
Abstract
The software development and maintenance phase succeeded with significant regression testing activity. The software must be re-tested every time it upgrades to preserve its quality. Software testing as a whole is an expensive and tedious task due to resource constraints. Using the prioritization technique implies regression testing to re-test software after it has been modified. In this situation, the prioritization technique can use information acquired about earlier test case executions to generate test case orderings. The approaches for test case prioritization arrange them all in such a sequence that maximizes their efficacy in accomplishing specific goals. This paper presents a hybrid technique for change-testing or regression testing through test case prioritization. The suggested method first generates the test cases, then clustered in untested and unimportant groups using kernel-based fuzzy c-means clustering technique. The appropriate test cases are then considered for prioritization using the grey wolf optimizer. The results compared with the approaches such as ant colony, particle swarm, and genetic algorithm optimization method, and it is observed that the proposed approach efficiency increased by 91% of fault detection rate.
Introduction
Testing is a time-consuming and expensive process. It accounts for approximately half of all software development costs [1]. Cost and time can be significantly reduced by automating software testing processes associated with software development. Numerous software testing issues demand solutions, such as requiring the smallest possible collection of test data while meeting the highest possible coverage standards. Search-based software engineering is recasting software engineering works as an optimization problem.
The regression testing process is re-testing a program after its modification to ensure that its existing, modified, and new components behave correctly. In regression testing, test suite augmentation is used to determine which program code elements are affected by changes and to develop test cases targeting those parts of the code. Our previous work [2] detected changes and their affected parts in modified code. In this work, we generate test cases and prioritize the test suite to reduce the testing efforts. We proposed a kernel-based fuzzy c-means clustering (KFCM) technique for clustering the generated test cases into untested and unimportant ones. In addition, the grey wolf optimizer (GWO) method is evaluated for test case prioritization (TCP) using local and global search properties. The optimization is achieved by considering the affected elements in some order while generating test cases. Existing and newly developed test cases are combined, and the test case generation algorithms are utilized. Furthermore, the experiment validates that the test case generation algorithm influences the test case optimization, affecting cost and effectiveness.
The TCP techniques exclusively emphasize test cases that are more significant than others. This process helps to develop effective change-testing for the modified version of the software code. Selecting test cases restricts to cover the modified areas of the code. The technique of reducing and selecting the test cases decreases the test suite by eliminating unessential test cases or by picking only significant test cases. The major application area of the work is software evolution in regression testing and very useful for IT industries.
Several naturally inspired algorithms have been applied to priority test cases, such as genetic algorithms [3], particles swarm optimizations [4, 5], and ant-colony optimization [6], etc. In this document, we used a new nature-inspired optimization method, the GWO. The suggested algorithm is explored and evaluated in sample studies using the popular evaluation measure of the Average Percentage of Fault Detection (APFD). This research aims to find a method that prioritizes new test suites to find faults early and increase the fault detection rate.
Mirjalili et al. (2014) presented the GWO as a population-based swarm intelligence algorithm [7]. The researchers have highly considered this algorithm over the past 3–4 years. In this paper, the GWO algorithm is applied variably to extracted features of abstract syntax trees to optimize test suite augmentation. In addition, the algorithm is used to design change testing techniques that find change-related faults and reduce testing effort.
Related work
TCP is impactful work for regression testing. As the software matures, test suites tend to expand in size, eventually necessitating the use of expensive resources. The primary goal of running regression tests is to ensure that any changes made to a software module do not affect the unmodified components. In this situation, test cases created for revised software may produce correct results for that version alone. These test cases may produce erroneous outcomes for future software versions generated due to modifications to the first version. Regression testing may be useful in this case.
Simulated Annealing and Genetic Algorithm (GA) is applied for prioritizing test cases [8, 10]. The GA-based technique is used for TCP. In regression testing, TCP prioritizes test cases using the information available.
There are some metaheuristic search-based techniques used for TCP. To give priority to test cases Firefly algorithm is used [11]. The firefly algorithm is used with a fitness function that was determined by a model called similarity distance to optimize the ordering of the test cases. Rustam and Aini [12] applied fuzzy kernal c-means algorithm for intrusion detection.
Cuckoo Search (CS) algorithm is suggested for the selection and prioritization of test cases [13]. A CS method and Ant Colony Optimization (ACO) algorithm with modification opted for optimising the test cases in less time [14]. A Bat inspired algorithm is used the bat’s pulse emission rates for priority test cases with loudness and echolocation [15, 16].
For regression testing, all important change propagation paths are identified, and the method for handling several more complicated changes is expanded [17]. Gupta, N et al. (2018) presented a detailed study on the generation of test cases for regression for web-based applications [18]. Create two more Adaptive Test Prioritization strategies based on the fuzzy analytical hierarchy process and the weighted sum model [19]. A fuzzy expert system used for TCP in [20]. ACO based algorithm is used to optimize regression test [21]. A local beam search base meth-od is used for TCP [22]. The Cuckoo Search and Bee Colony Algorithm method is used for test case optimization and path convergence generation in a short time [23].
We conclude from the above literature that these algorithms have ended with higher time complexity issues in optimizing and prioritizing test cases. So, the major challenge was finding a method that reduced the time by tracing the faults on test cases as early as possible.
Methodology suggested
The regression testing method includes ensuring that any system updates carry out successfully and fulfil the expected expectations. Regression testing entails testing a variety of characteristics to ensure that they have not been damaged by changes to a specific feature or function. The ordering of test cases is being carried out to increase the efficacy of regression testing, and the regression testing test case priority problem is involved.
Strong research has been carried out on increasing the accuracy of regression tests, e.g., (1) identifying test cases that do not need to rework on a modified software version, (2) in a test suite that eliminates redundant test cases based on predetermined criteria. Therefore, it is necessary to determine whether the current test suites are appropriate for the changes in a program to regulate this efficiency. This paper focuses on the generation of test cases caused by changes. The changes either affect the software behaviour or introduce bugs.
Our new technique derives test cases from the considered applications. The suggested methodology combines various techniques to find the optimized test case sequence. First, a modified KFCM is used for test case clustering. This clustering technique put the generated test cases into two groups: important and unrelated test cases. The cluster of important test cases that are untested may be further processed. TCP is applied on the first cluster using a GWO. The purpose of test case prioritizing is to rank test cases to identify which cases are most likely to find code errors before it is released. Figure 1 shows the flow of our proposed technique.
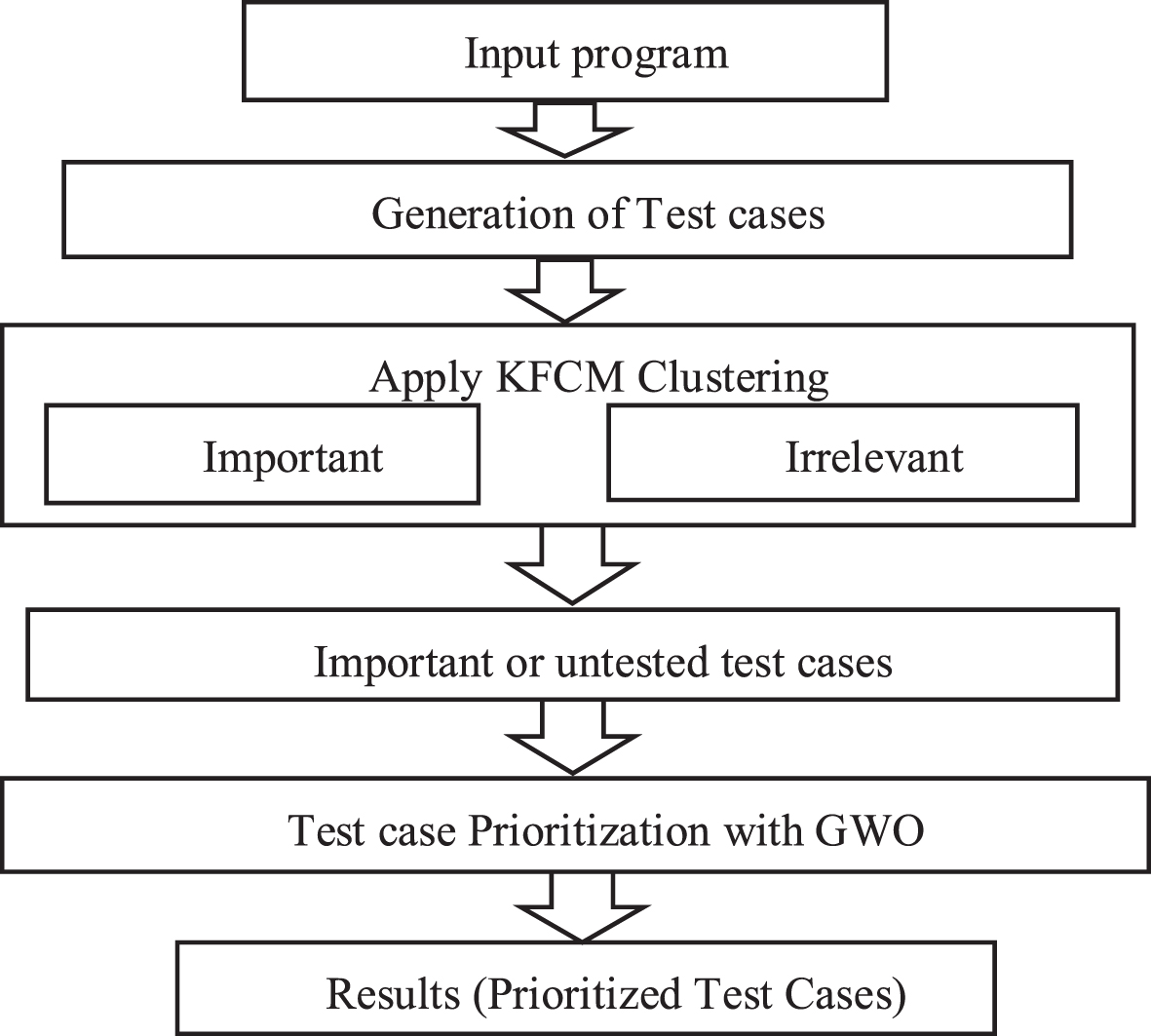
Flow for proposed test case generation and prioritization.
Due to program PO and its changed version Pn, the regression test suite can expose behavioral variations between the two programs and therefore assist developers in finding effects caused by changes or unintentional impacts of modifications introduced in Pn. Let the TO be the test suite for PO. It is needed to validate Pn occurs in regression testing. The test cases on TO is usually a concern of testers and various researchers that is more cost-effective with re-utilization in regression test.
Test suite augmentation strategies do not include the reuse of TO. Instead, the responsibilities concerned are (1) identifying the changed components as parts of Pn for which new test cases are required and (2) developing the test cases which exercise these components. In our previous work [4], we achieved the first requirement and identified the changed code. Here, our focus is on the task of test case generation for identified changed elements on Pn.
Changed code testing
One reason regression tests exist is to ensure that any alterations made to the software don’t negatively affect the functionality of all software modules. When working on regression testing, the best method is to follow TCP approaches that move high-risk test cases to the front of the list and work down from there. A test case clustering method is used to categorize the developed test cases into important and unimportant test cases. A KFCM method is used for clustering purposes. TCP starts with sorting test cases from clustered relevant cases. A TCP’s primary purpose is to find a test case order that will help to maximize the possibility of finding software defects earlier
Clustering with KFCM
With the help of kernel-based FCM techniques, we will prioritize our regression test cases in this research paper. The technique under consideration employs various kernel fuzzy c methods for grouping individual jobs. Our approach is similar to fuzzy c means, which will identify similarities between test cases by calculating metrics on their coverage. A method using kernel functions in place of Euclidean distance to strengthening linear machine capabilities. Samples are mapped to high dimensional space, increasing the disparities between the cluster centers and eliminating FCM shortcomings.
Our system uses an algorithm called clustering for grouping current test cases based on the similarity of coverage measures. The following Equation (1) summarizes the objective function (OF) of the proposed kernel based fuzzy c-means method.
Where 1≤i≤n, 1≤j≤c and 0 ≤ μi,j ≤ 1
U = (μi,j) nXc = membership function of ith element of jth cluster
S = set of data points
A = Positive definite matrix
n = no of elements in a set
c = no of clusters
r = degree of fuzziness for partition
x i = ith element of a set
V
j
= mean of ith point on jth cluster and calculated as Equation (4):
The goal is to minimize OF with Equation (5):
V i = meanofA i
The KFCM is obtained by combining FCM with the kernel function, and the optimal objective function is obtained as Equation (6):
Define kernel function as k (x, y) = 〈f (x) , f (y) 〉 where 〈f (x) , f (y) 〉 is an inner product [28].
Where f : R
d
→ F, R
d
= data space, F = feature space,
We have considered these kernels for our work. The below steps are followed for clustering through KFCM:
Step 1: Initialization of the number of test cases τ, number of clusters c (c≥2), and random value r.
Step 2: Start with fuzzy c partition (FCP) of U and S
Step 3: Calculate the mean (cluster center) using Equation (8) as:
In KFCM τ i represented by kernel function k (x, y).
Step 4: Calculate the membership function of ith data of jth cluster as Equation (9):
Where (di,j) 2 = k (x i , x i ) -2k (x i , V j ) + k (V j , V j )
Step 5: Go to step 3 until convergence criteria are not satisfied. (The data point belongs to a particular cluster or not)
We will predict an error using this kernel-based FCM. The final phase is error localization, in which we will determine the position and cause of an issue. The clustering process is used to categorize the developed test cases as either important or unimportant. Next to test case clustering, important/untested test cases are examined for test case priority. The purpose of prioritizing test cases is to identify the sequence of test cases that optimizes the chance of discovering source code defects early.
TCP
The test case selection for change code testing is an important part of our study. PT represents all potential orderings of T, and function f takes a given ordering of T and generates a corresponding specific value. It’s defined below: test suite T has several permutations PT, and the function f takes PT and turns it into real numbers. a T that satisfies the constraints (∀T) (T ≠ T).
Tre are several possible priorities mentioned here: Tting team might desire to enhance a fault dection rate for the test suite or the probability of discovering defects sooner in executing the test suite for regression tests. Tm may desire to improve the rate at which a test suite detects high-risk errors, therefore discovering them sooner during the testing process. The team may desire to enhance the probability of discovering errors associated with certain code modifications sooner in the regression testing process.
The priority levels have several conceivable aims. A grey wolf pack’s social order is replicated by the GWO algorithm.
GWO
GWO is a population-based swarm intelligence system motivated by the grey wolf dominance hierarchy [10]. Grey wolves coexist with humans. Each pack comprises between 5 and 12 people. Assume that each wolf is scouring the search space for a solution. The variable w i = wi1, wi2, . . . , w in denotes the position vectors of the wolves in the search space, whereas the size of the dimension is denoted by n. There are four grades of members in the pack’s dominating hierarchy.
Encircling prey: Following is the mathematical model for the process of encircling prey given as Equation (11),
Where
Coefficient vectors Where
The vectors
Where value of
The value of the wolves’ fitness function is computed using the new locations, and α, β, and δ will be picked. The population n of the grey wolf is the number of tt cases obtained from the path coverage on changed or affected components. The GWO method is used to determine the efficiency and usage of each hosted re. The termination of an algorithm happens after t termination criteria are met. After the GWO md computes a score, the prioritizing process bins,s occurs based othe score generated. zed tt suite is more useful afulfilling the prioritizing objective for modified code in a specific way and is more suited to achieve success in a single release than test suites developed from broad TCP. Last, we discuss how to prioritize regression test cases and reduce testing effort; this methodology is not limited tst-development testing.
The proposed method using KFCM with GWO is implemented on Windows 10 with 8GB RAM, Intel Core i7,4690T central processing unit, 2.50 GHz, 64-bit OS, x64 based processor. An anaconda environment is used for the GWO algorithm. We have taken a Python program of the triangle and angle classification problem for empirical evaluation. The generated test cases are clustered and considered for prioritization for regression testing. To quantify the aim of enhancing the rate of fault detection for a portion of the test suite, we utilize a measure called APFD.
Prioritized test suite sequence using GWO
We have used the GWO algorithm to prioritize test case sequences in the test suite for early fault detection for regression testing. The total test case 5 of test suite T is initialized as the pack size of wolves. The total population is t1, t2, t3, t4, t5. The position vector
Where t = current iteration
max t = maximum no. of iterations
The values of search agents are updated by comparing the values with the fitness value. The algorithm is terminated after the termination criteria are satisfied. After termination, we have achieved a prioritized test case sequence which helps to detect maximum faults as early as possible. The prioritized test sequence t3 - t4 - t2 - t5 - t1 is generated.
This parameter indicates the rate of fault detection with the percentage of test suite execution. It is a metric used to analyze and compare the performance of different approaches for priority test cases. To measure how quickly a prioritized test suite discovers problems during test suite performance, we utilize a weighted average number of faults discovered or APFD. These values vary between 0 and 100; higher APFD figures indicate faster (better) error detection rates. The APFD is derived by averaging the proportion of defects identified during the test suite’s execution. The following formula, as in Equation (17), may be used to determine the APFD:
Where:
Tf m test suite contains n number of test cases f set of m faults.
Tf1 is the first test case in T that exposes faults i.
The number of test cases or test paths n = 5 for the example we have considered. So T ={ t1, t2, t3, t4, t5 } that detects m = 6 number of faults F ={ f1, f2, f3, f4, f5, f6 } on the basis of the branch coverage prioritization technique (Rothermel et al., 2001).
Table 1 consists of the test cases and their corresponding detected faults in the form of a matrix.
Tests and faults matrix
Tests and faults matrix
Test case t1 detects 3 faults from a total of 6 faults which is 50% of fault detected when 0.2 test case of test suite T1 is used. The next test case is t2 have detected 3 out of 6 faults, which means again, 50 % of faults have been detected by 0.4 test cases of the same test suite. For t3, the total fault detected is 4 out of 6, which is 67%, and 0.6 test cases of the test suite. In the same way, this test suite which has a default sequence t1 - t2 - t3 - t4 - t5 gives an APFD of around 56%.
The prioritized test suite with a test sequence obtained from GWO algorithm and the order is changed from T1 to T i at ith iteration as t3 - t4 - t2 - t5 - t1. This prioritized order gives APFD 91%. The value of APFD for T i is much higher than the APFD for T1. Higher APFD values imply faster rates of error detection. Figure 2 shows a comparative chart for APFD for a non-prioritized test suite. Figure 3 depicts a comparative cht for APFD for the prioritized test suite. It is evidenat this order leads to the quickest identification of the most defects and shows an optimum APFD order of 91.
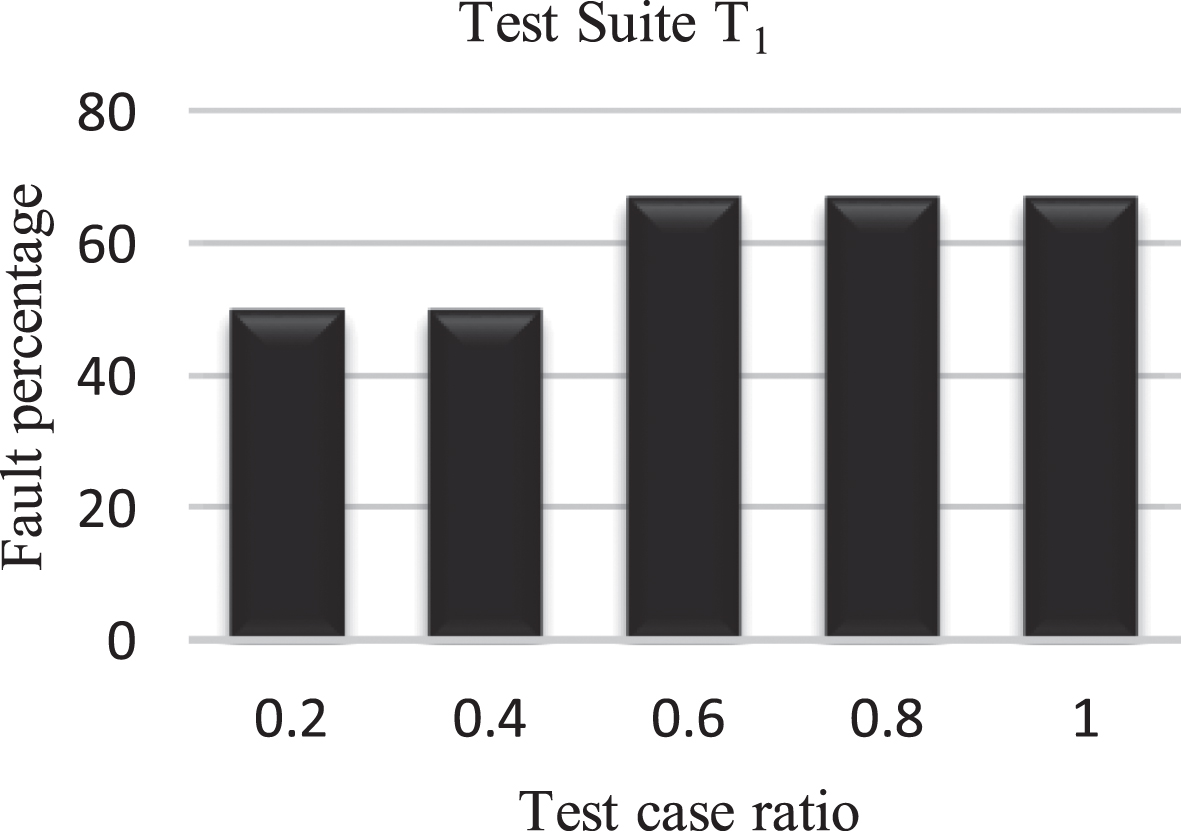
APFD for Non-prioritized test suite.
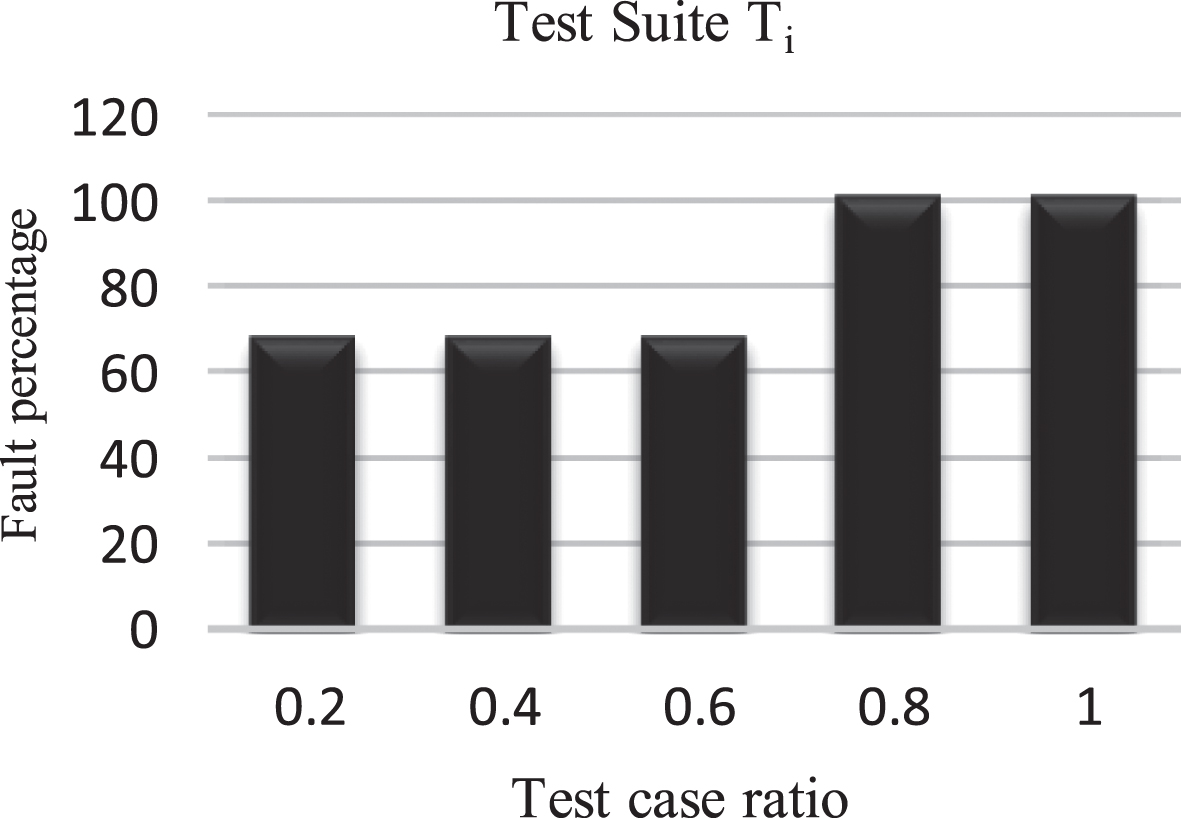
APFD for Prioritized test suite.
The time obtained for generating a prioritized test case on a different number of iterations is given in Table 2.
Time elapsed to prioritized test cases on the number of iterations
The time taken for various iterations gradually increases accordingly.
As shown in Table 2, the 10th iteration takes 334.9 ms, and the 100th takes 916.83 ms of time, respectively.
The significance of results drawn from the proposed method is interpreted as the proper ordering of test cases in the test suite finding maximum faults in a few iterations and in less time.
To evaluate the suggested method’s performance, we compare its outcome with current methods. The result of our technique is compared with other prioritization techniques based on APFD in a generalized way.
The proposed technique gives better results for APFD in comparison to other methods. Panwar D et al. (2018) proposed a cuckoo search-based method that ended with a 70.17% fault detection rate [14], and CSBCA based approach of Lakshminarayana P (2021) achieved a 65% fault case detection rate [23]. Table 3 shows the various technique suggested and their fault detection rate.
Comparative analysis
Comparative analysis
Table 3 shows that our projected framework based on the GWO algorithm is achieving a better fault detection rate for TCP than other techniques mentioned. This increases the calculation efficiency and demonstrates that our proposed technique is more efficient than the existing methods.
The test case generating approaches are designed to create as many test cases as possible for each scenario. Then, suggested a framework using GWO based algorithm to prioritize the test cases. Our suggested technique was assessed using the APFD assessment measures. The time required for prioritizing test cases is significantly reduced compared to previous approaches, and the results are also accurate. The results demonstrate that the GWO beats the other classification strategy by enabling very high accuracy. As a result, we can see that our suggested approach outperforms previous work in terms of regression test case prioritizing.
Conflict of interest
Authors have no conflict of interest.