
Abstract
Background:
Alzheimer’s disease and related dementias (ADRDs) are being diagnosed at epidemic rates, with incidence to triple from 35 to 115 million cases worldwide. Most ADRDs are characterized by progressive neurodegeneration, and Alzheimer’s disease (AD) is the sixth leading cause of death in the United States. The ideal moment for diagnosing ADRDs is during the earliest stages of its progression; however, current diagnostic methods are inefficient, expensive, and unsuccessful at making diagnoses during the earliest stages of the disease.
Objective:
The aim of this project was to utilize Raman hyperspectroscopy in combination with machine learning to develop a novel method for the diagnosis of AD based on the analysis of saliva.
Methods:
Raman hyperspectroscopy was used to analyze saliva samples collected from normative, AD, and mild cognitive impairment (MCI) individuals. Genetic Algorithm and Artificial Neural Networks machine learning techniques were applied to the spectral dataset to build a diagnostic algorithm.
Results:
Internal cross-validation showed 99% accuracy for differentiating the three classes; blind external validation was conducted using an independent dataset to further verify the results, achieving 100% accuracy.
Conclusion:
Raman hyperspectroscopic analysis of saliva has a remarkable potential for use as a non-invasive, efficient, and accurate method for diagnosing AD.
Keywords
INTRODUCTION
Alzheimer’s disease (AD) is the most common form of neurodegeneration-induced dementia in the elderly population worldwide [1]. In the United States alone, an estimated 5.7 million Americans are affected by the disease, which is also the sixth leading cause of death [2]. The rapid increase in number of AD patients, combined with overall increased life expectancy and lack of effective treatment, has had a devastating impact on healthcare systems in industrialized nations across the world. In fact, in 2018 alone, the disease cost the United States almost $300 billion [2]. Its devastating impact has worsened due to the fact that AD is progressive, incurable, and lethal.
The etiology and pathogenesis of AD are highly complex, and several major factors have been found to play an important role in its progression. The most prominent theory says the disease is caused by the build-up of the amyloid-β (Aβ) protein within the brain, which then forms the typical plaques and neurofibrillary tangles that are characteristic of the disease [3]. Hyper-phosphorylation of the tau protein is also believed to play an imperative role in causing the neurodegeneration associated with AD [4]. While the complete causation of the disease remains questioned, it is believed that the disease begins years before clinical manifestations arise [5, 6].
The lack of a complete set of information surrounding what causes AD deters the development of simple diagnostic methods. In fact, there is no single test currently capable of diagnosing AD that is approved for use in clinical settings or at the point of care [2]. A combination of many different tests and exams is usually conducted in order to aid in making a diagnosis, including a complete medical exam, mental status tests, neurological exams, and brain imaging tests. The combination of these tests is time consuming, expensive, and can be invasive, especially for repetitive use in older adults. Ideally, a definitive method for diagnosing the disease early on in its progression, before neurodegeneration becomes too severe, is desired; this will allow for initiation of disease-modifying treatments at the earliest stages of AD [7].
The development of a new noninvasive diagnostic method based on body fluid analysis that integrates multiple biomarkers can significantly improve the accuracy of diagnosis. Recent studies analyzing blood, saliva, and cerebrospinal fluid have been conducted in efforts toward developing a method for diagnosing AD [8–13]. Of these biological materials, collection of saliva is the least invasive. Saliva is produced by several glands in the mouth, including the salivary glands [14]. It is mainly composed of water; however, the chemical components that are present in the next highest concentrations comprise of electrolytes (including bicarbonate and phosphate), mucus, various enzymes (including lipase, amylase, and lysozyme), and antibacterial compounds (including thiocyanate) [15–17]. Saliva has been shown to have great diagnostic potential [18]. Because saliva collection is inexpensive and non-invasive, it is an attractive option for use in diagnostics. Development of a method for diagnosing AD using saliva will not only help in identifying the disease early-on for treatment intervention, but will also allow repeat analyses to be conducted in order to monitor the brain health of adults as they age. Such a widely applicable test would provide the basis for further understanding of disease-linked salivary changes, and would reduce the need for alternative, expensive, and time-consuming diagnostic methods. Moreover, a fast and reliable diagnostic test would accelerate both AD diagnosis and prognosis evaluation and would foster expedited treatment interventions.
In this regard, Raman spectroscopy has been evaluated for its diagnostic potential [19, 20]. In fact, Raman spectroscopy has been used in several applications including for diagnosing cancers, [21] asthma, [22] cornea infection, [23] and osteoarthritis [24]. Several studies have already displayed the potential of Raman spectroscopy to be used for diagnosing AD and other forms of dementia based on blood analysis [9, 25–28]. Furthermore, Raman hyperspectroscopy is advantageous over other techniques used for disease diagnostics due to its ability to produce a spectral “fingerprint” representing the total biochemical composition of the sample and, as such, combining the contribution from several biochemical markers of the disease. Because of this, Raman hyperspectroscopy has the potential to detect changes occurring in biological samples during the onset and progression of a disease.
This proof-of-concept study focused on understanding the selectivity of Raman hyperspectroscopy in combination with machine learning through the examination of Raman spectral profiles of saliva collected from normative, AD, or mild cognitive impairment (MCI) individuals. Machine learning, sometimes referred to as multivariate statistical methods, were used to generate a classification model that capitalizes on differences between spectral profiles of the three classes, which then was used to diagnose a person with AD or with MCI with high levels of accuracy. Specifically, Artificial Neural Networks (ANN) was used. Furthermore, it was found that feature selection could benefit multivariate analysis by removing irrelevant or redundant variables from a dataset. Thus, Genetic Algorithm (GA) was used as the feature selection technique; the combination of GA with ANN improved the classification model’s performance by achieving deeper understanding of what spectral variables were important as well as by simplifying the model through elimination of irrelevant features of the data set. Ideally, GA should select features in the Raman spectra of saliva that are associated with neurodegeneration-induced dementia. A diagnostic ANN model was built with the purpose of differentiating AD and MCI Raman spectra from spectra of normative donors, and was optimized based on GA-selected spectral features. This novel concept delivers a crucial step toward creating a simple, non-invasive, and accurate method for diagnosing AD.
MATERIALS AND METHODS
Sample collection and preparation
The 39 participants from whom saliva was collected in this study were volunteers selected from the local community; individuals were screened using a battery of neuropsychological assessments to evaluate executive function and overall cognition. The Montreal Cognitive Assessment (MoCA) and Alzheimer’s Disease Assessment Scale (ADAS) Wordlists were used as experimental diagnostic tools to differentiate between MCI, AD, and healthy age- and gender-matched controls. Information regarding the MoCA classification system can be found in Supplementary Material 1.
Participants were asked to refrain from drinking alcohol within 12 h of saliva collection; eating a major meal or brushing teeth within 1 h of collection; and eating dairy products, acidic, or high sugar-content foods, or chew on gum or candy within 30 min of collection. Any currently used medications as well as recent dental work was recorded at the time of collection. Roughly 2 mL of saliva was accumulated from each participant. The samples were then stored at -80°C.
For preparation, samples were thawed and saliva was pipetted into microfuge tubes and centrifuged for 10 min at 10,000 rpm. The supernatant was saved and used. Samples were stored at –20°C from the time of preparation to the time of analysis. For analysis, samples were thawed and 10μL of saliva was deposited on a glass microscope slide covered in aluminum foil and allowed to dry completely overnight. The aluminum foil was used as a substrate for decreasing contribution of fluorescence.
Raman spectroscopic methods
Raman spectra were collected using a Renishaw inVia Raman spectrometer equipped with a research-grade Leica microscope. The 50x objective was used to focus on the sample. All measurements were performed through use of a PRIOR automatic mapping stage. Spectra were recorded in the spectral range of 400–1700 cm–1 under excitation by a 785 nm wavelength diode laser using WiRE 3.2 software. Laser power was reduced to 55 mW to avoid photo-degradation of the sample. The automatic mapping stage collected approximately 40 spectra per sample, with one 30-s accumulation taken at each sample position. Collecting multiple spectra per sample ensures accurate representation of the heterogeneous composition of a sample.
Data treatment
A total of 1,580 spectra from 39 total donors were imported to MATLAB (R2017b) software (Mathworks, Inc.). Any Raman spectra that showed a poor signal-to-noise ratio or cosmic rays were removed from the dataset. Four samples (donors) were randomly selected to create a holdout data set and were set aside to be used for designing an external validation experiment for independent testing of the model. These samples were only measured after the model training was finished. All spectra from the remaining 35 donors were subjected to preprocessing steps, including smoothing by automatic-weighted least squares and normalization by total area. The four samples (donors) that were set aside to create an independent, external validation dataset were preprocessed in the same manner but separately from the other data, and after the prediction model was already built. The spectral data of the 35 donors were used for variable selection and for building the classification model. GA was used to select important features to be included in the training of ANN models. The ANN analysis was performed using R-project software, ver. 3.4.3, with the “neuralnet” package [29]. Further information describing GA and ANN can be found in Supplementary Material 2.
RESULTS
Raman spectra were collected from saliva of 39 donors through the use of automatic mapping. Mapping is conducted in order to obtain multiple spectra from each sample, thereby acquiring an accurate representation of inherit compositional heterogeneity. The donors consisted of individuals from three different classes: normative (10), AD (11), and mild cognitive impairment (18) individuals. Four of the donors were separated from the rest of the samples at the beginning of the experiment, before spectral data collection and statistical analysis. After the data from the other 35 donors were processed and the final ANN model was built, the spectral data from these four samples (donors) were collected, preprocessed, analyzed and their class was predicted. The mean preprocessed spectra of each class is shown in Fig. 1A. As expected, the spectra depict the characteristic biochemical composition of saliva. The difference between the average AD and average normative spectra are depicted in Fig. 1B (additional difference spectra seen in Supplementary Material 3). The difference spectrum is shown as lying within±2 standard deviations, suggesting that the mean difference between classes is statistically insignificant, and multivariate analysis is required to uncover useful variability within individual spectra for the purpose of building diagnostic algorithms. This is not an unexpected result as the averaging of complex sets of data will result in small differences which exist within donors of a class or between classes to become hidden. As such, GA and ANN machine learning techniques were used to analyze the collected spectral data.
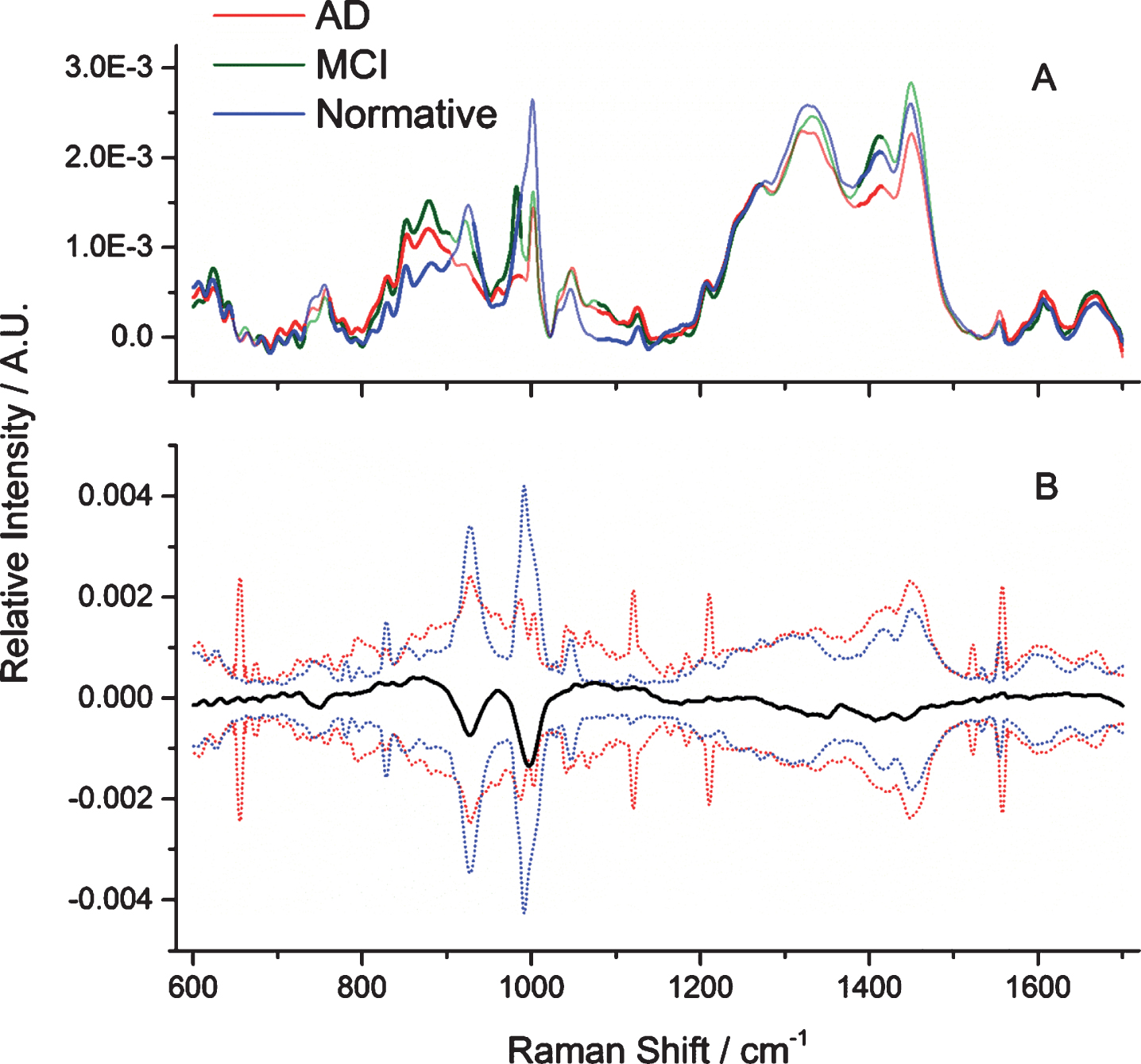
A) Pre-processed mean saliva spectra of the three classes, including the spectral ranges selected by Genetic Algorithm: AD (red), MCI (green), and normative (blue). Areas selected by Genetic Algorithm are marked as bold lines, whereas excluded spectral ranges are marked as unfilled transparent lines. B) The pre-processed difference mean saliva spectra between AD and normative (bold line) with the positive and negative 2 standard deviations (dotted lines) of the AD (red) and normative (blue) donors’ spectral data sets.
Since a large number of input variables can lead to overfitting of the ANN, and because portions of the Raman spectra are non-informative, GA was applied to reduce the variables that will be examined by the ANN classifier. GA was used to select the most informative features in the training data set consisting of 35 donors and 1440 spectra. The parameters of GA are given as follows: the population size was set to 62, the mutation rate to 0.005, and the maximum number of generations for every run was set to 100. The breeding was set to double crossover, the window width was 30 variables, and 30% of the windows were initially included. In order to pick out diagnostic feature information from the measured Raman spectra, GA was independently run 200 times, to select significant spectral bands.
The subsets of data identified by GA signify the areas of the spectra that have the strongest distinguishing capabilities between the different classes. As seen in Fig. 1, not all regions which exhibit the greatest differences between mean spectra were selected by GA; this is most likely due to the large standard deviations observed for those regions. GA iteratively split and analyzed all combinations of various subsets of spectral data with the goal of differentiating the three classes; the spectral features identified as having the lowest prediction errors “survived” and were passed along to the next potential solution. The regions and bands recognized by GA are represented by the bold lines in the spectra, as seen in Fig. 1A. The transparent lines indicate areas of the spectra that were not considered significant for differentiation purposes.
The ANN approach was used with a multilayer perceptron neural network as a classification technique and with the resilient backpropagation learning algorithm. In multivariate statistics, ANN conducts information processing in a manner that is similar to the way the human brain works. ANNs are composed of several layers of simple interconnected processing elements (i.e., neurons), which each perform a mathematical operation on input values and transfer the result to one or more hidden layers, or an output layer. The GA-identified dataset is introduced to the model through the input layer; one or more hidden layers perform processing through a system of weighted connections that perform calculations on the input data, and the output layer finally gives the classification result. Because ANN is a supervised statistical method, each donor will have a class (AD, MCI, or normative) assigned to each of its individual spectra.
During the training phase, the neural network learns the relationship between independent and dependent variables. Specifically, it learns to make associations between intensity values at specific wavelengths of the input spectral data with sample class membership, which are the designated outputs of the neural network. A total of 1,440 labeled spectra were presented to the network. During the learning phase, the network weights were adjusted to minimize differences between the output of the network and the known class labels of the samples. The process of weight optimization was based on the resilient backpropagation algorithm with weight backtracking, with a threshold set to 0.01 for defining the partial derivatives of the error function [30]. The backpropagation learning algorithm is a common method used to update weights in feedforward ANNs due to its computational efficiency [31]. Once the network weights, together with network architecture, were adjusted using the spectral dataset, the network was used to predict the labels of the unknown samples in the independent validation set. The goal was to produce a neural network model that fit the data set well while still allowing for accurate prediction of data that was not used to build the model. ANN models can be over-trained, which means they do not show good generalization due to the model fitting noise; thus, applying noise reduction techniques, such as GA, to the input data before the initiation of training can prevent overtraining of the model.
The architecture and main neural network parameters for differentiating the three classes was identified by a trial-and-error process. The network weights were trained with different configurations of the adjustable parameters and various network architectures. The performance of each ANN was assessed using the bootstrapped Latin partition (BLP) validation procedure in order to determine the optimal ANN that can differentiate AD, MCI, and normative spectra. BLP provides an unbiased evaluation of pattern recognition models. BLP divides the dataset into training and validation sets; here, nine training-validation subsets of complete samples (donors) were furnished, ensuring that each sample was only used once for prediction. The proportions of each class distribution remains fixed to maintain equal class distributions. Multiple neural network structures were built and tested using BLP to determine which structure had the best prediction capabilities.
The neural network structure that yielded the best results through validation by BLP consisted of two hidden layers, the first with 100 neurons and the second with 20 neurons. The output layer contained three neurons and was responsible for giving the predicted class. This network structure provided the lowest prediction errors for validation datasets as compared to the other networks tested in the trial-by-error process. The final network results are depicted in Table 1. Here, the performance parameters for each class, determined through BLP, are shown. The sensitivity (true-positive rate), specificity (true-negative rate), and accuracy (percentage of correctly predicted spectra among total cases) for each class prediction is reported together with 95% confidence intervals. All three classes were successfully differentiated with an average sensitivity of 98.56%, specificity of 99.29%, and accuracy of 99.14%.
Performance parameters of the Artificial Neural Network determined using BLP
To verify the success of the model, “blind” external validation was conducted. Here, a total of 140 spectra from the four samples, which were previously set aside, were introduced into the validated model. To guarantee independence, spectral data was used from samples that were specifically not used in the model-building process and were only collected and preprocessed after the model training was finished. Furthermore, the classification of these samples was not known to the researcher conducting the external validation and were thus considered “blind”. Once again, the ANN model computes the probability of each individual spectrum for belonging to each class. All unlabeled spectra are then assigned to the class with the highest probability. The classification of each individual spectrum from each of the four samples is depicted in Table 2 (left-hand side), demonstrating an overall average accuracy of 72% for all three classes.
Classification predictions for all individual spectra collected from each of the four samples (left) and overall donor-level classification predictions of the four samples (right) used for “blind” external validation
The overall donor-level classification of each of the four donors, based on spectral-level predictions, is shown on the right-hand side of Table 2. A donor sample was assigned to the class (MCI, AD, or normative) that received the majority of spectra assigned to it. Figure 2 plots the spectral level classifications for the four unknown samples as a percentage of spectra classified to each class, which is expressed as the height of the bar. The lowest maximum percentage was observed for Donor #2 who was assigned to the normative class with 44% of spectra correctly assigned. True classification of the samples was only revealed after the model had made its predictions. All four samples that were introduced into the model for external prediction were correctly classified. This indicates that the ANN model optimized using BLP is robust enough to reliably classify “unseen”, or new, data.
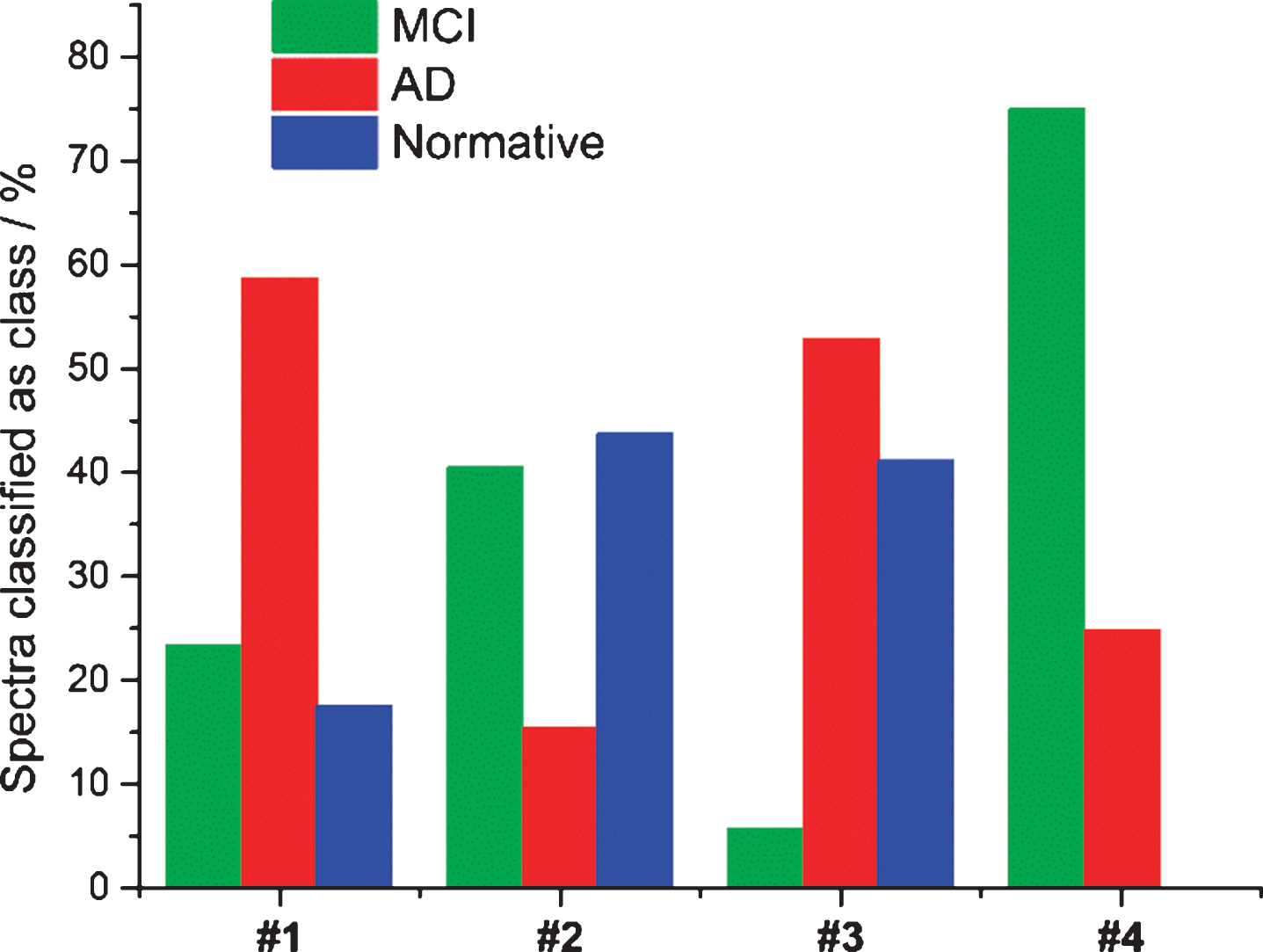
Histogram plotting the results from “blind” external validation of the ANN model. The percent of spectra assigned to three classes: AD (red), MCI (green), and normative (blue) is plotted as the bar heights for all donors.
Lastly, peak intensity ratios were compared between normative and AD samples. Specifically, the ratio between 1320 cm–1 (internal standard) and 878 cm–1 (peak which greatly differed between classes and was also selected by GA) were compared. The difference in peak ratios between averaged spectra from normative and AD donors was significant enough for discrimination (see Supplementary Material 4).
DISCUSSION
Many of the bands identified by GA can be assigned to major components of saliva. A summary of those peaks and their assignments as well as tentative contributions can be found in Table 3. Proteins, lipids, and other small biological molecules are mostly responsible for contributing to the average Raman spectra seen in Fig. 1A.
aTwisting, bstretching, crocking, dbending.
Notably, the results of GA are consistent with recent lipidomic and metabolomic studies conducted to determine potential biomarker panels for diagnosing AD. Of interest, metabolic differences in saliva between subjects with AD and healthy controls identified sphinganine-1-phosphate, phenyllactic acid, inosine, and hypoxanthine as influencing diagnostic power [32]. Concurrently, Mapstone et al. identified phospholipids, including phosphatidylcholine, and various amino acids, including proline and phenylalanine, which also contributed toward diagnostic functions [33]. Lysozyme has also been identified as having diagnostic capabilities as its concentration will increase in response to inflammation, a symptom associated with AD [34]. The GA-selected spectral regions are representative of previously determined biomarkers for diagnosing AD and were thus specifically used for further statistical analysis.
The usefulness of saliva for diagnosing diseases has been previously demonstrated. Diagnostic biomarkers within saliva have been used to diagnose various cancers, and bacterial, viral, cardiovascular, and autoimmune diseases [18]. A thorough review of the usefulness of saliva in metabolomics and disease diagnostics can be found elsewhere [18]. Importantly, saliva is completely noninvasive to collect, making it an attractive option over invasive blood or private urine collection. Because of its apparent usefulness and advantages, the analysis of saliva by Raman hyperspectroscopy was considered here for the first time for diagnosing AD.
Raman hyperspectroscopy is uniquely suitable for characterizing micro-heterogeneous environments [35]. Multiple spectra are collected from individual points of a sample, which represent approximately a few hundred femtoliters of volume [36]. The collected spectral data contributes to a three-dimensional hyperspectral data cube (x, y, λ), where x and y are spatial dimensions and λ is the spectral dimension. When machine learning is applied to the data cube, the spatial distribution of biochemical components can be elucidated [37]. This produces a statistically significant characterization of the sample’s heterogeneity and multicomponent composition which can further be used to identify biomarkers, including those present at low average concentrations. Since the entirety of the biochemical composition of a sample is probed, the spectroscopic signature produced for different disease states will be based on the simultaneous integration of multiple biomarkers of the disease, which significantly improves the sensitivity and selectivity of the technique for diagnostic purposes [35].
Furthermore, due to the heterogeneous nature of the sample, the distribution of biochemical components within saliva will be varied. Thus, not every spectrum collected from a single sample will be identical, as some spectra will represent higher or lower local concentrations of biomarkers and biochemical components. This creates the possibility for individual spectra to be misclassified. Because of this, it is important to make donor-level classifications based on spectral-level predictions. Thus, each of the four unknown samples examined during external validation were classified as belonging to the class that the majority of its spectra were assigned. The spectral-level predictions for the four unknown samples are summarized in a histogram (Fig. 2), with the number of spectra assigned to each class scaled to accommodate relative frequencies per donor. The donor-level predictions for each unknown sample are summarized in Table 2 (right-hand side).
External “blind” classification reached 100% accuracy for predicting the class of four unknown donors, showing excellent prediction results and indicating that the model is not majorly overfit. While “blind” external validation was able to show the reliability of the method for diagnosing AD based on saliva, it should be noted this study was designed as a proof-of-concept and the test data set was created using only a few samples. Therefore, more testing is necessary to obtain a strong understanding of the classification accuracy and generalizability of the method. Mean spectra of all four unknown samples are provided in the Supplementary Material 5.
This proof-of-concept study demonstrates the incredible potential of Raman hyperspectroscopy to identify and screen for AD based on analysis of saliva. This technique is sensitive and specific for distinguishing between samples from different classes and is an exemplar non-invasive technique, as saliva can be collected easily through passive drooling. Raman hyperspectroscopy in combination with machine learning was used to successfully differentiate saliva collected from patients with AD or with MCI from normative individuals with an average accuracy of 99%. GA identified areas of spectral data with the strongest differentiation capabilities; the assignments of these identified spectral bands can be attributed to various proteins, amino acids, and lipids, many of which have previously been reported in the literature as potential biomarkers for AD. These important differences in spectral data were utilized by ANN to successfully execute classification between the three different sets of samples. The results were verified through “blind” external validation using an independent dataset to comprehend how well the novel method could classify new unknown data. All four samples used for this task were correctly predicted. Based on such successful results, Raman hyperspectroscopic analysis of saliva is shown here to have a remarkable potential for use as a non-invasive, efficient, and accurate technique for diagnosing AD.