
Abstract
The development of web applications based on the Internet, especially the mobile Internet, is very rapid and the traditional test methods have limitations. This paper proposes a method based on user session similarity and an improved agglutination clustering algorithm to automatically generate test cases. This approach not only guarantees the validity of the test, but also maintains the order in the user’s session. This method gives the definition of similarity between two URLs, and then uses a dynamic programming algorithm to calculate the similarity between two user sessions. Secondly, a bottom-up aggregation-level algorithm is used to similarly cluster user sessions. Finally, a new method was used to select representative test cases and remove redundant test cases. The experimental results show that the method of this paper can generate suitable test cases quickly and efficiently.
Introduction
There are many widely used tools and methods for automatic testing. For example, Xie and Luo [21] proposed a new automatic testing approach to check the invoke state of the appointed application interfaces (APIs) of software package, which is an important test item for the acceptance test Recording/Replay techniques are typically used for automated functional testing and performance testing. Record/Replay tools record the actions of test engineers. And under the pressure of high loads, executing them against the system can acquire the performance indexes such as throughput, user concurrency, response time. But test engineers usually spend plenty of time recording or scripting the actions, and generating test data manually. However, it only represents the operations of test engineers and cannot stand for all the realistic users. In other words, the generated loads by test script may not be in accordance with the scenario acted by actual users. Therefore, the validity of testing results cannot be guaranteed. Nowadays, web applications have the characteristics of distribution, heterogeneity and independent platform, which makes the performance testing technology for traditional web applications not suitable anymore.
To solve the problems mentioned above, this paper proposes a method that the user sessions data is utilized to improve the automatic performance testing. User sessions bring valuable insight into dynamic behavior of web applications. Over the past decade, many researchers have made important contributions to the testing method based on user sessions [1]. But seldom researchers have concerned about user-session-based technique with performance testing. The authors argue that it’s meaningful to combine performance testing with user-sessions-based technique. The data acquisition technique is used in user sessions, so the web testing method based on user sessions can create test cases automatically and reduce artificial efforts. Moreover, test cases generated by user-session-based approach can reflect the behaviors of real users, which is of significant importance for web applications performance testing; meanwhile, user sessions can be easily captured and available to test engineers. Thus, it is feasible to use user sessions which are recorded in server logs to generate performance test cases.
However, the number of test cases generated by user sessions without processing is usually enormous and possibly unfeasible. Besides, a considerable numbers of test cases are redundant. That is, the redundant test cases exercise the same behaviors and output similar test results. In addition, it’s time-consuming to execute all test cases. For these reasons, reduction, prioritization and selection of user sessions should be applied for user-session-based performance testing, which can effectively enhance the efficiency and performance of test suites. Clustering is a widely-used technique in the field of data mining that organizes similar objects into a single collection. By using cluster technology, user sessions can be clustered to different classes which can be taken as various test suites. From each test suites, typical test cases are selected and the redundant ones are deleted. Therefore, the remaining test cases are typical and valid.
The approach proposed in this paper aims at reducing the manual effort when test engineers design the performance test cases and output the realistic, valid, optimized test suites to simulate system behaviors. One of innovative key points is that sequence alignment algorithm is used to calculate the similarity between user sessions, which makes the generated test suites more meaningful because the order of user sessions is ensured. The other key point is that agglutinate hierarchy clustering algorithm is employed to cluster typical test cases based on user sessions and reduce redundant test cases.
Related work
Performance testing
There are currently two methods for generating test cases in the field of performance testing: handwritten scripts and recording/playback methods. In many cases, due to the complexity and the lack of effective automated test tools, performance testing is still done by hand-writing scripts that the user behaviors are described as a subprogram [2, 3]. For each virtual user, each subprogram is performed to describe certain aspects of each virtual user’s behaviors. The hand-written scripts method is the most flexible which is suitable for all kinds of web applications. However, it needs a lot of manual work to construct the scripts, contrary to the idea of automated testing.
Record/replay technology is also widely employed by many automated test tools. For example, software load testing tool Load Runner [4] can realize automation testing by recording and replaying the operations performed by real users. There is no demand for programming skills to conduct the test cases, but test engineers usually spend a lot of time in recording or designing the test scripts manually. Moreover, it only represents the operations of test engineers and cannot stand for all the true users, which means the loads generated by test script may not accord with the loads generated by actual users. Therefore, the validity of the testing results can not be ensured.
Zhen and Yun [5] proposed a method which leverages user session data to assist web application performance testing. The researchers discussed the prospect of performance test area and indicated the insufficiency of traditional performance test approach. But there only presents a process model without a specific method to cluster the user sessions or optimize the test cases. Quan and Lu [6] presented a session-based user behaviors Meta model (SUBM) to automatically generate test cases for user level QoS load testing. SUBM applied decision-tree-based algorithm to cluster name-value pairs in server logs for automatic test data generation and employed the Longest Common Subsequence (LCS) algorithm to seek common Hyper Text Transfer Protocol (HTTP) request sequences for test scripts generation. However, they did not apply cluster algorithm but simply used LCS algorithm to process the Uniform Resource Location (URL) sequences, so the time complexity is high and the test suite is incomplete.
User-session-based technique and web sessions clustering
Although most of researches on user-session-based technique were done for functional testing, it’s still worth reviewing predecessors’ work. For example, Elbaum et al. [7] firstly leveraged the collection of client’s request information in server logs to conduct test cases and reported the experiment results by comparing new test generation techniques with traditional ones. Rothermel and Harrold [8] and Chen et al. [9] proposed a theory that the selection of test cases can improve the test efficiency because a considerable test cases can lead to similar test results. Nowadays, some researchers have applied cluster algorithm to assist test cases selection. For example, Sampath et al. [10] regarded user sessions as entities when apply it to cluster user sessions, and on that basis, they achieved user-session clusters by using clustering algorithm, then found out the representative user session from each test suite for simplifying the test suites. They also programmed a practical user-session-based test tools and showed the experimental results in their researches [13]. In the research of Wu and Gao [14], hierarchy clustering technique was firstly applied to a huge set of real internet traffic traces so as to identify web user sessions. A novel bottom-up clustering algorithm is proposed and compared with the classical threshold-based scheme. Liu et al. [15] proposed a method called User Sessions Clustering based on Hierarchical Clustering algorithm (USCHC) for test cases optimization. The distance between user sessions is calculated and agglutinate hierarchical clustering algorithm is adopted to cluster the initial test cases, then the test suited with various types are produced. The research not only considers the similarities of the URLs sets, but also the similarities of data type.
However, for most of the methods in the literature to deal with cluster user sessions, sessions are regarded as sets of visited pages within a time period without considering the sequence of click-stream visitation. In this paper, the authors argue that it’s significant to maintain the order of user sessions because the order of URLs in user sessions reflects the operation order of real users. In order to generate the real loads, it’s essential to consider the sequentiality of each user sessions. For most of the cluster algorithms, when clustering user sessions are used, sessions are treated as unordered sets of URLs. The measures used to compare the similarity between sessions are simply based on intersections of these sets such as cosine measure and Jaccard measure [20] which is as follow. X and Y mean the set of elements.
The process model and algorithm of the proposed method are shown in Fig. 1. A detailed description of the algorithm will be given later.
Process model of the modified hierarchy clustering algorithm.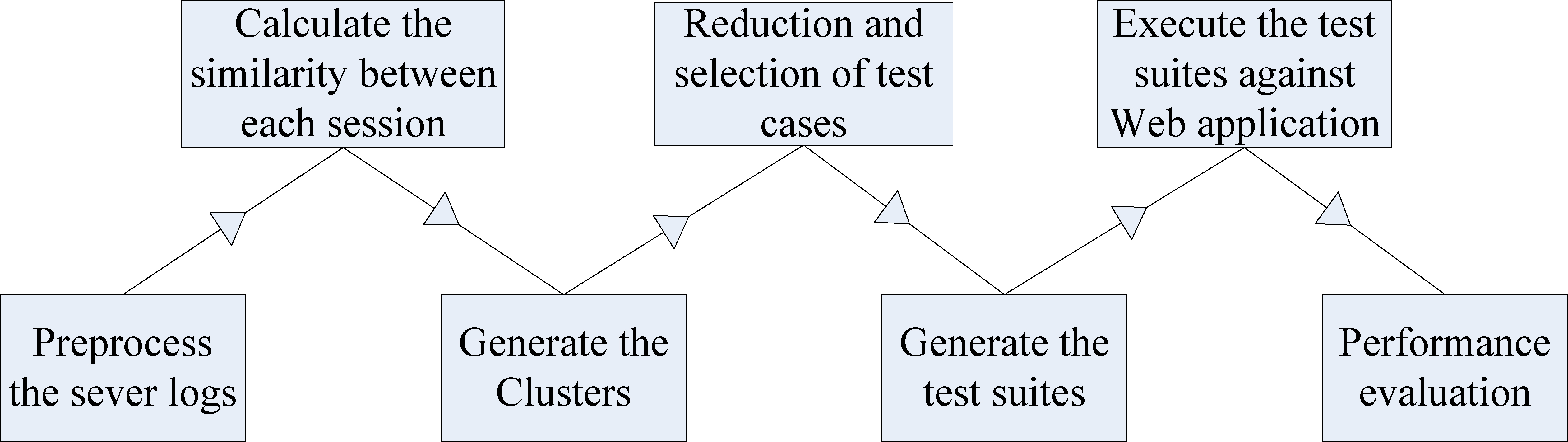
Firstly, the server logs are preprocessed, and a dynamic programming algorithm is utilized to calculate the similarities between two user sessions. Secondly, a bottom-up agglutinate hierarchical algorithm is employed to cluster the similar user-sessions. Thirdly the authors propose a method to select the representative test cases and delete the redundant test cases. Finally, the typical test suites are generated.
The under-mentioned algorithm firstly measures the distance between user sessions on the basis of the similarity between user sessions, then clusters initial user-session-based test cases; after the test cases are clustered into test suites, relevant and typical test cases are selected to replace suites.
The first problem is how to measure the similarity between sessions on the premise of ensuring the sessions’ sequentiality. Most of the previous related works apply either Euclidean distance for vector or set similarity measures, but the disadvantages are obvious: (1) The transferred space could be high-dimensional; (2) The original click stream is naturally a click sequence. It cannot be fully represented by a vector or a set of URLs without considering the order of clicks; (3) Euclidean distance has proven not suitable for measuring similarity in categorical vector space.
The authors consider the original session data as a set of sequences, and apply sequence similarity measure to measure similarity between sessions. Sequence alignment actually is not a new topic; in the field of biology research, there already exist several algorithms for solving sequence alignment problems [16, 17]. In the light of the basic ideas of these algorithms, the technique is put forward to measure the similarity between session sequences.
There exist two steps in definition of session similarity in this paper. Firstly, it’s necessary to define similarity between two web pages because each session includes several web pages; the second step is to define session similarity using page similarity as an inner function.
Preprocess server logs files and calculate the similarity between web pages
It’s known that most of the web applications use directory tree to organize web pages or other kinds of recourses. Therefore, every URL is layered. It can make use of this characteristic to measure the difference between each URL.
One example is the following three URL:
http://www.unl.edu/ucomm/research/index.html http://www.unl.edu/ucomm/research/current.html http://www.unl.edu/newsroom/index.html
It’s not difficult to find out that URL1 and URL2 are very similar pages in the same subdirectory “research”. Besides, there is some similarity between URL#1 and URL#3, but the similarity is obviously not as strong as the similarity between URL#1 and URL#2 in the previous example. A systematic method is needed to give a numerical measure for calculating the similarity between two URLs.
In order to measure the similarity between two web pages, each level of a URL is presented by a token. Thus, the token string of the full path of a URL is the concatenation of all the representative tokens of each level. This process corresponds to the labeled tree structure of a website as shown in Fig. 2.
A labeled tree structure of a web application.
For example, ‘www.unl.edu/ucomm/current/information.html’ in Fig. 1 is presented by the token string as ‘0111’, and ‘
The web similarity computation is divided into two steps:
Each corresponding token of the two token strings is compared one by one from the beginning, and this process stops when the first pair of different tokens appears, then record the number of the tokens which are the same as Suppose the number of the longest token string is
The variables
If the two pages are totally different, which means that they have no same corresponding tokens, their similarity is
After defining the method of calculating the similarity between two URLs, we can measure sessions’ similarity on this foundation, and use dynamic programming technique to find the best matching between two sequences. Most of the sequence alignment algorithms are on the basis of dynamic programming. In fact, Sequence alignment is a fundamental operation in bioinformatics [18]. Pairwise sequence alignment is used to determine homology (i.e., similar structure) in both DNA and protein sequences, so we can gain insight into the functions of DNA and protein sequences. In this paper, Basic ideas from Sequence alignment are used to calculate the similarity between each session.
A scoring system is used to find out the optimal matching between two session sequences. An optimal matching is an alignment with the highest score [19]. The score for the optimal matching is then used to calculate the similarity between two sessions. The followings are the principles in matching the sequences:
The matching score of US1 and US2 is as followed.
According to the Eq. (4), the similarity between US#1 and US#2 is 0.625.
It is not simply counts the number of identical web pages when session sequences are aligned. Instead, a scoring function based on web page similarity measure is employed. For each pair of web pages, the scoring function gives a similarity score where higher score indicates higher similarity between web pages. A pair of identical web pages is only a special case of matching – the scoring function returns
The problem of finding out the optimal matching can typically be solved by using dynamic programming method. Here a specific example is presented to describe the process of the method.
Suppose there are two user sessions:
Session matching matrix.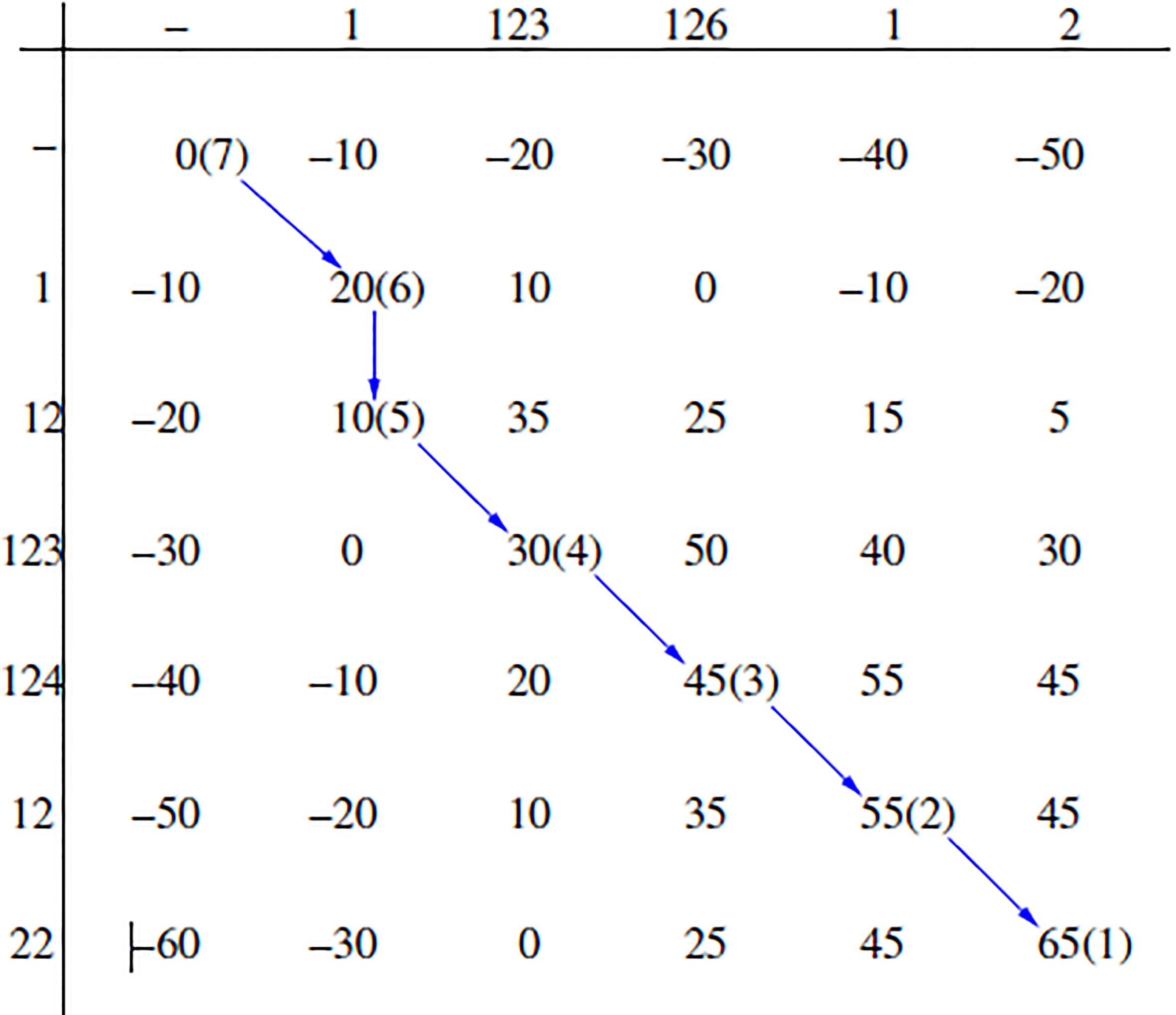
The process can be described by using a matrix as shown in Fig. 3. One sequence is placed along the top of the matrix and the other sequence is placed along the left side. A gap, being added to the start of each sequence, indicates the starting point of matching. The process of looking for the optimal matching between two sequences is actually to search an optimal path from the top left corner to the bottom right corner of the matrix. Any step in any path can only go right, down or diagonal. Each shift based on diagonal corresponds to the matching between two web pages. The right shift means that a gap is inserted into the vertical webpage sequence to match the webpage in the horizontal sequence. And the downward shift means that a gap is inserted into the horizontal webpage sequence to match the webpage in the vertical sequence.
In order to solve the optimal matching problem, the dynamic programming algorithm propagates scores from the matching start point (upper-left corner) to the destination point (lower-right corner) of the matrix. The optimal path is then achieved through the back propagation from destination point to starting point. In the given example, the optimal path is connected by arrows where the numbers in brackets indicate the step number in back propagation. Besides, it shows the best matching pattern. The scores of any element in the matrix are the maximums in the following three directions: left, upper and upper-left. For example:
Calculation example.
The score of
The score in the lower-right corner is the optimal sequence alignment score. After finding out the final score for the optimal session alignment, the final similarity between the two sessions is computed by considering the final optimal score and the length of the two sessions.
The algorithm of this part is concluded as followed.
On the basis of the distance measure method in the above description, agglutinate hierarchy clustering algorithm is employed to cluster the test cases generated from user sessions now. In data mining, agglutinate hierarchical clustering is a method of cluster analysis which seeks to build a hierarchy of clusters. Each cluster starts from its own set. When each set gradually moves up to the hierarchical structure, the sets conforming to the clustering are merged. And the cycle repeats itself until the terminal condition of clustering is satisfied. Compared to K partitioning clustering, the agglutinate hierarchical clustering has the advantage of fewer input parameters. More importantly, agglutinate hierarchical clustering can apply to numerical data as well as categorical data. Figure 5 shows how the agglutinate hierarchical clustering algorithm is working.
Agglutinate hierarchical clustering.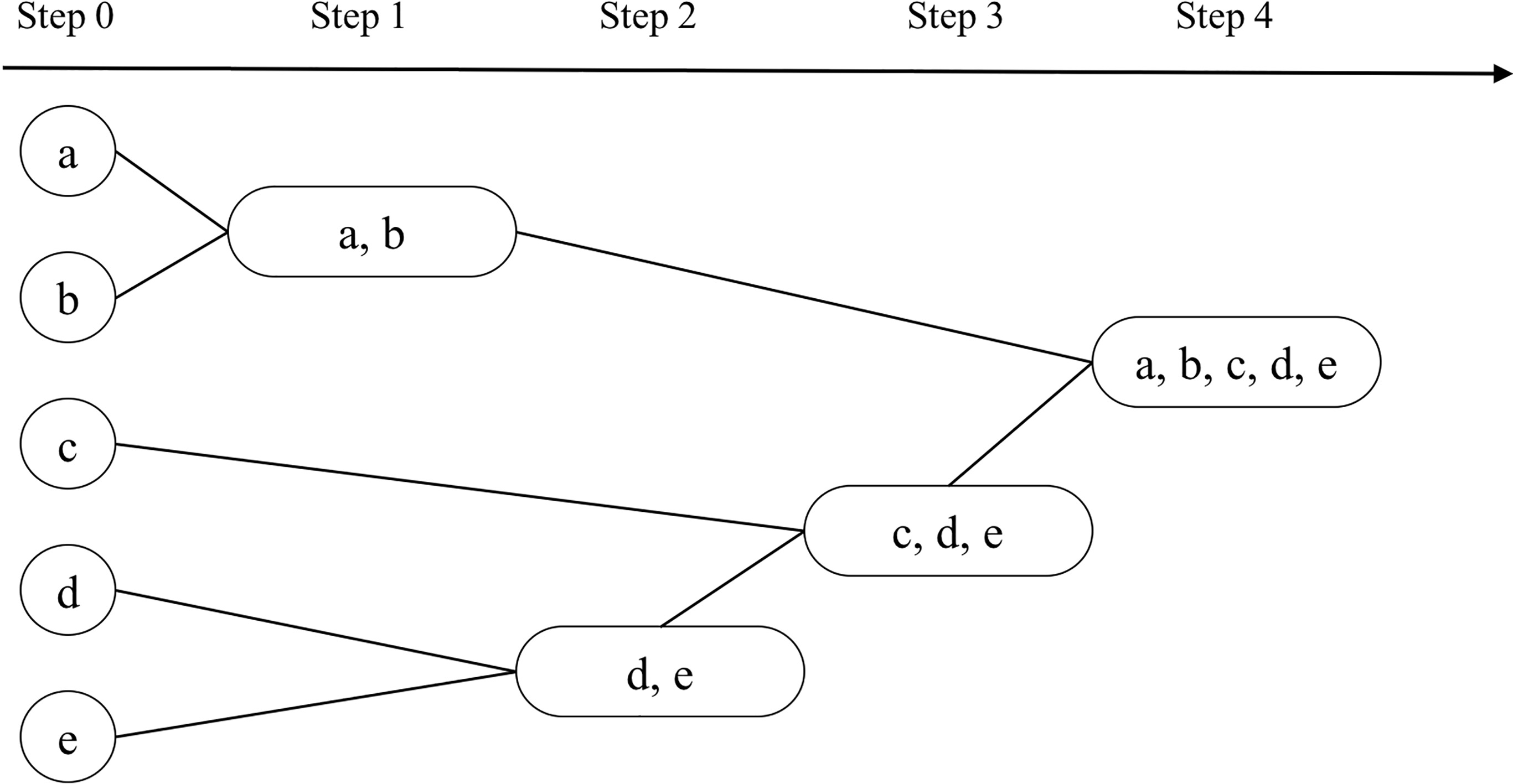
The modified clustering algorithm is described as follow.
Initially, each test case is regarded as a test suite. The initial distance matrix is generated, then two sessions with the minimum distance are clustered into one test suite from the distance matrix. If the number of test suites meets the demand, then quit, otherwise continue clustering (a minimum distance
Where Output the final clustering result of test cases as the input for optimizing the test suites.
The test cases in each test suit generated by agglutinate hierarchy clustering exercise similar features of the application, and the performance results are still the same. It means that a considerable number of test cases are reluctant. If test cases picked in a test suite can cover the code area just as the corresponding test suit, so the test cases set can be formed a new test suite to replace the older one.
Suppose
Choose one test case US Keep looking for the test case US Repeat step 2 until
Finally, the further optimized set of test suites can be acquired.
This paper will show a running example with an e-business ordering web application to illustrate the test cases generation process.
E-commerce site
An online book shopping site is used in this experiment. The website can be downloaded at
E-commerce site used in experiment.
In order to collect user session data, our study team recruited some college students as volunteers. Volunteers were instructed to play the role of customers and encouraged to access e-commerce sites according to their own habits. Web logs are collected in a week after taking into account the time and efficiency of the experiment.
Preprocess the user session
After collecting the user sessions from the sever logs, it is needs to preprocess the session data. Uncorrelated and invalid data should be eliminated from the user sessions. There are two types of invalid data that should be eliminated:
Usually, the users of Web application do not explicitly request the graphics files and css files. Therefore, ending of the URL with jsp, jpeg, jpg, gif, css and js should be deleted. The failed requests whose return code is 4xx (request error) or 5xx (server error). After the user sessions are cleaned, each URL is represented by a token string.
After the data preprocessing, a total of 120 valid user sessions were collected. And there are 10 user session examples as follows:
The characters in quotes indicate that URL the user is accessing.
According to the algorithm in this paper, firstly it is needs to determine a similar distance threshold for stopping the clustering cycle. Due to the relatively simple business process of the book shopping website, the distance threshold of this experiment is set to 0.6 in order to reduce the number of test cases.
The first distance matrix calculation is performed firstly. The results are as follows:
The minimum distance in the matrix is d(u5, u9)
In the same way, we find out the minimum distance
Repeat the same calculation cycle, and the sixth clustering result is:
The test suite set calculated from the cluster result is as below:
Then representative test cases are selected from each test suite:
For
Under the premise of guaranteeing the order of the user’s session sequence, we compare the method of this paper with the traditional method. Methods without considering the order of the user’s session sequence are not in the context of comparison. According to the traditional user session-based test case generation method, all valid user sessions belong to a test case, so there are 120 test cases. And the test time takes 225 minutes. If use the proposed technique in this article, it only needs to generate 72 test cases, and the test time takes 72 minutes. Compared with the traditional method, proposed technique reduces test case number and test time by more than 40%, which can be shown in Table 1.
Comparison between the proposed method in this paper and traditional method
Comparison between the proposed method in this paper and traditional method
From the experimental results, it shows that the proposed technique in this paper can effectively reduce the number of test cases and generate valid test suites.
For the web application, which has been released for a period of time, this paper proposed a novel method named user-session-based performance testing based on a modified hierarchy clustering algorithm. The sequence alignment algorithm and the bottom-up hierarchical clustering algorithm are employed to select and optimize the test cases produced from user sessions. And the key technique is to calculate the diverging distance between user sessions on the premise of ensuring their sequentiality. From the experimental results, a prototype for online book shopping website demonstrates that the proposed technique costs less time and redundant test cases than the one that uses the user sessions directly to test the web application. And the proposed technique is significantly better than the other method which treats the sessions as sets of visited pages over a period of time and does not consider the sequence of click-stream visitation.
However, the work of testing web applications based on mining user sessions is a complex systematic project. It is not easy to get an effective and practical tool because the testing is over-dependent on the session data.
In the future, the authors plan to deploy more testing services and collect a variety of runtime information to perform corresponding analysis. Furthermore, performance evaluation of web application after performance testing is also needed to be researched.
Footnotes
Acknowledgments
This work was supported in part by the National Nature Science Foundation of China (No. 61370103), Guangdong Province Application Major Fund (2015B010131013) and Zhongshan Produce and Research Fund (2016A1038).