
Abstract
Community detection is an important way to describe the evolution of network events. In order to study.how to differentiate network community structure accurately and effectively, and solve the problem of the Sync clustering algorithm directly connected nodes without common neighbor nodes existing similarity underestimated tendency, and the synchronization time being too long, we put forward a method which breaks edge disconnection between connected nodes directly and add auxiliary nodes. We can think that the two nodes are connected by the secondary node and the edge of the two nodes connected respectively, and then realize the improvement of node similarity. Secondly this paper uses neighborhood radius to divide community, and detect the community before the node object has reacded fully synchronous. Simulation experiments are done respectively on the artificial data and real data sets generated, and the results show that the improved algorithm is more accurate to effectively find community structure compared with the original algorithm.
Introduction
Wireless Mesh network is an important wireless broadband access technology. Its advantges are the self-organiing, large coverage, easy maintenance, good network scalability, and low cost, and it is the important option of Internet for the “last kilometer” extension [1] mesh customer base has resulted in the server load stress. Researches indicate that community can be explored according to the geographic information of P2P network node society, and guide them in the same community for data exchange, which can alleviate the load on the server, so community detection plays an important role to relieve the load on the server.
Community structure of internal corporate links closely, and sparse between corporate connection [2, 3]. So far, scientists have come up with a large amount of network community discovery algorithms such as optimization algorithm based on the module, hierarchical clustering, spectral clustering and Sync clustering algorithm [3, 4, 5, 6, 7, 8, 9, 10]. There are some defects in these methods such as community number and some parameters. Sync algorithm thinks that the connecting edge between two nodes and no public neighbors have no similarity, this may underestimate the similarity between them, and the synchronization algorithm cost too much time to deal with mass of data. Regarding these problems, this paper considers the impact on the similarities between connected nodes directly, and improves the similarity of Sync clustering algorithm. It can detect the community structure before complete synchronization object by using the principle of neighborhood closures and module changing trend at the same time, which reduces the time of the dynamic interaction of node objects greatly, and this method does not need to know the number of the community in advance.
Sync clustering algorithm
Huang et al. propose a community discovery algorithm which bases on synchronous dynamic model (Sync) [11]: Given an undirected weighted networks
The oscillator phase values of convergence are regarded as a community finally. If it is a undirected network, Eq. (1) is equivalent to Eq. (2):
It uses the clustering order parameter to describe oscillator level of synchronization between the nodes [12]. The formula is as follows
Sync clustering algorithm uses the
When using the Sync synchronization algorithm in the process, under the effect of partial synchronization [13], as time goes on, more and more node objects are synchronized, and the value of is becoming bigger and bigger. When nearly reaches 1 of the preset value, the clustering will end, and now we think the synchronization of node objects to be completed, and the node objects in the same community move to the almost same coordinate point. However, to achieve synchronization is a relatively long process of dynamic synchronization. The efficiency of the algorithm is low. For the sake of easy, symbols in this article are introduced in Table 1.
The improved similarity measure
There are similarities that tend to be underestimated in the Sync algorithm. The article considers the similarity between nodes from two cases: between the connected two nodes and endless connected, as shown the nodes
The symbols are used in this article
The symbols are used in this article
An edge between x and y.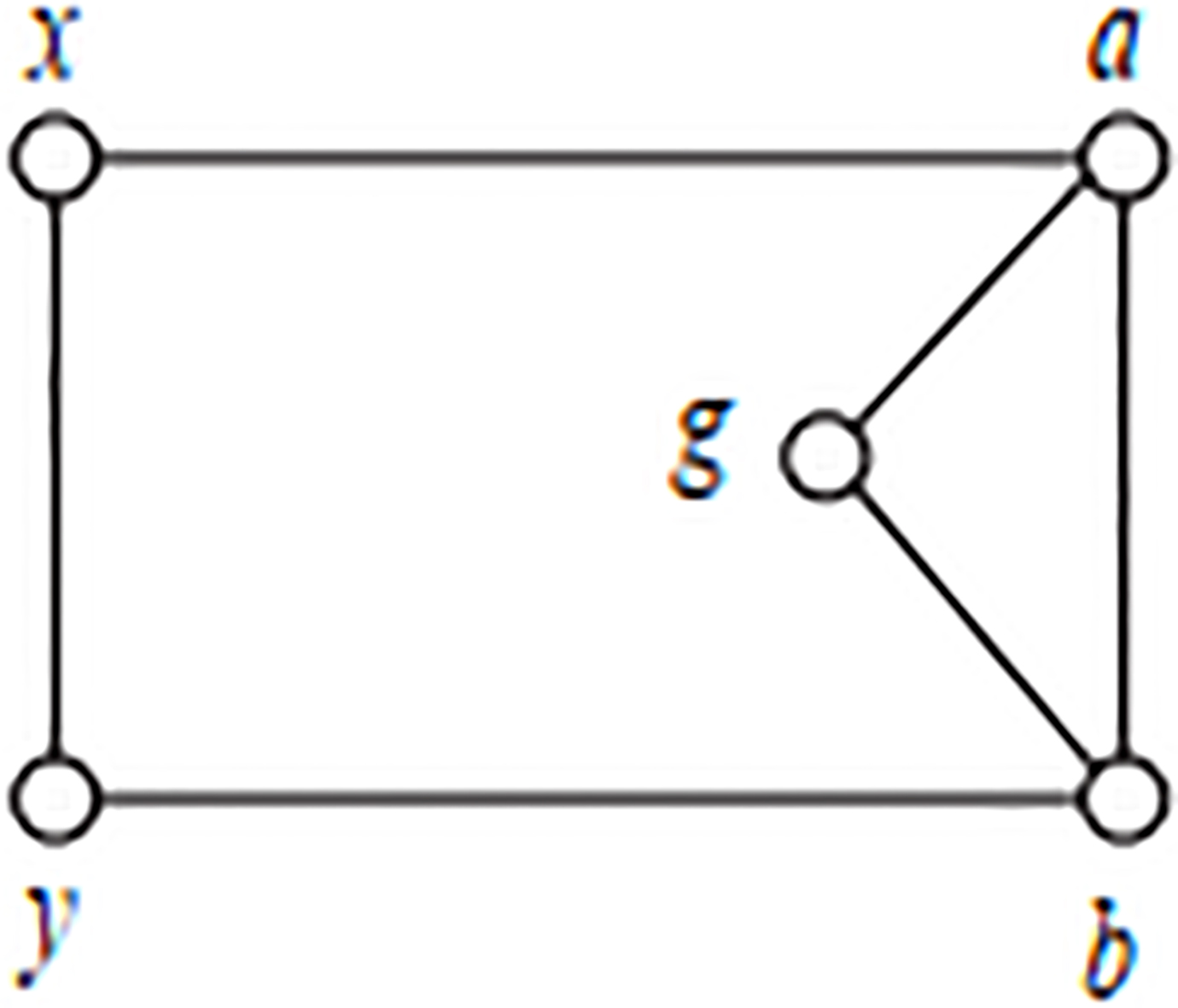
No edge between x and y.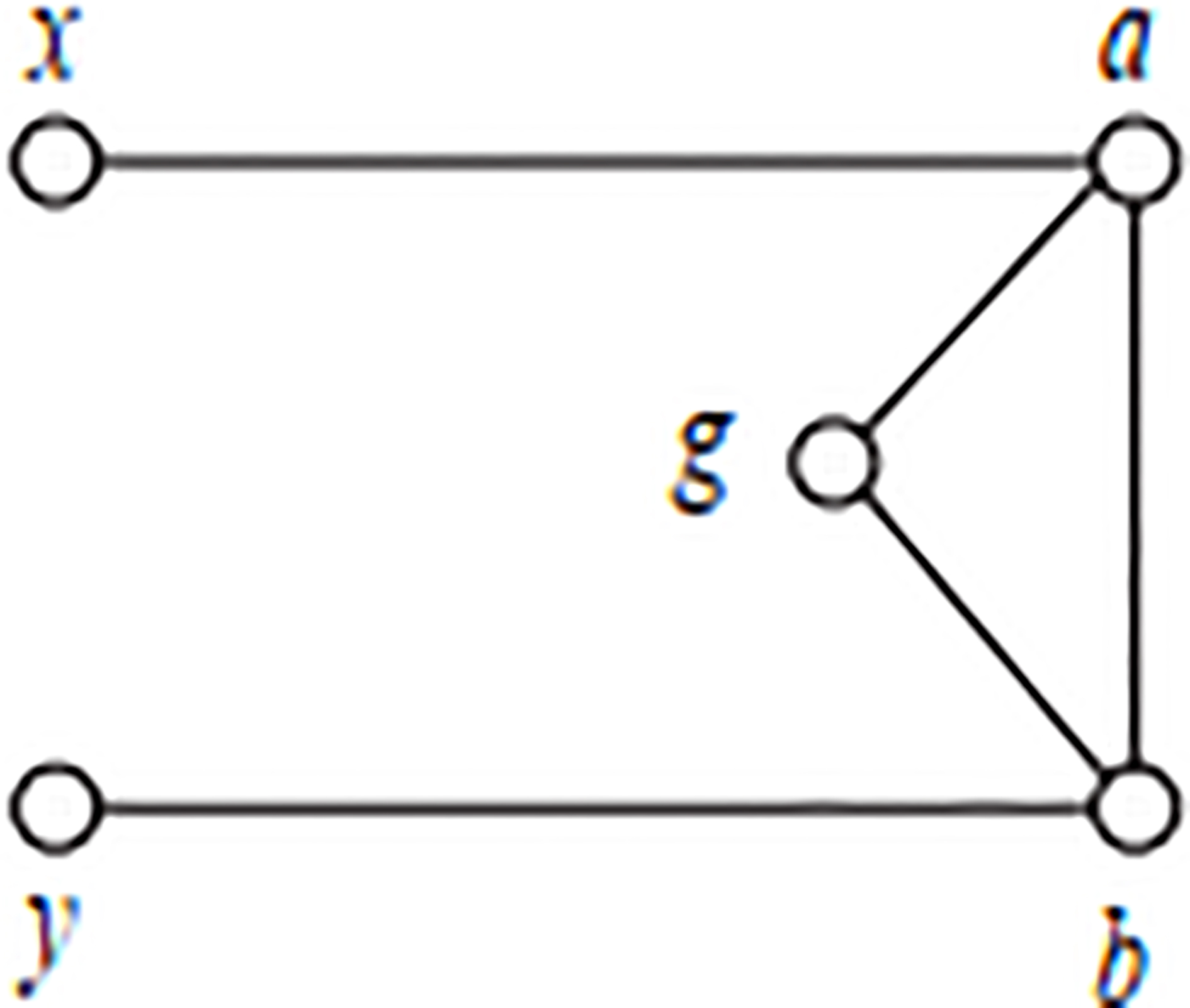
Adding auxiliary c.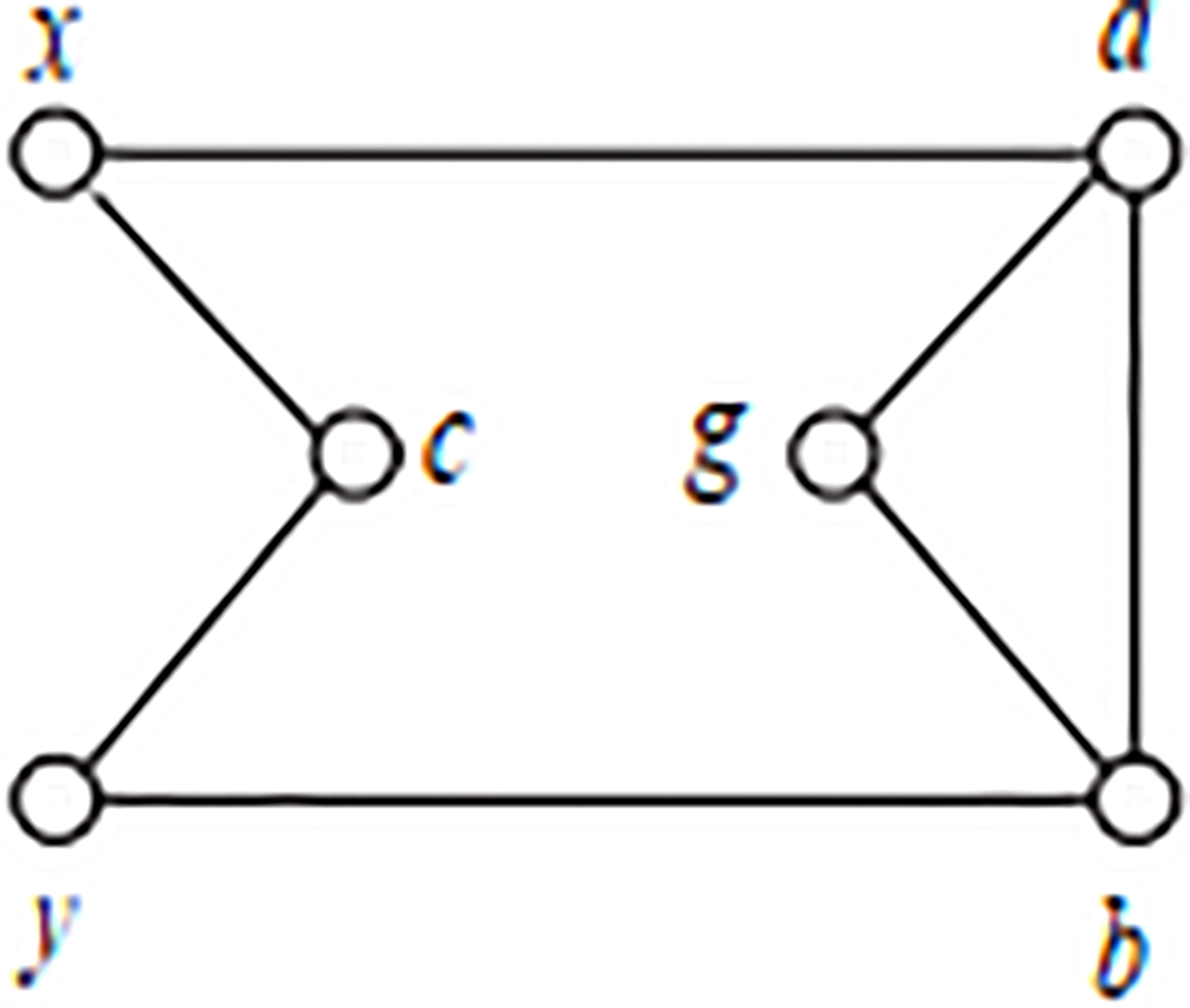
If the adjacency matrix of the network is A, Eq. (4) is equivalent to Eq. (5):
The similarity of two nodes after adding a secondary node c is Mxy, put the adjacency matrix A into the Eq. (5):
In the Eq. (6), 1 means the adding common neighbor node c. Other public node numbers are equal to the public node numbers with not auxiliary node, acted, we can use Eq. (7) to calculate. Therefore, the similarity of any node can be represented by Eq. (7).
Put Eq. (7) into Eq. (2).and get Eq. (8).
Figure 4 is a simple network diagram which contains two communities. One community contains a, b, c, d, and the other contains e, f, g, h. Table 2 is the similarity of sequence got by two kinds of similarity index. Sxy represents improved similarity index, and Mxy represents unimproved similarity index. We can see from Table 2 that node a and node c have the highest similarity in Sxy. This is due to node a and node c have the maximum number of neighbors, the second is the g. Node a and node b are connected directly but have no neighbors, their similarity is 0. This is not conform to the network’s actual division. Sxy only considers the shared neighbor nodes, and it underestimates the directly connected neighbor nodes without similarity. For Mxy, node a and node c have the highest similarity, followed by d, b or g. The similarity between node a and node b is not zero when we use Mxy to calculate. The improved similarity coefficient can better reveal similarity between nodes in complex networks from this simple case.
Order table of similarity of nodes
Order table of similarity of nodes
A simple network.
Figure 5 simply describes the meaning of $-neighborhood closure. This paper mainly studies the nodes on the OX axis movement. There are nodes a,b,c,d in $-neighborhood of the node a, that is N$(a)
The algorithm of this article uses $-neighborhood closure instead of the order parameter s in Sync clustering algorithm, to detect the community structure before arriving in complete synchronization object, thereby significantly reducing the number of times synchronization among the node objects, and improves the efficiency of the algorithm.
$-neighborhood closure.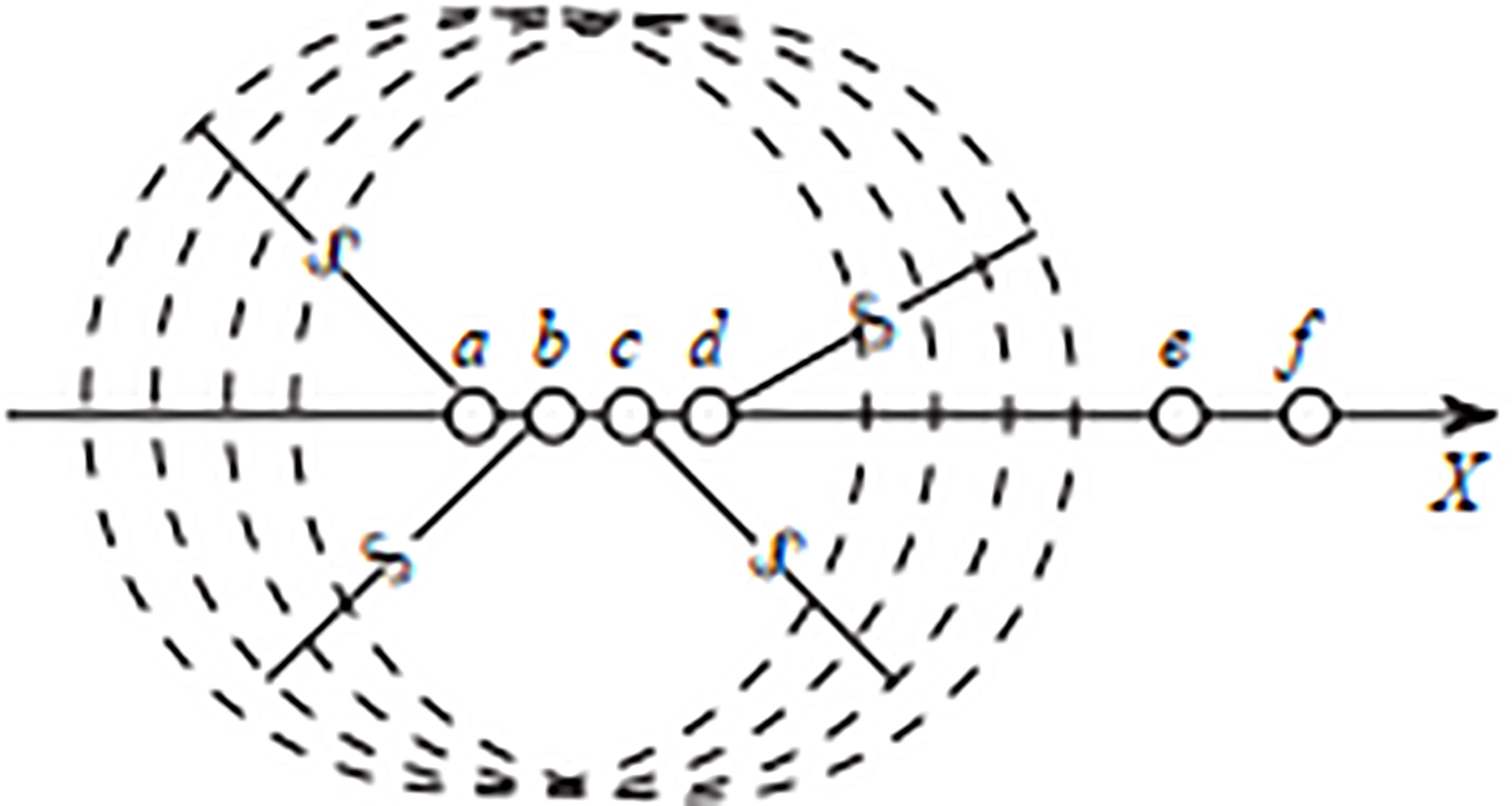
Proof. Each node object is effected only by its $-neighbors according to Eq. (8). When N$ (x) is a $-neighborhood closure,the nodes in the object set Y are $-neighborhood closures each other, and the node object in $-neighborhood closure meet the transitive closure properties, so any objects are in the Y only forced by other objects in the collection, and the node objects outside of the set have no effect on it, therefore the node objects in the Y only move in the area, moreover the edge nodes far from the center of move toward the center of the $-neighborhood under the impact on the other nodes of the set. This makes the collection radius is shrinking, and will eventually reach synchronization completely.
Proof. Given a $- a neighborhood parameter in the node set Y. Any object xi $-neighborhood N$(xi) of the collection is a subset of the set Y. If There shown in Fig. 6, x and g are unstable data. The unstable node object x and the stable objects in the set of Y are different. It is influenced by on not only the data in set N$(x) but also the data in set is the following: (1) Movement towards a certain N$(xi). This separates oneself from other N$ (x) to his influence. (2) The multiple node objects in N$(x) are influenced by x. This will gradually move closer to the $-neighborhood of x, and the final will be merged into one N$ (x). The Unstable data in set Y will always move in the light of the above two cases, until these data become stable. So any nodes of set Y in the process of synchronization will reach $-neighborhood closures.
Unstable data.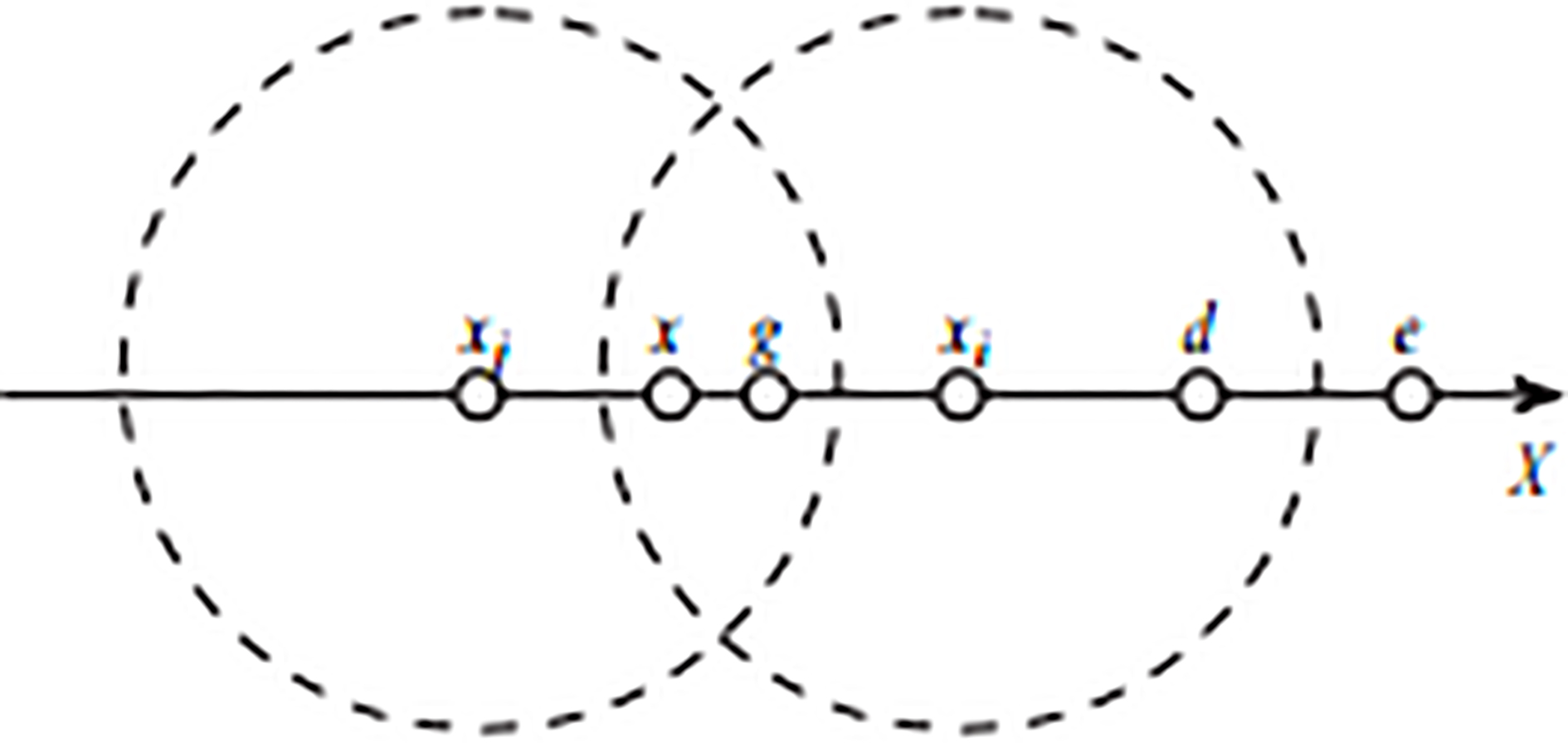
Given an undirected network G
Set the value of the parameter $; According to Eq. (8), we can get the new node coordinates after synchronization of each node within its $-neighborhood radius of node; We can get the new node coordinates according to step 2, then make the nodes which has not been divided into a community and its $-neighbor-hood radius of node into a community in turn; Calculate the classification results of the modularity Q, and compare with the last partition modularity. If the Q is always declining, then the result is the optimal community, and output the optimal community structure. If Q is not declining,then go to step 5. Increase the value of $, and repeat step 2. detection by gradually increasing the value of $ and synchronizing many times. First, choose the small- er parameters $ to synchronize ($
Part of the algorithm code is as follows:
input: d
output: Results of dividing network communities
public double[] dYt(int[][] G,double[] v,double $,int count)
Sync6 tong2
TongBuSuanFa5 tong5
double[][] simaryPoint
if(count
for(int i
double h
for(int j=0;j
// With each node as the active object, determine $ neighborhood the object of each active object
if(Math.abs(v[i]-v[j])
// at present, the point v[j] is in the point v[i] $-neighborhood
double sin=v[j]-v[i]; h+=simaryPoint[i][j]*Math.sin(sin);
d++;
// v[i] is the coordinate of the node i
v[i]+=(1.0/d*h);
System.out.println("the order" +count+" the iteration: ");
//According to the coordinate value, the clustering of several $-neighborhood closures is found, and
the result of each synchronous division of communities is obtained.
tong2.linyu($, v,G);
//The $ parameter can be changed
$+
count++;
// the iteration
v=dYt(G, v, $,count);
return v;
The algorithm realizes division of associations by gradually increasing the value of the neighborhood radius. At first, the smaller parameters are selected for synchronization (in the following experiments, $
The experimental environment
In order to verify the feasibility and effectiveness of the improved algorithm, we do experiment not only in computer-generated graphs [19] but also in real-world graphs. The algorithm is written by Java, and we use MATLAB [20] to draw. All the experiments are completed in the computer with 2.6 GHZ CPU and 4 GB of memory.
The evaluating indicator
This paper uses two indicators to evaluate the algorithm: modularity and running time.
Modularity [21]: To evaluate the validity and rationality of the divided network community structure,Newman et al put forward the concept of modular degree, which is regarded as the evaluation index of division community effect. The formula of modular degree
Where, Uptime: An indicator used to evaluate the efficiency of the algorithm. The shorter the running time is, the higher efficiency of the algorithm is.
It compared with module degrees and running time changes of the improved algorithm and the sync algorithm to verify the rationality and effectiveness of the improved algorithm.
Experimental process of artificial network data set
The experimental steps are as follows:
It generated GN benchmark network [22] by computer to verify our algorithm. The network consists of 128 nodes and 4 communities, in which each community contains 32 nodes, and the expected value of each nodal degree is 16.
The experiments adopted
The modularity of the two algorithms is compared as shown in Fig. 7, and the synchronization time comparison is shown in Fig. 8.
Modularity as a function of 
The running time of the contrast on computer generated graph.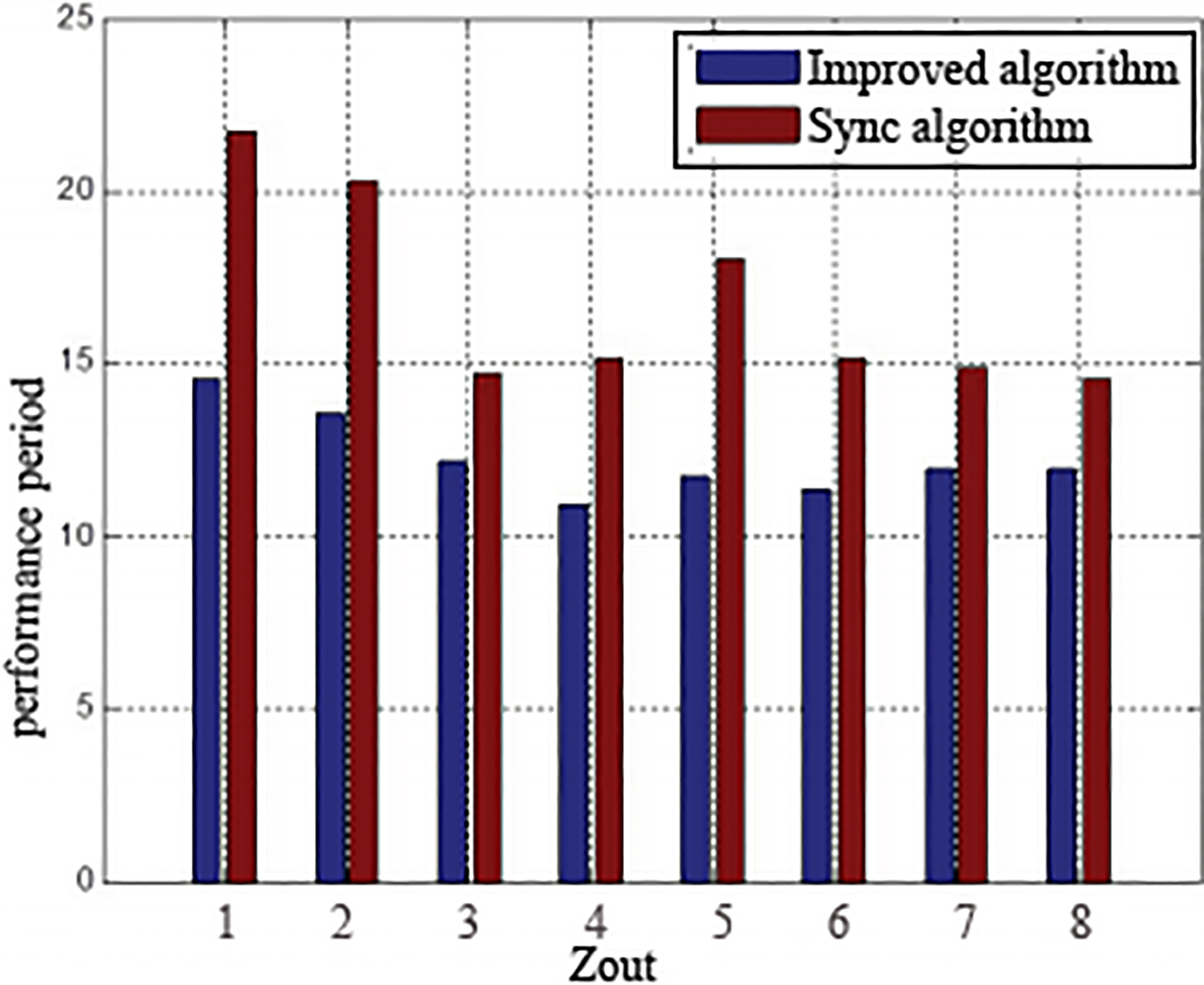
We can see from Fig. 7: The larger the value of
As can be seen from Fig. 8: When the two algorithms synchronize on the same
Zachary Club Network [23, 24, 25] is a real social data network set, It’s based on social relations among 34 members of a karate club at a university in the United States. The network consists of 78 edges and 34 nodes. The experimental results of the network is divided into community by using the improved algorithm as shown in Fig. 9. Comparison of experimental results on real network data sets
Result acquired by using this algorithm to dividekarate club network.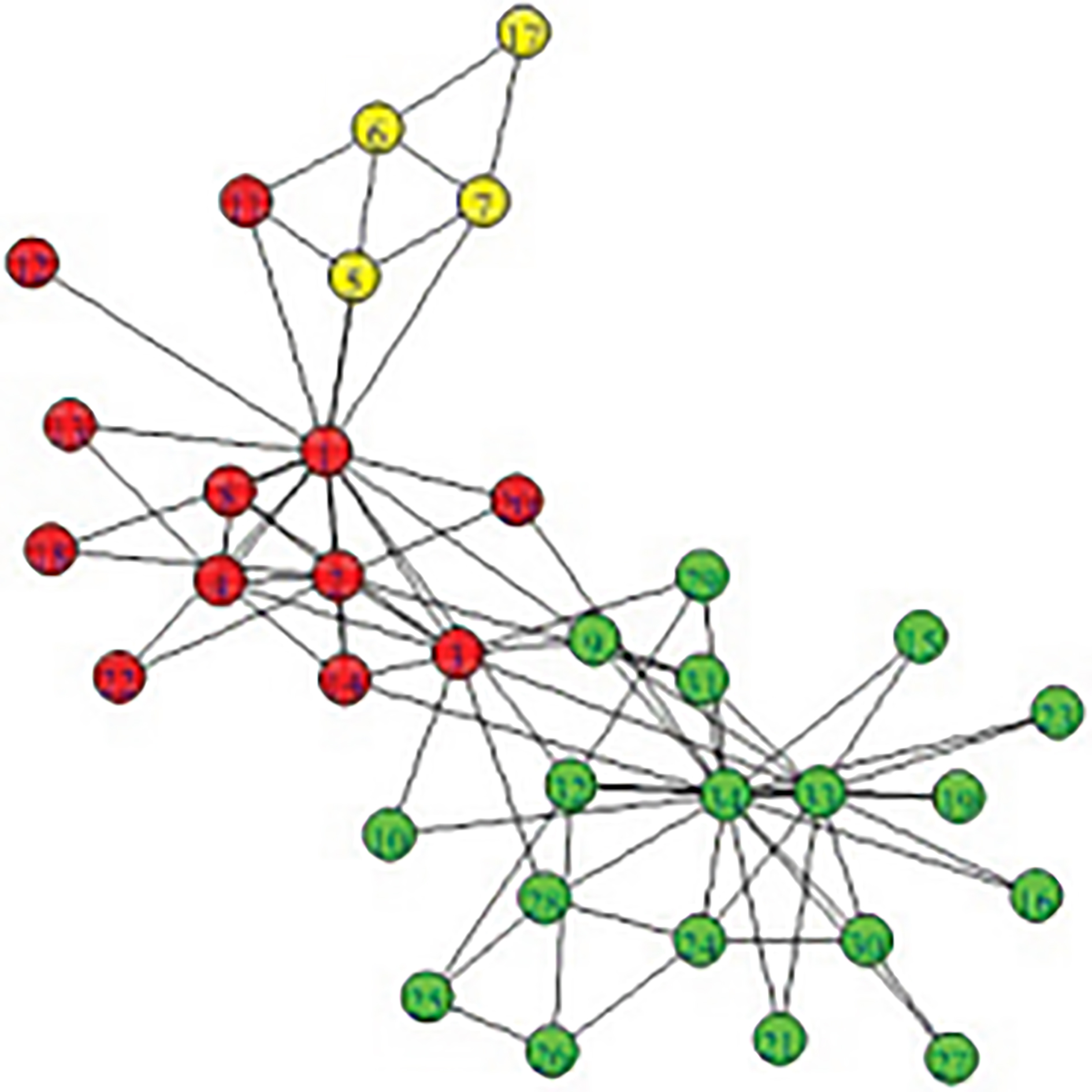
Zachary karate club network is divided into different communities, and the gap between the experimental results and the real community division results is very small, which proves that the algorithm is reasonable and effective in small networks.
This paper also does an experiment on the American University Football League network. The network was built on the basis of the regular season schedule for 2000 fall season. The network node represents the team, and the side represents the match between the teams, The network consists of 115 nodes and 616 edges. The experimental results of the network is divided into community by using the improved algorithm as shown in Fig. 10.
Result acquired by using this algorithm to divide NCAA football network.
As you can see from Fig. 10: The community structure that is divided by using this algorithm is very clear, and the effectiveness and feasibility [26, 27] of the improved algorithm are proved in large scale networks .
In order to verify the efficiency of this algorithm we also record the operation frequency and synchronization time of above experiment. Table 3 is the comparison of synchronization steps and time consuming.
From Table 3, we can see that the modularity
As we can see from Table 3, the improved algorithm divides communities in less time. This is because the improved algorithm uses the domain radius to divide the network, it replaced clustering order parameters in sync clustering algorithm with $-neighborhood closure and detected the community structure before the object reaches full synchronization. Thus, the number of synchronization between node objects is greatly reduced, and the algorithm efficiency is improved.
Based on the sync clustering algorithm, a new method to measure the similarity between nodes is proposed in this paper. It combined with the concept of neighborhood closure. When the module degree is decreasing, the community division stops, and the result is the community partition result. This method of discovering community structure in advance greatly reduces the time of dynamic interaction between node objects. The experimental results show that it is compared with the original sync clustering algorithm, and the improved algorithm not only improves the running efficiency, but also improves the partition effect. It can be applied to wireless mesh networks. however, when the algorithm is used to divide the community, it has some limitations on the value of neighborhood radius, and the appropriate neighborhood radius can get a better result of the community division. So finding the appropriate parameter value is the focus of the next research.
Footnotes
Acknowledgments
This work was supported by the National Natural Science Foundation of China (No. 11601129), the Key Science and Research Programs in Universities of Henan Province (No. 16A120013), Jiaxing Sci-ence and Technology Project (No. 2012AY1027) and Henan Polytechnic University doctoral fund (No. B2013-035).