades and recent developments are encouraging, substantial additional work is needed to truly establish a culture of openness in the federal government. Peled (2011) recounts the historical underpinnings of the OGD movement based on existing literature, combined with website performance data from Data.gov, the primary open data site for U.S. federal agencies. Results indicated that federal agencies initially met the minimum requirements of federal open data directives but subsequently they were largely ignored.
Other studies reported additional historical perspectives on OGD (Thorsby et al., 2017; Zhu, 2017). Thorsby et al. (2017) recount the OGD history including the emergence of open data portals in thirty-six major U.S. cities, and examine the features and types of datasets provided in their open data portals. They found that a city’s population size was a critical factor in determining the number of datasets available in open data portals, variety of dataset content types, and open data portal features. Zhu (2017) uses document analysis to trace the history of the JURIS system as a specific case of OGD failure. The JURIS system, a U.S. government legal information database containing federal court decisions and other primary legal materials, was opened to the public due to efforts of ODG advocates. This analysis provided several reasons for OGD failure (e.g. Department of Justice’s reluctance to compete with private sector information providers, lack of powerful allies in the campaign to open the JURIS system, and strong opposition from specific stakeholders), as well as additional information on the OGD movement’s initiation and its many complexities and challenges.
Current study
The current study advances prior literature by providing a comprehensive narrative of how the goals and benefits of OGD can be achieved, through a detailed analysis of activities in selected U.S. jurisdictions that were early adopters of OGD. We accomplish this via numerous in-depth key informant interviews with experts that had diverse roles in OGD. Although past studies have described the OGD evolution, they have relied primarily on secondary documentary data and/or descriptive analyses of OGD portals and their performance data. Our analysis contributes to the literature by using an in-depth empirical analysis of a rich set of primary interview data which allows for a more detailed understanding of this area. Focusing on “innovators” and “early adopters” (Rogers, 2003) of OGD allows us to identify concrete strategies for OGD program success and achieving the long-term benefits, which can be used by “late majority” or “laggard” (Rogers, 2003) jurisdictions that are in initial stages of or have not yet started OGD implementation. A final contribution is that OGD research is characterized by a lack of theoretical frameworks (Charalabidis et al., 2015; Susha et al., 2015b; Zuiderwijk et al., 2014, 2015); and our conceptual framework allows for a novel lens to examine OGD in a focused domain. While we don’t believe health to be unique, studying one domain in detail can yield richer insights into the evolution of OGD that can be applied to other domains more generally.
Methods
Study overview
A requirement for achieving the beneficial outcomes and goals of OGD initiatives is fostering potential data users’ engagement with OGD. Our study aimed to identify how U.S. jurisdictions releasing data can move past the phase of basic data publication and toward more meaningful engagement and use of OGD, which is necessary to achieve OGD goals. Toward this aim, we used a positive deviance approach to purposefully recruit key informants that were innovators and early adopters of OGD initiatives, who could provide greater feedback and insights about implementing OGD initiatives and their evolution. Such leading-edge cases can provide a more comprehensive and nuanced understanding of successful OGD implementation strategies, including facilitating factors that enable users’ engagement with and use of OGD. Obtaining perspectives from innovative OGD jurisdictions allows for sharing their best practices and insights on their lessons learned to other “late majority” or “laggard” government agencies that are in earlier stages of, or have not yet started, their OGD initiatives.
To discover and report themes and concepts from our key informant interviews, and given the nascent stage of OGD research generally (Hossain et al., 2016; Khayyat & Bannister, 2017; Ruijer & Martinius, 2017; Safarov et al., 2017; Susha et al., 2015; Weerakkody et al., 2017; Zuiderwijk et al., 2015) and its lack of theoretical foundations (Charalabidis et al., 2015; Susha et al., 2015b; Zuiderwijk et al., 2014; Zuiderwijk et al., 2015), we used a grounded theory methodological approach for this study (Charmaz, 1996; Strauss & Corbin, 1994). Rather than testing hypotheses derived from existing theoretical frameworks, we systematically and inductively examine the topic of OGD to discover themes and concepts related to OGD’s implementation and evolution in the specific case of open health data. The output from this analysis is reporting themes and concepts, including insights from key informants about how to achieve the desired outcomes of OGD initiatives by facilitating health data users’ engagement with OGD. In the discussion section, we synthesize our findings with the broader literature.
The protocol was exempted by the University at Albany Institutional Review Board.
Participant recruitment
Participants from U.S. city, state and federal jurisdictions that were early innovators in releasing open health data were recruited via purposive and snowball sampling (Charmaz, 2014; Corbin & Strauss, 2007; Patton, 1999) from government health departments as well as non-governmental organizations. Different producers of data were recruited to facilitate a holistic understanding of how their OGD programs evolved including barriers to specific activities in our conceptual framework, such as developing OGD platform infrastructure, releasing data, and engaging data users. The participant sampling aimed for diversity in professional roles (e.g., executive leadership, program directors, data owners, open data staff, legal affairs personnel, independent contractors, and entrepreneurs) and area of expertise (e.g., leadership, project management, public health, information technology, and open data). Participants were experienced with a variety of OGD initiatives and activities, including customizing open data platforms for their agency’s needs, releasing OGD, publicizing OGD, working with data journalists, organizing hackathons and innovation challenges, creating data visualizations, and other activities. During participant recruitment, via email, 50 people agreed to be interviewed, 8 did not respond, 1 declined due to retirement, and 5 declined citing a lack of expertise, but, suggested other individuals.
Characteristics of study participants
Characteristics of study participants

Key informants were initially selected through purposive sampling, aiming to recruit study participants that represented the job responsibilities and expertise that we believed to be necessary to achieve a comprehensive understanding of the evolution of OGD in the health domain. At the end of each interview, we asked study participants to recommend names of additional individuals to contact and we used this snowball sampling to recruit additional key informants. Recruitment continued until we achieved theoretical saturation, when no new topics or viewpoints emerged from subsequent interviews. We determined saturation through our ongoing analysis of the interview data (as subsequently described in Sections 3.3 and 3.4) and determining per consensus between authors that no new information emerged from subsequent interviews. The final sample consisted of 50 participants and 43 interviews (see Table 1), where some interview sessions consisted of two or more participants.
The semi-structured interview guide (see appendix) focused on different aspects of the evolution of OGD: the historical context, strategies for engaging users, benefits and challenges of engaging external data users, lessons learned, and future activities to improve engagement. And, the interview guide was customized for each participant to focus on their area of expertise. The interviews lasted approximately one hour and occurred in person or via telephone. Interviews were digitally recorded and transcribed, except for a few instances where executive leadership requested handwritten notes.
Data analysis
The interview transcripts were analyzed using a grounded theory methodological approach to discover and report themes and concepts (Charmaz, 1996, 2014; Corbin & Strauss, 2007; Patton, 1999; Strauss & Corbin, 1994). Each author independently reviewed transcripts to identify themes and concepts that emerged from the data and create associated codes. Authors compared and discussed codes, reached agreement, and drafted a coding guide. To further refine the coding guide, four interview transcripts were double coded independently using the guide and results compared. Modifications were made to the coding guide to improve interrater reliability (see appendix for the coding guide). One researcher (G.M.B.) subsequently coded the remaining transcripts, consulting (E.G.M.) throughout.
After the remaining transcripts were coded, all interview data corresponding to the “historical context,” “consumer engagement,” and “next steps” themes were reviewed independently by each author. In synthesizing the data, the authors characterized these themes (e.g., assembling timelines of the OGD programs’ evolutions, identifying specific activities to facilitate data users’ engagement with OGD, identifying common challenges to engaging data users), and identified areas of agreement and divergence across participants and settings. Authors subsequently discussed their independent syntheses to achieve consensus on their interpretation of the data.
Results
This section describes results from analysis of themes in the key informant interviews. Participants described three major eras of implementing their OGD programs, from conception to a current focus on user engagement. This description is followed by a synthesis of the major reported challenges and facilitators to progressing through these eras.
Historical evolution of open data among government health agencies
The U.S. open data movement is punctuated by three major eras (Fig. 2). Era 1 (pre-2009) consists of early activities to publish datasets in open formats, Era 2 (2009–2014) comprises executive orders and state-level events that catalyzed rapid evolution in open data portals, and Era 3 (2015-present) focuses on user engagement.
Evolution of the U.S. open government data movement among health agencies. Source: Authors’ analysis of key informant interviews. Abbreviations: Behavioral Risk Factor Surveillance System (BRFSS), National Health and Nutrition Examination Survey (NHANES), New York State Department of Health (NYSDOH), US Department of Health and Human Services (HHS).
Early open data activities focused on basic “electronic information access.” A state-level executive leader described, “the idea at that point was more about agency websites than a state open data commitment, but a lot of the principles…set the tone for a number of years of effort that followed.” Improved electronic government information access, along with key state-level legislation mandating the publishing of public records (e.g., Washington State Legislation 43.41A.125), established Washington State, California, New York, Illinois, and other jurisdictions as early open data innovators. Health departments improved data accessibility by publishing tables and datasets online and implementing formal data request procedures.
At that time, non-profit foundations including the Lucile Packard Foundation, the Kaiser Family Foundation, and the California Healthcare Foundation, were highly visible to this work as OGD was not yet seen as being within the scope of traditional public health practice. As one private sector entrepreneur explained, “At that time, we weren’t calling things ‘open data’, but in essence, we were opening up data. Governments weren’t as likely to do that then, so foundations often took the role of freeing the data.”
Toward the end of this era, the commercial developer Socrata, a company focused on delivering software services to the public sector, developed a technical platform to host open data sites. While some agencies, including the federal Department of Health and Human Services, developed their own technological infrastructure, many agencies opted to use Socrata’s commercial product. Early innovator government agencies began opening their data in earnest, generating crucial momentum for the open data movement.
Era 2: Open Data 1.0
In the next era, OGD transitioned from lower-visibility activities that were not recognized explicitly as “open data” to a defined movement with broad enthusiasm and support. One open data manager explained, “The enthusiasm in that room about open data, it was just exploding all over the place.”
In the subsequent five years, federal and state open data directives catalyzed a flurry of activity among innovative jurisdictions. The focus was to “increase the presence of state [and federal] open data…getting the agencies to get information up and out” and then to “work with local governments to help them do the same thing.” The strongest catalyst was President Barack Obama’s 2009 executive order. Immediately following this directive, the federal government launched Data.gov as a repository of open federal, state, and local data to provide unprecedented access to these government resources. Code for America, a non-profit organization focused on connecting government and citizens via technology solutions, was founded this same year.
Data managers launched open data initiatives by releasing data commonly requested via the Freedom of Information Act (FOIA) and other datasets, such as New York’s list of baby names, that were relatively easy to publish and generated public interest. According to one executive leader, “At first it was the low hanging fruit…like baby names and…smaller datasets that had public view type of value. So that was the initial real focus, was just get the low hanging interesting datasets out there.” Another executive leader explained, “we were able to move forward with some high value data sets quickly, focusing first on those data sets that were FOIA-ed often. They’re going to get many requests for this data anyway, let’s make our own lives easier by releasing those data sets in a form that’s usable and then updating it regularly.” The subsequent reduction in annual FOIA requests was a “tipping point” that increased the agency’s interest in releasing additional high-value data.
After releasing data, agencies promoted their open data initiatives through Code-a-Thons, publicity, and open data gatherings. Recalled one executive leader, “we started seeing…this big trend of doing these Code-A-Thons, getting the data out there so that people could actually use it, not just to view it, but actually use the data.” An influential and popular open data gathering that launched at this time was the Health Datapalooza, which entails “three and a half days of learning and explorations and applying data to decision-making, certainly fueling a ton of analytic tool development, IT applications and services, workflow processes and improvements,” as one federal leader described. What started out as a small group at the National Institutes of Health, grew exponentially into an event with over 2,000 attendees and continues to meet annually.
Another notable development during the Open Data 1.0 era was the emergence of data “communities,” comprising families of datasets focused on specific topics, such as health and education. The HealthData.gov site was the first major community and supported by DHHS. Health Data NY, the first state-level open data portal devoted to health, launched during this era, followed by topic-focused portals from other innovative state jurisdictions (e.g., California’s open health data portal).
Era 3: Open Data 2.0
After establishing their basic infrastructure and releasing high-value datasets, early OGD adopters transitioned to a new, and ongoing, “Open Data 2.0 era” that focuses on engaging data users. One executive leader characterized this era by noting, “it’s great that we take data and we make it publicly accessible, but if nobody’s using it, why go through all that effort. So, the third part is getting people to be aware of it, helping them know where it is and what it is and how it can be used.” A manager added, “So what has started out as, let’s inventory, do an inventory of the data, let’s get a portal up there to share the data, to institutionalizing it as a regular practice…we have moved from infancy and worrying about getting the data out there, to looking more at [data] use.” In parallel, another programmatic goal in this era is to improve data quality; as one federal executive leader noted, “there really was too much of an emphasis on just getting data files out and not enough emphasis on getting quality data files out or data files out in a fashion or with the para-data or metadata that let anyone actually use it.”
Jurisdictions that progressed to the Open Data 2.0 era employed numerous strategies to engage users. The first was taking a “demand-driven approach” to engaging users with open data, whereby agencies prioritize the release of datasets requested by users. This differs from the prior era’s “scattershot approach” of liberating large volumes of data, irrespective of their utility for data users. For example, informants at both the federal and state levels suggest “bi-directional” discussions (versus one-way feedback whereby data users submit suggestions via email or an online form) and focus groups with data users to understand their data needs and planned use. Such discussions can enable agencies to “learn, one, how your data is valuable and then, two, how you can make it more valuable,” noted one federal executive leader. They can also facilitate agencies getting to know their specific “data communities,” their unique data needs, and priority datasets. As the federal leader explained, “We constantly get entrepreneurs coming to us, telling us what kind of data they’re using, how they’re using it.”
In addition to connecting with data users to understand their needs, agencies in the Open Data 2.0 era actively promoted data through online feature stories, social media, events, open data training videos featuring specific agency datasets, and other outlets. Some key informants described the practice of innovative open data managers directing journalists to their open data resources and encouraging their use in news reporting. One state-level key informant noted, “[Public Affairs] has been able to promote the use of open data and encourage journalists to use that…We have the Los Angeles Times…the New York Times using open data out of our site.” Other approaches to facilitate engagement include innovation challenge competitions and Code-a-Thons. In New York, health department officials held a Health Innovation Challenge, a four-month contest for tech companies competing to create software applications using open health data. Federal agencies have also used such approaches, and “there’s a lot of…community engagement where we’re using hack-a-thons,” noted one division director.
Informants described “push” strategies to locate open data in website or mobile application environments where users already spend time, such as Yelp’s restaurant review app. Another example is encouraging the embedding of links to open datasets in other websites, to facilitate other data users’ awareness and use of specific data when they are online in other contexts. This diverges from “pull” approaches whereby users seek, find, and retrieve open data on their own. This is “powerful because it enables data that would otherwise be sitting on an obscure website and maybe not even online, and proactively allowing citizens to access it on platforms they regularly use,” noted one entrepreneur. A state-level senior manager aspired to, “pull [data] out of that portal and put it in places where, particularly, regular consumers, people who are not data savvy, can use the data, view the data, interact with the data, but not have to go to the portal.”
Another strategy is contextualizing data for users with maps, charts, or other data visualizations. As one open data manager observed, “to be honest, I can look at national health data sets and it’s interesting, but I don’t necessarily know what that means for me, as a citizen…or how that impacts my health services.” Providing better context can encourage use, particularly among data users who are not subject-matter experts. Helping data owners articulate messages and data stories can effectively provide context. One state executive leader noted, “that’s the hard part, is to get [data owners] to step away from what they’re doing and look at it from a public point of view who knows nothing about this dataset to…create the datasets that supports the message.” These two strategies support a third, related strategy to “make data more consumer-friendly” through interesting and accessible data visualizations. One example identified as successful is the collaboration between the federal health agencies and developers to create the Health Indicators Warehouse, a web portal providing health-related data whereby “the entire dataset is available through an [application programming interface] and some people are connecting to that and creating very nice mini data visualizations based on that data,” explained one federal executive leader.
When reflecting on their future priorities, some C-level executives expressed strong interest in understanding how health data users use mobile technologies. As the use of mobile devices has surpassed desktop use, key informants aspire to improve their consideration of mobile computing. As one senior manager bemoaned about the agency data portal, “It’s horrible on a mobile device…it’s designed for a desktop…So, I think we just need to meet the consumer need for mobile devices and handheld apps.”
As discussed above, the three eras that encapsulate the U.S. open data movement are each marked by different aspects. Figure 3 depicts each era and summarizes their characteristics, where Era 1 is characterized by early stage OGD activities, Era 2 by catalyzing OGD activities (referred to as “Open Data 1.0”), and Era 3 by later stage OGD activities (referred to as “Open Data 2.0”).
Characteristics of the three major eras of open data’s evolution in U.S. government health agencies.
In describing the evolution of their agencies’ activities to publish open health data, several common characteristics of these early adopters emerged. The first is a clear articulation of the long-term goals, similar to those presented in our conceptual framework. Key informants described potential benefits ranging from short-term access to crucial information, to policy reforms, improved health, and empowered healthcare consumers. For example, one entrepreneur using open health data in a restaurant inspection app stated, “I think the primary goal is to save people’s lives…have a meaningful impact on the problem of foodborne illness and increase the amount of transparency into restaurants and hygienic standards.” A California health data consultant echoed, “I think number one, improving health of Californians, whether that’s through increasing knowledge about something like asthma rates in your neighborhood and then leading hopefully to potential policy changes…improving people’s lives by making information that before wasn’t really accessible to them, very accessible to them and to the public and reporters and others that actually drive policy reform.” Having this clear vision motivated these agencies to progress towards Open Data 2.0.
External partnerships with healthcare foundations, consultants, and local community and civic technology groups were critical in each era. In the first era, they advanced OGD activities before they were formally recognized as part of public health practice. In the second era, Code for America was instrumental in coalescing the civic technology community around OGD. In the third era, key informants perceived that local community and civic technology groups are best positioned to understand the needs and interests of data users and local communities. One executive leader explained, “Given the size of California, it’s hard for us to have a lot of direct interface with a lot of local communities. So, by having that additional engagement and organization of the local communities around health and service data has been very valuable.” Local Code for America “Brigades,” in partnership with local civic tech groups, government, and community members provided invaluable feedback to open data managers about how to modify and prioritize data releases. In the third Open Data 2.0 era, the California Healthcare Foundation’s “Health Data Ambassadors” initiative funded independent contractors to tailor the California Health and Human Service Agency’s open data portal to local health data users’ needs.
Implementation of OGD was facilitated by policy environments that were friendly to opening data. For example, early innovator jurisdictions had state-level legislations that mandated that public records be made publicly available. President Barack Obama’s 2009 executive order catalyzed activity in federal health agencies, as well as some state and local health agencies that were able to build on federal activities.
OGD leaders consistently had executive leaders and champions who provided both support and necessary leadership to set strategic visions. While collecting data, synthesizing information, and sharing findings with communities for action are routine activities, publishing open datasets requires new investments and is potentially threatening for data owners who work in an environment that is highly segregated by disease area. Executives and internal agency champions successfully identified “high value” datasets that would garner attention from the public and benefit the agency. Starting with the datasets commonly requested via FOIA requests led to a tipping point in one agency, after which staff were able to see how proactively publishing open datasets might reduce their workload. Similarly, these leaders and champions were enthusiastic about developing strategies and tools to build momentum among users, which can in turn enhance staff support.
Challenges with engaging OGD users in the Open Data 2.0 era
Key informants described several substantial challenges with engaging potential health data users as they shifted into the Open Data 2.0 era. The most frequently reported challenge is understanding these data users: “I have no idea who is using our open data sets,” stated one federal department head. Other informants speculate that open data is used by journalists, developers, entrepreneurs, and civic hackers, but admit that they “don’t know if we really know.”
A related challenge is that open health data have many presumed audiences, limiting open data managers’ abilities to “meet the various data users where they are.” It is difficult to determine the best way to reach different groups across geographic areas, interests, and skillsets, and present datasets according to data users’ varying needs. Noted one senior manager, “As we try to look at these multi-stakeholder users and their uses, the construction of the portal and how we present the data all starts to take on different shapes and concerns and becomes a very complex problem.”
Another major obstacle is that data are not released in a format that allows engagement. Data granularity is particularly concerning. Many data communities find that “the data is too high in the abstraction level,” notes one consultant; and the data are not “in a granular enough format for it to drive decision making,” notes another.
Discussion
Our study, with its historic evolution focus, illustrates the U.S. OGD movement’s progression through three major eras of activity. Era 1 is marked by early activities around electronic information access. Era 2, or Open Data 1.0, encompasses core activities to develop necessary infrastructure and release data, and was catalyzed by executive orders and state-level events. The current Open Data 2.0 era focuses on improving data quality and engaging users, with the hopes of realizing long-term benefits such as improved health and empowered healthcare consumers. Early adopters who were successful at progressing to the Open Data 2.0 era were able to clearly articulate their long-term goals; developed meaningful partnerships with external non-governmental organizations who could provide financial support, expertise, community organizing, or other benefits; had enabling policy environments; and executive leadership and internal agency champions capable of implementing strategic visions. Despite these successes, there is limited evidence on best practices for engaging diverse data users in the Open Data 2.0 era, and many jurisdictions have not yet transitioned to this later phase.
From a theoretical perspective, our novel conceptual framework of the underlying logic of OGD activities and population health impacts provides a lens for understanding successful OGD initiatives and their potential benefits within specific contexts such as health. A promising theoretical framework for further understanding how to improve the adoption and success of OGD activities is the diffusion of innovations theory (Rogers, 2003). This theory has been noted in some other OGD research studies (Zuiderwijk et al., 2014; Susha et al., 2015a) and particularly helpful for classifying participants in the OGD ecosystem (Susha et al., 2015a). Our findings on mechanisms to facilitate adoption and use of OGD are consistent with earlier work (Gagliardi, et al., 2017; Graves & Hendler, 2013; Kassen, 2013; Khayyat & Bannister, 2017; Susha et al., 2015a, 2015b; Zuiderwijk et al., 2013, 2015b, 2016). For example, other studies recommend: demonstrating the benefits of open data use, increasing potential users’ awareness, developing social strategies to connect open data users, integrating open data use into daily activities, decreasing the effort necessary to use open data, and forging alliances between government data providers, businesses, and citizens to promote commercial value creation (Zuiderwijk et al., 2015, 2016). Further, some studies also suggest local community-level strategies to foster open data engagement (Kassen, 2013; Khayyat & Bannister, 2017), while others focus on technical requirements and prototypes to facilitate open data use (Gagliardi, et al., 2017; Graves & Hendler, 2013; Zuiderwijk et al., 2013). Our study is unique, however, with its focus on health-related OGD and its distinctive OGD ecosystem, and it addresses calls for domain-specific OGD studies (Zuiderwijk et al., 2015).
Our findings illustrate several enabling factors and conditions for successful OGD adoption and use in the health OGD ecosystem. One key enabling factor specific to the health OGD ecosystem was the external partnerships that innovative government health agencies fostered, which formed the basis of collaborations needed to progress OGD activities through the three eras. Challenges of health data include ensuring confidentiality of personally identifiable and Health Insurance Portability and Accountability Act (HIPPA)-protected information, the volume of varied information from diverse sources (e.g., the use of local health departments to collect routine surveillance data, which are subsequently aggregated by state health departments and submitted to the US Centers for Disease Control and Prevention), and a complex healthcare system with sophisticated billing algorithms and payer mixes which vary across U.S. states. Consequently, a high level of technical skills and content expertise is required to effectively interpret and use health data. As external partners, various healthcare foundations, consultants, and civic technology groups offer a skillful, nuanced understanding of health data, which in turn enhances health OGD’s evolution and adoption by data users. Government health agencies seeking to establish and advance their OGD initiatives are recommended to seek out and foster such external partnerships. For instance, the California Healthcare Foundation’s “Health Data Ambassadors” program is a unique example of an external partner that helped a government health agency to advance its OGD initiatives by working with local health data users to identify their health data needs and effectively contextualize health OGD. Another strategy for health OGD engagement is in-depth guidance for both healthcare consumers and providers on how to best use health OGD for shared decision-making regarding medical procedures, treatments, facilities, and other aspects of healthcare delivery where collaboration between consumer and provider is ideal.
Most government open data producers and managers appreciate open health data’s potential. They strongly desire releasing more data, promoting its use, and developing feasible strategies to engage users. As OGD diffuses more broadly, government agencies could seek to build upon early innovators’ strategies to adopt OGD practices within their agencies and engage OGD users. As OGD continues to evolve, an additional area for attention is the mobile realm, given the ubiquity of mobile devices and their surpassing of desktop computers as the primary technology for accessing the Internet. Key informants identified improving user experiences on mobile devices as one priority for the future.
Conclusion
The objective of this study was to identify how innovative government jurisdictions that were early adopters of OGD, can move beyond basic data publishing toward OGD activities that involve more purposeful engagement with and use of OGD – elements crucial for OGD success. Toward this aim, we traced the evolution of OGD publication among U.S. government health agencies that were early adopters of OGD. Study findings illustrate how health agencies evolved through several OGD stages, from early activities to set up basic infrastructure and publish datasets toward a more advanced “Open Data 2.0” era focused on engaging users with OGD. Findings further reveal that Open Data 2.0 emphasizes a demand-driven, meaningful approach for data engagement, and is critical to facilitating data use and achieving OGD objectives. We also identified key data user engagement strategies for government agencies that have advanced to a later stage of their OGD programs which include fostering local community engagement, contextualizing data using data visualizations, and “push” techniques to get OGD directly to users.
A key contribution of this work is its tracing of the history and evolution of OGD in the specific domain of health, via numerous interviews with OGD early adopters, to provide a clearer picture of how OGD goals and benefits might be achieved. We also present a novel conceptual framework that illustrates the implicit logic underlying OGD activities in the health domain and their anticipated outcomes and impact. This framework could be adapted for other domains to help visualize how successful OGD initiatives might unfold.
This study has several limitations. The first is the possibility of researcher influence on study participants as well as interviewer bias (Maxwell, 2013; Trochim & Donnelly, 2008). We minimized researcher influence by avoiding posing leading questions and analyzing discrepant evidence and negative cases. Interviewer bias was minimized using two researchers to review transcripts. The key informants were early innovators; and, although a range of participants were recruited, individuals with optimistic views of open data are over-represented. We explicitly took a positive deviance approach to our sampling and recruitment, and future work could explore perceptions and outcomes among “late majority” or “laggard” jurisdictions that have been slow to develop robust OGD platforms.
Findings suggest several areas for further research to enable progress towards the long-term objectives of OGD. The first is examining other data communities beyond health to understand the wider open data ecosystem and identify strategies that have been effective elsewhere to develop robust OGD platforms and facilitate user engagement. Local open data managers and advocates are most attuned to the needs and intended use of their local data users and promoting open data at the local level is a promising opportunity, an approach supported by earlier work (Kassen, 2013; Khayyat & Bannister, 2017). As local communities in advanced stages of OGD deployment implement novel user engagement strategies, further work could evaluate which activities are most successful for replication. Contextualizing data, making it more user-friendly, and facilitating data storytelling with visualizations is a highly promising user engagement and confidence-building strategy also supported by earlier work (Gagliardi, et al., 2017; Graves & Hendler, 2013), and studies on the effectiveness of these strategies are recommended. Following key informants’ stated interests in mobile options for open health data, along with limited existing research on the role of mobile technologies in open data (Charalabidis et al., 2015; Hossain et al., 2016; Huijboom & Van den Broek, 2011; Safarov et al., 2017), future studies on open data engagement via mobile technologies are warranted.
Footnotes
Acknowledgments
We are grateful to the study participants who provided invaluable perspectives on open data. We thank Dr. J. Ramon Gil-Garcia, Dr. Natalie Helbig, Dr. Xiaojun (Jenny) Yuan, and Dr. Luis Luna-Reyes for comments on earlier versions of this paper.
Appendix
What is your position title and can you briefly describe your main duties? As part of your job, how do you interact with public health data? Are you responsible for managing a specific dataset? Are you involved with management and overseeing data collection and analysis? As part of your job, how are you interacting with open data? Are you responsible for managing a specific dataset that is being released as open data? Are you involved with the management and/or oversight on health data releases?
What is your pie-in-the-sky vision of how open data could improve New York? What are your hopes for what could happen? What do you hope that researchers and other users will do with the data?
What are the major challenges that you are encountering in releasing open data? (What are the key political challenges? What are the key management challenges? What are the primary technical challenges? What are the specific policies that pose challenges to you in releasing health data? What are the challenges in managing end-users’ expectations of what [agency] can provide?) Are there special challenges to preparing the metadata that is posted to the platform? In our own conversations with researchers, we have heard them express a desire for consistent metadata, variables, and keywords. What are barriers to standardizing these attributes? Among these challenges we just discussed, which is the most difficult to overcome? In addition to the challenges we discussed, are there other concerns that you or other agency staff have about releasing open data? What could go wrong? (Do you have concerns about the datasets being misinterpreted/not interpreted within the proper context? Do you face challenges due to limited staff and other resources?)
What resources and other capabilities does [agency] need in order to release open data? To what extent do you think [agency] has sufficient capability to release open data? What are some specific gaps in the capabilities required to release data? What would be required to address these gaps?
Have you used any of the open data sites for your own purpose? If so, what for?
(If yes) Why did you use the open data site rather than getting the data directly from a colleague within the agency?
To what extent do you think that researchers currently know about and use these data? What factors are limiting the extent to which researchers are currently using open data? Besides researchers, what other user communities is [Health Data NY/Open-NY/healthdata.gov] targeting? (What is the target market for open data? Who are the other important stakeholders? How do researchers rank on this list of users?) In what ways does [Health Data NY/Open-NY/healthdata.gov] change the traditional interaction between [agency] and health researchers? How does [agency] traditionally interact with researchers? How does the open data platform change this interaction? Does [Health Data NY/Open-NY/healthdata.gov] lead to different opportunities for collaboration with researchers?
Before we finish our conversation, do you have any other comments about releasing open data at [agency] that we have not yet discussed? Based on our conversation today, is there anyone else you recommend we speak to?
Qualitative Interview Guide
Primary Interview Questions
Opening Questions
What is your position title and can you briefly describe your main duties? How did you initially become involved with the open health data movement?
How would you define “community engagement” in your own words? What are the goals of community engagement? Who are the individual consumers and community members currently engaging with open health data? (e.g. civic hackers/ developers, journalists, entrepreneurs?); Who are the individual consumers and community members you would like to see engaging with open health data? (e.g. average citizens, others?) What does “community engagement” mean in the context of open health data? What is the goal of such community engagement around open health data? Why should individual consumers and communities (groups of consumers) engage with open health data? Why is engaging with open health data of importance to consumers and communities (in your opinion)? How is community engagement different (or similar) to the concepts of “consumer engagement” and “consumer empowerment”? In general, what are some mechanisms for engaging individual consumers and communities with open health data? (What have you seen? What would you like to see?)
What is the role of [agency] in the open health data ecosystem overall/nationally/internationally? How do you and [agency] connect with various communities? What is the process to connect with and engage individuals and community groups with open health data? What are the key goals of [agency] around community engagement with open health data? What are you specifically trying to achieve? What is your ideal vision for community engagement around open health data? What are the feedback mechanisms between [agency] and community members regarding community members’ interests and needs around open health data? How do you elicit feedback from community members and provide responses? What happens next with the feedback?
How is CA engaging the community around open health data? (e.g. hackathons, visualizations, roundtables, brown bag events, surveys, journalists, social media) Can you describe the CA’s/CHHS’s open health data initiatives and how you are involved? Who is the audience for the community engagement efforts in CA? (e.g. journalists/media, civic technology community, entrepreneurs, etc.) Are there certain audiences you would consider as particularly “key” and/or “active”? How can various target audiences best engage with CA open health data? What are the opportunities for the average citizen (someone with no specific technical/data analysis skills) to engage with open health data (and how are they currently engaging)?
What are the key barriers and challenges you face as you/[agency] work toward deeper community engagement with open health data? a. What are some of the specific challenges in engaging with local/county health departments, other community groups, and individual consumers? What resources and other capabilities do you/[agency] need in order to successfully develop, launch and manage community engagement initiatives around open health data? What are some of the lessons you’ve learned so far in your community engagement initiatives around open health data?
What are some of your/[agency’s] greatest successes in engaging individual consumers and communities with open health data? What is your pie-in-the-sky vision of how open health data could improve [California/the nation]? What are your hopes for what could happen? What do you hope that the various audiences for open health data (e.g. researchers, entrepreneurs, journalists/media, local health departments, average citizens/consumers, others) will do with the data?
Before we finish our conversation, do you have any other comments about community engagement and open health data in CA/at CHHS…at [agency] that we have not yet discussed? Based on our conversation today, is there anyone else you recommend we speak to?
“Consumer Engagement” Interview Questions
Opening Questions
Coding Guide – Themes, Codes and Descriptions
Theme
Code
Description
Historical Context
New York State Open Data History
Discussions by key informants about the historical context, emergence, and evolution of open data in New York State (primarily open health data per HDNY, but, also data in general per Open New York)
Federal Government Open Data History
Discussions by key informants about the historical context, emergence, and evolution of open data at the federal level
State of Washington Open Data History
Discussions by key informants about the historical context, emergence, and evolution of open data in Washington State
State of California Open Data History
Discussions by key informants about the historical context, emergence, and evolution of open data in California
City of Chicago Open Data History
Discussions by key informants about the historical context, emergence, and evolution of open data in Chicago
Timeline Candidates
Listing of potential candidate events for the visual timeline of open health data history
Consumer Engagement
Why Open Health Data?
Discussions by key informants about their reasons for being proponents of open health data; and, their concern with the issue of consumer engagement
What is Consumer Engagement?
Key informants’ thoughts on what consumer engagement is and what it is supposed to accomplish
Emergence of Consumer Engagement
Discussions by key informants regarding the shift in open data activity toward consumer engagement
Mechanisms for Engaging Consumers
Discussions by key informants about specific examples of consumers engaging with open health data
Benefits/Value of Consumer Engagement
Discussions by key informants about the perceived benefits and value data consumers can glean from engaging with open health data
Consumer Engagement Challenges/Issues
Discussions by key informants about specific obstacles and/or issues interfering with consumers’ engagement with open health data
Strategies to Engage Consumers
Discussions by key informants about specific strategies to engage consumers with open health data
Consumer Engagement Analytics
Discussion by key informants re: the use of digital analytics tools to assess consumer engagement with the open health data portal and open health datasets
Consumer Groups
An accounting of the various consumer groups mentioned by key informants
Next Steps
Plan/Idea
Discussions where key informants expressed an explicit suggestion re: next steps that could be taken with open data initiatives, particularly regarding facilitating consumer engagement with open health data
Sentiment
Discussions where key informants expressed sentiments about next steps and the future of open data
Evolution of Open Data
Discussion by key informants about the evolution of open data