
Abstract
Background:
Available therapies for Alzheimer’s disease (AD) can only alleviate and delay the advance of symptoms, with the greatest impact eventually achieved when provided at an early stage. Thus, early identification of which subjects at high risk, e.g., with MCI, will later develop AD is of key importance. Currently available machine learning algorithms achieve only limited predictive accuracy or they are based on expensive and hard-to-collect information.
Objective:
The current study aims to develop an algorithm for a 3-year prediction of conversion to AD in MCI and PreMCI subjects based only on non-invasively and effectively collectable predictors.
Methods:
A dataset of 123 MCI/PreMCI subjects was used to train different machine learning techniques. Baseline information regarding sociodemographic characteristics, clinical and neuropsychological test scores, cardiovascular risk indexes, and a visual rating scale for brain atrophy was used to extract 36 predictors. Leave-pair-out-cross-validation was employed as validation strategy and a recursive feature elimination procedure was applied to identify a relevant subset of predictors.
Results:
16 predictors were selected from all domains excluding sociodemographic information. The best model resulted a support vector machine with radial-basis function kernel (whole sample: AUC = 0.962, best balanced accuracy = 0.913; MCI sub-group alone: AUC = 0.914, best balanced accuracy = 0.874).
Conclusions:
Our algorithm shows very high cross-validated performances that outperform the vast majority of the currently available algorithms, and all those which use only non-invasive and effectively assessable predictors. Further testing and optimization in independent samples will warrant its application in both clinical practice and clinical trials.
Keywords
INTRODUCTION
Alzheimer’s disease (AD) is a neurodegenerative disease characterized by progressive loss of memory and functional abilities that leads to severe dementia and eventually death. It is the most common neurodegenerative disease and currently affects 47 million people worldwide, being the top cause for disabilities in later life. The global cost of AD and dementia is estimated to be $818 billion, which is nearly 1% of the entire world’s gross domestic product. These numbers are projected to increase, with a global expected cost of $2 trillion by 2030 and more than 131 million people suffering from this disorder by 2050 [1].
No cure or disease modifying treatment is currently available for AD and current treatment regimens only provide symptomatic relief [2]. By the time AD is clinically diagnosed, there is considerable multi-system degeneration that has occurred within the brain. As such, emerging treatments will likely have the greatest impact when provided at the earliest possible stage of the disease process [3, 4].
Therefore, the prompt identification of subjects truly at high risk of developing AD is a crucial issue still without a solution.
Mild cognitive impairment (MCI) is a condition characterized by changes in cognitive capabilities beyond what is expected for the subject’s age and education that are sufficiently mild that they do not interfere significantly with its daily activities. Individuals with such condition are at high risk of converting to dementia and especially AD in the next few years (20–40% of conversion rate by three years, with a lower rate evidenced in epidemiologic samples than in clinical ones [5, 6]).
Furthermore, even subjects with an intermediate state between normal cognition and MCI, i.e., the so called premild cognitive impairment (PreMCI) stage [7], are more likely to progress to a formal diagnosis of MCI or dementia within a two- to three-year period, and this might represent the earliest clinically definable stage of AD [8].
However, some subjects with MCI have shown to remain stable over years or even to recover to cognitively normal with no further progression to AD. This holds even more true for subjects with PreMCI than for those with MCI [8]. Different health problems other than neurodegenerative diseases can cause transient MCI and PreMCI conditions and these do not necessarily lead to AD [9]. Thus, sole reliance on these precursor conditions are not enough to provide a precise identification of those subjects at true risk of later developing AD.
Beyond MCI and preMCI, several attempts to identify subject’s characteristics that may improve the prediction of progression to AD have been done. Investigations have regarded a vast variety of potential predictors, such as sociodemographic and clinical characteristics, cognitive performances, neuropsychiatric symptomatology, cardiovascular indexes, dietary and life habits, structural and functional neuroimaging investigations, gene typization, and several biomarkers assessed both in the cerebrospinal fluid and peripherally [10–16].
It is increasingly recognized that better predictive capability can be achieved by models that simultaneously exploit the information coming from several predictors, and machine learning can be used to create such models. This is a fast-growing field at the crossroads of computer science, engineering, and statistics “that gives computers the ability to learn without being explicitly programmed” [17]. Machine learning techniques use known training examples to create algorithms able to provide the best possible prediction when applied to new cases whose outcome is still unknown. Machine learning has been applied in the attempt to predict MCI-AD conversion in more than 50 published studies. Different combinations of the above-mentioned predictors were applied to various machine learning techniques in the attempt to predict conversion from MCI to dementia from one year to even five years after the baseline assessment. The results achieved vary broadly among studies, ranging from some that achieved performances just above the chance to a few showing high accuracy levels [18–26].
Despite this huge research effort, no gold-standard algorithm is available to predict progression in those at risk for AD and clinical translation is still lacking. All the “top performing” algorithms have not been tested in further independent samples thus far, and, in addition, certain predictors employed by some models may represent a significant barrier to their clinical adoption due to their high costs and/or invasiveness (e.g., fludeoxyglucose positron emission tomography scans or lumbar puncture).
Considering all the above-mentioned issues, the current study aims to be the first step in the development of a clinically-translatable algorithm for the identification of the conversion to AD in subjects with either MCI or PreMCI. To be quickly adoptable in clinical practice, the algorithm should include only non-invasive predictors that are either already routinely assessed or effectively introducible in clinical practice, and achieve a high predictive accuracy. Considering the evidence available so far, we hypothesize that the information provided by sociodemographic characteristics, clinical and neuropsychological tests, cardiovascular risk indexes, and clinician-rated level of brain atrophy might allow achieving this. In this investigation, a series of machine learning algorithm will be developed and cross-validated within a sample of patients with either MCI/PreMCI whose diagnostic follow-up was available for at least three years after the baseline assessment. Out-of-the-sample testing of the best algorithm in independent samples of MCI/PreMCI patients will be performed in a further phase.
MATERIALS AND METHODS
Subjects
Data regarding 90 subjects with MCI and 94 subjects with PreMCI at baseline and with available diagnostic follow-up assessments for at least three years were included in the study.
These are part of a dataset that collects several patients recruited in a study investigating longitudinal changes associated with MCI and normal aging, which involved community volunteers as well as subjects recruited from the Memory Disorders Clinic at the Wien Center for Alzheimer’s disease, the Memory Disorders at Mount Sinai Medical Center, Miami, Beach, Florida, and the community and memory disorders center at the University of South Florida which were collaborative partners in an Alzheimer’s Disease Research Center (ADRC). All subjects at each of the sites had a common clinical and neuropsychological battery as described below.
Considering the final aim of developing a predictive algorithm to be used in clinical practice, no other inclusion or exclusion criteria were applied beyond these diagnostic criteria. Subjects were classified as converters to probable AD (cAD; n = 48, 26.1%) if they presented a Dementia syndrome by DSM-IV-TR criteria [27] during at least one of the follow-up assessments occurred within three years from the baseline investigation, and satisfied the National Institute of Neurological and Communicative Disorders and Stroke/Alzheimer’s Disease and Related Disorders Association criteria for AD [28]. Otherwise they were classified as non-converters to AD (NC; n = 136, 73.9%).
The study was conducted with the ethical standards of the relevant national and institutional committees on human experimentation and with the Helsinki Declaration of 1975, as revised in 2008. All subjects gave their written informed consent to the use of their clinical data for scientific research purposes.
Feature extraction
Considering our aim to employ only predictors that are non-invasive and that are either already routinely assessed or cost-effectively introducible in clinical practice, we decided to focus on information available in our dataset that regard diagnostic subtypes, sociodemographic characteristics, clinical and neuropsychological test scores, cardiovascular risk indexes, and levels of medial temporal lobe brain atrophy in the hippocampus (HPC), entorhinal cortex (ERC), and perirhinal cortex (PRC) as assessed by a clinician-rated Visual Rating Scale (VRS) [29].
Among all the variables related to these domains, some of them were not assessed in all recruited subjects. Variables that had more than 20% missing values in either the cAD or NC groups were discarded. The following pieces of information were finally used.
Sociodemographic characteristics
Gender, age (in years), and years of education calculated by years of schooling and highest degree obtained.
MCI subgroups
Subjects were classified as MCI if they presented subjective memory complaints by the participant and/or or collateral informant, evidence of decline from clinical history and evaluation. All of the MCI patients had a global Clinical Dementia Rating (CDR) score [30] of 0.5. Those who had one or more memory measures (including the Hopkins Verbal Learning Test Revised, the Fuld Object Memory Evaluation, Logical Memory Delay and Visual Reproduction of the WMS-IV, Trial Making Test, Category Fluency, Letter Fluency and Block Design of the Wechsler Adult Intelligence Scale – Version 3) 1.5 standard deviation or greater below expected normative values were defined as belonging to the amnestic mild cognitive impairment (aMCI) subgroup. MCI subjects with non-memory impairment only were defined as non-amnestic mild cognitive impairment (non-aMCI).
PreMCI subgroups
As defined by Loewenstein and colleagues [8], those individuals who had a global CDR of 0 but had memory or non-memory neuropsychological deficits as described above were diagnosed as Premild Cognitive Impairment – neuropsychological subtype (PreMCI-np). Participants who obtained a global CDR of 0.5 and had within normal limits performance on neuropsychological testing were classified as Premild Cognitive Impairment – clinical subtype (PreMCI-cl).
Clinical scales
The CDR [30] is a 5-point scale (0 = none; 0.5 = very mild, 1 = mild, 2 = moderate, 3 = severe) used to characterize six domains of cognitive and functional performance in AD and related dementias: Memory, Orientation, Judgment & Problem Solving, Community Affairs, Home & Hobbies, and Personal Care. The rating is obtained through a semi-structured interview of the patient together with other informants (e.g., family members). The global score was used in the analyses. The memory sum score of a modified informant-based version of CDR (ModCDR-M) was also available and used (range 0–12) [31]. The Geriatric Depression Scale (GDS) is a 30-item yes-no self-report assessment used to identify depression in the elderly [32] and the total score was included in the current analyses (range 0–30).
Visual Rating Scale for brain atrophy
HPC, ERC, and PRC atrophy levels were assessed with a 0–4 VRS [29]. This is an adaptation from the original Scheltens’ VRS for the global assessment of medial temporal atrophy [33]. VRS ratings for HPC, ERC, and PRC were performed in each hemisphere on a magnetic resonance imaging (MRI) image of a standardized coronal slice, perpendicular to the line joining the anterior and posterior commissures, intersecting the mammillary bodies and on adjacent slices. All these 6 VRS measures were separately included as predictors in this study. Ratings are based on a five-point scale: 0 = no atrophy, 1 = minimal atrophy, 2 = mild atrophy, 3 = moderate atrophy, and 4 = severe atrophy. A computer interface provides a library of reference images defining the anatomical boundaries of each brain structure and depicting different levels of atrophy. The whole rating usually takes 5 to 6 minutes per subject [34] and excellent inter-rater (kappa, 0.75 to 0.94) and intra-rater (kappa, 0.84 to 0.94) agreements have been reported [29, 34]. VRS measures of HPC and ERC have already proved to be predictive of later conversion to AD in MCI patients [35].
Neuropsychological tests
The Hopkins Verbal Learning Test Revised – Total Recall (HVLTR-R) and Hopkins Verbal Learning Test Revised – Delayed Recall (HVLTR-D) scores [36] measuring the verbal learning and memory, the Semantic Interference Test – Total Retroactive (SIT-RT) and Semantic Interference Test – Total Recognition (SIT-RC) scores [37] measuring memory function and interference, and the Trial Making Test – version A (TMT-A) and Trial Making Test – version B (TMT-B), both errors and time [38], measuring visual-motor coordination and attentive functions were considered. Moreover, the Digit-Symbol-Coding Test (DSC), the Block Design (Raw Score) and the Similarities tests of the Wechsler Adult Intelligence Scale – Version 3 [39], which investigates respectively associative learning, visuospatial function and verbal comprehension, and the Delayed Visual Reproduction Test (DVR) and the Logical Memory Test – Immediate Recall (LM-I) and Logical Memory Test – Delayed Recall (LM-D) scores of the WMS-IV [40], which measure visual and verbal memory, were also included.
Cardiovascular risk indexes
Subjects were assessed by physician regarding heart rate, presence or absence of hypertension, high cholesterol levels, diabetes, history of tobacco use, history of myocardial infarction, history of coronary bypass/angioplasty, and history of stroke/transient ischemic attack.
Continuous variables were standardized and categorical variables were coded in order to optimize the number of classes. Categorical cardiovascular risk indexes were re-coded dichotomously and the diagnostic variable was the only polytomous variable, indicating the four diagnostic subgroups (aMCI, non-aMCI, PreMCI-np, PreMCI-cl). In the end, 26 continuous, 9 dichotomous categorical, and one four-class categorical features were used. The full list is available in Table 1.
Descriptive statistics
S.D., standard deviation; EN, Elastic Net; RFE, recursive feature elimination; N, number of subjects; aMCI, amnestic mild cognitive impairment; non-aMCI, non-amnestic mild cognitive impairment; PreMCI-cl, premild cognitive impairment – clinical subtype; PreMCI-np, premild cognitive impairment – neuropsychological subtype; WAIS-III, Wechsler Adult Intelligence Scale – Version 3; WMS-IV, Weschler Memory Scale – Fourth Edition; VRS, Visual Rating Scale; y, years; s, seconds; bpm, beat per minute.
123 subjects have no missing data for all these variables (cAD = 30, 24.39%; NC = 93, 75.61%) and constitute the final sample used in the current study.
Machine learning techniques
Several machine learning procedures exist to solve classification problems. In the current study, we decided to proceed with the following supervised techniques.
All analyses were parallelized on a Microsoft® Windows® server equipped with two 6-cores X5650 Intel® Xeon® 2.66 GHz CPUs and were performed in R [44], using the implementation of the machine learning techniques available in the caret package [45].
Elastic Net
EN is a regression method that adds two types of penalties during the training process. These penalties are the L1 norm of the regression coefficients, as used in LASSO (least absolute shrinkage and selection operator) regression
Elastic Net with polynomial features
Considering the explanation above, EN models including degree three polynomials of the continuous features were also trained.
Support vector machine
Intuitively, in this algorithm, each case can be viewed as a point in n-dimensional space, where n is the number of features. During the learning process, the linear hyper-plane that optimize the separation of the two classes in such multi-dimensional space is found. New examples are then “plotted” into that space and predicted to belong to a class based on which side they fall on. However, this would allow only to solve so-called linearly separable problems, likewise to what logistic regression can achieve, but SVMs can also perform non-linear classification, transforming the original feature space to a higher dimensional space (i.e., creating several new features from the original ones) where the classification problem may better result linearly separable. To perform this transformation in a computationally efficiently manner, the so-called “kernel trick” can be applied, which avoids the explicit transformation that is needed to get linear learning algorithm to learn to perform nonlinear classification. Instead, it enables to operate in an “implicit” feature space without ever computing the coordinate of each case in the new higher dimensional space, but by simply computing the distance of all pairs of cases only considering the original features. In this study, we used the radial basis function (Gaussian) kernel, that is
Gaussian processes (GP)
GP is a method based on Bayesian theory that can be applied in solving both regression and classification problems, modelling the relationship between the inputs and the outputs following a Bayesian probabilistic approach. A Gaussian process can be viewed as a distribution over functions, and inference consists of applying Bayes’ rule to find the posterior function distribution that best approximates the training data. The covariance function matrix of the model can be substituted with a kernel matrix, which represents the counterpart of the “kernel trick” seen before. The radial basis kernel was used also for GP and again this kernel has σ as parameter that requires optimization. A detailed explanation of GP can be found in [43].
k-Nearest Neighbors (kNN)
In the kNN, at first the distances (i.e., the dissimilarity) between a new case and all known examples (i.e., those included in the training set whose output is already known) is calculated. In this analysis, the Euclidean distance was used as distance metric, that is
Cross-validation procedure
All the machine learning techniques used in this study have different so-called hyper-parameters that allow a different tuning of the algorithm during the training process. These are λ1 and λ2 in EN and EN-poly, σ and C in SVM, σ in GP, and k in kNN. We trained each model, when possible, with up to 200 random hyper-parameter configurations. Different configurations of these parameters lead to algorithms with different predictive performances. Specifically, we are interested in achieving the best possible performance when the algorithm is applied to new cases that are not part of the training sample.
Considering the small sample size available at this phase, we used cross-validation to provide an estimate of such generalized performance. In cross-validation, the train sample is divided in several folds of cases. Training is iteratively performed with the remaining cases not included in each fold and then the algorithm is tested on the fold cases. Several different cross-validation protocols exist (e.g., n-fold, repeated n-fold, leave-one-out-cross-validation). Recent simulation studies found the rarely applied leave-pair-out cross-validation (LPOCV) protocol to be the best choice when the sample size is limited, being nearly unbiased compared to other commonly applied options such as leave-one-out-cross-validation that instead leads to biased estimate [46, 47]. In our study, LPOCV implies to use as folds all possible combinations made of one cAD and one NC. The flaw of LPOCV is its high computational expensiveness. For each attempted hyper-parameter configurations, the training process is performed excluding each defined pair (2790 pairs in the current study) from the training sample and calculating the performance of the algorithm in this left-out pair. Finally, the average performance metric is taken as estimate of the generalized performance of the algorithm created with that particular technique and hyper-parameter configuration.
The performance achieved during the LPOCV procedure will be considered as a first estimate of the performance for the algorithm when applied to new cases. A test of the model that showed the best LPOCV performance will be performed as a future step using a fully independent dataset. Even if this further investigation is usually lacking for machine learning models developed in the medical field, this will provide a more accurate estimate of the algorithm predictive performance when applied to clinical samples.
Performance metrics
As primary performance metric, the Area Under the Receiving Operating Curve (AUC) was used. At first the algorithms output a continuous prediction score (range: 0–1; the closer to 1 the higher the predicted risk of conversion for that subject) and then the dichotomous prediction of cAD/NC is finally made setting a cut-off score (cAD if above or equal to the cut-off score, NC if below). The AUC value can be interpreted as the probability that a randomly selected cAD subject will receive a higher output score than a randomly selected NC subject, no matter which cut-off is applied to the output score. The AUC is 0.5 when the algorithm makes predictions at random and 1 in case it is infallible. Considering the LPOCV protocol applied in the analyses, the cross-validated AUC was calculated with the following formula:
The algorithm with the highest performance will be compared to all other algorithms with a paired-sample t-test calculating the standard deviation of the AUCs difference with the 10000 stratified bootstrap-generated samples, based on what proposed in [49].
Moreover, the cross-validated levels of specificities and balanced accuracy values when sensitivity approached to 0.95, 0.9, 0.85, 0.8, 0.75 were calculated. The cut-off applied to the algorithm output scores was progressively increased starting from 0 and the thresholds providing the closest sensitivity to the aforementioned ones was used to calculate the two other values. The sensitivity and specificity at the best achieved balanced accuracy were also calculated.
To provide distinct predictive performances in the two subpopulations and ease the comparison with previously published models that usually addressed only MCI patients, all performance metrics were also separately calculated in the MCI and PreMCI subsamples. Only the cross-validation pairs containing two MCI and two PreMCI subjects (one cAD and the other NC) were used. Considering that only three converting PreMCI subjects were available, results in the PreMCI subsample should be taken just as a preliminary evidence.
The advantage of using AUC, sensitivity, specificity and balanced accuracy over other performance metrics (e.g., accuracy, positive predictive value, negative predictive value) is that they are independent from the prevalence of the two outcome classes. Given that the observed rate of conversion to AD may not be the same in different independent samples, these metrics provide more stable performance estimates and ease the comparison with the performance achieved in other studies.
Feature selection
Training was initially performed including all the 36 features. Only EN and EN-poly automatically operate a selection of features that are finally included in the algorithm. Excluding non-relevant and redundant features and reducing the dimensionality of the algorithm feature-space usually brings to better generalized predictive performance. SVM, GP, kNN, and LR do not automatically operate any feature selection during the training and so, for these techniques, we re-performed the training and hyper-parameter optimization process with two reduced set of features.
At first, we included only those features selected by the final EN model. Then, we applied a recursive feature elimination (RFE) method with Random Forest as implemented in the rfe function of the caret R package [45]. Detailed description of the algorithm can be found at the following webpage: http://topepo.github.io/caret/recursive-feature-elimination.html. In brief, a Random Forest model is initially trained with all features in each cross-validation fold. Features are ranked according to their importance through a permutation procedure and then the training is re-performed iteratively removing the least ranked feature until when all features have been removed. The optimal number of features is selected according to the average performance of all cross-validated folds. At the end, the model is trained with the whole sample, features are ranked and those falling in the previously identified optimal number of features are retained. As different initial conditions may lead to different final feature subsets, we performed the RFE procedure 100 times with random initialization. We finally included only those features that were selected in more than 50 of the 100 repetitions and we used these to train the SVM, GP, kNN, and LR models.
The same paired-sample t-test with bootstrap resampling was also used to test the significance of the change in the LPOCV AUC achieved applying the two aforementioned feature selection procedure compared to including all the features.
Feature importance
While ranking the importance of features in linear models is straightforward (e.g., in GLM and EN), this is a particularly uneasy task in more complex models (e.g., non-linear kernel SVM and GP). The latter are sometimes referred as black-box models, making it hard-to-“impossible” to extract the rules that relate each feature to the outcome. Moreover, different strategy exists for different techniques and a gold-standard procedure has not been defined yet.
To provide a general ranking of the importance of the predictors, the LPOCV AUC of each of the 36 features when taken individually was calculated. This gives a metric of importance for each predictor that is independent from both the applied technique and all other predictors. The 95% CI with the abovementioned stratified bootstrap procedure were also calculated. Feature importance indicated by the LPOCV AUC was compared with the selection of features operated by the two feature selection procedures applied in our analyses.
RESULTS
Final analyses required approximately 23 hours of non-stop computations (excluding exploratory and preliminary analyses, and debugging). Descriptive statistics of each feature in both the cAD and NC groups are reported in Table 1. Statistics of continuous features are reported before the standardization was applied.
Cross-validated predictive performance of algorithms
The cross-validated AUC for each of the final models is reported in the Table 2 and Fig. 1. SVM, GP, and kNN globally achieved better performances then the techniques that cannot model the interaction between the features, i.e., LR and EN. The latter performed generally poorly, even when feature selection strategies were applied to LR and polynomial features were inserted in the EN. LR without feature selection, which was used as reference technique, resulted very poorly performing, being the worst performing model and the sole one showing an AUC below 0.8 (AUC = 0.692; C.I. 95% bootstrap = 0.598, 0.788).
Leave-Pair-Out-Cross-Validation AUC of the final algorithms
AUC, area under the receiving operating curve; LPOCV, leave-pair-out cross-validation; CI, confidence interval; EN, Elastic Net; EN-poly, Elastic Net with Polynomial features; GP, Gaussian Processes; kNN, k-Nearest Neighbors; LR, logistic regression; RFE, recursive feature elimination; SVM, support vector machine.
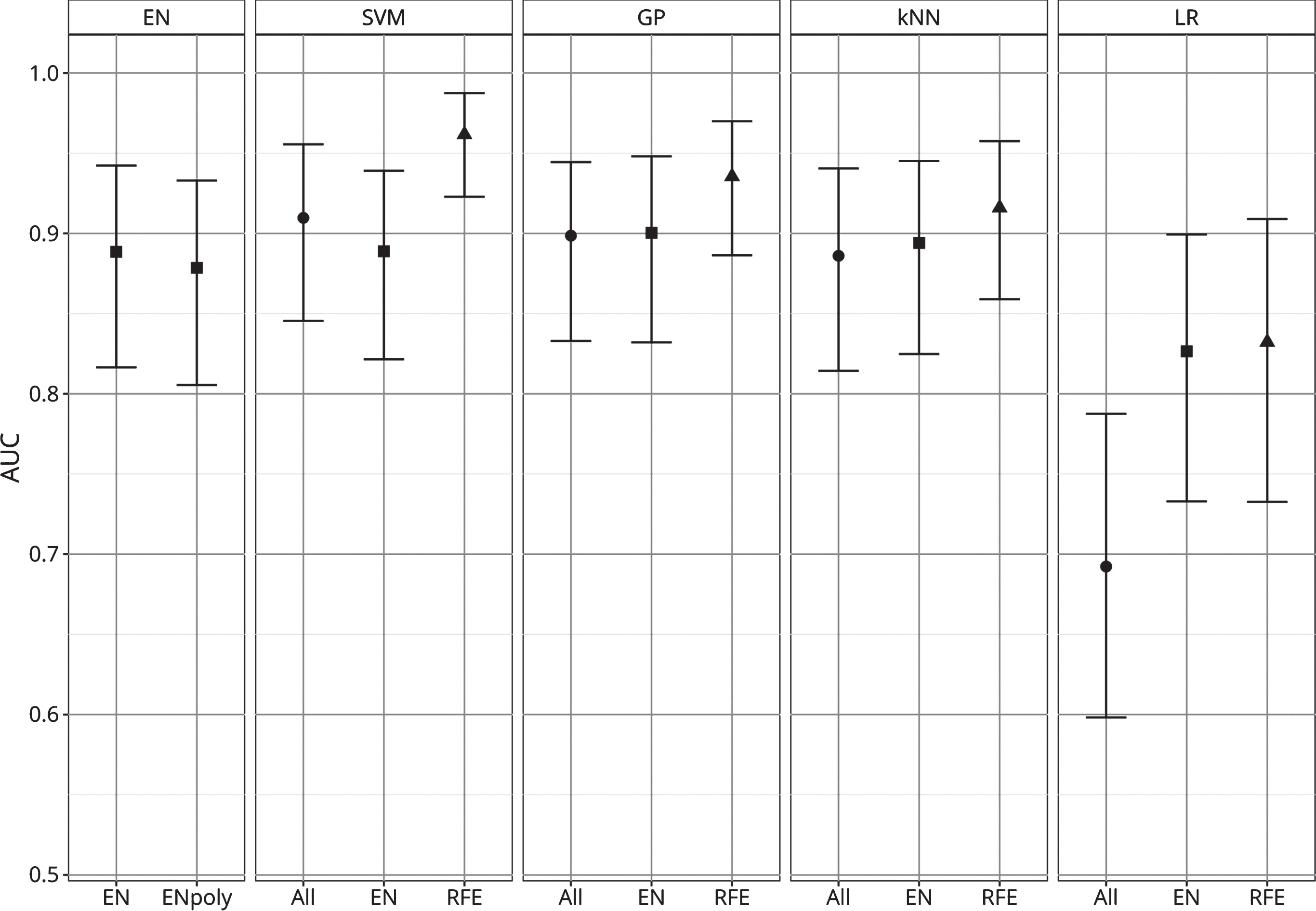
AUC of algorithms. The figure indicates the cross-validated AUC and its 95% bootstrap CI for each algorithm. Algorithms are grouped according to the machine learning techniques. The different feature selection procedure applied are indicated below, as well as by different point shapes (circle = all features; square = features selected via EN, triangle = features selected via RFE).
SVM with the features selected by the RFE procedure is the technique that achieved the highest cross-validated AUC (AUC = 0.962; C.I. 95% bootstrap = 0.923, 0.987). The results of the paired-sample t-test with stratified bootstrap resampling evidenced that the AUC of this model was statistically significantly higher (p < 0.05) than all other algorithms, except for the algorithm ranked second (SVM RFE versus GP RFE: p = 0.074). The model achieved high predictive performances also when the two subgroups were considered separately, although lower in the MCI subsample (AUC = 0.914; C.I. 95% bootstrap = 0.822, 0.975) and very high in the PreMCI subsample (AUC = 0.994; C.I. 95% bootstrap = 0.932, 1).
The cross-validated levels of specificity and balanced accuracy when sensitivity approached 0.95, 0.9, 0.85, 0.8, 0.75, as much as the sensitivity and specificity at the best achieved balanced accuracy are reported in Table 3. Considering the whole sample of both MCI and PreMCI subjects, the best achieved cross-validated balanced accuracy is 0.913 (sensitivity = 0.956, specificity = 0.871). Again, performances were still high but lower in magnitude in the MCI subsample, with a best balanced accuracy of 0.874 (sensitivity = 0.880, specificity = 0.867). Instead, preliminary results in the PreMCI subsample presented very high performances, with a best balanced accuracy of 0.980 (sensitivity = 1, specificity = 0.960).
Performance metrics of the best model, SVM with features selected by RFE
AUC, area under the receiving operating curve; MCI, mild cognitive impairment; PreMCI, premild cognitive impairment.
Efficacy of feature selection procedures
The features selected by both the EN model with the best hyper-parameter configuration and the RFE procedure are also specified in Table 1. The RFE procedure used in this study resulted effective in identifying a relevant subset of the initial features, leading in all techniques to a significant improvement of the cross-validated performances compared to the use of all features (SVM versus SVM RFE: p = 0.015; GP versus GP RFE: p = 0.023; kNN versus kNN RFE: p = 0.048; LR versus LR RFE: p < 0.001). Moreover, also the models ranked second and third were GP and kNN with the features selected by the RFE procedure and they both achieved a AUC higher than 0.9.
Instead, the approach of using the features selected by the EN model was not particularly efficacious, leading to not statistically significant improvements in GP, kNN, and LR and even leading to a reduced performance in SVM.
Feature importance
The LPOCV AUC of each of the 36 features is reported in Table 4, ranked from the highest to the lowest AUC, and in Fig. 2, subdivided based on their type (i.e., sociodemographic, diagnosis, clinical, VRS, neuropsychological tests, and of cardiovascular risk indexes).
Feature importance
WAIS-III, Wechsler Adult Intelligence Scale – Version 3; WMS-IV, Weschler Memory Scale – Fourth Edition; VRS, Visual Rating Scale; AUC, area under the receiving operating curve; LPOCV, leave-pair-out cross-validation; CI, confidence interval.

AUC of individual predictors. The figure indicates the cross-validated AUC and its 95% bootstrap CI when prediction is made by each single predictor. Predictors are grouped according to conceptual domains, in descending order sociodemographic information, diagnosis, clinical scores, brain atrophy, cognitive measures and cardiovascular risk index. Non-significant AUC (i.e., lower bound of the CI lower than or equal to 0.5) are in grey, significant ones in black.
The sociodemographic features had poor predictive capability. All their AUC resulted below 0.65 and only age achieved statistical significance (lower bound of the 95% C.I. higher than 0.5). As a matter of facts, neither the EN model nor the RFE procedures selected any of the sociodemographic features to be included in the models.
The baseline diagnosis (i.e., aMCI, non-aMCI, PreMCI-np, and PreMCI-cl) resulted instead quite predictive, with an AUC of 0.759. This is again in accordance with both the feature selection procedure that identified these features as those to be retained.
Among the clinical scales, only the ModCDR-M score resulted with both a significant and relevant cross-validated AUC (AUC = 0.730), being the sole selected by both the feature selection procedures. The global CDR score, although resulting with a statistically significant AUC, had an AUC very small in magnitude (AUC = 0.559).
The AUC of the six VRS scores ranged from 0.761 (right ERC atrophy) to 0.647 (the left PRC atrophy). The left PRC atrophy score was the sole not selected by the RFE procedure while all VRS scores were included in the final EN model.
Among the fourteen neuropsychological test scores, the HVLTR-R and HVLTR-D scores, the SIT-RT and SIT-RC scores, LM-I and LM-D scores of the Weschler Memory Scale – Fourth Edition (WMS-IV) resulted the tests with the highest predictive performances (all AUC above 0.750) and these were all selected by both the feature selection procedures. The DVR score of the WMS-IV also resulted able to provide statistically significant although less precise prediction of conversion (AUC = 0.718), as much as TMT-A and TMT-B errors (AUC ranging between 0.6 and 0.7). Of these, both time and errors of the TMT-B resulted included also in the final EN model, while the RFE procedure selected only TMT-B errors.
Finally, among the cardiovascular risk features, only history of stroke/TIA and history of coronary bypass/angioplasty were found to have an AUC statistically significant and higher than 0.6. Interestingly, the selection of these features by the two feature selection procedures resulted quite different from this evidence. The final EN model did not include any of the cardiovascular risk features, while the RFE selected history of myocardial infarction and heart rate, which had a non-significant LPOCV AUC, and not history of myocardial infarction and history of coronary bypass/angioplasty.
DISCUSSION
The current study represents the first step in the development of a novel machine-learning algorithm for the identification of three-year conversion to AD in subjects with either MCI or PreMCI. Such an algorithm aims in the end to be efficiently applicable in clinical practice, which require it to achieve high accuracy and to be based on predictors that can be easily and effectively assessed in clinical settings.
The algorithms developed in this study promise to fulfill both these requirements. We employed only predictors based on sociodemographic characteristics, clinical and neuropsychological tests, cardiovascular risk indexes, and level of brain atrophy as assessed by clinicians through the VRS from structural MRI images. With these pieces of information, our best algorithm achieved a global cross-validated AUC higher than 0.96, with a AUC higher than 0.91 also in the MCI subsample. This indicates that our best algorithm already outperforms the clear majority of the several previously proposed algorithms. Furthermore, to the best of our knowledge, this is the only available predictive model that was developed for subjects at a PreMCI stage, showing very high preliminary performance (AUC > 0.99) also in the PreMCI subgroup.
Translation to clinical practice
Among all the algorithms we developed, the one which showed the best performance was the SVM with radial-basis function kernel that included only the features selected via the RFE procedure. Regarding the MCI subsample, roughly 88% of specificity and 87% sensitively are the levels that resulted maximizing the overall cross-validated balanced accuracy (87%). We also found results of a nearly perfect identification of cAD in the PreMCI subsample (cross-validated accuracy = 98%), although these should be considered preliminary as we only had three cAD PreMCI subjects in our sample. Further testing in independent clinical samples would finally confirm these results.
The predictive capabilities achieved by this model would make its application useful in clinical practice as much as in clinical trials, representing a relevant improvement in the current possibility to identify only those subjects truly at risk of converting to AD. Moreover, it would be possible to further optimize the desired levels of specificity and sensitivity according to the cost associated in predicting false positives and negatives.
In addition, although the prediction scores output by some techniques does not represent true probabilities, there are procedures that can calibrate them so that they can provide the individual risk of conversion. Considering that having not only a categorical prediction but also the associated risk of conversion would be of great clinical utility, we plan to perform such calibration with Platt scaling [50] or isotonic regression in the next step of the development of the algorithm, when a further independent sample will be available.
We achieved the obtained results employing routine collectable information. All the measures we used as predictors are non-invasive and can be easily introduced in any clinical center without requiring any particular difficulty or the purchase of non-standardly available equipment. All the neuropsychological tests do not necessitate any intensive training and can be administered by a technician under the supervision of a neuropsychologist. Moreover, the availability of machines for structural MRI is now widespread and the VRS is fast and easily adoptable thanks to the availability of a software with reference images that guide the clinician during the rating, providing training for the relatively uninitiated radiologist, neurologist, or any other interested rater [34]. The VRS overcomes the issue of MRI data obtained from different machines, which are usually non-automatically comparable. All the remaining information we considered, such as socio-demographic, clinical, and cardiovascular risk, can be readily collected during neurological interviews.
Comparisons with other available machine learning algorithms
Several machine learning algorithms have been previously proposed to predict the MCI to AD conversion. Among those that used only baseline information and make a prediction of conversion in about three years, we could identify only a few achieving performances similar or superior to the ours, and they are reported in Table 5.
Comparison with previous algorithms for MCI subjects with comparable or superior performances
AUC, area under the receiving operating curve; SVM, support vector machine.
Specifically, five studies evidenced superior performances. The algorithm proposed by Argwal and colleagues [18] uses a selection of blood plasma proteins as sole predictors. This is a very interesting result as their model uses information from a different domain and it may be partially complementary to the features we used. Also, the prediction is entirely based on the analysis of a single blood sample and even if the assessment of such protein blood levels is not currently clinical routine, it requires a very little invasive procedure and may be developed so to result cost-effectively adoptable in clinical practice. However, these results come from a small training sample and further investigation is necessary to evidence the soundness of such promising results.
Three further algorithms have been developed based on structural MRI data: those proposed by Minhas and colleagues [19], and Plant and colleagues [20] were trained and cross-validated in very small samples, respectively of 13 and 24 MCI subjects, while Long and colleagues [26] used a larger sample (n = 227). All these algorithms showed very high cross-validated performance. However, they directly use structural MRI data and considering the difficulties of employing together data coming from different scanners [51], this may place a barrier to an efficient dissemination of such algorithms into clinical practice.
Finally, also Hojjati and colleagues proposed an algorithm [25] with high predictive accuracy based on resting state functional MRI data. If the availability of MRI machines in clinical setting is quite common nowadays, functional MRI is still mainly used in research settings. Thus, such algorithm may currently result difficulty applicable in clinical practice.
Additional studies proposed algorithm with performances similar to the ours. Three studies employed predictors that may not allow an easy translation to clinical practice: Morandi and colleagues [22] used structural MRI data, Dukart and colleagues [23] both structural MRI and fludeoxyglucose positron emission tomography data, and Apostolova and colleagues [24] cerebrospinal fluid p-tau protein levels.
Instead, Clark and colleagues [21] used only sociodemographic, clinical, and neuropsychological test scores, achieving high cross-validated performances although inferior to those achieved by our best model. Two other studies proposed algorithms based only on these types of predictive information [52, 53]. They also achieved high predictive performances but inferior to Clark’s algorithm.
Considering this evidence, our and these three algorithms are the only currently available that achieved a relevant predictive performance using only predictors that may be easily assessed in nowadays clinical practice, with our algorithm that seems to outperform all of them. As we used different predictors than those employed in these other algorithms (i.e., they did not use brain atrophy levels assessed via the VRS but included the scores of different neuropsychological tests), it would be of great interest to investigate in the next steps if adding such predictors to our features would bring a further increase in the predictive performance of our algorithm.
Importance of predictors
As mentioned above, the interpretation of the predictor importance in non-linear models, such as SVM, GP, and kNN, is a complex and not yet solved issues. Considering this, in the current study we decided to focus only on evaluating the individual importance of each 36 predictors initially considered in this study.
While sociodemographic and cardiovascular risk were not particularly predictive, memory and brain atrophy seems to be the most relevant for the prediction of AD conversion. The HVLTR, SIT, and LM tests were identified as the most relevant cognitive measures by all feature selection and importance procedures and they all assess different aspects of memory. The ModCDR-M score was also suggested as a particularly relevant feature. The important role of memory functioning as predictor was somehow expected considering previous findings [54] and that memory deficits are the core clinical characteristics that defines AD. Also, the evidence of an important role of brain atrophy is in line with previous evidence [55] as well as several other studies which developed highly performing machine learning algorithms starting from structural MRI data, alone (i.e., [20]) or in combination with neuropsychological test scores (i.e., [19, 22]). Memory deterioration and brain atrophy may begin years before a full-blown AD diagnosis can be made and a proper set of sensible measures can allow to promptly identify them. Our study further suggests that machine learning techniques have the potential to exploit such information to early identify those subjects in which the onset of the pathophysiological processes leading to AD has been occurring.
Limitations
Our study has some potential limitations that should be taken into account. We used cross-validation as validation procedure but further testing in an independent sample of new cases has not been performed yet. However, nearly all the algorithms proposed to make a MCI-to-AD prediction currently lack such further testing. Furthermore, the sample we used to train the algorithm was limited in size and included only three cAD PreMCI. Thus, the performance estimate obtained for the PreMCI should be considered as very preliminary and requires further investigation.
We applied only some of the many machine learning as well as feature selection procedures available. Although we have already reached good results, there is no guarantee that other machine learning procedures and other subsets of features would allow to achieve even better predictive accuracy.
Moreover, all subjects of our sample were recruited in the same abovementioned clinical centers. The population referring to these might have peculiar characteristics and algorithms might perform less well in different MCI and PreMCI populations. Also, both the features and subjects we finally included were selected from a larger set of available variables and subjects according to the lack of missing values. Their occurrence in such excluded variables and subjects may be due to reasons that are beyond mere randomness, potentially limiting the representativeness of our feature set and train sample and thus leading to biases in our algorithm.
Given these current issues, we plan to test the performance in a new sample of MCI and PreMCI subjects participating in a new longitudinal study in Miami, currently in its third year, as well as to try new procedures for further optimization.
Another potential shortcoming is the complexity of providing a clear explanation of the role that each feature plays in the prediction. While a first basic approach has been attempted in this study, more strategies will be applied while proceeding in the next phases with larger samples and a future study will be addressed in attempting to open the model black-box. A better interpretability of the model will help both in gaining further understandings of how these variables are related to the development of AD and in generating more trust towards the application of model by clinicians as much as patients.
Conclusion
In conclusion, we used supervised machine learning techniques to develop algorithms able to identify which subjects with PreMCI and MCI will convert to AD in the following three years. As the opportunity of an efficient clinical translation was one of the main goal motivating our study, we used predictors based only on sociodemographic characteristics, clinical tests, cognitive measures, cardiovascular risk indexes, and level of brain atrophy as assessed by clinicians through the VRS from structural MRI images. We promisingly achieved high predictive performance, among the very best of the many algorithms available in literature and the best achieved so far using only information easily collectable in clinical practice. Considering these results, we plan to proceed in further testing and optimization in other independent and larger samples as to reach the level of reliability necessary for an actual applicability.