
Abstract
This paper proposes a frequent itemset mining algorithm based on the divide and conquer strategy in composite granular computing. In order to construct composite information granules (CIGs) and find the frequent patterns, an iterative approach is used in this algorithm. First, create atomic information granules. Next, atomic composite information granules are generated by atomic information granules. Then, through the intersect operation between atomic composite information granules and prune action, the frequent 2-CIGs that will be used to construct frequent 3-CIGs will be constructed, and so on, until no more frequent CIGs can be found. When creating CIGs, this method will improve the computing speed by logical operation in binary. It can avoid scanning database frequently and avoid using complex data structure, so it will reduce the I/O overhead and save a lot of memory space. And it also can optimize the generation of candidate CIGs and compress the transaction database dynamically. The experimental results show that this algorithm has good performance and has low computational complexity and high efficiency.
Introduction
Data mining, the knowledge discovery in database (KDD) [1], has been the hot topic in research of artificial intelligence [2, 3, 4, 5]. One important task in data mining is mining the association rules, which needs to find out interesting rules in transaction database [6, 7, 8]. Apriori algorithm is one of the most classic algorithm in data mining, which is a seminal algorithm proposed for mining frequent itemsets for association rules [9]. From Apriori was proposed by Agrawal and Srikant in 1994, many researches have proposed a lot of algorithms for mining association rules [10, 11, 12]. According to the characteristics of generating frequent itemsets for these mining algorithms, we can divide them into two types.
Mining association rules with candidate generation. This kind of mining algorithms needs to generate candidates when searching frequent itemsets. They are based on Apriori algorithm framework. The advantages of this kind of algorithms are that they use simple data structure, low memory usage, and these algorithms are easy to be realized. The disadvantage is that they need to scan database frequently and generate a large amount of candidates. The other type is the mining algorithms that search frequent itemsets without candidate generation. They are based on FP-growth algorithm framework. The advantage is that the running speed is fast. But the disadvantage is that because this kind of algorithms needs to construct tree, a complex data structure, they will use a large amount of memory space.
Granular computing (GrC) is a new method for simulating human thinking and solving complicated problems [13, 14]. This kind of information processing is referred to as the processing of information granulation [15]. When you use GrC to solve problems, you can analyze the same problem at different levels of granularity. This low cost problem solving method can greatly simplify the complicated problems.
Rough set theory, quotient space theory and fuzzy set theory are three main theory models in GrC [16, 17, 18, 19, 20, 21]. The main task of GrC is about representing, constructing, and processing of information granules [22]. Information granules can be formalized by many different approaches [23, 24]. GrC as a methodology has been introduced in many fields [25, 26]. Li et al. [27] presented a line flow GrC approach for power flow calculation to assist the investigation on economic dispatch (ED) with line constraints, where the hierarchy method is adopted to divide the power network into multiple layers to reduce computational complexity. Kok and Chan [28] proposed a novel crowd segmentation framework based on GrC to enable the problem of crowd segmentation to be conceptualized at different levels of granularity, and to map problems into computationally tractable sub-problems. Roselin and Thangavel [29] presented the rough entropy based on GrC to segment mammogram images.
Recently, GrC has been introduced in data mining [30, 31]. more and more researchers focus on finding association rules based on the GrC [32, 33, 34]. Xu et al. [35] focused on the association rules and decision-making rules of the information system based on classical granular computing and association rules. Fang and Wu [36] proposed a kind of finding frequent spatiotemporal association patterns mining based on granular computing. Although some algorithms described association rule mining based on formal methods, they are also restrained by traditional mining algorithm frameworks. The efficiencies of these methods are undesirable. For instance, Ju et al. [37] designed an improved frequent patterns mining algorithm based on transactional granule. It is also a mining algorithm based on the Apriori framework. Tsai et al. [38] found the generalized negative association rules by granule computing. The running speed is fast. While, it is also a mining algorithm based on the FP-growth framework.
In order to make more use of the advantages of these two traditional classic mining algorithm frameworks and further improve the efficiency of association rule mining algorithm, this paper puts forward a kind of frequent itemset mining algorithm based on composite granular computing (FIMCG), which uses the simple data structure and uses divide and conquer strategy in composite granular computing to calculate the support counts of itemsets. It can avoid scanning database repeatedly and reduce the computational complexity and the I/O overhead. When FIMCG generates new CIGs, it can use binary operation to improve the computing speed. It also can optimize the generation of candidate CIGs, and compress the transaction database dynamically.
In this section, we present the related concepts and definitions of composite granular computing based on the set theory.
Note that, this EIS has one more element,
For example, if
It is constructed by the frequent atomic information granule (FAIG). ACIG is also frequent. It has one more element (the binary sequence
Proof: If transactions and items with in a transaction are sorted in lexicographic order, the intensions of
Proof: When this algorithm generates
The corresponding relations between CIG, information granule, and traditional association rules are shown in Table 1 [41].
The corresponding relations of concepts
Note that: the CIG is an extended model of information granule. The composite information granule, which is proposed by us, can compress the relational database to reduce data, and fast generate the intension of CIGs, candidate itemsets, through the intersect operation between two CIGs. There are more details about the use of CIG as described in Section 3.1.
In this section, one detail example about the use of CIGs and the algorithm description which is used to find frequent itemsets efficiently is given. And then, the performance analysis and experiment results are displayed to verify the efficiency of this new algorithm.
The example
According to the related concepts and definitions of composite granular computing in Section 2, this kind of frequent itemset mining algorithm based on composite granular computing, FIMCG algorithm, can be described as follows: according to the minimum support, find out all
Although FIMCG algorithm in this paper will generate candidate itemsets, the way of generating candidate itemsets is different from Apriori algorithm framework. According to composite granule computing, FIMCG only need to scan database once, and then find out the frequent itemsets, so it can reduce I/O overhead as FP-growth algorithm framework. And FIMCG don’t need to traverse the complex frequent pattern tree like FP-growth. It won’t use a large amount of memory space.
Suppose there are itemset
Scan the database, set support at 50%, we can get the following atom information granules,
AIG
The support count of
ACIG
Next, the new 2-CIGs will be generated by the intersect operation between ACIGs based on bottom-up method. The remark-“prune” after the information granules means these information granule have been deleted. According to the Definition 4, using the intension and the binary sequence of each ACIG, we will get the following CIGs,
CIG
This FIMCG algorithm executes intersect operation continuously. According to the Definition 5 and Corallary 1, this algorithm is optimized continuously, when it generates the intensions of CIGs. According to the Definition 6 and Corallary 2, FIMCG calculates support counts, prunes some branches off, and compresses transaction database dramatically when it generates the extensions of composite granules. The rest of the CIGs are as follows,
CIG
Algorithm description
1)
2)
3)
4)
5)
6)
7)
8)
9)
10)
11)
12)
13)
14)
15)
16)
17)
18)
19)
20)
21)
22)
23)
24)
25)
26)
27)
28)
29)
30)
31)
32)
33)
34)
Next, we analyze the performance of Apriori algorithm, the improved apriori algorithm based on transactional granule (IG-Apriori), FP-growth and FIMCG algorithm.
Performance analysis
Performance analysis
From Table 2, that shows about the scan times of database, data structure, generate candidates, memory usage, and CPU overhead, we know that FIMCG performs more excellently compared with Apriori and IG-Apriori and FP-growth. Therefore, it suggests that FIMCG, the improved algorithm in this paper, is effective and feasible.
In order to verify that FIMCG has more advantages in runtime and memory usage compared with Apriori, IG-Apriori, and FP-growth. The experimental results are given as follows.
Experiment environment: Windows 8 (32-bit), Intel (R) Core (TM) i3-3120M CPU @ 2.50 GHZ, 4 GB RAM. Software development environment: Microsoft Visual Studio 2013, C# programming language.
The test data in Figs 1 and 3 comes from dataset, Food Mart 2000, in SQL Server 2000, which is filtered from 164558 sales data in 1998. There are 34015 records in dataset, and the number of attributes is 23. This dataset is used to reflect the performance of each algorithm under the same transaction number, but the different supports.
The test data in Figs 2 and 4 comes from 4 sub-datasets in ExtendedBakery. They are 1000, 5000, 20000 and 75000 records in each sub-dataset respectively, and the number of attributes is 50. They comes from a website, which is
Runtime of the four algorithms under different supports on dadaset Food Mart 2000.
Runtime of the four algorithms under the support 0.5% on 4 sub-datasets in ExtendedBakery.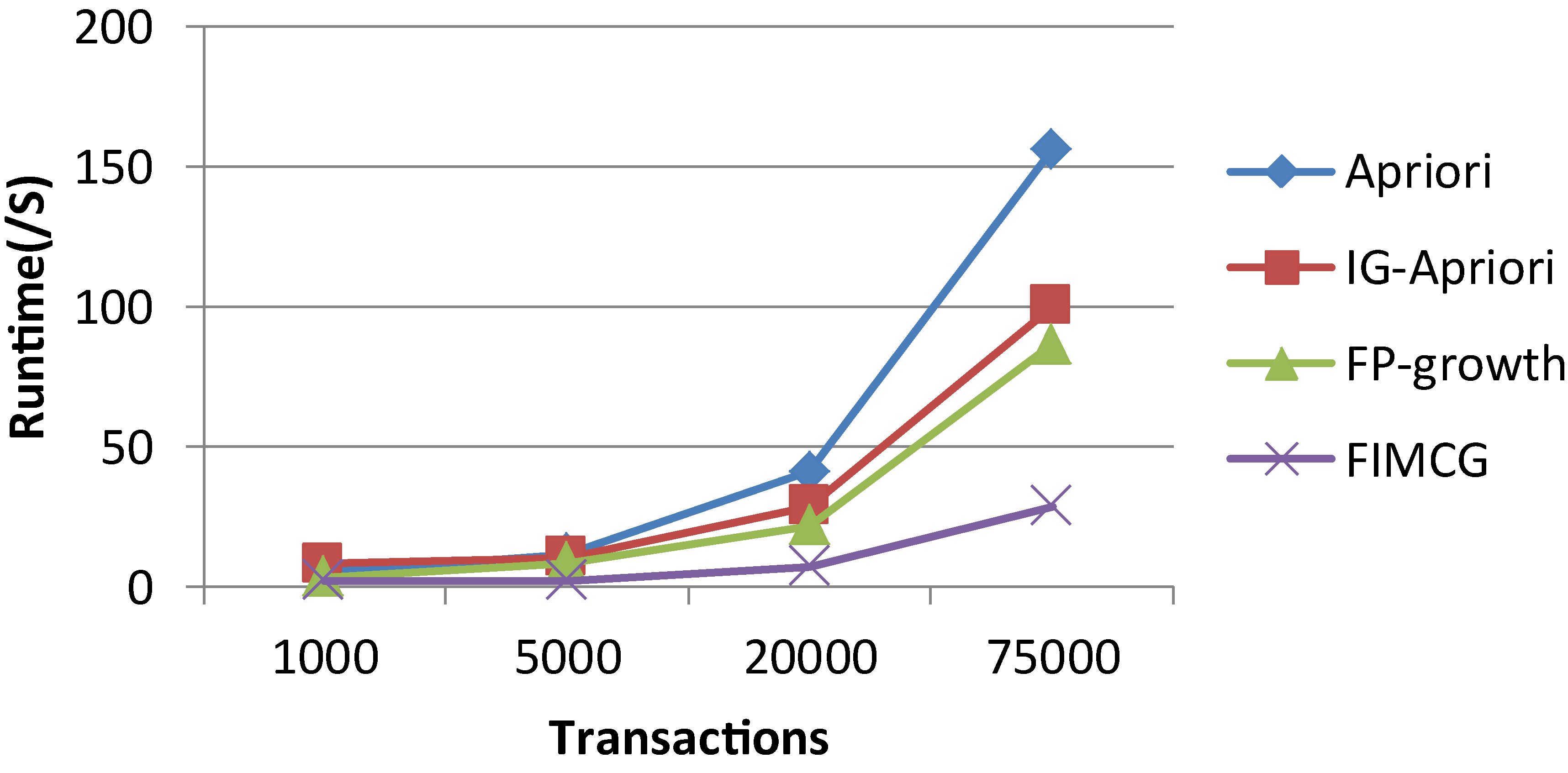
Memory usage of the four algorithms under different supports on dadaset Food Mart 2000.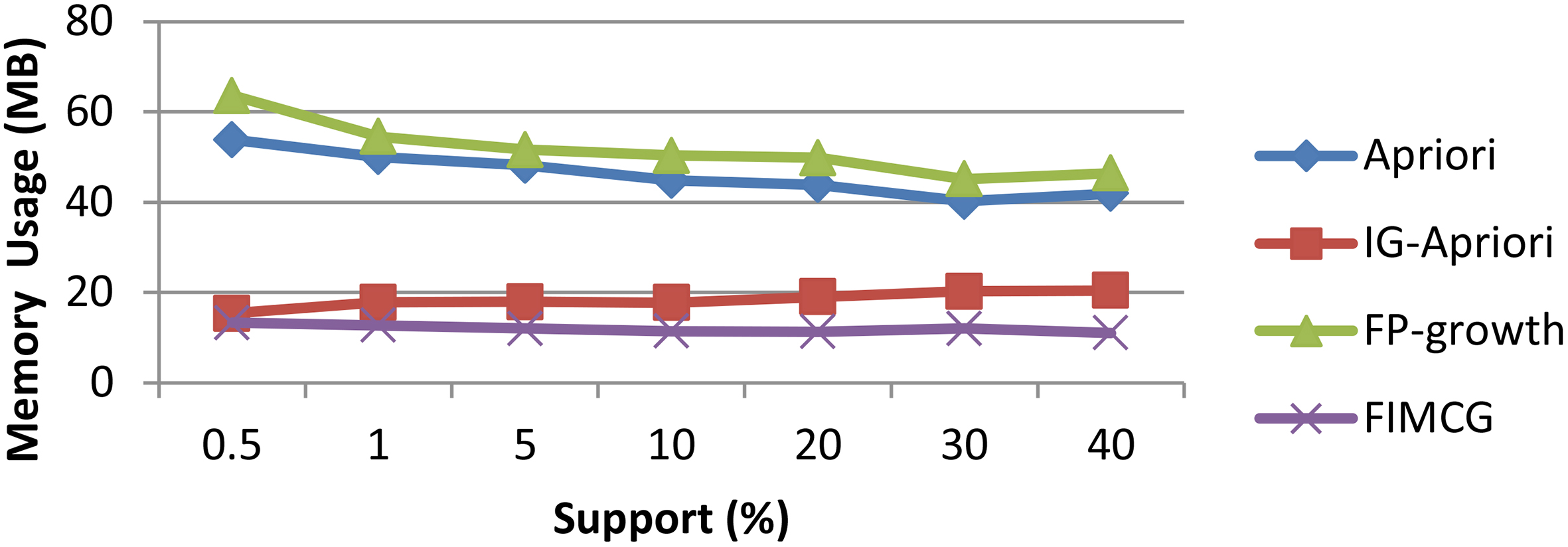
Memory usage of the four algorithms under the support 0.5% on 4 sub-datasets in ExtendedBakery.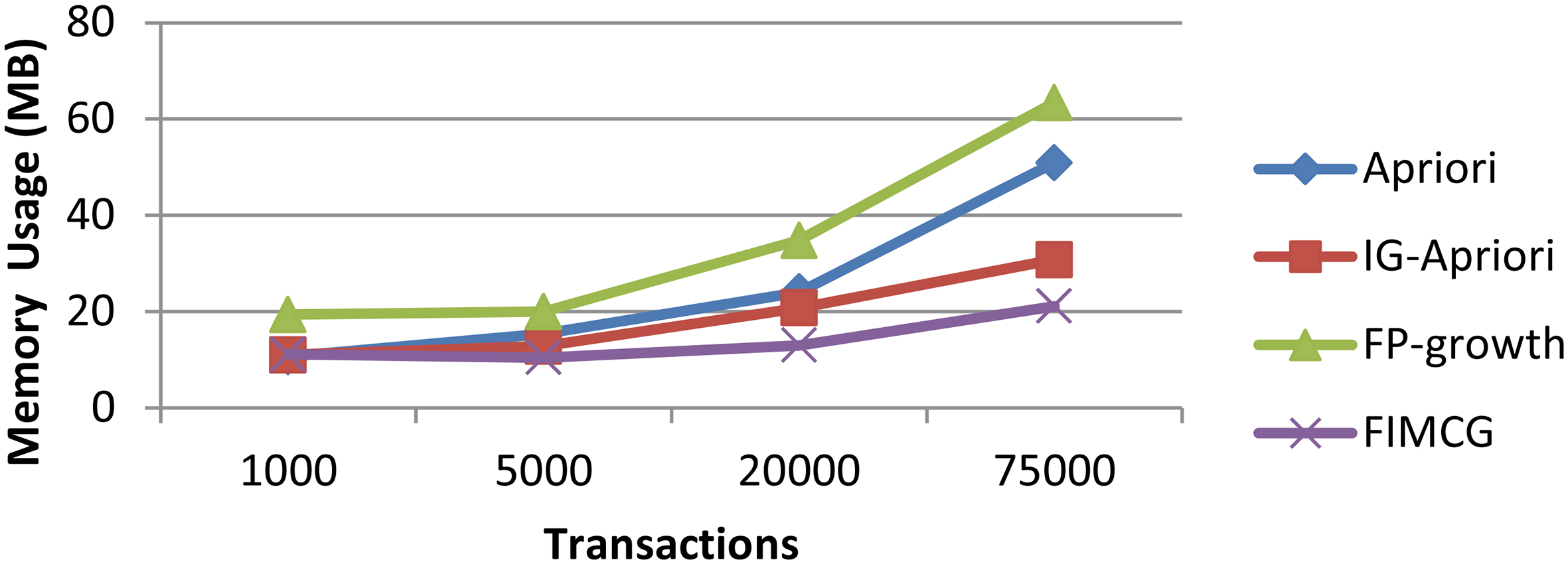
Figure 1 shows that with the change of support, the FIMCG algorithm in this paper run faster than the classic Apriori algorithm, FP-growth, and IG-Apriori algorithm. Figure 2 shows that the performances of classic Apriori algorithm, FP-growth and IG-Apriori algorithm dramatically decline with the increase of transactions. Particularly when there are a lot of transactions and attributes the efficiency of FIMCG algorithm is higher because the FIMCG use binary image operation to improve the computing speed, optimize the generation of candidate CIGs, and compress the transaction database dynamically.
The memory usage of four algorithms as shown in Figs 3 and 4. Memory usage refers to the max memory usage, including the memory space used by codes and temporary storage units.
Figures 3 and 4 show that the memory usage of FIMCG are less than Apriori, IG-Apriori and FP-growth, especially much less than FP-growth. The main reason is FP-growth uses the complex tree data structure, while the FIMCG use the simple linear array.
In order to further discuss the GrC in the application of association rule mining, this paper presented a new improved frequent itemset mining algorithm based on composite granular computing. First, AIGs were founded. Next, ACIGs were generated by AIGs. Then, by the intersect operation between ACIGs and prune actions, the frequent 2-CIGs that will be used to construct frequent 3-CIGs were constructed, and so on, until no more frequent CIGs can be found. This method used simple data structure, avoided multiple scanning database, improved the operation speed, and reduced the computational complexity, memory usage and I/O overhead. The algorithm also optimized the generation of candidate itemsets and compressed certain degree of transaction database dynamically. Experiments showed that this algorithm improved the algorithm efficiency, and had lower complexity.
Footnotes
Acknowledgments
This research is supported by Scientific and Technological Research Program of Chongqing Municipal Education Commission (Grant No. KJ1401010), Chongqing Municipal Key Laboratory of Institutions of Higher Education (Grant No. [2017]3), and Scientific and Technological Research Program of Chongqing Municipal Education Commission (Grant No. KJ1601015).
Conflict of interest
The authors declare that they have no competing interests.