
Abstract
Despite intense research on Alzheimer’s disease, no validated treatment able to reverse symptomatology or stop disease progression exists. A recent systematic review by Kim and colleagues evaluated possible reasons behind the failure of the majority of the clinical trials. As the focus was on methodological factors, no statistical trends were examined in detail. Here, we aim to complete this picture leveraging on Bayesian analysis. In particular, we tested whether the failure of those clinical trials was essentially due to insufficient statistical power or to lack of a true effect. The strong Bayes’ Factor obtained supported the latter hypothesis.
INTRODUCTION
Alzheimer’s disease (AD) is a chronic multifactorial neurodegeneration-based disorder and the most common cause of dementia worldwide [1], with an estimated prevalence of 30 million people [2]. AD is characterized by extensive neuronal loss that tends to induce loss of memory and a more generalized cognitive decline [3]. Other clinical features include loss of bodily functions and psychological impairments, such as depression, aggressivity, and sleep disturbance.
Over the last two decades, a number of biomedical efforts have suggested that multiple factors are actively involved in the disorder, including the accumulation of amyloid-β plaques, formation of tau-protein neurofibrillary tangles, low levels of acetylcholine, and mitochondrial dysfunctions [4–6]. Despite the substantial availability of scientific literature and the constant research effort, no effective and validated treatment for patients with AD can to date reverse symptomatology or stop disease progression [7]. In a very recent study, Kim et al. [8] have systematically reviewed eligible clinical trials for AD from the ClinicalTrials.gov database. 98 interventional phase II and phase III trials for unique compounds, carried-on between 2004 and 2021, were identified. The specific reason behind their failure was subsequently evaluated for each of them. The authors [8] elegantly demonstrated that the various methodological factors contributing to these clinical failures can be categorized into 1) insufficient evidence to initiate the pivotal trials and 2) pivotal trial design shortcomings. Although Kim et al. highlighted the relevance of a desirable complementary investigation focused on the statistical features of the failed trials, this remained unexplored in their work [8]. We therefore aimed to complete this big picture by means of a direct statistical evaluation of the efficacy of those trials.
In clinical trials the concept of efficacy is funded on the decision about the existence/non-existence of a treatment effect. In statistical terms, this is usually verified by means of a null hypothesis testing (NHST). Therefore, an effect is considered “positive” when the drug/compound under evaluation has a statistically significant effect (e.g., p < 0.05) on the primary endpoint compared to placebo. It is important to note that the NHST is a frequentist-based formal approach potentially associated to a number of issues. Common criticisms include a sensitivity to sample size, error rates, and statistical power [9, 10]. In particular, the failure to find a statistically significant result is often interpreted as an evidence that the effect does not exist at all. However, this is a misconception, as the NHST method does not allow to simultaneously draw inference for competing hypothesis (i.e., ‘the treatment showed an effect’ versus ‘the treatment showed no effect’) [11]. A correct interpretation only allows to conclude that there is no evidence of effect given the specific statistical parameters imposed (i.e., analysed sample size, selected p-value). In recent years, several authors have suggested that the NHST should no longer be the default statistical approach in biomedical field. Different inferential methods should be adopted instead to correctly address peculiar research questions and overcome the biomedical replication crisis [12–15]. In particular, the adoption of Bayesian-based models may offer several practical and inferential advantages [16–23] in the specific context of clinical trials. A relevant one is the Bayes Factor (BF) [24], an alternative hypothesis testing technique evaluating the conditional probability between two competing hypotheses. Here, we therefore used the BF approach to provide a statistical evaluation of the AD interventional phase II and III trials considered by Kim et al. [8]. In particular, we evaluated whether the failures of these clinical trials are essentially due to the lack of statistical power or to a true lack of effect. This offers an invaluable insight to understand criticalities associated with previous attempts, while suggesting an improved approach to evaluate future clinical trials.
MATERIALS AND METHODS
Data
We systematically reviewed the 98 failed AD compounds included in the study of Kim, et al. [8]. In order to be eligible for the subsequent analyses, clinical trials were retained if:
1) associated data were accessible through peer reviewed publications;
and
2) the Clinical Dementia Rating scale – sum of boxes (CDR-SB) had been used to evaluate cognitive and functional performance.
We decided to limit the analysis to a single cognitive test in order to avoid potential confounding effects due to methodological differences. Among those listed in Kim et al. [8] the CDR-SB was selected coherently with the recent work by Costa and Cauda [23]. Based on these selective inclusion criteria, 11 clinical trials interventional phase II and III from 2004 to 2021 were further considered [25–35]. For each of them, the mean and standard error (SE) for the placebo condition and the clinical condition, and the mean difference between the two conditions and the total standard error were obtained.
Statistical methods
The statistical technique used here was the Bayes Factor. The BF allows to determine the strength of the evidence for the null hypothesis H0 with respect to an alternative hypothesis H1. In this specific case, the BF can be conceptualized as follows:
H0 is therefore the model of no difference, while the H1 models the existence of an effect. The value of BF01 can range between 0 and infinite. When BF01 < 1 the evidence favors H1; conversely, when BF01 > 1 the evidence favors H0. Crucially, unlike the NHST, this approach fully models both the hypotheses. In other terms, this means describing “what the data should look like when there is an effect” [36]. Therefore, a probability distribution, with a specified shape, can be used to express the plausibility of different effect sizes. Since H0 hypothesizes no difference between groups, this can be modelled through a point-null hypothesis, meaning that 0 is predicted as the only plausible value. With regard to H1, clinical trials usually expect the effect to have a specific direction (e.g., improved score in a given cognitive test). Consequently, a convenient way of representing H1 is by means of a half-normal distribution centered on zero (see Fig. 1). This implies that small effects are expected to be more plausible than large effects.
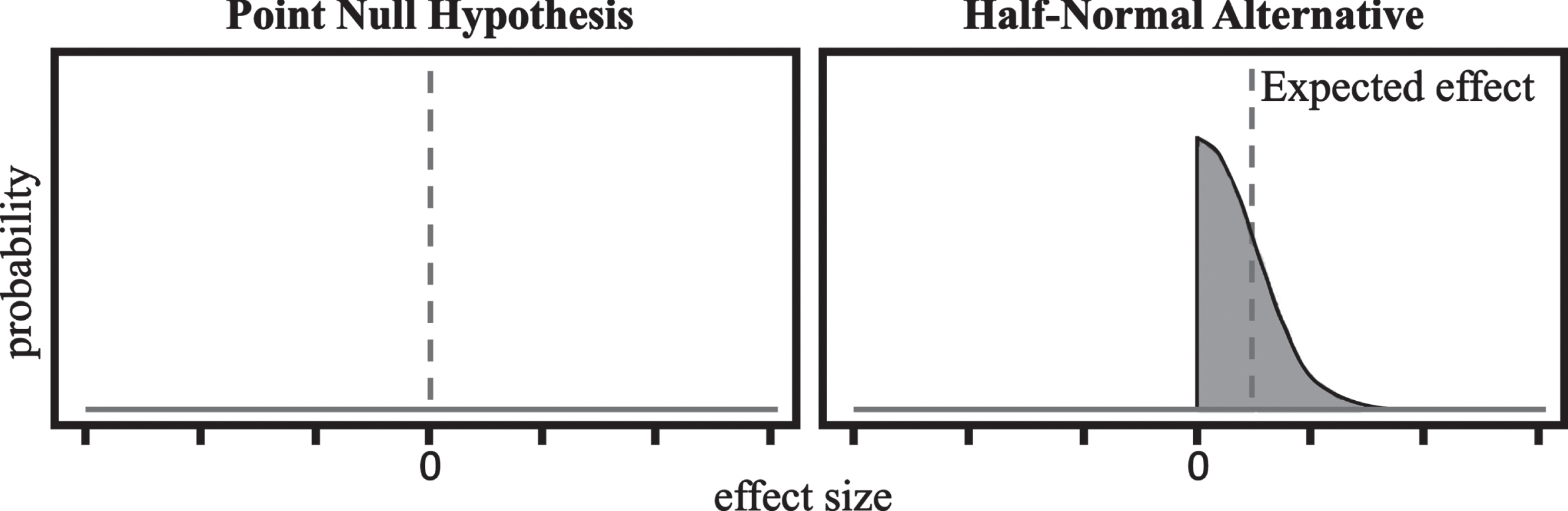
The two probability distributions used to model the hypotheses for the computation of the BF.
The standard deviation (σ) of such distribution is usually set depending on the scale the expected effect. According to the literature, a suitable choice for the standard deviation is half of the maximum measured or estimated value [36]. In this specific case, the maximum value to be considered is the one that allows you to pass from one class to another of the CDR-SB test. As this is 4 points, a σ = 2 was assumed. However, since the value assigned to σ could have an influence on the results, an additional sensitivity analysis was performed by iteratively varying the standard deviation of the effect size (from 1 to 3) and each time calculating the BF.
In light of the methodological differences among the 11 considered trials (e.g., groups design, administered dosages, type of drug) the BF was calculated separately for each one, without merging results. However, the BF value obtained can be directly compared, allowing to have an overview of the actual effectiveness of the considered clinical trials.
RESULTS AND DISCUSSION
For each of the 17 endpoints considered, the BF01 showed stronger evidence for H0(Table 1).
The obtained Bayes Factor (BF) values
This means that in no cases the hypothesis of observing a real effect was more plausible than that of observing no effect. The highest value BF01 = 150 was obtained for the 2019 trial on Verubecestat [33]. Of note, according to Kass and Raftery [37] a BF greater than 20 means that the force of evidence is strong. Overall, the probability density showed that most of the values are concentrated around an average BF01 of 24.26, and a standard error (SE) of 8.9 (see Fig. 2). Therefore, the null hypothesis (i.e., there is no real effect) was 24 times more likely than the alternative hypothesis (i.e., a difference exists between the groups). In terms of probability, we can be confident at the 96% that the treatment induced no effects, and that this is not due to design factors or sample size.
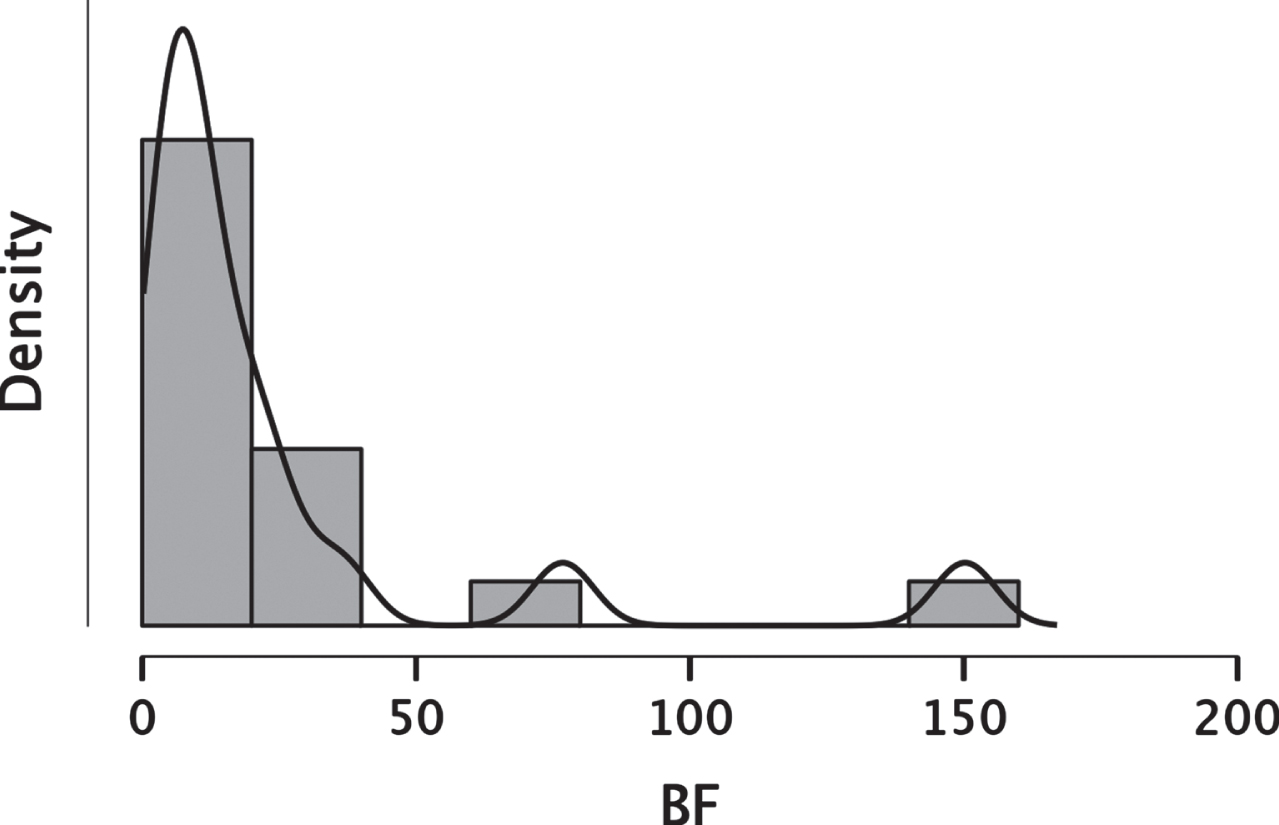
Density distribution of the Bayes Factor based on the CDR-SB test results reported in the investigated clinical trials. Note that, despite the binning, no values fell between 0 and 1.
Interestingly, the original results of the Verubecestat trial [34] reporting the inefficacy of the compound were very robust, as shown by their very small variance. The Bayesian analysis converged, giving a high BF that confirmed the strength of the evidence. Nevertheless, the information given by these results is different and somewhat complementary. The original study based on the frequentist approach [34] tell us that the effect of Verubecestat was negligible. The BF proves instead that, given the data collected during the trial, the result is 150 times more plausible under the assumption that Verubecestat is indeed ineffectual, rather than under the hypothesis that it is effective but the trial failed to detect its effect. The same logic can be extended to the other clinical trials considered. Since the Bayesian approach directly tests the effect, it is unaffected by the parameters that must be defined in the NHST framework. Therefore, while in frequentist analyses greater samples are more likely to produce significant results, and the statistical significance of the results primarily depends on the specific p-value selected, these features does not impact on the BF. Moreover, our analyses showed that the absence of real effect is highly plausible across all the study considered, despite differences in cohorts, sample size, tested compounds, level of significance. Therefore we can reasonably conclude that our results show that the failure of previous clinical trials was not due to methodological aspects, but to a real inefficacy of the treatment.
Finally, the sensitivity analysis, performed to test the possible influence of the value assigned to the standard deviation of the effect size, showed that result remained very stable. The probability to find no effect ranged between 93% and 97%. This indicates that the evidence of the null hypothesis is actually very strong.
Although the focus of this research is on statistical aspects, it is worth mentioning that the repeated failure of clinical trials is likely to be related with the lack of a clear etiopathological hypothesis. While the amyloid hypothesis has been followed for decades, it was repeatedly challenged [8, 39]. Therefore, it might not be a coincidence that all the failed compounds here considered but one (Nilvadipine) has a mechanism of action ascribable to the amyloid hypothesis.
Conclusion
In this short communication, a Bayesian framework was adopted to analyze the results of 11 failed clinical trials which tested different treatments for AD. The results showed that absence of real effect (i.e., H0) is highly plausible across all the study considered, despite differences in cohorts, sample size, tested compounds, level of significance. Therefore we can reasonably conclude that our results suggest that the failure of previous clinical trials was not due to methodological aspects, but to a real inefficacy of the treatment. This evidence gives a possible negative answer to the question posed by Kim et al. [8], if following more rational drug development principles could improve the success rate of clinical trials. On the contrary, a more common use of the Bayesian framework in biomedicine can improve the way we approach research hypothesis, possibly improving the insight obtained from clinical trials.
DISCLOSURE STATEMENT
Authors’ disclosures available online (https://www.j-alz.com/manuscript-disclosures/22-0942r1).