
Abstract
This paper is about the parameter identification of an energy based hysteresis model from measurements by employing automatic differentiation and neural networks. We first introduce the energy based hysteresis model and the parameters which are to be identified. Then we show how the model can benefit from automatic differentiation. After that we incorporate a parametrization of the energy based hysteresis model via distribution functions and identify the parameters of the distribution function. Then, the hysteresis model is sampled and the generated datasets are used to train neural networks to predict the hysteresis parameters. The described methods are tested and verified on synthetic as well as measurement data.
Introduction
The problem of parameter identification [1] is one of the key burdens of developing realistic simulations. Even though precise models and measurement data are often present, the step from measurement data to model parameters is a challenging one. This can manifest itself in long optimization runs, very demanding computations or challenging parametrizations. In this paper we are dealing with the parameter identification of an energy based hysteresis model. One of the main challenges associated with the identification of energy based hysteresis model parameters is the dependency of the model expressivity on the number of parameters. The problem with a growing number of parameters is that the dimension of the optimization space is also growing linearly with it, which makes the whole identification process more difficult. Also, with a larger number of parameters, calculating the derivatives of the error function with respect to these becomes more expensive. Therefore in this work we focus on mitigating these issues while still preserving an accurate depiction of the measurements.
The paper is structured as follows. First, the energy based hysteresis model [2] is introduced where the origin and the role of the hysteresis model parameters are explained. Then we show how and why automatic differentiation [3], which is mainly used in the machine learning community, is employed in this context. In doing so, derivatives of the hysteresis model can be efficiently computed while allowing for simple interfacing with optimization routines. Next, we introduce the general parameter identification problem. To simplify the whole problem we introduce a different parametrization of the hysteresis model parameters. This is done by describing the hysteresis parameters with distribution functions. Using such a parametrization of the model, we apply a classical parameter identification directly on the simplified parameter set instead of the whole hysteresis parameter set. Additionally, the simplified parametrization allows for generating samples of the hysteresis model which can be directly used for neural network training. These generated datasets are then used to condition a neural network to predict the parameters based on measured field values. Finally, the method is tested on synthetically generated data samples and then verified on measurements.
Energy based hysteresis model
Introducing the model
The energy based vector hysteresis model used in this work is based on [2] that writes the conservation of energy in the context of magnetic fields  denotes a time derivative. That equation states that every change in the magnetic field energy is accompanied by a power dissipation, so power that is entirely converted into heat due to irreversible processes in the material. To enforce a ferromagnetic behavior, the functionals u(
denotes a time derivative. That equation states that every change in the magnetic field energy is accompanied by a power dissipation, so power that is entirely converted into heat due to irreversible processes in the material. To enforce a ferromagnetic behavior, the functionals u(
Up until now, the model is only able to represent the major loop, since there is only one pinning force 𝜒. If this 𝜒 is overcome, the magnetization would suddenly start to increase according to the anhysteretic function. Such a sudden jump from zero does not depict a realistic behavior of a multi grain material with several magnetic domains. A common approach to model a bulk material with a certain number of magnetic domains is to introduce pseudo particles, which introduces N individual contributions, each with its representative pinning force
Automatic differentiation (AD) represents a set of methods for computing derivatives of computer programs. Other methods for computing derivatives include manual, numerical and symbolic differentiation. Manual differentiation involves calculating the needed derivatives ‘by hand’. This is quite labour intensive and very impractical for complex problems if not impossible. Numerical differentiation has the advantage of being very simple to implement in the form of finite difference methods. The biggest downside of finite differences is that they require a large number of forward computations of the problem. For most practical problems this is too expensive, especially considering the computation of gradients with respect to a large number of parameters. Another way of calculating derivatives is by symbolic differentiation. Although this method provides exact derivatives it is not practically applicable as it requires the problems to be written in closed form. Meaning that no loops, conditional statements and common programming paradigms can be used. This reduces the set of possible applications of these methods drastically. AD can be thought of as a combination of numerical and symbolic differentiation. This way it inherits the main advantages of both methods. It is easy to use, does not approximate but gives the exact values of the derivatives and can operate on arbitrary numerical code. Meaning that loops, conditional statements, recursion, etc., can be used.
AD achieves this by implementing differentiation rules on a low level. Meaning that for each basic numerical computation AD knows what the derivative function is. Additionally by applying the chain rule it can compute derivatives of more complex computations. This core idea is applied to any numeric program which receives input values and computes the corresponding output values. The first step is the construction of a so-called computational graph which represents the code in a graph structure where the nodes are variables connected with basic numerical computations. By doing so AD can then traverse the graph and compute the values of the derivatives for each node in the graph and apply the chain rule to combine these individual derivatives.
Depending on the direction, the graph is traversed, two variations of AD arise, the forward and reverse modes. For more detailed information on these we refer the reader to [3].
Employing AD
The introduced energy based hysteresis model was implemented in the Julia programming language. This allowed taking advantage of the large AD ecosystem of Julia which includes ForwardDiff [6], ReverseDiff [7] and Zygote [8]. To validate the derivatives computed with AD we do a simple test where we evaluate the implemented hysteresis model M
x
for a given excitation signal H
x
, the blue and red curves respectively in Fig. 1. Furthermore, the derivative
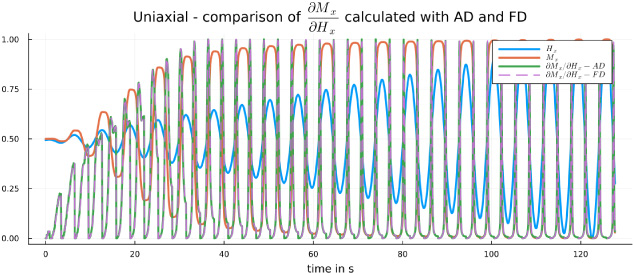
AD computed derivatives compared to Finite Difference results. Depicted on the plot are the excitation field H x (blue line), the magnetization M x (red line) resulting from evaluating the hysteresis model for the given excitation field and the computed derivatives (green and purple lines). All values are scaled to the range [0,1] for a better visibility.
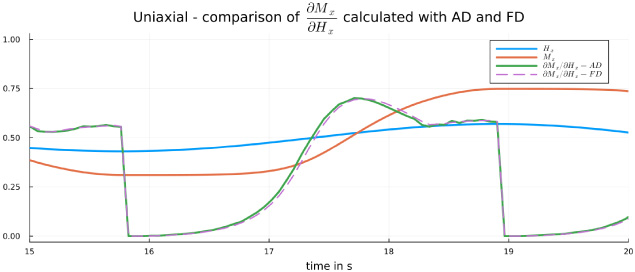
Zoomed view of Fig. 1 between 15 s and 20 s.
Problem setup
As previously introduced, the hysteresis model parameters are the
It is evident that the number of hysteresis model parameters grows linearly with the number of pseudo particles. This becomes challenging to optimize as the number of parameters increases while also ensuring that the given parameter constraints are met. Therefore in the next section we go over a method of how to reduce the number of parameters and eliminate the need for a constrained optimization.
From [9,10] we see that it is possible to draw the hysteresis parameters ω from distributions like the gaussian or rayleigh distribution, Fig. 3. The pinning force 𝜒 is then chosen as the random variable and for each 𝜒
i
we get a weight ω
i
, depending on the used distribution function. For the normal (gaussian) distribution we can write this as
From (13) it is clear how one can calculate the weights given the pinning forces and the distribution parameters, but how do we choose the correct pinning force values? In [10] the pinning force values for a given distribution function and number of pseudo particles N are obtained as the optimal nodes for a piecewise constant approximation of the PDF (probability density function) of the given distribution. We adopt a similar approach where the error of a piecewise linear interpolation of the PDF is minimized by iteratively placing nodes in regions with the highest errors, as can be seen in Fig. 4. This iterative process is repeated until the number of nodes is equal to the number of pseudo particles N. The initial two points are chosen such that the first pinning force 𝜒1 is 0 and the last one 𝜒N is the maximal H-field value, which can be obtained from the underlying data. Therefore, for a given number of pseudo particles, maximal H-field value and distribution function with its parameters, the hysteresis model parameters

Shapes of the Gaussian, Rayleigh and Gumbel distribution. For more information about the distributions, see [11].
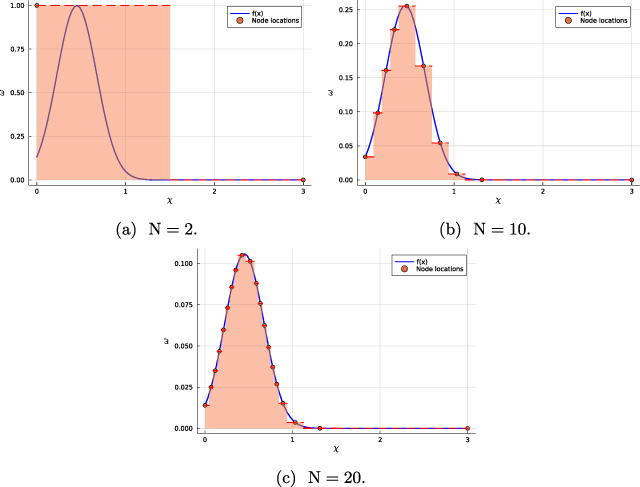
Hysteresis parameters drawn from a Gaussian distribution for different numbers of pseudo particles.
Further, we define a modified hysteresis model function
Here we solve the optimization problem given in ((14)) by optimizing the distribution parameters
Distribution parameter p
d
identification from synthetic data
Distribution parameter
If on the other hand we solve the optimization problem from (11) we obtain the results in Table 2. The resulting hysteresis curves of these two approaches can also be seen in Fig. 5. The problem with the optimization in the space of hysteresis parameters
Hysteresis parameter
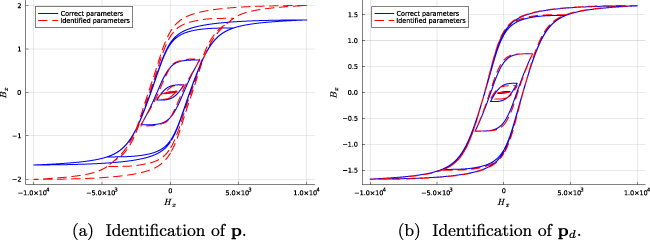
(a) Resulting hysteresis curves from parameters identified by finding the optimal
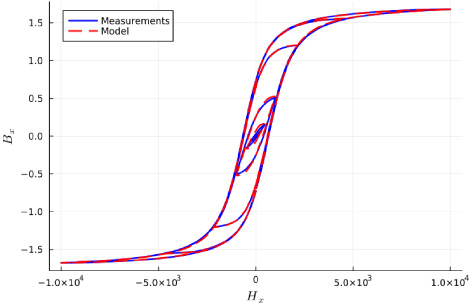
Measurement data compared to the model output with the identified parameters.
The basic idea behind the identification of the hysteresis model parameters with a neural network is to condition a neural network on data pairs (
The following table gives an overview of the data generated for the network training purposes. It is important to note that the type of the distribution has a great impact on the expressivity of the parameters generated with it. Therefore we include also the mixture model data which combines two distributions and allows for more complex parameter sets to be generated. For each dataset N s samples were generated with a latin hypercube sampling plan as given in Table 3. From the 10000 generated samples 5% is used for testing purposes which is a total of 500 points. The hysteresis model parameters obtained, are rescaled depending on the maximum H-field. This way one can reuse the generated parameter sets even for different input signals but needs to recompute the B-field values given the parameters.
Generated datasets for neural network training
Generated datasets for neural network training
Now that we have defined the problem and obtained data for the neural network we can describe the basic idea of identifying the parameters of the hysteresis model via neural networks. We denote the neural network as a function f
NN
(

Loss convergence for the training of the network predicting the μ parameter of
Root mean square errors of the three neural networks (M1, M2, M3) when comparing the hysteresis curves obtained from the predicted parameters
B-max-errors of the three neural networks (M1, M2, M3) when comparing the hysteresis curves obtained from the predicted parameters
Errors corresponding to the hysteresis curves calculated with the parameters obtained from the three constructed neural network models

Measurement data compared to the model output with the identified parameters.
In this paper we have shown two approaches for identifying the parameters of an energy based hysteresis model. They make use of the automatically differentiable and computationally efficient implementation of the energy based hysteresis model in the Julia programming language. Furthermore a modified parametrization of the hysteresis model based on distribution functions is utilized which makes it possible to treat the identification process as an unconstrained optimization problem. This is then used in the first approach to identify the distribution function parameters which generate the full hysteresis parameter vector. This approach shows good performance on the synthetical test data and measurements. The previously mentioned problem with the starting point for the identification process can be partially alleviated by running a stochastic optimizer first and then using its endpoint as the starting point for the BFGS algorithm. This way the global search is performed with the stochastic method and the local with the deterministic one. In the second approach a neural network, which is conditioned on synthetic data, is used to predict the parameters of the distribution functions given the B-field values. This method also gives good results for both, the synthetic test cases and the measurement values. One important point here is the data generation part. Care needs to be taken so that the generated dataset covers a large space of possible solutions from which the network can learn. This needs to be investigated further to find efficient ways of setting up the sampling. Other outlook points for this work include the application to measurements from a rotational single sheet tester and more complex excitation field signals.
Footnotes
Acknowledgement
The work is supported by the joint DFG/FWF Collaborative Research Center CREATOR (CRC - TRR361/F90) at TU Darmstadt, TU Graz and JKU Linz.