
Abstract
Abstract:
Population-based surveys were used to estimate community prevalence of dementia, but have low response fractions due, among other things, to difficulties in obtaining informed consent from people with diminished capacity. Cohort studies of younger people are subject to recruitment bias and non-random drop-outs. Dementia registries can delineate sub-types of dementia but have limited population coverage and are costly to maintain. Administrative datasets have low costs but may be subject to selection bias and uncertain sensitivity. We propose that astute combination of methodologies, including assessment of coverage and validity of administrative datasets, is the most cost-effective process to estimate and monitor community prevalence.
A precise measure of the prevalence of dementia is useful to improve scientific understanding of dementia risk, enable provision of appropriate services and to enable understanding of the burden of illness, and how these things change over time. The nature of the dementia syndrome is associated with features that hinder one’s ability to determine its true prevalence and incidence. The onset of dementia is usually gradual and delays in diagnosis common [1]. A recent systematic review of young-onset dementia found the population prevalence to be below 0.1% before the age of 55 years, rising to approximately 1% for the age group 60 to 64 years [2]. The prevalence of dementia is thought to increase exponentially with age, approximately doubling every 5 years after the age of 60 years and well into the over 90-year age group [3]. The advanced age of people with incident dementia may result in considerable misclassification of other causes of cognitive impairment, in particular delirium and psychiatric illnesses of older people, and possibly failure to pursue a definitive diagnosis. Additionally, co-morbid physical illness may result in functional dependency that can be difficult to disentangle from functional deficits thought to arise from cognitive decline (functional decline remains an essential requirement for the diagnosis of dementia on International Classification of Diseases 11th Revision (ICD-11)) criteria.
Surveys of older people have become more difficult to perform because of decreasing consent rates [4]. Using the same sampling methodology, the Medical Research Council Cognitive Function and Ageing Studies in the UK reported an increase in non-participation of older people from 18.3% in the period 1989–1994 to 45.3% in 2008–2011 [5]. A particular challenge for surveys of older people is the complexity of consent, including the need for proxy consent for people with cognitive impairment [6]. Another limitation of community surveys is that the differentiation of sub-types of dementia now requires structural imaging to ascertain vascular load that forms an essential component of the second major etiological cause of dementia, i.e., vascular dementia. Such imaging requires a second diagnostic phase, and there may be a substantial reduction in participation between the initial assessment and the imaging appointment [7]. Additionally, as dementia progresses, the capacity for independent living diminishes, so that residential care support may be needed. Such residential care may be geographically distant from the original abode of an older person, making both follow-up and ascribing the case to a particular region problematic. Furthermore, these community studies are rarely performed in rural and remote locations, further reducing representativeness.
One way to avoid the difficulties with response bias and consent issues associated with cognitive impairment is to recruit cohorts of people earlier in life. These cohorts may also have low response fractions even if recruited in middle age [4]. Such studies require very long follow-up periods to identify incident cases, and there may be selective attrition because people with dementia or frailty are less likely to be available for follow-up assessments [8]. Many of the dementia specific cohorts are essentially volunteer cohorts, e.g., the Alzheimer’s Disease Neuroimaging Initiative (ADNI), and although their findings may be useful in elucidating risk factors and biomarkers for subtyping dementia, they have no utility in determining population incidence or prevalence [9]. Similarly other, more generally focused cohorts of older people, e.g., the ASPREE Longitudinal Study of Older Persons (ALSOP), have low response fractions even when the sample is drawn from a more population-based framework [10].
Another possible method for estimating the total number of people with dementia is through the use of registries. A registry is defined as a “database of identifiable persons containing a clearly defined set of health and demographic data collected for a specific public health purpose” [11]. There are many conditions with clear-cut and readily available pathological diagnoses, e.g., specific cancers, that are ideal candidates for registries. Dementia is not one of these conditions because the onset is insidious and the identification of all cases in a population is difficult. Registries are at risk of missing people with very mild or severe disease, and the exclusion of people with dementia over the age of 85 years is common [12]. Consequently, registries are likely to have incomplete coverage and may include a mixture of prevalent and incident cases. There are also issues associated with the costs of establishing and maintaining a registry, compliance with ethical requirements, international harmonization of definitions and data collection, and questions about confidentiality for the transfer of data [11]. A systematic review of 31 dementia registries found widely different scopes and purposes, with more than half set up to facilitate research. Others were set up with the aim of improving the quality of assessment and care [13]. To address specific epidemiological questions, such as determining population prevalence or incidence, registries would be an economically inefficient approach [11].
Administrative datasets in healthcare are massive repositories of data, usually collected for the purpose of allocation of funding. They are maintained in hospitals and by third party payers, including insurance organizations, health maintenance organizations, and government entities. They may also be used in allocation of funding to aged care services and residential aged care facilities. If the records for episodes of care can be linked for individuals, these data could be invaluable for epidemiological purposes if they have good coverage of an identifiable population. Their advantages are low additional costs, access to longitudinal follow-up, and assumed consent. Their major limitation is the potential for information bias due to the imperfect ascertainment of cases [14]. In the context of dementia diagnosis this may be an important limitation. There are additional concerns about sensitivity because the diagnosis of mild, or even moderately severe, dementia can be missed during a hospital or residential care admission. Problems with specificity are also common, as older people may receive the diagnosis of dementia when, in fact, their cognitive difficulties may have been the expression of an acute illness leading to delirium. The validity of using administrative datasets to establish the diagnosis of dementia has been assessed in a review of 27 studies that used varying reference standards [15]. Only 5 of the 27 studies were thought to have low risk of bias, with most of the others having unclear quality ratings. Positive predictive value (PPV) was the commonest accuracy measure reported and, despite considerable variation, about 60% of studies had PPV > 75%. Sensitivity was generally low but was improved by combining datasets from different sources. At the time of that review only the combinations of hospital admissions and death data were available [15] (see summary of approaches in Table 1).
Methodologies used to determine prevalence/incidence of dementia
The most relevant outcome of interest for the general public, service providers, and policy makers is age-specific prevalence of dementia in the population. These estimates need to be: Generalizable to a complete population; Robust to recruitment bias and attrition, particularly drop-outs, which are not at random; Cover a sufficiently long period and be regularly updated to detect secular changes; Based on large samples so there is good statistical power to estimate rates reliably, especially for subgroups (e.g., ethnic subpopulations); Obtained by sustainable processes; Informed by high quality diagnostic processes to allow diagnostic subtypes.
We propose that the best estimates will be achieved through the use of multiple linked administrative datasets, with targeted research studies to identify and minimize the risk of bias. Ideally such linkage should include diagnoses from emergency department and hospital records, mortality data, medication prescription data, community service records for older persons (including mental health services), residential aged care, and any available registries. The data tend to follow a natural progression enabling the estimation of prevalence and increasing severity, as illustrated by Fig. 1. The use of “capture-recapture” techniques enables the statistical adjustment of undercount that might occur at any point during the course of dementia by assessing the overlap between various linked datasets [16]. Removing one dataset at a time allows some estimation of the individual dataset’s contribution to the overall prevalence and the stability of the estimation of the undercount. Problems remain as the estimate of this undercount may not be stable over time and requires constant attention to the quality of the records, that is in turn based on the care that clinicians bring to the recording of diagnoses. For example, there is evidence that the UK hospital morbidity administrative dataset demonstrated increased sensitivity over time [17]. Data from participants of research cohorts with extensive imaging and specialist review can be used to check the validity of diagnostic information and determine proportions of dementia subtypes. These types of administrative data are often available almost continuously, allowing determination of secular changes. Another potential advantage of this approach is that it may allow for the evaluation of population level risk and protective factors, such as improved control of high blood pressure or decreased exposure to airborne pollution, on dementia prevalence.
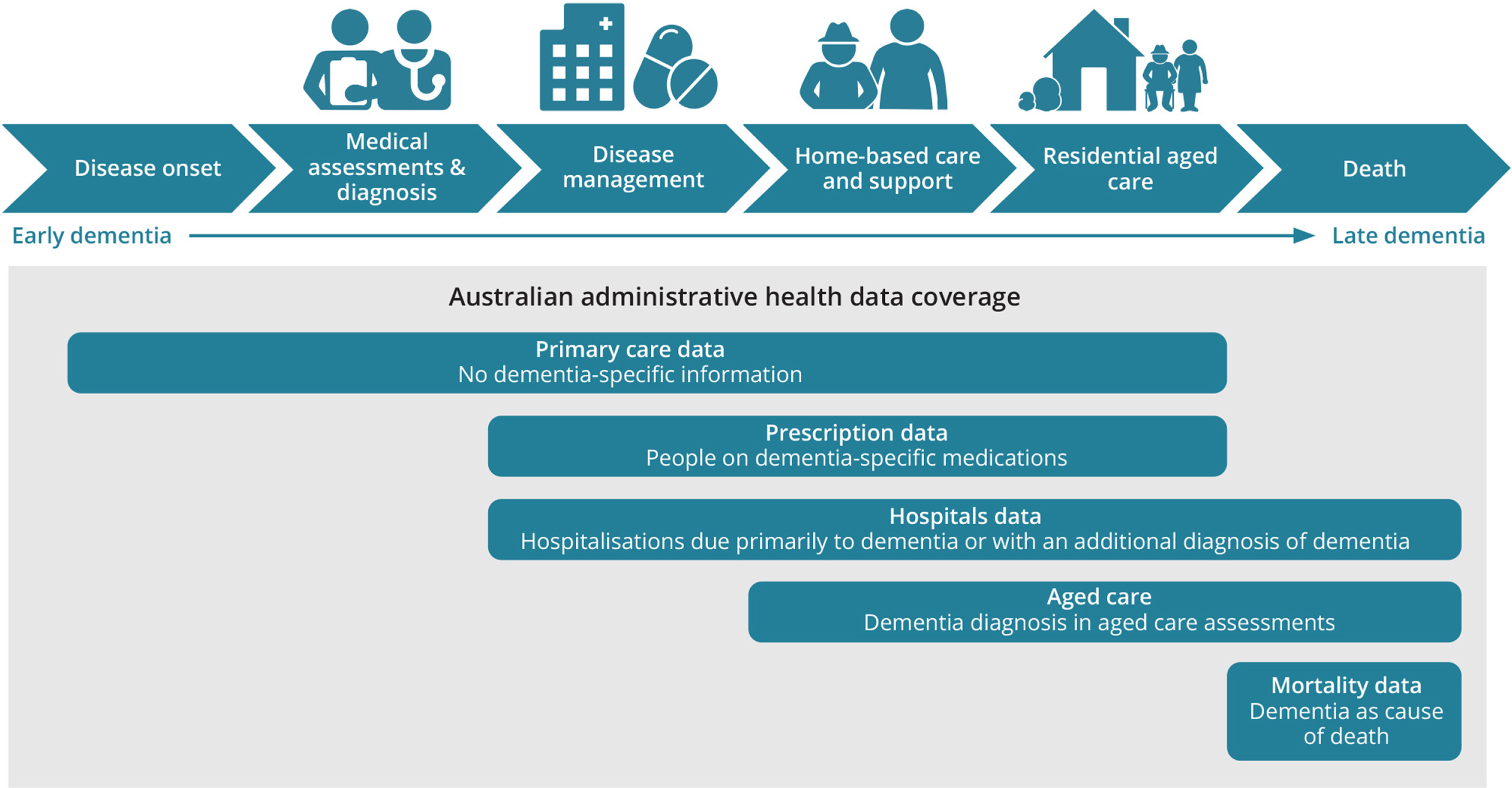
Dementia pathway and associated national data collections and their coverage for reporting dementia. Source: Australian Institute of Health and Welfare 2021. Predicting early dementia using Medicare claims: a feasibility study using the National Integrated Health Services Information Analysis Asset. AIHW, Canberra.
This approach has limitations. The main one concerns ascertainment bias where changes in prevalence estimates may be affected by diagnostic fashions that encourage clinicians to change clinical practice. For example, the advent of the cholinesterase inhibitors resulted in a considerable increase in the diagnoses of dementia made in older people in the UK [18]. An examination of mortality data in Australia showed that rates of dementia as an underlying cause were increasing at the same time as rates of dementia as an associated cause of death were falling [19]. It may be difficult to disentangle changes in diagnostic fashion as opposed to true changes over time. We are mindful of technical challenges using capture/recapture models to improve the validity of inferences about the course of dementia, and also the difference in the accessibility, coverage and quality of administrative data in different countries. Nevertheless, the combination of these techniques, based on administrative datasets, provides the most attractive mechanism to continuously review the prevalence estimates of dementia, one of the commonest causes of disability and death worldwide.
Footnotes
ACKNOWLEDGMENTS
The authors received support from the Australian National Health and Medical Research Council Grant Boosting Dementia Grants Project no. 1171319. Leon Flicker is in receipt of a Practitioner Fellowship funded by the Medical Research Future Fund APP 1155669. Kaarin Anstey is funded by ARC Fellowship FL190100011.